An intermittent outage at Cloudflare on Tuesday briefly knocked many of the Internet’s top destinations offline. Some affected Cloudflare customers were able to pivot away from the platform temporarily so that visitors could still access their websites. But security experts say doing so may have also triggered an impromptu network penetration test for organizations that have come to rely on Cloudflare to block many types of abusive and malicious traffic.
![]()
At around 6:30 EST/11:30 UTC on Nov. 18, Cloudflare’s status page acknowledged the company was experiencing “an internal service degradation.” After several hours of Cloudflare services coming back up and failing again, many websites behind Cloudflare found they could not migrate away from using the company’s services because the Cloudflare portal was unreachable and/or because they also were getting their domain name system (DNS) services from Cloudflare.
However, some customers did manage to pivot their domains away from Cloudflare during the outage. And many of those organizations probably need to take a closer look at their web application firewall (WAF) logs during that time, said Aaron Turner, a faculty member at IANS Research.
Turner said Cloudflare’s WAF does a good job filtering out malicious traffic that matches any one of the top ten types of application-layer attacks, including credential stuffing, cross-site scripting, SQL injection, bot attacks and API abuse. But he said this outage might be a good opportunity for Cloudflare customers to better understand how their own app and website defenses may be failing without Cloudflare’s help.
“Your developers could have been lazy in the past for SQL injection because Cloudflare stopped that stuff at the edge,” Turner said. “Maybe you didn’t have the best security QA [quality assurance] for certain things because Cloudflare was the control layer to compensate for that.”
Turner said one company he’s working with saw a huge increase in log volume and they are still trying to figure out what was “legit malicious” versus just noise.
“It looks like there was about an eight hour window when several high-profile sites decided to bypass Cloudflare for the sake of availability,” Turner said. “Many companies have essentially relied on Cloudflare for the OWASP Top Ten [web application vulnerabilities] and a whole range of bot blocking. How much badness could have happened in that window? Any organization that made that decision needs to look closely at any exposed infrastructure to see if they have someone persisting after they’ve switched back to Cloudflare protections.”
Turner said some cybercrime groups likely noticed when an online merchant they normally stalk stopped using Cloudflare’s services during the outage.
“Let’s say you were an attacker, trying to grind your way into a target, but you felt that Cloudflare was in the way in the past,” he said. “Then you see through DNS changes that the target has eliminated Cloudflare from their web stack due to the outage. You’re now going to launch a whole bunch of new attacks because the protective layer is no longer in place.”
Nicole Scott, senior product marketing manager at the McLean, Va. based Replica Cyber, called yesterday’s outage “a free tabletop exercise, whether you meant to run one or not.”
“That few-hour window was a live stress test of how your organization routes around its own control plane and shadow IT blossoms under the sunlamp of time pressure,” Scott said in a post on LinkedIn. “Yes, look at the traffic that hit you while protections were weakened. But also look hard at the behavior inside your org.”
Scott said organizations seeking security insights from the Cloudflare outage should ask themselves:
1. What was turned off or bypassed (WAF, bot protections, geo blocks), and for how long?
2. What emergency DNS or routing changes were made, and who approved them?
3. Did people shift work to personal devices, home Wi-Fi, or unsanctioned Software-as-a-Service providers to get around the outage?
4. Did anyone stand up new services, tunnels, or vendor accounts “just for now”?
5. Is there a plan to unwind those changes, or are they now permanent workarounds?
6. For the next incident, what’s the intentional fallback plan, instead of decentralized improvisation?
In a postmortem published Tuesday evening, Cloudflare said the disruption was not caused, directly or indirectly, by a cyberattack or malicious activity of any kind.
“Instead, it was triggered by a change to one of our database systems’ permissions which caused the database to output multiple entries into a ‘feature file’ used by our Bot Management system,” Cloudflare CEO Matthew Prince wrote. “That feature file, in turn, doubled in size. The larger-than-expected feature file was then propagated to all the machines that make up our network.”
Cloudflare estimates that roughly 20 percent of websites use its services, and with much of the modern web relying heavily on a handful of other cloud providers including AWS and Azure, even a brief outage at one of these platforms can create a single point of failure for many organizations.
Martin Greenfield, CEO at the IT consultancy Quod Orbis, said Tuesday’s outage was another reminder that many organizations may be putting too many of their eggs in one basket.
“There are several practical and overdue fixes,” Greenfield advised. “Split your estate. Spread WAF and DDoS protection across multiple zones. Use multi-vendor DNS. Segment applications so a single provider outage doesn’t cascade. And continuously monitor controls to detect single-vendor dependency.”
For the past week, domains associated with the massive Aisuru botnet have repeatedly usurped Amazon, Apple, Google and Microsoft in Cloudflare’s public ranking of the most frequently requested websites. Cloudflare responded by redacting Aisuru domain names from their top websites list. The chief executive at Cloudflare says Aisuru’s overlords are using the botnet to boost their malicious domain rankings, while simultaneously attacking the company’s domain name system (DNS) service.
The #1 and #3 positions in this chart are Aisuru botnet controllers with their full domain names redacted. Source: radar.cloudflare.com.
Aisuru is a rapidly growing botnet comprising hundreds of thousands of hacked Internet of Things (IoT) devices, such as poorly secured Internet routers and security cameras. The botnet has increased in size and firepower significantly since its debut in 2024, demonstrating the ability to launch record distributed denial-of-service (DDoS) attacks nearing 30 terabits of data per second.
Until recently, Aisuru’s malicious code instructed all infected systems to use DNS servers from Google — specifically, the servers at 8.8.8.8. But in early October, Aisuru switched to invoking Cloudflare’s main DNS server — 1.1.1.1 — and over the past week domains used by Aisuru to control infected systems started populating Cloudflare’s top domain rankings.
As screenshots of Aisuru domains claiming two of the Top 10 positions ping-ponged across social media, many feared this was yet another sign that an already untamable botnet was running completely amok. One Aisuru botnet domain that sat prominently for days at #1 on the list was someone’s street address in Massachusetts followed by “.com”. Other Aisuru domains mimicked those belonging to major cloud providers.
Cloudflare tried to address these security, brand confusion and privacy concerns by partially redacting the malicious domains, and adding a warning at the top of its rankings:
“Note that the top 100 domains and trending domains lists include domains with organic activity as well as domains with emerging malicious behavior.”
![]()
Cloudflare CEO Matthew Prince told KrebsOnSecurity the company’s domain ranking system is fairly simplistic, and that it merely measures the volume of DNS queries to 1.1.1.1.
“The attacker is just generating a ton of requests, maybe to influence the ranking but also to attack our DNS service,” Prince said, adding that Cloudflare has heard reports of other large public DNS services seeing similar uptick in attacks. “We’re fixing the ranking to make it smarter. And, in the meantime, redacting any sites we classify as malware.”
Renee Burton, vice president of threat intel at the DNS security firm Infoblox, said many people erroneously assumed that the skewed Cloudflare domain rankings meant there were more bot-infected devices than there were regular devices querying sites like Google and Apple and Microsoft.
“Cloudflare’s documentation is clear — they know that when it comes to ranking domains you have to make choices on how to normalize things,” Burton wrote on LinkedIn. “There are many aspects that are simply out of your control. Why is it hard? Because reasons. TTL values, caching, prefetching, architecture, load balancing. Things that have shared control between the domain owner and everything in between.”
Alex Greenland is CEO of the anti-phishing and security firm Epi. Greenland said he understands the technical reason why Aisuru botnet domains are showing up in Cloudflare’s rankings (those rankings are based on DNS query volume, not actual web visits). But he said they’re still not meant to be there.
“It’s a failure on Cloudflare’s part, and reveals a compromise of the trust and integrity of their rankings,” he said.
Greenland said Cloudflare planned for its Domain Rankings to list the most popular domains as used by human users, and it was never meant to be a raw calculation of query frequency or traffic volume going through their 1.1.1.1 DNS resolver.
“They spelled out how their popularity algorithm is designed to reflect real human use and exclude automated traffic (they said they’re good at this),” Greenland wrote on LinkedIn. “So something has evidently gone wrong internally. We should have two rankings: one representing trust and real human use, and another derived from raw DNS volume.”
Why might it be a good idea to wholly separate malicious domains from the list? Greenland notes that Cloudflare Domain Rankings see widespread use for trust and safety determination, by browsers, DNS resolvers, safe browsing APIs and things like TRANCO.
“TRANCO is a respected open source list of the top million domains, and Cloudflare Radar is one of their five data providers,” he continued. “So there can be serious knock-on effects when a malicious domain features in Cloudflare’s top 10/100/1000/million. To many people and systems, the top 10 and 100 are naively considered safe and trusted, even though algorithmically-defined top-N lists will always be somewhat crude.”
Over this past week, Cloudflare started redacting portions of the malicious Aisuru domains from its Top Domains list, leaving only their domain suffix visible. Sometime in the past 24 hours, Cloudflare appears to have begun hiding the malicious Aisuru domains entirely from the web version of that list. However, downloading a spreadsheet of the current Top 200 domains from Cloudflare Radar shows an Aisuru domain still at the very top.
According to Cloudflare’s website, the majority of DNS queries to the top Aisuru domains — nearly 52 percent — originated from the United States. This tracks with my reporting from early October, which found Aisuru was drawing most of its firepower from IoT devices hosted on U.S. Internet providers like AT&T, Comcast and Verizon.
Experts tracking Aisuru say the botnet relies on well more than a hundred control servers, and that for the moment at least most of those domains are registered in the .su top-level domain (TLD). Dot-su is the TLD assigned to the former Soviet Union (.su’s Wikipedia page says the TLD was created just 15 months before the fall of the Berlin wall).
A Cloudflare blog post from October 27 found that .su had the highest “DNS magnitude” of any TLD, referring to a metric estimating the popularity of a TLD based on the number of unique networks querying Cloudflare’s 1.1.1.1 resolver. The report concluded that the top .su hostnames were associated with a popular online world-building game, and that more than half of the queries for that TLD came from the United States, Brazil and Germany [it’s worth noting that servers for the world-building game Minecraft were some of Aisuru’s most frequent targets].
A simple and crude way to detect Aisuru bot activity on a network may be to set an alert on any systems attempting to contact domains ending in .su. This TLD is frequently abused for cybercrime and by cybercrime forums and services, and blocking access to it entirely is unlikely to raise any legitimate complaints.
KrebsOnSecurity last week was hit by a near record distributed denial-of-service (DDoS) attack that clocked in at more than 6.3 terabits of data per second (a terabit is one trillion bits of data). The brief attack appears to have been a test run for a massive new Internet of Things (IoT) botnet capable of launching crippling digital assaults that few web destinations can withstand. Read on for more about the botnet, the attack, and the apparent creator of this global menace.
![]()
For reference, the 6.3 Tbps attack last week was ten times the size of the assault launched against this site in 2016 by the Mirai IoT botnet, which held KrebsOnSecurity offline for nearly four days. The 2016 assault was so large that Akamai – which was providing pro-bono DDoS protection for KrebsOnSecurity at the time — asked me to leave their service because the attack was causing problems for their paying customers.
Since the Mirai attack, KrebsOnSecurity.com has been behind the protection of Project Shield, a free DDoS defense service that Google provides to websites offering news, human rights, and election-related content. Google Security Engineer Damian Menscher told KrebsOnSecurity the May 12 attack was the largest Google has ever handled. In terms of sheer size, it is second only to a very similar attack that Cloudflare mitigated and wrote about in April.
After comparing notes with Cloudflare, Menscher said the botnet that launched both attacks bears the fingerprints of Aisuru, a digital siege machine that first surfaced less than a year ago. Menscher said the attack on KrebsOnSecurity lasted less than a minute, hurling large UDP data packets at random ports at a rate of approximately 585 million data packets per second.
“It was the type of attack normally designed to overwhelm network links,” Menscher said, referring to the throughput connections between and among various Internet service providers (ISPs). “For most companies, this size of attack would kill them.”
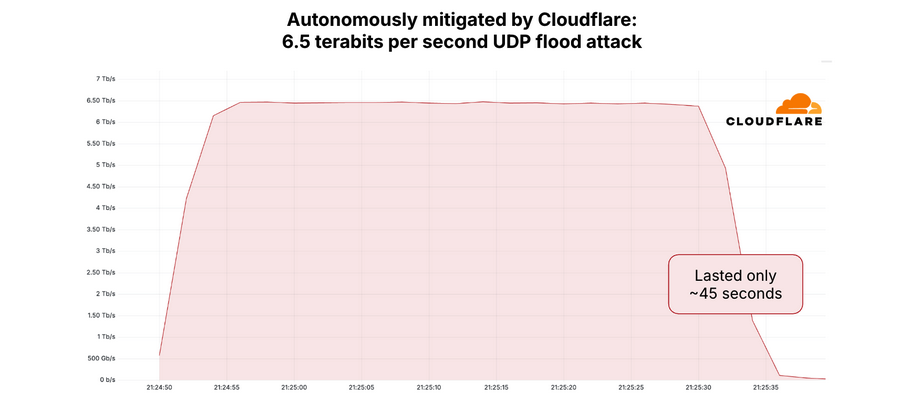
A graph depicting the 6.5 Tbps attack mitigated by Cloudflare in April 2025. Image: Cloudflare.
The Aisuru botnet comprises a globally-dispersed collection of hacked IoT devices, including routers, digital video recorders and other systems that are commandeered via default passwords or software vulnerabilities. As documented by researchers at QiAnXin XLab, the botnet was first identified in an August 2024 attack on a large gaming platform.
Aisuru reportedly went quiet after that exposure, only to reappear in November with even more firepower and software exploits. In a January 2025 report, XLab found the new and improved Aisuru (a.k.a. “Airashi“) had incorporated a previously unknown zero-day vulnerability in Cambium Networks cnPilot routers.
The people behind the Aisuru botnet have been peddling access to their DDoS machine in public Telegram chat channels that are closely monitored by multiple security firms. In August 2024, the botnet was rented out in subscription tiers ranging from $150 per day to $600 per week, offering attacks of up to two terabits per second.
“You may not attack any measurement walls, healthcare facilities, schools or government sites,” read a notice posted on Telegram by the Aisuru botnet owners in August 2024.
Interested parties were told to contact the Telegram handle “@yfork” to purchase a subscription. The account @yfork previously used the nickname “Forky,” an identity that has been posting to public DDoS-focused Telegram channels since 2021.
According to the FBI, Forky’s DDoS-for-hire domains have been seized in multiple law enforcement operations over the years. Last year, Forky said on Telegram he was selling the domain stresser[.]best, which saw its servers seized by the FBI in 2022 as part of an ongoing international law enforcement effort aimed at diminishing the supply of and demand for DDoS-for-hire services.
“The operator of this service, who calls himself ‘Forky,’ operates a Telegram channel to advertise features and communicate with current and prospective DDoS customers,” reads an FBI seizure warrant (PDF) issued for stresser[.]best. The FBI warrant stated that on the same day the seizures were announced, Forky posted a link to a story on this blog that detailed the domain seizure operation, adding the comment, “We are buying our new domains right now.”
A screenshot from the FBI’s seizure warrant for Forky’s DDoS-for-hire domains shows Forky announcing the resurrection of their service at new domains.
Approximately ten hours later, Forky posted again, including a screenshot of the stresser[.]best user dashboard, instructing customers to use their saved passwords for the old website on the new one.
A review of Forky’s posts to public Telegram channels — as indexed by the cyber intelligence firms Unit 221B and Flashpoint — reveals a 21-year-old individual who claims to reside in Brazil [full disclosure: Flashpoint is currently an advertiser on this blog].
Since late 2022, Forky’s posts have frequently promoted a DDoS mitigation company and ISP that he operates called botshield[.]io. The Botshield website is connected to a business entity registered in the United Kingdom called Botshield LTD, which lists a 21-year-old woman from Sao Paulo, Brazil as the director. Internet routing records indicate Botshield (AS213613) currently controls several hundred Internet addresses that were allocated to the company earlier this year.
Domaintools.com reports that botshield[.]io was registered in July 2022 to a Kaike Southier Leite in Sao Paulo. A LinkedIn profile by the same name says this individual is a network specialist from Brazil who works in “the planning and implementation of robust network infrastructures, with a focus on security, DDoS mitigation, colocation and cloud server services.”
Image: Jaclyn Vernace / Shutterstock.com.
In his posts to public Telegram chat channels, Forky has hardly attempted to conceal his whereabouts or identity. In countless chat conversations indexed by Unit 221B, Forky could be seen talking about everyday life in Brazil, often remarking on the extremely low or high prices in Brazil for a range of goods, from computer and networking gear to narcotics and food.
Reached via Telegram, Forky claimed he was “not involved in this type of illegal actions for years now,” and that the project had been taken over by other unspecified developers. Forky initially told KrebsOnSecurity he had been out of the botnet scene for years, only to concede this wasn’t true when presented with public posts on Telegram from late last year that clearly showed otherwise.
Forky denied being involved in the attack on KrebsOnSecurity, but acknowledged that he helped to develop and market the Aisuru botnet. Forky claims he is now merely a staff member for the Aisuru botnet team, and that he stopped running the botnet roughly two months ago after starting a family. Forky also said the woman named as director of Botshield is related to him.
Forky offered equivocal, evasive responses to a number of questions about the Aisuru botnet and his business endeavors. But on one point he was crystal clear:
“I have zero fear about you, the FBI, or Interpol,” Forky said, asserting that he is now almost entirely focused on their hosting business — Botshield.
Forky declined to discuss the makeup of his ISP’s clientele, or to clarify whether Botshield was more of a hosting provider or a DDoS mitigation firm. However, Forky has posted on Telegram about Botshield successfully mitigating large DDoS attacks launched against other DDoS-for-hire services.
DomainTools finds the same Sao Paulo street address in the registration records for botshield[.]io was used to register several other domains, including cant-mitigate[.]us. The email address in the WHOIS records for that domain is forkcontato@gmail.com, which DomainTools says was used to register the domain for the now-defunct DDoS-for-hire service stresser[.]us, one of the domains seized in the FBI’s 2023 crackdown.
On May 8, 2023, the U.S. Department of Justice announced the seizure of stresser[.]us, along with a dozen other domains offering DDoS services. The DOJ said ten of the 13 domains were reincarnations of services that were seized during a prior sweep in December, which targeted 48 top stresser services (also known as “booters”).
Forky claimed he could find out who attacked my site with Aisuru. But when pressed a day later on the question, Forky said he’d come up empty-handed.
“I tried to ask around, all the big guys are not retarded enough to attack you,” Forky explained in an interview on Telegram. “I didn’t have anything to do with it. But you are welcome to write the story and try to put the blame on me.”
The 6.3 Tbps attack last week caused no visible disruption to this site, in part because it was so brief — lasting approximately 45 seconds. DDoS attacks of such magnitude and brevity typically are produced when botnet operators wish to test or demonstrate their firepower for the benefit of potential buyers. Indeed, Google’s Menscher said it is likely that both the May 12 attack and the slightly larger 6.5 Tbps attack against Cloudflare last month were simply tests of the same botnet’s capabilities.
In many ways, the threat posed by the Aisuru/Airashi botnet is reminiscent of Mirai, an innovative IoT malware strain that emerged in the summer of 2016 and successfully out-competed virtually all other IoT malware strains in existence at the time.
As first revealed by KrebsOnSecurity in January 2017, the Mirai authors were two U.S. men who co-ran a DDoS mitigation service — even as they were selling far more lucrative DDoS-for-hire services using the most powerful botnet on the planet.
Less than a week after the Mirai botnet was used in a days-long DDoS against KrebsOnSecurity, the Mirai authors published the source code to their botnet so that they would not be the only ones in possession of it in the event of their arrest by federal investigators.
Ironically, the leaking of the Mirai source is precisely what led to the eventual unmasking and arrest of the Mirai authors, who went on to serve probation sentences that required them to consult with FBI investigators on DDoS investigations. But that leak also rapidly led to the creation of dozens of Mirai botnet clones, many of which were harnessed to fuel their own powerful DDoS-for-hire services.
Menscher told KrebsOnSecurity that as counterintuitive as it may sound, the Internet as a whole would probably be better off if the source code for Aisuru became public knowledge. After all, he said, the people behind Aisuru are in constant competition with other IoT botnet operators who are all striving to commandeer a finite number of vulnerable IoT devices globally.
Such a development would almost certainly cause a proliferation of Aisuru botnet clones, he said, but at least then the overall firepower from each individual botnet would be greatly diminished — or at least within range of the mitigation capabilities of most DDoS protection providers.
Barring a source code leak, Menscher said, it would be nice if someone published the full list of software exploits being used by the Aisuru operators to grow their botnet so quickly.
“Part of the reason Mirai was so dangerous was that it effectively took out competing botnets,” he said. “This attack somehow managed to compromise all these boxes that nobody else knows about. Ideally, we’d want to see that fragmented out, so that no [individual botnet operator] controls too much.”
The payment card giant MasterCard just fixed a glaring error in its domain name server settings that could have allowed anyone to intercept or divert Internet traffic for the company by registering an unused domain name. The misconfiguration persisted for nearly five years until a security researcher spent $300 to register the domain and prevent it from being grabbed by cybercriminals.
A DNS lookup on the domain az.mastercard.com on Jan. 14, 2025 shows the mistyped domain name a22-65.akam.ne.
From June 30, 2020 until January 14, 2025, one of the core Internet servers that MasterCard uses to direct traffic for portions of the mastercard.com network was misnamed. MasterCard.com relies on five shared Domain Name System (DNS) servers at the Internet infrastructure provider Akamai [DNS acts as a kind of Internet phone book, by translating website names to numeric Internet addresses that are easier for computers to manage].
All of the Akamai DNS server names that MasterCard uses are supposed to end in “akam.net” but one of them was misconfigured to rely on the domain “akam.ne.”
This tiny but potentially critical typo was discovered recently by Philippe Caturegli, founder of the security consultancy Seralys. Caturegli said he guessed that nobody had yet registered the domain akam.ne, which is under the purview of the top-level domain authority for the West Africa nation of Niger.
Caturegli said it took $300 and nearly three months of waiting to secure the domain with the registry in Niger. After enabling a DNS server on akam.ne, he noticed hundreds of thousands of DNS requests hitting his server each day from locations around the globe. Apparently, MasterCard wasn’t the only organization that had fat-fingered a DNS entry to include “akam.ne,” but they were by far the largest.
Had he enabled an email server on his new domain akam.ne, Caturegli likely would have received wayward emails directed toward mastercard.com or other affected domains. If he’d abused his access, he probably could have obtained website encryption certificates (SSL/TLS certs) that were authorized to accept and relay web traffic for affected websites. He may even have been able to passively receive Microsoft Windows authentication credentials from employee computers at affected companies.
But the researcher said he didn’t attempt to do any of that. Instead, he alerted MasterCard that the domain was theirs if they wanted it, copying this author on his notifications. A few hours later, MasterCard acknowledged the mistake, but said there was never any real threat to the security of its operations.
“We have looked into the matter and there was not a risk to our systems,” a MasterCard spokesperson wrote. “This typo has now been corrected.”
Meanwhile, Caturegli received a request submitted through Bugcrowd, a program that offers financial rewards and recognition to security researchers who find flaws and work privately with the affected vendor to fix them. The message suggested his public disclosure of the MasterCard DNS error via a post on LinkedIn (after he’d secured the akam.ne domain) was not aligned with ethical security practices, and passed on a request from MasterCard to have the post removed.
MasterCard’s request to Caturegli, a.k.a. “Titon” on infosec.exchange.
Caturegli said while he does have an account on Bugcrowd, he has never submitted anything through the Bugcrowd program, and that he reported this issue directly to MasterCard.
“I did not disclose this issue through Bugcrowd,” Caturegli wrote in reply. “Before making any public disclosure, I ensured that the affected domain was registered to prevent exploitation, mitigating any risk to MasterCard or its customers. This action, which we took at our own expense, demonstrates our commitment to ethical security practices and responsible disclosure.”
Most organizations have at least two authoritative domain name servers, but some handle so many DNS requests that they need to spread the load over additional DNS server domains. In MasterCard’s case, that number is five, so it stands to reason that if an attacker managed to seize control over just one of those domains they would only be able to see about one-fifth of the overall DNS requests coming in.
But Caturegli said the reality is that many Internet users are relying at least to some degree on public traffic forwarders or DNS resolvers like Cloudflare and Google.
“So all we need is for one of these resolvers to query our name server and cache the result,” Caturegli said. By setting their DNS server records with a long TTL or “Time To Live” — a setting that can adjust the lifespan of data packets on a network — an attacker’s poisoned instructions for the target domain can be propagated by large cloud providers.
“With a long TTL, we may reroute a LOT more than just 1/5 of the traffic,” he said.
The researcher said he’d hoped that the credit card giant might thank him, or at least offer to cover the cost of buying the domain.
“We obviously disagree with this assessment,” Caturegli wrote in a follow-up post on LinkedIn regarding MasterCard’s public statement. “But we’ll let you judge— here are some of the DNS lookups we recorded before reporting the issue.”
Caturegli posted this screenshot of MasterCard domains that were potentially at risk from the misconfigured domain.
As the screenshot above shows, the misconfigured DNS server Caturegli found involved the MasterCard subdomain az.mastercard.com. It is not clear exactly how this subdomain is used by MasterCard, however their naming conventions suggest the domains correspond to production servers at Microsoft’s Azure cloud service. Caturegli said the domains all resolve to Internet addresses at Microsoft.
“Don’t be like Mastercard,” Caturegli concluded in his LinkedIn post. “Don’t dismiss risk, and don’t let your marketing team handle security disclosures.”
One final note: The domain akam.ne has been registered previously — in December 2016 by someone using the email address um-i-delo@yandex.ru. The Russian search giant Yandex reports this user account belongs to an “Ivan I.” from Moscow. Passive DNS records from DomainTools.com show that between 2016 and 2018 the domain was connected to an Internet server in Germany, and that the domain was left to expire in 2018.
This is interesting given a comment on Caturegli’s LinkedIn post from an ex-Cloudflare employee who linked to a report he co-authored on a similar typo domain apparently registered in 2017 for organizations that may have mistyped their AWS DNS server as “awsdns-06.ne” instead of “awsdns-06.net.” DomainTools reports that this typo domain also was registered to a Yandex user (playlotto@yandex.ru), and was hosted at the same German ISP — Team Internet (AS61969).
A financial firm registered in Canada has emerged as the payment processor for dozens of Russian cryptocurrency exchanges and websites hawking cybercrime services aimed at Russian-speaking customers, new research finds. Meanwhile, an investigation into the Vancouver street address used by this company shows it is home to dozens of foreign currency dealers, money transfer businesses, and cryptocurrency exchanges — none of which are physically located there.
![]()
Richard Sanders is a blockchain analyst and investigator who advises the law enforcement and intelligence community. Sanders spent most of 2023 in Ukraine, traveling with Ukrainian soldiers while mapping the shifting landscape of Russian crypto exchanges that are laundering money for narcotics networks operating in the region.
More recently, Sanders has focused on identifying how dozens of popular cybercrime services are getting paid by their customers, and how they are converting cryptocurrency revenues into cash. For the past several months, he’s been signing up for various cybercrime services, and then tracking where their customer funds go from there.
The 122 services targeted in Sanders’ research include some of the more prominent businesses advertising on the cybercrime forums today, such as:
-abuse-friendly or “bulletproof” hosting providers like anonvm[.]wtf, and PQHosting;
-sites selling aged email, financial, or social media accounts, such as verif[.]work and kopeechka[.]store;
-anonymity or “proxy” providers like crazyrdp[.]com and rdp[.]monster;
-anonymous SMS services, including anonsim[.]net and smsboss[.]pro.
The site Verif dot work, which processes payments through Cryptomus, sells financial accounts, including debit and credit cards.
Sanders said he first encountered some of these services while investigating Kremlin-funded disinformation efforts in Ukraine, as they are all useful in assembling large-scale, anonymous social media campaigns.
According to Sanders, all 122 of the services he tested are processing transactions through a company called Cryptomus, which says it is a cryptocurrency payments platform based in Vancouver, British Columbia. Cryptomus’ website says its parent firm — Xeltox Enterprises Ltd. (formerly certa-pay[.]com) — is registered as a money service business (MSB) with the Financial Transactions and Reports Analysis Centre of Canada (FINTRAC).
Sanders said the payment data he gathered also shows that at least 56 cryptocurrency exchanges are currently using Cryptomus to process transactions, including financial entities with names like casher[.]su, grumbot[.]com, flymoney[.]biz, obama[.]ru and swop[.]is.
These platforms are built for Russian speakers, and they each advertise the ability to anonymously swap one form of cryptocurrency for another. They also allow the exchange of cryptocurrency for cash in accounts at some of Russia’s largest banks — nearly all of which are currently sanctioned by the United States and other western nations.
A machine-translated version of Flymoney, one of dozens of cryptocurrency exchanges apparently nested at Cryptomus.
An analysis of their technology infrastructure shows that all of these exchanges use Russian email providers, and most are directly hosted in Russia or by Russia-backed ISPs with infrastructure in Europe (e.g. Selectel, Netwarm UK, Beget, Timeweb and DDoS-Guard). The analysis also showed nearly all 56 exchanges used services from Cloudflare, a global content delivery network based in San Francisco.
“Purportedly, the purpose of these platforms is for companies to accept cryptocurrency payments in exchange for goods or services,” Sanders told KrebsOnSecurity. “Unfortunately, it is next to impossible to find any goods for sale with websites using Cryptomus, and the services appear to fall into one or two different categories: Facilitating transactions with sanctioned Russian banks, and platforms providing the infrastructure and means for cyber attacks.”
Cryptomus did not respond to multiple requests for comment.
The Cryptomus website and its FINTRAC listing say the company’s registered address is Suite 170, 422 Richards St. in Vancouver, BC. This address was the subject of an investigation published in July by CTV National News and the Investigative Journalism Foundation (IJF), which documented dozens of cases across Canada where multiple MSBs are incorporated at the same address, often without the knowledge or consent of the location’s actual occupant.
This building at 422 Richards St. in downtown Vancouver is the registered address for 90 money services businesses, including 10 that have had their registrations revoked. Image: theijf.org/msb-cluster-investigation.
Their inquiry found 422 Richards St. was listed as the registered address for at least 76 foreign currency dealers, eight MSBs, and six cryptocurrency exchanges. At that address is a three-story building that used to be a bank and now houses a massage therapy clinic and a co-working space. But they found none of the MSBs or currency dealers were paying for services at that co-working space.
The reporters found another collection of 97 MSBs clustered at an address for a commercial office suite in Ontario, even though there was no evidence these companies had ever arranged for any business services at that address.
Peter German, a former deputy commissioner for the Royal Canadian Mounted Police who authored two reports on money laundering in British Columbia, told the publications it goes against the spirit of Canada’s registration requirements for such businesses, which are considered high-risk for money laundering and terrorist financing.
“If you’re able to have 70 in one building, that’s just an abuse of the whole system,” German said.
Ten MSBs registered to 422 Richard St. had their registrations revoked. One company at 422 Richards St. whose registration was revoked this year had a director with a listed address in Russia, the publications reported. “Others appear to be directed by people who are also directors of companies in Cyprus and other high-risk jurisdictions for money laundering,” they wrote.
A review of FINTRAC’s registry (.CSV) shows many of the MSBs at 422 Richards St. are international money transfer or remittance services to countries like Malaysia, India and Nigeria. Some act as currency exchanges, while others appear to sell merchant accounts and online payment services. Still, KrebsOnSecurity could find no obvious connections between the 56 Russian cryptocurrency exchanges identified by Sanders and the dozens of payment companies that FINTRAC says share an address with the Cryptomus parent firm Xeltox Enterprises.
In August 2023, Binance and some of the largest cryptocurrency exchanges responded to sanctions against Russia by cutting off many Russian banks and restricting Russian customers to transactions in Rubles only. Sanders said prior to that change, most of the exchanges currently served by Cryptomus were handling customer funds with their own self-custodial cryptocurrency wallets.
By September 2023, Sanders said he found the exchanges he was tracking had all nested themselves like Matryoshka dolls at Cryptomus, which adds a layer of obfuscation to all transactions by generating a new cryptocurrency wallet for each order.
![]()
“They all simply moved to Cryptomus,” he said. “Cryptomus generates new wallets for each order, rendering ongoing attribution to require transactions with high fees each time.”
“Exchanges like Binance and OKX removing Sberbank and other sanctioned banks and offboarding Russian users did not remove the ability of Russians to transact in and out of cryptocurrency easily,” he continued. “In fact, it’s become easier, because the instant-swap exchanges do not even have Know Your Customer rules. The U.S. sanctions resulted in the majority of Russian instant exchanges switching from their self-custodial wallets to platforms, especially Cryptomus.”
Russian President Vladimir Putin in August signed a new law legalizing cryptocurrency mining and allowing the use of cryptocurrency for international payments. The Russian government’s embrace of cryptocurrency was a remarkable pivot: Bloomberg notes that as recently as January 2022, just weeks before Russia’s full-scale invasion of Ukraine, the central bank proposed a blanket ban on the use and creation of cryptocurrencies.
In a report on Russia’s cryptocurrency ambitions published in September, blockchain analysis firm Chainalysis said Russia’s move to integrate crypto into its financial system may improve its ability to bypass the U.S.-led financial system and to engage in non-dollar denominated trade.
“Although it can be hard to quantify the true impact of certain sanctions actions, the fact that Russian officials have singled out the effect of sanctions on Moscow’s ability to process cross-border trade suggests that the impact felt is great enough to incite urgency to legitimize and invest in alternative payment channels it once decried,” Chainalysis assessed.
Asked about its view of activity on Cryptomus, Chainanlysis said Cryptomus has been used by criminals of all stripes for laundering money and/or the purchase of goods and services.
“We see threat actors engaged in ransomware, narcotics, darknet markets, fraud, cybercrime, sanctioned entities and jurisdictions, and hacktivism making deposits to Cryptomus for purchases but also laundering the services using Cryptomos payment API,” the company said in a statement.
It is unclear if Cryptomus and/or Xeltox Enterprises have any presence in Canada at all. A search in the United Kingdom’s Companies House registry for Xeltox’s former name — Certa Payments Ltd. — shows an entity by that name incorporated at a mail drop in London in December 2023.
The sole shareholder and director of that company is listed as a 25-year-old Ukrainian woman in the Czech Republic named Vira Krychka. Ms. Krychka was recently appointed the director of several other new U.K. firms, including an entity created in February 2024 called Globopay UAB Ltd, and another called WS Management and Advisory Corporation Ltd. Ms. Krychka did not respond to a request for comment.
WS Management and Advisory Corporation bills itself as the regulatory body that exclusively oversees licenses of cryptocurrencies in the jurisdiction of Western Sahara, a disputed territory in northwest Africa. Its website says the company assists applicants with bank setup and formation, online gaming licenses, and the creation and licensing of foreign exchange brokers. One of Certa Payments’ former websites — certa[.]website — also shared a server with 12 other domains, including rasd-state[.]ws, a website for the Central Reserve Authority of the Western Sahara.
The website crasadr dot com, the official website of the Central Reserve Authority of Western Sahara.
This business registry from the Czech Republic indicates Ms. Krychka works as a director at an advertising and marketing firm called Icon Tech SRO, which was previously named Blaven Technologies (Blaven’s website says it is an online payment service provider).
In August 2024, Icon Tech changed its name again to Mezhundarondnaya IBU SRO, which describes itself as an “experienced company in IT consulting” that is based in Armenia. The same registry says Ms. Krychka is somehow also a director at a Turkish investment venture. So much business acumen at such a young age!
For now, Canada remains an attractive location for cryptocurrency businesses to set up shop, at least on paper. The IJF and CTV News found that as of February 2024, there were just over 3,000 actively registered MSBs in Canada, 1,247 of which were located at the same building as at least one other MSB.
“That analysis does not include the roughly 2,700 MSBs whose registrations have lapsed, been revoked or otherwise stopped,” they observed. “If they are included, then a staggering 2,061 out of 5,705 total MSBs share a building with at least one other MSB.”
I've spent more than a decade now writing about how to make Have I Been Pwned (HIBP) fast. Really fast. Fast to the extent that sometimes, it was even too fast:
The response from each search was coming back so quickly that the user wasn’t sure if it was legitimately checking subsequent addresses they entered or if there was a glitch.
Over the years, the service has evolved to use emerging new techniques to not just make things fast, but make them scale more under load, increase availability and sometimes, even drive down cost. For example, 8 years ago now I started rolling the most important services to Azure Functions, "serverless" code that was no longer bound by logical machines and would just scale out to whatever volume of requests was thrown at it. And just last year, I turned on Cloudflare cache reserve to ensure that all cachable objects remained cached, even under conditions where they previously would have been evicted.
And now, the pièce de résistance, the coolest performance thing we've done to date (and it is now "we", thank you Stefán): just caching the whole lot at Cloudflare. Everything. Every search you do... almost. Let me explain, firstly by way of some background:
When you hit any of the services on HIBP, the first place the traffic goes from your browser is to one of Cloudflare's 330 "edge nodes":
As I sit here writing this on the Gold Coast on Australia's most eastern seaboard, any request I make to HIBP hits that edge node on the far right of the Aussie continent which is just up the road in Brisbane. The capital city of our great state of Queensland is just a short jet ski away, about 80km as the crow flies. Before now, every single time I searched HIBP from home, my request bytes would travel up the wire to Brisbane and then take a giant 12,000km trip to Seattle where the Azure Function in the West US Azure data would query the database before sending the response 12,000km back west to Cloudflare's edge node, then the final 80km down to my Surfers Paradise home. But what if it didn't have to be that way? What if that data was already sitting on the Cloudflare edge node in Brisbane? And the one in Paris, and the one in well, I'm not even sure where all those blue dots are, but what if it was everywhere? Several awesome things would happen:
In short, pushing data and processing "closer to the edge" benefits both our customers and ourselves. But how do you do that for 5 billion unique email addresses? (Note: As of today, HIBP reports over 14 billion breached accounts, the number of unique email addresses is lower as on average, each breached address has appeared in multiple breaches.) To answer this question, let's recap on how the data is queried:
Let's delve into that last point further because it's the secret sauce to how this whole caching model works. In order to provide subscribers of this service with complete anonymity over the email addresses being searched for, the only data passed to the API is the first six characters of the SHA-1 hash of the full email address. If this sounds odd, read the blog post linked to in that last bullet point for full details. The important thing for now, though, is that it means there are a total of 16^6 different possible requests that can be made to the API, which is just over 16 million. Further, we can transform the first two use cases above into k-anonymity searches on the server side as it simply involved hashing the email address and taking those first six characters.
In summary, this means we can boil the entire searchable database of email addresses down to the following:
That's a large albeit finite list, and that's what we're now caching. So, here's what a search via email address looks like:
K-anonymity searches obviously go straight to step four, skipping the first few steps as we already know the hash prefix. All of this happens in a Cloudflare worker, so it's "code on the edge" creating hashes, checking cache then retrieving from the origin where necessary. That code also takes care of handling parameters that transform queries, for example, filtering by domain or truncating the response. It's a beautiful, simple model that's all self-contained within a worker and a very simple origin API. But there's a catch - what happens when the data changes?
There are two events that can change cached data, one is simple and one is major:
The second point is kind of frustrating as we've built up this beautiful collection of data all sitting close to the consumer where it's super fast to query, and then we nuke it all and go from scratch. The problem is it's either that or we selectively purge what could be many millions of individual hash prefixes, which you can't do:
For Zones on Enterprise plan, you may purge up to 500 URLs in one API call.
And:
Cache-Tag, host, and prefix purging each have a rate limit of 30,000 purge API calls in every 24 hour period.
We're giving all this further thought, but it's a non-trivial problem and a full cache flush is both easy and (near) instantaneous.
Enough words, let's get to some pictures! Here's a typical week of queries to the enterprise k-anonymity API:
This is a very predictable pattern, largely due to one particular subscriber regularly querying their entire customer base each day. (Sidenote: most of our enterprise level subscribers use callbacks such that we push updates to them via webhook when a new breach impacts their customers.) That's the total volume of inbound requests, but the really interesting bit is the requests that hit the origin (blue) versus those served directly by Cloudflare (orange):
Let's take the lowest blue data point towards the end of the graph as an example:
At that time, 96% of requests were served from Cloudflare's edge. Awesome! But look at it only a little bit later:
That's when I flushed cache for the Finsure breach, and 100% of traffic started being directed to the origin. (We're still seeing 14.24k hits via Cloudflare as, inevitably, some requests in that 1-hour block were to the same hash range and were served from cache.) It then took a whole 20 hours for the cache to repopulate to the extent that the hit:miss ratio returned to about 50:50:
Look back towards the start of the graph and you can see the same pattern from when I loaded the DemandScience breach. This all does pretty funky things to our origin API:
That last sudden increase is more than a 30x traffic increase in an instant! If we hadn't been careful about how we managed the origin infrastructure, we would have built a literal DDoS machine. Stefán will write later about how we manage the underlying database to ensure this doesn't happen, but even still, whilst we're dealing with the cyclical support patterns seen in that first graph above, I know that the best time to load a breach is later in the Aussie afternoon when the traffic is a third of what it is first thing in the morning. This helps smooth out the rate of requests to the origin such that by the time the traffic is ramping up, more of the content can be returned directly from Cloudflare. You can see that in the graphs above; that big peaky block towards the end of the last graph is pretty steady, even though the inbound traffic the first graph over the same period of time increases quite significantly. It's like we're trying to race the increasing inbound traffic by building ourselves up a bugger in cache.
Here's another angle to this whole thing: now more than ever, loading a data breach costs us money. For example, by the end of the graphs above, we were cruising along at a 50% cache hit ratio, which meant we were only paying for half as many of the Azure Function executions, egress bandwidth, and underlying SQL database as we would have been otherwise. Flushing cache and suddenly sending all the traffic to the origin doubles our cost. Waiting until we're back at 90% cache it ratio literally increases those costs 10x when we flush. If I were to be completely financially ruthless about it, I would need to either load fewer breaches or bulk them together such that a cache flush is only ejecting a small amount of data anyway, but clearly, that's not what I've been doing 😄
There's just one remaining fly in the ointment...
Of those three methods of querying email addresses, the first is a no-brainer: searches from the front page of the website hit a Cloudflare Worker where it validates the Turnstile token and returns a result. Easy. However, the second two models (the public and enterprise APIs) have the added burden of validating the API key against Azure API Management (APIM), and the only place that exists is in the West US origin service. What this means for those endpoints is that before we can return search results from a location that may be just a short jet ski ride away, we need to go all the way to the other side of the world to validate the key and ensure the request is within the rate limit. We do this in the lightest possible way with barely any data transiting the request to check the key, plus we do it in async with pulling the data back from the origin service if it isn't already in cache. In other words, we're as efficient as humanly possible, but we still cop a massive latency burden.
Doing API management at the origin is super frustrating, but there are really only two alternatives. The first is to distribute our APIM instance to other Azure data centres, and the problem with that is we need a Premium instance of the product. We presently run on a Basic instance, which means we're talking about a 19x increase in price just to unlock that ability. But that's just to go Premium; we then need at least one more instance somewhere else for this to make sense, which means we're talking about a 28x increase. And every region we add amplifies that even further. It's a financial non-starter.
The second option is for Cloudflare to build an API management product. This is the killer piece of this puzzle, as it would put all the checks and balances within the one edge node. It's a suggestion I've put forward on many occasions now, and who knows, maybe it's already in the works, but it's a suggestion I make out of a love of what the company does and a desire to go all-in on having them control the flow of our traffic. I did get a suggestion this week about rolling what is effectively a "poor man's API management" within workers, and it's a really cool suggestion, but it gets hard when people change plans or when we want to apply quotas to APIs rather than rate limits. So c'mon Cloudflare, let's make this happen!
Finally, just one more stat on how powerful serving content directly from the edge is: I shared this stat last month for Pwned Passwords which serves well over 99% of requests from Cloudflare's cache reserve:
There it is - we’ve now passed 10,000,000,000 requests to Pwned Password in 30 days 😮 This is made possible with @Cloudflare’s support, massively edge caching the data to make it super fast and highly available for everyone. pic.twitter.com/kw3C9gsHmB
— Troy Hunt (@troyhunt) October 5, 2024
That's about 3,900 requests per second, on average, non-stop for 30 days. It's obviously way more than that at peak; just a quick glance through the last month and it looks like about 17k requests per second in a one-minute period a few weeks ago:
But it doesn't matter how high it is, because I never even think about it. I set up the worker, I turned on cache reserve, and that's it 😎
I hope you've enjoyed this post, Stefán and I will be doing a live stream on this topic at 06:00 AEST Friday morning for this week's regular video update, and it'll be available for replay immediately after. It's also embedded here for convenience:
![]()
![]()
CloakQuest3r is a powerful Python tool meticulously crafted to uncover the true IP address of websites safeguarded by Cloudflare, a widely adopted web security and performance enhancement service. Its core mission is to accurately discern the actual IP address of web servers that are concealed behind Cloudflare's protective shield. Subdomain scanning is employed as a key technique in this pursuit. This tool is an invaluable resource for penetration testers, security professionals, and web administrators seeking to perform comprehensive security assessments and identify vulnerabilities that may be obscured by Cloudflare's security measures.
Key Features:
Real IP Detection: CloakQuest3r excels in the art of discovering the real IP address of web servers employing Cloudflare's services. This crucial information is paramount for conducting comprehensive penetration tests and ensuring the security of web assets.
Subdomain Scanning: Subdomain scanning is harnessed as a fundamental component in the process of finding the real IP address. It aids in the identification of the actual server responsible for hosting the website and its associated subdomains.
Threaded Scanning: To enhance efficiency and expedite the real IP detection process, CloakQuest3r utilizes threading. This feature enables scanning of a substantial list of subdomains without significantly extending the execution time.
Detailed Reporting: The tool provides comprehensive output, including the total number of subdomains scanned, the total number of subdomains found, and the time taken for the scan. Any real IP addresses unveiled during the process are also presented, facilitating in-depth analysis and penetration testing.
With CloakQuest3r, you can confidently evaluate website security, unveil hidden vulnerabilities, and secure your web assets by disclosing the true IP address concealed behind Cloudflare's protective layers.
- Still in the development phase, sometimes it can't detect the real Ip.
- CloakQuest3r combines multiple indicators to uncover real IP addresses behind Cloudflare. While subdomain scanning is a part of the process, we do not assume that all subdomains' A records point to the target host. The tool is designed to provide valuable insights but may not work in every scenario. We welcome any specific suggestions for improvement.
1. False Negatives: CloakReveal3r may not always accurately identify the real IP address behind Cloudflare, particularly for websites with complex network configurations or strict security measures.
2. Dynamic Environments: Websites' infrastructure and configurations can change over time. The tool may not capture these changes, potentially leading to outdated information.
3. Subdomain Variation: While the tool scans subdomains, it doesn't guarantee that all subdomains' A records will point to the pri mary host. Some subdomains may also be protected by Cloudflare.
How to Use:
Run CloudScan with a single command-line argument: the target domain you want to analyze.
git clone https://github.com/spyboy-productions/CloakQuest3r.git
cd CloakQuest3r
pip3 install -r requirements.txt
python cloakquest3r.py example.com
The tool will check if the website is using Cloudflare. If not, it will inform you that subdomain scanning is unnecessary.
If Cloudflare is detected, CloudScan will scan for subdomains and identify their real IP addresses.
You will receive detailed output, including the number of subdomains scanned, the total number of subdomains found, and the time taken for the scan.
Any real IP addresses found will be displayed, allowing you to conduct further analysis and penetration testing.
CloudScan simplifies the process of assessing website security by providing a clear, organized, and informative report. Use it to enhance your security assessments, identify potential vulnerabilities, and secure your web assets.
Run it online on replit.com : https://replit.com/@spyb0y/CloakQuest3r