![]()
This tool compilation is carefully crafted with the purpose of being useful both for the beginners and veterans from the malware analysis world. It has also proven useful for people trying their luck at the cracking underworld.
It's the ideal complement to be used with the manuals from the site, and to play with the numbered theories mirror.
To be clear, this pack is thought to be the most complete and robust in existence. Some of the pros are:
It contains all the basic (and not so basic) tools that you might need in a real life scenario, be it a simple or a complex one.
The pack is integrated with an Universal Updater made by us from scratch. Thanks to that, we get to mantain all the tools in an automated fashion.
It's really easy to expand and modify: you just have to update the file bin\updater\tools.ini to integrate the tools you use to the updater, and then add the links for your tools to bin\sendto\sendto, so they appear in the context menus.
The installer sets up everything we might need automatically - everything, from the dependencies to the environment variables, and it can even add a scheduled task to update the whole pack of tools weekly.
You can simply download the stable versions from the release section, where you can also find the installer.
Once downloaded, you can update the tools with the Universal Updater that we specifically developed for that sole purpose.
You will find the binary in the folder bin\updater\updater.exe.
This toolkit is composed by 98 apps that cover everything we might need to perform reverse engineering and binary/malware analysis.
Every tool has been downloaded from their original/official websites, but we still recommend you to use them with caution, specially those tools whose official pages are forum threads. Always exercise common sense.
You can check the complete list of tools here.
Pull Requests are welcome. If you'd want to propose big changes, you should first create an Issue about it, so we all can analyze and discuss it. The tools are compressed with 7-zip, and the format used for nomenclature is {name} - {version}.7z

Noia is a web-based tool whose main aim is to ease the process of browsing mobile applications sandbox and directly previewing SQLite databases, images, and more. Powered by frida.re.
Please note that I'm not a programmer, but I'm probably above the median in code-savyness. Try it out, open an issue if you find any problems. PRs are welcome.
npm install -g noia
noia
Explore third-party applications files and directories. Noia shows you details including the access permissions, file type and much more.
View custom binary files. Directly preview SQLite databases, images, and more.
Search application by name.
Search files and directories by name.
Navigate to a custom directory using the ctrl+g shortcut.
Download the application files and directories for further analysis.
Basic iOS support
and more
Noia is available on npm, so just type the following command to install it and run it:
npm install -g noia
noia
Noia is powered by frida.re, thus requires Frida to run.
See: * https://frida.re/docs/android/ * https://frida.re/docs/ios/
Security Warning
This tool is not secure and may include some security vulnerabilities so make sure to isolate the webpage from potential hackers.
MIT

Mobile Helper Framework is a tool that automates the process of identifying the framework/technology used to create a mobile application. Additionally, it assists in finding sensitive information or provides suggestions for working with the identified platform.
The tool searches for files associated with the technologies used in mobile application development, such as configuration files, resource files, and source code files.
Search files:
index.html
cordova.js
cordova_plugins.js
Search file
Andorid files:
libreactnativejni.so
index.android.bundle
iOS files:
main.jsbundle
❗A minimum of Java 8 is required to run Apktool.
pip install -r requirements.txt
python3 mhf.py app.apk|ipa|aab
python3 mobile_helper_framework.py file.apk
[+] App was written in React Native
Do you want analizy the application (y/n) y
Output directory already exists. Skipping decompilation.
Beauty the react code? (y/n) n
Search any info? (y/n) y
==>>Searching possible internal IPs in the file
results.........
==>>Searching possible emails in the file
results.........
==>>Searching possible interesting words in the file
results.........
==>>Searching Private Keys in the file
results.........
==>>Searching high confidential secrets
results.........
==>>Searching possible sensitive URLs in js files
results.........
==>>Searching possible endpoints in js files results.........
This tool uses Apktool for decompilation of Android applications.
This tool renames the .ipa file of iOS applications to .zip and extracts the contents.
| Feature | Note | Cordova | React Native | Native JavaScript | Flutter | Xamarin |
|---|---|---|---|---|---|---|
| JavaScript beautifier | Use this for the first few occasions to see better results. | ✅ | ✅ | ✅ | ||
| Identifying multiple sensitive information | IPs, Private Keys, API Keys, Emails, URLs | ✅ | ✅ | ✅ | ❌ | |
| Cryptographic Functions | ✅ | ✅ | ✅ | ❌ | ❌ | |
| Endpoint extractor | ✅ | ✅ | ✅ | ❌ | ❌ | |
| Automatically detects if the code has been beautified. | ❌ | ❌ | ❌ | |||
| Extracts automatically apk of devices/emulator | ❌ | ❌ | ❌ | ❌ | ❌ | |
| Patching apk | ✅ | |||||
| Extract an APK from a bundle file. | ✅ | ✅ | ✅ | ✅ | ✅ | |
| Detect if JS files are encrypted | ❌ | ❌ | ||||
| Detect if the resources are compressed. | ❌ | Hermes✅ | ❌ | ❌ | XALZ✅ | |
| Detect if the app is split | ❌ | ❌ | ❌ | ❌ | ❌ |
What is patching apk: This tool uses Reflutter, a framework that assists with reverse engineering of Flutter apps using a patched version of the Flutter library.
More information: https://github.com/Impact-I/reFlutter
Split APKs is a technique used by Android to reduce the size of an application and allow users to download and use only the necessary parts of the application.
Instead of downloading a complete application in a single APK file, Split APKs divide the application into several smaller APK files, each of which contains only a part of the application such as resources, code libraries, assets, and configuration files.
adb shell pm path com.package
package:/data/app/com.package-NW8ZbgI5VPzvSZ1NgMa4CQ==/base.apk
package:/data/app/com.package-NW8ZbgI5VPzvSZ1NgMa4CQ==/split_config.arm64_v8a.apk
package:/data/app/com.package-NW8ZbgI5VPzvSZ1NgMa4CQ==/split_config.en.apk
package:/data/app/com.package-NW8ZbgI5VPzvSZ1NgMa4CQ==/split_config.xxhdpi.apk
For example, in Flutter if the application is a Split it's necessary patch split_config.arm64_v8a.apk, this file contains libflutter.so

BREAD (BIOS Reverse Engineering & Advanced Debugging) is an 'injectable' real-mode x86 debugger that can debug arbitrary real-mode code (on real HW) from another PC via serial cable.
BREAD emerged from many failed attempts to reverse engineer legacy BIOS. Given that the vast majority -- if not all -- BIOS analysis is done statically using disassemblers, understanding the BIOS becomes extremely difficult, since there's no way to know the value of registers or memory in a given piece of code.
Despite this, BREAD can also debug arbitrary code in real-mode, such as bootable code or DOS programs too.
This debugger is divided into two parts: the debugger (written entirely in assembly and running on the hardware being debugged) and the bridge, written in C and running on Linux.
The debugger is the injectable code, written in 16-bit real-mode, and can be placed within the BIOS ROM or any other real-mode code. When executed, it sets up the appropriate interrupt handlers, puts the processor in single-step mode, and waits for commands on the serial port.
The bridge, on the other hand, is the link between the debugger and GDB. The bridge communicates with GDB via TCP and forwards the requests/responses to the debugger through the serial port. The idea behind the bridge is to remove the complexity of GDB packets and establish a simpler protocol for communicating with the machine. In addition, the simpler protocol enables the final code size to be smaller, making it easier for the debugger to be injectable into various different environments.
As shown in the following diagram:
+---------+ simple packets +----------+ GDB packets +---------+
| |--------------->| |--------------->| |
| dbg | | bridge | | gdb |
|(real HW)|<---------------| (Linux) |<---------------| (Linux) |
+---------+ serial +----------+ TCP +---------+By implementing the GDB stub, BREAD has many features out-of-the-box. The following commands are supported:
How many? Yes. Since the code being debugged is unaware that it is being debugged, it can interfere with the debugger in several ways, to name a few:
Protected-mode jump: If the debugged code switches to protected-mode, the structures for interrupt handlers, etc. are altered and the debugger will no longer be invoked at that point in the code. However, it is possible that a jump back to real mode (restoring the full previous state) will allow the debugger to work again.
IDT changes: If for any reason the debugged code changes the IDT or its base address, the debugger handlers will not be properly invoked.
Stack: BREAD uses a stack and assumes it exists! It should not be inserted into locations where the stack has not yet been configured.
For BIOS debugging, there are other limitations such as: it is not possible to debug the BIOS code from the very beggining (bootblock), as a minimum setup (such as RAM) is required for BREAD to function correctly. However, it is possible to perform a "warm-reboot" by setting CS:EIP to F000:FFF0. In this scenario, the BIOS initialization can be followed again, as BREAD is already properly loaded. Please note that the "code-path" of BIOS initialization during a warm-reboot may be different from a cold-reboot and the execution flow may not be exactly the same.
Building only requires GNU Make, a C compiler (such as GCC, Clang, or TCC), NASM, and a Linux machine.
The debugger has two modes of operation: polling (default) and interrupt-based:
Polling mode is the simplest approach and should work well in a variety of environments. However, due the polling nature, there is a high CPU usage:
$ git clone https://github.com/Theldus/BREAD.git
$ cd BREAD/
$ makeThe interrupt-based mode optimizes CPU utilization by utilizing UART interrupts to receive new data, instead of constantly polling for it. This results in the CPU remaining in a 'halt' state until receiving commands from the debugger, and thus, preventing it from consuming 100% of the CPU's resources. However, as interrupts are not always enabled, this mode is not set as the default option:
$ git clone https://github.com/Theldus/BREAD.git
$ cd BREAD/
$ make UART_POLLING=noUsing BREAD only requires a serial cable (and yes, your motherboard has a COM header, check the manual) and injecting the code at the appropriate location.
To inject, minimal changes must be made in dbg.asm (the debugger's src). The code's 'ORG' must be changed and also how the code should return (look for ">> CHANGE_HERE <<" in the code for places that need to be changed).
Using an AMI legacy as an example, where the debugger module will be placed in the place of the BIOS logo (0x108200 or FFFF:8210) and the following instructions in the ROM have been replaced with a far call to the module:
...
00017EF2 06 push es
00017EF3 1E push ds
00017EF4 07 pop es
00017EF5 8BD8 mov bx,ax -┐ replaced by: call 0xFFFF:0x8210 (dbg.bin)
00017EF7 B8024F mov ax,0x4f02 -┘
00017EFA CD10 int 0x10
00017EFC 07 pop es
00017EFD C3 ret
...the following patch is sufficient:
diff --git a/dbg.asm b/dbg.asm
index caedb70..88024d3 100644
--- a/dbg.asm
+++ b/dbg.asm
@@ -21,7 +21,7 @@
; SOFTWARE.
[BITS 16]
-[ORG 0x0000] ; >> CHANGE_HERE <<
+[ORG 0x8210] ; >> CHANGE_HERE <<
%include "constants.inc"
@@ -140,8 +140,8 @@ _start:
; >> CHANGE_HERE <<
; Overwritten BIOS instructions below (if any)
- nop
- nop
+ mov ax, 0x4F02
+ int 0x10
nop
nopIt is important to note that if you have altered a few instructions within your ROM to invoke the debugger code, they must be restored prior to returning from the debugger.
The reason for replacing these two instructions is that they are executed just prior to the BIOS displaying the logo on the screen, which is now the debugger, ensuring a few key points:
Finding a good location to call the debugger (where the BIOS has already initialized enough, but not too late) can be challenging, but it is possible.
After this, dbg.bin is ready to be inserted into the correct position in the ROM.
Debugging DOS programs with BREAD is a bit tricky, but possible:
dbg.asm so that DOS understands it as a valid DOS program:times)int 0x20)The following patch addresses this:
diff --git a/dbg.asm b/dbg.asm
index caedb70..b042d35 100644
--- a/dbg.asm
+++ b/dbg.asm
@@ -21,7 +21,10 @@
; SOFTWARE.
[BITS 16]
-[ORG 0x0000] ; >> CHANGE_HERE <<
+[ORG 0x100]
+
+times 40*1024 db 0x90 ; keep some distance,
+ ; 40kB should be enough
%include "constants.inc"
@@ -140,7 +143,7 @@ _start:
; >> CHANGE_HERE <<
; Overwritten BIOS instructions below (if any)
- nop
+ int 0x20 ; DOS interrupt to exit process
nopCreate a bootable FreeDOS (or DOS) floppy image containing just the kernel and the terminal: KERNEL.SYS and COMMAND.COM. Also add to this floppy image the program to be debugged and the DBG.COM (dbg.bin).
The following steps should be taken after creating the image:
bridge already opened (refer to the next section for instructions).DBG.COM.DBG.COM process to continue until it finishes.It is important to note that DOS does not erase the process image after it exits. As a result, the debugger can be configured like any other DOS program and the appropriate breakpoints can be set. The beginning of the debugger is filled with NOPs, so it is anticipated that the new process will not overwrite the debugger's memory, allowing it to continue functioning even after it appears to be "finished". This allows BREaD to debug other programs, including DOS itself.
Bridge is the glue between the debugger and GDB and can be used in different ways, whether on real hardware or virtual machine.
Its parameters are:
Usage: ./bridge [options]
Options:
-s Enable serial through socket, instead of device
-d <path> Replaces the default device path (/dev/ttyUSB0)
(does not work if -s is enabled)
-p <port> Serial port (as socket), default: 2345
-g <port> GDB port, default: 1234
-h This help
If no options are passed the default behavior is:
./bridge -d /dev/ttyUSB0 -g 1234
Minimal recommended usages:
./bridge -s (socket mode, serial on 2345 and GDB on 1234)
./bridge (device mode, serial on /dev/ttyUSB0 and GDB on 1234)
To use it on real hardware, just invoke it without parameters. Optionally, you can change the device path with the -d parameter:
./bridge or ./bridge -d /path/to/device)Single-stepped, you can now connect GDB! and then launch GDB: gdb.For use in a virtual machine, the execution order changes slightly:
./bridge or ./bridge -d /path/to/device)make bochs or make qemu)Single-stepped, you can now connect GDB! and then launch GDB: gdb.In both cases, be sure to run GDB inside the BRIDGE root folder, as there are auxiliary files in this folder for GDB to work properly in 16-bit.
BREAD is always open to the community and willing to accept contributions, whether with issues, documentation, testing, new features, bugfixes, typos, and etc. Welcome aboard.
BREAD is licensed under MIT License. Written by Davidson Francis and (hopefully) other contributors.
Breakpoints are implemented as hardware breakpoints and therefore have a limited number of available breakpoints. In the current implementation, only 1 active breakpoint at a time! ↩
Hardware watchpoints (like breakpoints) are also only supported one at a time. ↩
Please note that debug registers do not work by default on VMs. For bochs, it needs to be compiled with the --enable-x86-debugger=yes flag. For Qemu, it needs to run with KVM enabled: --enable-kvm (make qemu already does this). ↩

This Ghidra Toolkit is a comprehensive suite of tools designed to streamline and automate various tasks associated with running Ghidra in Headless mode. This toolkit provides a wide range of scripts that can be executed both inside and alongside Ghidra, enabling users to perform tasks such as Vulnerability Hunting, Pseudo-code Commenting with ChatGPT and Reporting with Data Visualization on the analyzed codebase. It allows user to load and save their own script and interract with the built-in API of the script.
Headless Mode Automation: The toolkit enables users to seamlessly launch and run Ghidra in Headless mode, allowing for automated and batch processing of code analysis tasks.
Script Repository/Management: The toolkit includes a repository of pre-built scripts that can be executed within Ghidra. These scripts cover a variety of functionalities, empowering users to perform diverse analysis and manipulation tasks. It allows users to load and save their own scripts, providing flexibility and customization options for their specific analysis requirements. Users can easily manage and organize their script collection.
Flexible Input Options: Users can utilize the toolkit to analyze individual files or entire folders containing multiple files. This flexibility enables efficient analysis of both small-scale and large-scale codebases.
Before using this project, make sure you have the following software installed:
pip install sekiryu.In order to use the script you can simply run it against a binary with the options that you want to execute.
sekiryu [-F FILE][OPTIONS]Please note that performing a binary analysis with Ghidra (or any other product) is a relatively slow process. Thus, expect the binary analysis to take several minutes depending on the host performance. If you run Sekiryu against a very large application or a large amount of binary files, be prepared to WAIT
proxy.send_data Scripts are saved in the folder /modules/scripts/ you can simply copy your script there. In the ghidra_pilot.py file you can find the following function which is responsible to run a headless ghidra script:
def exec_headless(file, script):
"""
Execute the headless analysis of ghidra
"""
path = ghidra_path + 'analyzeHeadless'
# Setting variables
tmp_folder = "/tmp/out"
os.mkdir(tmp_folder)
cmd = ' ' + tmp_folder + ' TMP_DIR -import'+ ' '+ file + ' '+ "-postscript "+ script +" -deleteProject"
# Running ghidra with specified file and script
try:
p = subprocess.run([str(path + cmd)], shell=True, capture_output=True)
os.rmdir(tmp_folder)
except KeyError as e:
print(e)
os.rmdir(tmp_folder)The usage is pretty straight forward, you can create your own script then just add a function in the ghidra_pilot.py such as:
def yourfunction(file):
try:
# Setting script
script = "modules/scripts/your_script.py"
# Start the exec_headless function in a new thread
thread = threading.Thread(target=exec_headless, args=(file, script))
thread.start()
thread.join()
except Exception as e:
print(str(e))The file cli.py is responsible for the command-line-interface and allows you to add argument and command associated like this:
analysis_parser.add_argument('[-ShortCMD]', '[--LongCMD]', help="Your Help Message", action="store_true")The xmlrpc.server module is not secure against maliciously constructed data. If you need to parse
untrusted or unauthenticated data see XML vulnerabilities.
A lot of people encouraged me to push further on this tool and improve it. Without you all this project wouldn't have been
the same so it's time for a proper shout-out:
- @JeanBedoul @McProustinet @MilCashh @Aspeak @mrjay @Esbee|sandboxescaper @Rosen @Cyb3rops @RussianPanda @Dr4k0nia
- @Inversecos @Vs1m @djinn @corelanc0d3r @ramishaath @chompie1337
Thanks for your feedback, support, encouragement, test, ideas, time and care.
For more information about Bushido Security, please visit our website: https://www.bushido-sec.com/.
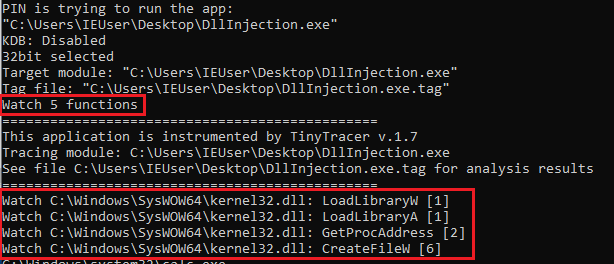
A Pin Tool for tracing:
Bypasses the anti-tracing check based on RDTSC.
Generates a report in a .tag format (which can be loaded into other analysis tools):
RVA;traced eventi.e.
345c2;section: .text
58069;called: C:\Windows\SysWOW64\kernel32.dll.IsProcessorFeaturePresent
3976d;called: C:\Windows\SysWOW64\kernel32.dll.LoadLibraryExW
3983c;called: C:\Windows\SysWOW64\kernel32.dll.GetProcAddress
3999d;called: C:\Windows\SysWOW64\KernelBase.dll.InitializeCriticalSectionEx
398ac;called: C:\Windows\SysWOW64\KernelBase.dll.FlsAlloc
3995d;called: C:\Windows\SysWOW64\KernelBase.dll.FlsSetValue
49275;called: C:\Windows\SysWOW64\kernel32.dll.LoadLibraryExW
4934b;called: C:\Windows\SysWOW64\kernel32.dll.GetProcAddress
...To compile the prepared project you need to use Visual Studio >= 2012. It was tested with Intel Pin 3.28.
Clone this repo into \source\tools that is inside your Pin root directory. Open the project in Visual Studio and build. Detailed description available here.
To build with Intel Pin < 3.26 on Windows, use the appropriate legacy Visual Studio project.
For now the support for Linux is experimental. Yet it is possible to build and use Tiny Tracer on Linux as well. Please refer tiny_runner.sh for more information. Detailed description available here.
Details about the usage you will find on the project's Wiki.
install32_64 you can find a utility that checks if Kernel Debugger is disabled (kdb_check.exe, source), and it is used by the Tiny Tracer's .bat scripts. This utilty sometimes gets flagged as a malware by Windows Defender (it is a known false positive). If you encounter this issue, you may need to exclude the installation directory from Windows Defender scans.Questions? Ideas? Join Discussions!