A critical resource that cybersecurity professionals worldwide rely on to identify, mitigate and fix security vulnerabilities in software and hardware is in danger of breaking down. The federally funded, non-profit research and development organization MITRE warned today that its contract to maintain the Common Vulnerabilities and Exposures (CVE) program — which is traditionally funded each year by the Department of Homeland Security — expires on April 16.
A letter from MITRE vice president Yosry Barsoum, warning that the funding for the CVE program will expire on April 16, 2025.
Tens of thousands of security flaws in software are found and reported every year, and these vulnerabilities are eventually assigned their own unique CVE tracking number (e.g. CVE-2024-43573, which is a Microsoft Windows bug that Redmond patched last year).
There are hundreds of organizations — known as CVE Numbering Authorities (CNAs) — that are authorized by MITRE to bestow these CVE numbers on newly reported flaws. Many of these CNAs are country and government-specific, or tied to individual software vendors or vulnerability disclosure platforms (a.k.a. bug bounty programs).
Put simply, MITRE is a critical, widely-used resource for centralizing and standardizing information on software vulnerabilities. That means the pipeline of information it supplies is plugged into an array of cybersecurity tools and services that help organizations identify and patch security holes — ideally before malware or malcontents can wriggle through them.
“What the CVE lists really provide is a standardized way to describe the severity of that defect, and a centralized repository listing which versions of which products are defective and need to be updated,” said Matt Tait, chief operating officer of Corellium, a cybersecurity firm that sells phone-virtualization software for finding security flaws.
In a letter sent today to the CVE board, MITRE Vice President Yosry Barsoum warned that on April 16, 2025, “the current contracting pathway for MITRE to develop, operate and modernize CVE and several other related programs will expire.”
“If a break in service were to occur, we anticipate multiple impacts to CVE, including deterioration of national vulnerability databases and advisories, tool vendors, incident response operations, and all manner of critical infrastructure,” Barsoum wrote.
MITRE told KrebsOnSecurity the CVE website listing vulnerabilities will remain up after the funding expires, but that new CVEs won’t be added after April 16.
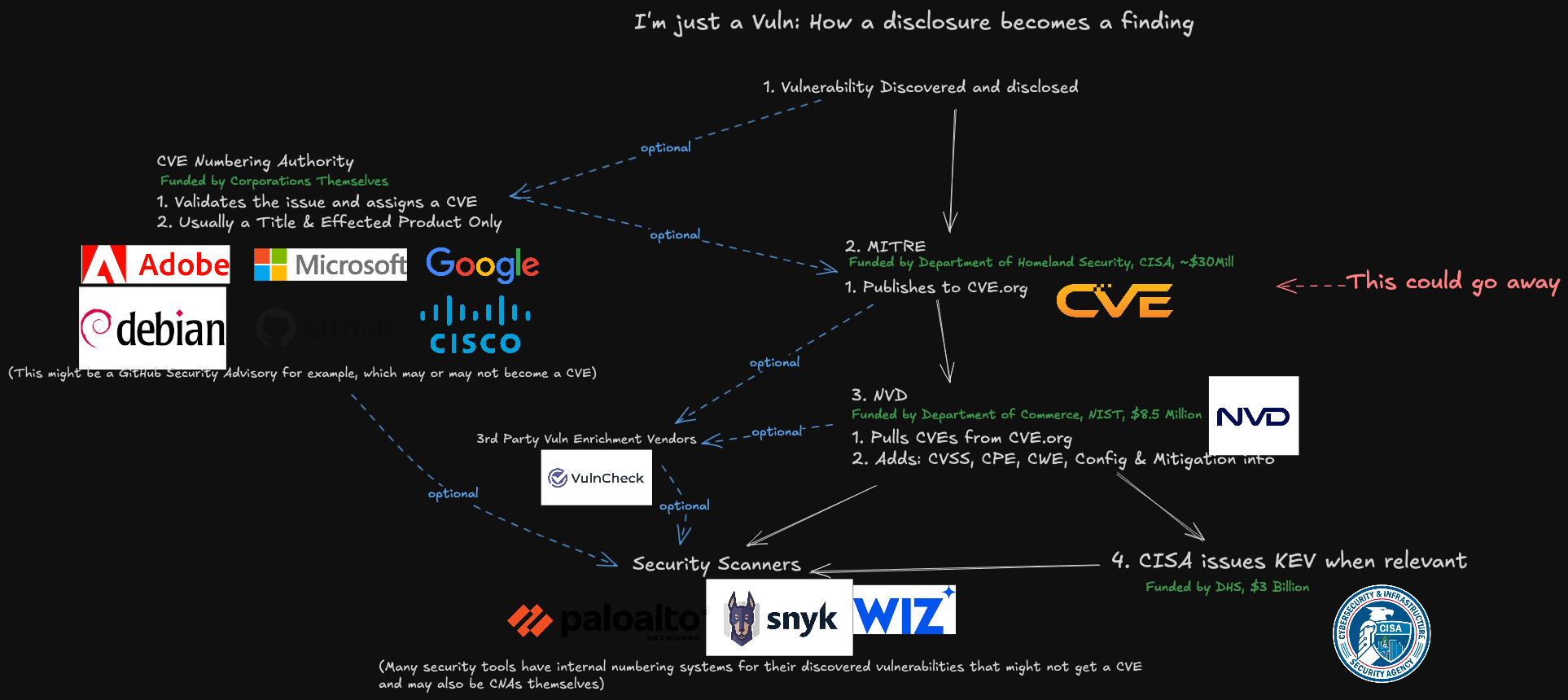
A representation of how a vulnerability becomes a CVE, and how that information is consumed. Image: James Berthoty, Latio Tech, via LinkedIn.
DHS officials did not immediately respond to a request for comment. The program is funded through DHS’s Cybersecurity & Infrastructure Security Agency (CISA), which is currently facing deep budget and staffing cuts by the Trump administration. The CVE contract available at USAspending.gov says the project was awarded approximately $40 million last year.
Former CISA Director Jen Easterly said the CVE program is a bit like the Dewey Decimal System, but for cybersecurity.
“It’s the global catalog that helps everyone—security teams, software vendors, researchers, governments—organize and talk about vulnerabilities using the same reference system,” Easterly said in a post on LinkedIn. “Without it, everyone is using a different catalog or no catalog at all, no one knows if they’re talking about the same problem, defenders waste precious time figuring out what’s wrong, and worst of all, threat actors take advantage of the confusion.”
John Hammond, principal security researcher at the managed security firm Huntress, told Reuters he swore out loud when he heard the news that CVE’s funding was in jeopardy, and that losing the CVE program would be like losing “the language and lingo we used to address problems in cybersecurity.”
“I really can’t help but think this is just going to hurt,” said Hammond, who posted a Youtube video to vent about the situation and alert others.
Several people close to the matter told KrebsOnSecurity this is not the first time the CVE program’s budget has been left in funding limbo until the last minute. Barsoum’s letter, which was apparently leaked, sounded a hopeful note, saying the government is making “considerable efforts to continue MITRE’s role in support of the program.”
Tait said that without the CVE program, risk managers inside companies would need to continuously monitor many other places for information about new vulnerabilities that may jeopardize the security of their IT networks. Meaning, it may become more common that software updates get mis-prioritized, with companies having hackable software deployed for longer than they otherwise would, he said.
“Hopefully they will resolve this, but otherwise the list will rapidly fall out of date and stop being useful,” he said.
Update, April 16, 11:00 a.m. ET: The CVE board today announced the creation of non-profit entity called The CVE Foundation that will continue the program’s work under a new, unspecified funding mechanism and organizational structure.
“Since its inception, the CVE Program has operated as a U.S. government-funded initiative, with oversight and management provided under contract,” the press release reads. “While this structure has supported the program’s growth, it has also raised longstanding concerns among members of the CVE Board about the sustainability and neutrality of a globally relied-upon resource being tied to a single government sponsor.”
The organization’s website, thecvefoundation.org, is less than a day old and currently hosts no content other than the press release heralding its creation. The announcement said the foundation would release more information about its structure and transition planning in the coming days.
Update, April 16, 4:26 p.m. ET: MITRE issued a statement today saying it “identified incremental funding to keep the programs operational. We appreciate the overwhelming support for these programs that have been expressed by the global cyber community, industry and government over the last 24 hours. The government continues to make considerable efforts to support MITRE’s role in the program and MITRE remains committed to CVE and CWE as global resources.”
![]()
![]()
![]()
The introduction of the MITRE ATT&CK evaluations is a welcomed addition to the third-party testing arena. The ATT&CK framework, and the evaluations in particular, have gone such a long way in helping advance the security industry as a whole, and the individual security products serving the market.
The insight garnered from these evaluations is incredibly useful. But let’s admit, for everyone except those steeped in the analysis, it can be hard to understand. The information is valuable, but dense. There are multiple ways to look at the data and even more ways to interpret and present the results (as no doubt you’ve already come to realize after reading all the vendor blogs and industry articles!) We have been looking at the data for the past week since it published, and still have more to examine over the coming days and weeks.
The more we assess the information, the clearer the story becomes, so we wanted to share with you Trend Micro’s 10 key takeaways for our results:
1. Looking at the results of the first run of the evaluation is important:
|
|
![]()
|
|
![]()
2. There is a hierarchy in the type of main detections – Techniques is most significant
|
|
![]()
https://attackevals.mitre.org/APT29/detection-categories.html
3. More alerts does not equal better alerting – quite the opposite
|
|
4. Managed Service detections are not exclusive
|
|
![]()
5. Let’s not forget about the effectiveness and need for blocking!
|
|
6. We need to look through more than the Windows
|
|
7. The evaluation shows where our product is going
|
|
8. This evaluation is helping us make our product better
|
|
9. MITRE is more than the evaluation
|
|
10. It is hard not to get confused by the fud!
|
|
The post Trend Micro’s Top Ten MITRE Evaluation Considerations appeared first on .
Full disclosure: I am a security product testing nerd*.
I’ve been following the MITRE ATT&CK Framework for a while, and this week the results were released of the most recent evaluation using APT29 otherwise known as COZY BEAR.
First, here’s a snapshot of the Trend eval results as I understand them (rounded down):
91.79% on overall detection. That’s in the top 2 of 21.
91.04% without config changes. The test allows for config changes after the start – that wasn’t required to achieve the high overall results.
107 Telemetry. That’s very high. Capturing events is good. Not capturing them is not-good.
28 Alerts. That’s in the middle, where it should be. Not too noisy, not too quiet. Telemetry I feel is critical whereas alerting is configurable, but only on detections and telemetry.
So our Apex One product ran into a mean and ruthless bear and came away healthy. But that summary is a simplification and doesn’t capture all the nuance to the testing. Below are my takeaways for you of what the MITRE ATT&CK Framework is, and how to go about interpreting the results.
Takeaway #1 – ATT&CK is Scenario Based
The MITRE ATT&CK Framework is intriguing to me as it mixes real world attack methods by specific adversaries with a model for detection for use by SOCs and product makers. The ATT&CK Framework Evaluations do this but in a lab environment to assess how security products would likely handle an attack by that adversary and their usual methods. There had always been a clear divide between pen testing and lab testing and ATT&CK was kind of mixing both. COZY BEAR is super interesting because those attacks were widely known for being quite sophisticated and being state-sponsored, and targeted the White House and US Democratic Party. COZY BEAR and its family of derivatives use backdoors, droppers, obfuscation, and careful exfiltration.
Takeaway #2 – Look At All The Threat Group Evals For The Best Picture
I see the tradeoffs as ATT&CK evals are only looking at that one scenario, but that scenario is very reality based and with enough evals across enough scenarios a narrative is there to better understand a product. Trend did great on the most recently released APT/29/COZY BEAR evaluation, but my point is that a product is only as good as all the evaluations. I always advised Magic Quadrant or NSS Value Map readers to look at older versions in order to paint a picture over time of what trajectory a product had.
Takeaway #3 – It’s Detection Focused (Only)
The APT29 test like most Att&ck evals is testing detection, not prevention nor other parts of products (e.g. support). The downside is that a product’s ability to block the attacks isn’t evaluated, at least not yet. In fact blocking functions have to be disabled for parts of the test to be done. I get that – you can’t test the upstairs alarm with the attack dog roaming the downstairs. Starting with poor detection never ends well, so the test methodology seems to be focused on ”if you can detect it you can block it”. Some pen tests are criticized that a specific scenario isn’t realistic because A would stop it before B could ever occur. IPS signature writers everywhere should nod in agreement on that one. I support MITRE on how they constructed the methodology because there has to be limitations and scope on every lab test, but readers too need to understand those limitations and scopes. I believe that the next round of tests will include protection (blocking) as well, so that is cool.
Takeaway #4 – Choose Your Own Weather Forecast
Att&ck is no magazine style review. There is no final grade or comparison of products. To fully embrace Att&ck imagine being provided dozens of very sound yet complex meteorological measurements and being left to decide on what the weather will be. Or have vendors carpet bomb you with press releases of their interpretations. I’ve been deep into the numbers of the latest eval scores and when looking at some of the blogs and press releases out there they almost had me convinced they did well even when I read the data at hand showing they didn’t. I guess a less jaded view is that the results can be interpreted in many ways, some of them quite creative. It brings to mind the great quote from the Lockpicking Lawyer review “the threat model does not include an attacker with a screwdriver”.
Josh Zelonis at Forrester provides a great example of the level of work required to parse the test outcomes, and he provides extended analysis on Github here that is easier on the eyes than the above. Even that great work product requires the context of what the categories mean. I understand that MITRE is taking the stance of “we do the tests, you interpret the data” in order to pick fewer fights and accommodate different use cases and SOC workflows, but that is a lot to put on buyers. I repeat: there’s a lot of nuance in the terms and test report categories.
If, in the absence of Josh’s work, if I have to pick one metric Detection Rate is likely the best one. Note that Detection rate isn’t 100% for any product in the APT29 test, because of the meaning of that metric. The best secondary metrics I like are Techniques and Telemetry. Tactics sounds like a good thing, but in the framework it is lesser than Techniques, as Tactics are generalized bad things (“Something moving outside!”) and Techniques are more specific detections (“Healthy adult male Lion seen outside door”), so a higher score in Techniques combined with a low score in Tactics is a good thing. Telemetry scoring is, to me, best right in the middle. Not too many alerts (noisy/fatiguing) and not too few (“about that lion I saw 5 minutes ago”).
Here’s an example of the interpretations that are valuable to me. Looking at the Trend Micro eval source page here I get info on detections in the steps, or how many of the 134 total steps in the test were detected. I’ll start by excluding any human involvement and exclude the MSSP detections and look at unassisted only. But the numbers are spread across all 20 test steps, so I’ll use Josh’s spreadsheet shows 115 of 134 steps visible, or 85.82%. I do some averaging on the visibility scores across all the products evaluated and that is 66.63%, which is almost 30% less. Besides the lesson that the data needs gathering and interpretation, it highlights that no product spotted 100% across all steps and the spread was wide. I’ll now look at the impact of human involvement add in the MSSP detections and the Trend number goes to 91%. Much clinking of glasses heard from the endpoint dev team. But if I’m not using an MSSP service that… you see my point about context/use-case/workflow. There’s effectively some double counting (i.e. a penalty, so that when removing MSSP it inordinately drops the detection ) of the MSSP factor when removing it in the analyses, but I’ll leave that to a future post. There’s no shortage of fodder for security testing nerds.
Takeaway #5 – Data Is Always Good
Security test nerdery aside, this eval is a great thing and the data from it is very valuable. Having this kind of evaluation makes security products and the uses we put them to better. So dig into ATT&CK and read it considering not just product evaluations but how your organization’s framework for detecting and processing attacks maps to the various threat campaigns. We’ll no doubt have more posts on APT29 and upcoming evals.
*I was a Common Criteria tester in a place that also ran a FIPS 140-2 lab. Did you know that at Level 4 of FIPS a freezer is used as an exploit attempt? I even dipped my toe into the arcane area of Formal Methods using the GYPSY methodology and ran from it screaming “X just equals X! We don’t need to prove that!”. The deepest testing rathole I can recall was doing a portability test of the Orange Book B1 rating for MVS RACF when using logical partitions. I’m never getting those months of my life back. I’ve been pretty active in interacting with most security testing labs like NSS and ICSA and their schemes (that’s not a pejorative, but testing nerds like to use British usages to sound more learned) for decades because I thought it was important to understand the scope and limits of testing before accepting it in any product buying decisions. If you want to make Common Criteria nerds laugh point out something bad that has happened and just say “that’s not bad, it was just mistakenly put in scope”, and that will then upset the FIPS testers because a crypto boundary is a very real thing and not something real testers joke about. And yes, Common Criteria is the MySpace of tests.
The post Getting ATT&CKed By A Cozy Bear And Being Really Happy About It: What MITRE Evaluations Are, and How To Read Them appeared first on .