![]()
Thank you for following me! https://cybdetective.com
| Name | Link | Description | Price |
|---|---|---|---|
| Shodan | https://developer.shodan.io | Search engine for Internet connected host and devices | from $59/month |
| Netlas.io | https://netlas-api.readthedocs.io/en/latest/ | Search engine for Internet connected host and devices. Read more at Netlas CookBook | Partly FREE |
| Fofa.so | https://fofa.so/static_pages/api_help | Search engine for Internet connected host and devices | ??? |
| Censys.io | https://censys.io/api | Search engine for Internet connected host and devices | Partly FREE |
| Hunter.how | https://hunter.how/search-api | Search engine for Internet connected host and devices | Partly FREE |
| Fullhunt.io | https://api-docs.fullhunt.io/#introduction | Search engine for Internet connected host and devices | Partly FREE |
| IPQuery.io | https://ipquery.io | API for ip information such as ip risk, geolocation data, and asn details | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Social Links | https://sociallinks.io/products/sl-api | Email info lookup, phone info lookup, individual and company profiling, social media tracking, dark web monitoring and more. Code example of using this API for face search in this repo | PAID. Price per request |
| Name | Link | Description | Price |
|---|---|---|---|
| Numverify | https://numverify.com | Global Phone Number Validation & Lookup JSON API. Supports 232 countries. | 250 requests FREE |
| Twillo | https://www.twilio.com/docs/lookup/api | Provides a way to retrieve additional information about a phone number | Free or $0.01 per request (for caller lookup) |
| Plivo | https://www.plivo.com/lookup/ | Determine carrier, number type, format, and country for any phone number worldwide | from $0.04 per request |
| GetContact | https://github.com/kovinevmv/getcontact | Find info about user by phone number | from $6,89 in months/100 requests |
| Veriphone | https://veriphone.io/ | Phone number validation & carrier lookup | 1000 requests/month FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Global Address | https://rapidapi.com/adminMelissa/api/global-address/ | Easily verify, check or lookup address | FREE |
| US Street Address | https://smartystreets.com/docs/cloud/us-street-api | Validate and append data for any US postal address | FREE |
| Google Maps Geocoding API | https://developers.google.com/maps/documentation/geocoding/overview | convert addresses (like "1600 Amphitheatre Parkway, Mountain View, CA") into geographic coordinates | 0.005 USD per request |
| Postcoder | https://postcoder.com/address-lookup | Find adress by postcode | £130/5000 requests |
| Zipcodebase | https://zipcodebase.com | Lookup postal codes, calculate distances and much more | 5000 requests FREE |
| Openweathermap geocoding API | https://openweathermap.org/api/geocoding-api | get geographical coordinates (lat, lon) by using name of the location (city name or area name) | 60 calls/minute 1,000,000 calls/month |
| DistanceMatrix | https://distancematrix.ai/product | Calculate, evaluate and plan your routes | $1.25-$2 per 1000 elements |
| Geotagging API | https://geotagging.ai/ | Predict geolocations by texts | Freemium |
| Name | Link | Description | Price |
|---|---|---|---|
| Approuve.com | https://appruve.co | Allows you to verify the identities of individuals, businesses, and connect to financial account data across Africa | Paid |
| Onfido.com | https://onfido.com | Onfido Document Verification lets your users scan a photo ID from any device, before checking it's genuine. Combined with Biometric Verification, it's a seamless way to anchor an account to the real identity of a customer. India | Paid |
| Superpass.io | https://surepass.io/passport-id-verification-api/ | Passport, Photo ID and Driver License Verification in India | Paid |
| Name | Link | Description | Price |
|---|---|---|---|
| Open corporates | https://api.opencorporates.com | Companies information | Paid, price upon request |
| Linkedin company search API | https://docs.microsoft.com/en-us/linkedin/marketing/integrations/community-management/organizations/company-search?context=linkedin%2Fcompliance%2Fcontext&tabs=http | Find companies using keywords, industry, location, and other criteria | FREE |
| Mattermark | https://rapidapi.com/raygorodskij/api/Mattermark/ | Get companies and investor information | free 14-day trial, from $49 per month |
| Name | Link | Description | Price |
|---|---|---|---|
| API OSINT DS | https://github.com/davidonzo/apiosintDS | Collect info about IPv4/FQDN/URLs and file hashes in md5, sha1 or sha256 | FREE |
| InfoDB API | https://www.ipinfodb.com/api | The API returns the location of an IP address (country, region, city, zipcode, latitude, longitude) and the associated timezone in XML, JSON or plain text format | FREE |
| Domainsdb.info | https://domainsdb.info | Registered Domain Names Search | FREE |
| BGPView | https://bgpview.docs.apiary.io/# | allowing consumers to view all sort of analytics data about the current state and structure of the internet | FREE |
| DNSCheck | https://www.dnscheck.co/api | monitor the status of both individual DNS records and groups of related DNS records | up to 10 DNS records/FREE |
| Cloudflare Trace | https://github.com/fawazahmed0/cloudflare-trace-api | Get IP Address, Timestamp, User Agent, Country Code, IATA, HTTP Version, TLS/SSL Version & More | FREE |
| Host.io | https://host.io/ | Get info about domain | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| BeVigil OSINT API | https://bevigil.com/osint-api | provides access to millions of asset footprint data points including domain intel, cloud services, API information, and third party assets extracted from millions of mobile apps being continuously uploaded and scanned by users on bevigil.com | 50 credits free/1000 credits/$50 |
| Name | Link | Description | Price |
|---|---|---|---|
| WebScraping.AI | https://webscraping.ai/ | Web Scraping API with built-in proxies and JS rendering | FREE |
| ZenRows | https://www.zenrows.com/ | Web Scraping API that bypasses anti-bot solutions while offering JS rendering, and rotating proxies apiKey Yes Unknown | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Whois freaks | https://whoisfreaks.com/ | well-parsed and structured domain WHOIS data for all domain names, registrars, countries and TLDs since the birth of internet | $19/5000 requests |
| WhoisXMLApi | https://whois.whoisxmlapi.com | gathers a variety of domain ownership and registration data points from a comprehensive WHOIS database | 500 requests in month/FREE |
| IPtoWhois | https://www.ip2whois.com/developers-api | Get detailed info about a domain | 500 requests/month FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Ipstack | https://ipstack.com | Detect country, region, city and zip code | FREE |
| Ipgeolocation.io | https://ipgeolocation.io | provides country, city, state, province, local currency, latitude and longitude, company detail, ISP lookup, language, zip code, country calling code, time zone, current time, sunset and sunrise time, moonset and moonrise | 30 000 requests per month/FREE |
| IPInfoDB | https://ipinfodb.com/api | Free Geolocation tools and APIs for country, region, city and time zone lookup by IP address | FREE |
| IP API | https://ip-api.com/ | Free domain/IP geolocation info | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Mylnikov API | https://www.mylnikov.org | public API implementation of Wi-Fi Geo-Location database | FREE |
| Wigle | https://api.wigle.net/ | get location and other information by SSID | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| PeetingDB | https://www.peeringdb.com/apidocs/ | Database of networks, and the go-to location for interconnection data | FREE |
| PacketTotal | https://packettotal.com/api.html | .pcap files analyze | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Binlist.net | https://binlist.net/ | get information about bank by BIN | FREE |
| FDIC Bank Data API | https://banks.data.fdic.gov/docs/ | institutions, locations and history events | FREE |
| Amdoren | https://www.amdoren.com/currency-api/ | Free currency API with over 150 currencies | FREE |
| VATComply.com | https://www.vatcomply.com/documentation | Exchange rates, geolocation and VAT number validation | FREE |
| Alpaca | https://alpaca.markets/docs/api-documentation/api-v2/market-data/alpaca-data-api-v2/ | Realtime and historical market data on all US equities and ETFs | FREE |
| Swiftcodesapi | https://swiftcodesapi.com | Verifying the validity of a bank SWIFT code or IBAN account number | $39 per month/4000 swift lookups |
| IBANAPI | https://ibanapi.com | Validate IBAN number and get bank account information from it | Freemium/10$ Starter plan |
| Name | Link | Description | Price |
|---|---|---|---|
| EVA | https://eva.pingutil.com/ | Measuring email deliverability & quality | FREE |
| Mailboxlayer | https://mailboxlayer.com/ | Simple REST API measuring email deliverability & quality | 100 requests FREE, 5000 requests in month — $14.49 |
| EmailCrawlr | https://emailcrawlr.com/ | Get key information about company websites. Find all email addresses associated with a domain. Get social accounts associated with an email. Verify email address deliverability. | 200 requests FREE, 5000 requets — $40 |
| Voila Norbert | https://www.voilanorbert.com/api/ | Find anyone's email address and ensure your emails reach real people | from $49 in month |
| Kickbox | https://open.kickbox.com/ | Email verification API | FREE |
| FachaAPI | https://api.facha.dev/ | Allows checking if an email domain is a temporary email domain | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Genderize.io | https://genderize.io | Instantly answers the question of how likely a certain name is to be male or female and shows the popularity of the name. | 1000 names/day free |
| Agify.io | https://agify.io | Predicts the age of a person given their name | 1000 names/day free |
| Nataonalize.io | https://nationalize.io | Predicts the nationality of a person given their name | 1000 names/day free |
| Name | Link | Description | Price |
|---|---|---|---|
| HaveIBeenPwned | https://haveibeenpwned.com/API/v3 | allows the list of pwned accounts (email addresses and usernames) | $3.50 per month |
| Psdmp.ws | https://psbdmp.ws/api | search in Pastebin | $9.95 per 10000 requests |
| LeakPeek | https://psbdmp.ws/api | searc in leaks databases | $9.99 per 4 weeks unlimited access |
| BreachDirectory.com | https://breachdirectory.com/api_documentation | search domain in data breaches databases | FREE |
| LeekLookup | https://leak-lookup.com/api | search domain, email_address, fullname, ip address, phone, password, username in leaks databases | 10 requests FREE |
| BreachDirectory.org | https://rapidapi.com/rohan-patra/api/breachdirectory/pricing | search domain, email_address, fullname, ip address, phone, password, username in leaks databases (possible to view password hashes) | 50 requests in month/FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Wayback Machine API (Memento API, CDX Server API, Wayback Availability JSON API) | https://archive.org/help/wayback_api.php | Retrieve information about Wayback capture data | FREE |
| TROVE (Australian Web Archive) API | https://trove.nla.gov.au/about/create-something/using-api | Retrieve information about TROVE capture data | FREE |
| Archive-it API | https://support.archive-it.org/hc/en-us/articles/115001790023-Access-Archive-It-s-Wayback-index-with-the-CDX-C-API | Retrieve information about archive-it capture data | FREE |
| UK Web Archive API | https://ukwa-manage.readthedocs.io/en/latest/#api-reference | Retrieve information about UK Web Archive capture data | FREE |
| Arquivo.pt API | https://github.com/arquivo/pwa-technologies/wiki/Arquivo.pt-API | Allows full-text search and access preserved web content and related metadata. It is also possible to search by URL, accessing all versions of preserved web content. API returns a JSON object. | FREE |
| Library Of Congress archive API | https://www.loc.gov/apis/ | Provides structured data about Library of Congress collections | FREE |
| BotsArchive | https://botsarchive.com/docs.html | JSON formatted details about Telegram Bots available in database | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| MD5 Decrypt | https://md5decrypt.net/en/Api/ | Search for decrypted hashes in the database | 1.99 EURO/day |
| Name | Link | Description | Price |
|---|---|---|---|
| BTC.com | https://btc.com/btc/adapter?type=api-doc | get information about addresses and transanctions | FREE |
| Blockchair | https://blockchair.com | Explore data stored on 17 blockchains (BTC, ETH, Cardano, Ripple etc) | $0.33 - $1 per 1000 calls |
| Bitcointabyse | https://www.bitcoinabuse.com/api-docs | Lookup bitcoin addresses that have been linked to criminal activity | FREE |
| Bitcoinwhoswho | https://www.bitcoinwhoswho.com/api | Scam reports on the Bitcoin Address | FREE |
| Etherscan | https://etherscan.io/apis | Ethereum explorer API | FREE |
| apilayer coinlayer | https://coinlayer.com | Real-time Crypto Currency Exchange Rates | FREE |
| BlockFacts | https://blockfacts.io/ | Real-time crypto data from multiple exchanges via a single unified API, and much more | FREE |
| Brave NewCoin | https://bravenewcoin.com/developers | Real-time and historic crypto data from more than 200+ exchanges | FREE |
| WorldCoinIndex | https://www.worldcoinindex.com/apiservice | Cryptocurrencies Prices | FREE |
| WalletLabels | https://www.walletlabels.xyz/docs | Labels for 7,5 million Ethereum wallets | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| VirusTotal | https://developers.virustotal.com/reference | files and urls analyze | Public API is FREE |
| AbuseLPDB | https://docs.abuseipdb.com/#introduction | IP/domain/URL reputation | FREE |
| AlienVault Open Threat Exchange (OTX) | https://otx.alienvault.com/api | IP/domain/URL reputation | FREE |
| Phisherman | https://phisherman.gg | IP/domain/URL reputation | FREE |
| URLScan.io | https://urlscan.io/about-api/ | Scan and Analyse URLs | FREE |
| Web of Thrust | https://support.mywot.com/hc/en-us/sections/360004477734-API- | IP/domain/URL reputation | FREE |
| Threat Jammer | https://threatjammer.com/docs/introduction-threat-jammer-user-api | IP/domain/URL reputation | ??? |
| Name | Link | Description | Price |
|---|---|---|---|
| Search4faces | https://search4faces.com/api.html | Detect and locate human faces within an image, and returns high-precision face bounding boxes. Face⁺⁺ also allows you to store metadata of each detected face for future use. | $21 per 1000 requests |
## Face Detection
| Name | Link | Description | Price |
|---|---|---|---|
| Face++ | https://www.faceplusplus.com/face-detection/ | Search for people in social networks by facial image | from 0.03 per call |
| BetaFace | https://www.betafaceapi.com/wpa/ | Can scan uploaded image files or image URLs, find faces and analyze them. API also provides verification (faces comparison) and identification (faces search) services, as well able to maintain multiple user-defined recognition databases (namespaces) | 50 image per day FREE/from 0.15 EUR per request |
## Reverse Image Search
| Name | Link | Description | Price |
|---|---|---|---|
| Google Reverse images search API | https://github.com/SOME-1HING/google-reverse-image-api/ | This is a simple API built using Node.js and Express.js that allows you to perform Google Reverse Image Search by providing an image URL. | FREE (UNOFFICIAL) |
| TinEyeAPI | https://services.tineye.com/TinEyeAPI | Verify images, Moderate user-generated content, Track images and brands, Check copyright compliance, Deploy fraud detection solutions, Identify stock photos, Confirm the uniqueness of an image | Start from $200/5000 searches |
| Bing Images Search API | https://www.microsoft.com/en-us/bing/apis/bing-image-search-api | With Bing Image Search API v7, help users scour the web for images. Results include thumbnails, full image URLs, publishing website info, image metadata, and more. | 1,000 requests free per month FREE |
| MRISA | https://github.com/vivithemage/mrisa | MRISA (Meta Reverse Image Search API) is a RESTful API which takes an image URL, does a reverse Google image search, and returns a JSON array with the search results | FREE? (no official) |
| PicImageSearch | https://github.com/kitUIN/PicImageSearch | Aggregator for different Reverse Image Search API | FREE? (no official) |
## AI Geolocation
| Name | Link | Description | Price |
|---|---|---|---|
| Geospy | https://api.geospy.ai/ | Detecting estimation location of uploaded photo | Access by request |
| Picarta | https://picarta.ai/api | Detecting estimation location of uploaded photo | 100 request/day FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Twitch | https://dev.twitch.tv/docs/v5/reference | ||
| YouTube Data API | https://developers.google.com/youtube/v3 | ||
| https://www.reddit.com/dev/api/ | |||
| Vkontakte | https://vk.com/dev/methods | ||
| Twitter API | https://developer.twitter.com/en | ||
| Linkedin API | https://docs.microsoft.com/en-us/linkedin/ | ||
| All Facebook and Instagram API | https://developers.facebook.com/docs/ | ||
| Whatsapp Business API | https://www.whatsapp.com/business/api | ||
| Telegram and Telegram Bot API | https://core.telegram.org | ||
| Weibo API | https://open.weibo.com/wiki/API文档/en | ||
| https://dev.xing.com/partners/job_integration/api_docs | |||
| Viber | https://developers.viber.com/docs/api/rest-bot-api/ | ||
| Discord | https://discord.com/developers/docs | ||
| Odnoklassniki | https://ok.ru/apiok | ||
| Blogger | https://developers.google.com/blogger/ | The Blogger APIs allows client applications to view and update Blogger content | FREE |
| Disqus | https://disqus.com/api/docs/auth/ | Communicate with Disqus data | FREE |
| Foursquare | https://developer.foursquare.com/ | Interact with Foursquare users and places (geolocation-based checkins, photos, tips, events, etc) | FREE |
| HackerNews | https://github.com/HackerNews/API | Social news for CS and entrepreneurship | FREE |
| Kakao | https://developers.kakao.com/ | Kakao Login, Share on KakaoTalk, Social Plugins and more | FREE |
| Line | https://developers.line.biz/ | Line Login, Share on Line, Social Plugins and more | FREE |
| TikTok | https://developers.tiktok.com/doc/login-kit-web | Fetches user info and user's video posts on TikTok platform | FREE |
| Tumblr | https://www.tumblr.com/docs/en/api/v2 | Read and write Tumblr Data | FREE |
!WARNING Use with caution! Accounts may be blocked permanently for using unofficial APIs.
| Name | Link | Description | Price |
|---|---|---|---|
| TikTok | https://github.com/davidteather/TikTok-Api | The Unofficial TikTok API Wrapper In Python | FREE |
| Google Trends | https://github.com/suryasev/unofficial-google-trends-api | Unofficial Google Trends API | FREE |
| YouTube Music | https://github.com/sigma67/ytmusicapi | Unofficial APi for YouTube Music | FREE |
| Duolingo | https://github.com/KartikTalwar/Duolingo | Duolingo unofficial API (can gather info about users) | FREE |
| Steam. | https://github.com/smiley/steamapi | An unofficial object-oriented Python library for accessing the Steam Web API. | FREE |
| https://github.com/ping/instagram_private_api | Instagram Private API | FREE | |
| Discord | https://github.com/discordjs/discord.js | JavaScript library for interacting with the Discord API | FREE |
| Zhihu | https://github.com/syaning/zhihu-api | FREE Unofficial API for Zhihu | FREE |
| Quora | https://github.com/csu/quora-api | Unofficial API for Quora | FREE |
| DnsDumbster | https://github.com/PaulSec/API-dnsdumpster.com | (Unofficial) Python API for DnsDumbster | FREE |
| PornHub | https://github.com/sskender/pornhub-api | Unofficial API for PornHub in Python | FREE |
| Skype | https://github.com/ShyykoSerhiy/skyweb | Unofficial Skype API for nodejs via 'Skype (HTTP)' protocol. | FREE |
| Google Search | https://github.com/aviaryan/python-gsearch | Google Search unofficial API for Python with no external dependencies | FREE |
| Airbnb | https://github.com/nderkach/airbnb-python | Python wrapper around the Airbnb API (unofficial) | FREE |
| Medium | https://github.com/enginebai/PyMedium | Unofficial Medium Python Flask API and SDK | FREE |
| https://github.com/davidyen1124/Facebot | Powerful unofficial Facebook API | FREE | |
| https://github.com/tomquirk/linkedin-api | Unofficial Linkedin API for Python | FREE | |
| Y2mate | https://github.com/Simatwa/y2mate-api | Unofficial Y2mate API for Python | FREE |
| Livescore | https://github.com/Simatwa/livescore-api | Unofficial Livescore API for Python | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Google Custom Search JSON API | https://developers.google.com/custom-search/v1/overview | Search in Google | 100 requests FREE |
| Serpstack | https://serpstack.com/ | Google search results to JSON | FREE |
| Serpapi | https://serpapi.com | Google, Baidu, Yandex, Yahoo, DuckDuckGo, Bint and many others search results | $50/5000 searches/month |
| Bing Web Search API | https://www.microsoft.com/en-us/bing/apis/bing-web-search-api | Search in Bing (+instant answers and location) | 1000 transactions per month FREE |
| WolframAlpha API | https://products.wolframalpha.com/api/pricing/ | Short answers, conversations, calculators and many more | from $25 per 1000 queries |
| DuckDuckgo Instant Answers API | https://duckduckgo.com/api | An API for some of our Instant Answers, not for full search results. | FREE |
| Memex Marginalia | https://memex.marginalia.nu/projects/edge/api.gmi | An API for new privacy search engine | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| MediaStack | https://mediastack.com/ | News articles search results in JSON | 500 requests/month FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Darksearch.io | https://darksearch.io/apidoc | search by websites in .onion zone | FREE |
| Onion Lookup | https://onion.ail-project.org/ | onion-lookup is a service for checking the existence of Tor hidden services and retrieving their associated metadata. onion-lookup relies on an private AIL instance to obtain the metadata | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Jackett | https://github.com/Jackett/Jackett | API for automate searching in different torrent trackers | FREE |
| Torrents API PY | https://github.com/Jackett/Jackett | Unofficial API for 1337x, Piratebay, Nyaasi, Torlock, Torrent Galaxy, Zooqle, Kickass, Bitsearch, MagnetDL,Libgen, YTS, Limetorrent, TorrentFunk, Glodls, Torre | FREE |
| Torrent Search API | https://github.com/Jackett/Jackett | API for Torrent Search Engine with Extratorrents, Piratebay, and ISOhunt | 500 queries/day FREE |
| Torrent search api | https://github.com/JimmyLaurent/torrent-search-api | Yet another node torrent scraper (supports iptorrents, torrentleech, torrent9, torrentz2, 1337x, thepiratebay, Yggtorrent, TorrentProject, Eztv, Yts, LimeTorrents) | FREE |
| Torrentinim | https://github.com/sergiotapia/torrentinim | Very low memory-footprint, self hosted API-only torrent search engine. Sonarr + Radarr Compatible, native support for Linux, Mac and Windows. | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| National Vulnerability Database CVE Search API | https://nvd.nist.gov/developers/vulnerabilities | Get basic information about CVE and CVE history | FREE |
| OpenCVE API | https://docs.opencve.io/api/cve/ | Get basic information about CVE | FREE |
| CVEDetails API | https://www.cvedetails.com/documentation/apis | Get basic information about CVE | partly FREE (?) |
| CVESearch API | https://docs.cvesearch.com/ | Get basic information about CVE | by request |
| KEVin API | https://kevin.gtfkd.com/ | API for accessing CISA's Known Exploited Vulnerabilities Catalog (KEV) and CVE Data | FREE |
| Vulners.com API | https://vulners.com | Get basic information about CVE | FREE for personal use |
| Name | Link | Description | Price |
|---|---|---|---|
| Aviation Stack | https://aviationstack.com | get information about flights, aircrafts and airlines | FREE |
| OpenSky Network | https://opensky-network.org/apidoc/index.html | Free real-time ADS-B aviation data | FREE |
| AviationAPI | https://docs.aviationapi.com/ | FAA Aeronautical Charts and Publications, Airport Information, and Airport Weather | FREE |
| FachaAPI | https://api.facha.dev | Aircraft details and live positioning API | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Windy Webcams API | https://api.windy.com/webcams/docs | Get a list of available webcams for a country, city or geographical coordinates | FREE with limits or 9990 euro without limits |
## Regex
| Name | Link | Description | Price |
|---|---|---|---|
| Autoregex | https://autoregex.notion.site/AutoRegex-API-Documentation-97256bad2c114a6db0c5822860214d3a | Convert English phrase to regular expression | from $3.49/month |
| Name | Link |
|---|---|
| API Guessr (detect API by auth key or by token) | https://api-guesser.netlify.app/ |
| REQBIN Online REST & SOAP API Testing Tool | https://reqbin.com |
| ExtendClass Online REST Client | https://extendsclass.com/rest-client-online.html |
| Codebeatify.org Online API Test | https://codebeautify.org/api-test |
| SyncWith Google Sheet add-on. Link more than 1000 APIs with Spreadsheet | https://workspace.google.com/u/0/marketplace/app/syncwith_crypto_binance_coingecko_airbox/449644239211?hl=ru&pann=sheets_addon_widget |
| Talend API Tester Google Chrome Extension | https://workspace.google.com/u/0/marketplace/app/syncwith_crypto_binance_coingecko_airbox/449644239211?hl=ru&pann=sheets_addon_widget |
| Michael Bazzel APIs search tools | https://inteltechniques.com/tools/API.html |
| Name | Link |
|---|---|
| Convert curl commands to Python, JavaScript, PHP, R, Go, C#, Ruby, Rust, Elixir, Java, MATLAB, Dart, CFML, Ansible URI or JSON | https://curlconverter.com |
| Curl-to-PHP. Instantly convert curl commands to PHP code | https://incarnate.github.io/curl-to-php/ |
| Curl to PHP online (Codebeatify) | https://codebeautify.org/curl-to-php-online |
| Curl to JavaScript fetch | https://kigiri.github.io/fetch/ |
| Curl to JavaScript fetch (Scrapingbee) | https://www.scrapingbee.com/curl-converter/javascript-fetch/ |
| Curl to C# converter | https://curl.olsh.me |
| Name | Link |
|---|---|
| Sheety. Create API frome GOOGLE SHEET | https://sheety.co/ |
| Postman. Platform for creating your own API | https://www.postman.com |
| Reetoo. Rest API Generator | https://retool.com/api-generator/ |
| Beeceptor. Rest API mocking and intercepting in seconds (no coding). | https://beeceptor.com |
| Name | Link |
|---|---|
| RapidAPI. Market your API for millions of developers | https://rapidapi.com/solution/api-provider/ |
| Apilayer. API Marketplace | https://apilayer.com |
| Name | Link | Description |
|---|---|---|
| Keyhacks | https://github.com/streaak/keyhacks | Keyhacks is a repository which shows quick ways in which API keys leaked by a bug bounty program can be checked to see if they're valid. |
| All about APIKey | https://github.com/daffainfo/all-about-apikey | Detailed information about API key / OAuth token for different services (Description, Request, Response, Regex, Example) |
| API Guessr | https://api-guesser.netlify.app/ | Enter API Key and and find out which service they belong to |
| Name | Link | Description |
|---|---|---|
| APIDOG ApiHub | https://apidog.com/apihub/ | |
| Rapid APIs collection | https://rapidapi.com/collections | |
| API Ninjas | https://api-ninjas.com/api | |
| APIs Guru | https://apis.guru/ | |
| APIs List | https://apislist.com/ | |
| API Context Directory | https://apicontext.com/api-directory/ | |
| Any API | https://any-api.com/ | |
| Public APIs Github repo | https://github.com/public-apis/public-apis |
If you don't know how to work with the REST API, I recommend you check out the Netlas API guide I wrote for Netlas.io.
There it is very brief and accessible to write how to automate requests in different programming languages (focus on Python and Bash) and process the resulting JSON data.
Thank you for following me! https://cybdetective.com

Dealing with failing web scrapers due to anti-bot protections or website changes? Meet Scrapling.
Scrapling is a high-performance, intelligent web scraping library for Python that automatically adapts to website changes while significantly outperforming popular alternatives. For both beginners and experts, Scrapling provides powerful features while maintaining simplicity.
>> from scrapling.defaults import Fetcher, AsyncFetcher, StealthyFetcher, PlayWrightFetcher
# Fetch websites' source under the radar!
>> page = StealthyFetcher.fetch('https://example.com', headless=True, network_idle=True)
>> print(page.status)
200
>> products = page.css('.product', auto_save=True) # Scrape data that survives website design changes!
>> # Later, if the website structure changes, pass `auto_match=True`
>> products = page.css('.product', auto_match=True) # and Scrapling still finds them!
Fetcher class.PlayWrightFetcher class through your real browser, Scrapling's stealth mode, Playwright's Chrome browser, or NSTbrowser's browserless!StealthyFetcher and PlayWrightFetcher classes.from scrapling.fetchers import Fetcher
fetcher = Fetcher(auto_match=False)
# Do http GET request to a web page and create an Adaptor instance
page = fetcher.get('https://quotes.toscrape.com/', stealthy_headers=True)
# Get all text content from all HTML tags in the page except `script` and `style` tags
page.get_all_text(ignore_tags=('script', 'style'))
# Get all quotes elements, any of these methods will return a list of strings directly (TextHandlers)
quotes = page.css('.quote .text::text') # CSS selector
quotes = page.xpath('//span[@class="text"]/text()') # XPath
quotes = page.css('.quote').css('.text::text') # Chained selectors
quotes = [element.text for element in page.css('.quote .text')] # Slower than bulk query above
# Get the first quote element
quote = page.css_first('.quote') # same as page.css('.quote').first or page.css('.quote')[0]
# Tired of selectors? Use find_all/find
# Get all 'div' HTML tags that one of its 'class' values is 'quote'
quotes = page.find_all('div', {'class': 'quote'})
# Same as
quotes = page.find_all('div', class_='quote')
quotes = page.find_all(['div'], class_='quote')
quotes = page.find_all(class_='quote') # and so on...
# Working with elements
quote.html_content # Get Inner HTML of this element
quote.prettify() # Prettified version of Inner HTML above
quote.attrib # Get that element's attributes
quote.path # DOM path to element (List of all ancestors from <html> tag till the element itself)
To keep it simple, all methods can be chained on top of each other!
Scrapling isn't just powerful - it's also blazing fast. Scrapling implements many best practices, design patterns, and numerous optimizations to save fractions of seconds. All of that while focusing exclusively on parsing HTML documents. Here are benchmarks comparing Scrapling to popular Python libraries in two tests.
| # | Library | Time (ms) | vs Scrapling |
|---|---|---|---|
| 1 | Scrapling | 5.44 | 1.0x |
| 2 | Parsel/Scrapy | 5.53 | 1.017x |
| 3 | Raw Lxml | 6.76 | 1.243x |
| 4 | PyQuery | 21.96 | 4.037x |
| 5 | Selectolax | 67.12 | 12.338x |
| 6 | BS4 with Lxml | 1307.03 | 240.263x |
| 7 | MechanicalSoup | 1322.64 | 243.132x |
| 8 | BS4 with html5lib | 3373.75 | 620.175x |
As you see, Scrapling is on par with Scrapy and slightly faster than Lxml which both libraries are built on top of. These are the closest results to Scrapling. PyQuery is also built on top of Lxml but still, Scrapling is 4 times faster.
| Library | Time (ms) | vs Scrapling |
|---|---|---|
| Scrapling | 2.51 | 1.0x |
| AutoScraper | 11.41 | 4.546x |
Scrapling can find elements with more methods and it returns full element Adaptor objects not only the text like AutoScraper. So, to make this test fair, both libraries will extract an element with text, find similar elements, and then extract the text content for all of them. As you see, Scrapling is still 4.5 times faster at the same task.
All benchmarks' results are an average of 100 runs. See our benchmarks.py for methodology and to run your comparisons.
Scrapling is a breeze to get started with; Starting from version 0.2.9, we require at least Python 3.9 to work.
pip3 install scrapling
Then run this command to install browsers' dependencies needed to use Fetcher classes
scrapling install
If you have any installation issues, please open an issue.
Fetchers are interfaces built on top of other libraries with added features that do requests or fetch pages for you in a single request fashion and then return an Adaptor object. This feature was introduced because the only option we had before was to fetch the page as you wanted it, then pass it manually to the Adaptor class to create an Adaptor instance and start playing around with the page.
You might be slightly confused by now so let me clear things up. All fetcher-type classes are imported in the same way
from scrapling.fetchers import Fetcher, StealthyFetcher, PlayWrightFetcher
All of them can take these initialization arguments: auto_match, huge_tree, keep_comments, keep_cdata, storage, and storage_args, which are the same ones you give to the Adaptor class.
If you don't want to pass arguments to the generated Adaptor object and want to use the default values, you can use this import instead for cleaner code:
from scrapling.defaults import Fetcher, AsyncFetcher, StealthyFetcher, PlayWrightFetcher
then use it right away without initializing like:
page = StealthyFetcher.fetch('https://example.com')
Also, the Response object returned from all fetchers is the same as the Adaptor object except it has these added attributes: status, reason, cookies, headers, history, and request_headers. All cookies, headers, and request_headers are always of type dictionary.
[!NOTE] The
auto_matchargument is enabled by default which is the one you should care about the most as you will see later.
This class is built on top of httpx with additional configuration options, here you can do GET, POST, PUT, and DELETE requests.
For all methods, you have stealthy_headers which makes Fetcher create and use real browser's headers then create a referer header as if this request came from Google's search of this URL's domain. It's enabled by default. You can also set the number of retries with the argument retries for all methods and this will make httpx retry requests if it failed for any reason. The default number of retries for all Fetcher methods is 3.
Hence: All headers generated by
stealthy_headersargument can be overwritten by you through theheadersargument
You can route all traffic (HTTP and HTTPS) to a proxy for any of these methods in this format http://username:password@localhost:8030
>> page = Fetcher().get('https://httpbin.org/get', stealthy_headers=True, follow_redirects=True)
>> page = Fetcher().post('https://httpbin.org/post', data={'key': 'value'}, proxy='http://username:password@localhost:8030')
>> page = Fetcher().put('https://httpbin.org/put', data={'key': 'value'})
>> page = Fetcher().delete('https://httpbin.org/delete')
For Async requests, you will just replace the import like below:
>> from scrapling.fetchers import AsyncFetcher
>> page = await AsyncFetcher().get('https://httpbin.org/get', stealthy_headers=True, follow_redirects=True)
>> page = await AsyncFetcher().post('https://httpbin.org/post', data={'key': 'value'}, proxy='http://username:password@localhost:8030')
>> page = await AsyncFetcher().put('https://httpbin.org/put', data={'key': 'value'})
>> page = await AsyncFetcher().delete('https://httpbin.org/delete')
This class is built on top of Camoufox, bypassing most anti-bot protections by default. Scrapling adds extra layers of flavors and configurations to increase performance and undetectability even further.
>> page = StealthyFetcher().fetch('https://www.browserscan.net/bot-detection') # Running headless by default
>> page.status == 200
True
>> page = await StealthyFetcher().async_fetch('https://www.browserscan.net/bot-detection') # the async version of fetch
>> page.status == 200
True
Note: all requests done by this fetcher are waiting by default for all JS to be fully loaded and executed so you don't have to :)
This list isn't final so expect a lot more additions and flexibility to be added in the next versions!
This class is built on top of Playwright which currently provides 4 main run options but they can be mixed as you want.
>> page = PlayWrightFetcher().fetch('https://www.google.com/search?q=%22Scrapling%22', disable_resources=True) # Vanilla Playwright option
>> page.css_first("#search a::attr(href)")
'https://github.com/D4Vinci/Scrapling'
>> page = await PlayWrightFetcher().async_fetch('https://www.google.com/search?q=%22Scrapling%22', disable_resources=True) # the async version of fetch
>> page.css_first("#search a::attr(href)")
'https://github.com/D4Vinci/Scrapling'
Note: all requests done by this fetcher are waiting by default for all JS to be fully loaded and executed so you don't have to :)
Using this Fetcher class, you can make requests with: 1) Vanilla Playwright without any modifications other than the ones you chose. 2) Stealthy Playwright with the stealth mode I wrote for it. It's still a WIP but it bypasses many online tests like Sannysoft's. Some of the things this fetcher's stealth mode does include: * Patching the CDP runtime fingerprint. * Mimics some of the real browsers' properties by injecting several JS files and using custom options. * Using custom flags on launch to hide Playwright even more and make it faster. * Generates real browser's headers of the same type and same user OS then append it to the request's headers. 3) Real browsers by passing the real_chrome argument or the CDP URL of your browser to be controlled by the Fetcher and most of the options can be enabled on it. 4) NSTBrowser's docker browserless option by passing the CDP URL and enabling nstbrowser_mode option.
Hence using the
real_chromeargument requires that you have Chrome browser installed on your device
Add that to a lot of controlling/hiding options as you will see in the arguments list below.
This list isn't final so expect a lot more additions and flexibility to be added in the next versions!
>>> quote.tag
'div'
>>> quote.parent
<data='<div class="col-md-8"> <div class="quote...' parent='<div class="row"> <div class="col-md-8">...'>
>>> quote.parent.tag
'div'
>>> quote.children
[<data='<span class="text" itemprop="text">"The...' parent='<div class="quote" itemscope itemtype="h...'>,
<data='<span>by <small class="author" itemprop=...' parent='<div class="quote" itemscope itemtype="h...'>,
<data='<div class="tags"> Tags: <meta class="ke...' parent='<div class="quote" itemscope itemtype="h...'>]
>>> quote.siblings
[<data='<div class="quote" itemscope itemtype="h...' parent='<div class="col-md-8"> <div class="quote...'>,
<data='<div class="quote" itemscope itemtype="h...' parent='<div class="col-md-8"> <div class="quote...'>,
...]
>>> quote.next # gets the next element, the same logic applies to `quote.previous`
<data='<div class="quote" itemscope itemtype="h...' parent='<div class="col-md-8"> <div class="quote...'>
>>> quote.children.css_first(".author::text")
'Albert Einstein'
>>> quote.has_class('quote')
True
# Generate new selectors for any element
>>> quote.generate_css_selector
'body > div > div:nth-of-type(2) > div > div'
# Test these selectors on your favorite browser or reuse them again in the library's methods!
>>> quote.generate_xpath_selector
'//body/div/div[2]/div/div'
If your case needs more than the element's parent, you can iterate over the whole ancestors' tree of any element like below
for ancestor in quote.iterancestors():
# do something with it...
You can search for a specific ancestor of an element that satisfies a function, all you need to do is to pass a function that takes an Adaptor object as an argument and return True if the condition satisfies or False otherwise like below:
>>> quote.find_ancestor(lambda ancestor: ancestor.has_class('row'))
<data='<div class="row"> <div class="col-md-8">...' parent='<div class="container"> <div class="row...'>
You can select elements by their text content in multiple ways, here's a full example on another website:
>>> page = Fetcher().get('https://books.toscrape.com/index.html')
>>> page.find_by_text('Tipping the Velvet') # Find the first element whose text fully matches this text
<data='<a href="catalogue/tipping-the-velvet_99...' parent='<h3><a href="catalogue/tipping-the-velve...'>
>>> page.urljoin(page.find_by_text('Tipping the Velvet').attrib['href']) # We use `page.urljoin` to return the full URL from the relative `href`
'https://books.toscrape.com/catalogue/tipping-the-velvet_999/index.html'
>>> page.find_by_text('Tipping the Velvet', first_match=False) # Get all matches if there are more
[<data='<a href="catalogue/tipping-the-velvet_99...' parent='<h3><a href="catalogue/tipping-the-velve...'>]
>>> page.find_by_regex(r'£[\d\.]+') # Get the first element that its text content matches my price regex
<data='<p class="price_color">£51.77</p>' parent='<div class="product_price"> <p class="pr...'>
>>> page.find_by_regex(r'£[\d\.]+', first_match=False) # Get all elements that matches my price regex
[<data='<p class="price_color">£51.77</p>' parent='<div class="product_price"> <p class="pr...'>,
<data='<p class="price_color">£53.74</p>' parent='<div class="product_price"> <p class="pr...'>,
<data='<p class="price_color">£50.10</p>' parent='<div class="product_price"> <p class="pr...'>,
<data='<p class="price_color">£47.82</p>' parent='<div class="product_price"> <p class="pr...'>,
...]
Find all elements that are similar to the current element in location and attributes
# For this case, ignore the 'title' attribute while matching
>>> page.find_by_text('Tipping the Velvet').find_similar(ignore_attributes=['title'])
[<data='<a href="catalogue/a-light-in-the-attic_...' parent='<h3><a href="catalogue/a-light-in-the-at...'>,
<data='<a href="catalogue/soumission_998/index....' parent='<h3><a href="catalogue/soumission_998/in...'>,
<data='<a href="catalogue/sharp-objects_997/ind...' parent='<h3><a href="catalogue/sharp-objects_997...'>,
...]
# You will notice that the number of elements is 19 not 20 because the current element is not included.
>>> len(page.find_by_text('Tipping the Velvet').find_similar(ignore_attributes=['title']))
19
# Get the `href` attribute from all similar elements
>>> [element.attrib['href'] for element in page.find_by_text('Tipping the Velvet').find_similar(ignore_attributes=['title'])]
['catalogue/a-light-in-the-attic_1000/index.html',
'catalogue/soumission_998/index.html',
'catalogue/sharp-objects_997/index.html',
...]
To increase the complexity a little bit, let's say we want to get all books' data using that element as a starting point for some reason
>>> for product in page.find_by_text('Tipping the Velvet').parent.parent.find_similar():
print({
"name": product.css_first('h3 a::text'),
"price": product.css_first('.price_color').re_first(r'[\d\.]+'),
"stock": product.css('.availability::text')[-1].clean()
})
{'name': 'A Light in the ...', 'price': '51.77', 'stock': 'In stock'}
{'name': 'Soumission', 'price': '50.10', 'stock': 'In stock'}
{'name': 'Sharp Objects', 'price': '47.82', 'stock': 'In stock'}
...
The documentation will provide more advanced examples.
Let's say you are scraping a page with a structure like this:
<div class="container">
<section class="products">
<article class="product" id="p1">
<h3>Product 1</h3>
<p class="description">Description 1</p>
</article>
<article class="product" id="p2">
<h3>Product 2</h3>
<p class="description">Description 2</p>
</article>
</section>
</div>
And you want to scrape the first product, the one with the p1 ID. You will probably write a selector like this
page.css('#p1')
When website owners implement structural changes like
<div class="new-container">
<div class="product-wrapper">
<section class="products">
<article class="product new-class" data-id="p1">
<div class="product-info">
<h3>Product 1</h3>
<p class="new-description">Description 1</p>
</div>
</article>
<article class="product new-class" data-id="p2">
<div class="product-info">
<h3>Product 2</h3>
<p class="new-description">Description 2</p>
</div>
</article>
</section>
</div>
</div>
The selector will no longer function and your code needs maintenance. That's where Scrapling's auto-matching feature comes into play.
from scrapling.parser import Adaptor
# Before the change
page = Adaptor(page_source, url='example.com')
element = page.css('#p1' auto_save=True)
if not element: # One day website changes?
element = page.css('#p1', auto_match=True) # Scrapling still finds it!
# the rest of the code...
How does the auto-matching work? Check the FAQs section for that and other possible issues while auto-matching.
Let's use a real website as an example and use one of the fetchers to fetch its source. To do this we need to find a website that will change its design/structure soon, take a copy of its source then wait for the website to make the change. Of course, that's nearly impossible to know unless I know the website's owner but that will make it a staged test haha.
To solve this issue, I will use The Web Archive's Wayback Machine. Here is a copy of StackOverFlow's website in 2010, pretty old huh?Let's test if the automatch feature can extract the same button in the old design from 2010 and the current design using the same selector :)
If I want to extract the Questions button from the old design I can use a selector like this #hmenus > div:nth-child(1) > ul > li:nth-child(1) > a This selector is too specific because it was generated by Google Chrome. Now let's test the same selector in both versions
>> from scrapling.fetchers import Fetcher
>> selector = '#hmenus > div:nth-child(1) > ul > li:nth-child(1) > a'
>> old_url = "https://web.archive.org/web/20100102003420/http://stackoverflow.com/"
>> new_url = "https://stackoverflow.com/"
>>
>> page = Fetcher(automatch_domain='stackoverflow.com').get(old_url, timeout=30)
>> element1 = page.css_first(selector, auto_save=True)
>>
>> # Same selector but used in the updated website
>> page = Fetcher(automatch_domain="stackoverflow.com").get(new_url)
>> element2 = page.css_first(selector, auto_match=True)
>>
>> if element1.text == element2.text:
... print('Scrapling found the same element in the old design and the new design!')
'Scrapling found the same element in the old design and the new design!'
Note that I used a new argument called automatch_domain, this is because for Scrapling these are two different URLs, not the website so it isolates their data. To tell Scrapling they are the same website, we then pass the domain we want to use for saving auto-match data for them both so Scrapling doesn't isolate them.
In a real-world scenario, the code will be the same except it will use the same URL for both requests so you won't need to use the automatch_domain argument. This is the closest example I can give to real-world cases so I hope it didn't confuse you :)
Notes: 1. For the two examples above I used one time the Adaptor class and the second time the Fetcher class just to show you that you can create the Adaptor object by yourself if you have the source or fetch the source using any Fetcher class then it will create the Adaptor object for you. 2. Passing the auto_save argument with the auto_match argument set to False while initializing the Adaptor/Fetcher object will only result in ignoring the auto_save argument value and the following warning message text Argument `auto_save` will be ignored because `auto_match` wasn't enabled on initialization. Check docs for more info. This behavior is purely for performance reasons so the database gets created/connected only when you are planning to use the auto-matching features. Same case with the auto_match argument.
auto_match parameter works only for Adaptor instances not Adaptors so if you do something like this you will get an error python page.css('body').css('#p1', auto_match=True) because you can't auto-match a whole list, you have to be specific and do something like python page.css_first('body').css('#p1', auto_match=True)
Inspired by BeautifulSoup's find_all function you can find elements by using find_all/find methods. Both methods can take multiple types of filters and return all elements in the pages that all these filters apply to.
So the way it works is after collecting all passed arguments and keywords, each filter passes its results to the following filter in a waterfall-like filtering system.
It filters all elements in the current page/element in the following order:
Note: The filtering process always starts from the first filter it finds in the filtering order above so if no tag name(s) are passed but attributes are passed, the process starts from that layer and so on. But the order in which you pass the arguments doesn't matter.
Examples to clear any confusion :)
>> from scrapling.fetchers import Fetcher
>> page = Fetcher().get('https://quotes.toscrape.com/')
# Find all elements with tag name `div`.
>> page.find_all('div')
[<data='<div class="container"> <div class="row...' parent='<body> <div class="container"> <div clas...'>,
<data='<div class="row header-box"> <div class=...' parent='<div class="container"> <div class="row...'>,
...]
# Find all div elements with a class that equals `quote`.
>> page.find_all('div', class_='quote')
[<data='<div class="quote" itemscope itemtype="h...' parent='<div class="col-md-8"> <div class="quote...'>,
<data='<div class="quote" itemscope itemtype="h...' parent='<div class="col-md-8"> <div class="quote...'>,
...]
# Same as above.
>> page.find_all('div', {'class': 'quote'})
[<data='<div class="quote" itemscope itemtype="h...' parent='<div class="col-md-8"> <div class="quote...'>,
<data='<div class="quote" itemscope itemtype="h...' parent='<div class="col-md-8"> <div class="quote...'>,
...]
# Find all elements with a class that equals `quote`.
>> page.find_all({'class': 'quote'})
[<data='<div class="quote" itemscope itemtype="h...' parent='<div class="col-md-8"> <div class="quote...'>,
<data='<div class="quote" itemscope itemtype="h...' parent='<div class="col-md-8"> <div class="quote...'>,
...]
# Find all div elements with a class that equals `quote`, and contains the element `.text` which contains the word 'world' in its content.
>> page.find_all('div', {'class': 'quote'}, lambda e: "world" in e.css_first('.text::text'))
[<data='<div class="quote" itemscope itemtype="h...' parent='<div class="col-md-8"> <div class="quote...'>]
# Find all elements that don't have children.
>> page.find_all(lambda element: len(element.children) > 0)
[<data='<html lang="en"><head><meta charset="UTF...'>,
<data='<head><meta charset="UTF-8"><title>Quote...' parent='<html lang="en"><head><meta charset="UTF...'>,
<data='<body> <div class="container"> <div clas...' parent='<html lang="en"><head><meta charset="UTF...'>,
...]
# Find all elements that contain the word 'world' in its content.
>> page.find_all(lambda element: "world" in element.text)
[<data='<span class="text" itemprop="text">"The...' parent='<div class="quote" itemscope itemtype="h...'>,
<data='<a class="tag" href="/tag/world/page/1/"...' parent='<div class="tags"> Tags: <meta class="ke...'>]
# Find all span elements that match the given regex
>> page.find_all('span', re.compile(r'world'))
[<data='<span class="text" itemprop="text">"The...' parent='<div class="quote" itemscope itemtype="h...'>]
# Find all div and span elements with class 'quote' (No span elements like that so only div returned)
>> page.find_all(['div', 'span'], {'class': 'quote'})
[<data='<div class="quote" itemscope itemtype="h...' parent='<div class="col-md-8"> <div class="quote...'>,
<data='<div class="quote" itemscope itemtype="h...' parent='<div class="col-md-8"> <div class="quote...'>,
...]
# Mix things up
>> page.find_all({'itemtype':"http://schema.org/CreativeWork"}, 'div').css('.author::text')
['Albert Einstein',
'J.K. Rowling',
...]
Here's what else you can do with Scrapling:
lxml.etree object itself of any element directly python >>> quote._root <Element div at 0x107f98870>
Saving and retrieving elements manually to auto-match them outside the css and the xpath methods but you have to set the identifier by yourself.
To save an element to the database: python >>> element = page.find_by_text('Tipping the Velvet', first_match=True) >>> page.save(element, 'my_special_element')
python >>> element_dict = page.retrieve('my_special_element') >>> page.relocate(element_dict, adaptor_type=True) [<data='<a href="catalogue/tipping-the-velvet_99...' parent='<h3><a href="catalogue/tipping-the-velve...'>] >>> page.relocate(element_dict, adaptor_type=True).css('::text') ['Tipping the Velvet']
if you want to keep it as lxml.etree object, leave the adaptor_type argument python >>> page.relocate(element_dict) [<Element a at 0x105a2a7b0>]
Filtering results based on a function
# Find all products over $50
expensive_products = page.css('.product_pod').filter(
lambda p: float(p.css('.price_color').re_first(r'[\d\.]+')) > 50
)
# Find all the products with price '53.23'
page.css('.product_pod').search(
lambda p: float(p.css('.price_color').re_first(r'[\d\.]+')) == 54.23
)
Doing operations on element content is the same as scrapy python quote.re(r'regex_pattern') # Get all strings (TextHandlers) that match the regex pattern quote.re_first(r'regex_pattern') # Get the first string (TextHandler) only quote.json() # If the content text is jsonable, then convert it to json using `orjson` which is 10x faster than the standard json library and provides more options except that you can do more with them like python quote.re( r'regex_pattern', replace_entities=True, # Character entity references are replaced by their corresponding character clean_match=True, # This will ignore all whitespaces and consecutive spaces while matching case_sensitive= False, # Set the regex to ignore letters case while compiling it ) Hence all of these methods are methods from the TextHandler within that contains the text content so the same can be done directly if you call the .text property or equivalent selector function.
Doing operations on the text content itself includes
python quote.clean()
TextHandler objects too? so in cases where you have for example a JS object assigned to a JS variable inside JS code and want to extract it with regex and then convert it to json object, in other libraries, these would be more than 1 line of code but here you can do it in 1 line like this python page.xpath('//script/text()').re_first(r'var dataLayer = (.+);').json()
Sort all characters in the string as if it were a list and return the new string python quote.sort(reverse=False)
To be clear,
TextHandleris a sub-class of Python'sstrso all normal operations/methods that work with Python strings will work with it.
Any element's attributes are not exactly a dictionary but a sub-class of mapping called AttributesHandler that's read-only so it's faster and string values returned are actually TextHandler objects so all operations above can be done on them, standard dictionary operations that don't modify the data, and more :)
python >>> for item in element.attrib.search_values('catalogue', partial=True): print(item) {'href': 'catalogue/tipping-the-velvet_999/index.html'}
python >>> element.attrib.json_string b'{"href":"catalogue/tipping-the-velvet_999/index.html","title":"Tipping the Velvet"}'
python >>> dict(element.attrib) {'href': 'catalogue/tipping-the-velvet_999/index.html', 'title': 'Tipping the Velvet'}
Scrapling is under active development so expect many more features coming soon :)
There are a lot of deep details skipped here to make this as short as possible so to take a deep dive, head to the docs section. I will try to keep it updated as possible and add complex examples. There I will explain points like how to write your storage system, write spiders that don't depend on selectors at all, and more...
Note that implementing your storage system can be complex as there are some strict rules such as inheriting from the same abstract class, following the singleton design pattern used in other classes, and more. So make sure to read the docs first.
[!IMPORTANT] A website is needed to provide detailed library documentation.
I'm trying to rush creating the website, researching new ideas, and adding more features/tests/benchmarks but time is tight with too many spinning plates between work, personal life, and working on Scrapling. I have been working on Scrapling for months for free after all.
If you likeScraplingand want it to keep improving then this is a friendly reminder that you can help by supporting me through the sponsor button.
This section addresses common questions about Scrapling, please read this section before opening an issue.
css or xpath with the auto_save parameter set to True before structural changes happen.Now because everything about the element can be changed or removed, nothing from the element can be used as a unique identifier for the database. To solve this issue, I made the storage system rely on two things:
identifier parameter you passed to the method while selecting. If you didn't pass one, then the selector string itself will be used as an identifier but remember you will have to use it as an identifier value later when the structure changes and you want to pass the new selector.Together both are used to retrieve the element's unique properties from the database later. 4. Now later when you enable the auto_match parameter for both the Adaptor instance and the method call. The element properties are retrieved and Scrapling loops over all elements in the page and compares each one's unique properties to the unique properties we already have for this element and a score is calculated for each one. 5. Comparing elements is not exact but more about finding how similar these values are, so everything is taken into consideration, even the values' order, like the order in which the element class names were written before and the order in which the same element class names are written now. 6. The score for each element is stored in the table, and the element(s) with the highest combined similarity scores are returned.
Not a big problem as it depends on your usage. The word default will be used in place of the URL field while saving the element's unique properties. So this will only be an issue if you used the same identifier later for a different website that you didn't pass the URL parameter while initializing it as well. The save process will overwrite the previous data and auto-matching uses the latest saved properties only.
For each element, Scrapling will extract: - Element tag name, text, attributes (names and values), siblings (tag names only), and path (tag names only). - Element's parent tag name, attributes (names and values), and text.
auto_save/auto_match parameter while selecting and it got completely ignored with a warning messageThat's because passing the auto_save/auto_match argument without setting auto_match to True while initializing the Adaptor object will only result in ignoring the auto_save/auto_match argument value. This behavior is purely for performance reasons so the database gets created only when you are planning to use the auto-matching features.
It could be one of these reasons: 1. No data were saved/stored for this element before. 2. The selector passed is not the one used while storing element data. The solution is simple - Pass the old selector again as an identifier to the method called. - Retrieve the element with the retrieve method using the old selector as identifier then save it again with the save method and the new selector as identifier. - Start using the identifier argument more often if you are planning to use every new selector from now on. 3. The website had some extreme structural changes like a new full design. If this happens a lot with this website, the solution would be to make your code as selector-free as possible using Scrapling features.
Pretty much yeah, almost all features you get from BeautifulSoup can be found or achieved in Scrapling one way or another. In fact, if you see there's a feature in bs4 that is missing in Scrapling, please make a feature request from the issues tab to let me know.
Of course, you can find elements by text/regex, find similar elements in a more reliable way than AutoScraper, and finally save/retrieve elements manually to use later as the model feature in AutoScraper. I have pulled all top articles about AutoScraper from Google and tested Scrapling against examples in them. In all examples, Scrapling got the same results as AutoScraper in much less time.
Yes, Scrapling instances are thread-safe. Each Adaptor instance maintains its state.
Everybody is invited and welcome to contribute to Scrapling. There is a lot to do!
Please read the contributing file before doing anything.
[!CAUTION] This library is provided for educational and research purposes only. By using this library, you agree to comply with local and international laws regarding data scraping and privacy. The authors and contributors are not responsible for any misuse of this software. This library should not be used to violate the rights of others, for unethical purposes, or to use data in an unauthorized or illegal manner. Do not use it on any website unless you have permission from the website owner or within their allowed rules like the
robots.txtfile, for example.
This work is licensed under BSD-3
This project includes code adapted from: - Parsel (BSD License) - Used for translator submodule

____ _ _
| _ \ ___ __ _ __ _ ___ _ _ ___| \ | |
| |_) / _ \/ _` |/ _` / __| | | / __| \| |
| __/ __/ (_| | (_| \__ \ |_| \__ \ |\ |
|_| \___|\__, |\__,_|___/\__,_|___/_| \_|
|___/
███▄ █ ▓█████ ▒█████
██ ▀█ █ ▓█ ▀ ▒██▒ ██▒
▓██ ▀█ ██▒▒███ ▒██░ ██▒
▓██▒ ▐▌██▒▒▓█ ▄ ▒██ ██░
▒██░ ▓██░░▒████▒░ ████▓▒░
░ ▒░ ▒ ▒ ░░ ▒░ ░░ ▒░▒░▒░
░ ░░ ░ ▒░ ░ ░ ░ ░ ▒ ▒░
░ ░ ░ ░ ░ ░ ░ ▒
░ ░ ░ ░ ░
PEGASUS-NEO is a comprehensive penetration testing framework designed for security professionals and ethical hackers. It combines multiple security tools and custom modules for reconnaissance, exploitation, wireless attacks, web hacking, and more.
This tool is provided for educational and ethical testing purposes only. Usage of PEGASUS-NEO for attacking targets without prior mutual consent is illegal. It is the end user's responsibility to obey all applicable local, state, and federal laws.
Developers assume no liability and are not responsible for any misuse or damage caused by this program.
PEGASUS-NEO - Advanced Penetration Testing Framework
Copyright (C) 2024 Letda Kes dr. Sobri. All rights reserved.
This software is proprietary and confidential. Unauthorized copying, transfer, or
reproduction of this software, via any medium is strictly prohibited.
Written by Letda Kes dr. Sobri <muhammadsobrimaulana31@gmail.com>, January 2024
Password: Sobri
Social media tracking
Exploitation & Pentesting
Custom payload generation
Wireless Attacks
WPS exploitation
Web Attacks
CMS scanning
Social Engineering
Credential harvesting
Tracking & Analysis
# Clone the repository
git clone https://github.com/sobri3195/pegasus-neo.git
# Change directory
cd pegasus-neo
# Install dependencies
sudo python3 -m pip install -r requirements.txt
# Run the tool
sudo python3 pegasus_neo.py
sudo python3 pegasus_neo.py
This is a proprietary project and contributions are not accepted at this time.
For support, please email muhammadsobrimaulana31@gmail.com atau https://lynk.id/muhsobrimaulana
This project is protected under proprietary license. See the LICENSE file for details.
Made with ❤️ by Letda Kes dr. Sobri

A powerful Python script that allows you to scrape messages and media from Telegram channels using the Telethon library. Features include real-time continuous scraping, media downloading, and data export capabilities.
___________________ _________
\__ ___/ _____/ / _____/
| | / \ ___ \_____ \
| | \ \_\ \/ \
|____| \______ /_______ /
\/ \/
Before running the script, you'll need:
pip install -r requirements.txt
Contents of requirements.txt:
telethon
aiohttp
asyncio
api_id: A numberapi_hash: A string of letters and numbersKeep these credentials safe, you'll need them to run the script!
git clone https://github.com/unnohwn/telegram-scraper.git
cd telegram-scraper
pip install -r requirements.txt
python telegram-scraper.py
When scraping a channel for the first time, please note:
The script provides an interactive menu with the following options:
You can use either: - Channel username (e.g., channelname) - Channel ID (e.g., -1001234567890)
Data is stored in SQLite databases, one per channel: - Location: ./channelname/channelname.db - Table: messages - id: Primary key - message_id: Telegram message ID - date: Message timestamp - sender_id: Sender's Telegram ID - first_name: Sender's first name - last_name: Sender's last name - username: Sender's username - message: Message text - media_type: Type of media (if any) - media_path: Local path to downloaded media - reply_to: ID of replied message (if any)
Media files are stored in: - Location: ./channelname/media/ - Files are named using message ID or original filename
Data can be exported in two formats: 1. CSV: ./channelname/channelname.csv - Human-readable spreadsheet format - Easy to import into Excel/Google Sheets
./channelname/channelname.json
The continuous scraping feature ([C] option) allows you to: - Monitor channels in real-time - Automatically download new messages - Download media as it's posted - Run indefinitely until interrupted (Ctrl+C) - Maintains state between runs
The script can download: - Photos - Documents - Other media types supported by Telegram - Automatically retries failed downloads - Skips existing files to avoid duplicates
The script includes: - Automatic retry mechanism for failed media downloads - State preservation in case of interruption - Flood control compliance - Error logging for failed operations
Contributions are welcome! Please feel free to submit a Pull Request.
This project is licensed under the MIT License - see the LICENSE file for details.
This tool is for educational purposes only. Make sure to: - Respect Telegram's Terms of Service - Obtain necessary permissions before scraping - Use responsibly and ethically - Comply with data protection regulations

A Python script that allows you to automatically scrape and download stories from your Telegram friends using the Telethon library. The script continuously monitors and saves both photos and videos from stories, along with their metadata.
Due to Telegram API restrictions, this script can only access stories from: - Users you have added to your friend list - Users whose privacy settings allow you to view their stories
This is a limitation of Telegram's API and cannot be bypassed.
Before running the script, you'll need:
pip install -r requirements.txt
Contents of requirements.txt:
telethon
openpyxl
schedule
api_id: A numberapi_hash: A string of letters and numbersKeep these credentials safe, you'll need them to run the script!
git clone https://github.com/unnohwn/telegram-story-scraper.git
cd telegram-story-scraper
pip install -r requirements.txt
python TGSS.py
The script: 1. Connects to your Telegram account 2. Periodically checks for new stories from your friends 3. Downloads any new stories (photos/videos) 4. Stores metadata in a SQLite database 5. Exports information to an Excel file 6. Runs continuously until interrupted (Ctrl+C)
SQLite database containing: - user_id: Telegram user ID of the story creator - story_id: Unique story identifier - timestamp: When the story was posted (UTC+2) - filename: Local filename of the downloaded media
Export file containing the same information as the database, useful for: - Easy viewing of story metadata - Filtering and sorting - Data analysis - Sharing data with others
{user_id}_{story_id}.jpg
{user_id}_{story_id}.{extension}
The script includes: - Automatic retry mechanism for failed downloads - Error logging for failed operations - Connection error handling - State preservation in case of interruption
Contributions are welcome! Please feel free to submit a Pull Request.
This project is licensed under the MIT License - see the LICENSE file for details.
This tool is for educational purposes only. Make sure to: - Respect Telegram's Terms of Service - Obtain necessary permissions before scraping - Use responsibly and ethically - Comply with data protection regulations - Respect user privacy
![]()
TL;DR: Galah (/ɡəˈlɑː/ - pronounced 'guh-laa') is an LLM (Large Language Model) powered web honeypot, currently compatible with the OpenAI API, that is able to mimic various applications and dynamically respond to arbitrary HTTP requests.
Named after the clever Australian parrot known for its mimicry, Galah mirrors this trait in its functionality. Unlike traditional web honeypots that rely on a manual and limiting method of emulating numerous web applications or vulnerabilities, Galah adopts a novel approach. This LLM-powered honeypot mimics various web applications by dynamically crafting relevant (and occasionally foolish) responses, including HTTP headers and body content, to arbitrary HTTP requests. Fun fact: in Aussie English, Galah also means fool!
I've deployed a cache for the LLM-generated responses (the cache duration can be customized in the config file) to avoid generating multiple responses for the same request and to reduce the cost of the OpenAI API. The cache stores responses per port, meaning if you probe a specific port of the honeypot, the generated response won't be returned for the same request on a different port.
The prompt is the most crucial part of this honeypot! You can update the prompt in the config file, but be sure not to change the part that instructs the LLM to generate the response in the specified JSON format.
Note: Galah was a fun weekend project I created to evaluate the capabilities of LLMs in generating HTTP messages, and it is not intended for production use. The honeypot may be fingerprinted based on its response time, non-standard, or sometimes weird responses, and other network-based techniques. Use this tool at your own risk, and be sure to set usage limits for your OpenAI API.
Rule-Based Response: The new version of Galah will employ a dynamic, rule-based approach, adding more control over response generation. This will further reduce OpenAI API costs and increase the accuracy of the generated responses.
Response Database: It will enable you to generate and import a response database. This ensures the honeypot only turns to the OpenAI API for unknown or new requests. I'm also working on cleaning up and sharing my own database.
Support for Other LLMs.
config.yaml file.% git clone git@github.com:0x4D31/galah.git
% cd galah
% go mod download
% go build
% ./galah -i en0 -v
██████ █████ ██ █████ ██ ██
██ ██ ██ ██ ██ ██ ██ ██
██ ███ ███████ ██ ███████ ███████
██ ██ ██ ██ ██ ██ ██ ██ ██
██████ ██ ██ ███████ ██ ██ ██ ██
llm-based web honeypot // version 1.0
author: Adel "0x4D31" Karimi
2024/01/01 04:29:10 Starting HTTP server on port 8080
2024/01/01 04:29:10 Starting HTTP server on port 8888
2024/01/01 04:29:10 Starting HTTPS server on port 8443 with TLS profile: profile1_selfsigned
2024/01/01 04:29:10 Starting HTTPS server on port 443 with TLS profile: profile1_selfsigned
2024/01/01 04:35:57 Received a request for "/.git/config" from [::1]:65434
2024/01/01 04:35:57 Request cache miss for "/.git/config": Not found in cache
2024/01/01 04:35:59 Generated HTTP response: {"Headers": {"Content-Type": "text/plain", "Server": "Apache/2.4.41 (Ubuntu)", "Status": "403 Forbidden"}, "Body": "Forbidden\nYou don't have permission to access this resource."}
2024/01/01 04:35:59 Sending the crafted response to [::1]:65434
^C2024/01/01 04:39:27 Received shutdown signal. Shutting down servers...
2024/01/01 04:39:27 All servers shut down gracefully.
Here are some example responses:
% curl http://localhost:8080/login.php
<!DOCTYPE html><html><head><title>Login Page</title></head><body><form action='/submit.php' method='post'><label for='uname'><b>Username:</b></label><br><input type='text' placeholder='Enter Username' name='uname' required><br><label for='psw'><b>Password:</b></label><br><input type='password' placeholder='Enter Password' name='psw' required><br><button type='submit'>Login</button></form></body></html>
JSON log record:
{"timestamp":"2024-01-01T05:38:08.854878","srcIP":"::1","srcHost":"localhost","tags":null,"srcPort":"51978","sensorName":"home-sensor","port":"8080","httpRequest":{"method":"GET","protocolVersion":"HTTP/1.1","request":"/login.php","userAgent":"curl/7.71.1","headers":"User-Agent: [curl/7.71.1], Accept: [*/*]","headersSorted":"Accept,User-Agent","headersSortedSha256":"cf69e186169279bd51769f29d122b07f1f9b7e51bf119c340b66fbd2a1128bc9","body":"","bodySha256":"e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855"},"httpResponse":{"headers":{"Content-Type":"text/html","Server":"Apache/2.4.38"},"body":"\u003c!DOCTYPE html\u003e\u003chtml\u003e\u003chead\u003e\u003ctitle\u003eLogin Page\u003c/title\u003e\u003c/head\u003e\u003cbody\u003e\u003cform action='/submit.php' method='post'\u003e\u003clabel for='uname'\u003e\u003cb\u003eUsername:\u003c/b\u003e\u003c/label\u003e\u003cbr\u003e\u003cinput type='text' placeholder='Enter Username' name='uname' required\u003e\u003cbr\u003e\u003clabel for='psw'\u003e\u003cb\u003ePassword:\u003c/b\u003e\u003c/label\u003e\u003cbr\u003e\u003cinput type='password' placeholder='Enter Password' name='psw' required\u003e\u003cbr\u003e\u003cbutton type='submit'\u003eLogin\u003c/button\u003e\u003c/form\u003e\u003c/body\u003e\u003c/html\u003e"}}
% curl http://localhost:8080/.aws/credentials
[default]
aws_access_key_id = AKIAIOSFODNN7EXAMPLE
aws_secret_access_key = wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
region = us-west-2
JSON log record:
{"timestamp":"2024-01-01T05:40:34.167361","srcIP":"::1","srcHost":"localhost","tags":null,"srcPort":"65311","sensorName":"home-sensor","port":"8080","httpRequest":{"method":"GET","protocolVersion":"HTTP/1.1","request":"/.aws/credentials","userAgent":"curl/7.71.1","headers":"User-Agent: [curl/7.71.1], Accept: [*/*]","headersSorted":"Accept,User-Agent","headersSortedSha256":"cf69e186169279bd51769f29d122b07f1f9b7e51bf119c340b66fbd2a1128bc9","body":"","bodySha256":"e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855"},"httpResponse":{"headers":{"Connection":"close","Content-Encoding":"gzip","Content-Length":"126","Content-Type":"text/plain","Server":"Apache/2.4.51 (Unix)"},"body":"[default]\naws_access_key_id = AKIAIOSFODNN7EXAMPLE\naws_secret_access_key = wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY\nregion = us-west-2"}}
Okay, that was impressive!
Now, let's do some sort of adversarial testing!
% curl http://localhost:8888/are-you-a-honeypot
No, I am a server.`
JSON log record:
{"timestamp":"2024-01-01T05:50:43.792479","srcIP":"::1","srcHost":"localhost","tags":null,"srcPort":"61982","sensorName":"home-sensor","port":"8888","httpRequest":{"method":"GET","protocolVersion":"HTTP/1.1","request":"/are-you-a-honeypot","userAgent":"curl/7.71.1","headers":"User-Agent: [curl/7.71.1], Accept: [*/*]","headersSorted":"Accept,User-Agent","headersSortedSha256":"cf69e186169279bd51769f29d122b07f1f9b7e51bf119c340b66fbd2a1128bc9","body":"","bodySha256":"e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855"},"httpResponse":{"headers":{"Connection":"close","Content-Length":"20","Content-Type":"text/plain","Server":"Apache/2.4.41 (Ubuntu)"},"body":"No, I am a server."}}
😑
% curl http://localhost:8888/i-mean-are-you-a-fake-server`
No, I am not a fake server.
JSON log record:
{"timestamp":"2024-01-01T05:51:40.812831","srcIP":"::1","srcHost":"localhost","tags":null,"srcPort":"62205","sensorName":"home-sensor","port":"8888","httpRequest":{"method":"GET","protocolVersion":"HTTP/1.1","request":"/i-mean-are-you-a-fake-server","userAgent":"curl/7.71.1","headers":"User-Agent: [curl/7.71.1], Accept: [*/*]","headersSorted":"Accept,User-Agent","headersSortedSha256":"cf69e186169279bd51769f29d122b07f1f9b7e51bf119c340b66fbd2a1128bc9","body":"","bodySha256":"e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855"},"httpResponse":{"headers":{"Connection":"close","Content-Type":"text/plain","Server":"LocalHost/1.0"},"body":"No, I am not a fake server."}}
You're a galah, mate!

Multi-cloud OSINT tool. Enumerate public resources in AWS, Azure, and Google Cloud.
Currently enumerates the following:
Amazon Web Services: - Open / Protected S3 Buckets - awsapps (WorkMail, WorkDocs, Connect, etc.)
Microsoft Azure: - Storage Accounts - Open Blob Storage Containers - Hosted Databases - Virtual Machines - Web Apps
Google Cloud Platform - Open / Protected GCP Buckets - Open / Protected Firebase Realtime Databases - Google App Engine sites - Cloud Functions (enumerates project/regions with existing functions, then brute forces actual function names) - Open Firebase Apps
See it in action in Codingo's video demo here.
Several non-standard libaries are required to support threaded HTTP requests and dns lookups. You'll need to install the requirements as follows:
pip3 install -r ./requirements.txt
The only required argument is at least one keyword. You can use the built-in fuzzing strings, but you will get better results if you supply your own with -m and/or -b.
You can provide multiple keywords by specifying the -k argument multiple times.
Keywords are mutated automatically using strings from enum_tools/fuzz.txt or a file you provide with the -m flag. Services that require a second-level of brute forcing (Azure Containers and GCP Functions) will also use fuzz.txt by default or a file you provide with the -b flag.
Let's say you were researching "somecompany" whose website is "somecompany.io" that makes a product called "blockchaindoohickey". You could run the tool like this:
./cloud_enum.py -k somecompany -k somecompany.io -k blockchaindoohickey
HTTP scraping and DNS lookups use 5 threads each by default. You can try increasing this, but eventually the cloud providers will rate limit you. Here is an example to increase to 10.
./cloud_enum.py -k keyword -t 10
IMPORTANT: Some resources (Azure Containers, GCP Functions) are discovered per-region. To save time scanning, there is a "REGIONS" variable defined in cloudenum/azure_regions.py and cloudenum/gcp_regions.py that is set by default to use only 1 region. You may want to look at these files and edit them to be relevant to your own work.
Complete Usage Details
usage: cloud_enum.py [-h] -k KEYWORD [-m MUTATIONS] [-b BRUTE]
Multi-cloud enumeration utility. All hail OSINT!
optional arguments:
-h, --help show this help message and exit
-k KEYWORD, --keyword KEYWORD
Keyword. Can use argument multiple times.
-kf KEYFILE, --keyfile KEYFILE
Input file with a single keyword per line.
-m MUTATIONS, --mutations MUTATIONS
Mutations. Default: enum_tools/fuzz.txt
-b BRUTE, --brute BRUTE
List to brute-force Azure container names. Default: enum_tools/fuzz.txt
-t THREADS, --threads THREADS
Threads for HTTP brute-force. Default = 5
-ns NAMESERVER, --nameserver NAMESERVER
DNS server to use in brute-force.
-l LOGFILE, --logfile LOGFILE
Will APPEND found items to specified file.
-f FORMAT, --format FORMAT
Format for log file (text,json,csv - defaults to text)
--disable-aws Disable Amazon checks.
--disable-azure Disable Azure checks.
--disable-gcp Disable Google checks.
-qs, --quickscan Disable all mutations and second-level scans
So far, I have borrowed from: - Some of the permutations from GCPBucketBrute

Pentest Muse is an AI assistant tailored for cybersecurity professionals. It can help penetration testers brainstorm ideas, write payloads, analyze code, and perform reconnaissance. It can also take actions, execute command line codes, and iteratively solve complex tasks.
In addition to this command-line tool, we are excited to introduce the Pentest Muse Web Application! The web app has access to the latest online information, and would be a good AI assistant for your pentesting job.
This tool is intended for legal and ethical use only. It should only be used for authorized security testing and educational purposes. The developers assume no liability and are not responsible for any misuse or damage caused by this program.
requirements.txt
git clone https://github.com/pentestmuse-ai/PentestMuse cd PentestMuse
pip install -r requirements.txt
Install Pentest Muse as a Python Package:
pip install .
In the chat mode, you can chat with pentest muse and ask it to help you brainstorm ideas, write payloads, and analyze code. Run the application with:
python run_app.py
or
pmuse
You can also give Pentest Muse more control by asking it to take actions for you with the agent mode. In this mode, Pentest Muse can help you finish a simple task (e.g., 'help me do sql injection test on url xxx'). To start the program with agent model, you can use:
python run_app.py agent
or
pmuse agent
You can use Pentest Muse with our managed APIs after signing up at www.pentestmuse.ai/signup. After creating an account, you can simply start the pentest muse cli, and the program will prompt you to login.
Alternatively, you can also choose to use your own OpenAI API keys. To do this, you can simply add argument --openai-api-key=[your openai api key] when starting the program.
For any feedback or suggestions regarding Pentest Muse, feel free to reach out to us at contact@pentestmuse.ai or join our discord. Your input is invaluable in helping us improve and evolve.
![]()
BloodHound is a monolithic web application composed of an embedded React frontend with Sigma.js and a Go based REST API backend. It is deployed with a Postgresql application database and a Neo4j graph database, and is fed by the SharpHound and AzureHound data collectors.
BloodHound uses graph theory to reveal the hidden and often unintended relationships within an Active Directory or Azure environment. Attackers can use BloodHound to easily identify highly complex attack paths that would otherwise be impossible to identify quickly. Defenders can use BloodHound to identify and eliminate those same attack paths. Both blue and red teams can use BloodHound to easily gain a deeper understanding of privilege relationships in an Active Directory or Azure environment.
BloodHound CE is created and maintained by the BloodHound Enterprise Team. The original BloodHound was created by @_wald0, @CptJesus, and @harmj0y.
The easiest way to get up and running is to use our pre-configured Docker Compose setup. The following steps will get BloodHound CE up and running with the least amount of effort.
curl -L https://ghst.ly/getbhce | docker compose -f - up
http://localhost:8080/ui/login. Login with a username of admin and the randomly generated password from the logsNOTE: going forward, the default docker-compose.yml example binds only to localhost (127.0.0.1). If you want to access BloodHound outside of localhost, you'll need to follow the instructions in examples/docker-compose/README.md to configure the host binding for the container.
![]()
# Verify if Docker Engine is Running
docker info
# Attempt to stop Neo4j Service if running (on Windows)
Stop-Service "Neo4j" -ErrorAction SilentlyContinue
https://github.com/SpecterOps/BloodHound/assets/12970156/ea9dc042-1866-4ccb-9839-933140cc38b9
Please check out the Contact page in our wiki for details on how to reach out with questions and suggestions.

gssapi-abuse was released as part of my DEF CON 31 talk. A full write up on the abuse vector can be found here: A Broken Marriage: Abusing Mixed Vendor Kerberos Stacks
The tool has two features. The first is the ability to enumerate non Windows hosts that are joined to Active Directory that offer GSSAPI authentication over SSH.
The second feature is the ability to perform dynamic DNS updates for GSSAPI abusable hosts that do not have the correct forward and/or reverse lookup DNS entries. GSSAPI based authentication is strict when it comes to matching service principals, therefore DNS entries should match the service principal name both by hostname and IP address.
gssapi-abuse requires a working krb5 stack along with a correctly configured krb5.conf.
On Windows hosts, the MIT Kerberos software should be installed in addition to the python modules listed in requirements.txt, this can be obtained at the MIT Kerberos Distribution Page. Windows krb5.conf can be found at C:\ProgramData\MIT\Kerberos5\krb5.conf
The libkrb5-dev package needs to be installed prior to installing python requirements
Once the requirements are satisfied, you can install the python dependencies via pip/pip3 tool
pip install -r requirements.txt
The enumeration mode will connect to Active Directory and perform an LDAP search for all computers that do not have the word Windows within the Operating System attribute.
Once the list of non Windows machines has been obtained, gssapi-abuse will then attempt to connect to each host over SSH and determine if GSSAPI based authentication is permitted.
python .\gssapi-abuse.py -d ad.ginge.com enum -u john.doe -p SuperSecret!
[=] Found 2 non Windows machines registered within AD
[!] Host ubuntu.ad.ginge.com does not have GSSAPI enabled over SSH, ignoring
[+] Host centos.ad.ginge.com has GSSAPI enabled over SSH
DNS mode utilises Kerberos and dnspython to perform an authenticated DNS update over port 53 using the DNS-TSIG protocol. Currently dns mode relies on a working krb5 configuration with a valid TGT or DNS service ticket targetting a specific domain controller, e.g. DNS/dc1.victim.local.
Adding a DNS A record for host ahost.ad.ginge.com
python .\gssapi-abuse.py -d ad.ginge.com dns -t ahost -a add --type A --data 192.168.128.50
[+] Successfully authenticated to DNS server win-af8ki8e5414.ad.ginge.com
[=] Adding A record for target ahost using data 192.168.128.50
[+] Applied 1 updates successfully
Adding a reverse PTR record for host ahost.ad.ginge.com. Notice that the data argument is terminated with a ., this is important or the record becomes a relative record to the zone, which we do not want. We also need to specify the target zone to update, since PTR records are stored in different zones to A records.
python .\gssapi-abuse.py -d ad.ginge.com dns --zone 128.168.192.in-addr.arpa -t 50 -a add --type PTR --data ahost.ad.ginge.com.
[+] Successfully authenticated to DNS server win-af8ki8e5414.ad.ginge.com
[=] Adding PTR record for target 50 using data ahost.ad.ginge.com.
[+] Applied 1 updates successfully
Forward and reverse DNS lookup results after execution
nslookup ahost.ad.ginge.com
Server: WIN-AF8KI8E5414.ad.ginge.com
Address: 192.168.128.1
Name: ahost.ad.ginge.com
Address: 192.168.128.50
nslookup 192.168.128.50
Server: WIN-AF8KI8E5414.ad.ginge.com
Address: 192.168.128.1
Name: ahost.ad.ginge.com
Address: 192.168.128.50
![]()
Pantheon is a GUI application that allows users to display information regarding network cameras in various countries as well as an integrated live-feed for non-protected cameras.
Pantheon allows users to execute an API crawler. There was original functionality without the use of any API's (like Insecam), but Google TOS kept getting in the way of the original scraping mechanism.
git clone https://github.com/josh0xA/Pantheon.gitcd Pantheonpip3 install -r requirements.txtpython3 pantheon.py
chmod +x distros/ubuntu_install.sh./distros/ubuntu_install.shchmod +x distros/debian-kali_install.sh./distros/debian-kali_install.sh(Enter) on a selected IP:Port to establish a Pantheon webview of the camera. (Use this at your own risk)
(Left-click) on a selected IP:Port to view the geolocation of the camera.
(Right-click) on a selected IP:Port to view the HTTP data of the camera (Ctrl+Left-click for Mac).
Adjust the map as you please to see the markers.
The developer of this program, Josh Schiavone, is not resposible for misuse of this data gathering tool. Pantheon simply provides information that can be indexed by any modern search engine. Do not try to establish unauthorized access to live feeds that are password protected - that is illegal. Furthermore, if you do choose to use Pantheon to view a live-feed, do so at your own risk. Pantheon was developed for educational purposes only. For further information, please visit: https://joshschiavone.com/panth_info/panth_ethical_notice.html
MIT License
Copyright (c) Josh Schiavone

APIDetector is a powerful and efficient tool designed for testing exposed Swagger endpoints in various subdomains with unique smart capabilities to detect false-positives. It's particularly useful for security professionals and developers who are engaged in API testing and vulnerability scanning.
Before running APIDetector, ensure you have Python 3.x and pip installed on your system. You can download Python here.
Clone the APIDetector repository to your local machine using:
git clone https://github.com/brinhosa/apidetector.git
cd apidetector
pip install requests Run APIDetector using the command line. Here are some usage examples:
Common usage, scan with 30 threads a list of subdomains using a Chrome user-agent and save the results in a file:
python apidetector.py -i list_of_company_subdomains.txt -o results_file.txt -t 30 -ua "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36"To scan a single domain:
python apidetector.py -d example.comTo scan multiple domains from a file:
python apidetector.py -i input_file.txtTo specify an output file:
python apidetector.py -i input_file.txt -o output_file.txtTo use a specific number of threads:
python apidetector.py -i input_file.txt -t 20To scan with both HTTP and HTTPS protocols:
python apidetector.py -m -d example.comTo run the script in quiet mode (suppress verbose output):
python apidetector.py -q -d example.comTo run the script with a custom user-agent:
python apidetector.py -d example.com -ua "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36"-d, --domain: Single domain to test.-i, --input: Input file containing subdomains to test.-o, --output: Output file to write valid URLs to.-t, --threads: Number of threads to use for scanning (default is 10).-m, --mixed-mode: Test both HTTP and HTTPS protocols.-q, --quiet: Disable verbose output (default mode is verbose).-ua, --user-agent: Custom User-Agent string for requests.Exposing Swagger or OpenAPI documentation endpoints can present various risks, primarily related to information disclosure. Here's an ordered list based on potential risk levels, with similar endpoints grouped together APIDetector scans:
'/swagger-ui.html', '/swagger-ui/', '/swagger-ui/index.html', '/api/swagger-ui.html', '/documentation/swagger-ui.html', '/swagger/index.html', '/api/docs', '/docs', '/api/swagger-ui', '/documentation/swagger-ui'
'/openapi.json', '/swagger.json', '/api/swagger.json', '/swagger.yaml', '/swagger.yml', '/api/swagger.yaml', '/api/swagger.yml', '/api.json', '/api.yaml', '/api.yml', '/documentation/swagger.json', '/documentation/swagger.yaml', '/documentation/swagger.yml'
'/v2/api-docs', '/v3/api-docs', '/api/v2/swagger.json', '/api/v3/swagger.json', '/api/v1/documentation', '/api/v2/documentation', '/api/v3/documentation', '/api/v1/api-docs', '/api/v2/api-docs', '/api/v3/api-docs', '/swagger/v2/api-docs', '/swagger/v3/api-docs', '/swagger-ui.html/v2/api-docs', '/swagger-ui.html/v3/api-docs', '/api/swagger/v2/api-docs', '/api/swagger/v3/api-docs'
'/swagger-resources', '/swagger-resources/configuration/ui', '/swagger-resources/configuration/security', '/api/swagger-resources', '/api.html'
Contributions to APIDetector are welcome! Feel free to fork the repository, make changes, and submit pull requests.
The use of APIDetector should be limited to testing and educational purposes only. The developers of APIDetector assume no liability and are not responsible for any misuse or damage caused by this tool. It is the end user's responsibility to obey all applicable local, state, and federal laws. Developers assume no responsibility for unauthorized or illegal use of this tool. Before using APIDetector, ensure you have permission to test the network or systems you intend to scan.
This project is licensed under the MIT License.

dynmx (spoken dynamics) is a signature-based detection approach for behavioural malware features based on Windows API call sequences. In a simplified way, you can think of dynmx as a sort of YARA for API call traces (so called function logs) originating from malware sandboxes. Hence, the data basis for the detection approach are not the malware samples themselves which are analyzed statically but data that is generated during a dynamic analysis of the malware sample in a malware sandbox. Currently, dynmx supports function logs of the following malware sandboxes:
report.json file)report.json file)The detection approach is described in detail in the master thesis Signature-Based Detection of Behavioural Malware Features with Windows API Calls. This project is the prototype implementation of this approach and was developed in the course of the master thesis. The signatures are manually defined by malware analysts in the dynmx signature DSL and can be detected in function logs with the help of this tool. Features and syntax of the dynmx signature DSL can also be found in the master thesis. Furthermore, you can find sample dynmx signatures in the repository dynmx-signatures. In addition to detecting malware features based on API calls, dynmx can extract OS resources that are used by the malware (a so called Access Activity Model). These resources are extracted by examining the API calls and reconstructing operations on OS resources. Currently, OS resources of the categories filesystem, registry and network are considered in the model.
In the following section, examples are shown for the detection of malware features and for the extraction of resources.
For this example, we choose the malware sample with the SHA-256 hash sum c0832b1008aa0fc828654f9762e37bda019080cbdd92bd2453a05cfb3b79abb3. According to MalwareBazaar, the sample belongs to the malware family Amadey. There is a public VMRay analysis report of this sample available which also provides the function log traced by VMRay. This function log will be our data basis which we will use for the detection.
If we would like to know if the malware sample uses an injection technique called Process Hollowing, we can try to detect the following dynmx signature in the function log.
dynmx_signature:
meta:
name: process_hollow
title: Process Hollowing
description: Detection of Process hollowing malware feature
detection:
proc_hollow:
# Create legit process in suspended mode
- api_call: ["CreateProcess[AW]", "CreateProcessInternal[AW]"]
with:
- argument: "dwCreationFlags"
operation: "flag is set"
value: 0x4
- return_value: "return"
operation: "is not"
value: 0
store:
- name: "hProcess"
as: "proc_handle"
- name: "hThread"
as: "thread_handle"
# Injection of malicious code into memory of previously created process
- variant:
- path:
# Allocate memory with read, write, execute permission
- api_call: ["VirtualAllocE x", "VirtualAlloc", "(Nt|Zw)AllocateVirtualMemory"]
with:
- argument: ["hProcess", "ProcessHandle"]
operation: "is"
value: "$(proc_handle)"
- argument: ["flProtect", "Protect"]
operation: "is"
value: 0x40
- api_call: ["WriteProcessMemory"]
with:
- argument: "hProcess"
operation: "is"
value: "$(proc_handle)"
- api_call: ["SetThreadContext", "(Nt|Zw)SetContextThread"]
with:
- argument: "hThread"
operation: "is"
value: "$(thread_handle)"
- path:
# Map memory section with read, write, execute permission
- api_call: "(Nt|Zw)MapViewOfSection"
with:
- argument: "ProcessHandle"
operation: "is"
value: "$(proc_handle)"
- argument: "AccessProtection"
operation: "is"
value: 0x40
# Resume thread to run injected malicious code
- api_call: ["ResumeThread", "(Nt|Zw)ResumeThread"]
with:
- argument: ["hThread", "ThreadHandle"]
operation: "is"
value: "$(thread_handle)"
condition: proc_hollow as sequenceBased on the signature, we can find some DSL features that make dynmx powerful:
AND, OR, NOT)If we run dynmx with the signature shown above against the function of the sample c0832b1008aa0fc828654f9762e37bda019080cbdd92bd2453a05cfb3b79abb3, we get the following output indicating that the signature was detected.
$ python3 dynmx.py detect -i 601941f00b194587c9e57c5fabaf1ef11596179bea007df9bdcdaa10f162cac9.json -s process_hollow.yml
|
__| _ _ _ _ _
/ | | | / |/ | / |/ |/ | /\/
\_/|_/ \_/|/ | |_/ | | |_/ /\_/
/|
\|
Ver. 0.5 (PoC), by 0x534a
[+] Parsing 1 function log(s)
[+] Loaded 1 dynmx signature(s)
[+] Starting detection process with 1 worker(s). This probably takes some time...
[+] Result
process_hollow c0832b1008aa0fc828654f9762e37bda019080cbdd92bd2453a05cfb3b79abb3.txt
We can get into more detail by setting the output format to detail. Now, we can see the exact API call sequence that was detected in the function log. Furthermore, we can see that the signature was detected in the process 51f0.exe.
$ python3 dynmx.py -f detail detect -i 601941f00b194587c9e57c5fabaf1ef11596179bea007df9bdcdaa10f162cac9.json -s process_hollow.yml
|
__| _ _ _ _ _
/ | | | / |/ | / |/ |/ | /\/
\_/|_/ \_/|/ | |_/ | | |_/ /\_/
/|
\|
Ver. 0.5 (PoC), by 0x534a
[+] Parsing 1 function log(s)
[+] Loaded 1 dynmx signature(s)
[+] Starting detection process with 1 worker(s). This probably takes some time...
[+] Result
Function log: c0832b1008aa0fc828654f9762e37bda019080cbdd92bd2453a05cfb3b79abb3.txt
Signature: process_hollow
Process: 51f0.exe (PID: 3768)
Number of Findings: 1
Finding 0
proc_hollow : API Call CreateProcessA (Function log line 20560, index 938)
proc_hollow : API Call VirtualAllocEx (Function log line 20566, index 944)
proc_hollow : API Call WriteProcessMemory (Function log line 20573, index 951)
proc_hollow : API Call SetThreadContext (Function log line 20574, index 952)
proc_hollow : API Call ResumeThread (Function log line 20575, index 953)
In order to extract the accessed OS resources from a function log, we can simply run the dynmx command resources against the function log. An example of the detailed output is shown below for the sample with the SHA-256 hash sum 601941f00b194587c9e57c5fabaf1ef11596179bea007df9bdcdaa10f162cac9. This is a CAPE sandbox report which is part of the Avast-CTU Public CAPEv2 Dataset.
$ python3 dynmx.py -f detail resources --input 601941f00b194587c9e57c5fabaf1ef11596179bea007df9bdcdaa10f162cac9.json
|
__| _ _ _ _ _
/ | | | / |/ | / |/ |/ | /\/
\_/|_/ \_/|/ | |_/ | | |_/ /\_/
/|
\|
Ver. 0.5 (PoC), by 0x534a
[+] Parsing 1 function log(s)
[+] Processing function log(s) with the command 'resources'...
[+] Result
Function log: 601941f00b194587c9e57c5fabaf1ef11596179bea007df9bdcdaa10f162cac9.json (/Users/sijansen/Documents/dev/dynmx_flogs/cape/Public_Avast_CTU_CAPEv2_Dataset_Full/extracted/601941f00b194587c9e57c5fabaf1ef11596179bea007df9bdcdaa10f162cac9.json)
Process: 601941F00B194587C9E5.exe (PID: 2008)
Filesystem:
C:\Windows\SysWOW64\en-US\SETUPAPI.dll.mui (CREATE)
API-MS-Win-Core-LocalRegistry-L1-1-0.dll (EXECUTE)
C:\Windows\SysWOW64\ntdll.dll (READ)
USER32.dll (EXECUTE)
KERNEL32. dll (EXECUTE)
C:\Windows\Globalization\Sorting\sortdefault.nls (CREATE)
Registry:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\OLEAUT (READ)
HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\Setup (READ)
HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\Setup\SourcePath (READ)
HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion (READ)
HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\DevicePath (READ)
HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\Internet Settings (READ)
HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\Internet Settings\DisableImprovedZoneCheck (READ)
HKEY_LOCAL_MACHINE\Software\Policies\Microsoft\Windows\CurrentVersion\Internet Settings (READ)
HKEY_LOCAL_MACHINE\Software\Policies\Microsoft\Windows\CurrentVersion\Internet Settings\Security_HKLM_only (READ)
Process: 601941F00B194587C9E5.exe (PID: 1800)
Filesystem:
C:\Windows\SysWOW64\en-US\SETUPAPI.dll.mui (CREATE)
API-MS-Win-Core-LocalRegistry-L1-1-0.dll (EXECUTE)
C:\Windows\SysWOW64\ntdll.dll (READ)
USER32.dll (EXECUTE)
KERNEL32.dll (EXECUTE)
[...]
C:\Users\comp\AppData\Local\vscmouse (READ)
C:\Users\comp\AppData\Local\vscmouse\vscmouse.exe:Zone.Identifier (DELETE)
Registry:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\OLEAUT (READ)
HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\Setup (READ)
[...]
Process: vscmouse.exe (PID: 900)
Filesystem:
C:\Windows\SysWOW64\en-US\SETUPAPI.dll.mui (CREATE)
API-MS-Win-Core-LocalRegistry-L1-1-0.dll (EXECUTE)
C:\Windows\SysWOW64\ntdll.dll (READ)
USER32.dll (EXECUTE)
KERNEL32.dll (EXECUTE)
C:\Windows\Globalization\Sorting\sortdefault.nls (CREATE)
Registry:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\OLEAUT (READ)
HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\C urrentVersion\Setup (READ)
HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\Setup\SourcePath (READ)
HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion (READ)
HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\DevicePath (READ)
HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\Internet Settings (READ)
HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\Internet Settings\DisableImprovedZoneCheck (READ)
HKEY_LOCAL_MACHINE\Software\Policies\Microsoft\Windows\CurrentVersion\Internet Settings (READ)
HKEY_LOCAL_MACHINE\Software\Policies\Microsoft\Windows\CurrentVersion\Internet Settings\Security_HKLM_only (READ)
Process: vscmouse.exe (PID: 3036)
Filesystem:
C:\Windows\SysWOW64\en-US\SETUPAPI.dll.mui (CREATE)
API-MS-Win-Core-LocalRegistry-L1-1-0.dll (EXECUTE)
C:\Windows\SysWOW64\ntdll.dll (READ)
USER32.dll (EXECUTE)
KERNEL32.dll (EXECUTE)
C:\Windows\Globalization\Sorting\sortdefault.nls (CREATE)
C:\ (READ)
C:\Windows\System32\uxtheme.dll (EXECUTE)
dwmapi.dll (EXECUTE)
advapi32.dll (EXECUTE)
shell32.dll (EXECUTE)
C:\Users\comp\AppData\Local\vscmouse\vscmouse.exe (CREATE,READ)
C:\Users\comp\AppData\Local\iproppass\iproppass.exe (DELETE)
crypt32.dll (EXECUTE)
urlmon.dll (EXECUTE)
userenv.dll (EXECUTE)
wininet.dll (EXECUTE)
wtsapi32.dll (EXECUTE)
CRYPTSP.dll (EXECUTE)
CRYPTBASE.dll (EXECUTE)
ole32.dll (EXECUTE)
OLEAUT32.dll (EXECUTE)
C:\Windows\SysWOW64\oleaut32.dll (EXECUTE)
IPHLPAPI.DLL (EXECUTE)
DHCPCSVC.DLL (EXECUTE)
C:\Users\comp\AppData\Roaming\Microsoft\Network\Connections\Pbk\_hiddenPbk\ (CREATE)
C:\Users\comp\AppData\Roaming\Microsoft\Network\Connections\Pbk\_hiddenPbk\rasphone.pbk (CREATE,READ)
Registry:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\OLEAUT (READ )
HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\Setup (READ)
[...]
Network:
24.151.31.150:465 (READ)
http://24.151.31.150:465 (READ,WRITE)
107.10.49.252:80 (READ)
http://107.10.49.252:80 (READ,WRITE)
Based on the shown output and the accessed resources, we can deduce some malware features:
601941F00B194587C9E5.exe (PID 1800), the Zone Identifier of the file C:\Users\comp\AppData\Local\vscmouse\vscmouse.exe is deletedvscmouse.exe (PID: 3036) connects to the network endpoints http://24.151.31.150:465 and http://107.10.49.252:80
The accessed resources are interesting for identifying host- and network-based detection indicators. In addition, resources can be used in dynmx signatures. A popular example is the detection of persistence mechanisms in the Registry.
In order to use the software Python 3.9 must be available on the target system. In addition, the following Python packages need to be installed:
anytree,lxml,pyparsing,PyYAML,six andstringcaseTo install the packages run the pip3 command shown below. It is recommended to use a Python virtual environment instead of installing the packages system-wide.
pip3 install -r requirements.txt
To use the prototype, simply run the main entry point dynmx.py. The usage information can be viewed with the -h command line parameter as shown below.
$ python3 dynmx.py -h
usage: dynmx.py [-h] [--format {overview,detail}] [--show-log] [--log LOG] [--log-level {debug,info,error}] [--worker N] {detect,check,convert,stats,resources} ...
Detect dynmx signatures in dynamic program execution information (function logs)
optional arguments:
-h, --help show this help message and exit
--format {overview,detail}, -f {overview,detail}
Output format
--show-log Show all log output on stdout
--log LOG, -l LOG log file
--log-level {debug,info,error}
Log level (default: info)
--worker N, -w N Number of workers to spawn (default: number of processors - 2)
sub-commands:
task to perform
{detect,check,convert,stats,resources}
detect Detects a dynmx signature
check Checks the syntax of dynmx signature(s)
convert Converts function logs to the dynmx generic function log format
stats Statistics of function logs
resources Resource activity derived from function log
In general, as shown in the output, several command line parameters regarding the log handling, the output format for results or multiprocessing can be defined. Furthermore, a command needs be chosen to run a specific task. Please note, that the number of workers only affects commands that make use of multiprocessing. Currently, these are the commands detect and convert.
The commands have specific command line parameters that can be explored by giving the parameter -h to the command, e.g. for the detect command as shown below.
$ python3 dynmx.py detect -h
usage: dynmx.py detect [-h] --sig SIG [SIG ...] --input INPUT [INPUT ...] [--recursive] [--json-result JSON_RESULT] [--runtime-result RUNTIME_RESULT] [--detect-all]
optional arguments:
-h, --help show this help message and exit
--recursive, -r Search for input files recursively
--json-result JSON_RESULT
JSON formatted result file
--runtime-result RUNTIME_RESULT
Runtime statistics file formatted in CSV
--detect-all Detect signature in all processes and do not stop after the first detection
required arguments:
--sig SIG [SIG ...], -s SIG [SIG ...]
dynmx signature(s) to detect
--input INPUT [INPUT ...], -i INPUT [INPUT ...]
Input files
As a user of dynmx, you can decide how the output is structured. If you choose to show the log on the console by defining the parameter --show-log, the output consists of two sections (see listing below). The log is shown first and afterwards the results of the used command. By default, the log is neither shown in the console nor written to a log file (which can be defined using the --log parameter). Due to multiprocessing, the entries in the log file are not necessarily in chronological order.
|
__| _ _ _ _ _
/ | | | / |/ | / |/ |/ | /\/
\_/|_/ \_/|/ | |_/ | | |_/ /\_/
/|
\|
Ver. 0.5 (PoC), by 0x534a
[+] Log output
2023-06-27 19:07:38,068+0000 [INFO] (__main__) [PID: 13315] []: Start of dynmx run
[...]
[+] End of log output
[+] Result
[...]
The level of detail of the result output can be defined using the command line parameter --output-format which can be set to overview for a high-level result or to detail for a detailed result. For example, if you define the output format to detail, detection results shown in the console will contain the exact API calls and resources that caused the detection. The overview output format will just indicate what signature was detected in which function log.
Detection of a dynmx signature in a function log with one worker process
python3 dynmx.py -w 1 detect -i "flog.txt" -s dynmx_signature.yml
Conversion of a function log to the dynmx generic function log format
python3 dynmx.py convert -i "flog.txt" -o /tmp/
Check a signature (only basic sanity checks)
python3 dynmx.py check -s dynmx_signature.yml
Get a detailed list of used resources used by a malware sample based on the function log (access activity model)
python3 dynmx.py -f detail resources -i "flog.txt"
Please consider that this tool is a proof-of-concept which was developed besides writing the master thesis. Hence, the code quality is not always the best and there may be bugs and errors. I tried to make the tool as robust as possible in the given time frame.
The best way to troubleshoot errors is to enable logging (on the console and/or to a log file) and set the log level to debug. Exception handlers should write detailed errors to the log which can help troubleshooting.
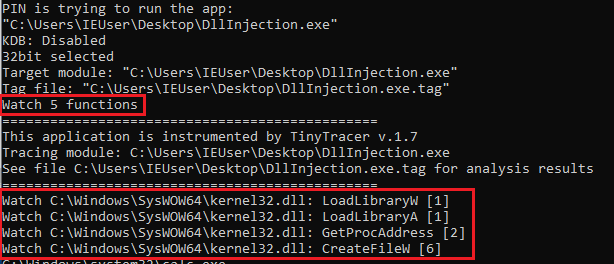
A Pin Tool for tracing:
Bypasses the anti-tracing check based on RDTSC.
Generates a report in a .tag format (which can be loaded into other analysis tools):
RVA;traced eventi.e.
345c2;section: .text
58069;called: C:\Windows\SysWOW64\kernel32.dll.IsProcessorFeaturePresent
3976d;called: C:\Windows\SysWOW64\kernel32.dll.LoadLibraryExW
3983c;called: C:\Windows\SysWOW64\kernel32.dll.GetProcAddress
3999d;called: C:\Windows\SysWOW64\KernelBase.dll.InitializeCriticalSectionEx
398ac;called: C:\Windows\SysWOW64\KernelBase.dll.FlsAlloc
3995d;called: C:\Windows\SysWOW64\KernelBase.dll.FlsSetValue
49275;called: C:\Windows\SysWOW64\kernel32.dll.LoadLibraryExW
4934b;called: C:\Windows\SysWOW64\kernel32.dll.GetProcAddress
...To compile the prepared project you need to use Visual Studio >= 2012. It was tested with Intel Pin 3.28.
Clone this repo into \source\tools that is inside your Pin root directory. Open the project in Visual Studio and build. Detailed description available here.
To build with Intel Pin < 3.26 on Windows, use the appropriate legacy Visual Studio project.
For now the support for Linux is experimental. Yet it is possible to build and use Tiny Tracer on Linux as well. Please refer tiny_runner.sh for more information. Detailed description available here.
Details about the usage you will find on the project's Wiki.
install32_64 you can find a utility that checks if Kernel Debugger is disabled (kdb_check.exe, source), and it is used by the Tiny Tracer's .bat scripts. This utilty sometimes gets flagged as a malware by Windows Defender (it is a known false positive). If you encounter this issue, you may need to exclude the installation directory from Windows Defender scans.Questions? Ideas? Join Discussions!
![]()
| Language | Framework | URL | Method | Param | Header | WS |
|---|---|---|---|---|---|---|
| Go | Echo | ✅ | ✅ | X | X | X |
| Python | Django | ✅ | X | X | X | X |
| Python | Flask | ✅ | X | X | X | X |
| Ruby | Rails | ✅ | ✅ | ✅ | X | X |
| Ruby | Sinatra | ✅ | ✅ | ✅ | X | X |
| Php | ✅ | ✅ | ✅ | X | X | |
| Java | Spring | ✅ | ✅ | X | X | X |
| Java | Jsp | X | X | X | X | X |
| Crystal | Kemal | ✅ | ✅ | ✅ | X | ✅ |
| JS | Express | ✅ | ✅ | X | X | X |
| JS | Next | X | X | X | X | X |
| Specification | Format | URL | Method | Param | Header | WS |
|---|---|---|---|---|---|---|
| Swagger | JSON | ✅ | ✅ | ✅ | X | X |
| Swagger | YAML | ✅ | ✅ | ✅ | X | X |
brew tap hahwul/noir
brew install noir# Install Crystal-lang
# https://crystal-lang.org/install/
# Clone this repo
git clone https://github.com/hahwul/noir
cd noir
# Install Dependencies
shards install
# Build
shards build --release --no-debug
# Copy binary
cp ./bin/noir /usr/bin/docker pull ghcr.io/hahwul/noir:mainUsage: noir <flags>
Basic:
-b PATH, --base-path ./app (Required) Set base path
-u URL, --url http://.. Set base url for endpoints
-s SCOPE, --scope url,param Set scope for detection
Output:
-f FORMAT, --format json Set output format [plain/json/markdown-table/curl/httpie]
-o PATH, --output out.txt Write result to file
--set-pvalue VALUE Specifies the value of the identified parameter
--no-color Disable color output
--no-log Displaying only the results
Deliver:
--send-req Send the results to the web request
--send-proxy http://proxy.. Send the results to the web request via http proxy
Technologies:
-t TECHS, --techs rails,php Set technologies to use
--exclude-techs rails,php Specify the technologies to be excluded
--list-techs Show all technologies
Others:
-d, --debug Show debug messages
-v, --version Show version
-h, --help Show help
Example
noir -b . -u https://testapp.internal.domainsJSON Result
noir -b . -u https://testapp.internal.domains -f json
[
...
{
"headers": [],
"method": "POST",
"params": [
{
"name": "article_slug",
"param_type": "json",
"value": ""
},
{
"name": "body",
"param_type": "json",
"value": ""
},
{
"name": "id",
"param_type": "json",
"value": ""
}
],
"protocol": "http",
"url": "https://testapp.internal.domains/comments"
}
]
Toolkit demonstrating another approach of a QRLJacking attack, allowing to perform remote account takeover, through sign-in QR code phishing.
It consists of a browser extension used by the attacker to extract the sign-in QR code and a server application, which retrieves the sign-in QR codes to display them on the hosted phishing pages.
Watch the demo video:
Read more about it on my blog: https://breakdev.org/evilqr-phishing
The parameters used by Evil QR are hardcoded into extension and server source code, so it is important to change them to use custom values, before you build and deploy the toolkit.
| parameter | description | default value |
|---|---|---|
| API_TOKEN | API token used to authenticate with REST API endpoints hosted on the server | 00000000-0000-0000-0000-000000000000 |
| QRCODE_ID | QR code ID used to bind the extracted QR code with the one displayed on the phishing page | 11111111-1111-1111-1111-111111111111 |
| BIND_ADDRESS | IP address with port the HTTP server will be listening on | 127.0.0.1:35000 |
| API_URL | External URL pointing to the server, where the phishing page will be hosted | http://127.0.0.1:35000 |
Here are all the places in the source code, where the values should be modified:
You can load the extension in Chrome, through Load unpacked feature: https://developer.chrome.com/docs/extensions/mv3/getstarted/development-basics/#load-unpacked
Once the extension is installed, make sure to pin its icon in Chrome's extension toolbar, so that the icon is always visible.
Make sure you have Go installed version at least 1.20.
To build go to /server directory and run the command:
Windows:
build_run.bat
Linux:
chmod 700 build.sh
./build.sh
Built server binaries will be placed in the ./build/ directory.
./server/build/evilqr-server
https://discord.com/login
https://web.telegram.org/k/
https://whatsapp.com
https://store.steampowered.com/login/
https://accounts.binance.com/en/login
https://www.tiktok.com/login
http://127.0.0.1:35000 (default)Evil QR is made by Kuba Gretzky (@mrgretzky) and it's released under MIT license.
![]()
AiCEF is a tool implementing the accompanying framework [1] in order to harness the intelligence that is available from online resources, as well as threat groups' activities, arsenal (eg. MITRE), to create relevant and timely cybersecurity exercise content. This way, we abstract the events from the reports in a machine-readable form. The produced graphs can be infused with additional intelligence, e.g. the threat actor profile from MITRE, also mapped in our ontology. While this may fill gaps that would be missing from a report, one can also manipulate the graph to create custom and unique models. Finally, we exploit transformer-based language models like GPT to convert the graph into text that can serve as the scenario of a cybersecurity exercise. We have tested and validated AiCEF with a group of experts in cybersecurity exercises, and the results clearly show that AiCEF significantly augments the capabilities in creating timely and relevant cybersecurity exercises in terms of both quality and time.
We used Python to create a machine-learning-powered Exercise Generation Framework and developed a set of tools to perform a set of individual tasks which would help an exercise planner (EP) to create a timely and targeted Cybersecurity Exercise Scenario, regardless of her experience.
Problems an Exercise Planner faces:
Our Main Objective: Build an AI powered tool that can generate relevant and up-to-date Cyber Exercise Content in a few steps with little technical expertise from the user.
The updated project, AiCEF v.2.0 is planned to be publicly released by the end of 2023, pending heavy code review and functionality updates. Submodules with reduced functinality will start being release by early June 2023. Thank you for your patience.
The most convenient way to install AiCEF is by using the docker-compose command. For production deployment, we advise you deploy MySQL manually in a dedicated environment and then to start the other components using Docker.
First, make sure you have docker-compose installed in your environment:
$ sudo apt-get install docker-composeThen, clone the repository:
$ git clone https://github.com/grazvan/AiCEF/docker.git /<choose-a-path>/AiCEF-docker
$ cd /<choose-a-path>/AiCEF-dockerImport the MySQL file in your
$ mysql -u <your_username> –-password=<your_password> AiCEF_db < AiCEF_db.sql Before running the docker-compose command, settings must be configured. Copy the sample settings file and change it accordingly to your needs.
$ cp .env.sample .envNote: Make sure you have an OpenAI API key available. Load the environment setttings (including your MySQL connection details):
set -a ; source .envFinally, run docker-compose in detached (-d) mode:
$ sudo docker-compose up -dA common usage flow consists of generating a Trend Report to analyze patterns over time, parsing relevant articles and converting them into Incident Breadcrumbs using MLTP module and storing them in a knowledge database called KDb. Incidents are then generated using IncGen component and can be enhanced using the Graph Enhancer module to simulate known APT activity. The incidents come with injects that can be edited on the fly. The CSE scenario is then created using CEGen, which defines various attributes like CSE name, number of Events, and Incidents. MLCESO is a crucial step in the methodology where dedicated ML models are trained to extract information from the collected articles with over 80% accuracy. The Incident Generation & Enhancer (IncGen) workflow can be automated, generating a variety of incidents based on filtering parameters and the existing database. The knowledge database (KDB) consists of almost 3000 articles classified into six categories that can be augmented using APT Enhancer by using the activity of known APT groups from MITRE or manually.
Find below some sample usage screenshots: ![]()
AiCEF is a product designed and developed by Alex Zacharis, Razvan Gavrila and Constantinos Patsakis.
[1] https://link.springer.com/article/10.1007/s10207-023-00693-z
[2] https://oasis-open.github.io/cti-documentation/stix/intro.html
Contributions are welcome! If you'd like to contribute to AiCEF v2.0, please follow these steps:
git checkout -b feature/your-branch-name)git commit -m 'Add some feature')git push origin feature/your-branch-name)AiCEF is licensed under Attribution-NonCommercial 4.0 International (CC BY-NC 4.0) license. See for more information.
Under the following terms:
Attribution — You must give appropriate credit, provide a link to the license, and indicate if changes were made. You may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use. NonCommercial — You may not use the material for commercial purposes. No additional restrictions — You may not apply legal terms or technological measures that legally restrict others from doing anything the license permits.
![]()
The VX-API is a collection of malicious functionality to aid in malware development. It is recommended you clone and/or download this entire repo then open the Visual Studio solution file to easily explore functionality and concepts.
Some functions may be dependent on other functions present within the solution file. Using the solution file provided here will make it easier to identify which other functionality and/or header data is required.
You're free to use this in any manner you please. You do not need to use this entire solution for your malware proof-of-concepts or Red Team engagements. Strip, copy, paste, delete, or edit this projects contents as much as you'd like.
| Function Name | Original Author |
|---|---|
| AdfCloseHandleOnInvalidAddress | Checkpoint Research |
| AdfIsCreateProcessDebugEventCodeSet | Checkpoint Research |
| AdfOpenProcessOnCsrss | Checkpoint Research |
| CheckRemoteDebuggerPresent2 | ReactOS |
| IsDebuggerPresentEx | smelly__vx |
| IsIntelHardwareBreakpointPresent | Checkpoint Research |
| Function Name | Original Author |
|---|---|
| HashStringDjb2 | Dan Bernstein |
| HashStringFowlerNollVoVariant1a | Glenn Fowler, Landon Curt Noll, and Kiem-Phong Vo |
| HashStringJenkinsOneAtATime32Bit | Bob Jenkins |
| HashStringLoseLose | Brian Kernighan and Dennis Ritchie |
| HashStringRotr32 | T. Oshiba (1972) |
| HashStringSdbm | Ozan Yigit |
| HashStringSuperFastHash | Paul Hsieh |
| HashStringUnknownGenericHash1A | Unknown |
| HashStringSipHash | RistBS |
| HashStringMurmur | RistBS |
| CreateMd5HashFromFilePath | Microsoft |
| CreatePseudoRandomInteger | Apple (c) 1999 |
| CreatePseudoRandomString | smelly__vx |
| HashFileByMsiFileHashTable | smelly__vx |
| CreatePseudoRandomIntegerFromNtdll | smelly__vx |
| LzMaximumCompressBuffer | smelly__vx |
| LzMaximumDecompressBuffer | smelly__vx |
| LzStandardCompressBuffer | smelly__vx |
| LzStandardDecompressBuffer | smelly__vx |
| XpressHuffMaximumCompressBuffer | smelly__vx |
| XpressHuffMaximumDecompressBuffer | smelly__vx |
| XpressHuffStandardCompressBuffer | smelly__vx |
| XpressHuffStandardDecompressBuffer | smelly__vx |
| XpressMaximumCompressBuffer | smelly__vx |
| XpressMaximumDecompressBuffer | smelly__vx |
| XpressStandardCompressBuffer | smelly__vx |
| XpressStandardDecompressBuffer | smelly__vx |
| ExtractFilesFromCabIntoTarget | smelly__vx |
| Function Name | Original Author |
|---|---|
| GetLastErrorFromTeb | smelly__vx |
| GetLastNtStatusFromTeb | smelly__vx |
| RtlNtStatusToDosErrorViaImport | ReactOS |
| GetLastErrorFromTeb | smelly__vx |
| SetLastErrorInTeb | smelly__vx |
| SetLastNtStatusInTeb | smelly__vx |
| Win32FromHResult | Raymond Chen |
| Function Name | Original Author |
|---|---|
| AmsiBypassViaPatternScan | ZeroMemoryEx |
| DelayedExecutionExecuteOnDisplayOff | am0nsec and smelly__vx |
| HookEngineRestoreHeapFree | rad9800 |
| MasqueradePebAsExplorer | smelly__vx |
| RemoveDllFromPeb | rad9800 |
| RemoveRegisterDllNotification | Rad98, Peter Winter-Smith |
| SleepObfuscationViaVirtualProtect | 5pider |
| RtlSetBaseUnicodeCommandLine | TheWover |
| Function Name | Original Author |
|---|---|
| GetCurrentLocaleFromTeb | 3xp0rt |
| GetNumberOfLinkedDlls | smelly__vx |
| GetOsBuildNumberFromPeb | smelly__vx |
| GetOsMajorVersionFromPeb | smelly__vx |
| GetOsMinorVersionFromPeb | smelly__vx |
| GetOsPlatformIdFromPeb | smelly__vx |
| IsNvidiaGraphicsCardPresent | smelly__vx |
| IsProcessRunning | smelly__vx |
| IsProcessRunningAsAdmin | Vimal Shekar |
| GetPidFromNtQuerySystemInformation | smelly__vx |
| GetPidFromWindowsTerminalService | modexp |
| GetPidFromWmiComInterface | aalimian and modexp |
| GetPidFromEnumProcesses | smelly__vx |
| GetPidFromPidBruteForcing | modexp |
| GetPidFromNtQueryFileInformation | modexp, Lloyd Davies, Jonas Lyk |
| GetPidFromPidBruteForcingExW | smelly__vx, LLoyd Davies, Jonas Lyk, modexp |
| Function Name | Original Author |
|---|---|
| CreateLocalAppDataObjectPath | smelly__vx |
| CreateWindowsObjectPath | smelly__vx |
| GetCurrentDirectoryFromUserProcessParameters | smelly__vx |
| GetCurrentProcessIdFromTeb | ReactOS |
| GetCurrentUserSid | Giovanni Dicanio |
| GetCurrentWindowTextFromUserProcessParameter | smelly__vx |
| GetFileSizeFromPath | smelly__vx |
| GetProcessHeapFromTeb | smelly__vx |
| GetProcessPathFromLoaderLoadModule | smelly__vx |
| GetProcessPathFromUserProcessParameters | smelly__vx |
| GetSystemWindowsDirectory | Geoff Chappell |
| IsPathValid | smelly__vx |
| RecursiveFindFile | Luke |
| SetProcessPrivilegeToken | Microsoft |
| IsDllLoaded | smelly__vx |
| TryLoadDllMultiMethod | smelly__vx |
| CreateThreadAndWaitForCompletion | smelly__vx |
| GetProcessBinaryNameFromHwndW | smelly__vx |
| GetByteArrayFromFile | smelly__vx |
| Ex_GetHandleOnDeviceHttpCommunication | x86matthew |
| IsRegistryKeyValid | smelly__vx |
| FastcallExecuteBinaryShellExecuteEx | smelly__vx |
| GetCurrentProcessIdFromOffset | RistBS |
| GetPeBaseAddress | smelly__vx |
| LdrLoadGetProcedureAddress | c5pider |
| IsPeSection | smelly__vx |
| AddSectionToPeFile | smelly__vx |
| WriteDataToPeSection | smelly__vx |
| GetPeSectionSizeInByte | smelly__vx |
| ReadDataFromPeSection | smelly__vx |
| GetCurrentProcessNoForward | ReactOS |
| GetCurrentThreadNoForward | ReactOS |
| Function Name | Original Author |
|---|---|
| GetKUserSharedData | Geoff Chappell |
| GetModuleHandleEx2 | smelly__vx |
| GetPeb | 29a |
| GetPebFromTeb | ReactOS |
| GetProcAddress | 29a Volume 2, c5pider |
| GetProcAddressDjb2 | smelly__vx |
| GetProcAddressFowlerNollVoVariant1a | smelly__vx |
| GetProcAddressJenkinsOneAtATime32Bit | smelly__vx |
| GetProcAddressLoseLose | smelly__vx |
| GetProcAddressRotr32 | smelly__vx |
| GetProcAddressSdbm | smelly__vx |
| GetProcAddressSuperFastHash | smelly__vx |
| GetProcAddressUnknownGenericHash1 | smelly__vx |
| GetProcAddressSipHash | RistBS |
| GetProcAddressMurmur | RistBS |
| GetRtlUserProcessParameters | ReactOS |
| GetTeb | ReactOS |
| RtlLoadPeHeaders | smelly__vx |
| ProxyWorkItemLoadLibrary | Rad98, Peter Winter-Smith |
| ProxyRegisterWaitLoadLibrary | Rad98, Peter Winter-Smith |
| Function Name | Original Author |
|---|---|
| MpfGetLsaPidFromServiceManager | modexp |
| MpfGetLsaPidFromRegistry | modexp |
| MpfGetLsaPidFromNamedPipe | modexp |
| Function Name | Original Author |
|---|---|
| UrlDownloadToFileSynchronous | Hans Passant |
| ConvertIPv4IpAddressStructureToString | smelly__vx |
| ConvertIPv4StringToUnsignedLong | smelly__vx |
| SendIcmpEchoMessageToIPv4Host | smelly__vx |
| ConvertIPv4IpAddressUnsignedLongToString | smelly__vx |
| DnsGetDomainNameIPv4AddressAsString | smelly__vx |
| DnsGetDomainNameIPv4AddressUnsignedLong | smelly__vx |
| GetDomainNameFromUnsignedLongIPV4Address | smelly__vx |
| GetDomainNameFromIPV4AddressAsString | smelly__vx |
| Function Name | Original Author |
|---|---|
| OleGetClipboardData | Microsoft |
| MpfComVssDeleteShadowVolumeBackups | am0nsec |
| MpfComModifyShortcutTarget | Unknown |
| MpfComMonitorChromeSessionOnce | smelly__vx |
| MpfExtractMaliciousPayloadFromZipFileNoPassword | Codu |
| Function Name | Original Author |
|---|---|
| CreateProcessFromIHxHelpPaneServer | James Forshaw |
| CreateProcessFromIHxInteractiveUser | James Forshaw |
| CreateProcessFromIShellDispatchInvoke | Mohamed Fakroud |
| CreateProcessFromShellExecuteInExplorerProcess | Microsoft |
| CreateProcessViaNtCreateUserProcess | CaptMeelo |
| CreateProcessWithCfGuard | smelly__vx and Adam Chester |
| CreateProcessByWindowsRHotKey | smelly__vx |
| CreateProcessByWindowsRHotKeyEx | smelly__vx |
| CreateProcessFromINFSectionInstallStringNoCab | smelly__vx |
| CreateProcessFromINFSetupCommand | smelly__vx |
| CreateProcessFromINFSectionInstallStringNoCab2 | smelly__vx |
| CreateProcessFromIeFrameOpenUrl | smelly__vx |
| CreateProcessFromPcwUtil | smelly__vx |
| CreateProcessFromShdocVwOpenUrl | smelly__vx |
| CreateProcessFromShell32ShellExecRun | smelly__vx |
| MpfExecute64bitPeBinaryInMemoryFromByteArrayNoReloc | aaaddress1 |
| CreateProcessFromWmiWin32_ProcessW | CIA |
| CreateProcessFromZipfldrRouteCall | smelly__vx |
| CreateProcessFromUrlFileProtocolHandler | smelly__vx |
| CreateProcessFromUrlOpenUrl | smelly__vx |
| CreateProcessFromMsHTMLW | smelly__vx |
| Function Name | Original Author |
|---|---|
| MpfPiControlInjection | SafeBreach Labs |
| MpfPiQueueUserAPCViaAtomBomb | SafeBreach Labs |
| MpfPiWriteProcessMemoryCreateRemoteThread | SafeBreach Labs |
| MpfProcessInjectionViaProcessReflection | Deep Instinct |
| Function Name | Original Author |
|---|---|
| IeCreateFile | smelly__vx |
| CopyFileViaSetupCopyFile | smelly__vx |
| CreateFileFromDsCopyFromSharedFile | Jonas Lyk |
| DeleteDirectoryAndSubDataViaDelNode | smelly__vx |
| DeleteFileWithCreateFileFlag | smelly__vx |
| IsProcessRunningAsAdmin2 | smelly__vx |
| IeCreateDirectory | smelly__vx |
| IeDeleteFile | smelly__vx |
| IeFindFirstFile | smelly__vx |
| IEGetFileAttributesEx | smelly__vx |
| IeMoveFileEx | smelly__vx |
| IeRemoveDirectory | smelly__vx |
| Function Name | Original Author |
|---|---|
| MpfSceViaImmEnumInputContext | alfarom256, aahmad097 |
| MpfSceViaCertFindChainInStore | alfarom256, aahmad097 |
| MpfSceViaEnumPropsExW | alfarom256, aahmad097 |
| MpfSceViaCreateThreadpoolWait | alfarom256, aahmad097 |
| MpfSceViaCryptEnumOIDInfo | alfarom256, aahmad097 |
| MpfSceViaDSA_EnumCallback | alfarom256, aahmad097 |
| MpfSceViaCreateTimerQueueTimer | alfarom256, aahmad097 |
| MpfSceViaEvtSubscribe | alfarom256, aahmad097 |
| MpfSceViaFlsAlloc | alfarom256, aahmad097 |
| MpfSceViaInitOnceExecuteOnce | alfarom256, aahmad097 |
| MpfSceViaEnumChildWindows | alfarom256, aahmad097, wra7h |
| MpfSceViaCDefFolderMenu_Create2 | alfarom256, aahmad097, wra7h |
| MpfSceViaCertEnumSystemStore | alfarom256, aahmad097, wra7h |
| MpfSceViaCertEnumSystemStoreLocation | alfarom256, aahmad097, wra7h |
| MpfSceViaEnumDateFormatsW | alfarom256, aahmad097, wra7h |
| MpfSceViaEnumDesktopWindows | alfarom256, aahmad097, wra7h |
| MpfSceViaEnumDesktopsW | alfarom256, aahmad097, wra7h |
| MpfSceViaEnumDirTreeW | alfarom256, aahmad097, wra7h |
| MpfSceViaEnumDisplayMonitors | alfarom256, aahmad097, wra7h |
| MpfSceViaEnumFontFamiliesExW | alfarom256, aahmad097, wra7h |
| MpfSceViaEnumFontsW | alfarom256, aahmad097, wra7h |
| MpfSceViaEnumLanguageGroupLocalesW | alfarom256, aahmad097, wra7h |
| MpfSceViaEnumObjects | alfarom256, aahmad097, wra7h |
| MpfSceViaEnumResourceTypesExW | alfarom256, aahmad097, wra7h |
| MpfSceViaEnumSystemCodePagesW | alfarom256, aahmad097, wra7h |
| MpfSceViaEnumSystemGeoID | alfarom256, aahmad097, wra7h |
| MpfSceViaEnumSystemLanguageGroupsW | alfarom256, aahmad097, wra7h |
| MpfSceViaEnumSystemLocalesEx | alfarom256, aahmad097, wra7h |
| MpfSceViaEnumThreadWindows | alfarom256, aahmad097, wra7h |
| MpfSceViaEnumTimeFormatsEx | alfarom256, aahmad097, wra7h |
| MpfSceViaEnumUILanguagesW | alfarom256, aahmad097, wra7h |
| MpfSceViaEnumWindowStationsW | alfarom256, aahmad097, wra7h |
| MpfSceViaEnumWindows | alfarom256, aahmad097, wra7h |
| MpfSceViaEnumerateLoadedModules64 | alfarom256, aahmad097, wra7h |
| MpfSceViaK32EnumPageFilesW | alfarom256, aahmad097, wra7h |
| MpfSceViaEnumPwrSchemes | alfarom256, aahmad097, wra7h |
| MpfSceViaMessageBoxIndirectW | alfarom256, aahmad097, wra7h |
| MpfSceViaChooseColorW | alfarom256, aahmad097, wra7h |
| MpfSceViaClusWorkerCreate | alfarom256, aahmad097, wra7h |
| MpfSceViaSymEnumProcesses | alfarom256, aahmad097, wra7h |
| MpfSceViaImageGetDigestStream | alfarom256, aahmad097, wra7h |
| MpfSceViaVerifierEnumerateResource | alfarom256, aahmad097, wra7h |
| MpfSceViaSymEnumSourceFiles | alfarom256, aahmad097, wra7h |
| Function Name | Original Author |
|---|---|
| ByteArrayToCharArray | smelly__vx |
| CharArrayToByteArray | smelly__vx |
| ShlwapiCharStringToWCharString | smelly__vx |
| ShlwapiWCharStringToCharString | smelly__vx |
| CharStringToWCharString | smelly__vx |
| WCharStringToCharString | smelly__vx |
| RtlInitEmptyUnicodeString | ReactOS |
| RtlInitUnicodeString | ReactOS |
| CaplockString | simonc |
| CopyMemoryEx | ReactOS |
| SecureStringCopy | Apple (c) 1999 |
| StringCompare | Apple (c) 1999 |
| StringConcat | Apple (c) 1999 |
| StringCopy | Apple (c) 1999 |
| StringFindSubstring | Apple (c) 1999 |
| StringLength | Apple (c) 1999 |
| StringLocateChar | Apple (c) 1999 |
| StringRemoveSubstring | smelly__vx |
| StringTerminateStringAtChar | smelly__vx |
| StringToken | Apple (c) 1999 |
| ZeroMemoryEx | ReactOS |
| ConvertCharacterStringToIntegerUsingNtdll | smelly__vx |
| MemoryFindMemory | KamilCuk |
| Function Name | Original Author |
|---|---|
| UacBypassFodHelperMethod | winscripting.blog |
| Function Name | Original Author |
|---|---|
| InitHardwareBreakpointEngine | rad98 |
| ShutdownHardwareBreakpointEngine | rad98 |
| ExceptionHandlerCallbackRoutine | rad98 |
| SetHardwareBreakpoint | rad98 |
| InsertDescriptorEntry | rad98 |
| RemoveDescriptorEntry | rad98 |
| SnapshotInsertHardwareBreakpointHookIntoTargetThread | rad98 |
| Function Name | Original Author |
|---|---|
| GenericShellcodeHelloWorldMessageBoxA | SafeBreach Labs |
| GenericShellcodeHelloWorldMessageBoxAEbFbLoop | SafeBreach Labs |
| GenericShellcodeOpenCalcExitThread | MsfVenom |
![]()
ReconAIzer is a powerful Jython extension for Burp Suite that leverages OpenAI to help bug bounty hunters optimize their recon process. This extension automates various tasks, making it easier and faster for security researchers to identify and exploit vulnerabilities.
Once installed, ReconAIzer add a contextual menu and a dedicated tab to see the results:
Follow these steps to install the ReconAIzer extension on Burp Suite:
ReconAIzer.py file in Step 3.1. Select the file and click "Open."Congratulations! You have successfully installed the ReconAIzer extension in Burp Suite. You can now start using it to enhance your bug bounty hunting experience.
Once it's done, you must configure your OpenAI API key on the "Config" tab under "ReconAIzer" tab.
Feel free to suggest prompts improvements or anything you would like to see on ReconAIzer!
Happy bug hunting!
![]()
HardHat is a multiplayer C# .NET-based command and control framework. Designed to aid in red team engagements and penetration testing. HardHat aims to improve the quality of life factors during engagements by providing an easy-to-use but still robust C2 framework.
It contains three primary components, an ASP.NET teamserver, a blazor .NET client, and C# based implants.
Alpha Release - 3/29/23 NOTE: HardHat is in Alpha release; it will have bugs, missing features, and unexpected things will happen. Thank you for trying it, and please report back any issues or missing features so they can be addressed.
Discord Join the community to talk about HardHat C2, Programming, Red teaming and general cyber security things The discord community is also a great way to request help, submit new features, stay up to date on the latest additions, and submit bugs.
documentation can be found at docs
To configure the team server's starting address (where clients will connect), edit the HardHatC2\TeamServer\Properties\LaunchSettings.json changing the "applicationUrl": "https://127.0.0.1:5000" to the desired location and port. start the teamserver with dotnet run from its top-level folder ../HrdHatC2/Teamserver/
Code contributions are welcome feel free to submit feature requests, pull requests or send me your ideas on discord.
![]()
burpgpt leverages the power of AI to detect security vulnerabilities that traditional scanners might miss. It sends web traffic to an OpenAI model specified by the user, enabling sophisticated analysis within the passive scanner. This extension offers customisable prompts that enable tailored web traffic analysis to meet the specific needs of each user. Check out the Example Use Cases section for inspiration.
The extension generates an automated security report that summarises potential security issues based on the user's prompt and real-time data from Burp-issued requests. By leveraging AI and natural language processing, the extension streamlines the security assessment process and provides security professionals with a higher-level overview of the scanned application or endpoint. This enables them to more easily identify potential security issues and prioritise their analysis, while also covering a larger potential attack surface.
[!WARNING] Data traffic is sent to
OpenAIfor analysis. If you have concerns about this or are using the extension for security-critical applications, it is important to carefully consider this and review OpenAI's Privacy Policy for further information.
[!WARNING] While the report is automated, it still requires triaging and post-processing by security professionals, as it may contain false positives.
[!WARNING] The effectiveness of this extension is heavily reliant on the quality and precision of the prompts created by the user for the selected
GPTmodel. This targeted approach will help ensure theGPT modelgenerates accurate and valuable results for your security analysis.
passive scan check, allowing users to submit HTTP data to an OpenAI-controlled GPT model for analysis through a placeholder system.OpenAI's GPT models to conduct comprehensive traffic analysis, enabling detection of various issues beyond just security vulnerabilities in scanned applications.GPT tokens used in the analysis by allowing for precise adjustments of the maximum prompt length.OpenAI models to choose from, allowing them to select the one that best suits their needs.prompts and unleash limitless possibilities for interacting with OpenAI models. Browse through the Example Use Cases for inspiration.Burp Suite, providing all native features for pre- and post-processing, including displaying analysis results directly within the Burp UI for efficient analysis.Burp Event Log, enabling users to quickly resolve communication issues with the OpenAI API.Operating System: Compatible with Linux, macOS, and Windows operating systems.
Java Development Kit (JDK): Version 11 or later.
Burp Suite Professional or Community Edition: Version 2023.3.2 or later.
[!IMPORTANT] Please note that using any version lower than
2023.3.2may result in a java.lang.NoSuchMethodError. It is crucial to use the specified version or a more recent one to avoid this issue.
Version 6.9 or later (recommended). The build.gradle file is provided in the project repository.JAVA_HOME environment variable to point to the JDK installation directory.Please ensure that all system requirements, including a compatible version of Burp Suite, are met before building and running the project. Note that the project's external dependencies will be automatically managed and installed by Gradle during the build process. Adhering to the requirements will help avoid potential issues and reduce the need for opening new issues in the project repository.
Ensure you have Gradle installed and configured.
Download the burpgpt repository:
git clone https://github.com/aress31/burpgpt
cd .\burpgpt\Build the standalone jar:
./gradlew shadowJarBurp Suite
To install burpgpt in Burp Suite, first go to the Extensions tab and click on the Add button. Then, select the burpgpt-all jar file located in the .\lib\build\libs folder to load the extension.
To start using burpgpt, users need to complete the following steps in the Settings panel, which can be accessed from the Burp Suite menu bar:
OpenAI API key.model.max prompt size. This field controls the maximum prompt length sent to OpenAI to avoid exceeding the maxTokens of GPT models (typically around 2048 for GPT-3).Once configured as outlined above, the Burp passive scanner sends each request to the chosen OpenAI model via the OpenAI API for analysis, producing Informational-level severity findings based on the results.
burpgpt enables users to tailor the prompt for traffic analysis using a placeholder system. To include relevant information, we recommend using these placeholders, which the extension handles directly, allowing dynamic insertion of specific values into the prompt:
| Placeholder | Description |
|---|---|
{REQUEST} | The scanned request. |
{URL} | The URL of the scanned request. |
{METHOD} | The HTTP request method used in the scanned request. |
{REQUEST_HEADERS} | The headers of the scanned request. |
{REQUEST_BODY} | The body of the scanned request. |
{RESPONSE} | The scanned response. |
{RESPONSE_HEADERS} | The headers of the scanned response. |
{RESPONSE_BODY} | The body of the scanned response. |
{IS_TRUNCATED_PROMPT} | A boolean value that is programmatically set to true or false to indicate whether the prompt was truncated to the Maximum Prompt Size defined in the Settings. |
These placeholders can be used in the custom prompt to dynamically generate a request/response analysis prompt that is specific to the scanned request.
[!NOTE] >
Burp Suiteprovides the capability to support arbitraryplaceholdersthrough the use of Session handling rules or extensions such as Custom Parameter Handler, allowing for even greater customisation of theprompts.
The following list of example use cases showcases the bespoke and highly customisable nature of burpgpt, which enables users to tailor their web traffic analysis to meet their specific needs.
Identifying potential vulnerabilities in web applications that use a crypto library affected by a specific CVE:
Analyse the request and response data for potential security vulnerabilities related to the {CRYPTO_LIBRARY_NAME} crypto library affected by CVE-{CVE_NUMBER}:
Web Application URL: {URL}
Crypto Library Name: {CRYPTO_LIBRARY_NAME}
CVE Number: CVE-{CVE_NUMBER}
Request Headers: {REQUEST_HEADERS}
Response Headers: {RESPONSE_HEADERS}
Request Body: {REQUEST_BODY}
Response Body: {RESPONSE_BODY}
Identify any potential vulnerabilities related to the {CRYPTO_LIBRARY_NAME} crypto library affected by CVE-{CVE_NUMBER} in the request and response data and report them.
Scanning for vulnerabilities in web applications that use biometric authentication by analysing request and response data related to the authentication process:
Analyse the request and response data for potential security vulnerabilities related to the biometric authentication process:
Web Application URL: {URL}
Biometric Authentication Request Headers: {REQUEST_HEADERS}
Biometric Authentication Response Headers: {RESPONSE_HEADERS}
Biometric Authentication Request Body: {REQUEST_BODY}
Biometric Authentication Response Body: {RESPONSE_BODY}
Identify any potential vulnerabilities related to the biometric authentication process in the request and response data and report them.
Analysing the request and response data exchanged between serverless functions for potential security vulnerabilities:
Analyse the request and response data exchanged between serverless functions for potential security vulnerabilities:
Serverless Function A URL: {URL}
Serverless Function B URL: {URL}
Serverless Function A Request Headers: {REQUEST_HEADERS}
Serverless Function B Response Headers: {RESPONSE_HEADERS}
Serverless Function A Request Body: {REQUEST_BODY}
Serverless Function B Response Body: {RESPONSE_BODY}
Identify any potential vulnerabilities in the data exchanged between the two serverless functions and report them.
Analysing the request and response data for potential security vulnerabilities specific to a Single-Page Application (SPA) framework:
Analyse the request and response data for potential security vulnerabilities specific to the {SPA_FRAMEWORK_NAME} SPA framework:
Web Application URL: {URL}
SPA Framework Name: {SPA_FRAMEWORK_NAME}
Request Headers: {REQUEST_HEADERS}
Response Headers: {RESPONSE_HEADERS}
Request Body: {REQUEST_BODY}
Response Body: {RESPONSE_BODY}
Identify any potential vulnerabilities related to the {SPA_FRAMEWORK_NAME} SPA framework in the request and response data and report them.
Settings panel that allows users to set the maxTokens limit for requests, thereby limiting the request size.AI model, allowing users to run and interact with the model on their local machines, potentially improving response times and data privacy.maxTokens value for each model to transmit the maximum allowable data and obtain the most extensive GPT response possible.Burp Suite restarts.GPT responses into the Vulnerability model for improved reporting.The extension is currently under development and we welcome feedback, comments, and contributions to make it even better.
If this extension has saved you time and hassle during a security assessment, consider showing some love by sponsoring a cup of coffee
for the developer. It's the fuel that powers development, after all. Just hit that shiny Sponsor button at the top of the page or click here to contribute and keep the caffeine flowing.Did you find a bug? Well, don't just let it crawl around! Let's squash it together like a couple of bug whisperers!
Please report any issues on the GitHub issues tracker. Together, we'll make this extension as reliable as a cockroach surviving a nuclear apocalypse!
Looking to make a splash with your mad coding skills?
Awesome! Contributions are welcome and greatly appreciated. Please submit all PRs on the GitHub pull requests tracker. Together we can make this extension even more amazing!
See LICENSE.
![]()
Sandboxes are commonly used to analyze malware. They provide a temporary, isolated, and secure environment in which to observe whether a suspicious file exhibits any malicious behavior. However, malware developers have also developed methods to evade sandboxes and analysis environments. One such method is to perform checks to determine whether the machine the malware is being executed on is being operated by a real user. One such check is the RAM size. If the RAM size is unrealistically small (e.g., 1GB), it may indicate that the machine is a sandbox. If the malware detects a sandbox, it will not execute its true malicious behavior and may appear to be a benign file
The GetPhysicallyInstalledSystemMemory API retrieves the amount of RAM that is physically installed on the computer from the SMBIOS firmware tables. It takes a PULONGLONG parameter and returns TRUE if the function succeeds, setting the TotalMemoryInKilobytes to a nonzero value. If the function fails, it returns FALSE.
The amount of physical memory retrieved by the GetPhysicallyInstalledSystemMemory function must be equal to or greater than the amount reported by the GlobalMemoryStatusEx function; if it is less, the SMBIOS data is malformed and the function fails with ERROR_INVALID_DATA, Malformed SMBIOS data may indicate a problem with the user's computer .
The register rcx holds the parameter TotalMemoryInKilobytes. To overwrite the jump address of GetPhysicallyInstalledSystemMemory, I use the following opcodes: mov qword ptr ss:[rcx],4193B840. This moves the value 4193B840 (or 1.1 TB) to rcx. Then, the ret instruction is used to pop the return address off the stack and jump to it, Therefore, whenever GetPhysicallyInstalledSystemMemory is called, it will set rcx to the custom value."
![]()
Hades is a proof of concept loader that combines several evasion technques with the aim of bypassing the defensive mechanisms commonly used by modern AV/EDRs.
The easiest way, is probably building the project on Linux using make.
git clone https://github.com/f1zm0/hades && cd hades
makeThen you can bring the executable to a x64 Windows host and run it with .\hades.exe [options].
PS > .\hades.exe -h
'||' '||' | '||''|. '||''''| .|'''.|
|| || ||| || || || . ||.. '
||''''|| | || || || ||''| ''|||.
|| || .''''|. || || || . '||
.||. .||. .|. .||. .||...|' .||.....| |'....|'
version: dev [11/01/23] :: @f1zm0
Usage:
hades -f <filepath> [-t selfthread|remotethread|queueuserapc]
Options:
-f, --file <str> shellcode file path (.bin)
-t, --technique <str> injection technique [selfthread, remotethread, queueuserapc]
Inject shellcode that spawms calc.exe with queueuserapc technique:
.\hades.exe -f calc.bin -t queueuserapc
User-mode hooking bypass with syscall RVA sorting (NtQueueApcThread hooked with frida-trace and custom handler)
Instrumentation callback bypass with indirect syscalls (injected DLL is from syscall-detect by jackullrich)
In the latest release, direct syscall capabilities have been replaced by indirect syscalls provided by acheron. If for some reason you want to use the previous version of the loader that used direct syscalls, you need to explicitly pass the direct_syscalls tag to the compiler, which will figure out what files needs to be included and excluded from the build.
GOOS=windows GOARCH=amd64 go build -ldflags "-s -w" -tags='direct_syscalls' -o dist/hades_directsys.exe cmd/hades/main.go
Warning
This project has been created for educational purposes only, to experiment with malware dev in Go, and learn more about the unsafe package and the weird Go Assembly syntax. Don't use it to on systems you don't own. The developer of this project is not responsible for any damage caused by the improper use of this tool.
Shoutout to the following people that shared their knowledge and code that inspired this tool:
This project is licensed under the GPLv3 License - see the LICENSE file for details