One month into his second term, President Trump’s actions to shrink the government through mass layoffs, firings and withholding funds allocated by Congress have thrown federal cybersecurity and consumer protection programs into disarray. At the same time, agencies are battling an ongoing effort by the world’s richest man to wrest control over their networks and data.
Image: Shutterstock. Greg Meland.
The Trump administration has fired at least 130 employees at the federal government’s foremost cybersecurity body — the Cybersecurity and Infrastructure Security Agency (CISA). Those dismissals reportedly included CISA staff dedicated to securing U.S. elections, and fighting misinformation and foreign influence operations.
Earlier this week, technologists with Elon Musk’s Department of Government Efficiency (DOGE) arrived at CISA and gained access to the agency’s email and networked files. Those DOGE staffers include Edward “Big Balls” Coristine, a 19-year-old former denizen of the “Com,” an archipelago of Discord and Telegram chat channels that function as a kind of distributed cybercriminal social network.
The investigative journalist Jacob Silverman writes that Coristine is the grandson of Valery Martynov, a KGB double agent who spied for the United States. Silverman recounted how Martynov’s wife Natalya Martynova moved to the United States with her two children after her husband’s death.
“Her son became a Virginia police officer who sometimes posts comments on blogs about his historically famous father,” Silverman wrote. “Her daughter became a financial professional who married Charles Coristine, the proprietor of LesserEvil, a snack company. Among their children is a 19-year-old young man named Edward Coristine, who currently wields an unknown amount of power and authority over the inner-workings of our federal government.”
Another member of DOGE is Christopher Stanley, formerly senior director for security engineering at X and principal security engineer at Musk’s SpaceX. Stanley, 33, had a brush with celebrity on Twitter in 2015 when he leaked the user database for the DDoS-for-hire service LizardStresser, and soon faced threats of physical violence against his family.
My 2015 story on that leak did not name Stanley, but he exposed himself as the source by posting a video about it on his Youtube channel. A review of domain names registered by Stanley shows he went by the nickname “enKrypt,” and was the former owner of a pirated software and hacking forum called error33[.]net, as well as theC0re, a video game cheating community.
DOGE has been steadily gaining sensitive network access to federal agencies that hold a staggering amount of personal and financial information on Americans, including the Social Security Administration (SSA), the Department of Homeland Security, the Office of Personnel Management (OPM), and the Treasury Department.
Most recently, DOGE has sought broad access to systems at the Internal Revenue Service that contain the personal tax information on millions of Americans, including how much individuals earn and owe, property information, and even details related to child custody agreements. The New York Times reported Friday that the IRS had reached an agreement whereby a single DOGE employee — 25-year-old Gavin Kliger — will be allowed to see only anonymized taxpayer information.
The rapidity with which DOGE has rifled through one federal database after another in the name of unearthing “massive fraud” by government agencies has alarmed many security experts, who warned that DOGE’s actions bypassed essential safeguards and security measures.
“The most alarming aspect isn’t just the access being granted,” wrote Bruce Schneier and Davi Ottenheimer, referring to DOGE as a national cyberattack. “It’s the systematic dismantling of security measures that would detect and prevent misuse—including standard incident response protocols, auditing, and change-tracking mechanisms—by removing the career officials in charge of those security measures and replacing them with inexperienced operators.”
Jacob Williams is a former hacker with the U.S. National Security Agency who now works as managing director of the cybersecurity firm Hunter Labs. Williams kicked a virtual hornet’s nest last week when he posted on LinkedIn that the network incursions by DOGE were “a bigger threat to U.S. federal government information systems than China.”
Williams said while he doesn’t believe anyone at DOGE would intentionally harm the integrity and availability of these systems, it’s widely reported (and not denied) that DOGE introduced code changes into multiple federal IT systems. These code changes, he maintained, are not following the normal process for vetting and review given to federal government IT systems.
“For those thinking ‘I’m glad they aren’t following the normal federal government IT processes, those are too burdensome’ I get where you’re coming from,” Williams wrote. “But another name for ‘red tape’ are ‘controls.’ If you’re comfortable bypassing controls for the advancement of your agenda, I have questions – mostly about whether you do this in your day job too. Please tag your employer letting them know your position when you comment that controls aren’t important (doubly so if you work in cybersecurity). All satire aside, if you’re comfortable abandoning controls for expediency, I implore you to decide where the line is that you won’t cross in that regard.”
The DOGE website’s “wall of receipts” boasts that Musk and his team have saved the federal government more than $55 billion through staff reductions, lease cancellations and terminated contracts. But a team of reporters at The New York Times found the math that could back up those checks is marred with accounting errors, incorrect assumptions, outdated data and other mistakes.
For example, DOGE claimed it saved $8 billion in one contract, when the total amount was actually $8 million, The Times found.
“Some contracts the group claims credit for were double- or triple-counted,” reads a Times story with six bylines. “Another initially contained an error that inflated the totals by billions of dollars. While the DOGE team has surely cut some number of billions of dollars, its slapdash accounting adds to a pattern of recklessness by the group, which has recently gained access to sensitive government payment systems.”
So far, the DOGE website does not inspire confidence: We learned last week that the doge.gov administrators somehow left their database wide open, allowing someone to publish messages that ridiculed the site’s insecurity.
A screenshot of the DOGE website after it was defaced with the message: “These ‘experts’ left their database open – roro”
Trump’s efforts to grab federal agencies by their data has seen him replace career civil servants who refused to allow DOGE access to agency networks. CNN reports that Michelle King, acting commissioner of the Social Security Administration for more than 30 years, was shown the door after she denied DOGE access to sensitive information.
King was replaced by Leland Dudek, formerly a senior advisor in the SSA’s Office of Program Integrity. This week, Dudek posted a now-deleted message on LinkedIn acknowledging he had been placed on administrative leave for cooperating with DOGE.
“I confess,” Dudek wrote. “I bullied agency executives, shared executive contact information, and circumvented the chain of command to connect DOGE with the people who get stuff done. I confess. I asked where the fat was and is in our contracts so we can make the right tough choices.”
Dudek’s message on LinkedIn.
According to Wired, the National Institute of Standards and Technology (NIST) was also bracing this week for roughly 500 staffers to be fired, which could have serious impacts on NIST’s cybersecurity standards and software vulnerability tracking work.
“And cuts last week at the US Digital Service included the cybersecurity lead for the central Veterans Affairs portal, VA.gov, potentially leaving VA systems and data more vulnerable without someone in his role,” Wired’s Andy Greenberg and Lily Hay Newman wrote.
NextGov reports that Trump named the Department of Defense’s new chief information security officer: Katie Arrington, a former South Carolina state lawmaker who helped steer Pentagon cybersecurity contracting policy before being put on leave amid accusations that she disclosed classified data from a military intelligence agency.
NextGov notes that the National Security Agency suspended her clearance in 2021, although the exact reasons that led to the suspension and her subsequent leave were classified. Arrington argued that the suspension was a politically motivated effort to silence her.
Trump also appointed the former chief operating officer of the Republican National Committee as the new head of the Office of National Cyber Director. Sean Cairncross, who has no formal experience in technology or security, will be responsible for coordinating national cybersecurity policy, advising the president on cyber threats, and ensuring a unified federal response to emerging cyber-risks, Politico writes.
DarkReading reports that Cairncross would share responsibility for advising the president on cyber matters, along with the director of cyber at the White House National Security Council (NSC) — a group that advises the president on all matters security related, and not just cyber.
The president also ordered staffers at the Consumer Financial Protection Bureau (CFPB) to stop most work. Created by Congress in 2011 to be a clearinghouse of consumer complaints, the CFPB has sued some of the nation’s largest financial institutions for violating consumer protection laws.
The CFPB says its actions have put nearly $18 billion back in Americans’ pockets in the form of monetary compensation or canceled debts, and imposed $4 billion in civil money penalties against violators. The CFPB’s homepage has featured a “404: Page not found” error for weeks now.
Trump has appointed Russell Vought, the architect of the conservative policy playbook Project 2025, to be the CFPB’s acting director. Vought has publicly favored abolishing the agency, as has Elon Musk, whose efforts to remake X into a payments platform would otherwise be regulated by the CFPB.
The New York Times recently published a useful graphic showing all of the government staffing changes, including the firing of several top officials, affecting agencies with federal investigations into or regulatory battles with Musk’s companies. Democrats on the House Judiciary Committee also have released a comprehensive account (PDF) of Musk’s various conflicts of interest.
Image: nytimes.com
As the Times notes, Musk and his companies have repeatedly failed to comply with federal reporting protocols aimed at protecting state secrets, and these failures have prompted at least three federal reviews. Those include an inquiry launched last year by the Defense Department’s Office of Inspector General. Four days after taking office, Trump fired the DoD inspector general along with 17 other inspectors general.
The Trump administration also shifted the enforcement priorities of the U.S. Securities and Exchange Commission (SEC) away from prosecuting misconduct in the cryptocurrency sector, reassigning lawyers and renaming the unit to focus more on “cyber and emerging technologies.”
Reuters reports that the former SEC chair Gary Gensler made fighting misconduct in a sector he termed the “wild west” a priority for the agency, targeting not only cryptocurrency fraudsters but also the large firms that facilitate trading such as Coinbase.
On Friday, Coinbase said the SEC planned to withdraw its lawsuit against the crypto exchange. Also on Friday, the cryptocurrency exchange Bybit announced on X that a cybersecurity breach led to the theft of more than $1.4 billion worth of cryptocurrencies — making it the largest crypto heist ever.
On Feb. 10, Trump ordered executive branch agencies to stop enforcing the U.S. Foreign Corrupt Practices Act, which froze foreign bribery investigations, and even allows for “remedial actions” of past enforcement actions deemed “inappropriate.”
Trump’s action also disbanded the Kleptocracy Asset Recovery Initiative and KleptoCapture Task Force — units which proved their value in corruption cases and in seizing the assets of sanctioned Russian oligarchs — and diverted resources away from investigating white-collar crime.
That’s according to the independent Organized Crime and Corruption Reporting Project (OCCRP), an investigative journalism outlet that until very recently was funded in part by the U.S. Agency for International Development (USAID).
The OCCRP lost nearly a third of its funding and was forced to lay off 43 reporters and staff after Trump moved to shutter USAID and freeze its spending. NBC News reports the Trump administration plans to gut the agency and leave fewer than 300 staffers on the job out of the current 8,000 direct hires and contractors.
The Global Investigative Journalism Network wrote this week that the sudden hold on USAID foreign assistance funding has frozen an estimated $268 million in agreed grants for independent media and the free flow of information in more than 30 countries — including several under repressive regimes.
Elon Musk has called USAID “a criminal organization” without evidence, and promoted fringe theories on his social media platform X that the agency operated without oversight and was rife with fraud. Just months before the election, USAID’s Office of Inspector General announced an investigation into USAID’s oversight of Starlink satellite terminals provided to the government of Ukraine.
KrebsOnSecurity this week heard from a trusted source that all outgoing email from USAID now carries a notation of “sensitive but unclassified,” a designation that experts say could make it more difficult for journalists and others to obtain USAID email records under the Freedom of Information Act (FOIA). On Feb. 20, Fedscoop reported also hearing the same thing from multiple sources, noting that the added message cannot be seen by senders until after the email is sent.
On Feb. 18, Trump issued an executive order declaring that only the U.S. attorney general and the president can provide authoritative interpretations of the law for the executive branch, and that this authority extends to independent agencies operating under the executive branch.
Trump is arguing that Article II, Clause 1 of the Constitution vests this power with the president. However, jurist.org writes that Article II does not expressly state the president or any other person in the executive branch has the power to interpret laws.
“The article states that the president is required to ‘take care that the laws be faithfully executed,'” Juris noted. “Jurisdiction to interpret laws and determine constitutionality belongs to the judicial branch under Article III. The framers of the Constitution designed the separation of duties to prevent any single branch of government from becoming too powerful.”
The executive order requires all agencies to submit to “performance standards and management objectives” to be established by the White House Office of Management and Budget, and to report periodically to the president.
Those performance metrics are already being requested: Employees at multiple federal agencies on Saturday reported receiving an email from the Office of Personnel Management ordering them to reply with a set of bullet points justifying their work for the past week.
“Please reply to this email with approx. 5 bullets of what you accomplished last week and cc your manager,” the notice read. “Please do not send any classified information, links, or attachments. Deadline is this Monday at 11:59 p.m. EST.”
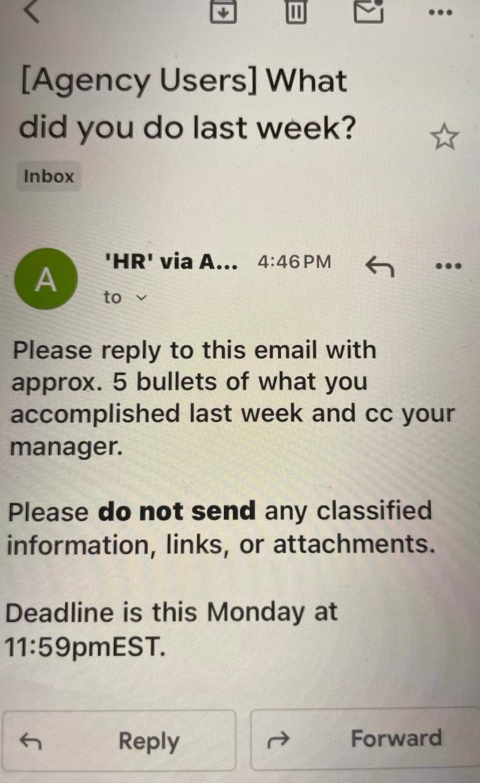
An email sent by the OPM to more than two million federal employees late in the afternoon EST on Saturday, Feb. 22.
In a social media post Saturday, Musk said the directive came at the behest of President Trump, and that failure to respond would be taken as a resignation. Meanwhile, Bloomberg writes the Department of Justice has been urging employees to hold off replying out of concern doing so could trigger ethics violations. The National Treasury Employees Union also is advising its employees not to respond.
A legal battle over Trump’s latest executive order is bound to join more than 70 other lawsuits currently underway to halt the administration’s efforts to massively reduce the size of the federal workforce through layoffs, firings and attrition.
On Feb. 15, the president posted on social media, “He who saves his Country does not violate any Law,” citing a quote often attributed to the French dictator Napoleon Bonaparte. Four days later, Trump referred to himself as “the king” on social media, while the White House nonchalantly posted an illustration of him wearing a crown.
Trump has been publicly musing about running for an unconstitutional third-term in office, a statement that some of his supporters dismiss as Trump just trying to rile his liberal critics. However, just days after Trump began his second term, Rep. Andy Ogles (R-Tenn.) introduced a bill to amend the Constitution so that Trump — and any other future president — can be elected to serve a third term.
This week at the Conservative Political Action Conference (CPAC), Rep. Ogles reportedly led a group of Trump supporters calling itself the “Third Term Project,” which is trying to gain support for the bill from GOP lawmakers. The event featured images of Trump depicted as Caesar.
A banner at the CPAC conference this week in support of The Third Term Project, a group of conservatives trying to gain support for a bill to amend the Constitution and allow Trump to run for a third term.
Russia continues to be among the world’s top exporters of cybercrime, narcotics, money laundering, human trafficking, disinformation, war and death, and yet the Trump administration has suddenly broken with the Western world in normalizing relations with Moscow.
This week President Trump stunned U.S. allies by repeating Kremlin talking points that Ukraine is somehow responsible for Russia’s invasion, and that Ukrainian President Volodymyr Zelensky is a “dictator.” The president repeated these lies even as his administration is demanding that Zelensky give the United States half of his country’s mineral wealth in exchange for a promise that Russia will cease its territorial aggression there.
President Trump’s servility toward an actual dictator — Russian President Vladimir Putin — does not bode well for efforts to improve the cybersecurity of U.S. federal IT networks, or the private sector systems on which the government is largely reliant. In addition, this administration’s baffling moves to alienate, antagonize and sideline our closest allies could make it more difficult for the United States to secure their ongoing cooperation in cybercrime investigations.
It’s also startling how closely DOGE’s approach so far hews to tactics typically employed by ransomware gangs: A group of 20-somethings with names like “Big Balls” shows up on a weekend and gains access to your servers, deletes data, locks out key staff, takes your website down, and prevents you from serving customers.
When the federal executive starts imitating ransomware playbooks against its own agencies while Congress largely gazes on in either bewilderment or amusement, we’re in four-alarm fire territory. At least in theory, one can negotiate with ransomware purveyors.
![]()
Tool for Fingerprinting HTTP requests of malware. Based on Tshark and written in Python3. Working prototype stage :-)
Its main objective is to provide unique representations (fingerprints) of malware requests, which help in their identification. Unique means here that each fingerprint should be seen only in one particular malware family, yet one family can have multiple fingerprints. Hfinger represents the request in a shorter form than printing the whole request, but still human interpretable.
Hfinger can be used in manual malware analysis but also in sandbox systems or SIEMs. The generated fingerprints are useful for grouping requests, pinpointing requests to particular malware families, identifying different operations of one family, or discovering unknown malicious requests omitted by other security systems but which share fingerprint.
An academic paper accompanies work on this tool, describing, for example, the motivation of design choices, and the evaluation of the tool compared to p0f, FATT, and Mercury.
The basic assumption of this project is that HTTP requests of different malware families are more or less unique, so they can be fingerprinted to provide some sort of identification. Hfinger retains information about the structure and values of some headers to provide means for further analysis. For example, grouping of similar requests - at this moment, it is still a work in progress.
After analysis of malware's HTTP requests and headers, we have identified some parts of requests as being most distinctive. These include: * Request method * Protocol version * Header order * Popular headers' values * Payload length, entropy, and presence of non-ASCII characters
Additionally, some standard features of the request URL were also considered. All these parts were translated into a set of features, described in details here.
The above features are translated into varying length representation, which is the actual fingerprint. Depending on report mode, different features are used to fingerprint requests. More information on these modes is presented below. The feature selection process will be described in the forthcoming academic paper.
Minimum requirements needed before installation: * Python >= 3.3, * Tshark >= 2.2.0.
Installation available from PyPI:
pip install hfinger
Hfinger has been tested on Xubuntu 22.04 LTS with tshark package in version 3.6.2, but should work with older versions like 2.6.10 on Xubuntu 18.04 or 3.2.3 on Xubuntu 20.04.
Please note that as with any PoC, you should run Hfinger in a separated environment, at least with Python virtual environment. Its setup is not covered here, but you can try this tutorial.
After installation, you can call the tool directly from a command line with hfinger or as a Python module with python -m hfinger.
For example:
foo@bar:~$ hfinger -f /tmp/test.pcap
[{"epoch_time": "1614098832.205385000", "ip_src": "127.0.0.1", "ip_dst": "127.0.0.1", "port_src": "53664", "port_dst": "8080", "fingerprint": "2|3|1|php|0.6|PO|1|us-ag,ac,ac-en,ho,co,co-ty,co-le|us-ag:f452d7a9/ac:as-as/ac-en:id/co:Ke-Al/co-ty:te-pl|A|4|1.4"}]
Help can be displayed with short -h or long --help switches:
usage: hfinger [-h] (-f FILE | -d DIR) [-o output_path] [-m {0,1,2,3,4}] [-v]
[-l LOGFILE]
Hfinger - fingerprinting malware HTTP requests stored in pcap files
optional arguments:
-h, --help show this help message and exit
-f FILE, --file FILE Read a single pcap file
-d DIR, --directory DIR
Read pcap files from the directory DIR
-o output_path, --output-path output_path
Path to the output directory
-m {0,1,2,3,4}, --mode {0,1,2,3,4}
Fingerprint report mode.
0 - similar number of collisions and fingerprints as mode 2, but using fewer features,
1 - representation of all designed features, but a little more collisions than modes 0, 2, and 4,
2 - optimal (the default mode),
3 - the lowest number of generated fingerprints, but the highest number of collisions,
4 - the highest fingerprint entropy, but slightly more fingerprints than modes 0-2
-v, --verbose Report information about non-standard values in the request
(e.g., non-ASCII characters, no CRLF tags, values not present in the configuration list).
Without --logfile (-l) will print to the standard error.
-l LOGFILE, --logfile LOGFILE
Output logfile in the verbose mode. Implies -v or --verbose switch.
You must provide a path to a pcap file (-f), or a directory (-d) with pcap files. The output is in JSON format. It will be printed to standard output or to the provided directory (-o) using the name of the source file. For example, output of the command:
hfinger -f example.pcap -o /tmp/pcap
will be saved to:
/tmp/pcap/example.pcap.json
Report mode -m/--mode can be used to change the default report mode by providing an integer in the range 0-4. The modes differ on represented request features or rounding modes. The default mode (2) was chosen by us to represent all features that are usually used during requests' analysis, but it also offers low number of collisions and generated fingerprints. With other modes, you can achieve different goals. For example, in mode 3 you get a lower number of generated fingerprints but a higher chance of a collision between malware families. If you are unsure, you don't have to change anything. More information on report modes is here.
Beginning with version 0.2.1 Hfinger is less verbose. You should use -v/--verbose if you want to receive information about encountered non-standard values of headers, non-ASCII characters in the non-payload part of the request, lack of CRLF tags (\r\n\r\n), and other problems with analyzed requests that are not application errors. When any such issues are encountered in the verbose mode, they will be printed to the standard error output. You can also save the log to a defined location using -l/--log switch (it implies -v/--verbose). The log data will be appended to the log file.
Beginning with version 0.2.0, Hfinger supports importing to other Python applications. To use it in your app simply import hfinger_analyze function from hfinger.analysis and call it with a path to the pcap file and reporting mode. The returned result is a list of dicts with fingerprinting results.
For example:
from hfinger.analysis import hfinger_analyze
pcap_path = "SPECIFY_PCAP_PATH_HERE"
reporting_mode = 4
print(hfinger_analyze(pcap_path, reporting_mode))
Beginning with version 0.2.1 Hfinger uses logging module for logging information about encountered non-standard values of headers, non-ASCII characters in the non-payload part of the request, lack of CRLF tags (\r\n\r\n), and other problems with analyzed requests that are not application errors. Hfinger creates its own logger using name hfinger, but without prior configuration log information in practice is discarded. If you want to receive this log information, before calling hfinger_analyze, you should configure hfinger logger, set log level to logging.INFO, configure log handler up to your needs, add it to the logger. More information is available in the hfinger_analyze function docstring.
A fingerprint is based on features extracted from a request. Usage of particular features from the full list depends on the chosen report mode from a predefined list (more information on report modes is here). The figure below represents the creation of an exemplary fingerprint in the default report mode.
![]()
Three parts of the request are analyzed to extract information: URI, headers' structure (including method and protocol version), and payload. Particular features of the fingerprint are separated using | (pipe). The final fingerprint generated for the POST request from the example is:
2|3|1|php|0.6|PO|1|us-ag,ac,ac-en,ho,co,co-ty,co-le|us-ag:f452d7a9/ac:as-as/ac-en:id/co:Ke-Al/co-ty:te-pl|A|4|1.4
The creation of features is described below in the order of appearance in the fingerprint.
Firstly, URI features are extracted: * URI length represented as a logarithm base 10 of the length, rounded to an integer, (in the example URI is 43 characters long, so log10(43)≈2), * number of directories, (in the example there are 3 directories), * average directory length, represented as a logarithm with base 10 of the actual average length of the directory, rounded to an integer, (in the example there are three directories with total length of 20 characters (6+6+8), so log10(20/3)≈1), * extension of the requested file, but only if it is on a list of known extensions in hfinger/configs/extensions.txt, * average value length represented as a logarithm with base 10 of the actual average value length, rounded to one decimal point, (in the example two values have the same length of 4 characters, what is obviously equal to 4 characters, and log10(4)≈0.6).
Secondly, header structure features are analyzed: * request method encoded as first two letters of the method (PO), * protocol version encoded as an integer (1 for version 1.1, 0 for version 1.0, and 9 for version 0.9), * order of the headers, * and popular headers and their values.
To represent order of the headers in the request, each header's name is encoded according to the schema in hfinger/configs/headerslow.json, for example, User-Agent header is encoded as us-ag. Encoded names are separated by ,. If the header name does not start with an upper case letter (or any of its parts when analyzing compound headers such as Accept-Encoding), then encoded representation is prefixed with !. If the header name is not on the list of the known headers, it is hashed using FNV1a hash, and the hash is used as encoding.
When analyzing popular headers, the request is checked if they appear in it. These headers are: * Connection * Accept-Encoding * Content-Encoding * Cache-Control * TE * Accept-Charset * Content-Type * Accept * Accept-Language * User-Agent
When the header is found in the request, its value is checked against a table of typical values to create pairs of header_name_representation:value_representation. The name of the header is encoded according to the schema in hfinger/configs/headerslow.json (as presented before), and the value is encoded according to schema stored in hfinger/configs directory or configs.py file, depending on the header. In the above example Accept is encoded as ac and its value */* as as-as (asterisk-asterisk), giving ac:as-as. The pairs are inserted into fingerprint in order of appearance in the request and are delimited using /. If the header value cannot be found in the encoding table, it is hashed using the FNV1a hash.
If the header value is composed of multiple values, they are tokenized to provide a list of values delimited with ,, for example, Accept: */*, text/* would give ac:as-as,te-as. However, at this point of development, if the header value contains a "quality value" tag (q=), then the whole value is encoded with its FNV1a hash. Finally, values of User-Agent and Accept-Language headers are directly encoded using their FNV1a hashes.
Finally, in the payload features: * presence of non-ASCII characters, represented with the letter N, and with A otherwise, * payload's Shannon entropy, rounded to an integer, * and payload length, represented as a logarithm with base 10 of the actual payload length, rounded to one decimal point.
Hfinger operates in five report modes, which differ in features represented in the fingerprint, thus information extracted from requests. These are (with the number used in the tool configuration): * mode 0 - producing a similar number of collisions and fingerprints as mode 2, but using fewer features, * mode 1 - representing all designed features, but producing a little more collisions than modes 0, 2, and 4, * mode 2 - optimal (the default mode), representing all features which are usually used during requests' analysis, but also offering a low number of collisions and generated fingerprints, * mode 3 - producing the lowest number of generated fingerprints from all modes, but achieving the highest number of collisions, * mode 4 - offering the highest fingerprint entropy, but also generating slightly more fingerprints than modes 0-2.
The modes were chosen in order to optimize Hfinger's capabilities to uniquely identify malware families versus the number of generated fingerprints. Modes 0, 2, and 4 offer a similar number of collisions between malware families, however, mode 4 generates a little more fingerprints than the other two. Mode 2 represents more request features than mode 0 with a comparable number of generated fingerprints and collisions. Mode 1 is the only one representing all designed features, but it increases the number of collisions by almost two times comparing to modes 0, 1, and 4. Mode 3 produces at least two times fewer fingerprints than other modes, but it introduces about nine times more collisions. Description of all designed features is here.
The modes consist of features (in the order of appearance in the fingerprint): * mode 0: * number of directories, * average directory length represented as an integer, * extension of the requested file, * average value length represented as a float, * order of headers, * popular headers and their values, * payload length represented as a float. * mode 1: * URI length represented as an integer, * number of directories, * average directory length represented as an integer, * extension of the requested file, * variable length represented as an integer, * number of variables, * average value length represented as an integer, * request method, * version of protocol, * order of headers, * popular headers and their values, * presence of non-ASCII characters, * payload entropy represented as an integer, * payload length represented as an integer. * mode 2: * URI length represented as an integer, * number of directories, * average directory length represented as an integer, * extension of the requested file, * average value length represented as a float, * request method, * version of protocol, * order of headers, * popular headers and their values, * presence of non-ASCII characters, * payload entropy represented as an integer, * payload length represented as a float. * mode 3: * URI length represented as an integer, * average directory length represented as an integer, * extension of the requested file, * average value length represented as an integer, * order of headers. * mode 4: * URI length represented as a float, * number of directories, * average directory length represented as a float, * extension of the requested file, * variable length represented as a float, * average value length represented as a float, * request method, * version of protocol, * order of headers, * popular headers and their values, * presence of non-ASCII characters, * payload entropy represented as a float, * payload length represented as a float.
If you live in the United States, the data broker Radaris likely knows a great deal about you, and they are happy to sell what they know to anyone. But how much do we know about Radaris? Publicly available data indicates that in addition to running a dizzying array of people-search websites, the co-founders of Radaris operate multiple Russian-language dating services and affiliate programs. It also appears many of their businesses have ties to a California marketing firm that works with a Russian state-run media conglomerate currently sanctioned by the U.S. government.
Formed in 2009, Radaris is a vast people-search network for finding data on individuals, properties, phone numbers, businesses and addresses. Search for any American’s name in Google and the chances are excellent that a listing for them at Radaris.com will show up prominently in the results.
![]()
Radaris reports typically bundle a substantial amount of data scraped from public and court documents, including any current or previous addresses and phone numbers, known email addresses and registered domain names. The reports also list address and phone records for the target’s known relatives and associates. Such information could be useful if you were trying to determine the maiden name of someone’s mother, or successfully answer a range of other knowledge-based authentication questions.
Currently, consumer reports advertised for sale at Radaris.com are being fulfilled by a different people-search company called TruthFinder. But Radaris also operates a number of other people-search properties — like Centeda.com — that sell consumer reports directly and behave almost identically to TruthFinder: That is, reel the visitor in with promises of detailed background reports on people, and then charge a $34.99 monthly subscription fee just to view the results.
The Better Business Bureau (BBB) assigns Radaris a rating of “F” for consistently ignoring consumers seeking to have their information removed from Radaris’ various online properties. Of the 159 complaints detailed there in the last year, several were from people who had used third-party identity protection services to have their information removed from Radaris, only to receive a notice a few months later that their Radaris record had been restored.
What’s more, Radaris’ automated process for requesting the removal of your information requires signing up for an account, potentially providing more information about yourself that the company didn’t already have (see screenshot above).
Radaris has not responded to requests for comment.
Radaris, TruthFinder and others like them all force users to agree that their reports will not be used to evaluate someone’s eligibility for credit, or a new apartment or job. This language is so prominent in people-search reports because selling reports for those purposes would classify these firms as consumer reporting agencies (CRAs) and expose them to regulations under the Fair Credit Reporting Act (FCRA).
These data brokers do not want to be treated as CRAs, and for this reason their people search reports typically do not include detailed credit histories, financial information, or full Social Security Numbers (Radaris reports include the first six digits of one’s SSN).
But in September 2023, the U.S. Federal Trade Commission found that TruthFinder and another people-search service Instant Checkmate were trying to have it both ways. The FTC levied a $5.8 million penalty against the companies for allegedly acting as CRAs because they assembled and compiled information on consumers into background reports that were marketed and sold for employment and tenant screening purposes.
An excerpt from the FTC’s complaint against TruthFinder and Instant Checkmate.
The FTC also found TruthFinder and Instant Checkmate deceived users about background report accuracy. The FTC alleges these companies made millions from their monthly subscriptions using push notifications and marketing emails that claimed that the subject of a background report had a criminal or arrest record, when the record was merely a traffic ticket.
“All the while, the companies touted the accuracy of their reports in online ads and other promotional materials, claiming that their reports contain “the MOST ACCURATE information available to the public,” the FTC noted. The FTC says, however, that all the information used in their background reports is obtained from third parties that expressly disclaim that the information is accurate, and that TruthFinder and Instant Checkmate take no steps to verify the accuracy of the information.
The FTC said both companies deceived customers by providing “Remove” and “Flag as Inaccurate” buttons that did not work as advertised. Rather, the “Remove” button removed the disputed information only from the report as displayed to that customer; however, the same item of information remained visible to other customers who searched for the same person.
The FTC also said that when a customer flagged an item in the background report as inaccurate, the companies never took any steps to investigate those claims, to modify the reports, or to flag to other customers that the information had been disputed.
According to Radaris’ profile at the investor website Pitchbook.com, the company’s founder and “co-chief executive officer” is a Massachusetts resident named Gary Norden, also known as Gary Nard.
An analysis of email addresses known to have been used by Mr. Norden shows he is a native Russian man whose real name is Igor Lybarsky (also spelled Lubarsky). Igor’s brother Dmitry, who goes by “Dan,” appears to be the other co-CEO of Radaris. Dmitry Lybarsky’s Facebook/Meta account says he was born in March 1963.
The Lybarsky brothers Dmitry or “Dan” (left) and Igor a.k.a. “Gary,” in an undated photo.
Indirectly or directly, the Lybarskys own multiple properties in both Sherborn and Wellesley, Mass. However, the Radaris website is operated by an offshore entity called Bitseller Expert Ltd, which is incorporated in Cyprus. Neither Lybarsky brother responded to requests for comment.
A review of the domain names registered by Gary Norden shows that beginning in the early 2000s, he and Dan built an e-commerce empire by marketing prepaid calling cards and VOIP services to Russian expatriates who are living in the United States and seeking an affordable way to stay in touch with loved ones back home.
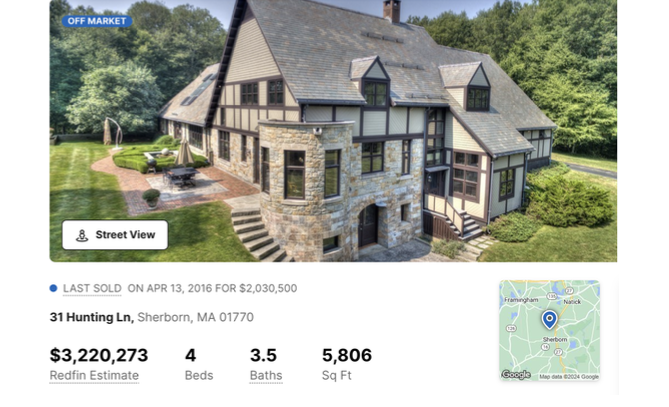
A Sherborn, Mass. property owned by Barsky Real Estate Trust and Dmitry Lybarsky.
In 2012, the main company in charge of providing those calling services — Wellesley Hills, Mass-based Unipoint Technology Inc. — was fined $179,000 by the U.S. Federal Communications Commission, which said Unipoint never applied for a license to provide international telecommunications services.
DomainTools.com shows the email address gnard@unipointtech.com is tied to 137 domains, including radaris.com. DomainTools also shows that the email addresses used by Gary Norden for more than two decades — epop@comby.com, gary@barksy.com and gary1@eprofit.com, among others — appear in WHOIS registration records for an entire fleet of people-search websites, including: centeda.com, virtory.com, clubset.com, kworld.com, newenglandfacts.com, and pub360.com.
Still more people-search platforms tied to Gary Norden– like publicreports.com and arrestfacts.com — currently funnel interested customers to third-party search companies, such as TruthFinder and PersonTrust.com.
The email addresses used by Gary Nard/Gary Norden are also connected to a slew of data broker websites that sell reports on businesses, real estate holdings, and professionals, including bizstanding.com, homemetry.com, trustoria.com, homeflock.com, rehold.com, difive.com and projectlab.com.
Domain records indicate that Gary and Dan for many years operated a now-defunct pay-per-click affiliate advertising network called affiliate.ru. That entity used domain name servers tied to the aforementioned domains comby.com and eprofit.com, as did radaris.ru.
A machine-translated version of Affiliate.ru, a Russian-language site that advertised hundreds of money making affiliate programs, including the Comfi.com prepaid calling card affiliate.
Comby.com used to be a Russian language social media network that looked a great deal like Facebook. The domain now forwards visitors to Privet.ru (“hello” in Russian), a dating site that claims to have 5 million users. Privet.ru says it belongs to a company called Dating Factory, which lists offices in Switzerland. Privet.ru uses the Gary Norden domain eprofit.com for its domain name servers.
Dating Factory’s website says it sells “powerful dating technology” to help customers create unique or niche dating websites. A review of the sample images available on the Dating Factory homepage suggests the term “dating” in this context refers to adult websites. Dating Factory also operates a community called FacebookOfSex, as well as the domain analslappers.com.
Email addresses for the Comby and Eprofit domains indicate Gary Norden operates an entity in Wellesley Hills, Mass. called RussianAmerican Holding Inc. (russianamerica.com). This organization is listed as the owner of the domain newyork.ru, which is a site dedicated to orienting newcomers from Russia to the Big Apple.
Newyork.ru’s terms of service refer to an international calling card company called ComFi Inc. (comfi.com) and list an address as PO Box 81362 Wellesley Hills, Ma. Other sites that include this address are russianamerica.com, russianboston.com, russianchicago.com, russianla.com, russiansanfran.com, russianmiami.com, russiancleveland.com and russianseattle.com (currently offline).
ComFi is tied to Comfibook.com, which was a search aggregator website that collected and published data from many online and offline sources, including phone directories, social networks, online photo albums, and public records.
The current website for russianamerica.com. Note the ad in the bottom left corner of this image for Channel One, a Russian state-owned media firm that is currently sanctioned by the U.S. government.
Many of the U.S. city-specific online properties apparently tied to Gary Norden include phone numbers on their contact pages for a pair of Russian media and advertising firms based in southern California. The phone number 323-874-8211 appears on the websites russianla.com, russiasanfran.com, and rosconcert.com, which sells tickets to theater events performed in Russian.
Historic domain registration records from DomainTools show rosconcert.com was registered in 2003 to Unipoint Technologies — the same company fined by the FCC for not having a license. Rosconcert.com also lists the phone number 818-377-2101.
A phone number just a few digits away — 323-874-8205 — appears as a point of contact on newyork.ru, russianmiami.com, russiancleveland.com, and russianchicago.com. A search in Google shows this 82xx number range — and the 818-377-2101 number — belong to two different entities at the same UPS Store mailbox in Tarzana, Calif: American Russian Media Inc. (armediacorp.com), and Lamedia.biz.
Armediacorp.com is the home of FACT Magazine, a glossy Russian-language publication put out jointly by the American-Russian Business Council, the Hollywood Chamber of Commerce, and the West Hollywood Chamber of Commerce.
Lamedia.biz says it is an international media organization with more than 25 years of experience within the Russian-speaking community on the West Coast. The site advertises FACT Magazine and the Russian state-owned media outlet Channel One. Clicking the Channel One link on the homepage shows Lamedia.biz offers to submit advertising spots that can be shown to Channel One viewers. The price for a basic ad is listed at $500.
In May 2022, the U.S. government levied financial sanctions against Channel One that bar US companies or citizens from doing business with the company.
The website of lamedia.biz offers to sell advertising on two Russian state-owned media firms currently sanctioned by the U.S. government.
In 2014, a group of people sued Radaris in a class-action lawsuit claiming the company’s practices violated the Fair Credit Reporting Act. Court records indicate the defendants never showed up in court to dispute the claims, and as a result the judge eventually awarded the plaintiffs a default judgement and ordered the company to pay $7.5 million.
But the plaintiffs in that civil case had a difficult time collecting on the court’s ruling. In response, the court ordered the radaris.com domain name (~9.4M monthly visitors) to be handed over to the plaintiffs.
However, in 2018 Radaris was able to reclaim their domain on a technicality. Attorneys for the company argued that their clients were never named as defendants in the original lawsuit, and so their domain could not legally be taken away from them in a civil judgment.
“Because our clients were never named as parties to the litigation, and were never served in the litigation, the taking of their property without due process is a violation of their rights,” Radaris’ attorneys argued.
In October 2023, an Illinois resident filed a class-action lawsuit against Radaris for allegedly using people’s names for commercial purposes, in violation of the Illinois Right of Publicity Act.
On Feb. 8, 2024, a company called Atlas Data Privacy Corp. sued Radaris LLC for allegedly violating “Daniel’s Law,” a statute that allows New Jersey law enforcement, government personnel, judges and their families to have their information completely removed from people-search services and commercial data brokers. Atlas has filed at least 140 similar Daniel’s Law complaints against data brokers recently.
Daniel’s Law was enacted in response to the death of 20-year-old Daniel Anderl, who was killed in a violent attack targeting a federal judge (his mother). In July 2020, a disgruntled attorney who had appeared before U.S. District Judge Esther Salas disguised himself as a Fedex driver, went to her home and shot and killed her son (the judge was unharmed and the assailant killed himself).
Earlier this month, The Record reported on Atlas Data Privacy’s lawsuit against LexisNexis Risk Data Management, in which the plaintiffs representing thousands of law enforcement personnel in New Jersey alleged that after they asked for their information to remain private, the data broker retaliated against them by freezing their credit and falsely reporting them as identity theft victims.
Another data broker sued by Atlas Data Privacy — pogodata.com — announced on Mar. 1 that it was likely shutting down because of the lawsuit.
“The matter is far from resolved but your response motivates us to try to bring back most of the names while preserving redaction of the 17,000 or so clients of the redaction company,” the company wrote. “While little consolation, we are not alone in the suit – the privacy company sued 140 property-data sites at the same time as PogoData.”
Atlas says their goal is convince more states to pass similar laws, and to extend those protections to other groups such as teachers, healthcare personnel and social workers. Meanwhile, media law experts say they’re concerned that enacting Daniel’s Law in other states would limit the ability of journalists to hold public officials accountable, and allow authorities to pursue criminals charges against media outlets that publish the same type of public and governments records that fuel the people-search industry.
There are some pending changes to the US legal and regulatory landscape that could soon reshape large swaths of the data broker industry. But experts say it is unlikely that any of these changes will affect people-search companies like Radaris.
On Feb. 28, 2024, the White House issued an executive order that directs the U.S. Department of Justice (DOJ) to create regulations that would prevent data brokers from selling or transferring abroad certain data types deemed too sensitive, including genomic and biometric data, geolocation and financial data, as well as other as-yet unspecified personal identifiers. The DOJ this week published a list of more than 100 questions it is seeking answers to regarding the data broker industry.
In August 2023, the Consumer Financial Protection Bureau (CFPB) announced it was undertaking new rulemaking related to data brokers.
Justin Sherman, an adjunct professor at Duke University, said neither the CFPB nor White House rulemaking will likely address people-search brokers because these companies typically get their information by scouring federal, state and local government records. Those government files include voting registries, property filings, marriage certificates, motor vehicle records, criminal records, court documents, death records, professional licenses, bankruptcy filings, and more.
“These dossiers contain everything from individuals’ names, addresses, and family information to data about finances, criminal justice system history, and home and vehicle purchases,” Sherman wrote in an October 2023 article for Lawfare. “People search websites’ business pitch boils down to the fact that they have done the work of compiling data, digitizing it, and linking it to specific people so that it can be searched online.”
Sherman said while there are ongoing debates about whether people search data brokers have legal responsibilities to the people about whom they gather and sell data, the sources of this information — public records — are completely carved out from every single state consumer privacy law.
“Consumer privacy laws in California, Colorado, Connecticut, Delaware, Indiana, Iowa, Montana, Oregon, Tennessee, Texas, Utah, and Virginia all contain highly similar or completely identical carve-outs for ‘publicly available information’ or government records,” Sherman wrote. “Tennessee’s consumer data privacy law, for example, stipulates that “personal information,” a cornerstone of the legislation, does not include ‘publicly available information,’ defined as:
“…information that is lawfully made available through federal, state, or local government records, or information that a business has a reasonable basis to believe is lawfully made available to the general public through widely distributed media, by the consumer, or by a person to whom the consumer has disclosed the information, unless the consumer has restricted the information to a specific audience.”
Sherman said this is the same language as the carve-out in the California privacy regime, which is often held up as the national leader in state privacy regulations. He said with a limited set of exceptions for survivors of stalking and domestic violence, even under California’s newly passed Delete Act — which creates a centralized mechanism for consumers to ask some third-party data brokers to delete their information — consumers across the board cannot exercise these rights when it comes to data scraped from property filings, marriage certificates, and public court documents, for example.
“With some very narrow exceptions, it’s either extremely difficult or impossible to compel these companies to remove your information from their sites,” Sherman told KrebsOnSecurity. “Even in states like California, every single consumer privacy law in the country completely exempts publicly available information.”
Below is a mind map that helped KrebsOnSecurity track relationships between and among the various organizations named in the story above:
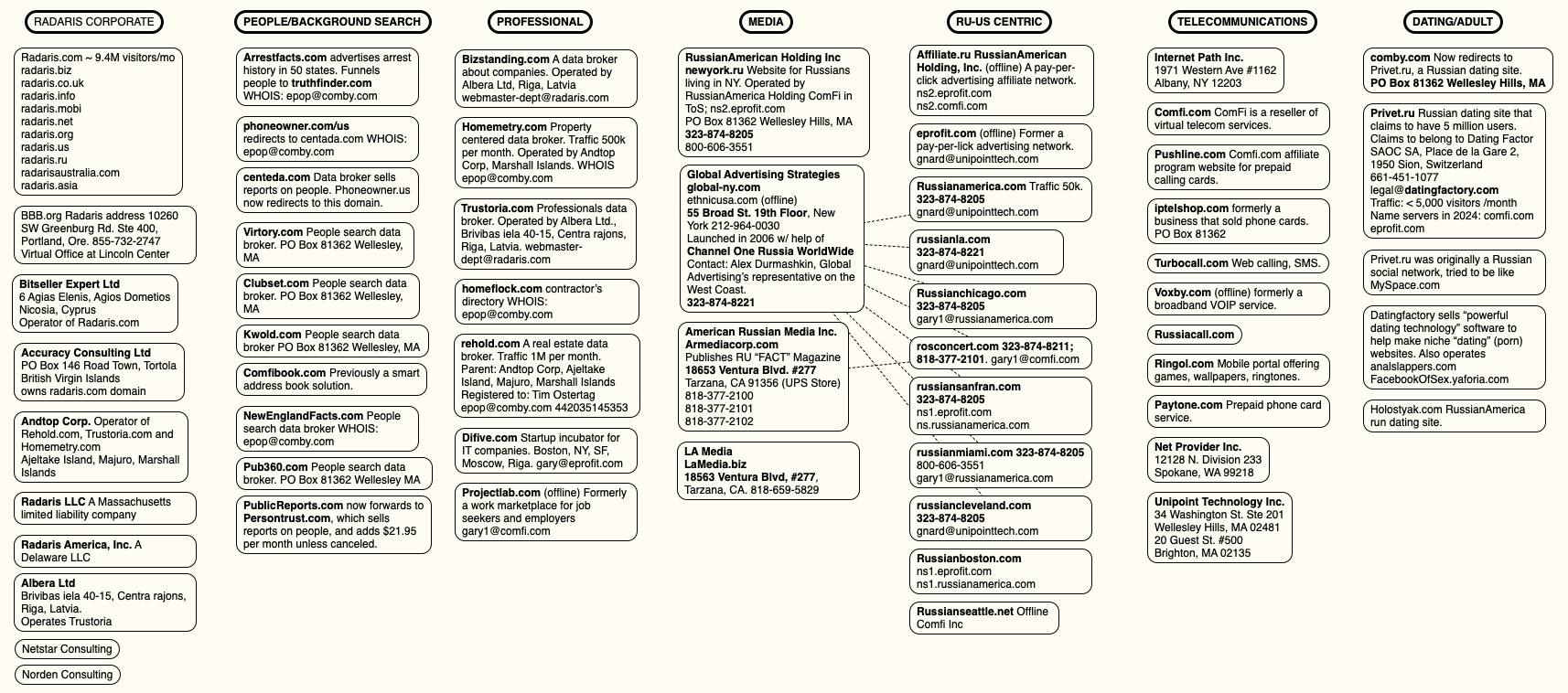
A mind map of various entities apparently tied to Radaris and the company’s co-founders. Click to enlarge.
![]()
How PurpleOps is different:
# Clone this repository
$ git clone https://github.com/CyberCX-STA/PurpleOps
# Go into the repository
$ cd PurpleOps
# Alter PurpleOps settings (if you want to customize anything but should work out the box)
$ nano .env
# Run the app with docker
$ sudo docker compose up
# PurpleOps should now by available on http://localhost:5000, it is recommended to add a reverse proxy such as nginx or Apache in front of it if you want to expose this to the outside world.
# Alternatively
$ sudo docker run --name mongodb -d -p 27017:27017 mongo
$ pip3 install -r requirements.txt
$ python3 seeder.py
$ python3 purpleops.pyWe would love to hear back from you, if something is broken or have and idea to make it better add a ticket or ping us pops@purpleops.app | @_w_m__