The cybercriminals in control of Kimwolf — a disruptive botnet that has infected more than 2 million devices — recently shared a screenshot indicating they’d compromised the control panel for Badbox 2.0, a vast China-based botnet powered by malicious software that comes pre-installed on many Android TV streaming boxes. Both the FBI and Google say they are hunting for the people behind Badbox 2.0, and thanks to bragging by the Kimwolf botmasters we may now have a much clearer idea about that.
Our first story of 2026, The Kimwolf Botnet is Stalking Your Local Network, detailed the unique and highly invasive methods Kimwolf uses to spread. The story warned that the vast majority of Kimwolf infected systems were unofficial Android TV boxes that are typically marketed as a way to watch unlimited (pirated) movie and TV streaming services for a one-time fee.
Our January 8 story, Who Benefitted from the Aisuru and Kimwolf Botnets?, cited multiple sources saying the current administrators of Kimwolf went by the nicknames “Dort” and “Snow.” Earlier this month, a close former associate of Dort and Snow shared what they said was a screenshot the Kimwolf botmasters had taken while logged in to the Badbox 2.0 botnet control panel.
That screenshot, a portion of which is shown below, shows seven authorized users of the control panel, including one that doesn’t quite match the others: According to my source, the account “ABCD” (the one that is logged in and listed in the top right of the screenshot) belongs to Dort, who somehow figured out how to add their email address as a valid user of the Badbox 2.0 botnet.
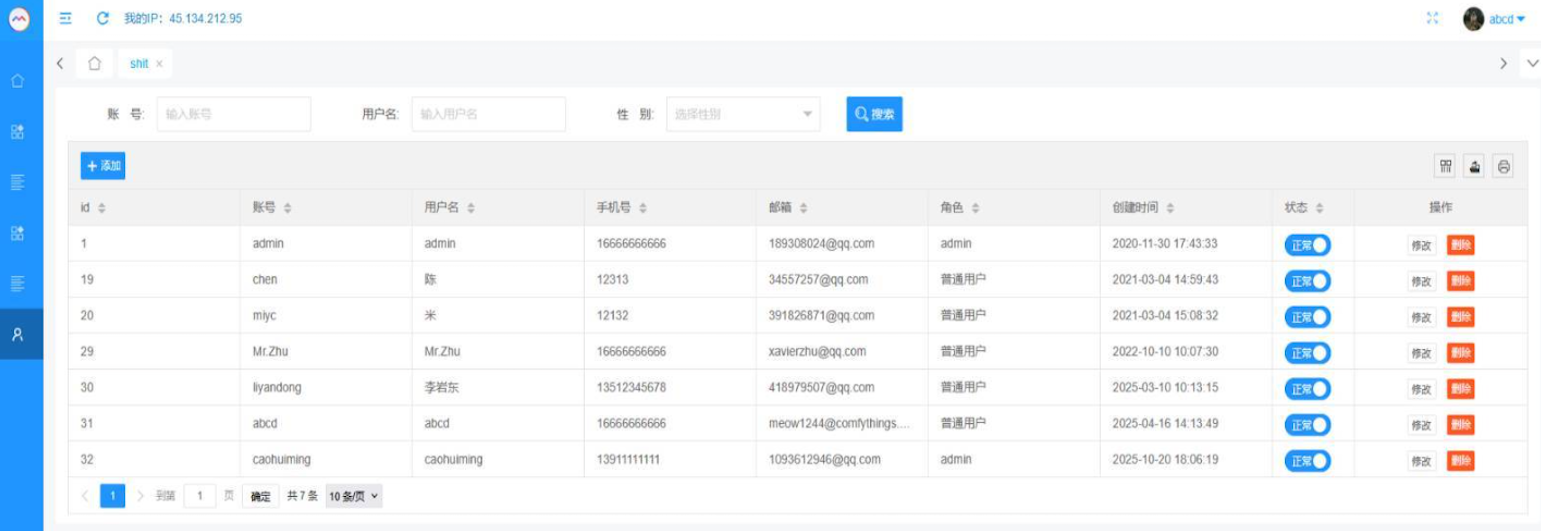
The control panel for the Badbox 2.0 botnet lists seven authorized users and their email addresses. Click to enlarge.
Badbox has a storied history that well predates Kimwolf’s rise in October 2025. In July 2025, Google filed a “John Doe” lawsuit (PDF) against 25 unidentified defendants accused of operating Badbox 2.0, which Google described as a botnet of over ten million unsanctioned Android streaming devices engaged in advertising fraud. Google said Badbox 2.0, in addition to compromising multiple types of devices prior to purchase, also can infect devices by requiring the download of malicious apps from unofficial marketplaces.
Google’s lawsuit came on the heels of a June 2025 advisory from the Federal Bureau of Investigation (FBI), which warned that cyber criminals were gaining unauthorized access to home networks by either configuring the products with malware prior to the user’s purchase, or infecting the device as it downloads required applications that contain backdoors — usually during the set-up process.
The FBI said Badbox 2.0 was discovered after the original Badbox campaign was disrupted in 2024. The original Badbox was identified in 2023, and primarily consisted of Android operating system devices (TV boxes) that were compromised with backdoor malware prior to purchase.
KrebsOnSecurity was initially skeptical of the claim that the Kimwolf botmasters had hacked the Badbox 2.0 botnet. That is, until we began digging into the history of the qq.com email addresses in the screenshot above.
An online search for the address 34557257@qq.com (pictured in the screenshot above as the user “Chen“) shows it is listed as a point of contact for a number of China-based technology companies, including:
–Beijing Hong Dake Wang Science & Technology Co Ltd.
–Beijing Hengchuang Vision Mobile Media Technology Co. Ltd.
–Moxin Beijing Science and Technology Co. Ltd.
The website for Beijing Hong Dake Wang Science is asmeisvip[.]net, a domain that was flagged in a March 2025 report by HUMAN Security as one of several dozen sites tied to the distribution and management of the Badbox 2.0 botnet. Ditto for moyix[.]com, a domain associated with Beijing Hengchuang Vision Mobile.
A search at the breach tracking service Constella Intelligence finds 34557257@qq.com at one point used the password “cdh76111.” Pivoting on that password in Constella shows it is known to have been used by just two other email accounts: daihaic@gmail.com and cathead@gmail.com.
Constella found cathead@gmail.com registered an account at jd.com (China’s largest online retailer) in 2021 under the name “陈代海,” which translates to “Chen Daihai.” According to DomainTools.com, the name Chen Daihai is present in the original registration records (2008) for moyix[.]com, along with the email address cathead@astrolink[.]cn.
Incidentally, astrolink[.]cn also is among the Badbox 2.0 domains identified in HUMAN Security’s 2025 report. DomainTools finds cathead@astrolink[.]cn was used to register more than a dozen domains, including vmud[.]net, yet another Badbox 2.0 domain tagged by HUMAN Security.
A cached copy of astrolink[.]cn preserved at archive.org shows the website belongs to a mobile app development company whose full name is Beijing Astrolink Wireless Digital Technology Co. Ltd. The archived website reveals a “Contact Us” page that lists a Chen Daihai as part of the company’s technology department. The other person featured on that contact page is Zhu Zhiyu, and their email address is listed as xavier@astrolink[.]cn.
A Google-translated version of Astrolink’s website, circa 2009. Image: archive.org.
Astute readers will notice that the user Mr.Zhu in the Badbox 2.0 panel used the email address xavierzhu@qq.com. Searching this address in Constella reveals a jd.com account registered in the name of Zhu Zhiyu. A rather unique password used by this account matches the password used by the address xavierzhu@gmail.com, which DomainTools finds was the original registrant of astrolink[.]cn.
The very first account listed in the Badbox 2.0 panel — “admin,” registered in November 2020 — used the email address 189308024@qq.com. DomainTools shows this email is found in the 2022 registration records for the domain guilincloud[.]cn, which includes the registrant name “Huang Guilin.”
Constella finds 189308024@qq.com is associated with the China phone number 18681627767. The open-source intelligence platform osint.industries reveals this phone number is connected to a Microsoft profile created in 2014 under the name Guilin Huang (桂林 黄). The cyber intelligence platform Spycloud says that phone number was used in 2017 to create an account at the Chinese social media platform Weibo under the username “h_guilin.”
The public information attached to Guilin Huang’s Microsoft account, according to the breach tracking service osintindustries.com.
The remaining three users and corresponding qq.com email addresses were all connected to individuals in China. However, none of them (nor Mr. Huang) had any apparent connection to the entities created and operated by Chen Daihai and Zhu Zhiyu — or to any corporate entities for that matter. Also, none of these individuals responded to requests for comment.
The mind map below includes search pivots on the email addresses, company names and phone numbers that suggest a connection between Chen Daihai, Zhu Zhiyu, and Badbox 2.0.
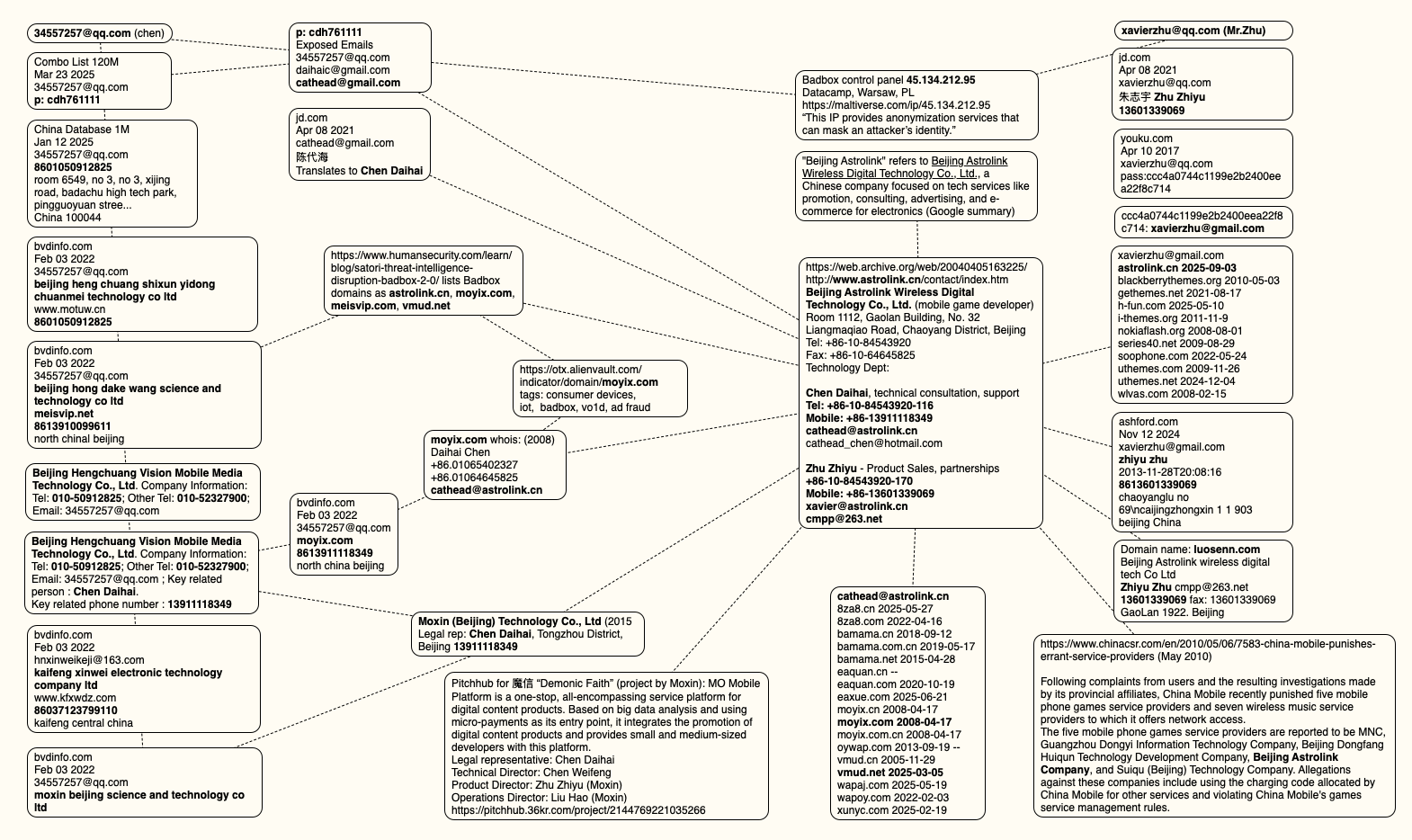
This mind map includes search pivots on the email addresses, company names and phone numbers that appear to connect Chen Daihai and Zhu Zhiyu to Badbox 2.0. Click to enlarge.
The idea that the Kimwolf botmasters could have direct access to the Badbox 2.0 botnet is a big deal, but explaining exactly why that is requires some background on how Kimwolf spreads to new devices. The botmasters figured out they could trick residential proxy services into relaying malicious commands to vulnerable devices behind the firewall on the unsuspecting user’s local network.
The vulnerable systems sought out by Kimwolf are primarily Internet of Things (IoT) devices like unsanctioned Android TV boxes and digital photo frames that have no discernible security or authentication built-in. Put simply, if you can communicate with these devices, you can compromise them with a single command.
Our January 2 story featured research from the proxy-tracking firm Synthient, which alerted 11 different residential proxy providers that their proxy endpoints were vulnerable to being abused for this kind of local network probing and exploitation.
Most of those vulnerable proxy providers have since taken steps to prevent customers from going upstream into the local networks of residential proxy endpoints, and it appeared that Kimwolf would no longer be able to quickly spread to millions of devices simply by exploiting some residential proxy provider.
However, the source of that Badbox 2.0 screenshot said the Kimwolf botmasters had an ace up their sleeve the whole time: Secret access to the Badbox 2.0 botnet control panel.
“Dort has gotten unauthorized access,” the source said. “So, what happened is normal proxy providers patched this. But Badbox doesn’t sell proxies by itself, so it’s not patched. And as long as Dort has access to Badbox, they would be able to load” the Kimwolf malware directly onto TV boxes associated with Badbox 2.0.
The source said it isn’t clear how Dort gained access to the Badbox botnet panel. But it’s unlikely that Dort’s existing account will persist for much longer: All of our notifications to the qq.com email addresses listed in the control panel screenshot received a copy of that image, as well as questions about the apparently rogue ABCD account.
![]()
Thank you for following me! https://cybdetective.com
| Name | Link | Description | Price |
|---|---|---|---|
| Shodan | https://developer.shodan.io | Search engine for Internet connected host and devices | from $59/month |
| Netlas.io | https://netlas-api.readthedocs.io/en/latest/ | Search engine for Internet connected host and devices. Read more at Netlas CookBook | Partly FREE |
| Fofa.so | https://fofa.so/static_pages/api_help | Search engine for Internet connected host and devices | ??? |
| Censys.io | https://censys.io/api | Search engine for Internet connected host and devices | Partly FREE |
| Hunter.how | https://hunter.how/search-api | Search engine for Internet connected host and devices | Partly FREE |
| Fullhunt.io | https://api-docs.fullhunt.io/#introduction | Search engine for Internet connected host and devices | Partly FREE |
| IPQuery.io | https://ipquery.io | API for ip information such as ip risk, geolocation data, and asn details | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Social Links | https://sociallinks.io/products/sl-api | Email info lookup, phone info lookup, individual and company profiling, social media tracking, dark web monitoring and more. Code example of using this API for face search in this repo | PAID. Price per request |
| Name | Link | Description | Price |
|---|---|---|---|
| Numverify | https://numverify.com | Global Phone Number Validation & Lookup JSON API. Supports 232 countries. | 250 requests FREE |
| Twillo | https://www.twilio.com/docs/lookup/api | Provides a way to retrieve additional information about a phone number | Free or $0.01 per request (for caller lookup) |
| Plivo | https://www.plivo.com/lookup/ | Determine carrier, number type, format, and country for any phone number worldwide | from $0.04 per request |
| GetContact | https://github.com/kovinevmv/getcontact | Find info about user by phone number | from $6,89 in months/100 requests |
| Veriphone | https://veriphone.io/ | Phone number validation & carrier lookup | 1000 requests/month FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Global Address | https://rapidapi.com/adminMelissa/api/global-address/ | Easily verify, check or lookup address | FREE |
| US Street Address | https://smartystreets.com/docs/cloud/us-street-api | Validate and append data for any US postal address | FREE |
| Google Maps Geocoding API | https://developers.google.com/maps/documentation/geocoding/overview | convert addresses (like "1600 Amphitheatre Parkway, Mountain View, CA") into geographic coordinates | 0.005 USD per request |
| Postcoder | https://postcoder.com/address-lookup | Find adress by postcode | £130/5000 requests |
| Zipcodebase | https://zipcodebase.com | Lookup postal codes, calculate distances and much more | 5000 requests FREE |
| Openweathermap geocoding API | https://openweathermap.org/api/geocoding-api | get geographical coordinates (lat, lon) by using name of the location (city name or area name) | 60 calls/minute 1,000,000 calls/month |
| DistanceMatrix | https://distancematrix.ai/product | Calculate, evaluate and plan your routes | $1.25-$2 per 1000 elements |
| Geotagging API | https://geotagging.ai/ | Predict geolocations by texts | Freemium |
| Name | Link | Description | Price |
|---|---|---|---|
| Approuve.com | https://appruve.co | Allows you to verify the identities of individuals, businesses, and connect to financial account data across Africa | Paid |
| Onfido.com | https://onfido.com | Onfido Document Verification lets your users scan a photo ID from any device, before checking it's genuine. Combined with Biometric Verification, it's a seamless way to anchor an account to the real identity of a customer. India | Paid |
| Superpass.io | https://surepass.io/passport-id-verification-api/ | Passport, Photo ID and Driver License Verification in India | Paid |
| Name | Link | Description | Price |
|---|---|---|---|
| Open corporates | https://api.opencorporates.com | Companies information | Paid, price upon request |
| Linkedin company search API | https://docs.microsoft.com/en-us/linkedin/marketing/integrations/community-management/organizations/company-search?context=linkedin%2Fcompliance%2Fcontext&tabs=http | Find companies using keywords, industry, location, and other criteria | FREE |
| Mattermark | https://rapidapi.com/raygorodskij/api/Mattermark/ | Get companies and investor information | free 14-day trial, from $49 per month |
| Name | Link | Description | Price |
|---|---|---|---|
| API OSINT DS | https://github.com/davidonzo/apiosintDS | Collect info about IPv4/FQDN/URLs and file hashes in md5, sha1 or sha256 | FREE |
| InfoDB API | https://www.ipinfodb.com/api | The API returns the location of an IP address (country, region, city, zipcode, latitude, longitude) and the associated timezone in XML, JSON or plain text format | FREE |
| Domainsdb.info | https://domainsdb.info | Registered Domain Names Search | FREE |
| BGPView | https://bgpview.docs.apiary.io/# | allowing consumers to view all sort of analytics data about the current state and structure of the internet | FREE |
| DNSCheck | https://www.dnscheck.co/api | monitor the status of both individual DNS records and groups of related DNS records | up to 10 DNS records/FREE |
| Cloudflare Trace | https://github.com/fawazahmed0/cloudflare-trace-api | Get IP Address, Timestamp, User Agent, Country Code, IATA, HTTP Version, TLS/SSL Version & More | FREE |
| Host.io | https://host.io/ | Get info about domain | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| BeVigil OSINT API | https://bevigil.com/osint-api | provides access to millions of asset footprint data points including domain intel, cloud services, API information, and third party assets extracted from millions of mobile apps being continuously uploaded and scanned by users on bevigil.com | 50 credits free/1000 credits/$50 |
| Name | Link | Description | Price |
|---|---|---|---|
| WebScraping.AI | https://webscraping.ai/ | Web Scraping API with built-in proxies and JS rendering | FREE |
| ZenRows | https://www.zenrows.com/ | Web Scraping API that bypasses anti-bot solutions while offering JS rendering, and rotating proxies apiKey Yes Unknown | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Whois freaks | https://whoisfreaks.com/ | well-parsed and structured domain WHOIS data for all domain names, registrars, countries and TLDs since the birth of internet | $19/5000 requests |
| WhoisXMLApi | https://whois.whoisxmlapi.com | gathers a variety of domain ownership and registration data points from a comprehensive WHOIS database | 500 requests in month/FREE |
| IPtoWhois | https://www.ip2whois.com/developers-api | Get detailed info about a domain | 500 requests/month FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Ipstack | https://ipstack.com | Detect country, region, city and zip code | FREE |
| Ipgeolocation.io | https://ipgeolocation.io | provides country, city, state, province, local currency, latitude and longitude, company detail, ISP lookup, language, zip code, country calling code, time zone, current time, sunset and sunrise time, moonset and moonrise | 30 000 requests per month/FREE |
| IPInfoDB | https://ipinfodb.com/api | Free Geolocation tools and APIs for country, region, city and time zone lookup by IP address | FREE |
| IP API | https://ip-api.com/ | Free domain/IP geolocation info | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Mylnikov API | https://www.mylnikov.org | public API implementation of Wi-Fi Geo-Location database | FREE |
| Wigle | https://api.wigle.net/ | get location and other information by SSID | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| PeetingDB | https://www.peeringdb.com/apidocs/ | Database of networks, and the go-to location for interconnection data | FREE |
| PacketTotal | https://packettotal.com/api.html | .pcap files analyze | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Binlist.net | https://binlist.net/ | get information about bank by BIN | FREE |
| FDIC Bank Data API | https://banks.data.fdic.gov/docs/ | institutions, locations and history events | FREE |
| Amdoren | https://www.amdoren.com/currency-api/ | Free currency API with over 150 currencies | FREE |
| VATComply.com | https://www.vatcomply.com/documentation | Exchange rates, geolocation and VAT number validation | FREE |
| Alpaca | https://alpaca.markets/docs/api-documentation/api-v2/market-data/alpaca-data-api-v2/ | Realtime and historical market data on all US equities and ETFs | FREE |
| Swiftcodesapi | https://swiftcodesapi.com | Verifying the validity of a bank SWIFT code or IBAN account number | $39 per month/4000 swift lookups |
| IBANAPI | https://ibanapi.com | Validate IBAN number and get bank account information from it | Freemium/10$ Starter plan |
| Name | Link | Description | Price |
|---|---|---|---|
| EVA | https://eva.pingutil.com/ | Measuring email deliverability & quality | FREE |
| Mailboxlayer | https://mailboxlayer.com/ | Simple REST API measuring email deliverability & quality | 100 requests FREE, 5000 requests in month — $14.49 |
| EmailCrawlr | https://emailcrawlr.com/ | Get key information about company websites. Find all email addresses associated with a domain. Get social accounts associated with an email. Verify email address deliverability. | 200 requests FREE, 5000 requets — $40 |
| Voila Norbert | https://www.voilanorbert.com/api/ | Find anyone's email address and ensure your emails reach real people | from $49 in month |
| Kickbox | https://open.kickbox.com/ | Email verification API | FREE |
| FachaAPI | https://api.facha.dev/ | Allows checking if an email domain is a temporary email domain | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Genderize.io | https://genderize.io | Instantly answers the question of how likely a certain name is to be male or female and shows the popularity of the name. | 1000 names/day free |
| Agify.io | https://agify.io | Predicts the age of a person given their name | 1000 names/day free |
| Nataonalize.io | https://nationalize.io | Predicts the nationality of a person given their name | 1000 names/day free |
| Name | Link | Description | Price |
|---|---|---|---|
| HaveIBeenPwned | https://haveibeenpwned.com/API/v3 | allows the list of pwned accounts (email addresses and usernames) | $3.50 per month |
| Psdmp.ws | https://psbdmp.ws/api | search in Pastebin | $9.95 per 10000 requests |
| LeakPeek | https://psbdmp.ws/api | searc in leaks databases | $9.99 per 4 weeks unlimited access |
| BreachDirectory.com | https://breachdirectory.com/api_documentation | search domain in data breaches databases | FREE |
| LeekLookup | https://leak-lookup.com/api | search domain, email_address, fullname, ip address, phone, password, username in leaks databases | 10 requests FREE |
| BreachDirectory.org | https://rapidapi.com/rohan-patra/api/breachdirectory/pricing | search domain, email_address, fullname, ip address, phone, password, username in leaks databases (possible to view password hashes) | 50 requests in month/FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Wayback Machine API (Memento API, CDX Server API, Wayback Availability JSON API) | https://archive.org/help/wayback_api.php | Retrieve information about Wayback capture data | FREE |
| TROVE (Australian Web Archive) API | https://trove.nla.gov.au/about/create-something/using-api | Retrieve information about TROVE capture data | FREE |
| Archive-it API | https://support.archive-it.org/hc/en-us/articles/115001790023-Access-Archive-It-s-Wayback-index-with-the-CDX-C-API | Retrieve information about archive-it capture data | FREE |
| UK Web Archive API | https://ukwa-manage.readthedocs.io/en/latest/#api-reference | Retrieve information about UK Web Archive capture data | FREE |
| Arquivo.pt API | https://github.com/arquivo/pwa-technologies/wiki/Arquivo.pt-API | Allows full-text search and access preserved web content and related metadata. It is also possible to search by URL, accessing all versions of preserved web content. API returns a JSON object. | FREE |
| Library Of Congress archive API | https://www.loc.gov/apis/ | Provides structured data about Library of Congress collections | FREE |
| BotsArchive | https://botsarchive.com/docs.html | JSON formatted details about Telegram Bots available in database | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| MD5 Decrypt | https://md5decrypt.net/en/Api/ | Search for decrypted hashes in the database | 1.99 EURO/day |
| Name | Link | Description | Price |
|---|---|---|---|
| BTC.com | https://btc.com/btc/adapter?type=api-doc | get information about addresses and transanctions | FREE |
| Blockchair | https://blockchair.com | Explore data stored on 17 blockchains (BTC, ETH, Cardano, Ripple etc) | $0.33 - $1 per 1000 calls |
| Bitcointabyse | https://www.bitcoinabuse.com/api-docs | Lookup bitcoin addresses that have been linked to criminal activity | FREE |
| Bitcoinwhoswho | https://www.bitcoinwhoswho.com/api | Scam reports on the Bitcoin Address | FREE |
| Etherscan | https://etherscan.io/apis | Ethereum explorer API | FREE |
| apilayer coinlayer | https://coinlayer.com | Real-time Crypto Currency Exchange Rates | FREE |
| BlockFacts | https://blockfacts.io/ | Real-time crypto data from multiple exchanges via a single unified API, and much more | FREE |
| Brave NewCoin | https://bravenewcoin.com/developers | Real-time and historic crypto data from more than 200+ exchanges | FREE |
| WorldCoinIndex | https://www.worldcoinindex.com/apiservice | Cryptocurrencies Prices | FREE |
| WalletLabels | https://www.walletlabels.xyz/docs | Labels for 7,5 million Ethereum wallets | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| VirusTotal | https://developers.virustotal.com/reference | files and urls analyze | Public API is FREE |
| AbuseLPDB | https://docs.abuseipdb.com/#introduction | IP/domain/URL reputation | FREE |
| AlienVault Open Threat Exchange (OTX) | https://otx.alienvault.com/api | IP/domain/URL reputation | FREE |
| Phisherman | https://phisherman.gg | IP/domain/URL reputation | FREE |
| URLScan.io | https://urlscan.io/about-api/ | Scan and Analyse URLs | FREE |
| Web of Thrust | https://support.mywot.com/hc/en-us/sections/360004477734-API- | IP/domain/URL reputation | FREE |
| Threat Jammer | https://threatjammer.com/docs/introduction-threat-jammer-user-api | IP/domain/URL reputation | ??? |
| Name | Link | Description | Price |
|---|---|---|---|
| Search4faces | https://search4faces.com/api.html | Detect and locate human faces within an image, and returns high-precision face bounding boxes. Face⁺⁺ also allows you to store metadata of each detected face for future use. | $21 per 1000 requests |
## Face Detection
| Name | Link | Description | Price |
|---|---|---|---|
| Face++ | https://www.faceplusplus.com/face-detection/ | Search for people in social networks by facial image | from 0.03 per call |
| BetaFace | https://www.betafaceapi.com/wpa/ | Can scan uploaded image files or image URLs, find faces and analyze them. API also provides verification (faces comparison) and identification (faces search) services, as well able to maintain multiple user-defined recognition databases (namespaces) | 50 image per day FREE/from 0.15 EUR per request |
## Reverse Image Search
| Name | Link | Description | Price |
|---|---|---|---|
| Google Reverse images search API | https://github.com/SOME-1HING/google-reverse-image-api/ | This is a simple API built using Node.js and Express.js that allows you to perform Google Reverse Image Search by providing an image URL. | FREE (UNOFFICIAL) |
| TinEyeAPI | https://services.tineye.com/TinEyeAPI | Verify images, Moderate user-generated content, Track images and brands, Check copyright compliance, Deploy fraud detection solutions, Identify stock photos, Confirm the uniqueness of an image | Start from $200/5000 searches |
| Bing Images Search API | https://www.microsoft.com/en-us/bing/apis/bing-image-search-api | With Bing Image Search API v7, help users scour the web for images. Results include thumbnails, full image URLs, publishing website info, image metadata, and more. | 1,000 requests free per month FREE |
| MRISA | https://github.com/vivithemage/mrisa | MRISA (Meta Reverse Image Search API) is a RESTful API which takes an image URL, does a reverse Google image search, and returns a JSON array with the search results | FREE? (no official) |
| PicImageSearch | https://github.com/kitUIN/PicImageSearch | Aggregator for different Reverse Image Search API | FREE? (no official) |
## AI Geolocation
| Name | Link | Description | Price |
|---|---|---|---|
| Geospy | https://api.geospy.ai/ | Detecting estimation location of uploaded photo | Access by request |
| Picarta | https://picarta.ai/api | Detecting estimation location of uploaded photo | 100 request/day FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Twitch | https://dev.twitch.tv/docs/v5/reference | ||
| YouTube Data API | https://developers.google.com/youtube/v3 | ||
| https://www.reddit.com/dev/api/ | |||
| Vkontakte | https://vk.com/dev/methods | ||
| Twitter API | https://developer.twitter.com/en | ||
| Linkedin API | https://docs.microsoft.com/en-us/linkedin/ | ||
| All Facebook and Instagram API | https://developers.facebook.com/docs/ | ||
| Whatsapp Business API | https://www.whatsapp.com/business/api | ||
| Telegram and Telegram Bot API | https://core.telegram.org | ||
| Weibo API | https://open.weibo.com/wiki/API文档/en | ||
| https://dev.xing.com/partners/job_integration/api_docs | |||
| Viber | https://developers.viber.com/docs/api/rest-bot-api/ | ||
| Discord | https://discord.com/developers/docs | ||
| Odnoklassniki | https://ok.ru/apiok | ||
| Blogger | https://developers.google.com/blogger/ | The Blogger APIs allows client applications to view and update Blogger content | FREE |
| Disqus | https://disqus.com/api/docs/auth/ | Communicate with Disqus data | FREE |
| Foursquare | https://developer.foursquare.com/ | Interact with Foursquare users and places (geolocation-based checkins, photos, tips, events, etc) | FREE |
| HackerNews | https://github.com/HackerNews/API | Social news for CS and entrepreneurship | FREE |
| Kakao | https://developers.kakao.com/ | Kakao Login, Share on KakaoTalk, Social Plugins and more | FREE |
| Line | https://developers.line.biz/ | Line Login, Share on Line, Social Plugins and more | FREE |
| TikTok | https://developers.tiktok.com/doc/login-kit-web | Fetches user info and user's video posts on TikTok platform | FREE |
| Tumblr | https://www.tumblr.com/docs/en/api/v2 | Read and write Tumblr Data | FREE |
!WARNING Use with caution! Accounts may be blocked permanently for using unofficial APIs.
| Name | Link | Description | Price |
|---|---|---|---|
| TikTok | https://github.com/davidteather/TikTok-Api | The Unofficial TikTok API Wrapper In Python | FREE |
| Google Trends | https://github.com/suryasev/unofficial-google-trends-api | Unofficial Google Trends API | FREE |
| YouTube Music | https://github.com/sigma67/ytmusicapi | Unofficial APi for YouTube Music | FREE |
| Duolingo | https://github.com/KartikTalwar/Duolingo | Duolingo unofficial API (can gather info about users) | FREE |
| Steam. | https://github.com/smiley/steamapi | An unofficial object-oriented Python library for accessing the Steam Web API. | FREE |
| https://github.com/ping/instagram_private_api | Instagram Private API | FREE | |
| Discord | https://github.com/discordjs/discord.js | JavaScript library for interacting with the Discord API | FREE |
| Zhihu | https://github.com/syaning/zhihu-api | FREE Unofficial API for Zhihu | FREE |
| Quora | https://github.com/csu/quora-api | Unofficial API for Quora | FREE |
| DnsDumbster | https://github.com/PaulSec/API-dnsdumpster.com | (Unofficial) Python API for DnsDumbster | FREE |
| PornHub | https://github.com/sskender/pornhub-api | Unofficial API for PornHub in Python | FREE |
| Skype | https://github.com/ShyykoSerhiy/skyweb | Unofficial Skype API for nodejs via 'Skype (HTTP)' protocol. | FREE |
| Google Search | https://github.com/aviaryan/python-gsearch | Google Search unofficial API for Python with no external dependencies | FREE |
| Airbnb | https://github.com/nderkach/airbnb-python | Python wrapper around the Airbnb API (unofficial) | FREE |
| Medium | https://github.com/enginebai/PyMedium | Unofficial Medium Python Flask API and SDK | FREE |
| https://github.com/davidyen1124/Facebot | Powerful unofficial Facebook API | FREE | |
| https://github.com/tomquirk/linkedin-api | Unofficial Linkedin API for Python | FREE | |
| Y2mate | https://github.com/Simatwa/y2mate-api | Unofficial Y2mate API for Python | FREE |
| Livescore | https://github.com/Simatwa/livescore-api | Unofficial Livescore API for Python | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Google Custom Search JSON API | https://developers.google.com/custom-search/v1/overview | Search in Google | 100 requests FREE |
| Serpstack | https://serpstack.com/ | Google search results to JSON | FREE |
| Serpapi | https://serpapi.com | Google, Baidu, Yandex, Yahoo, DuckDuckGo, Bint and many others search results | $50/5000 searches/month |
| Bing Web Search API | https://www.microsoft.com/en-us/bing/apis/bing-web-search-api | Search in Bing (+instant answers and location) | 1000 transactions per month FREE |
| WolframAlpha API | https://products.wolframalpha.com/api/pricing/ | Short answers, conversations, calculators and many more | from $25 per 1000 queries |
| DuckDuckgo Instant Answers API | https://duckduckgo.com/api | An API for some of our Instant Answers, not for full search results. | FREE |
| Memex Marginalia | https://memex.marginalia.nu/projects/edge/api.gmi | An API for new privacy search engine | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| MediaStack | https://mediastack.com/ | News articles search results in JSON | 500 requests/month FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Darksearch.io | https://darksearch.io/apidoc | search by websites in .onion zone | FREE |
| Onion Lookup | https://onion.ail-project.org/ | onion-lookup is a service for checking the existence of Tor hidden services and retrieving their associated metadata. onion-lookup relies on an private AIL instance to obtain the metadata | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Jackett | https://github.com/Jackett/Jackett | API for automate searching in different torrent trackers | FREE |
| Torrents API PY | https://github.com/Jackett/Jackett | Unofficial API for 1337x, Piratebay, Nyaasi, Torlock, Torrent Galaxy, Zooqle, Kickass, Bitsearch, MagnetDL,Libgen, YTS, Limetorrent, TorrentFunk, Glodls, Torre | FREE |
| Torrent Search API | https://github.com/Jackett/Jackett | API for Torrent Search Engine with Extratorrents, Piratebay, and ISOhunt | 500 queries/day FREE |
| Torrent search api | https://github.com/JimmyLaurent/torrent-search-api | Yet another node torrent scraper (supports iptorrents, torrentleech, torrent9, torrentz2, 1337x, thepiratebay, Yggtorrent, TorrentProject, Eztv, Yts, LimeTorrents) | FREE |
| Torrentinim | https://github.com/sergiotapia/torrentinim | Very low memory-footprint, self hosted API-only torrent search engine. Sonarr + Radarr Compatible, native support for Linux, Mac and Windows. | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| National Vulnerability Database CVE Search API | https://nvd.nist.gov/developers/vulnerabilities | Get basic information about CVE and CVE history | FREE |
| OpenCVE API | https://docs.opencve.io/api/cve/ | Get basic information about CVE | FREE |
| CVEDetails API | https://www.cvedetails.com/documentation/apis | Get basic information about CVE | partly FREE (?) |
| CVESearch API | https://docs.cvesearch.com/ | Get basic information about CVE | by request |
| KEVin API | https://kevin.gtfkd.com/ | API for accessing CISA's Known Exploited Vulnerabilities Catalog (KEV) and CVE Data | FREE |
| Vulners.com API | https://vulners.com | Get basic information about CVE | FREE for personal use |
| Name | Link | Description | Price |
|---|---|---|---|
| Aviation Stack | https://aviationstack.com | get information about flights, aircrafts and airlines | FREE |
| OpenSky Network | https://opensky-network.org/apidoc/index.html | Free real-time ADS-B aviation data | FREE |
| AviationAPI | https://docs.aviationapi.com/ | FAA Aeronautical Charts and Publications, Airport Information, and Airport Weather | FREE |
| FachaAPI | https://api.facha.dev | Aircraft details and live positioning API | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Windy Webcams API | https://api.windy.com/webcams/docs | Get a list of available webcams for a country, city or geographical coordinates | FREE with limits or 9990 euro without limits |
## Regex
| Name | Link | Description | Price |
|---|---|---|---|
| Autoregex | https://autoregex.notion.site/AutoRegex-API-Documentation-97256bad2c114a6db0c5822860214d3a | Convert English phrase to regular expression | from $3.49/month |
| Name | Link |
|---|---|
| API Guessr (detect API by auth key or by token) | https://api-guesser.netlify.app/ |
| REQBIN Online REST & SOAP API Testing Tool | https://reqbin.com |
| ExtendClass Online REST Client | https://extendsclass.com/rest-client-online.html |
| Codebeatify.org Online API Test | https://codebeautify.org/api-test |
| SyncWith Google Sheet add-on. Link more than 1000 APIs with Spreadsheet | https://workspace.google.com/u/0/marketplace/app/syncwith_crypto_binance_coingecko_airbox/449644239211?hl=ru&pann=sheets_addon_widget |
| Talend API Tester Google Chrome Extension | https://workspace.google.com/u/0/marketplace/app/syncwith_crypto_binance_coingecko_airbox/449644239211?hl=ru&pann=sheets_addon_widget |
| Michael Bazzel APIs search tools | https://inteltechniques.com/tools/API.html |
| Name | Link |
|---|---|
| Convert curl commands to Python, JavaScript, PHP, R, Go, C#, Ruby, Rust, Elixir, Java, MATLAB, Dart, CFML, Ansible URI or JSON | https://curlconverter.com |
| Curl-to-PHP. Instantly convert curl commands to PHP code | https://incarnate.github.io/curl-to-php/ |
| Curl to PHP online (Codebeatify) | https://codebeautify.org/curl-to-php-online |
| Curl to JavaScript fetch | https://kigiri.github.io/fetch/ |
| Curl to JavaScript fetch (Scrapingbee) | https://www.scrapingbee.com/curl-converter/javascript-fetch/ |
| Curl to C# converter | https://curl.olsh.me |
| Name | Link |
|---|---|
| Sheety. Create API frome GOOGLE SHEET | https://sheety.co/ |
| Postman. Platform for creating your own API | https://www.postman.com |
| Reetoo. Rest API Generator | https://retool.com/api-generator/ |
| Beeceptor. Rest API mocking and intercepting in seconds (no coding). | https://beeceptor.com |
| Name | Link |
|---|---|
| RapidAPI. Market your API for millions of developers | https://rapidapi.com/solution/api-provider/ |
| Apilayer. API Marketplace | https://apilayer.com |
| Name | Link | Description |
|---|---|---|
| Keyhacks | https://github.com/streaak/keyhacks | Keyhacks is a repository which shows quick ways in which API keys leaked by a bug bounty program can be checked to see if they're valid. |
| All about APIKey | https://github.com/daffainfo/all-about-apikey | Detailed information about API key / OAuth token for different services (Description, Request, Response, Regex, Example) |
| API Guessr | https://api-guesser.netlify.app/ | Enter API Key and and find out which service they belong to |
| Name | Link | Description |
|---|---|---|
| APIDOG ApiHub | https://apidog.com/apihub/ | |
| Rapid APIs collection | https://rapidapi.com/collections | |
| API Ninjas | https://api-ninjas.com/api | |
| APIs Guru | https://apis.guru/ | |
| APIs List | https://apislist.com/ | |
| API Context Directory | https://apicontext.com/api-directory/ | |
| Any API | https://any-api.com/ | |
| Public APIs Github repo | https://github.com/public-apis/public-apis |
If you don't know how to work with the REST API, I recommend you check out the Netlas API guide I wrote for Netlas.io.
There it is very brief and accessible to write how to automate requests in different programming languages (focus on Python and Bash) and process the resulting JSON data.
Thank you for following me! https://cybdetective.com

OWASP Maryam is a modular open-source framework based on OSINT and data gathering. It is designed to provide a robust environment to harvest data from open sources and search engines quickly and thoroughly.
$ pip install maryam
Alternatively, you can install the latest version with the following command (Recommended):
pip install git+https://github.com/saeeddhqan/maryam.git
# Using dns_search. --max means all of resources. --api shows the results as json.
# .. -t means use multi-threading.
maryam -e dns_search -d ibm.com -t 5 --max --api --form
# Using youtube. -q means query
maryam -e youtube -q "<QUERY>"
maryam -e google -q "<QUERY>"
maryam -e dnsbrute -d domain.tld
# Show framework modules
maryam -e show modules
# Set framework options.
maryam -e set proxy ..
maryam -e set agent ..
maryam -e set timeout ..
# Run web API
maryam -e web api 127.0.0.1 1313
Here is a start guide: Development Guide You can add a new search engine to the util classes or use the current search engines to write a new module. The best help to write a new module is checking the current modules.
To report bugs, requests, or any other issues please create an issue.
![]()
Welcome to TruffleHog Explorer, a user-friendly web-based tool to visualize and analyze data extracted using TruffleHog. TruffleHog is one of the most powerful secrets discovery, classification, validation, and analysis open source tool. In this context, a secret refers to a credential a machine uses to authenticate itself to another machine. This includes API keys, database passwords, private encryption keys, and more.
With an improved UI/UX, powerful filtering options, and export capabilities, this tool helps security professionals efficiently review potential secrets and credentials found in their repositories.
⚠️ This dashboard has been tested only with GitHub TruffleHog JSON outputs. Expect updates soon to support additional formats and platforms.
You can use online version here: TruffleHog Explorer
$ git clone https://github.com/yourusername/trufflehog-explorer.git
$ cd trufflehog-explorer
index.html
Simply open the index.html file in your preferred web browser.
$ open index.html
.json files from TruffleHog output.Happy Securing! 🔒
Clone the repository: bash git clone https://github.com/ALW1EZ/PANO.git cd PANO
Run the application:
./start_pano.sh
start_pano.bat
The startup script will automatically: - Check for updates - Set up the Python environment - Install dependencies - Launch PANO
In order to use Email Lookup transform You need to login with GHunt first. After starting the pano via starter scripts;
source venv/bin/activate
call venv\Scripts\activate
Visual node and edge styling
Timeline Analysis
Temporal relationship analysis
Map Integration
Connected services discovery
Username Analysis
Web presence analysis
Image Analysis
Entities are the fundamental building blocks of PANO. They represent distinct pieces of information that can be connected and analyzed:
📝 Text: Generic text content
Properties System
Transforms are automated operations that process entities to discover new information and relationships:
🔄 Enrichment: Add data to existing entities
Features
Helpers are specialized tools with dedicated UIs for specific investigation tasks:
🔄 Translator: Translate text between languages
Helper Features
We welcome contributions! To contribute to PANO:
Note: We use a single
mainbranch for development. All pull requests should be made directly tomain.
from dataclasses import dataclass
from typing import ClassVar, Dict, Any
from .base import Entity
@dataclass
class PhoneNumber(Entity):
name: ClassVar[str] = "Phone Number"
description: ClassVar[str] = "A phone number entity with country code and validation"
def init_properties(self):
"""Initialize phone number properties"""
self.setup_properties({
"number": str,
"country_code": str,
"carrier": str,
"type": str, # mobile, landline, etc.
"verified": bool
})
def update_label(self):
"""Update the display label"""
self.label = self.format_label(["country_code", "number"])
from dataclasses import dataclass
from typing import ClassVar, List
from .base import Transform
from entities.base import Entity
from entities.phone_number import PhoneNumber
from entities.location import Location
from ui.managers.status_manager import StatusManager
@dataclass
class PhoneLookup(Transform):
name: ClassVar[str] = "Phone Number Lookup"
description: ClassVar[str] = "Lookup phone number details and location"
input_types: ClassVar[List[str]] = ["PhoneNumber"]
output_types: ClassVar[List[str]] = ["Location"]
async def run(self, entity: PhoneNumber, graph) -> List[Entity]:
if not isinstance(entity, PhoneNumber):
return []
status = StatusManager.get()
operation_id = status.start_loading("Phone Lookup")
try:
# Your phone number lookup logic here
# Example: query an API for phone number details
location = Location(properties={
"country": "Example Country",
"region": "Example Region",
"carrier": "Example Carrier",
"source": "PhoneLookup transform"
})
return [location]
except Exception as e:
status.set_text(f"Error during phone lookup: {str(e)}")
return []
finally:
status.stop_loading(operation_id)
from PySide6.QtWidgets import (
QWidget, QVBoxLayout, QHBoxLayout, QPushButton,
QTextEdit, QLabel, QComboBox
)
from .base import BaseHelper
from qasync import asyncSlot
class DummyHelper(BaseHelper):
"""A dummy helper for testing"""
name = "Dummy Helper"
description = "A dummy helper for testing"
def setup_ui(self):
"""Initialize the helper's user interface"""
# Create input text area
self.input_label = QLabel("Input:")
self.input_text = QTextEdit()
self.input_text.setPlaceholderText("Enter text to process...")
self.input_text.setMinimumHeight(100)
# Create operation selector
operation_layout = QHBoxLayout()
self.operation_label = QLabel("Operation:")
self.operation_combo = QComboBox()
self.operation_combo.addItems(["Uppercase", "Lowercase", "Title Case"])
operation_layout.addWidget(self.operation_label)
operation_layout.addWidget(self.operation_combo)
# Create process button
self.process_btn = QPushButton("Process")
self.process_btn.clicked.connect(self.process_text)
# Create output text area
self.output_label = QLabel("Output:")
self.output_text = QTextEdit()
self.output_text.setReadOnly(True)
self.output_text.setMinimumHeight(100)
# Add widgets to main layout
self.main_layout.addWidget(self.input_label)
self.main_layout.addWidget(self.input_text)
self.main_layout.addLayout(operation_layout)
self.main_layout.addWidget(self.process_btn)
self.main_layout.addWidget(self.output_label)
self.main_layout.addWidget(self.output_text)
# Set dialog size
self.resize(400, 500)
@asyncSlot()
async def process_text(self):
"""Process the input text based on selected operation"""
text = self.input_text.toPlainText()
operation = self.operation_combo.currentText()
if operation == "Uppercase":
result = text.upper()
elif operation == "Lowercase":
result = text.lower()
else: # Title Case
result = text.title()
self.output_text.setPlainText(result)
This project is licensed under the Creative Commons Attribution-NonCommercial (CC BY-NC) License.
You are free to: - ✅ Share: Copy and redistribute the material - ✅ Adapt: Remix, transform, and build upon the material
Under these terms: - ℹ️ Attribution: You must give appropriate credit - 🚫 NonCommercial: No commercial use - 🔓 No additional restrictions
Special thanks to all library authors and contributors who made this project possible.
Created by ALW1EZ with AI ❤️

Enhanced version of bellingcat's Telegram Phone Checker!
A Python script to check Telegram accounts using phone numbers or username.
git clone https://github.com/unnohwn/telegram-checker.git
cd telegram-checker
pip install -r requirements.txt
Contents of requirements.txt:
telethon
rich
click
python-dotenv
Or install packages individually:
pip install telethon rich click python-dotenv
First time running the script, you'll need: - Telegram API credentials (get from https://my.telegram.org/apps) - Your Telegram phone number including countrycode + - Verification code (sent to your Telegram)
Run the script:
python telegram_checker.py
Choose from options: 1. Check phone numbers from input 2. Check phone numbers from file 3. Check usernames from input 4. Check usernames from file 5. Clear saved credentials 6. Exit
Results are saved in: - results/ - JSON files with detailed information - profile_photos/ - Downloaded profile pictures
This tool is for educational purposes only. Please respect Telegram's terms of service and user privacy.
MIT License

A powerful Python script that allows you to scrape messages and media from Telegram channels using the Telethon library. Features include real-time continuous scraping, media downloading, and data export capabilities.
___________________ _________
\__ ___/ _____/ / _____/
| | / \ ___ \_____ \
| | \ \_\ \/ \
|____| \______ /_______ /
\/ \/
Before running the script, you'll need:
pip install -r requirements.txt
Contents of requirements.txt:
telethon
aiohttp
asyncio
api_id: A numberapi_hash: A string of letters and numbersKeep these credentials safe, you'll need them to run the script!
git clone https://github.com/unnohwn/telegram-scraper.git
cd telegram-scraper
pip install -r requirements.txt
python telegram-scraper.py
When scraping a channel for the first time, please note:
The script provides an interactive menu with the following options:
You can use either: - Channel username (e.g., channelname) - Channel ID (e.g., -1001234567890)
Data is stored in SQLite databases, one per channel: - Location: ./channelname/channelname.db - Table: messages - id: Primary key - message_id: Telegram message ID - date: Message timestamp - sender_id: Sender's Telegram ID - first_name: Sender's first name - last_name: Sender's last name - username: Sender's username - message: Message text - media_type: Type of media (if any) - media_path: Local path to downloaded media - reply_to: ID of replied message (if any)
Media files are stored in: - Location: ./channelname/media/ - Files are named using message ID or original filename
Data can be exported in two formats: 1. CSV: ./channelname/channelname.csv - Human-readable spreadsheet format - Easy to import into Excel/Google Sheets
./channelname/channelname.json
The continuous scraping feature ([C] option) allows you to: - Monitor channels in real-time - Automatically download new messages - Download media as it's posted - Run indefinitely until interrupted (Ctrl+C) - Maintains state between runs
The script can download: - Photos - Documents - Other media types supported by Telegram - Automatically retries failed downloads - Skips existing files to avoid duplicates
The script includes: - Automatic retry mechanism for failed media downloads - State preservation in case of interruption - Flood control compliance - Error logging for failed operations
Contributions are welcome! Please feel free to submit a Pull Request.
This project is licensed under the MIT License - see the LICENSE file for details.
This tool is for educational purposes only. Make sure to: - Respect Telegram's Terms of Service - Obtain necessary permissions before scraping - Use responsibly and ethically - Comply with data protection regulations

A Python script that allows you to automatically scrape and download stories from your Telegram friends using the Telethon library. The script continuously monitors and saves both photos and videos from stories, along with their metadata.
Due to Telegram API restrictions, this script can only access stories from: - Users you have added to your friend list - Users whose privacy settings allow you to view their stories
This is a limitation of Telegram's API and cannot be bypassed.
Before running the script, you'll need:
pip install -r requirements.txt
Contents of requirements.txt:
telethon
openpyxl
schedule
api_id: A numberapi_hash: A string of letters and numbersKeep these credentials safe, you'll need them to run the script!
git clone https://github.com/unnohwn/telegram-story-scraper.git
cd telegram-story-scraper
pip install -r requirements.txt
python TGSS.py
The script: 1. Connects to your Telegram account 2. Periodically checks for new stories from your friends 3. Downloads any new stories (photos/videos) 4. Stores metadata in a SQLite database 5. Exports information to an Excel file 6. Runs continuously until interrupted (Ctrl+C)
SQLite database containing: - user_id: Telegram user ID of the story creator - story_id: Unique story identifier - timestamp: When the story was posted (UTC+2) - filename: Local filename of the downloaded media
Export file containing the same information as the database, useful for: - Easy viewing of story metadata - Filtering and sorting - Data analysis - Sharing data with others
{user_id}_{story_id}.jpg
{user_id}_{story_id}.{extension}
The script includes: - Automatic retry mechanism for failed downloads - Error logging for failed operations - Connection error handling - State preservation in case of interruption
Contributions are welcome! Please feel free to submit a Pull Request.
This project is licensed under the MIT License - see the LICENSE file for details.
This tool is for educational purposes only. Make sure to: - Respect Telegram's Terms of Service - Obtain necessary permissions before scraping - Use responsibly and ethically - Comply with data protection regulations - Respect user privacy
![]()
This tool is designed to interact with the GitHub API and retrieve specific user details, repository information, and commit emails for a given user.
pip install requestspython3 gitgrab.py
![]()
OSINT Tool for research social media accounts by username
```Install Requests pip install requests
#### Install BeautifulSoup
```Install BeautifulSoup
pip install beautifulsoup4
Execute Snoop python3 snoop.py
![]()
DockerSpy searches for images on Docker Hub and extracts sensitive information such as authentication secrets, private keys, and more.
Docker is an open-source platform that automates the deployment, scaling, and management of applications using containerization technology. Containers allow developers to package an application and its dependencies into a single, portable unit that can run consistently across various computing environments. Docker simplifies the development and deployment process by ensuring that applications run the same way regardless of where they are deployed.
Docker Hub is a cloud-based repository where developers can store, share, and distribute container images. It serves as the largest library of container images, providing access to both official images created by Docker and community-contributed images. Docker Hub enables developers to easily find, download, and deploy pre-built images, facilitating rapid application development and deployment.
Open Source Intelligence (OSINT) on Docker Hub involves using publicly available information to gather insights and data from container images and repositories hosted on Docker Hub. This is particularly important for identifying exposed secrets for several reasons:
Security Audits: By analyzing Docker images, organizations can uncover exposed secrets such as API keys, authentication tokens, and private keys that might have been inadvertently included. This helps in mitigating potential security risks.
Incident Prevention: Proactively searching for exposed secrets in Docker images can prevent security breaches before they happen, protecting sensitive information and maintaining the integrity of applications.
Compliance: Ensuring that container images do not expose secrets is crucial for meeting regulatory and organizational security standards. OSINT helps verify that no sensitive information is unintentionally disclosed.
Vulnerability Assessment: Identifying exposed secrets as part of regular security assessments allows organizations to address these vulnerabilities promptly, reducing the risk of exploitation by malicious actors.
Enhanced Security Posture: Continuously monitoring Docker Hub for exposed secrets strengthens an organization's overall security posture, making it more resilient against potential threats.
Utilizing OSINT on Docker Hub to find exposed secrets enables organizations to enhance their security measures, prevent data breaches, and ensure the confidentiality of sensitive information within their containerized applications.
DockerSpy obtains information from Docker Hub and uses regular expressions to inspect the content for sensitive information, such as secrets.
To use DockerSpy, follow these steps:
git clone https://github.com/UndeadSec/DockerSpy.git && cd DockerSpy && make
dockerspy
To customize DockerSpy configurations, edit the following files: - Regular Expressions - Ignored File Extensions
DockerSpy is intended for educational and research purposes only. Users are responsible for ensuring that their use of this tool complies with applicable laws and regulations.
Contributions to DockerSpy are welcome! Feel free to submit issues, feature requests, or pull requests to help improve this tool.
DockerSpy is developed and maintained by Alisson Moretto (UndeadSec)
I'm a passionate cyber threat intelligence pro who loves sharing insights and crafting cybersecurity tools.
Consider following me:
![]()
![]()
![]()
Special thanks to @akaclandestine
![]()
Most accomplished cybercriminals go out of their way to separate their real names from their hacker handles. But among certain old-school Russian hackers it is not uncommon to find major players who have done little to prevent people from figuring out who they are in real life. A case study in this phenomenon is “x999xx,” the nickname chosen by a venerated Russian hacker who specializes in providing the initial network access to various ransomware groups.
x999xx is a well-known “access broker” who frequently sells access to hacked corporate networks — usually in the form of remote access credentials — as well as compromised databases containing large amounts of personal and financial data.
In an analysis published in February 2019, cyber intelligence firm Flashpoint called x999xx one of the most senior and prolific members of the top-tier Russian-language cybercrime forum Exploit, where x999xx could be seen frequently advertising the sale of stolen databases and network credentials.
In August 2023, x999xx sold access to a company that develops software for the real estate industry. In July 2023, x999xx advertised the sale of Social Security numbers, names, and birthdays for the citizenry of an entire U.S. state (unnamed in the auction).
A month earlier, x999xx posted a sales thread for 80 databases taken from Australia’s largest retail company. “You may use this data to demand a ransom or do something different with it,” x999xx wrote on Exploit. “Unfortunately, the flaw was patched fast. [+] no one has used the data yet [+] the data hasn’t been used to send spam [+] the data is waiting for its time.”
In October 2022, x999xx sold administrative access to a U.S. healthcare provider.
The oldest account by the name x999xx appeared in 2009 on the Russian language cybercrime forum Verified, under the email address maxnm@ozersk.com. Ozersk is a city in the Chelyabinsk region of west-central Russia.
According to the breach tracking service Constella Intelligence, the address maxnm@ozersk.com was used more than a decade ago to create an account at Vktontakte (the Russian answer to Facebook) under the name Maxim Kirtsov from Ozersk. Mr. Kirtsov’s profile — “maxnm” — says his birthday is September 5, 1991.
Personal photos Maxnm shared on Vktontakte in 2016. The caption has been machine translated from Russian.
The user x999xx registered on the Russian language cybercrime community Zloy in 2014 using the email address maxnmalias-1@yahoo.com. Constella says this email address was used in 2022 at the Russian shipping service cdek.ru by a Maksim Georgievich Kirtsov from Ozersk.
Additional searches on these contact details reveal that prior to 2009, x999xx favored the handle Maxnm on Russian cybercrime forums. Cyber intelligence company Intel 471 finds the user Maxnm registered on Zloy in 2006 from an Internet address in Chelyabinsk, using the email address kirtsov@telecom.ozersk.ru.
That same email address was used to create Maxnm accounts on several other crime forums, including Spamdot and Exploit in 2005 (also from Chelyabinsk), and Damagelab in 2006.
A search in Constella for the Russian version of Kirtsov’s full name — Кирцов Максим Георгиевич — brings up multiple accounts registered to maksya@icloud.com.
A review of the digital footprint for maksya@icloud.com at osint.industries reveals this address was used a decade ago to register a still-active account at imageshack.com under the name x999xx. That account features numerous screenshots of financial statements from various banks, chat logs with other hackers, and even hacked websites.
x999xx’s Imageshack account includes screenshots of bank account balances from dozens of financial institutions, as well as chat logs with other hackers and pictures of homegrown weed.
Some of the photos in that Imageshack account also appear on Kirtsov’s Vkontakte page, including images of vehicles he owns, as well as pictures of potted marijuana plants. Kirtsov’s Vkontakte profile says that in 2012 he was a faculty member of the Ozersk Technological Institute National Research Nuclear University.
The Vkontakte page lists Kirtsov’s occupation as a website called ozersk[.]today, which on the surface appears to be a blog about life in Ozersk. However, in 2019 the security firm Recorded Future published a blog post which found this domain was being used to host a malicious Cobalt Strike server.
Cobalt Strike is a commercial network penetration testing and reconnaissance tool that is sold only to vetted partners. But stolen or ill-gotten Cobalt Strike licenses are frequently abused by cybercriminal gangs to help lay the groundwork for the installation of ransomware on a victim network.
In August 2023, x999xx posted a message on Exploit saying he was interested in buying a licensed version of Cobalt Strike. A month earlier, x999xx filed a complaint on Exploit against another forum member named Cobaltforce, an apparent onetime partner whose sudden and prolonged disappearance from the community left x999xx and others in the lurch. Cobaltforce recruited people experienced in using Cobalt Strike for ransomware operations, and offered to monetize access to hacked networks for a share of the profits.
DomainTools.com finds ozersk[.]today was registered to the email address dashin2008@yahoo.com, which also was used to register roughly two dozen other domains, including x999xx[.]biz. Virtually all of those domains were registered to Maxim Kirtsov from Ozersk. Below is a mind map used to track the identities mentioned in this story.
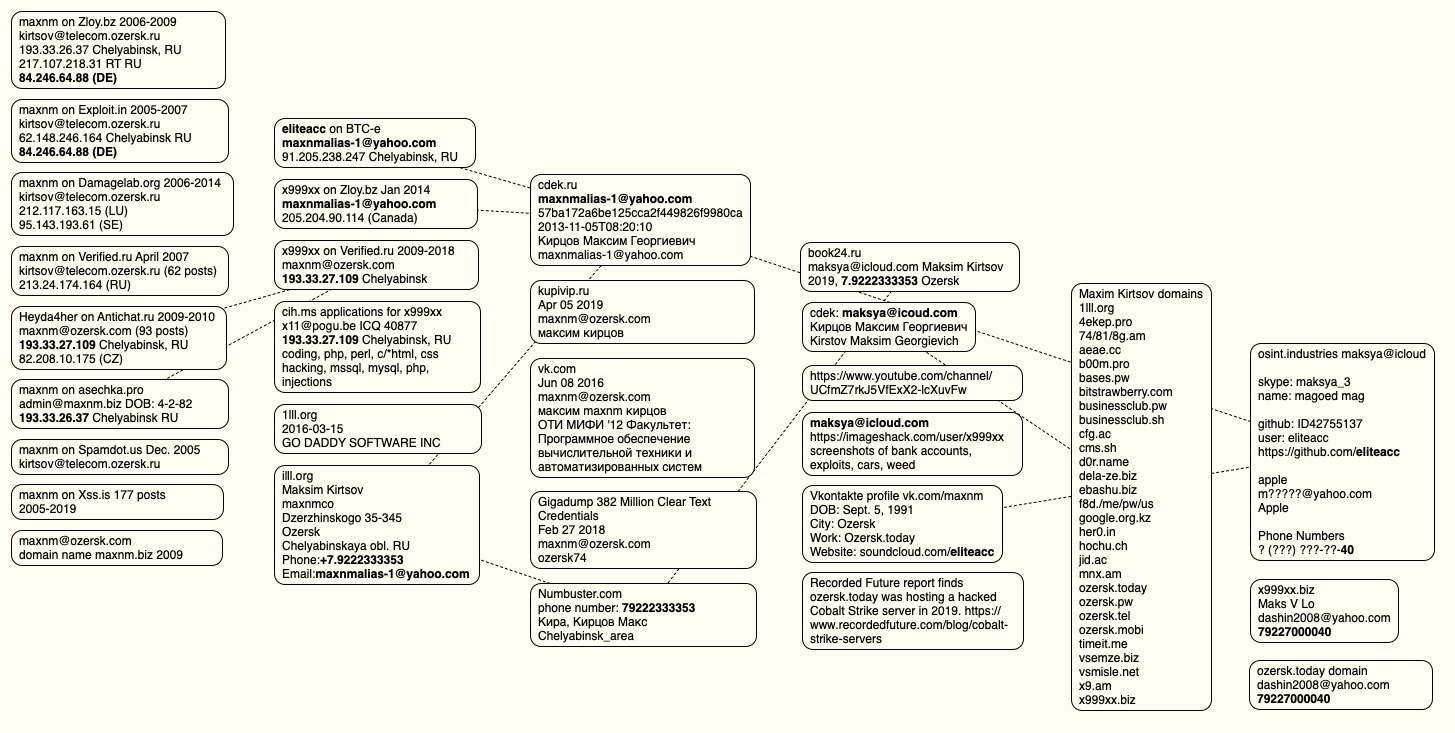
A visual depiction of the data points connecting x999xx to Max Kirtsov.
x999xx is a prolific member of the Russian webmaster forum “Gofuckbiz,” with more than 2,000 posts over nearly a decade, according to Intel 471. In one post from 2016, x999xx asked whether anyone knew where he could buy a heat lamp that simulates sunlight, explaining that one his pet rabbits had recently perished for lack of adequate light and heat. Mr. Kirtsov’s Vkontakte page includes several pictures of caged rabbits from 2015 and earlier.
Reached via email, Mr. Kirtsov acknowledged that he is x999xx. Kirtsov said he and his team are also regular readers of KrebsOnSecurity.
“We’re glad to hear and read you,” Kirtsov replied.
Asked whether he was concerned about the legal and moral implications of his work, Kirtsov downplayed his role in ransomware intrusions, saying he was more focused on harvesting data.
“I consider myself as committed to ethical practices as you are,” Kirtsov wrote. “I have also embarked on research and am currently mentoring students. You may have noticed my activities on a forum, which I assume you know of through information gathered from public sources, possibly using the new tool you reviewed.”
“Regarding my posts about selling access, I must honestly admit, upon reviewing my own actions, I recall such mentions but believe they were never actualized,” he continued. “Many use the forum for self-serving purposes, which explains why listings of targets for sale have dwindled — they simply ceased being viable.”
Kirtsov asserted that he is not interested in harming healthcare institutions, just in stealing their data.
“As for health-related matters, I was once acquainted with affluent webmasters who would pay up to $50 for every 1000 health-themed emails,” Kirtsov said. “Therefore, I had no interest in the more sensitive data from medical institutions like X-rays, insurance numbers, or even names; I focused solely on emails. I am proficient in SQL, hence my ease with handling data like IDs and emails. And i never doing spam or something like this.”
On the Russian crime forums, x999xx said he never targets anything or anyone in Russia, and that he has little to fear from domestic law enforcement agencies provided he remains focused on foreign adversaries.
x999xx’s lackadaisical approach to personal security mirrors that of Wazawaka, another top Russian access broker who sold access to countless organizations and even operated his own ransomware affiliate programs.
“Don’t shit where you live, travel local, and don’t go abroad,” Wazawaka said of his own personal mantra. “Mother Russia will help you. Love your country, and you will always get away with everything.”
In January 2022, KrebsOnSecurity followed clues left behind by Wazawaka to identify him as 32-year-old Mikhail Matveev from Khakassia, Russia. In May 2023, the U.S. Department of Justice indicted Matveev as a key figure in several ransomware groups that collectively extorted hundreds of millions of dollars from victim organizations. The U.S. State Department is offering a $10 million reward for information leading to the capture and/or prosecution of Matveev.
Perhaps in recognition that many top ransomware criminals are largely untouchable so long as they remain in Russia, western law enforcement agencies have begun focusing more on getting inside the heads of those individuals. These so-called “psyops” are aimed at infiltrating ransomware-as-a-service operations, disrupting major cybercrime services, and decreasing trust within cybercriminal communities.
When authorities in the U.S. and U.K. announced in February 2024 that they’d infiltrated and seized the infrastructure used by the infamous LockBit ransomware gang, they borrowed the existing design of LockBit’s victim shaming website to link instead to press releases about the takedown, and included a countdown timer that was eventually replaced with the personal details of LockBit’s alleged leader.
In May 2024, law enforcement agencies in the United States and Europe announced Operation Endgame, a coordinated action against some of the most popular cybercrime platforms for delivering ransomware and data-stealing malware. The Operation Endgame website also included a countdown timer, which served to tease the release of several animated videos that mimic the same sort of flashy, short advertisements that established cybercriminals often produce to promote their services online.
![]()
Pip-Intel is a powerful tool designed for OSINT (Open Source Intelligence) and cyber intelligence gathering activities. It consolidates various open-source tools into a single user-friendly interface simplifying the data collection and analysis processes for researchers and cybersecurity professionals.
Pip-Intel utilizes Python-written pip packages to gather information from various data points. This tool is equipped with the capability to collect detailed information through email addresses, phone numbers, IP addresses, and social media accounts. It offers a wide range of functionalities including email-based OSINT operations, phone number-based inquiries, geolocating IP addresses, social media and user analyses, and even dark web searches.
![]()
![]()
![]()
Free to use IOC feed for various tools/malware. It started out for just C2 tools but has morphed into tracking infostealers and botnets as well. It uses shodan.io/">Shodan searches to collect the IPs. The most recent collection is always stored in data; the IPs are broken down by tool and there is an all.txt.
The feed should update daily. Actively working on making the backend more reliable
Many of the Shodan queries have been sourced from other CTI researchers:
Huge shoutout to them!
Thanks to BertJanCyber for creating the KQL query for ingesting this feed
And finally, thanks to Y_nexro for creating C2Live in order to visualize the data
If you want to host a private version, put your Shodan API key in an environment variable called SHODAN_API_KEY
echo SHODAN_API_KEY=API_KEY >> ~/.bashrc
bash
python3 -m pip install -r requirements.txt
python3 tracker.py
I encourage opening an issue/PR if you know of any additional Shodan searches for identifying adversary infrastructure. I will not set any hard guidelines around what can be submitted, just know, fidelity is paramount (high true/false positive ratio is the focus).

Multi-cloud OSINT tool. Enumerate public resources in AWS, Azure, and Google Cloud.
Currently enumerates the following:
Amazon Web Services: - Open / Protected S3 Buckets - awsapps (WorkMail, WorkDocs, Connect, etc.)
Microsoft Azure: - Storage Accounts - Open Blob Storage Containers - Hosted Databases - Virtual Machines - Web Apps
Google Cloud Platform - Open / Protected GCP Buckets - Open / Protected Firebase Realtime Databases - Google App Engine sites - Cloud Functions (enumerates project/regions with existing functions, then brute forces actual function names) - Open Firebase Apps
See it in action in Codingo's video demo here.
Several non-standard libaries are required to support threaded HTTP requests and dns lookups. You'll need to install the requirements as follows:
pip3 install -r ./requirements.txt
The only required argument is at least one keyword. You can use the built-in fuzzing strings, but you will get better results if you supply your own with -m and/or -b.
You can provide multiple keywords by specifying the -k argument multiple times.
Keywords are mutated automatically using strings from enum_tools/fuzz.txt or a file you provide with the -m flag. Services that require a second-level of brute forcing (Azure Containers and GCP Functions) will also use fuzz.txt by default or a file you provide with the -b flag.
Let's say you were researching "somecompany" whose website is "somecompany.io" that makes a product called "blockchaindoohickey". You could run the tool like this:
./cloud_enum.py -k somecompany -k somecompany.io -k blockchaindoohickey
HTTP scraping and DNS lookups use 5 threads each by default. You can try increasing this, but eventually the cloud providers will rate limit you. Here is an example to increase to 10.
./cloud_enum.py -k keyword -t 10
IMPORTANT: Some resources (Azure Containers, GCP Functions) are discovered per-region. To save time scanning, there is a "REGIONS" variable defined in cloudenum/azure_regions.py and cloudenum/gcp_regions.py that is set by default to use only 1 region. You may want to look at these files and edit them to be relevant to your own work.
Complete Usage Details
usage: cloud_enum.py [-h] -k KEYWORD [-m MUTATIONS] [-b BRUTE]
Multi-cloud enumeration utility. All hail OSINT!
optional arguments:
-h, --help show this help message and exit
-k KEYWORD, --keyword KEYWORD
Keyword. Can use argument multiple times.
-kf KEYFILE, --keyfile KEYFILE
Input file with a single keyword per line.
-m MUTATIONS, --mutations MUTATIONS
Mutations. Default: enum_tools/fuzz.txt
-b BRUTE, --brute BRUTE
List to brute-force Azure container names. Default: enum_tools/fuzz.txt
-t THREADS, --threads THREADS
Threads for HTTP brute-force. Default = 5
-ns NAMESERVER, --nameserver NAMESERVER
DNS server to use in brute-force.
-l LOGFILE, --logfile LOGFILE
Will APPEND found items to specified file.
-f FORMAT, --format FORMAT
Format for log file (text,json,csv - defaults to text)
--disable-aws Disable Amazon checks.
--disable-azure Disable Azure checks.
--disable-gcp Disable Google checks.
-qs, --quickscan Disable all mutations and second-level scans
So far, I have borrowed from: - Some of the permutations from GCPBucketBrute
![]()
During reconaissance phase or when doing OSINT , we often use google dorking and shodan and thus the idea of Dorkish.
Dorkish is a Chrome extension tool that facilitates custom dork creation for Google and Shodan using the builder and it offers prebuilt dorks for efficient reconnaissance and OSINT engagement.
1- Clone the repository
git clone https://github.com/yousseflahouifi/dorkish.git
2- Go to chrome://extensions/ and enable the Developer mode in the top right corner.
3- click on Load unpacked extension button and select the dorkish folder.
Note: For firefox users , you can find the extension here : https://addons.mozilla.org/en-US/firefox/addon/dorkish/
Once you have found or built the dork you need, simply click it and click search. This will direct you to the desired search engine, Shodan or Google, with the specific dork you've entered. Then, you can explore and enjoy the results that match your query.
I have built some dorks and I have used some public resources to gather the dorks , here's few : - https://github.com/lothos612/shodan - https://github.com/TakSec/google-dorks-bug-bounty
![]()
DarkGPT is an artificial intelligence assistant based on GPT-4-200K designed to perform queries on leaked databases. This guide will help you set up and run the project on your local environment.
Before starting, make sure you have Python installed on your system. This project has been tested with Python 3.8 and higher versions.
First, you need to clone the GitHub repository to your local machine. You can do this by executing the following command in your terminal:
git clone https://github.com/luijait/DarkGPT.git cd DarkGPT
You will need to set up some environment variables for the script to work correctly. Copy the .env.example file to a new file named .env:
DEHASHED_API_KEY="your_dehashed_api_key_here"
This project requires certain Python packages to run. Install them by running the following command:
pip install -r requirements.txt 4. Then Run the project: python3 main.py
![]()
SwaggerSpy is a tool designed for automated Open Source Intelligence (OSINT) on SwaggerHub. This project aims to streamline the process of gathering intelligence from APIs documented on SwaggerHub, providing valuable insights for security researchers, developers, and IT professionals.
Swagger is an open-source framework that allows developers to design, build, document, and consume RESTful web services. It simplifies API development by providing a standard way to describe REST APIs using a JSON or YAML format. Swagger enables developers to create interactive documentation for their APIs, making it easier for both developers and non-developers to understand and use the API.
SwaggerHub is a collaborative platform for designing, building, and managing APIs using the Swagger framework. It offers a centralized repository for API documentation, version control, and collaboration among team members. SwaggerHub simplifies the API development lifecycle by providing a unified platform for API design and testing.
Performing OSINT on SwaggerHub is crucial because developers, in their pursuit of efficient API documentation and sharing, may inadvertently expose sensitive information. Here are key reasons why OSINT on SwaggerHub is valuable:
Developer Oversights: Developers might unintentionally include secrets, credentials, or sensitive information in API documentation on SwaggerHub. These oversights can lead to security vulnerabilities and unauthorized access if not identified and addressed promptly.
Security Best Practices: OSINT on SwaggerHub helps enforce security best practices. Identifying and rectifying potential security issues early in the development lifecycle is essential to ensure the confidentiality and integrity of APIs.
Preventing Data Leaks: By systematically scanning SwaggerHub for sensitive information, organizations can proactively prevent data leaks. This is especially crucial in today's interconnected digital landscape where APIs play a vital role in data exchange between services.
Risk Mitigation: Understanding that developers might forget to remove or obfuscate sensitive details in API documentation underscores the importance of continuous OSINT on SwaggerHub. This proactive approach mitigates the risk of unintentional exposure of critical information.
Compliance and Privacy: Many industries have stringent compliance requirements regarding the protection of sensitive data. OSINT on SwaggerHub ensures that APIs adhere to these regulations, promoting a culture of compliance and safeguarding user privacy.
Educational Opportunities: Identifying oversights in SwaggerHub documentation provides educational opportunities for developers. It encourages a security-conscious mindset, fostering a culture of awareness and responsible information handling.
By recognizing that developers can inadvertently expose secrets, OSINT on SwaggerHub becomes an integral part of the overall security strategy, safeguarding against potential threats and promoting a secure API ecosystem.
SwaggerSpy obtains information from SwaggerHub and utilizes regular expressions to inspect API documentation for sensitive information, such as secrets and credentials.
To use SwaggerSpy, follow these steps:
git clone https://github.com/UndeadSec/SwaggerSpy.git
cd SwaggerSpy
pip install -r requirements.txt
python swaggerspy.py searchterm
SwaggerSpy is intended for educational and research purposes only. Users are responsible for ensuring that their use of this tool complies with applicable laws and regulations.
Contributions to SwaggerSpy are welcome! Feel free to submit issues, feature requests, or pull requests to help improve this tool.
SwaggerSpy is developed and maintained by Alisson Moretto (UndeadSec)
I'm a passionate cyber threat intelligence pro who loves sharing insights and crafting cybersecurity tools.
SwaggerSpy is licensed under the MIT License. See the LICENSE file for details.
Special thanks to @Liodeus for providing project inspiration through swaggerHole.

Introducing Uscrapper 2.0, A powerfull OSINT webscrapper that allows users to extract various personal information from a website. It leverages web scraping techniques and regular expressions to extract email addresses, social media links, author names, geolocations, phone numbers, and usernames from both hyperlinked and non-hyperlinked sources on the webpage, supports multithreading to make this process faster, Uscrapper 2.0 is equipped with advanced Anti-webscrapping bypassing modules and supports webcrawling to scrape from various sublinks within the same domain. The tool also provides an option to generate a report containing the extracted details.
Uscrapper extracts the following details from the provided website:
Uscrapper 2.0:
git clone https://github.com/z0m31en7/Uscrapper.git
cd Uscrapper/install/
chmod +x ./install.sh && ./install.sh #For Unix/Linux systemsTo run Uscrapper, use the following command-line syntax:
python Uscrapper-v2.0.py [-h] [-u URL] [-c (INT)] [-t THREADS] [-O] [-ns]
Arguments:
Uscrapper relies on web scraping techniques to extract information from websites. Make sure to use it responsibly and in compliance with the website's terms of service and applicable laws.
The accuracy and completeness of the extracted details depend on the structure and content of the website being analyzed.
To bypass some Anti-Webscrapping methods we have used selenium which can make the overall process slower.
![]()
Pantheon is a GUI application that allows users to display information regarding network cameras in various countries as well as an integrated live-feed for non-protected cameras.
Pantheon allows users to execute an API crawler. There was original functionality without the use of any API's (like Insecam), but Google TOS kept getting in the way of the original scraping mechanism.
git clone https://github.com/josh0xA/Pantheon.gitcd Pantheonpip3 install -r requirements.txtpython3 pantheon.py
chmod +x distros/ubuntu_install.sh./distros/ubuntu_install.shchmod +x distros/debian-kali_install.sh./distros/debian-kali_install.sh(Enter) on a selected IP:Port to establish a Pantheon webview of the camera. (Use this at your own risk)
(Left-click) on a selected IP:Port to view the geolocation of the camera.
(Right-click) on a selected IP:Port to view the HTTP data of the camera (Ctrl+Left-click for Mac).
Adjust the map as you please to see the markers.
The developer of this program, Josh Schiavone, is not resposible for misuse of this data gathering tool. Pantheon simply provides information that can be indexed by any modern search engine. Do not try to establish unauthorized access to live feeds that are password protected - that is illegal. Furthermore, if you do choose to use Pantheon to view a live-feed, do so at your own risk. Pantheon was developed for educational purposes only. For further information, please visit: https://joshschiavone.com/panth_info/panth_ethical_notice.html
MIT License
Copyright (c) Josh Schiavone
![]()
CloakQuest3r is a powerful Python tool meticulously crafted to uncover the true IP address of websites safeguarded by Cloudflare, a widely adopted web security and performance enhancement service. Its core mission is to accurately discern the actual IP address of web servers that are concealed behind Cloudflare's protective shield. Subdomain scanning is employed as a key technique in this pursuit. This tool is an invaluable resource for penetration testers, security professionals, and web administrators seeking to perform comprehensive security assessments and identify vulnerabilities that may be obscured by Cloudflare's security measures.
Key Features:
Real IP Detection: CloakQuest3r excels in the art of discovering the real IP address of web servers employing Cloudflare's services. This crucial information is paramount for conducting comprehensive penetration tests and ensuring the security of web assets.
Subdomain Scanning: Subdomain scanning is harnessed as a fundamental component in the process of finding the real IP address. It aids in the identification of the actual server responsible for hosting the website and its associated subdomains.
Threaded Scanning: To enhance efficiency and expedite the real IP detection process, CloakQuest3r utilizes threading. This feature enables scanning of a substantial list of subdomains without significantly extending the execution time.
Detailed Reporting: The tool provides comprehensive output, including the total number of subdomains scanned, the total number of subdomains found, and the time taken for the scan. Any real IP addresses unveiled during the process are also presented, facilitating in-depth analysis and penetration testing.
With CloakQuest3r, you can confidently evaluate website security, unveil hidden vulnerabilities, and secure your web assets by disclosing the true IP address concealed behind Cloudflare's protective layers.
- Still in the development phase, sometimes it can't detect the real Ip.
- CloakQuest3r combines multiple indicators to uncover real IP addresses behind Cloudflare. While subdomain scanning is a part of the process, we do not assume that all subdomains' A records point to the target host. The tool is designed to provide valuable insights but may not work in every scenario. We welcome any specific suggestions for improvement.
1. False Negatives: CloakReveal3r may not always accurately identify the real IP address behind Cloudflare, particularly for websites with complex network configurations or strict security measures.
2. Dynamic Environments: Websites' infrastructure and configurations can change over time. The tool may not capture these changes, potentially leading to outdated information.
3. Subdomain Variation: While the tool scans subdomains, it doesn't guarantee that all subdomains' A records will point to the pri mary host. Some subdomains may also be protected by Cloudflare.
How to Use:
Run CloudScan with a single command-line argument: the target domain you want to analyze.
git clone https://github.com/spyboy-productions/CloakQuest3r.git
cd CloakQuest3r
pip3 install -r requirements.txt
python cloakquest3r.py example.com
The tool will check if the website is using Cloudflare. If not, it will inform you that subdomain scanning is unnecessary.
If Cloudflare is detected, CloudScan will scan for subdomains and identify their real IP addresses.
You will receive detailed output, including the number of subdomains scanned, the total number of subdomains found, and the time taken for the scan.
Any real IP addresses found will be displayed, allowing you to conduct further analysis and penetration testing.
CloudScan simplifies the process of assessing website security by providing a clear, organized, and informative report. Use it to enhance your security assessments, identify potential vulnerabilities, and secure your web assets.
Run it online on replit.com : https://replit.com/@spyb0y/CloakQuest3r
![]()
Porch Pirate started as a tool to quickly uncover Postman secrets, and has slowly begun to evolve into a multi-purpose reconaissance / OSINT framework for Postman. While existing tools are great proof of concepts, they only attempt to identify very specific keywords as "secrets", and in very limited locations, with no consideration to recon beyond secrets. We realized we required capabilities that were "secret-agnostic", and had enough flexibility to capture false-positives that still provided offensive value.
Porch Pirate enumerates and presents sensitive results (global secrets, unique headers, endpoints, query parameters, authorization, etc), from publicly accessible Postman entities, such as:
python3 -m pip install porch-pirateThe Porch Pirate client can be used to nearly fully conduct reviews on public Postman entities in a quick and simple fashion. There are intended workflows and particular keywords to be used that can typically maximize results. These methodologies can be located on our blog: Plundering Postman with Porch Pirate.
Porch Pirate supports the following arguments to be performed on collections, workspaces, or users.
--globals--collections--requests--urls--dump--raw--curlporch-pirate -s "coca-cola.com"By default, Porch Pirate will display globals from all active and inactive environments if they are defined in the workspace. Provide a -w argument with the workspace ID (found by performing a simple search, or automatic search dump) to extract the workspace's globals, along with other information.
porch-pirate -w abd6bded-ac31-4dd5-87d6-aa4a399071b8When an interesting result has been found with a simple search, we can provide the workspace ID to the -w argument with the --dump command to begin extracting information from the workspace and its collections.
porch-pirate -w abd6bded-ac31-4dd5-87d6-aa4a399071b8 --dumpPorch Pirate can be supplied a simple search term, following the --globals argument. Porch Pirate will dump all relevant workspaces tied to the results discovered in the simple search, but only if there are globals defined. This is particularly useful for quickly identifying potentially interesting workspaces to dig into further.
porch-pirate -s "shopify" --globalsPorch Pirate can be supplied a simple search term, following the --dump argument. Porch Pirate will dump all relevant workspaces and collections tied to the results discovered in the simple search. This is particularly useful for quickly sifting through potentially interesting results.
porch-pirate -s "coca-cola.com" --dumpA particularly useful way to use Porch Pirate is to extract all URLs from a workspace and export them to another tool for fuzzing.
porch-pirate -w abd6bded-ac31-4dd5-87d6-aa4a399071b8 --urlsPorch Pirate will recursively extract all URLs from workspaces and their collections related to a simple search term.
porch-pirate -s "coca-cola.com" --urlsporch-pirate -w abd6bded-ac31-4dd5-87d6-aa4a399071b8 --collectionsporch-pirate -w abd6bded-ac31-4dd5-87d6-aa4a399071b8 --requestsporch-pirate -w abd6bded-ac31-4dd5-87d6-aa4a399071b8 --rawporch-pirate -w WORKSPACE_IDporch-pirate -c COLLECTION_IDporch-pirate -r REQUEST_IDporch-pirate -u USERNAME/TEAMNAMEPorch Pirate can build curl requests when provided with a request ID for easier testing.
porch-pirate -r 11055256-b1529390-18d2-4dce-812f-ee4d33bffd38 --curlporch-pirate -s coca-cola.com --proxy 127.0.0.1:8080p = porchpirate()
print(p.search('coca-cola.com'))p = porchpirate()
print(p.collections('4127fdda-08be-4f34-af0e-a8bdc06efaba'))p = porchpirate()
collections = json.loads(p.collections('4127fdda-08be-4f34-af0e-a8bdc06efaba'))
for collection in collections['data']:
requests = collection['requests']
for r in requests:
request_data = p.request(r['id'])
print(request_data)p = porchpirate()
print(p.workspace_globals('4127fdda-08be-4f34-af0e-a8bdc06efaba'))Other library usage examples can be located in the examples directory, which contains the following examples:
dump_workspace.pyformat_search_results.pyformat_workspace_collections.pyformat_workspace_globals.pyget_collection.pyget_collections.pyget_profile.pyget_request.pyget_statistics.pyget_team.pyget_user.pyget_workspace.pyrecursive_globals_from_search.pyrequest_to_curl.pysearch.pysearch_by_page.pyworkspace_collections.py
OSINT framework focused on gathering information from free tools or resources. The intention is to help people find free OSINT resources. Some of the sites included might require registration or offer more data for $$$, but you should be able to get at least a portion of the available information for no cost.
I originally created this framework with an information security point of view. Since then, the response from other fields and disciplines has been incredible. I would love to be able to include any other OSINT resources, especially from fields outside of infosec. Please let me know about anything that might be missing!
Please visit the framework at the link below and good hunting!
(T) - Indicates a link to a tool that must be installed and run locally
(D) - Google Dork, for more information: Google Hacking
(R) - Requires registration
(M) - Indicates a URL that contains the search term and the URL itself must be edited manually
Follow me on Twitter: @jnordine - https://twitter.com/jnordine
Watch or star the project on Github: https://github.com/lockfale/osint-framework
Feedback or new tool suggestions are extremely welcome! Please feel free to submit a pull request or open an issue on github or reach out on Twitter.
For new resources, please ensure that the site is available for public and free use.
Thank you!
Happy Hunting!

Poastal is an email OSINT tool that provides valuable information on any email address. With Poastal, you can easily input an email address and it will quickly answer several questions, providing you with crucial information.
Make sure you have the requirements installed.
pip install -r requirements.txt
Navigate to the backend folder and run poastal.py to start the Flask app. This points to port:8080.
python poastal.py
Open index.html in the root directory to use the UI.
Enter an email address and see the results.
Test with example@gmail.com.
There's a new GitHub module.
If you open up github.py you'll see a section that asks you to replace it with your own API key.
I hope you find Poastal to be a valuable tool for your OSINT investigations. If you have any feedback or suggestions on how we can improve Poastal, please let me know. I'm always looking for ways to improve this tool to better serve the OSINT community.
![]()
Efficiently finding registered accounts from emails.
Holehe checks if an email is attached to an account on sites like twitter, instagram, imgur and more than 120 others.
pip3 install holehe
git clone https://github.com/megadose/holehe.git
cd holehe/
python3 setup.py installHolehe can be run from the CLI and rapidly embedded within existing python applications.
holehe test@gmail.comimport trio
import httpx
from holehe.modules.social_media.snapchat import snapchat
async def main():
email = "test@gmail.com"
out = []
client = httpx.AsyncClient()
await snapchat(email, client, out)
print(out)
await client.aclose()
trio.run(main)For each module, data is returned in a standard dictionary with the following json-equivalent format :
{
"name": "example",
"rateLimit": false,
"exists": true,
"emailrecovery": "ex****e@gmail.com",
"phoneNumber": "0*******78",
"others": null
}Rate limit? Change your IP.
For BTC Donations : 1FHDM49QfZX6pJmhjLE5tB2K6CaTLMZpXZ
GNU General Public License v3.0
Built for educational purposes only.
| Name | Domain | Method | Frequent Rate Limit |
|---|---|---|---|
| aboutme | about.me | register | ✘ |
| adobe | adobe.com | password recovery | ✘ |
| amazon | amazon.com | login | ✘ |
| amocrm | amocrm.com | register | ✘ |
| anydo | any.do | login | ✔ |
| archive | archive.org | register | ✘ |
| armurerieauxerre | armurerie-auxerre.com | register | ✘ |
| atlassian | atlassian.com | register | ✘ |
| axonaut | axonaut.com | register | ✘ |
| babeshows | babeshows.co.uk | register | ✘ |
| badeggsonline | badeggsonline.com | register | ✘ |
| biosmods | bios-mods.com | register | ✘ |
| biotechnologyforums | biotechnologyforums.com | register | ✘ |
| bitmoji | bitmoji.com | login | ✘ |
| blablacar | blablacar.com | register | ✔ |
| blackworldforum | blackworldforum.com | register | ✔ |
| blip | blip.fm | register | ✔ |
| blitzortung | forum.blitzortung.org | register | ✘ |
| bluegrassrivals | bluegrassrivals.com | register | ✘ |
| bodybuilding | bodybuilding.com | register | ✘ |
| buymeacoffee | buymeacoffee.com | register | ✔ |
| cambridgemt | discussion.cambridge-mt.com | register | ✘ |
| caringbridge | caringbridge.org | register | ✘ |
| chinaphonearena | chinaphonearena.com | register | ✘ |
| clashfarmer | clashfarmer.com | register | ✔ |
| codecademy | codecademy.com | register | ✔ |
| codeigniter | forum.codeigniter.com | register | ✘ |
| codepen | codepen.io | register | ✘ |
| coroflot | coroflot.com | register | ✘ |
| cpaelites | cpaelites.com | register | ✘ |
| cpahero | cpahero.com | register | ✘ |
| cracked_to | cracked.to | register | ✔ |
| crevado | crevado.com | register | ✔ |
| deliveroo | deliveroo.com | register | ✔ |
| demonforums | demonforums.net | register | ✔ |
| devrant | devrant.com | register | ✘ |
| diigo | diigo.com | register | ✘ |
| discord | discord.com | register | ✘ |
| docker | docker.com | register | ✘ |
| dominosfr | dominos.fr | register | ✔ |
| ebay | ebay.com | login | ✔ |
| ello | ello.co | register | ✘ |
| envato | envato.com | register | ✘ |
| eventbrite | eventbrite.com | login | ✘ |
| evernote | evernote.com | login | ✘ |
| fanpop | fanpop.com | register | ✘ |
| firefox | firefox.com | register | ✘ |
| flickr | flickr.com | login | ✘ |
| freelancer | freelancer.com | register | ✘ |
| freiberg | drachenhort.user.stunet.tu-freiberg.de | register | ✘ |
| garmin | garmin.com | register | ✔ |
| github | github.com | register | ✘ |
| google.com | register | ✔ | |
| gravatar | gravatar.com | other | ✘ |
| hubspot | hubspot.com | login | ✘ |
| imgur | imgur.com | register | ✔ |
| insightly | insightly.com | login | ✘ |
| instagram.com | register | ✔ | |
| issuu | issuu.com | register | ✘ |
| koditv | forum.kodi.tv | register | ✘ |
| komoot | komoot.com | register | ✔ |
| laposte | laposte.fr | register | ✘ |
| lastfm | last.fm | register | ✘ |
| lastpass | lastpass.com | register | ✘ |
| mail_ru | mail.ru | password recovery | ✘ |
| mybb | community.mybb.com | register | ✘ |
| myspace | myspace.com | register | ✘ |
| nattyornot | nattyornotforum.nattyornot.com | register | ✘ |
| naturabuy | naturabuy.fr | register | ✘ |
| ndemiccreations | forum.ndemiccreations.com | register | ✘ |
| nextpvr | forums.nextpvr.com | register | ✘ |
| nike | nike.com | register | ✘ |
| nimble | nimble.com | register | ✘ |
| nocrm | nocrm.io | register | ✘ |
| nutshell | nutshell.com | register | ✘ |
| odnoklassniki | ok.ru | password recovery | ✘ |
| office365 | office365.com | other | ✔ |
| onlinesequencer | onlinesequencer.net | register | ✘ |
| parler | parler.com | login | ✘ |
| patreon | patreon.com | login | ✔ |
| pinterest.com | register | ✘ | |
| pipedrive | pipedrive.com | register | ✘ |
| plurk | plurk.com | register | ✘ |
| pornhub | pornhub.com | register | ✘ |
| protonmail | protonmail.ch | other | ✘ |
| quora | quora.com | register | ✘ |
| rambler | rambler.ru | register | ✘ |
| redtube | redtube.com | register | ✘ |
| replit | replit.com | register | ✔ |
| rocketreach | rocketreach.co | register | ✘ |
| samsung | samsung.com | register | ✘ |
| seoclerks | seoclerks.com | register | ✘ |
| sevencups | 7cups.com | register | ✔ |
| smule | smule.com | register | ✔ |
| snapchat | snapchat.com | login | ✘ |
| soundcloud | soundcloud.com | register | ✘ |
| sporcle | sporcle.com | register | ✘ |
| spotify | spotify.com | register | ✔ |
| strava | strava.com | register | ✘ |
| taringa | taringa.net | register | ✔ |
| teamleader | teamleader.com | register | ✘ |
| teamtreehouse | teamtreehouse.com | register | ✘ |
| tellonym | tellonym.me | register | ✘ |
| thecardboard | thecardboard.org | register | ✘ |
| therianguide | forums.therian-guide.com | register | ✘ |
| thevapingforum | thevapingforum.com | register | ✘ |
| tumblr | tumblr.com | register | ✘ |
| tunefind | tunefind.com | register | ✔ |
| twitter.com | register | ✘ | |
| venmo | venmo.com | register | ✔ |
| vivino | vivino.com | register | ✘ |
| voxmedia | voxmedia.com | register | ✘ |
| vrbo | vrbo.com | register | ✘ |
| vsco | vsco.co | register | ✘ |
| wattpad | wattpad.com | register | ✔ |
| wordpress | wordpress | login | ✘ |
| xing.com | register | ✘ | |
| xnxx | xnxx.com | register | ✔ |
| xvideos | xvideos.com | register | ✘ |
| yahoo | yahoo.com | login | ✔ |
| zoho | zoho.com | login | ✔ |

xsubfind3r is a command-line interface (CLI) utility to find domain's known subdomains from curated passive online sources.
Fetches domains from curated passive sources to maximize results.
Supports stdin and stdout for easy integration into workflows.
Cross-Platform (Windows, Linux & macOS).
Visit the releases page and find the appropriate archive for your operating system and architecture. Download the archive from your browser or copy its URL and retrieve it with wget or curl:
...with wget:
wget https://github.com/hueristiq/xsubfind3r/releases/download/v<version>/xsubfind3r-<version>-linux-amd64.tar.gz...or, with curl:
curl -OL https://github.com/hueristiq/xsubfind3r/releases/download/v<version>/xsubfind3r-<version>-linux-amd64.tar.gz...then, extract the binary:
tar xf xsubfind3r-<version>-linux-amd64.tar.gzTIP: The above steps, download and extract, can be combined into a single step with this onliner
curl -sL https://github.com/hueristiq/xsubfind3r/releases/download/v<version>/xsubfind3r-<version>-linux-amd64.tar.gz | tar -xzv
NOTE: On Windows systems, you should be able to double-click the zip archive to extract the xsubfind3r executable.
...move the xsubfind3r binary to somewhere in your PATH. For example, on GNU/Linux and OS X systems:
sudo mv xsubfind3r /usr/local/bin/NOTE: Windows users can follow How to: Add Tool Locations to the PATH Environment Variable in order to add xsubfind3r to their PATH.
Before you install from source, you need to make sure that Go is installed on your system. You can install Go by following the official instructions for your operating system. For this, we will assume that Go is already installed.
go install ...go install -v github.com/hueristiq/xsubfind3r/cmd/xsubfind3r@latestgo build ... the development VersionClone the repository
git clone https://github.com/hueristiq/xsubfind3r.git Build the utility
cd xsubfind3r/cmd/xsubfind3r && \
go build .Move the xsubfind3r binary to somewhere in your PATH. For example, on GNU/Linux and OS X systems:
sudo mv xsubfind3r /usr/local/bin/NOTE: Windows users can follow How to: Add Tool Locations to the PATH Environment Variable in order to add xsubfind3r to their PATH.
NOTE: While the development version is a good way to take a peek at xsubfind3r's latest features before they get released, be aware that it may have bugs. Officially released versions will generally be more stable.
xsubfind3r will work right after installation. However, BeVigil, Chaos, Fullhunt, Github, Intelligence X and Shodan require API keys to work, URLScan supports API key but not required. The API keys are stored in the $HOME/.hueristiq/xsubfind3r/config.yaml file - created upon first run - and uses the YAML format. Multiple API keys can be specified for each of these source from which one of them will be used.
Example config.yaml:
version: 0.3.0
sources:
- alienvault
- anubis
- bevigil
- chaos
- commoncrawl
- crtsh
- fullhunt
- github
- hackertarget
- intelx
- shodan
- urlscan
- wayback
keys:
bevigil:
- awA5nvpKU3N8ygkZ
chaos:
- d23a554bbc1aabb208c9acfbd2dd41ce7fc9db39asdsd54bbc1aabb208c9acfb
fullhunt:
- 0d9652ce-516c-4315-b589-9b241ee6dc24
github:
- d23a554bbc1aabb208c9acfbd2dd41ce7fc9db39
- asdsd54bbc1aabb208c9acfbd2dd41ce7fc9db39
intelx:
- 2.intelx.io:00000000-0000-0000-0000-000000000000
shodan:
- AAAAClP1bJJSRMEYJazgwhJKrggRwKA
urlscan:
- d4c85d34-e425-446e-d4ab-f5a3412acbe8To display help message for xsubfind3r use the -h flag:
xsubfind3r -hhelp message:
_ __ _ _ _____
__ _____ _ _| |__ / _(_)_ __ __| |___ / _ __
\ \/ / __| | | | '_ \| |_| | '_ \ / _` | |_ \| '__|
> <\__ \ |_| | |_) | _| | | | | (_| |___) | |
/_/\_\___/\__,_|_.__/|_| |_|_| |_|\__,_|____/|_| v0.3.0
USAGE:
xsubfind3r [OPTIONS]
INPUT:
-d, --domain string[] target domains
-l, --list string target domains' list file path
SOURCES:
--sources bool list supported sources
-u, --sources-to-use string[] comma(,) separeted sources to use
-e, --sources-to-exclude string[] comma(,) separeted sources to exclude
OPTIMIZATION:
-t, --threads int number of threads (default: 50)
OUTPUT:
--no-color bool disable colored output
-o, --output string output subdomains' file path
-O, --output-directory string output subdomains' directory path
-v, --verbosity string debug, info, warning, error, fatal or silent (default: info)
CONFIGURATION:
-c, --configuration string configuration file path (default: ~/.hueristiq/xsubfind3r/config.yaml)
Issues and Pull Requests are welcome! Check out the contribution guidelines.
This utility is distributed under the MIT license.

xurlfind3r is a command-line interface (CLI) utility to find domain's known URLs from curated passive online sources.
robots.txt snapshots.Visit the releases page and find the appropriate archive for your operating system and architecture. Download the archive from your browser or copy its URL and retrieve it with wget or curl:
...with wget:
wget https://github.com/hueristiq/xurlfind3r/releases/download/v<version>/xurlfind3r-<version>-linux-amd64.tar.gz...or, with curl:
curl -OL https://github.com/hueristiq/xurlfind3r/releases/download/v<version>/xurlfind3r-<version>-linux-amd64.tar.gz...then, extract the binary:
tar xf xurlfind3r-<version>-linux-amd64.tar.gzTIP: The above steps, download and extract, can be combined into a single step with this onliner
curl -sL https://github.com/hueristiq/xurlfind3r/releases/download/v<version>/xurlfind3r-<version>-linux-amd64.tar.gz | tar -xzv
NOTE: On Windows systems, you should be able to double-click the zip archive to extract the xurlfind3r executable.
...move the xurlfind3r binary to somewhere in your PATH. For example, on GNU/Linux and OS X systems:
sudo mv xurlfind3r /usr/local/bin/NOTE: Windows users can follow How to: Add Tool Locations to the PATH Environment Variable in order to add xurlfind3r to their PATH.
Before you install from source, you need to make sure that Go is installed on your system. You can install Go by following the official instructions for your operating system. For this, we will assume that Go is already installed.
go install ...go install -v github.com/hueristiq/xurlfind3r/cmd/xurlfind3r@latestgo build ... the development VersionClone the repository
git clone https://github.com/hueristiq/xurlfind3r.git Build the utility
cd xurlfind3r/cmd/xurlfind3r && \
go build .Move the xurlfind3r binary to somewhere in your PATH. For example, on GNU/Linux and OS X systems:
sudo mv xurlfind3r /usr/local/bin/NOTE: Windows users can follow How to: Add Tool Locations to the PATH Environment Variable in order to add xurlfind3r to their PATH.
NOTE: While the development version is a good way to take a peek at xurlfind3r's latest features before they get released, be aware that it may have bugs. Officially released versions will generally be more stable.
xurlfind3r will work right after installation. However, BeVigil, Github and Intelligence X require API keys to work, URLScan supports API key but not required. The API keys are stored in the $HOME/.hueristiq/xurlfind3r/config.yaml file - created upon first run - and uses the YAML format. Multiple API keys can be specified for each of these source from which one of them will be used.
Example config.yaml:
version: 0.2.0
sources:
- bevigil
- commoncrawl
- github
- intelx
- otx
- urlscan
- wayback
keys:
bevigil:
- awA5nvpKU3N8ygkZ
github:
- d23a554bbc1aabb208c9acfbd2dd41ce7fc9db39
- asdsd54bbc1aabb208c9acfbd2dd41ce7fc9db39
intelx:
- 2.intelx.io:00000000-0000-0000-0000-000000000000
urlscan:
- d4c85d34-e425-446e-d4ab-f5a3412acbe8To display help message for xurlfind3r use the -h flag:
xurlfind3r -hhelp message:
_ __ _ _ _____
__ ___ _ _ __| |/ _(_)_ __ __| |___ / _ __
\ \/ / | | | '__| | |_| | '_ \ / _` | |_ \| '__|
> <| |_| | | | | _| | | | | (_| |___) | |
/_/\_\\__,_|_| |_|_| |_|_| |_|\__,_|____/|_| v0.2.0
USAGE:
xurlfind3r [OPTIONS]
TARGET:
-d, --domain string (sub)domain to match URLs
SCOPE:
--include-subdomains bool match subdomain's URLs
SOURCES:
-s, --sources bool list sources
-u, --use-sources string sources to use (default: bevigil,commoncrawl,github,intelx,otx,urlscan,wayback)
--skip-wayback-robots bool with wayback, skip parsing robots.txt snapshots
--skip-wayback-source bool with wayback , skip parsing source code snapshots
FILTER & MATCH:
-f, --filter string regex to filter URLs
-m, --match string regex to match URLs
OUTPUT:
--no-color bool no color mode
-o, --output string output URLs file path
-v, --verbosity string debug, info, warning, error, fatal or silent (default: info)
CONFIGURATION:
-c, --configuration string configuration file path (default: ~/.hueristiq/xurlfind3r/config.yaml)
xurlfind3r -d hackerone.com --include-subdomains# filter images
xurlfind3r -d hackerone.com --include-subdomains -f '`^https?://[^/]*?/.*\.(jpg|jpeg|png|gif|bmp)(\?[^\s]*)?$`'# match js URLs
xurlfind3r -d hackerone.com --include-subdomains -m '^https?://[^/]*?/.*\.js(\?[^\s]*)?$'Issues and Pull Requests are welcome! Check out the contribution guidelines.
This utility is distributed under the MIT license.

Python 3 script to dump company employees from LinkedIn API
LinkedInDumper is a Python 3 script that dumps employee data from the LinkedIn social networking platform.
The results contain firstname, lastname, position (title), location and a user's profile link. Only 2 API calls are required to retrieve all employees if the company does not have more than 10 employees. Otherwise, we have to paginate through the API results. With the --email-format CLI flag one can define a Python string format to auto generate email addresses based on the retrieved first and last name.
LinkedInDumper talks with the unofficial LinkedIn Voyager API, which requires authentication. Therefore, you must have a valid LinkedIn user account. To keep it simple, LinkedInDumper just expects a cookie value provided by you. Doing it this way, even 2FA protected accounts are supported. Furthermore, you are tasked to provide a LinkedIn company URL to dump employees from.
li_at session cookie value e.g. via developer toolsli_at or temporarily during runtime via the CLI flag --cookie
usage: linkedindumper.py [-h] --url <linkedin-url> [--cookie <cookie>] [--quiet] [--include-private-profiles] [--email-format EMAIL_FORMAT]
options:
-h, --help show this help message and exit
--url <linkedin-url> A LinkedIn company url - https://www.linkedin.com/company/<company>
--cookie <cookie> LinkedIn 'li_at' session cookie
--quiet Show employee results only
--include-private-profiles
Show private accounts too
--email-format Python string format for emails; for example:
[1] john.doe@example.com > '{0}.{1}@example.com'
[2] j.doe@example.com > '{0[0]}.{1}@example.com'
[3] jdoe@example.com > '{0[0]}{1}@example.com'
[4] doe@example.com > '{1}@example.com'
[5] john@example.com > '{0}@example.com'
[6] jd@example.com > '{0[0]}{1[0]}@example.com'
docker run --rm l4rm4nd/linkedindumper:latest --url 'https://www.linkedin.com/company/apple' --cookie <cookie> --email-format '{0}.{1}@apple.de'
# install dependencies
pip install -r requirements.txt
python3 linkedindumper.py --url 'https://www.linkedin.com/company/apple' --cookie <cookie> --email-format '{0}.{1}@apple.de'
The script will return employee data as semi-colon separated values (like CSV):
██▓ ██▓ ███▄ █ ██ ▄█▀▓█████ ▓█████▄ ██▓ ███▄ █ ▓█████▄ █ ██ ███▄ ▄███▓ ██▓███ ▓█████ ██▀███
▓██▒ ▓██▒ ██ ▀█ █ ██▄█▒ ▓█ ▀ ▒██▀ ██▌▓██▒ ██ ▀█ █ ▒██▀ ██▌ ██ ▓██▒▓██▒▀█& #9600; ██▒▓██░ ██▒▓█ ▀ ▓██ ▒ ██▒
▒██░ ▒██▒▓██ ▀█ ██▒▓███▄░ ▒███ ░██ █▌▒██▒▓██ ▀█ ██▒░██ █▌▓██ ▒██░▓██ ▓██░▓██░ ██▓▒▒███ ▓██ ░▄█ ▒
▒██░ ░██░▓██▒ ▐▌██▒▓██ █▄ ▒▓█ ▄ ░▓█▄ ▌&# 9617;██░▓██▒ ▐▌██▒░▓█▄ ▌▓▓█ ░██░▒██ ▒██ ▒██▄█▓▒ ▒▒▓█ ▄ ▒██▀▀█▄
░██████▒░██░▒██░ ▓██░▒██▒ █▄░▒████▒░▒████▓ ░██░▒██░ ▓██░░▒████▓ ▒▒█████▓ ▒██▒ ░██▒▒██▒ ░ ░░▒████& #9618;░██▓ ▒██▒
░ ▒░▓ ░░▓ ░ ▒░ ▒ ▒ ▒ ▒▒ ▓▒░░ ▒░ ░ ▒▒▓ ▒ ░▓ ░ ▒░ ▒ ▒ ▒▒▓ ▒ ░▒▓▒ ▒ ▒ ░ ▒░ ░ ░▒▓▒░ ░ ░░░ ▒░ ░░ ▒▓ ░▒▓░
░ ░ ▒ ░ ▒ ░░ ░░ ░ ▒░░ ░▒ ▒░ ░ ░ ░ ░ ▒ ▒ ▒ ░░ ░░ ░ ▒░ ░ ▒ ▒ ░░▒░ ░ ░ ░ ░ ░░▒ ░ ░ ░ ░ ░▒ ░ ▒░
░ ░ ▒ ░ ░ ░ ░ ░ ░░ ░ ░ ░ ░ ░ ▒ ░ ░ ░ ░ ░ ░ ░ ░░░ ░ ░ ░ ░ ░░ ░ ░░ ░
░ ░ ░ ░ ░ ░ ░ ░ ░ ░ ░ ░ ░ ░ ░ ░ ░
░ ░ ░ by LRVT
[i] Company Name: apple
[i] Company X-ID: 162479
[i] LN Employees: 1000 employees found
[i] Dumping Date: 17/10/2022 13:55:06
[i] Email Format: {0}.{1}@apple.de
Firstname;Lastname;Email;Position;Gender;Location;Profile
Katrin;Honauer;katrin.honauer@apple.com;Software Engineer at Apple;N/A;Heidelberg;https://www.linkedin.com/in/katrin-honauer
Raymond;Chen;raymond.chen@apple.com;Recruiting at Apple;N/A;Austin, Texas Metropolitan Area;https://www.linkedin.com/in/raytherecruiter
[i] Successfully crawled 2 unique apple employee(s). Hurray ^_-
LinkedIn will allow only the first 1,000 search results to be returned when harvesting contact information. You may also need a LinkedIn premium account when you reached the maximum allowed queries for visiting profiles with your freemium LinkedIn account.
Furthermore, not all employee profiles are public. The results vary depending on your used LinkedIn account and whether you are befriended with some employees of the company to crawl or not. Therefore, it is sometimes not possible to retrieve the firstname, lastname and profile url of some employee accounts. The script will not display such profiles, as they contain default values such as "LinkedIn" as firstname and "Member" in the lastname. If you want to include such private profiles, please use the CLI flag --include-private-profiles. Although some accounts may be private, we can obtain the position (title) as well as the location of such accounts. Only firstname, lastname and profile URL are hidden for private LinkedIn accounts.
Finally, LinkedIn users are free to name their profile. An account name can therefore consist of various things such as saluations, abbreviations, emojis, middle names etc. I tried my best to remove some nonsense. However, this is not a complete solution to the general problem. Note that we are not using the official LinkedIn API. This script gathers information from the "unofficial" Voyager API.