
The sheer scope of cybercrime can be hard to fathom, even when you live and breathe it every day. It's not just the volume of data, but also the extent to which it replicates across criminal actors seeking to abuse it for their own gain, and to our detriment.
We were reminded of this recently when the FBI reached out and asked if they could send us 630 million more passwords. For the last four years, they've been sending over passwords found during the course of their investigations in the hope that we can help organisations block them from future use. Back then, we were supporting 1.26 billion searches of the service each month. Now, it's... more:
Just as it's hard to wrap your head around the scale of cybercrime, I find it hard to grasp that number fully. On average, that service is hit nearly 7 thousand times per second, and at peak, it's many times more than that. Every one of those requests is a chance to stop an account takeover. But the real scale goes well beyond the API itself. Because the data model is open source and freely available, many organisations use the Pwned Passwords Downloader to take the entire corpus offline and query it directly within their own applications. That tool alone calls the API around a million times during download, but the resulting data is then queried… well, who knows how many times after that. Pretty cool, right?
This latest corpus of data came to us as a result of the FBI seizing multiple devices belonging to a suspect. The data appeared to have originated from both the open web and Tor-based marketplaces, Telegram channels and infostealer malware families. We hadn't seen about 7.4% of them in HIBP before, which might sound small, but that's 46 million vulnerable passwords we weren't giving people using the service the opportunity to block. So, we've added those and bumped the prevalence count on the other 584 million we already had.
We're thrilled to be able to provide this service to the community for free and want to also quickly thank Cloudflare for their support in providing us with the infrastructure to make this possible. Thanks to their edge caching tech, all those passwords are queryable from a location just a handful of milliseconds away from wherever you are on the globe.
If you're hitting the API, then all the data is already searchable for you. If you're downloading it all offline, go and grab the latest data now. Either way, go forth and put it to good use and help make a cybercriminal's day just that much harder 😊

Normally, when someone sends feedback like this, I ignore it, but it happens often enough that it deserves an explainer, because the answer is really, really simple. So simple, in fact, that it should be evident to the likes of Bruce, who decided his misunderstanding deserved a 1-star Trustpilot review yesterday:
Now, frankly, Trustpilot is a pretty questionable source of real-world, quality reviews anyway, but the same feedback has come through other channels enough times that let's just sort this out once and for all. It all begins with one simple question:
You think you know - and Bruce thinks he knows - but you might both be wrong. To explain the answer to the question, we need to start with how HIBP ingests data, and that really is pretty simple: someone sends us a breach (which is typically just text files of data), and we run the open source Email Address Extractor tool over it, which then dumps all the unique addresses into a file. That file is then uploaded into the system, where the addresses are then searchable.
The logic for how we extract addresses is all in that Github repository, but in simple terms, it boils down to this:
That is all! We can't then tell if there's an actual mailbox behind the address, as that would require massive per-address processing, for example, sending an email to each one and seeing if it bounces. Can you imagine doing that 7 billion times?! That's the number of unique addresses in HIBP, and clearly, it's impossible. So, that means all the following were parsed as being valid and loaded into HIBP (deep links to the search result):
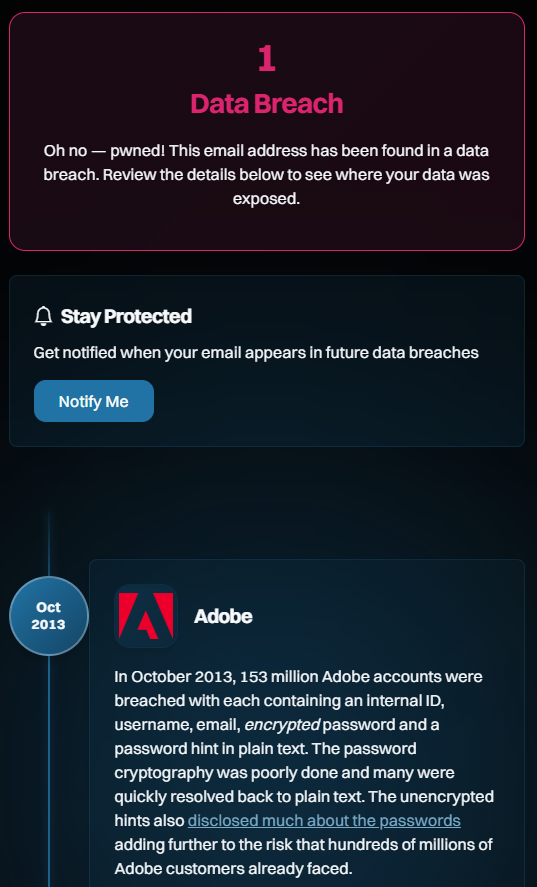
I particularly like that last one, as it feels like a sentiment Bruce would express. It's also a great example as it's clearly not "real"; the alias is a bit of a giveaway, as is the domain ("foo" is commonly used as a placeholder, similar to how we might also use "bar", or combine them as "foo bar"). But if you follow the link and see the breach it was exposed in, you'll see a very familiar name:
Which brings us to the next question:
This is also going to seem profoundly simple when you see it. Here goes:
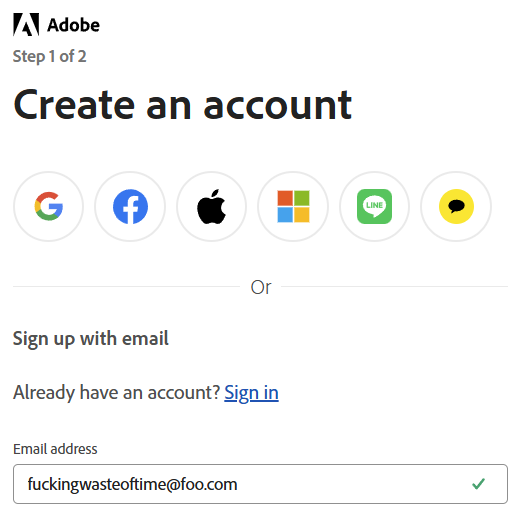
Any questions, Bruce? This is just as easily explainable as why we considered it a valid address and ingested it into HIBP: the email address has a valid structure. That is all. That's how it got into Adobe, and that's how it then flowed through into HIBP.
Ah, but shouldn't Adobe verify the address? I mean, shouldn't they send an email to the address along the lines of "Hey, are you sure you want to sign up for this service?" Yes, they should, but here's the kicker: that doesn't stop the email address from being added to their database in the first place! The way this normally works (and this is what we do with HIBP when you sign up for the free notification service) is you enter the email address, the system generates a random token, and then the two are saved together in the database. A link with the token is then emailed to the address and used to verify the user if they then follow that link. And if they don't follow that link? We delete the email address if it hasn't been verified within a few days, but evidently, Adobe doesn't. Most services don't, so here we are.
This is also going to seem profoundly obvious, but genuinely random email addresses (not "thisisfuckinguseless@") won't show up in HIBP. Want to test the theory? Try 1Password's generator (yes, Bruce, they also sponsor HIBP):
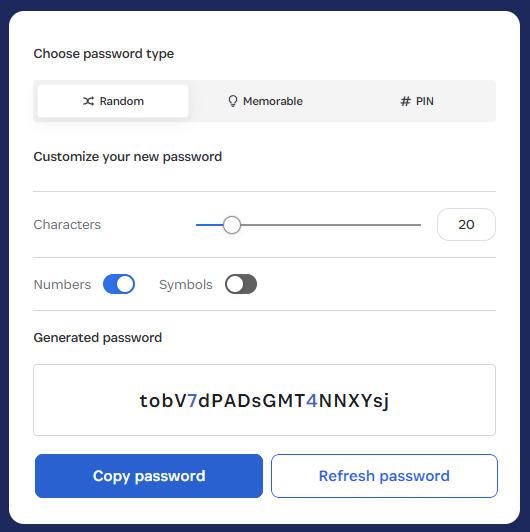
Now, whack that on the foo.com domain and do a search:
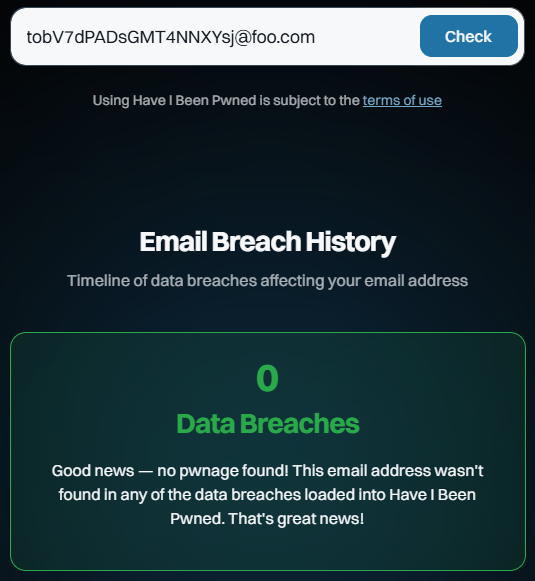
Huh, would you look at that? And you can keep doing that over and over again. You’ll get the same result because they are fabricated addresses that no one else has created or entered into a website that was subsequently breached, ipso facto proving they cannot appear in the dataset.
Today is HIBP's 12th birthday, and I've taken particular issue with Bruce's review because it calls into question the integrity with which I run this service. This is now the 218th blog post I've written about HIBP, and over the last dozen years, I've detailed everything from the architecture to the ethical considerations to how I verify breaches. It's hard to imagine being any more transparent about how this service runs, and per the above, it's very simple to disprove the Bruces of the world. If you've read this far and have an accurate, fact-based review you'd like to leave, that'd be awesome 😊

I hate hyperbolic news headlines about data breaches, but for the "2 Billion Email Addresses" headline to be hyperbolic, it'd need to be exaggerated or overstated - and it isn't. It's rounded up from the more precise number of 1,957,476,021 unique email addresses, but other than that, it's exactly what it sounds like. Oh - and 1.3 billion unique passwords, 625 million of which we'd never seen before either. It's the most extensive corpus of data we've ever processed, by a significant margin.
Edit: Just to be crystal clear about the origin of the data and the role of Synthient (who you’ll read about in the next paragraph): this data came from numerous locations where cybercriminals had published it. Synthient (run by Ben during his final year of college) indexed that data and provided it to Have I Been Pwned solely for the purpose of notifying victims. He’s the good guy shining a light on the bad guys, so keep that in mind as you read on. (Some of the feedback Ben has received is exactly what I foreshadowed in the final paragraph of this post.)
A couple of weeks ago, I wrote about the 183M unique email addresses that Synthient had indexed in their threat intelligence platform and then shared with us. I explained that this was only part of the corpus of data they'd indexed, and that it didn't include the credential stuffing records. Stealer log data is obtained by malware running on infected machines. In contrast, credential stuffing lists usually originate from other data breaches where email addresses and passwords are exposed. They're then bundled up, sold, redistributed, and ultimately used to log in to victims' accounts. Not just the accounts they were initially breached from, either, because people reuse the same password over and over again, the data from one breach is frequently usable on completely unrelated sites. A breach of a forum to comment on cats often exposes data that can then be used to log in to the victim's shopping, social media and even email accounts. In that regard, credential stuffing data becomes "the keys to the castle".
Let me run through how we verified the data, what you can do about it and for the tech folks, some of the hoops we had to jump through to make processing this volume of data possible.
The first person whose data I verified was easy - me 😔 An old email address I've had since the 90s has been in credential stuffing lists before, so it wasn't too much of a surprise. Furthermore, I found a password associated with my address, which I'd definitely used many eons ago, and it was about as terrible as you'd expect from that era. However, none of the other passwords associated with my address were familiar. They certainly looked like passwords that other people might have feasibly used, but I'm pretty sure they weren't mine. One was even just an IP address from Perth on the other side of the country, which is both infeasible as a password I would have used, yet eerily close to home. I mean, of all the places in the world an IP address could have appeared from, it had to be somewhere in my own country I've been many times before...
Moving on to HIBP subscribers, I reached out to a handful and asked for support verifying the data. I chose a mix of subscribers with many who'd never been involved in any data breach we'd ever seen before; my experience above suggested that there's recycled data in there, and we had previously verified that when investigating those other incidents. However, is the all-new stuff legitimate? The very first response I received was exactly what I was looking for:
#1 is an old password that I don't use anymore. #2 is a more recent password. Thanks for the heads up, I've gone and changed the password for every critical account that used either one.
Perfectly illustrating most people's behaviour with passwords, #2 referred to above was just #1 with two exclamation marks at the end!! (Incidentally, these were simple six and eight-character passwords, and neither of them was in Pwned Passwords either.) He had three passwords in total, which also means one of them, like with my data, was not familiar. However, the most important thing here is that this example perfectly illustrates why we put the effort into processing data like this: #2 was a real, live password that this guy was actively using, and it was sitting right next to his email address, being passed around among criminals. However, through this effort, that credential pair has now become useless, which is precisely what we're aiming for with this exercise, just a couple of billion times over.
The second respondent only had one password against their address:
Yes that was a password I used for many years for what I would call throw away or unimportant accounts between 20 and 10 years ago
That was also only eight characters, but this time, we'd seen it in Pwned Passwords many times before. And the observation about the password's age was consistent with my own records, so there's definitely some pretty old data in there.
The following response was not at all surprising:
I am familiar with that password... I used it almost 10 years ago... and cannot recall the last time I used it.
That was on a corporate account, too, and the owner of the address duly forwarded my email to the cybersecurity team for further investigation. The single password associated with this lady's email address had a massive nine characters, and also hadn't previously appeared in Pwned Passwords.
Next up was a respondent who replied inline to my questions, so I'll list them below with the corresponding answers:
Is this familiar? Yes
Have you ever used it in the past? Yes and is still on some accounts I do not use any longer.
And if so, how long ago? Unfortunately, it is still on some active accounts that I have just made a list of to change or close immediately.
This individual's eight-character password with uppercase, lowercase, numbers and a "special" character also wasn't in Pwned Passwords. Similarly, as with the earlier response, that password was still in active use, posing a real risk to the owner. It would pass most password complexity criteria and slip through any service using Pwned Passwords to block bad ones, so again, this highlights why it was so important for us to process the data.
The next person had three different passwords against rows with their email address, and they came back with a now common response:
Yes, these are familiar, last used 10 years ago
We'd actually seen all three of them in Pwned Passwords before, many times each. Another respondent with precisely the kind of gamer-like passwords you'd expect a kid to use (one of which we hadn't seen before), also confirmed (I think?) their use:
maybe when i was a kid lol
Responses that weren't an emphatic "yes, that's my data" were scarce. The two passwords against one person's name were both in Pwned Passwords (albeit only once each), yet it's entirely possible that neither of them had been used by this specific individual before. It's also possible they'd forgotten a password they'd used more than a decade ago, or it may have even been automatically assigned to them by the service that was subsequently breached. Put it down as a statistical anomaly, but I thought it was worth mentioning to highlight that being in this data set isn't a guarantee of a genuine password of yours being exposed. If your email address is found in this corpus then that's real, of course, so there must be some truth in the data, but it's a reminder that when data is aggregated from so many different sources over such a long period of time, there's going to be some inconsistencies.
As a brief recap, we load passwords into the service we call Pwned Passwords. When we do so, there is absolutely no association between the password and the email address it appeared next to. This is for both your protection and ours; can you imagine if HIBP was pwned? It's not beyond the realm of possibility, and the impact of exposing billions of credential pairs that can immediately unlock an untold number of accounts would be catastrophic. It's highly risky, and completely unnecessary when you can search for standalone passwords anyway without creating the risk of it being linked back to someone.
Think about it: if you have a password of "Fido123!" and you find it's been previously exposed (which it has), it doesn't matter if it was exposed against your email address or someone else's; it's still a bad password because it's named after your dog followed by a very predictable pattern. If you have a genuinely strong password and it's in Pwned Passwords, then you can walk away with some confidence that it really was yours. Either way, you shouldn't ever use that password again anywhere, and Pwned Passwords has done its job.
Checking the service is easy, anonymous and depending on your level of technical comfort, can be done in several different ways. Here's a copy and paste from the last Synthient blog post:
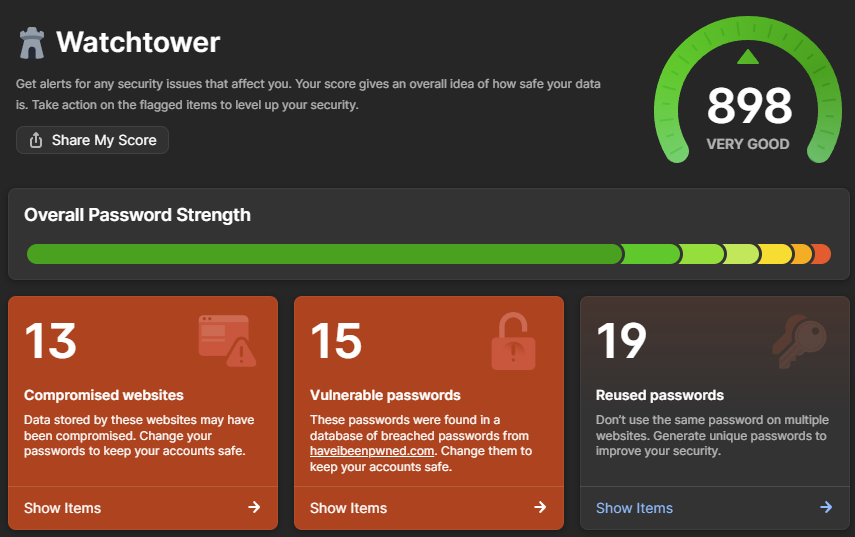
My vested interest in 1Password aside, Watchtower is the easiest, fastest way to understand your potential exposure in this incident. And in case you're wondering why I have so many vulnerable and reused passwords, it's a combination of the test accounts I've saved over the years and the 4-digit PINs some services force you to use. Would you believe that every single 4-digit number ever has been pwned?! (If you're interested, the ABC has a fantastic infographic using a heatmap based on HIBP data that shows some very predictable patterns for 4-digit PINs.)
It pains me to say it, but I have to, given the way the stealer logs made ridiculous, completely false headlines a couple of weeks ago:
This story has suddenly gained *way* more traction in recent hours, and something I thought was obvious needs clarifying: this *is not* a Gmail leak, it simply has the credentials of victims infected with malware, and Gmail is the dominant email provider: https://t.co/S75hF4T1es
— Troy Hunt (@troyhunt) October 27, 2025
There are 32 million different email domains in this latest corpus, of which gmail.com is one. It is, of course, the largest and has 394 million unique email addresses on it. In other words, 80% of the data in this corpus has absolutely nothing to do with Gmail, and the 20% of Gmail addresses have absolutely nothing to do with any sort of security vulnerability on Google's behalf. There - now let reporting sanity prevail!
I wanted to add this just to highlight how painful it has been to deal with this data. This corpus is nearly 3 times the size of the previous largest breach we'd loaded, and HIBP is many times larger than it was in 2019 when we loaded the Collection #1 data. Taking 2 billion records and adding the ones we hadn't already seen in the existing 15 billion corpus, whilst not adversely impacting the live system serving millions of visitors a day, was very non-trivial. Managing the nuances of SQL Server indexes such that we could optimise both inserts and queries is not my idea of fun, and it's been a pretty hard couple of weeks if I'm honest. It's also been a very expensive period as we turned the cloud up to 11 (we run on Azure SQL Hyperscale, which we maxed out at 80 cores for almost two weeks).
A simple example of the challenge is that after loading all the email addresses up into a staging table, we needed to create SHA1 hashes of each. Normally, that would involve something to the effect of "update table set column = sha1(email)" and you're done. That crashed completely, so we ended up doing "insert into new table select email, sha1(email)". But on other occasions the breach load required us to do updates on other columns (with no hash creation), which, on mulitple occasions, we had to kill after a day or more of execution with no end in sight. So, we ended up batching in loops (usually 1M records at a time), reporting on progress along the way so we had some idea of when it would actually finish. It was a painful process of trial, waiting ages, error then taking a completely different approach.
Notifying our subscribers is another problem. We have 5.9 million of them, and 2.9 million are in this data 🫨 Simply sending that many emails at once is hard. It's not so much hard in terms of firing them off, rather it's hard in terms of not ending up on a reputation naughty list or having mail throttled by the receiving server. That's happened many times in the past when loading large, albeit much smaller corpuses; Gmail, for example, suddenly sees a massive spike and slows down the delivery to inboxes. Not such a biggy for sending breach notices, but a major problem for people trying to sign into their dashboard who can no longer receive the email with the "magic" link.
What we've done to address that for this incident is to slow down the delivery of emails for the individual breach notification. Whilst I'd originally intended to send the emails at a constant rate over the period of a week, someone listening to me on my Friday live stream had a much better suggestion:
the strategy I've found to best work with large email delivery is to look at the average number of emails you've sent over the last 30 days each time you want to ramp up, and then increase that volume by around 50% per day until you've worked your way through the queue
Which makes a lot of sense, and stacked up as I did more research (thanks Joe!). So, here's what our planned delivery schedule now looks like:
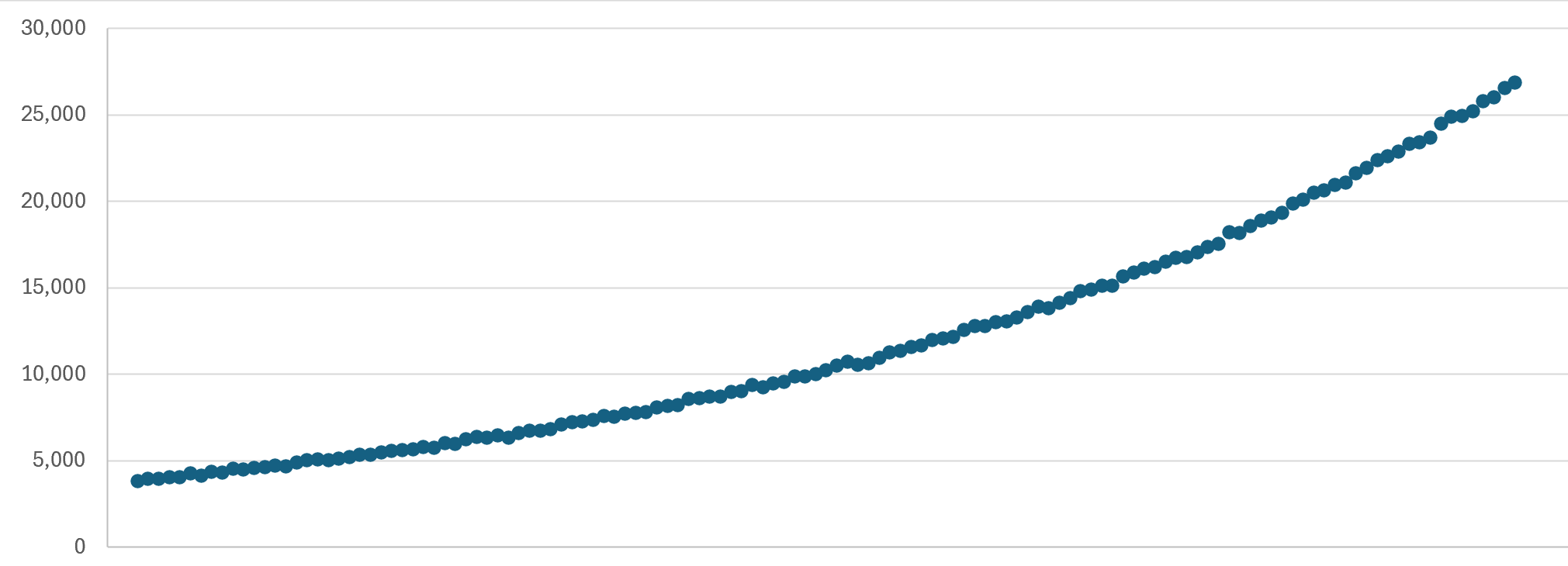
That's broken down by hour, increasing in volume by 1.015 times per hour, such that the emails are spread out in a similar, gradually increasing cadence. On a daily basis, that works out at a 45% increase in each 24-hour period, within Joe's suggested 50% threshold. Plus, we obviously have all the other mechanisms such as a dedicated IP, properly configured DKIM, DMARC and SPF, only emailing double-opted-in subscribers and spam-friendly message body construction. So, it could be days before you receive a notification, or just run a haveibeenpwned.com search on demand if you're impatient.
We've sent all the domain notification emails instantly because, by definition, they're going to a very wide range of different mail servers; it's just the individual ones we're drop-feeding.
Lastly, if you've integrated Pwned Passwords into your service, you'll now see noticeably larger response sizes. The numbers I mentioned in the opening paragraph increase the size of each hash range by an average of about 50%, which will push responses from about 26kb to 40kb. That's when brotli compressed, so obviously, make sure you're making requests that make the most of the compression.
This data is now searchable in HIBP as the Synthient Credential Stuffing Threat Data. It's an entirely separate corpus from that previous Synthient data I mentioned earlier; they're discrete datasets with some crossover, but obviously, this one is significantly larger. And, of course, all the passwords are now searchable per the Pwned Passwords guidance above.
If I could close with one request: this was an extremely laborious, time-consuming and expensive exercise for us to complete. We've done our best to verify the integrity of the data and make it searchable in a practical way while remaining as privacy-centric as possible. Sending as many notifications as we have will inevitably lead to a barrage of responses from people wanting access to complete rows of data, grilling us on precisely where it was obtained from or, believe it or not, outright abusing us. Not doing those things would be awesome, and I suggest instead putting the energy into getting a password manager, making passwords strong and unique (or even better, using passkeys where available), and turning on multi-factor auth. That would be an awesome outcome for all 😊
Edit: I've closed off comments on this blog post. As you'll see below, there was a constant stream of questions that have already been answered in the post itself, plus some comments that were starting to verge on precisely what I predicted in the last para above. Reading, responding and engaging is time-consuming and at this point, all the answers are already here both above and below this edit in the comments.

Where is your data on the internet? I mean, outside the places you've consciously provided it, where has it now flowed to and is being used and abused in ways you've never expected? The truth is that once the bad guys have your data, it often replicates over and over again via numerous channels and platforms. If you're able to aggregate enough of it en masse, you end up with huge volumes of "threat intelligence data", to use the industry buzzword. And that's precisely what Ben from Synthient has done, and then sent it to Have I Been Pwned (HIBP).
Ben is in his final year of college in the US and is carving out a niche in threat intelligence. He's written up a deeper dive in The Stealer Log Ecosystem: Processing Millions of Credentials a Day, but the headline gives you a sense of the volumes. Have a read of that post and you'll see Ben is pulling data from various sources, including social media, forums, Tor and, of course, Telegram. He's managed to aggregate so much of it that by the time he sent it to us, it was rather sizeable:
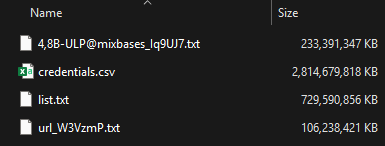
That's 3.5 terrabytes of data, with the largest file alone being 2.6TB and, combined, they contain 23 billion rows. It's a vast corpus, and if we were attempting to compete with recent hyperbolic headlines about breach sizes, this would be one of the largest. But I'm not going to play the "mine is bigger than yours" game because it makes no sense once you start analysing the data. Part of what makes the data so large is that we're actually looking at both stealer logs and credential stuffing lists, so let's assess them separately, starting with those stealer logs.
Stealer logs are the product of infostealers, that is, malware running on infected machines and capturing credentials entered into websites on input. The output of those stealer logs is primarily three things:
Someone logging into Gmail, for example, ends up with their email address and password captured against gmail.com, hence the three parts. Due to the fact that stealer logs are so heavily recycled (they're posted over and over again to the sorts of channels Ben monitors), the first thing we always do is try to get a sense of how much is genuinely new:
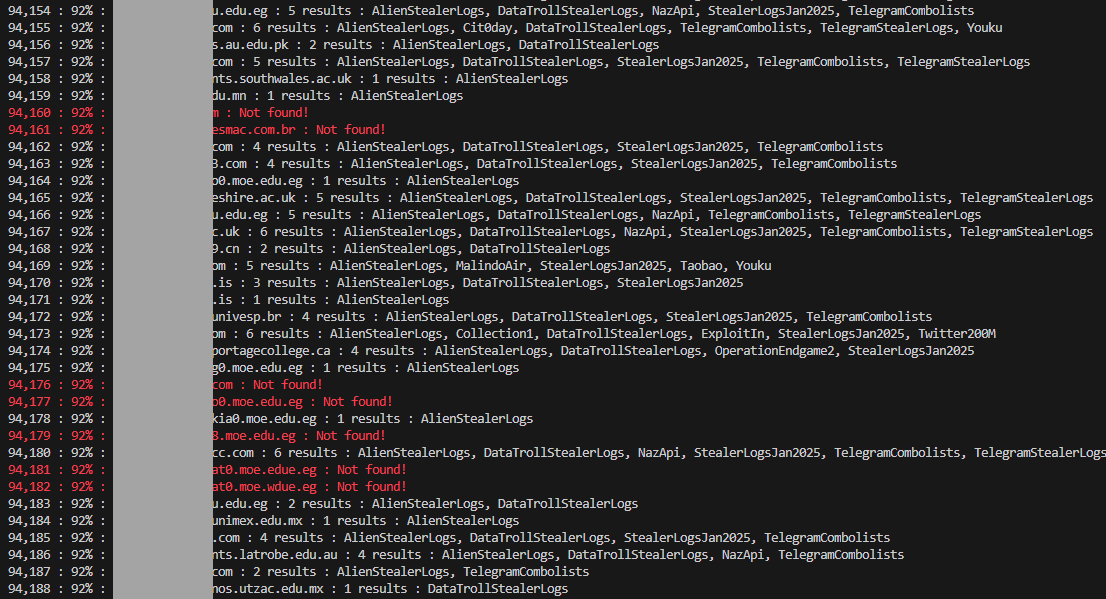
This is the output of a little PowerShell script we use to guage where the email addresses in a new breach corpus have been seen before. Especially when there's a suspicion that data might have been repurposed from elsewhere, it's really useful to run them against the HIBP API and see what comes back. What the output above tells us is that after checking a sample of 94k of them, 92% had been previously seen, mostly in stealer log corpuses we'd loaded in the past. This is an empirical demonstration of what I wrote in the opening paragraph - "it often replicates over and over again" - and as you can see, most of what has been seen before was in the ALIEN TXTBASE stealer logs.
Back to the console output again, and having previously seen 92% of addresses also means we haven't seen 8% of the addresses. That's 8% of a considerable number, too: we found 183M unique email addresses across Ben's stealer log data, so we're talking about 14M+ addresses that have never surfaced in HIBP. (The final number once the entire data set was loaded into HIBP was 91% pre-existing, with 16.4M previously unseen addresses in any data breach, not just stealer logs.) But as with everything we load, the question has to be asked: Is it legit? Can you trust the shady criminals who publish this data not to fill it with junk? The only way to know for sure is to ask the legitimate owners of the data, so I reached out to a bunch of our subscribers and sought their support in verifying.
One of the respondants was already concerned there could be something wrong with his Gmail account and sure enough, he had one stealer log entry for "https://accounts.google.com/signin/challenge/pwd/1" with a, uh, "suboptimal" password:
Yes I can confirm that was an accurate password on my gmail account a few months ago
Another respondant who offered support had somewhat of a recognisable pattern in the sites he'd been visiting:
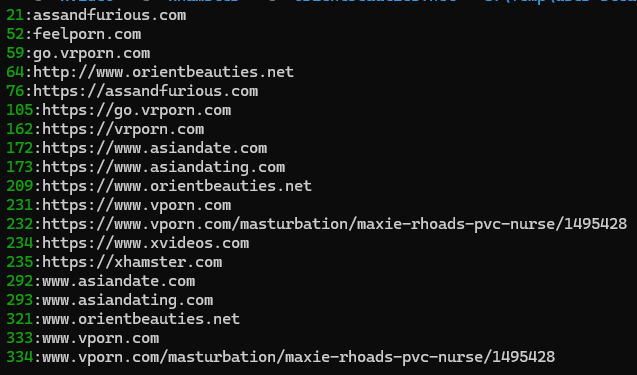
To his credit, he responded and confirmed that the list did indeed contain sites he'd visited, which also included online casinos, crypto websites and VPN services:
They all look like websites I have used and some still do use
As it turns out, he also had two other email addresses in the corpus of data, both with the same collection of passwords used on the first address he replied from. They also both aligned to services based on the same TLD as the other email address which suggested which country he's located in. (Incidentally, the online privacy offered by VPNs kinda falls apart when there's malware on your machine watching every site you visit and recording your credentials.)
Even without a response from a subscriber, it's still easy to get a sense of the legitimacy of the data in a privacy-preserving fashion (i.e. not logging in with their credentials!) just by testing enumeration vectors. For example, one subscriber had an account at ShopBack in the Philippines which offers what I'll refer to as "account enumeration as a service":
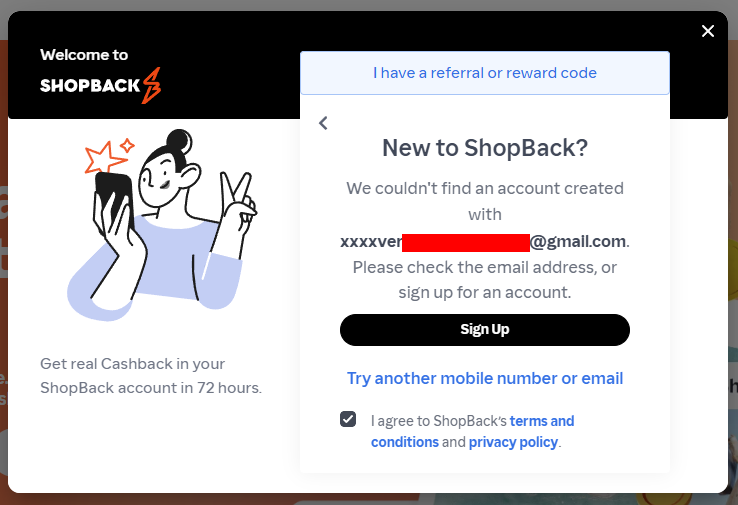
I simply added some character's in front of the email address and ShopBack happily confirmed that address didn't exist. However, remove the invalid characters and there's a very different response:
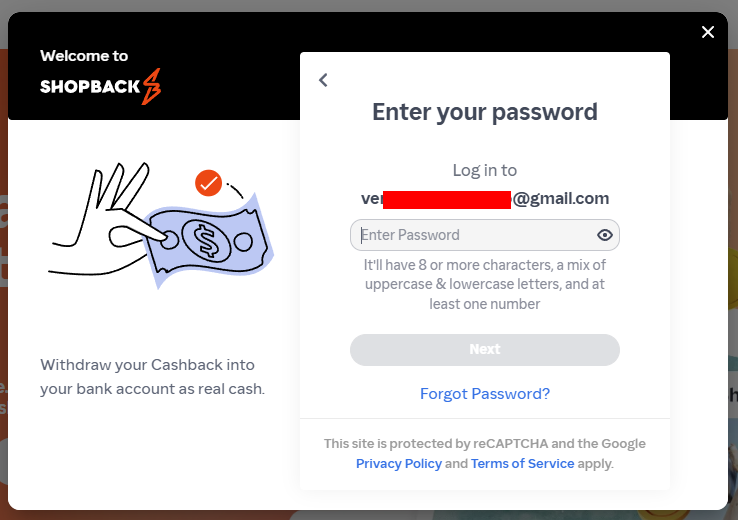
All of these little "tells" add up; another subscriber had a high prevalence of Greek websites they used, showing exactly the sort of pattern you'd expect to see for someone from that corner of the world. Another had various online survey sites they'd used, and like our "assandfurious" friend from earlier, a clear pattern emerged consistent with the apparent interests of the address's owner. Time and time again, the data checked out, so we loaded it. Those 183M email addresses are now searchable in HIBP, and the passwords are also searchable in Pwned Passwords, which has become rather popular:
Pwned Passwords just served 17.45 billion requests in 30 days 🤯 That's an *average* of 6,733 requests per second, but at our peak, we're hitting 42k per second in a 1-minute block. Crazy numbers! Made possible by @Cloudflare 😎 pic.twitter.com/Io6u1PiqJf
— Troy Hunt (@troyhunt) October 17, 2025
The website addresses are also now searchable, either in the stealer log section of your personal dashboard or by verified domain owners using the API. You'll find this data named "Synthient Stealer Log Threat Data" in HIBP, but stealer logs are only part of the Synthient story - the small part!
Ben's data also contained credential stuffing lists. Unlike stealer logs, which are the product of malware on the victim's machine, credential stuffing lists are typically aggregated from other places where email address and password pairs are obtained. For example, from data breaches where the passwords are either stored in plain text or protected with easily crackable hashing algorithms. Those lists are then used to access the other accounts of victims where they've reused their passwords.
Quick sidenote: Credential stuffing lists can be enormously damaging because they contain the keys to so many different services. Not only are they the gateway to so many takeovers of social media accounts, email addresses and other valuable personal resources, they're also responsible for many subsequent very serious data breaches. The 2017 Uber breach was attributed to previously breached employee credentials. Five years later, and the same approach provided the initial access to Uber again, after which MFA-bombing sealed the deal. Then there was the 23andMe breach in 2023, which was also traced back to credential stuffing. Similar but different was when Dunkin' Donuts had 20k customer details exposed in a show of how multifaceted this style of attack is: they were subsequently sued for not having sufficient controls to stop hackers from simply logging in with victims' legitimate credentials. It's wild; it's the attack that just keeps on giving.
Ever since loading Collection #1 in 2019, I have been extra cautious about dealing with credential stuffing lists. The 400+ comments on that blog post will give you just a little taste of how much attention that exercise garnered. Frankly, it was a significant contributor to the feeling that it was all getting a bit too much, leading to the decision that HIBP needed to find another home (which fortunately, never eventuated). The primary issue with credential stuffing lists is that we can't attribute a given row to a specific source website or data breach, and we don't offer a service to look up credential pairs. As you'll see from many of the comments on that post, I had angry people upset that, without knowing specifically which password was exposed in the list, the knowledge that they were in there was not actionable. I disagree, because by loading those passwords into Pwned Passwords, there are now three easy ways to check if you're using a vulnerable one:
My vested interest in 1Password aside, Watchtower is the easiest, fastest way to understand your potential exposure in this incident. And in case you're wondering why I have so many vulnerable and reused passwords, it's a combination of the test accounts I've saved over the years and the 4-digit PINs some services force you to use. Would you believe that every single 4-digit number ever has been pwned?! (If you're interested, the ABC has a fantastic infographic using a heatmap based on HIBP data that shows some very predictable patterns for 4-digit PINs.)
As of the time of publishing this blog post, only the stealer logs have been loaded, and as mentioned earlier, the data in HIBP has been called "Synthient Stealer Log Threat Data". We intend to load the credential stuffing data as a separate corpus next week and call it "Synthient Credential Stuffing Threat Data", assuming it's sufficiently new and the accuracy is confirmed with our subscribers! We're doing this in two parts simply because of the scale of the data and the fact that we want to break it into two discrete corpuses given the data originates via different means. I'll revise this blog post accordingly after we finish our analysis.
Something that is becoming more evident as we load more stealer logs is that treating them as a discrete "breach" is not an accurate representation of how these things work. The truth is that, unlike a single data breach such as Ashley Madison, Dropbox, or the many other hundreds already in HIBP, stealer logs are more of a firehose of data that's just constantly spewing personal info all over the place. That, combined with the duplication of previously seen data, means that we need a rethink on this model. The data itself is still on point, but I'd like to see HIBP better reflect that firehose analogy and provide a constant stream of new data. Until then, Synthient's Threat Data will still sit in HIBP and be searchable in all the usual ways.

You see it all the time after a tragedy occurs somewhere, and people flock to offer their sympathies via the "thoughts and prayers" line. Sympathy is great, and we should all express that sentiment appropriately. The criticism, however, is that the line is often offered as a substitute for meaningful action. Responding to an incident with "thoughts and prayers" doesn't actually do anything, which brings us to court injunctions in the wake of a data breach.
Let's start with HWL Ebsworth, an Australian law firm that was the victim of a ransomware attack in 2023. They were granted an injunction, which means the following:
The final interlocutory injunction restrained hackers from the ALPHV, or “BlackCat”, hackers group from publishing the HWL data on the internet, sharing it with any person, or using the information for any reason other than for obtaining legal advice on the court’s orders.
To paraphrase, the injunction prohibits the Russian crime gang that hacked the law firm and attempted to extort them from publishing the data on the internet. Right... The threat actor was subsequently served with the injunction, to which, per the article, they responded in an entirely predictable fashion:
Fuck you fuckers
And then they dumped a huge trove of data. Clearly, criminals aren't going to pay any attention whatsoever to an injunction, but this legal construct has reach far beyond just the bad guys:
The injunction will also “assist in limiting the dissemination of the exfiltrated material by enabling HWLE to inform online platforms, who are at risk of publishing the material”, Justice Slattery said.
In other words, the data is also off limits to the good guys. Journalists, security firms and yes, Have I Been Pwned (HIBP) are all impacted by injunctions like this. To some extent, you can understand this when the data is as sensitive as what a law firm typically holds, and you need only use a little bit of imagination to picture how damaging it can be for data like this to fall into the wrong hands. But data in a breach of a company like Qantas is very different:
And now here’s mine. Still no indication of specifically which service was breached, but feels very much like loyalty program data (i.e. nothing to do with specific flights, password, passport or payment details). pic.twitter.com/r7KnlfM8TV
— Troy Hunt (@troyhunt) July 11, 2025
As well as my interest in running HIBP, I also appear to be a victim of their data breach, along with my wife and kids. And just to highlight how much skin I have in the game, I'm also a Qantas shareholder and a very loyal customer:
Sitting at the airport about to take my 301st (tracked) @Qantas flight. Nice banter with the staff: “you can lose my data, just don’t lose my bags” 😬 pic.twitter.com/ZGxc4I0aB1
— Troy Hunt (@troyhunt) July 2, 2025
As such, I was particularly interested when they applied for, and were granted, a court injunction of their own. Why? What possible upside does this provide? Because by now, it's pretty clear what's going to happen to the data:
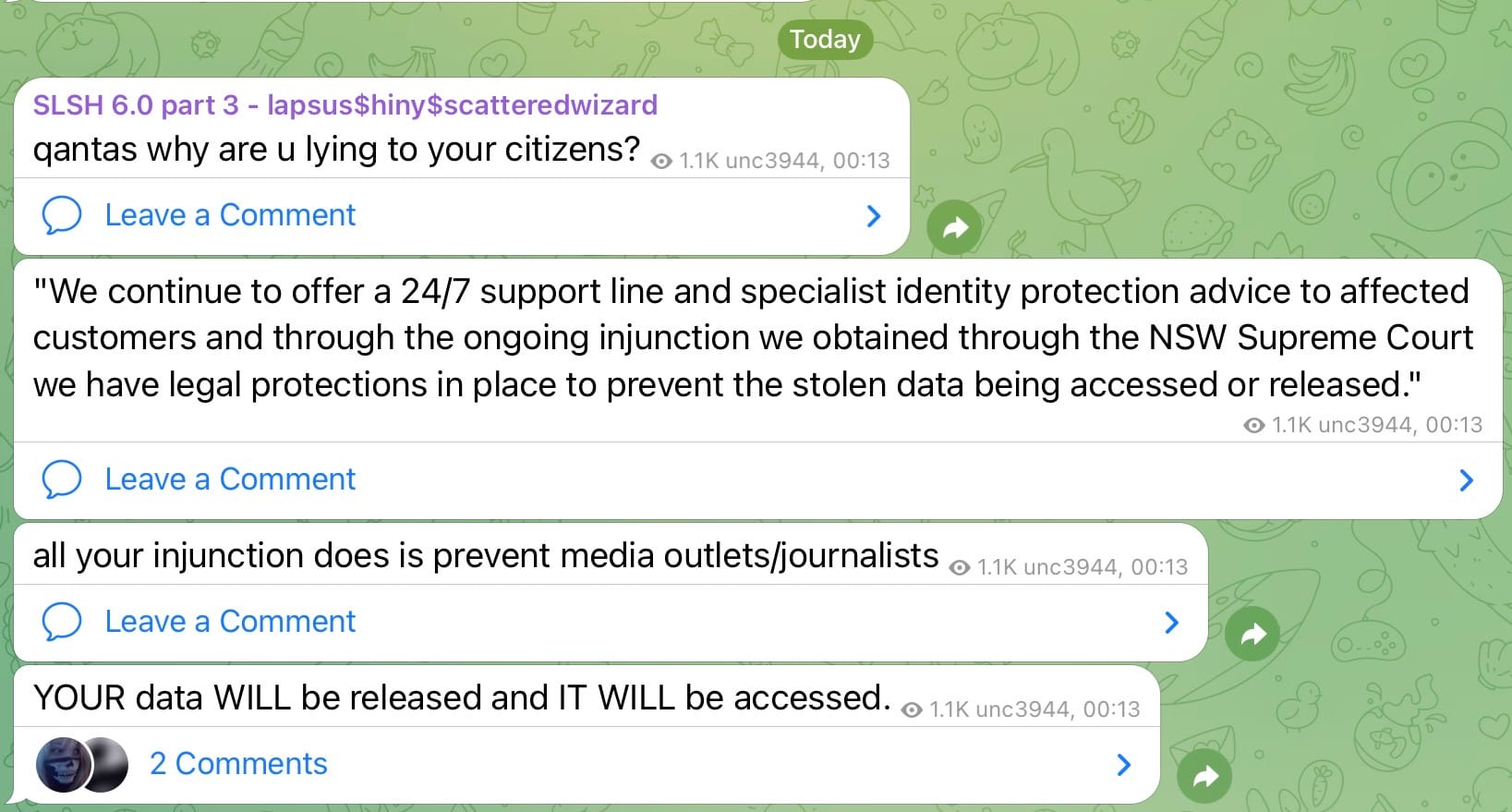
This is from a Telegram channel run by the group that took the Qantas data, along with some other huge names:
🚨🚨🚨BREAKING - New data leak site by Scattered LAPSUS$ Hunters exposes Salesforce customers. Dozens of global companies involved in a large-scale extortion campaign.
— Hackmanac (@H4ckmanac) October 3, 2025
Scattered LAPSUS$ Hunters claims to have breached Salesforce, exfiltrating ~1B records.
They accuse Salesforce… pic.twitter.com/u2PAO7miyP
"Scattered LAPSUS$ Hunters" is threatening to dump all the data publicly in a couple of days' time unless a ransom is paid, which it won't be. The quote from the Telegram image is from a Qantas spokesperson, and clearly, the injunction is not going to stop the publishing of data. Much of my gripe with injunctions is the premise that they in some way protect customers (like me), when clearly, they don't. But hey, "thoughts and prayers", right?
Without wanting to give too much credit to criminals attempting to ransom my data (and everyone else's), they're right about the media outlets. An injunction would have had a meaningful impact on the Ashley Madison coverage a decade ago, where the press happily outed the presence of famous people in the breach. Clearly, the Qantas data is nowhere near as newsworthy, and I can't imagine a headline going much beyond the significant point balances of certain politicians. The data just isn't that interesting.
The injunction is only effective against people who meet the following criteria:
The first two points are obvious, and an asterix adorns the third as it's very heavily caveated. This from a chat with a lawyer friend thir morning who specialises in this space:
it would depend on which country and whether it has a reciprocal agreement with Australia eg like the UK and also who you are trying it enforce it against and then it’s up to the court in that country to determine - but as this is an injunction (so not eg for a debt against a specific person) it’s almost impossible - you can’t just register a foreign judgement somewhere against the world at large as far as I know.
So, if the injunction is so useless at providing meaningful protections to data breach victims, what's the point? Who does it protect? In researching this piece, the best explanation I could find was from law firm Clayton Utz:
Where that confidentiality is breached due to a hack, parties should generally do - and be seen to be doing - what they can to prevent or minimise the extent of harm. Even if injunctions might not impact hackers, for the reasons set out above, they can provide ancillary benefits in relation to the further dissemination of hacked information by legitimate individuals and organisations. Depending on the terms, it might also assist with recovery on relevant insurance policies and reduce the risk of securities class actions being brought.
That term - "be seen to be doing" - says it all. This is now just me speculating, but I can envisage lawyers for Qantas standing up in court when they're defending against the inevitable class actions they'll face (which I also have strong views on), saying "Your honour, we did everything we could, we even got an injunction!" In a previous conversation I had regarding another data breach that had successfully been granted an injunction, I was told by the lawyer involved that they wanted to assure customers that they'd done everything possible. That breach was subsequently circulated online via a popular clear web hacking site (not "the dark web"), but I assume this fact and the ineffectiveness of the injunction on that audience was left out of customer communications. I feel pretty comfortable arguing that the primary beneficiary of the injunction is the shareholder, rather than the customer. And I assume the lawyers charge for their time, right?
Where this leaves us with Qantas is that, on a personal note, as a law-abiding Australian who is aware of the injunction, I won't be able to view my data or that of my kids. I can always request it of Qantas, of course, but I won't be able to go and obtain it if and when it's spread all over the internet. The criminals will, of course, and that's a very uncomfortable feeling.
From an HIBP perspective, we obviously can't load that data. It's very likely that hundreds of thousands of our subscribers will be impacted, and we won't be able to let them know (which is part of the reason I've written this post - so I can direct them here when asked). Granted, Qantas has obviously sent out disclosure notices to impacted individuals, but I'd argue that the notice that comes from HIBP carries a different gravitas: it's one thing to be told "we've had a security incident", and quite another to learn that your data is now in circulation to the extent that it's been sent to us. Further, Qantas won't be notifying the owners of the domains that their customers' email addresses are on. Many people will be using their work email address for their Qantas account, and when you tie that together with the other exposed data attributes, that creates organisational risk. Companies want to know when corporate assets (including email addresses) are exposed in a data breach, and unfortunately, we won't be able to provide them with that information.
I understand that Qantas' decision to pursue the injunction is about something much broader than the email addresses potentially appearing in HIBP. I actually think much of the advice Qantas has given is good, for example, the resources they've provided on their page about the breach:
These are all fantastic, and each of them has many good external resources people worried about scams should refer to. For example, ScamWatch has this one:
And cyber.gov.au has a handy tip courtesy of our Australian Signals Directorate makes this suggestion:

Not to miss a beat, our friends at IDCARE also offer great advice:

And, of course, the OAIC has some fantastic guidance too:

The scam resources Qantas recommends all link through to a service that will never return the Qantas data breach. Did I mention "thoughts and prayers" already?
As threatened, the Qantas data was dumped publicly 2 days after writing this post. The data appeared on a clear web file sharing service linked to by both their .onion website and a clear web site that popped up on a new domain shortly after the data was publicised. Due to the injunction, I've not accessed the data myself but have had security folks in other parts of the world reach out and confirm my record and that of my family members is present. I've also seen public commentary from other researchers analysing the data, and have had multiple people contact me and offer to send it.
Clearly, the injunction has proven to be extremely limited in its ability to stop the spread of data. Further, as a Qantas customer, I've not heard anything from them in relation to my data having now been publicly released. None of this should surprise anybody, including Qantas.
As to questions in the comments about the legitimacy of the injunction and where it can be obtained, the advice I've obtained from the law firm we use is that it is absolutely legitimate and interested parties would need to contact Qantas if they want to see it (likely a redacted version). I'm not savvy with the mechanics of how courts issue these and why they're not more publicly accessible, but I suggest this story with quotes from Justice Kunc is worth a read. Frankly, it's all a bit nuts, but that's the environment we're operating in and the rules we need to adhere to.
It's hard to explain the significance of CERN. It's the birthplace of the World Wide Web and the home of the largest machine ever built, the Large Hadron Collider. The bit that's hard to explain is, well, I mean, look at it!

Charlotte and I visited CERN in 2019, nestled in there between Switzerland and France, and descended into the mountainside where we saw the world's largest particle accelerator firsthand. I can't explain this! The physics are just mind-bending.
A few months ago, we headed back there and saw even more stuff I can't explain:

How on earth do you make antimatter?! I know there's a lot of magnets involved, but that's about the limit of my understanding.
But what I do understand a little better is the importance of CERN. They're working to help humanity understand the most profound questions about the universe by exploring fundamental physics—the very building blocks of nature. And closer to my heart (or at least to my expertise), their role in the World Wide Web and the contribution CERN has made to the internet as we know it today cannot be overstated. It's also staffed by passionate individuals with a love of science that transcends borders and politics, including many from parts of the world that don't normally see eye-to-eye. This passion was evident on both our visits, and perhaps that's an extra poignant observation in a time with so much conflict.
In relation to HIBP and our ongoing support of governments, CERN is similar yet different. It's an intergovernmental organisation operating outside the jurisdiction of any one nation. However, they face the same online threats, and just like sovereign government states, their people sign up to services that get breached and end up in HIBP. And, like the governments we support, services that can be provided to help them tackle that threat are always appreciated. I was surprised to hear on our last visit that the sum total of contributions from their member states amounts to the price of a cup of coffee per person per year! For the work they do and the contribution they make to society, onboarding CERN as the 41st (inter)government was a no-brainer. They now have full and free access to query all CERN domains across the breadth of HIBP data. Welcome aboard CERN!
![]()

One of the most common use cases for HIBP's API is querying by email address, and we support hundreds of millions of searches against this endpoint every month. Loads of organisations use this service to understand the exposure of their customers and provide them with better protection against account takeover attacks. Many also use it to support customers who've already fallen victim - "hey, did you know HIBP says you're in 7 data breaches, any chance you've been reusing passwords?" Some companies even use it to help establish the legitimacy of an email address; we're all so pwned that if an address isn't pwned, maybe it isn't even real.
The latest video demo walks you through how to use this API and introduces something new that has been requested for years: a test API key. We've had this request so many times, and my response has usually been something to the effect of "mate, a key is a few bucks, just get a cheapie and start writing code". However, even if it were just a few cents, it would still pose a burden to some for various reasons. So, today we're also launching a test key:
hibp-api-key: 00000000000000000000000000000000The test key can only be used for queries against the test accounts (and we've had those for many years now), but it allows developers to start immediately writing code against the real live APIs. The technical implementation is identical to the key you get when you have a paid subscription, so this should help a bunch of people really fast-track their development and remove that one little barrier we previously had. Here's how it all works:
So, that's the breached account API, and it comes off the back of last week's first demo, showing how domain searches work. We've got a heap more to add yet and I'd love to hear about and others you feel would help you get the most out of the service.

Well, one of them is, but what's important is that we now have a platform on which we can start pushing out a lot more. It's not that HIBP is a particularly complex system that needs explaining in any depth, but we still get a lot of "how do I..." style questions for the fundamentals. Stuff like "how do I search our domain", which is why that's now the very first video we have in the series:
You'll also find this on the brand new demos page at haveibeenpwned.com/Demos where you'll soon be seeing many more examples that'll start with the basics, then become increasingly complex. The APIs in particular are the source of many support tickets, and we hope that these demos simplify them for the masses and save us some ticketing overhead in the process.
The demo is only five and a bit minutes, and I want to keep each one pretty succinct. If there's something you'd like to see explained, please drop me a comment below, and I'll do my best to create some material on it. In the meantime, check out the brand new HIBP YouTube channel and give it some love, there's a lot more coming.
Incidentally, in checking the stats whilst preparing this, it seems that we now have 357k instances of someone monitoring a domain 😲 That includes almost a quarter of the world's top 1k largest domains too, so this is a very heavily used feature and was a logical place to get started.

We were recently travelling to faraway lands, doing meet and greets with gov partners, when one of them posed an interesting idea:
What if people from our part of the world could see a link through to our local resource on data breaches provided by the gov?
Initially, I was sceptical, primarily because no matter where you are in the world, isn't the guidance the same? Strong and unique passwords, turn on MFA, and so on and so forth. But our host explained the suggestion, which in retrospect made a lot of sense:
Showing people a local resource from a trusted government body has a gravitas that we believe would better support data breach victims.
And he was right. Not just about the significance of a government resource, but as we gave it more thought, all the other things that are specific to the local environment. Additional support resources. Avenues to report scams. Language! Like literally, presenting content in a way that normal everyday folks can understand it based on where they are in the world. And we have the mechanics to do this now as we're already geo-targeting content on the breach pages courtesy of HIBP's partner program.
Whilst we're still working through the mechanics with the gov that initially came up with this suggestion, during a recent chat with our friends "across the ditch" at New Zealand's National Cyber Security Centre, I mentioned the idea. They thought it was great, so we just did it 🙂 As of now, if you're a Kiwi and you open up any one of the 899 breach pages (such as this one), you'll see this advice off to the right of the screen:

That links off to a resource on their Own Your Online initiative, which aims to help everyday folks there protect themselves in cyberspace. There's lots of good practical advice on the site along the lines I mentioned earlier, and even a suggestion to go and check out HIBP (which now links you back to the NZ NCSC...)
I'll be reaching out to our other gov partners around the world and seeing what resources they have that we could integrate, hopefully it's just one more little step in the right direction to protect the masses from online nasties.
Edit: As we add more local resources, I'll update this blog post with screen grabs and links, starting with our local Australian Signals Directorate:

We've now also added Bulgaria, complete with local language instructions:

I'm often asked if cyber criminals are getting better at impersonating legitimate organisations in order to sneak their phishing attacks through. Yes, they absolutely are, but I also argue that the inverse is true too: legitimate organisations frequently communicate in ways that are indistinguishable from a phishing attack! I can name countless examples of banks, delivery services and even government agencies sending communication that I was convinced was a phish, but turned out to be legit. I once had an argument with an agent from our own tax office on precisely that basis. After having shown all the hallmarks of being a scammer, she instead turned out to be making a legitimate inquiry. And if you need more convincing that even I can't tell the difference between a scam and legit comms, look no further than my own recent failure to spot a phish that successfully extracted my Mailchimp credentials, including the 2FA code!
I don't mind recognising that I struggle with scams, and frankly, it creates a lot more empathy for the masses out there who don't spend their days thinking about cybersecurity. These are the sorts of folks who use Have I Been Pwned and often land there a bit frazzled, looking for answers after learning they've been breached in some nasty incident. They need a proactive defence against this style of attack that can protect them when the human controls fail, as they recently failed me. That's why today, I'm very happy to announce a new HIBP partner, Guardio! You'll find them located on each dedicated breach page, and on the home page of your personal dashboard:
We've now turned the above recommendation on for all US-based visitors and highlighted them for all audiences regardless of locale on the partners page. We believe the service they offer makes a meaningful difference to the security posture of our users, and we are happy to include them here to complement the unique services provided by our existing partners. So it's a big welcome to Guardio, and I look forward to sharing more about the work they're doing to protect us all in the future. Check out what Guardio does on their dedicated HIBP page now.

If I'm honest, I was never that keen on a merch store for Have I Been Pwned. It doesn't make the code run faster, nor does it load any more data breaches or add any useful features to the service whatsoever. But... people were keen. They wanted swag they could wear or drink from or whatever, and it's actually pretty cool that there's excitement about HIBP as a brand. Plus, setting up a merch store is easy, right?
To cut to the chase, we set up a store on Teespring and they've been an absolute bloody disaster. Like, appalling bad to the point where we began to wonder if they're even legitimate, and I wish we had found a blog post like this before entrusting them with our brand. Initially, it was just dumb stuff like this:
FFS @teespringcom 🤦♂️ So far finding their support just appealing incompetent, this is regarding the @haveibeenpwned merch store, check out the canonical link: https://t.co/uHBeTlI1yU pic.twitter.com/nJBTGfCrqg
— Troy Hunt (@troyhunt) June 2, 2025
I mean, really dumb:
<link rel="canonical" href="https://0.0.0.0:3000" />So, everyone who visited the store and tried to share it via a mobile device was sending that address, and Teespring's response was that people should just manually copy and paste the URL! I stand by my reactions in that tweet - FFS 🤦♂️
Or on a similar note of technical incompetence, they were completely unable to add me to our store as an admin:
For those that come later and consider @teespringcom, don't even think about it! I've been trying to join the store @Charlotte_Hunt_ set up for us for 4 weeks ago now and the invite just gives a JSON response about failed CAPTCHA every time. Support is completely useless 😡 pic.twitter.com/d4EH6nC5O2
— Troy Hunt (@troyhunt) June 9, 2025
That support thread spanned from the 16th of May to the 12th of June and culminated in:
At this time, I still don’t have any updates from the Tech team. I understand this isn’t the resolution you were hoping for, and I sincerely apologize for the inconvenience and the delay.
And that's just the technical examples. The real pain came once we ordered merch, here's the timeline:
It's not just us either; not only have I not seen a single "hey, check out my cool HIBP merch" social post, I have received messages like this:
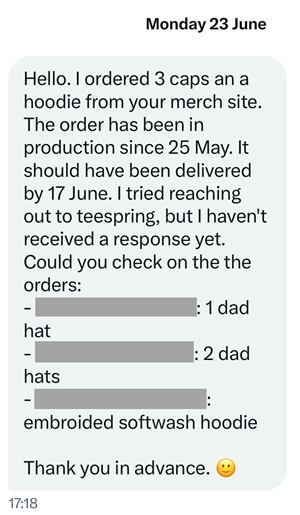
So, onto that dispute and believe it or not, this is the first time I've ever lodged a one. Turns out it's really simple, and I'd like to show everyone who made a purchase through the Teespring store just how easy it is. Firstly, I found the transaction on my Amex card:
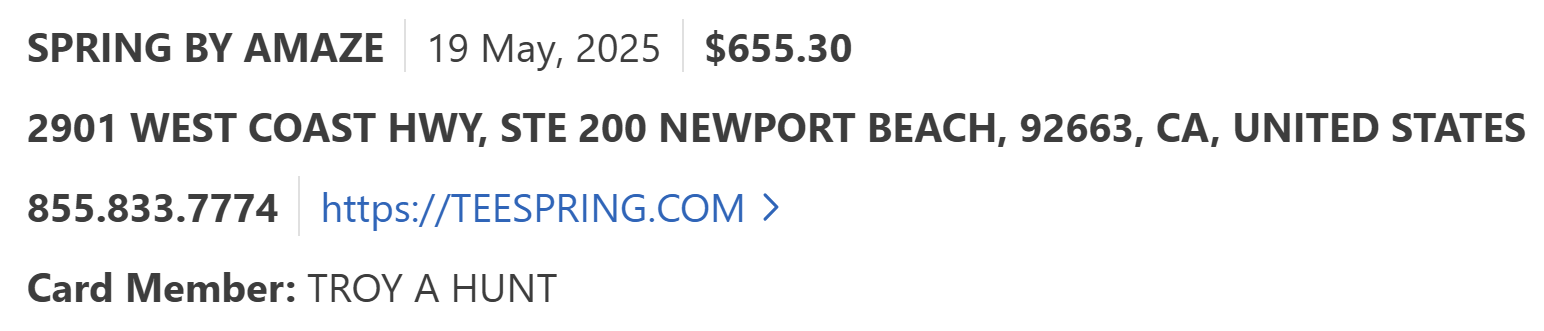
That record had an option to submit a dispute which then allowed me to choose a reason:
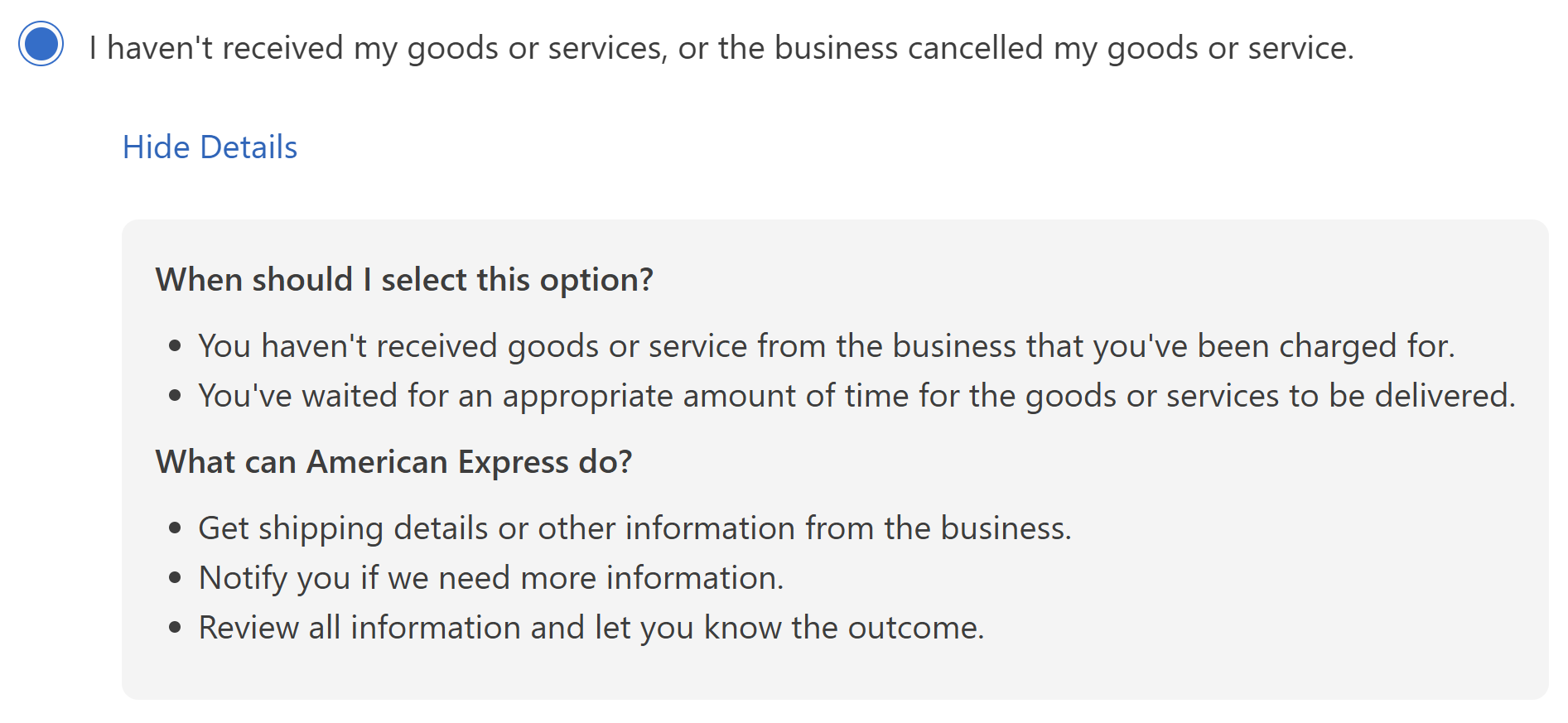
A few little questions in between (dates, attempts to contact them, etc), and we're done:
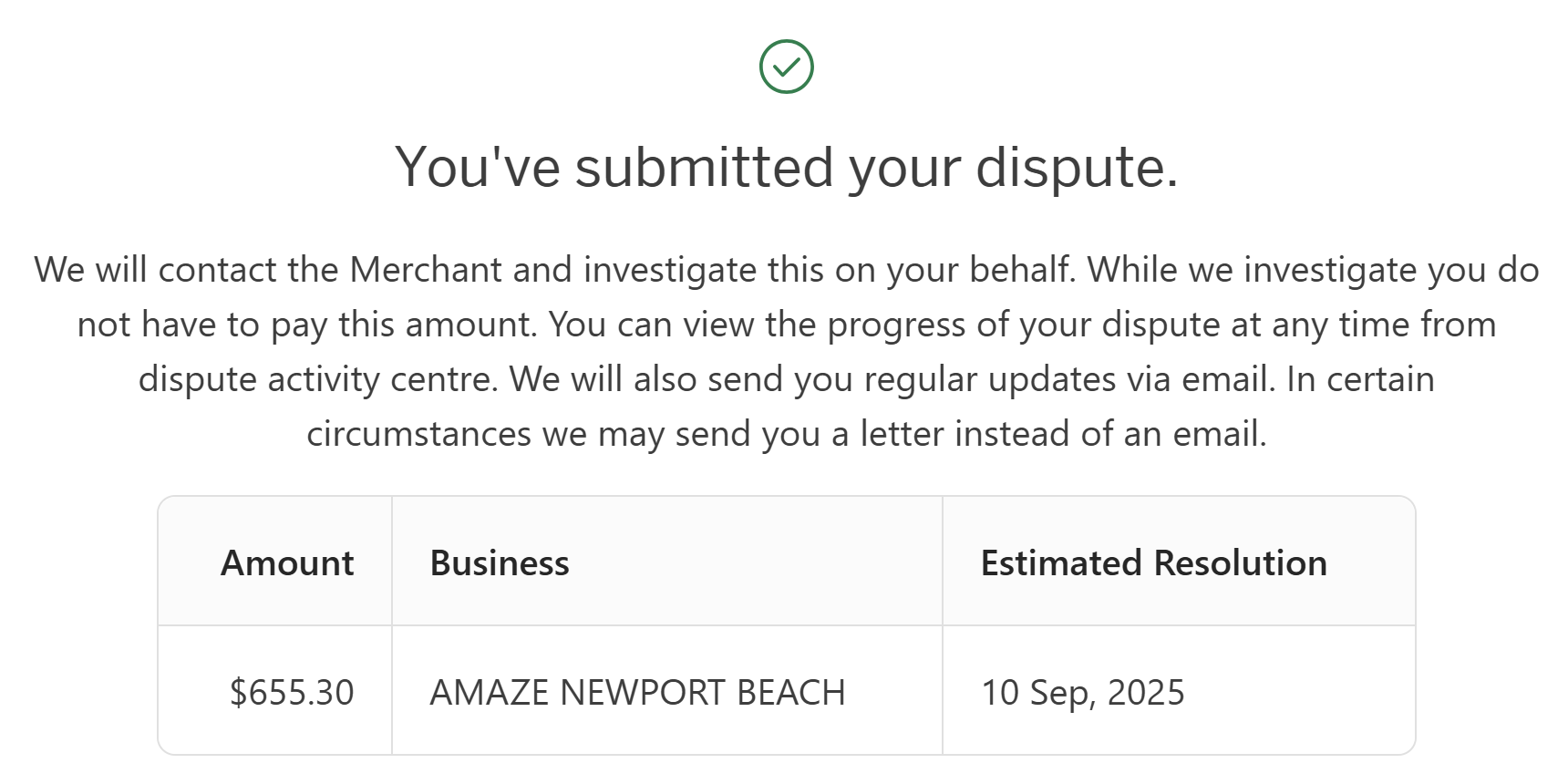
And just like that, Teespring suddenly found the ability to reply to support queries again!
We noticed a dispute was recently submitted for your transaction related to order #[reacted], with the reason noted as PRODUCT_NOT_RECEIVED. We wanted to reach out directly to better understand the situation and see how we can assist.
That came through yesterday, the 20th of July. As I think I've done a pretty decent job of outlining the situation in this blog post, we'll be sending them a link to it and following through with the dispute. Raising a dispute with your card provider not only returns the funds to your account, but it also levies a fee on the merchant, which in this case, seems entirely deserved.
I sincerely apologise to the HIBP supporters who trusted us enough to go to the merch store and make a purchase. This experience seriously sucks and should never have happened. I'll update this post with any further feedback I get from Teespring or Amex.
Onto more positive things, and an opportunity did arise out of Teespring's incompetence:
Happy to help you switch to Fourthwall. Shoot me a DM and we’ll move everything over for you
— Will Baumann (@dubbaumann) June 3, 2025
Usually, I'd be reluctant to respond to someone jumping in on a thread and pitching their product, but hey, we were desperate! And it turns out that Fourthwall is pretty awesome because people there actually talk to you and get stuff done 🙄 I mean, properly done:
We’ve got @haveibeenpwned merch! Arrived a little while ago and finally got into it today, we’ll keep adding more stuff to the store based on demand: https://t.co/uHBeTlI1yU pic.twitter.com/dQW7dcM0Ey
— Troy Hunt (@troyhunt) July 21, 2025
We ordered it on 2 July and received part of the order in Australia on 7 July, and the other part on 18 July. That's 5 and 16 days (both of which exceeded their estimate of 21-24 July), whilst the Teespring order was lodged 63 days ago 🤷♂️
So, check out merch.haveibeenpwned.com and have confidence that you will actually get what you order. Please leave a comment below if there's anything else you'd like to see in the store, and don't forget to pick up some nice thongs for yourself some nice thongs!

One of the greatest fears we all have in the wake of a data breach is having our identity stolen. Nefarious parties gather our personal information exposed in the breach, approach financial institutions and then impersonate us to do stuff like this:
So I recently somewhat had my identity stolen, someone used my driver's license to open about 10 different bank accounts across 6 Banks.
This was the message I received from a friend of mine just last week, and he was in a real mess. The bad guys had gotten so far into his real-life identity that not only were there a bunch of bank accounts now in his name, he was even having trouble proving who he was. Which makes sense when you think about it: once someone has the data attributes you use to verify your identity, how does a bank know that you're the real you? Like I said, it was a real mess, and he only found out about it after a lot of damage had already been done.
Which brings me to identity protection and, more specifically, Aura. I've known the folks there for years, and they were a sponsor of this blog for half a dozen weeks back in 2023. Their remit is to protect people from precisely the sort of outcomes my friend above suffered. They pride themselves on responding to fraud events super fast, providing 24/7 US-based customer support (that alone makes a massive difference), and even providing $1M American dollars in identity theft insurance. The US emphasis there is because, like Truyu who we recently onboarded to help Aussies, Aura is a geo-specific service and in this case, is there to help our friends in the US. As such, if you're coming to HIBP from that part of the world you'll see them appear in your dashboard and on the breach-specific pages:
Aura is there right alongside 1Password; two different companies offering two of the most valuable services to help protect you both before and after a data breach. And if you "Try Aura" per the link above, you'll land on their dedicated Have I Been Pwned page which provides you with a tasty discount.
Aura is a perfect example of the partnerships we've sought out to help make a positive difference to data breach victims, so a big welcome and thank you for providing the service they do.

As we gradually roll out HIBP’s Partner Program, we’re aiming to deliver targeted solutions that bridge the gap between being at risk and being protected. HIBP is the perfect place to bring these solutions to the forefront, as it's often the point at which individuals and organisations first learn of their exposure in data breaches. The challenge for corporates, in particular, is especially significant as they're tasked with protecting entire workforces, often against highly motivated and sophisticated attackers seeking to exploit organisational vulnerabilities. That's why today, I'm especially happy to welcome Push Security to the program.
Push's mandate is to "defend workforce identities in the browser" from attacks that put corporate assets at risk. Especially within the context of data breaches, this includes attacks that leverage reused credentials (which often appear in breaches), account takeovers, phishing and session hijacking. Protecting organisations directly in the browser makes a lot of sense given how many attacks originate in that environment (something I'm painfully familiar with myself), and as they're fond of saying, "Push Security is like EDR but for the browser".
Because Push is focused on business solutions, they now have placement within the business section of the HIBP dashboard, namely the overview and domains pages:
I'm really happy with how we've been able to position partners in a way that's contextual, relevant and non-obtrusive. We've clearly marked Push as "Sponsored" and positioned them right at the heart of where those protecting organisatoins spend their time on HIBP.
Lastly, we've also now launched a dedicated partners page, which lists each relationship we have, including Push Security:

Regardless of where you are in the world, you'll see each partner, the pages on which they are displayed, and any geolocation dependencies. This ensures both transparency and exposure for the organisations we've entrusted to help protect users of our service.
So, a big welcome to Push Security and one more piece in the puzzle of protecting organisations from the scourge of data breaches.

I always used to joke that when people used Have I Been Pwned (HIBP), we effectively said "Oh no - you've been pwned! Uh, good luck!" and left it at that. That was fine when it was a pet project used by people who live in a similar world to me, but it didn't do a lot for the everyday folks just learning about the scary world of data breaches. Partnering with 1Password in 2018 helped, but the impact of data breaches goes well beyond the exposure of passwords, so a couple of months ago, I wrote about finding new partners to help victims "after the breach", Today, I'm very happy to welcome the first such partner, Truyu.
I alluded to Truyu being an excellent example of a potential partner in the aforementioned blog post, so their inclusion in this program should come as no surprise, but let me embellish further. In fact, let's start with something very topical as of the moment of posting:
New email from @Qantas just now: “we believe your personal information was accessed during the cyber incident”. They definitely deserve credit for early communication. pic.twitter.com/dTLlvI0Byq
— Troy Hunt (@troyhunt) July 2, 2025
It's pure coincidence that Qantas' incident coincides with the onboarding of an Aussie identity protection service, but it also makes it all the more relevant. My own personal circumstances are a perfect example: apparently, my name, email address, phone number, date of birth, and frequent flyer number are now in the hands of a hacking group not exactly known for protecting people's privacy. In the earlier blog post about onboarding new partners, I showed how Truyu had sent me early alerts when my identity data was used to sign up for a couple of different financial services. If that happens as a result of the Qantas breach, at least I'm going to know about it early.
The introduction of Truyu as the first of several upcoming partners heralds the first time we've tailored content based on the geolocation of the user. What that means is that depending on where you are in the world, you may see something different to this:
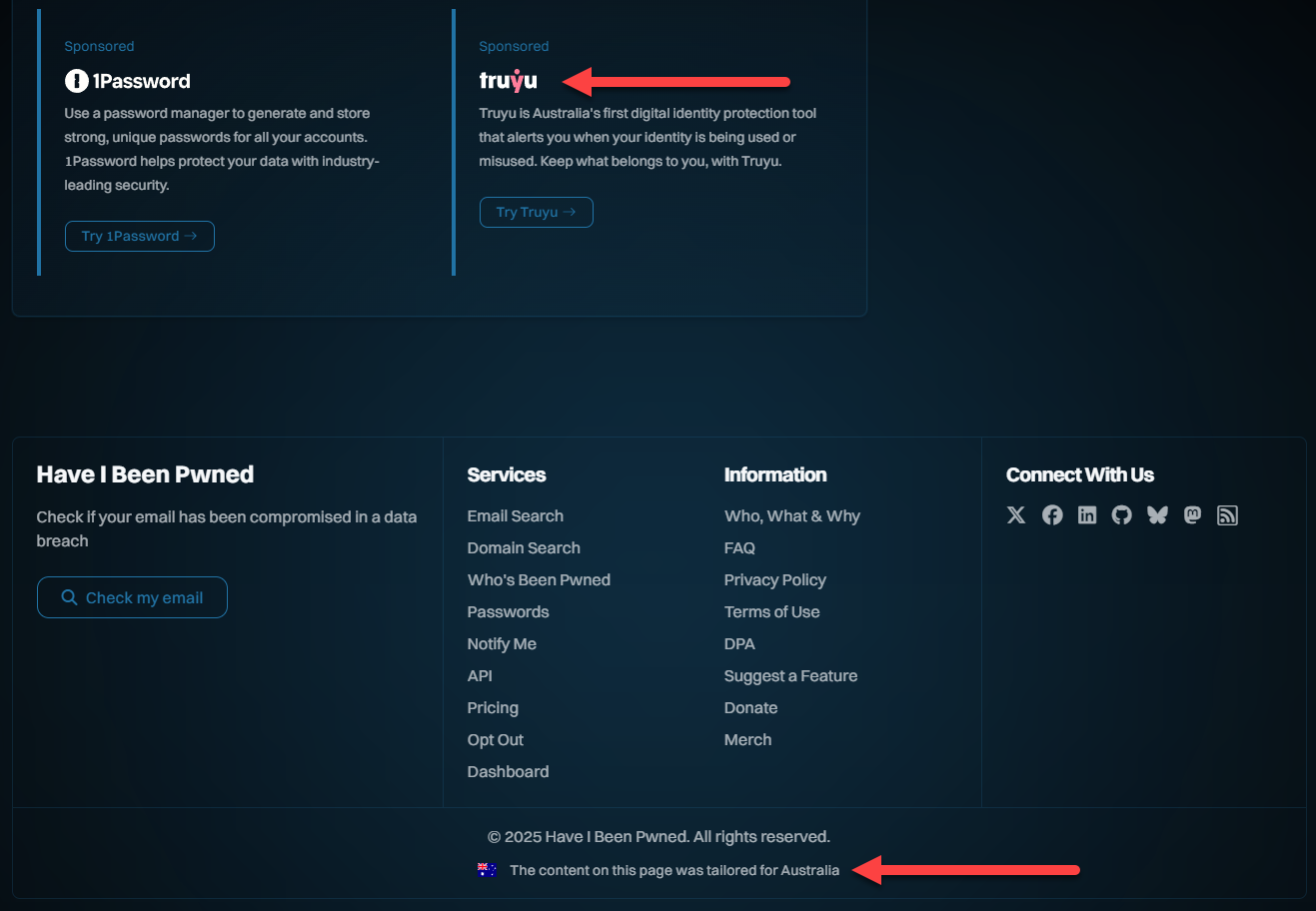
I'm seeing Truyu on the Dropbox breach page because I'm in Australia, and if you're not, you won't. You'll have your own footer with your own country, which is based on Cloudflare's IP geolocation headers. In time, depending on where you are in the world, you'll see more content tailored specifically for you where it's relevant to your location. That's not just product placements either, we'll be adding other resources I'll share more about shortly.
Putting another brand name on HIBP is not something I take lightly, as is evidenced by the fact this is only the second time I've done this in nearly 12 years. Truyu is there because it's a product I genuinely believe provides value to data breach victims and in this case, one I also use myself. And for what it's worth, I've also spent time with the Truyu team in person on multiple occasions and have only positive things to say about them. That, in my book, goes a long way.
So, that's our new partner, and they've arrived at just the perfect time. Now I'm off to jump on a Qantas flight, wish me luck!
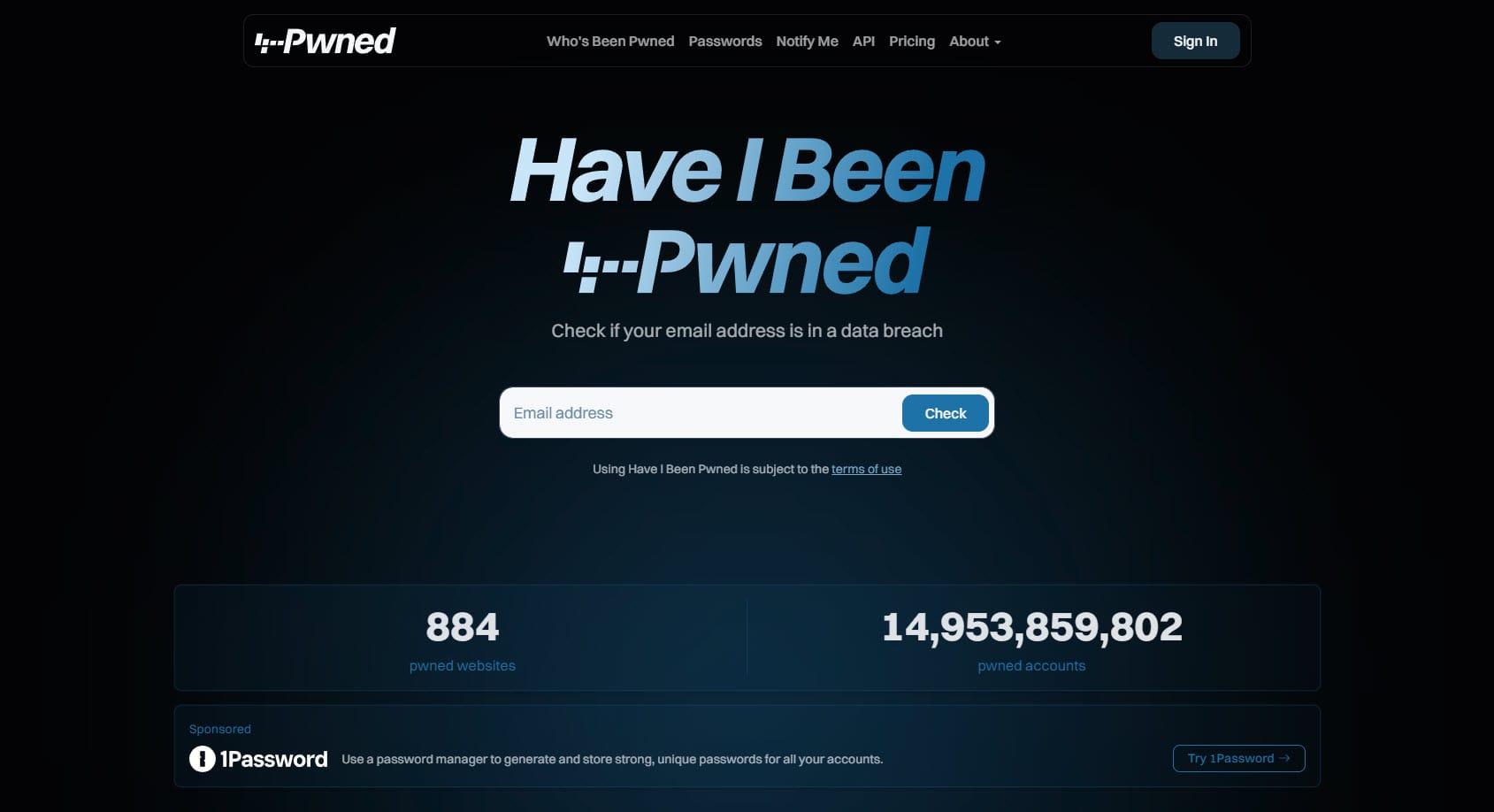
This has been a very long time coming, but finally, after a marathon effort, the brand new Have I Been Pwned website is now live!
Feb last year is when I made the first commit to the public repo for the rebranded service, and we soft-launched the new brand in March of this year. Over the course of this time, we've completely rebuilt the website, changed the functionality of pretty much every web page, added a heap of new features, and today, we're even launching a merch store 😎
Let me talk you through just some of the highlights, strap yourself in!
The signature feature of HIBP is that big search box on the front page, and now, it's even better - it has confetti!
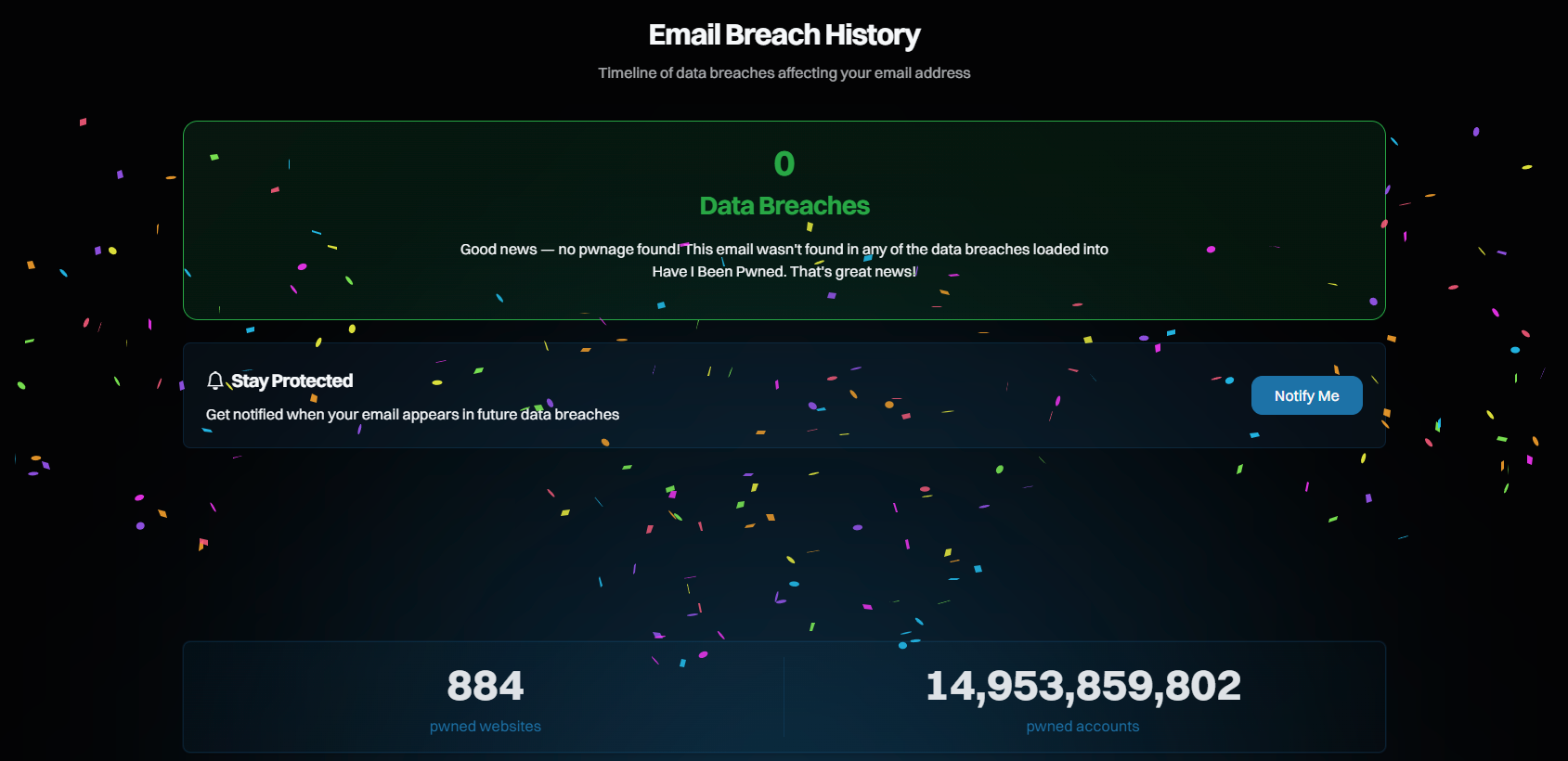
Well, not for everyone, only about half the people who use it will see a celebratory response. There's a reason why this response is intentionally jovial, let me explain:
As Charlotte and I have travelled and spent time with so many different users of the service around the world, a theme has emerged over and over again: HIBP is a bit playful. It's not a scary place emblazoned with hoodies, padlock icons, and fearmongering about "the dark web". Instead, we aim to be more consumable to the masses and provide factual, actionable information without the hyperbole. Confetti guns (yes, there are several, and they're animated) lighten the mood a bit. The alternative is that you get the red response:

There was a very brief moment where we considered a more light-hearted treatment on this page as well, but somehow a bit of sad trombone really didn't seem appropriate, so we deferred to a more demure response. But now it's on a timeline you can scroll through in reverse chronological order, with each breach summarising what happened. And if you want more info, we have an all-new page I'll talk about in a moment.
Just one little thing first - we've dropped username and phone number search support from the website. Username searches were introduced in 2014 for the Snapchat incident, and phone number searches in 2021 for the Facebook incident. And that was it. That's the only time we ever loaded those classes of data, and there are several good reasons why. Firstly, they're both painful to parse out of a breach compared to email addresses, which we simply use a regex to extract (we've open sourced the code that does this). Usernames are a string. Phone numbers are, well, it depends. They're not just numbers because if you properly internationalise them (like they were in the Facebook incident), they've also got a plus at the front, but they're frequently all over the place in terms of format. And we can't send notifications because nobody "owns" a username, and phone numbers are very expensive to send SMSs to compared to sending emails. Plus, every other incident in HIBP other than those two has had email addresses, so if we're asking "have I been pwned?" we can always answer that question without loading those two hard-to-parse fields, which usually aren't present in most breaches anyway. When the old site offered to accept them in the search box, it created confusion and support overhead: "why wasn't my number in the [whatever] breach?!". That's why it's gone from the website, but we've kept it supported on the API to ensure we don't break anything... just don't expect to see more data there.
There are many reasons we created this new page, not least of which is that the search results on the front page were getting too busy, and we wanted to palm off the details elsewhere. So, now we have a dedicated page for each breach, for example:

That's largely information we had already (albeit displayed in a much more user-friendly fashion), but what's unique about the new page is much more targeted advice about what to do after the breach:

I recently wrote about this section and how we plan to identify other partners who are able to provide appropriate services to people who find themselves in a breach. Identity protection providers, for example, make a lot of sense for many data breaches.
Now that we're live, we'll also work on fleshing this page out with more breach and user-specific data. For example, if the service supports 2FA, then we'll call that out specifically rather than rely on the generic advice above. Same with passkeys, and we'll add a section for that. A recent discussion with the NCSC while we were in the UK was around adding localised data breach guidance, for example, showing folks from the UK the NCSC logo and a link to their resource on the topic (which recommends checking HIBP 🙂).
I'm sure there's much more we can do here, so if you've got any great ideas, drop me a comment below.
Over the course of many years, we introduced more and more features that required us to know who you were (or at least that you had access to the email address you were using). It began with introducing the concept of a sensitive breach during the Ashley Madison saga of 2015, which meant the only way to see your involvement in that incident was to receive an email to the address before searching. (Sidenote: There are many good reasons why we don't do that on every breach.) In 2019, when I put an auth layer around the API to tackle abuse (which it did beautifully!) I required email verification first before purchasing a key. And more things followed: a dedicated domain search dashboard, managing your paid subscription and earlier this year, viewing stealer logs for your email address.
We've now unified all these different places into one central dashboard:
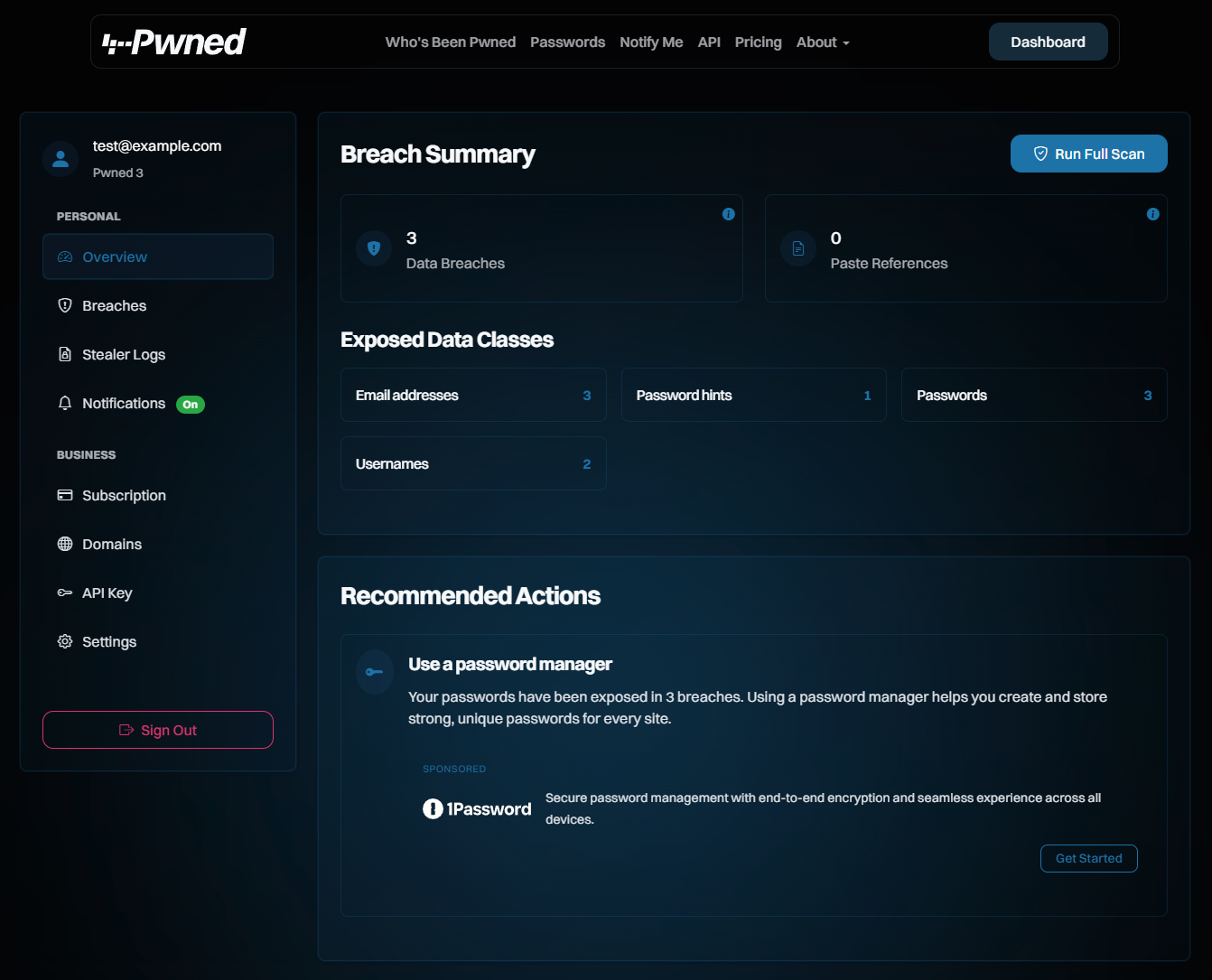
From a glance at the nav on the left, you can see a lot of familiar features that are pretty self-explanatory. These combine relevant things for the masses and those that are more business-oriented. They're now all behind the one "Sign In" that verifies access to the email address before being shown. In the future, we'll also add passkey support to avoid needing to send an email first.
The dashboard approach isn't just about moving existing features under one banner; it will also give us a platform on which to build new features in the future that require email address verification first. For example, we've often been asked to provide people with the ability to subscribe their family's email addresses to notifications, yet have them go to a different address. Many of us play tech support for others, and this would be a genuinely useful feature that makes sense to place at a point where you've already verified your email address. So, stay tuned for that one, among many others.
More time went into this one feature than most of the other ones combined. There's a lot we've tried to do here, starting with a much cleaner list of verified domains:

The search results now give a much cleaner summary and add filtering by both email address and a hotly requested new feature - just the latest breach (it's in the drop-down):
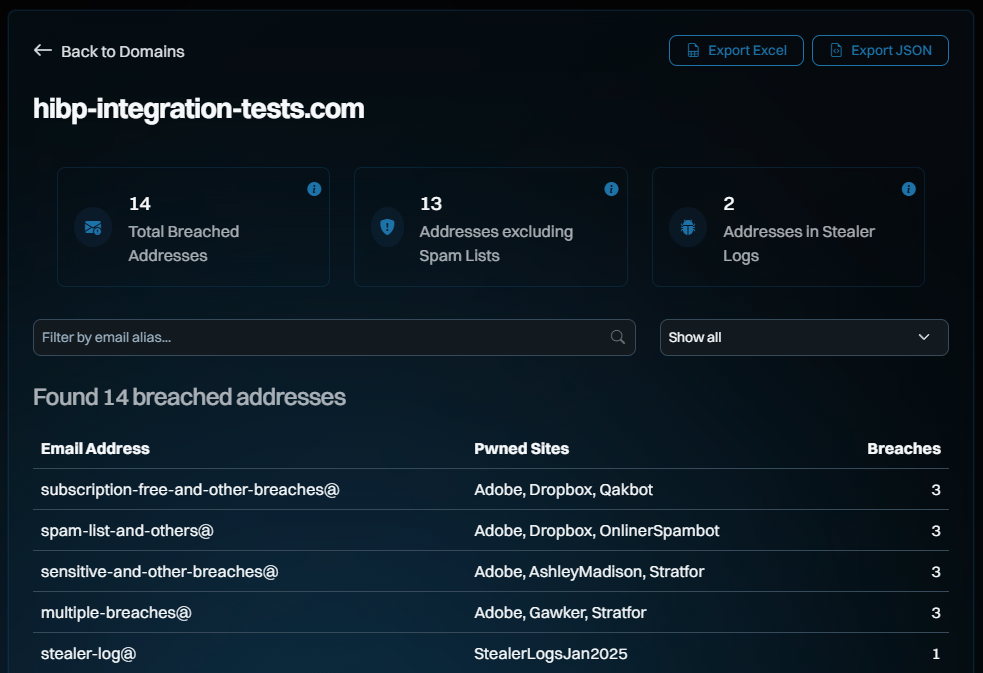
All those searches now just return JSON from APIs and the whole dashboard acts as a single-page app, so everything is really snappy. The filtering above is done purely client-side against the full JSON of the domain search, an approach we've tested with domains of over a quarter million breached email addresses and still been workable (although arguably, you really want that data via the API rather than scrolling through it in a browser window).
Verification of domain ownership has also been completely rewritten and has a much cleaner, simpler interface:
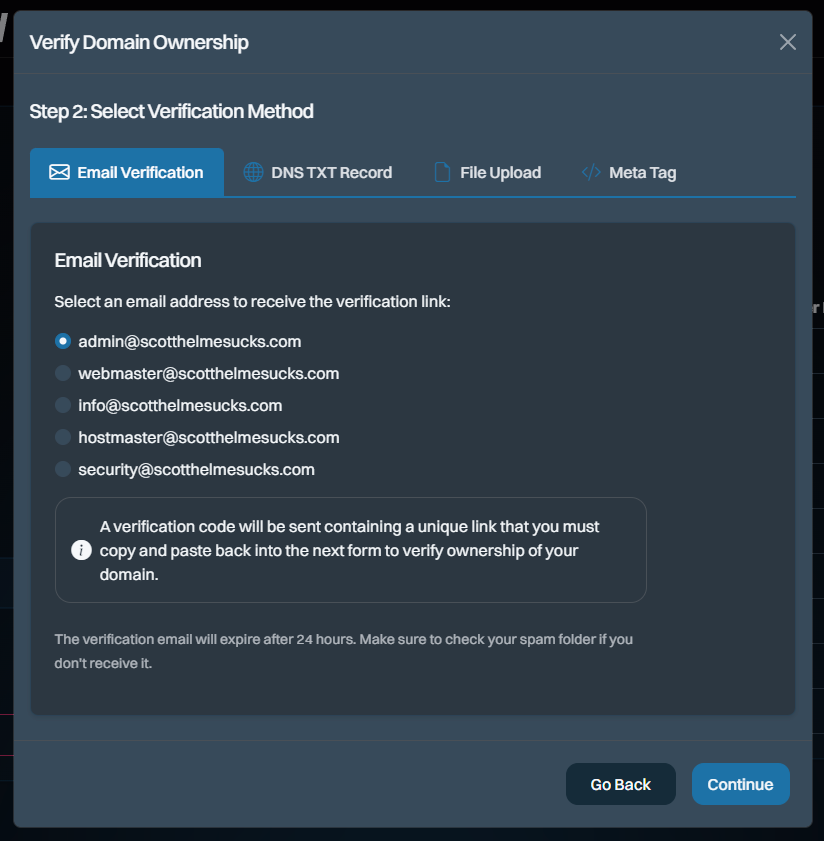
We still have work to do to make the non-email verification methods smoother, but that was the case before, too, so at least we haven't regressed. That'll happen shortly, promise!
First things first: there have been no changes to the API itself. This update doesn't break anything!
There's a discussion over on the UX rebuild GitHub repo about the right way to do API documentation. The general consensus is OpenAPI and we started going down that route using Scalar. In fact, you can even see the work Stefan did on this here at haveibeenpwned.com/scalar:

It's very cool, especially the way it documents samples in all sorts of different languages and even has a test runner, which is effectively Postman in the browser. Cool, but we just couldn't finish it in time. As such, we've kept the old documentation for now and just styled it so it looks like the rest of the site (which I reckon is still pretty slick), but we do intend to roll to the Scalar implementation when we're not under the duress of such a big launch.
You know what else is awesome? Merch! No, seriously, we've had so many requests over the years for HIBP branded merch and now, here we are:

We actually now have a real-life merch store at merch.haveibeenpwned.com! This was probably the worst possible use of our time, considering how much mechanical stuff we had to do to make all the new stuff work, but it was a bit of a passion project for Charlotte, so yeah, now you can actually buy HIBP merch. It's all done through Teespring (where have I heard that name before?!) and everything listed there is at cost price - we make absolutely zero dollars, it's just a fun initiative for the community 🙂
We did try out their option for stickers too, but they fell well short of what we already had up with our little one-item store on Sticker Mule so for now, that remains the go-to for laptop decorations. Or just go and grab the open source artwork and get your own printed from wherever you please.
We still run the origin services on Microsoft Azure using a combination of the App Service for the website, "serverless" Functions for most APIs (there are still a few async ones there that are called as a part of browser-based features), SQL Azure "Hyperscale" and storage account features like queues, blobs and tables. Pretty much all the coding there is C# with .NET 9.0 and ASP.NET MVC on .NET Core for the web app. Cloudflare still plays a massive role with a lot of code in workers, data in R2 storage and all their good bits around WAF and caching. We're also now exclusively using their Turnstile service for anti-automation and have ditched Google's reCAPTCHA completely - big yay!
The front end is now latest gen Bootstrap and we're using SASS for all our CSS and TypeScript for all our JavaScript. Our (other) man in Iceland Ingiber has just done an absolutely outstanding job with the interfaces and exceeded all our expectations by a massive margin. What we have now goes far beyond what we expected when we started this process, and a big part of that has been Ingiber's ability to take a simple requirement and turn it into a thing of beauty 😍 I'm very glad that Charlotte, Stefan and I got to spend time with him in Reykjavik last month and share some beers.
We also made some measurable improvements to website performance. For example, I ran a Pingdom website speed test just before taking the old one offline:

And then ran it over the new one:

So we cut out 28% of the page size and 31% of the requests. The load time is much of a muchness (and it's highly variable at that), but having solid measures for all the values in the column on the right is a very pleasing result. Consider also the commentary anyone in web dev would have seen over the years about how much bigger web pages have become, and here we are shaving off solid double-digit percentages 11 years later!
Finally, anything that could remotely be construed as tracking or ad bloat just isn't there, because we simply don't do any of that 🙂 In fact, the only real traffic stats we have are based on what Cloudflare sees when the traffic flows through their edge nodes. And that 1Password product placement is, as it's always been, just text and an image. We don't even track outbound clicks, that's up to them if they want to capture that on the landing page we link to. This actually makes discussions such as we're having with identity theft companies that want product placement much harder as they're used to getting the sorts of numbers that invasive tracking produces, but we wouldn't have it any other way.
I wanted to make a quick note of this here, as AI seems to be either constantly overblown or denigrated. Either it's going to solve the world's problems, or it just produces "slop". I used Chat GPT in particular really extensively during this rebuild, especially in the final days when time got tight and my brain got fried. Here are some examples where it made a big difference:
I'm using Bootstrap icons from here: https://icons.getbootstrap.com/
What's a good icon to illustrate a heading called "Index"?This was right at the 11th hour when we realised we didn't have time to implement Scalar properly, and I needed to quickly migrate all the existing API docs to the new template. There are over 2,000 icons on that page, and this approach meant it took about 30 seconds to find the right one, each and every time.
We killed off some pages on the old site, but before rolling it over, I wanted to know exactly what was there:
Write me a PowerShell script to crawl haveibeenpwned.com and write out each unique URL it findsAnd then:
Now write a script to take all the paths it found and see if they exist on stage.haveibeenpwned.com
It found good stuff too, like the security.txt file I'd forgotten to migrate. It also found stuff that never existed, so it's the usual "trust, but verify" situation.
And just a gazillion little things where every time I needed anything from some CSS advice to configuring Cloudflare rules to idiosyncrasies in the .NET Core web app, the correct answer was seconds away. I'd say it was right 90% of the time, too, and if you're not using AI aggressively in your software development work now (and I'm sure there are much better ways, too) I'm pretty confident in saying "you're doing it wrong".
It's hard to explain how much has gone into this, and that goes well beyond just what you see in front of you on the website today. It's seemingly little things, like minor revisions to the terms of use and privacy policy, which required many hours of time and thousands of dollars with lawyers (just minor updates to how we process data and a reflection of new services such as the stealer logs).
We pushed out the new site in the wee hours of Sunday morning my time, and almost everything went well:

One or two little glitches that we've fixed and pushed quickly, that's it. I've actually waited until now, 2 days after going live, to publish this post just so we could iron out as much stuff as possible first. We've pushed more than a dozen new releases already since that time, just to keep iterating and refining quickly. TBH, it's been a bit intense and has been an enormously time-consuming effort that's dominated our focus, especially over the last few weeks leading up to launch. And just to drive that point home, I literally got a health alert first thing Monday morning:
Nothing like empirical data to make a point! That last weekend when we went live was especially brutal; I don't think I've devoted that much high-intensity time to a software release for decades.
Have I Been Pwned has been a passion for a quarter of my life now. What I built in 2013 was never intended to take me this far or last this long, and I'm kinda shocked it did if I'm honest. I feel that what we've built with this new site and new brand has elevated this little pet project into a serious service that has a new level of professionalism. But I hope that in reading this, you see that it has maintained everything that has always been great about the service, and I'm so glad to still be here writing about it today in the 205th blog post with that tag. Thanks for reading, now go and enjoy the new website 😊
Edit (a few hours after initially posting): Let me expand on Cloudflare's Turnstile as it'll explain some idiosyncrasies some people have seen:
This is an anti-automation approach that doesn't involve palming traffic to Google (like reCAPTCHA did), and it can be implemented completely invisibly. There are more invasive implementations of it, but we're trying to be seamless here. It involves some Cloudflare script running in the browser and providing a challenge, which is then submitted with the HTTP request and verified server side. We've had it on HIBP in one form or another since 2023, and it can be awesome... until it isn't. If the challenge fails, what happens next? It depends.
On forms where we really need to block the robots (for example, any that send email), a failed Turnstile challenge was initially just showing a red error. It now says this:
Our anti-automation process thinks you're a bot, which you're obviously not! Try behaving like a human and clicking the button again and if it still misbehaves, give the page a reload.
We've often found a second click or a page reload solves the problem, so hopefully this sends people in the right direction. If it doesn't, we'll need to look at more in-your-face implementations of Turnstile that show a widget you need to interact with. To have a go yourself and see it in action, try the dashboard sign in page.
The other place Turnstile features heavily is on the main search page at the root of the site. We don't want that API being hit by bots, so it's a must have there. Here, like on the other pages of the new site, we're asynchronously posting to API endpoints and sending the challenge token along with the request. What we're doing differently on the front page, however, is that if the challenge fails and returns HTTP 401 when posted to the HIBP endpoint (you'll also see a response body of "Invalid Turnstile token"), we were meant to be falling back to a full page post. That wasn't happening in the new site when we first launched it. But it is now 🙂
When the full page post back occurs, Cloudflare will present a managed challenge. This is much more invasive, but it's also much more reliable and will then serve the same result as you would have seen anyway, albeit via a full page load. We implement the same managed challenge logic on the deep-linked account pages, which you can see here: https://haveibeenpwned.com/account/test@example.com
According to the Cloudflare stats, about 82% of all our issued challenges are successfully solved:
Of the 18% that aren't, many will be due to bots stopped by Turnstile doing exactly what it's meant to do. It's likely a single-digit percentage of requests that are real humans being impeded, and we need to look at ways to get that number down, but at least the fallback positions are improved now. If you were having problems, give the site a good refresh, see how you go and leave your feedback in the comments below.

For many years, people would come to Have I Been Pwned (HIBP), run a search on their email address, get the big red "Oh no - pwned!" response and then... I'm not sure. We really didn't have much guidance until we partnered with 1Password and started giving specific advice about how to secure your digital life. So, that's passwords sorted, but the impact of data breaches goes well beyond passwords alone...
There are many different ways people are impacted by breaches, for example, identity fraud. Breaches frequently contain precisely the sort of information that opens the door to impersonation and just taking a quick look at the HIBP stats now, there's a lot of data out there:
That's just the big numbers, then there's the long tail of all sorts of other exposed high-risk data, including partial credit cards (32 breaches), government-issued IDs (18 breaches) and passport numbers (7 breaches). As well as helping people choose good passwords, we want to help them stay safe in the other aspects of their lives put at risk when hackers run riot.
Identity protection services are a good example, and I might be showing my age here, but I've been using them since the 90's. Today, I use a local Aussie one called Truyu which is built by the Commonwealth Bank. Let me give you two examples from them to illustrate why it's a useful service:
The first one came on Melbourne Cup day last year, a day when Aussies traditionally get drunk and lose money betting on horse races. Because gambling (sorry - "gaming") is a heavily regulated industry, a whole bunch of identity data has to be provided if you want to set up an account with the likes of SportsBet. Whilst I personally maintain that gambling is a tax on people who can't do maths, Charlotte was convinced we should have a go anyway, which resulted in Truyu popping up this alert:

This was me (and yes, of course we lost everything we bet) but... what if it wasn't me, and my personal information had been used by someone else to open the account? That's the sort of thing I'd want to know about fast. As for all those "Illion Credit Header" entries, I asked Truyu to help explain what they mean and why they're important to know:
Yep, I'd definitely want to know if it wasn't me that initiated all that!
Then, on a recent visit to see the Irish National Cyber Security Centre, we found ourselves hungry in Dublin. Google Maps recommended this epic sushi place, but when we arrived, a sign at the front advised they didn't accept credit cards - in 2025!! Carrying only digital cards, having no cash and being hungry for sushi, I explored the only other avenue the store suggested: creating a Revolut account. Doing so required a bunch of personal information because, like betting, finance is a heavily regulated industry. This earned me another early warning from Truyu about the use of my data:

I pay Truyu A$4.99 each month via a subscription on my iPhone, and IMHO, it's money well spent. For full disclosure, Truyu is also an enterprise subscriber to HIBP (like 1Password is), and you can see breaches we've processed in their app too. I've included them here because they're a great example of a service that adds real value "after the breach", and it's one I genuinely use myself.
The point of all this is that there are organisations out there offering services that are particularly relevant to data breach victims, and we'd like to find the really good ones and put them on the new HIBP website. We've even built out some all-new dedicated spaces, for example on the new breach page:
But choosing partners is a bit more nuanced than that. For example, a service like Truyu caters to an Aussie audience, and the way identity protection works in the US or UK, for example, is different. We need different partners in different parts of the world, and further, offering different services. Identity protection is one thing, but what else? There are many different risks that both individuals and organisations (of which there are hundreds of thousands using HIBP today) face after being in a data breach.
So, we're looking for more partners that can make a positive difference for the folks that land on HIBP, do a search and then ask "now what?!" We're obviously going to be very selective and very cautious about who we work with because the trust people have in HIBP is not something I'll ever jeopardise by selecting the wrong partners. And, of course, any other brand that appears on this site needs to be one that reflects not just our values and mission, but is complementary to our favourite password manager as well.
Now that we're on the cusp of launching this new site (May 17 is our target), I'm inviting any organisations that think they fit the bill to get in touch with me and explain how they can make a positive difference to data breach victims looking for answers "after the breach".
Thank you for following me! https://cybdetective.com
| Name | Link | Description | Price |
|---|---|---|---|
| Shodan | https://developer.shodan.io | Search engine for Internet connected host and devices | from $59/month |
| Netlas.io | https://netlas-api.readthedocs.io/en/latest/ | Search engine for Internet connected host and devices. Read more at Netlas CookBook | Partly FREE |
| Fofa.so | https://fofa.so/static_pages/api_help | Search engine for Internet connected host and devices | ??? |
| Censys.io | https://censys.io/api | Search engine for Internet connected host and devices | Partly FREE |
| Hunter.how | https://hunter.how/search-api | Search engine for Internet connected host and devices | Partly FREE |
| Fullhunt.io | https://api-docs.fullhunt.io/#introduction | Search engine for Internet connected host and devices | Partly FREE |
| IPQuery.io | https://ipquery.io | API for ip information such as ip risk, geolocation data, and asn details | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Social Links | https://sociallinks.io/products/sl-api | Email info lookup, phone info lookup, individual and company profiling, social media tracking, dark web monitoring and more. Code example of using this API for face search in this repo | PAID. Price per request |
| Name | Link | Description | Price |
|---|---|---|---|
| Numverify | https://numverify.com | Global Phone Number Validation & Lookup JSON API. Supports 232 countries. | 250 requests FREE |
| Twillo | https://www.twilio.com/docs/lookup/api | Provides a way to retrieve additional information about a phone number | Free or $0.01 per request (for caller lookup) |
| Plivo | https://www.plivo.com/lookup/ | Determine carrier, number type, format, and country for any phone number worldwide | from $0.04 per request |
| GetContact | https://github.com/kovinevmv/getcontact | Find info about user by phone number | from $6,89 in months/100 requests |
| Veriphone | https://veriphone.io/ | Phone number validation & carrier lookup | 1000 requests/month FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Global Address | https://rapidapi.com/adminMelissa/api/global-address/ | Easily verify, check or lookup address | FREE |
| US Street Address | https://smartystreets.com/docs/cloud/us-street-api | Validate and append data for any US postal address | FREE |
| Google Maps Geocoding API | https://developers.google.com/maps/documentation/geocoding/overview | convert addresses (like "1600 Amphitheatre Parkway, Mountain View, CA") into geographic coordinates | 0.005 USD per request |
| Postcoder | https://postcoder.com/address-lookup | Find adress by postcode | £130/5000 requests |
| Zipcodebase | https://zipcodebase.com | Lookup postal codes, calculate distances and much more | 5000 requests FREE |
| Openweathermap geocoding API | https://openweathermap.org/api/geocoding-api | get geographical coordinates (lat, lon) by using name of the location (city name or area name) | 60 calls/minute 1,000,000 calls/month |
| DistanceMatrix | https://distancematrix.ai/product | Calculate, evaluate and plan your routes | $1.25-$2 per 1000 elements |
| Geotagging API | https://geotagging.ai/ | Predict geolocations by texts | Freemium |
| Name | Link | Description | Price |
|---|---|---|---|
| Approuve.com | https://appruve.co | Allows you to verify the identities of individuals, businesses, and connect to financial account data across Africa | Paid |
| Onfido.com | https://onfido.com | Onfido Document Verification lets your users scan a photo ID from any device, before checking it's genuine. Combined with Biometric Verification, it's a seamless way to anchor an account to the real identity of a customer. India | Paid |
| Superpass.io | https://surepass.io/passport-id-verification-api/ | Passport, Photo ID and Driver License Verification in India | Paid |
| Name | Link | Description | Price |
|---|---|---|---|
| Open corporates | https://api.opencorporates.com | Companies information | Paid, price upon request |
| Linkedin company search API | https://docs.microsoft.com/en-us/linkedin/marketing/integrations/community-management/organizations/company-search?context=linkedin%2Fcompliance%2Fcontext&tabs=http | Find companies using keywords, industry, location, and other criteria | FREE |
| Mattermark | https://rapidapi.com/raygorodskij/api/Mattermark/ | Get companies and investor information | free 14-day trial, from $49 per month |
| Name | Link | Description | Price |
|---|---|---|---|
| API OSINT DS | https://github.com/davidonzo/apiosintDS | Collect info about IPv4/FQDN/URLs and file hashes in md5, sha1 or sha256 | FREE |
| InfoDB API | https://www.ipinfodb.com/api | The API returns the location of an IP address (country, region, city, zipcode, latitude, longitude) and the associated timezone in XML, JSON or plain text format | FREE |
| Domainsdb.info | https://domainsdb.info | Registered Domain Names Search | FREE |
| BGPView | https://bgpview.docs.apiary.io/# | allowing consumers to view all sort of analytics data about the current state and structure of the internet | FREE |
| DNSCheck | https://www.dnscheck.co/api | monitor the status of both individual DNS records and groups of related DNS records | up to 10 DNS records/FREE |
| Cloudflare Trace | https://github.com/fawazahmed0/cloudflare-trace-api | Get IP Address, Timestamp, User Agent, Country Code, IATA, HTTP Version, TLS/SSL Version & More | FREE |
| Host.io | https://host.io/ | Get info about domain | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| BeVigil OSINT API | https://bevigil.com/osint-api | provides access to millions of asset footprint data points including domain intel, cloud services, API information, and third party assets extracted from millions of mobile apps being continuously uploaded and scanned by users on bevigil.com | 50 credits free/1000 credits/$50 |
| Name | Link | Description | Price |
|---|---|---|---|
| WebScraping.AI | https://webscraping.ai/ | Web Scraping API with built-in proxies and JS rendering | FREE |
| ZenRows | https://www.zenrows.com/ | Web Scraping API that bypasses anti-bot solutions while offering JS rendering, and rotating proxies apiKey Yes Unknown | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Whois freaks | https://whoisfreaks.com/ | well-parsed and structured domain WHOIS data for all domain names, registrars, countries and TLDs since the birth of internet | $19/5000 requests |
| WhoisXMLApi | https://whois.whoisxmlapi.com | gathers a variety of domain ownership and registration data points from a comprehensive WHOIS database | 500 requests in month/FREE |
| IPtoWhois | https://www.ip2whois.com/developers-api | Get detailed info about a domain | 500 requests/month FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Ipstack | https://ipstack.com | Detect country, region, city and zip code | FREE |
| Ipgeolocation.io | https://ipgeolocation.io | provides country, city, state, province, local currency, latitude and longitude, company detail, ISP lookup, language, zip code, country calling code, time zone, current time, sunset and sunrise time, moonset and moonrise | 30 000 requests per month/FREE |
| IPInfoDB | https://ipinfodb.com/api | Free Geolocation tools and APIs for country, region, city and time zone lookup by IP address | FREE |
| IP API | https://ip-api.com/ | Free domain/IP geolocation info | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Mylnikov API | https://www.mylnikov.org | public API implementation of Wi-Fi Geo-Location database | FREE |
| Wigle | https://api.wigle.net/ | get location and other information by SSID | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| PeetingDB | https://www.peeringdb.com/apidocs/ | Database of networks, and the go-to location for interconnection data | FREE |
| PacketTotal | https://packettotal.com/api.html | .pcap files analyze | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Binlist.net | https://binlist.net/ | get information about bank by BIN | FREE |
| FDIC Bank Data API | https://banks.data.fdic.gov/docs/ | institutions, locations and history events | FREE |
| Amdoren | https://www.amdoren.com/currency-api/ | Free currency API with over 150 currencies | FREE |
| VATComply.com | https://www.vatcomply.com/documentation | Exchange rates, geolocation and VAT number validation | FREE |
| Alpaca | https://alpaca.markets/docs/api-documentation/api-v2/market-data/alpaca-data-api-v2/ | Realtime and historical market data on all US equities and ETFs | FREE |
| Swiftcodesapi | https://swiftcodesapi.com | Verifying the validity of a bank SWIFT code or IBAN account number | $39 per month/4000 swift lookups |
| IBANAPI | https://ibanapi.com | Validate IBAN number and get bank account information from it | Freemium/10$ Starter plan |
| Name | Link | Description | Price |
|---|---|---|---|
| EVA | https://eva.pingutil.com/ | Measuring email deliverability & quality | FREE |
| Mailboxlayer | https://mailboxlayer.com/ | Simple REST API measuring email deliverability & quality | 100 requests FREE, 5000 requests in month — $14.49 |
| EmailCrawlr | https://emailcrawlr.com/ | Get key information about company websites. Find all email addresses associated with a domain. Get social accounts associated with an email. Verify email address deliverability. | 200 requests FREE, 5000 requets — $40 |
| Voila Norbert | https://www.voilanorbert.com/api/ | Find anyone's email address and ensure your emails reach real people | from $49 in month |
| Kickbox | https://open.kickbox.com/ | Email verification API | FREE |
| FachaAPI | https://api.facha.dev/ | Allows checking if an email domain is a temporary email domain | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Genderize.io | https://genderize.io | Instantly answers the question of how likely a certain name is to be male or female and shows the popularity of the name. | 1000 names/day free |
| Agify.io | https://agify.io | Predicts the age of a person given their name | 1000 names/day free |
| Nataonalize.io | https://nationalize.io | Predicts the nationality of a person given their name | 1000 names/day free |
| Name | Link | Description | Price |
|---|---|---|---|
| HaveIBeenPwned | https://haveibeenpwned.com/API/v3 | allows the list of pwned accounts (email addresses and usernames) | $3.50 per month |
| Psdmp.ws | https://psbdmp.ws/api | search in Pastebin | $9.95 per 10000 requests |
| LeakPeek | https://psbdmp.ws/api | searc in leaks databases | $9.99 per 4 weeks unlimited access |
| BreachDirectory.com | https://breachdirectory.com/api_documentation | search domain in data breaches databases | FREE |
| LeekLookup | https://leak-lookup.com/api | search domain, email_address, fullname, ip address, phone, password, username in leaks databases | 10 requests FREE |
| BreachDirectory.org | https://rapidapi.com/rohan-patra/api/breachdirectory/pricing | search domain, email_address, fullname, ip address, phone, password, username in leaks databases (possible to view password hashes) | 50 requests in month/FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Wayback Machine API (Memento API, CDX Server API, Wayback Availability JSON API) | https://archive.org/help/wayback_api.php | Retrieve information about Wayback capture data | FREE |
| TROVE (Australian Web Archive) API | https://trove.nla.gov.au/about/create-something/using-api | Retrieve information about TROVE capture data | FREE |
| Archive-it API | https://support.archive-it.org/hc/en-us/articles/115001790023-Access-Archive-It-s-Wayback-index-with-the-CDX-C-API | Retrieve information about archive-it capture data | FREE |
| UK Web Archive API | https://ukwa-manage.readthedocs.io/en/latest/#api-reference | Retrieve information about UK Web Archive capture data | FREE |
| Arquivo.pt API | https://github.com/arquivo/pwa-technologies/wiki/Arquivo.pt-API | Allows full-text search and access preserved web content and related metadata. It is also possible to search by URL, accessing all versions of preserved web content. API returns a JSON object. | FREE |
| Library Of Congress archive API | https://www.loc.gov/apis/ | Provides structured data about Library of Congress collections | FREE |
| BotsArchive | https://botsarchive.com/docs.html | JSON formatted details about Telegram Bots available in database | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| MD5 Decrypt | https://md5decrypt.net/en/Api/ | Search for decrypted hashes in the database | 1.99 EURO/day |
| Name | Link | Description | Price |
|---|---|---|---|
| BTC.com | https://btc.com/btc/adapter?type=api-doc | get information about addresses and transanctions | FREE |
| Blockchair | https://blockchair.com | Explore data stored on 17 blockchains (BTC, ETH, Cardano, Ripple etc) | $0.33 - $1 per 1000 calls |
| Bitcointabyse | https://www.bitcoinabuse.com/api-docs | Lookup bitcoin addresses that have been linked to criminal activity | FREE |
| Bitcoinwhoswho | https://www.bitcoinwhoswho.com/api | Scam reports on the Bitcoin Address | FREE |
| Etherscan | https://etherscan.io/apis | Ethereum explorer API | FREE |
| apilayer coinlayer | https://coinlayer.com | Real-time Crypto Currency Exchange Rates | FREE |
| BlockFacts | https://blockfacts.io/ | Real-time crypto data from multiple exchanges via a single unified API, and much more | FREE |
| Brave NewCoin | https://bravenewcoin.com/developers | Real-time and historic crypto data from more than 200+ exchanges | FREE |
| WorldCoinIndex | https://www.worldcoinindex.com/apiservice | Cryptocurrencies Prices | FREE |
| WalletLabels | https://www.walletlabels.xyz/docs | Labels for 7,5 million Ethereum wallets | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| VirusTotal | https://developers.virustotal.com/reference | files and urls analyze | Public API is FREE |
| AbuseLPDB | https://docs.abuseipdb.com/#introduction | IP/domain/URL reputation | FREE |
| AlienVault Open Threat Exchange (OTX) | https://otx.alienvault.com/api | IP/domain/URL reputation | FREE |
| Phisherman | https://phisherman.gg | IP/domain/URL reputation | FREE |
| URLScan.io | https://urlscan.io/about-api/ | Scan and Analyse URLs | FREE |
| Web of Thrust | https://support.mywot.com/hc/en-us/sections/360004477734-API- | IP/domain/URL reputation | FREE |
| Threat Jammer | https://threatjammer.com/docs/introduction-threat-jammer-user-api | IP/domain/URL reputation | ??? |
| Name | Link | Description | Price |
|---|---|---|---|
| Search4faces | https://search4faces.com/api.html | Detect and locate human faces within an image, and returns high-precision face bounding boxes. Face⁺⁺ also allows you to store metadata of each detected face for future use. | $21 per 1000 requests |
## Face Detection
| Name | Link | Description | Price |
|---|---|---|---|
| Face++ | https://www.faceplusplus.com/face-detection/ | Search for people in social networks by facial image | from 0.03 per call |
| BetaFace | https://www.betafaceapi.com/wpa/ | Can scan uploaded image files or image URLs, find faces and analyze them. API also provides verification (faces comparison) and identification (faces search) services, as well able to maintain multiple user-defined recognition databases (namespaces) | 50 image per day FREE/from 0.15 EUR per request |
## Reverse Image Search
| Name | Link | Description | Price |
|---|---|---|---|
| Google Reverse images search API | https://github.com/SOME-1HING/google-reverse-image-api/ | This is a simple API built using Node.js and Express.js that allows you to perform Google Reverse Image Search by providing an image URL. | FREE (UNOFFICIAL) |
| TinEyeAPI | https://services.tineye.com/TinEyeAPI | Verify images, Moderate user-generated content, Track images and brands, Check copyright compliance, Deploy fraud detection solutions, Identify stock photos, Confirm the uniqueness of an image | Start from $200/5000 searches |
| Bing Images Search API | https://www.microsoft.com/en-us/bing/apis/bing-image-search-api | With Bing Image Search API v7, help users scour the web for images. Results include thumbnails, full image URLs, publishing website info, image metadata, and more. | 1,000 requests free per month FREE |
| MRISA | https://github.com/vivithemage/mrisa | MRISA (Meta Reverse Image Search API) is a RESTful API which takes an image URL, does a reverse Google image search, and returns a JSON array with the search results | FREE? (no official) |
| PicImageSearch | https://github.com/kitUIN/PicImageSearch | Aggregator for different Reverse Image Search API | FREE? (no official) |
## AI Geolocation
| Name | Link | Description | Price |
|---|---|---|---|
| Geospy | https://api.geospy.ai/ | Detecting estimation location of uploaded photo | Access by request |
| Picarta | https://picarta.ai/api | Detecting estimation location of uploaded photo | 100 request/day FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Twitch | https://dev.twitch.tv/docs/v5/reference | ||
| YouTube Data API | https://developers.google.com/youtube/v3 | ||
| https://www.reddit.com/dev/api/ | |||
| Vkontakte | https://vk.com/dev/methods | ||
| Twitter API | https://developer.twitter.com/en | ||
| Linkedin API | https://docs.microsoft.com/en-us/linkedin/ | ||
| All Facebook and Instagram API | https://developers.facebook.com/docs/ | ||
| Whatsapp Business API | https://www.whatsapp.com/business/api | ||
| Telegram and Telegram Bot API | https://core.telegram.org | ||
| Weibo API | https://open.weibo.com/wiki/API文档/en | ||
| https://dev.xing.com/partners/job_integration/api_docs | |||
| Viber | https://developers.viber.com/docs/api/rest-bot-api/ | ||
| Discord | https://discord.com/developers/docs | ||
| Odnoklassniki | https://ok.ru/apiok | ||
| Blogger | https://developers.google.com/blogger/ | The Blogger APIs allows client applications to view and update Blogger content | FREE |
| Disqus | https://disqus.com/api/docs/auth/ | Communicate with Disqus data | FREE |
| Foursquare | https://developer.foursquare.com/ | Interact with Foursquare users and places (geolocation-based checkins, photos, tips, events, etc) | FREE |
| HackerNews | https://github.com/HackerNews/API | Social news for CS and entrepreneurship | FREE |
| Kakao | https://developers.kakao.com/ | Kakao Login, Share on KakaoTalk, Social Plugins and more | FREE |
| Line | https://developers.line.biz/ | Line Login, Share on Line, Social Plugins and more | FREE |
| TikTok | https://developers.tiktok.com/doc/login-kit-web | Fetches user info and user's video posts on TikTok platform | FREE |
| Tumblr | https://www.tumblr.com/docs/en/api/v2 | Read and write Tumblr Data | FREE |
!WARNING Use with caution! Accounts may be blocked permanently for using unofficial APIs.
| Name | Link | Description | Price |
|---|---|---|---|
| TikTok | https://github.com/davidteather/TikTok-Api | The Unofficial TikTok API Wrapper In Python | FREE |
| Google Trends | https://github.com/suryasev/unofficial-google-trends-api | Unofficial Google Trends API | FREE |
| YouTube Music | https://github.com/sigma67/ytmusicapi | Unofficial APi for YouTube Music | FREE |
| Duolingo | https://github.com/KartikTalwar/Duolingo | Duolingo unofficial API (can gather info about users) | FREE |
| Steam. | https://github.com/smiley/steamapi | An unofficial object-oriented Python library for accessing the Steam Web API. | FREE |
| https://github.com/ping/instagram_private_api | Instagram Private API | FREE | |
| Discord | https://github.com/discordjs/discord.js | JavaScript library for interacting with the Discord API | FREE |
| Zhihu | https://github.com/syaning/zhihu-api | FREE Unofficial API for Zhihu | FREE |
| Quora | https://github.com/csu/quora-api | Unofficial API for Quora | FREE |
| DnsDumbster | https://github.com/PaulSec/API-dnsdumpster.com | (Unofficial) Python API for DnsDumbster | FREE |
| PornHub | https://github.com/sskender/pornhub-api | Unofficial API for PornHub in Python | FREE |
| Skype | https://github.com/ShyykoSerhiy/skyweb | Unofficial Skype API for nodejs via 'Skype (HTTP)' protocol. | FREE |
| Google Search | https://github.com/aviaryan/python-gsearch | Google Search unofficial API for Python with no external dependencies | FREE |
| Airbnb | https://github.com/nderkach/airbnb-python | Python wrapper around the Airbnb API (unofficial) | FREE |
| Medium | https://github.com/enginebai/PyMedium | Unofficial Medium Python Flask API and SDK | FREE |
| https://github.com/davidyen1124/Facebot | Powerful unofficial Facebook API | FREE | |
| https://github.com/tomquirk/linkedin-api | Unofficial Linkedin API for Python | FREE | |
| Y2mate | https://github.com/Simatwa/y2mate-api | Unofficial Y2mate API for Python | FREE |
| Livescore | https://github.com/Simatwa/livescore-api | Unofficial Livescore API for Python | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Google Custom Search JSON API | https://developers.google.com/custom-search/v1/overview | Search in Google | 100 requests FREE |
| Serpstack | https://serpstack.com/ | Google search results to JSON | FREE |
| Serpapi | https://serpapi.com | Google, Baidu, Yandex, Yahoo, DuckDuckGo, Bint and many others search results | $50/5000 searches/month |
| Bing Web Search API | https://www.microsoft.com/en-us/bing/apis/bing-web-search-api | Search in Bing (+instant answers and location) | 1000 transactions per month FREE |
| WolframAlpha API | https://products.wolframalpha.com/api/pricing/ | Short answers, conversations, calculators and many more | from $25 per 1000 queries |
| DuckDuckgo Instant Answers API | https://duckduckgo.com/api | An API for some of our Instant Answers, not for full search results. | FREE |
| Memex Marginalia | https://memex.marginalia.nu/projects/edge/api.gmi | An API for new privacy search engine | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| MediaStack | https://mediastack.com/ | News articles search results in JSON | 500 requests/month FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Darksearch.io | https://darksearch.io/apidoc | search by websites in .onion zone | FREE |
| Onion Lookup | https://onion.ail-project.org/ | onion-lookup is a service for checking the existence of Tor hidden services and retrieving their associated metadata. onion-lookup relies on an private AIL instance to obtain the metadata | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Jackett | https://github.com/Jackett/Jackett | API for automate searching in different torrent trackers | FREE |
| Torrents API PY | https://github.com/Jackett/Jackett | Unofficial API for 1337x, Piratebay, Nyaasi, Torlock, Torrent Galaxy, Zooqle, Kickass, Bitsearch, MagnetDL,Libgen, YTS, Limetorrent, TorrentFunk, Glodls, Torre | FREE |
| Torrent Search API | https://github.com/Jackett/Jackett | API for Torrent Search Engine with Extratorrents, Piratebay, and ISOhunt | 500 queries/day FREE |
| Torrent search api | https://github.com/JimmyLaurent/torrent-search-api | Yet another node torrent scraper (supports iptorrents, torrentleech, torrent9, torrentz2, 1337x, thepiratebay, Yggtorrent, TorrentProject, Eztv, Yts, LimeTorrents) | FREE |
| Torrentinim | https://github.com/sergiotapia/torrentinim | Very low memory-footprint, self hosted API-only torrent search engine. Sonarr + Radarr Compatible, native support for Linux, Mac and Windows. | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| National Vulnerability Database CVE Search API | https://nvd.nist.gov/developers/vulnerabilities | Get basic information about CVE and CVE history | FREE |
| OpenCVE API | https://docs.opencve.io/api/cve/ | Get basic information about CVE | FREE |
| CVEDetails API | https://www.cvedetails.com/documentation/apis | Get basic information about CVE | partly FREE (?) |
| CVESearch API | https://docs.cvesearch.com/ | Get basic information about CVE | by request |
| KEVin API | https://kevin.gtfkd.com/ | API for accessing CISA's Known Exploited Vulnerabilities Catalog (KEV) and CVE Data | FREE |
| Vulners.com API | https://vulners.com | Get basic information about CVE | FREE for personal use |
| Name | Link | Description | Price |
|---|---|---|---|
| Aviation Stack | https://aviationstack.com | get information about flights, aircrafts and airlines | FREE |
| OpenSky Network | https://opensky-network.org/apidoc/index.html | Free real-time ADS-B aviation data | FREE |
| AviationAPI | https://docs.aviationapi.com/ | FAA Aeronautical Charts and Publications, Airport Information, and Airport Weather | FREE |
| FachaAPI | https://api.facha.dev | Aircraft details and live positioning API | FREE |
| Name | Link | Description | Price |
|---|---|---|---|
| Windy Webcams API | https://api.windy.com/webcams/docs | Get a list of available webcams for a country, city or geographical coordinates | FREE with limits or 9990 euro without limits |
## Regex
| Name | Link | Description | Price |
|---|---|---|---|
| Autoregex | https://autoregex.notion.site/AutoRegex-API-Documentation-97256bad2c114a6db0c5822860214d3a | Convert English phrase to regular expression | from $3.49/month |
| Name | Link |
|---|---|
| API Guessr (detect API by auth key or by token) | https://api-guesser.netlify.app/ |
| REQBIN Online REST & SOAP API Testing Tool | https://reqbin.com |
| ExtendClass Online REST Client | https://extendsclass.com/rest-client-online.html |
| Codebeatify.org Online API Test | https://codebeautify.org/api-test |
| SyncWith Google Sheet add-on. Link more than 1000 APIs with Spreadsheet | https://workspace.google.com/u/0/marketplace/app/syncwith_crypto_binance_coingecko_airbox/449644239211?hl=ru&pann=sheets_addon_widget |
| Talend API Tester Google Chrome Extension | https://workspace.google.com/u/0/marketplace/app/syncwith_crypto_binance_coingecko_airbox/449644239211?hl=ru&pann=sheets_addon_widget |
| Michael Bazzel APIs search tools | https://inteltechniques.com/tools/API.html |
| Name | Link |
|---|---|
| Convert curl commands to Python, JavaScript, PHP, R, Go, C#, Ruby, Rust, Elixir, Java, MATLAB, Dart, CFML, Ansible URI or JSON | https://curlconverter.com |
| Curl-to-PHP. Instantly convert curl commands to PHP code | https://incarnate.github.io/curl-to-php/ |
| Curl to PHP online (Codebeatify) | https://codebeautify.org/curl-to-php-online |
| Curl to JavaScript fetch | https://kigiri.github.io/fetch/ |
| Curl to JavaScript fetch (Scrapingbee) | https://www.scrapingbee.com/curl-converter/javascript-fetch/ |
| Curl to C# converter | https://curl.olsh.me |
| Name | Link |
|---|---|
| Sheety. Create API frome GOOGLE SHEET | https://sheety.co/ |
| Postman. Platform for creating your own API | https://www.postman.com |
| Reetoo. Rest API Generator | https://retool.com/api-generator/ |
| Beeceptor. Rest API mocking and intercepting in seconds (no coding). | https://beeceptor.com |
| Name | Link |
|---|---|
| RapidAPI. Market your API for millions of developers | https://rapidapi.com/solution/api-provider/ |
| Apilayer. API Marketplace | https://apilayer.com |
| Name | Link | Description |
|---|---|---|
| Keyhacks | https://github.com/streaak/keyhacks | Keyhacks is a repository which shows quick ways in which API keys leaked by a bug bounty program can be checked to see if they're valid. |
| All about APIKey | https://github.com/daffainfo/all-about-apikey | Detailed information about API key / OAuth token for different services (Description, Request, Response, Regex, Example) |
| API Guessr | https://api-guesser.netlify.app/ | Enter API Key and and find out which service they belong to |
| Name | Link | Description |
|---|---|---|
| APIDOG ApiHub | https://apidog.com/apihub/ | |
| Rapid APIs collection | https://rapidapi.com/collections | |
| API Ninjas | https://api-ninjas.com/api | |
| APIs Guru | https://apis.guru/ | |
| APIs List | https://apislist.com/ | |
| API Context Directory | https://apicontext.com/api-directory/ | |
| Any API | https://any-api.com/ | |
| Public APIs Github repo | https://github.com/public-apis/public-apis |
If you don't know how to work with the REST API, I recommend you check out the Netlas API guide I wrote for Netlas.io.
There it is very brief and accessible to write how to automate requests in different programming languages (focus on Python and Bash) and process the resulting JSON data.
Thank you for following me! https://cybdetective.com
I love a good road trip. Always have, but particularly during COVID when international options were somewhat limited, one road trip ended up, well, "extensive". I also love the recent trips Charlotte and I have taken to spend time with many of the great agencies we've worked with over the years, including the FBI, CISA, CCCS, RCMP, NCA, NCSC UK and NCSC Ireland. So, that's what we're going to do next month across some very cool locations in Europe:
Whilst the route isn't set in stone, we'll start out in Germany and cover Liechtenstein, Switzerland, France, Italy and Austria. We have existing relationships with folks in all but one of those locations (France, call me!) and hope to do some public events as we recently have at Oxford University, Reykjavik and even Perth back on (almost) this side of the world. And that's the reason for writing this post today: if you're in proximity of this route and would like to organise an event or if you're a partner I haven't already reached out to, please get in touch. We usually manage to line up a healthy collection of events and assuming we can do that again on this trip, I'll publish them to the events page shortly. There's also a little bit of availability in Dubai on the way over we'll put to productive use, so definitely reach out if you're over that way.
If you're in another part of the world that needs a visit with a handful of HIBP swag, let me know, there's a bunch of other locations on the short list, and we're always thinking about what's coming next 🌍

Today, we're happy to welcome the Gambia National CSIRT to Have I Been Pwned as the 38th government to be onboarded with full and free access to their government domains. We've been offering this service for seven years now, and it enables national CSIRTs to gain greater visibility into the impact of data breaches on their respective nations.
Our goal at HIBP remains very straightforward: to do good things with data breaches after bad things happen. We hope this initiative helps support the Gambia National CSIRT as it has with many other governments around the world.
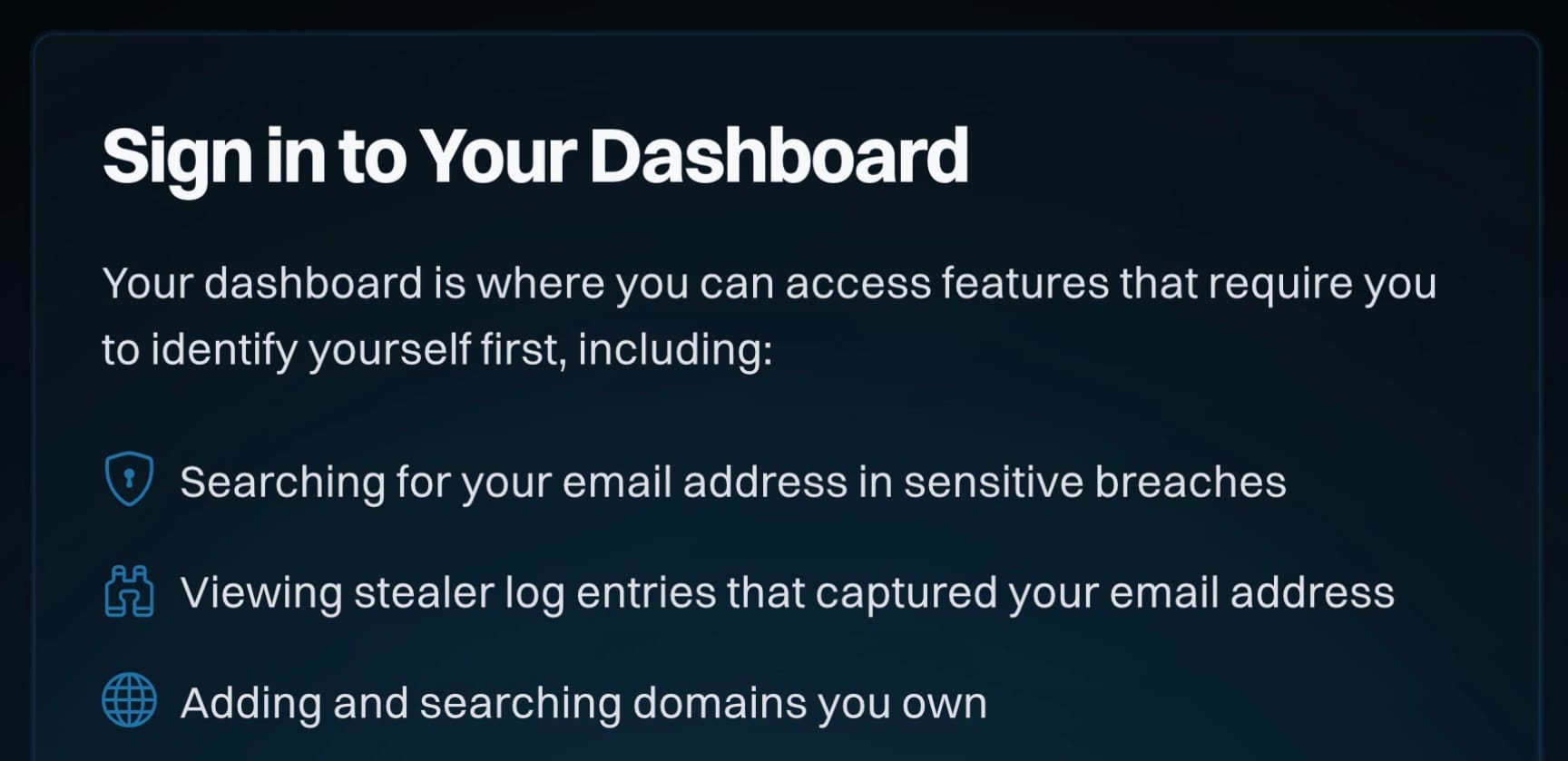
How do seemingly little things manage to consume so much time?! We had a suggestion this week that instead of being able to login to the new HIBP website, you should instead be able to log in. This initially confused me because I've been used to logging on to things for decades:
So, I went and signed in (yep, different again) to X and asked the masses what the correct term was:
When accessing your @haveibeenpwned dashboard, which of the following should you do? Preview screen for reference: https://t.co/9gqfr8hZrY
— Troy Hunt (@troyhunt) April 23, 2025
Which didn't result in a conclusive victor, so, I started browsing around.
Cloudflare's Zero Trust docs contain information about customising the login page, which I assume you can do once you log in:
Another, uh, "popular" site prompts you to log in:
After which you're invited to sign in:
You can log in to Canva, which is clearly indicated by the HTML title, which suggests you're on the login page:
You can log on to the Commonwealth Bank down here in Australia:

But the login page for ANZ bank requires to log in, unless you've forgotten your login details:
Ah, but many of these are just the difference between the noun "login" (the page is a thing) and the verb "log in" (when you perform an action), right? Well... depends who you bank with 🤷♂️
And maybe you don't log in or login at all:
Finally, from the darkness of seemingly interchangeable terms that may or may not violate principles of English language, emerged a pattern. You also sign in to Google:
And Microsoft:

And Amazon:
And Yahoo:

And, as I mentioned earlier, X:
And now, Have I Been Pwned:
There are some notable exceptions (Facebook and ChatGPT, for example), but "sign in" did emerge as the frontrunner among the world's most popular sites. If I really start to overthink it, I do feel that "log[whatever]" implies something different to why we authenticate to systems today and is more a remnant of a bygone era. But frankly, that argument is probably no more valid than whether you're doing a verb thing or a noun thing.

Designing the first logo for Have I Been Pwned was easy: I took a SQL injection pattern, wrote "have i been pwned?" after it and then, just to give it a touch of class, put a rectangle with rounded corners around it:

Job done! I mean really, what more did I need for a pet project with a stupid name that would likely only add to the litany of failed nerdy ideas I'd had before that? And then, to compress 11 and a bit years into a single sentence: it immediately became unexpectedly popular, I added an API and a notification service, I said "pwned" before US Congress, I added Pwned Passwords, went through a failed M&A, hired a developer and basically, devoted my life to running this service. There's been some "water under the bridge", so to speak.
The rebrand we're soft-launching today has been a long time coming, and true to that form, we're not rushing it. This is a "soft launch" in that we're sharing work in progress that's sufficiently evolved to put it out there to the public, but you won't see it in production anywhere yet. The website is no different, the social channels still have the same hero shots and avatars etc. This is the time to seek feedback and tweak before committing more effort into writing code and pushing this to the masses.
A quick primer on "why", as the question has come up a few times whilst previously discussing this. Assume for a moment that my valiant 2013 attempt at a logo was, itself, aesthetically sufficient. It's a hard one to use in different use cases (favicon, merch) and it's quite "busy" in it's current form with no easily recognisable symbol which makes it hard to apply to many use cases. And there are loads of use cases; I mentioned a couple just now, but how about in formal documents such a the contracts we write for enterprise customers? Or as it appears on Stripe-generated invoices, stickers, my 3D printed logos, email signatures and so on and so forth. And branding isn't just a logo, it's a whole set of different use cases and variants of the logo and colours such that you have flexibility to present the brand's image in a cohesive, recognisable fashion. Branding is an art form.
At one point there, I'd had a go at redoing the logo myself. It was terrible. You know how you can have this vision of something aesthetic in your mind and know instantly if it's the right thing when you see it, but just can't quite articulate it yourself? I'm like that with interior design... and logos. So, I reached out to Fiverr for help, and immediately regretted it:

I mean... wow. Ok, I get free revisions, let's give the designer another chance:

Dammit! This just wasn't going to work, and we were going to need to make a much more serious commitment if we wanted this done right. So, we went to Luft Design in Norway as Charlotte and Mikael went way back, and with his help, we went around and around through various iterations of mood boards, design styles, colours and carved out time in Oslo during our visit there in December to sit with Stefan as well and really nut this thing out. I was adamant that I wanted something immediately recognisable but also modern and cohesive without being fussy. Basically, give me everything, which Mikael did:

Let me talk you through the logic of these three variations, beginning with the icon. Mikael initially gave us multiple possible variations of a totally different icons which implied different things. My issue with that is you have to know what the symbology means in order for it to make sense. Perhaps if you're starting from scratch that can work, but when you're a decade+ into a name and a brand, there's history that I think you need to carry forward. One of the variations Mikael did reused that original SQL injection pattern I applied to the logo back in 2013 and just for the sake of justifying my choice, here's what it means for the uninitiated:
Take a SQL query like this:
SELECT * From User WHERE Name = 'blah'Now, imagine "blah" is untrusted user input, that being data that someone submits via a form, for example. They might then change "blah" to the following:
blah';DROP TABLE USERWe'll shortcut the whole SQL injection lesson about validation of untrusted data and parameterization of queries and just jump straight to the resultant query:
SELECT * From User WHERE Name = 'blah';DROP TABLE USER'And now, due to the additional query appended to the original one, your user table is gone. However... the SQL has a syntax error as there's a rogue apostrophe hanging off the end, so we fix it by using commenting syntax like so:
blah';DROP TABLE USER;--Chief among the characters in that pattern are these guys:
';--And that's the history; these are characters that play a role in the form of attack that has led to so many of the breaches in HIBP today. Turns out they're also really easy to stylise and represent as a concise logo:

We agonised over variations of this for months. The problem is that when you think about all the ones that are really recognisable without accompanying words, they're recognisable because the brand is massive. The Nike swoosh, the Mitsubishi diamonds, the Pepsi circle, the Apple logo etc. HIBP obviously doesn't have that level of cachet, but I really like the simplicity of reach of those, and that's what we have with this one as well as that connection to the history of the brand and the practical use of those characters.
But just as with many of those other recognisable logos, these are times when what is effectively just a logo alone isn't enough, so we have the longer form version:

"Have I Been Pwned" is a mouthful. It's not just long to say, it's long to put on the screen, long to print as a sticker, long to put on a shirt and so on and so forth. "Pwned", on the other hand, is short, concise and, I'd argue, has acheived much greater recognition as a word due to HIBP. Reading how “PWNED” went from hacker slang to the internet’s favorite taunt, I think that's a fair conclusion to draw. For a moment, we even toyed with the idea of an actual rename to just "Pwned" and looked at trying to buy pwned.com via a broker which, uh, didn't work out real well:
Appartently, you can put a price on it! So no, we're not renaming anything, we're just providing various stylistic options for representing the logo. This is why we still have the much wordier versions as well:


Unlike old mate at Fiverr, a proper branding exercise like Mikael has done goes well beyond just the logo alone. For example, we have a colour palette:
And we have typography:

Hoodies:

And t-shirts:

You get the idea.
But most importantly, there's the website. Obviously the brand needs to prevail across to the digital realm, but there's also the issue of the front-end tech stack we build on, and that's something I've been thinking about for months now:
In 2013, I built the front end of @haveibeenpwned on Bootstrap and jQuery. In 2025, @stebets and I are rebuilding it as part of a rebrand. What should we use? What are the front end tools that make web dev awesome today? (vanilla HTML, CSS and JS aside, of course)
— Troy Hunt (@troyhunt) December 27, 2024
You can read all sorts of different suggestions in that thread but in the end, we decided to keep it simple:
And that's it. Except Stefan and I are busy guys and we really didn't want to invest our precious cycles rebuilding the front end, so we got Ingiber Olafsson to do it. Ingiber came to us via Stefan (so now we have two Icelanders, two Norwegians and... me), and he's been absolutely smashing out the new front end of HIBP:
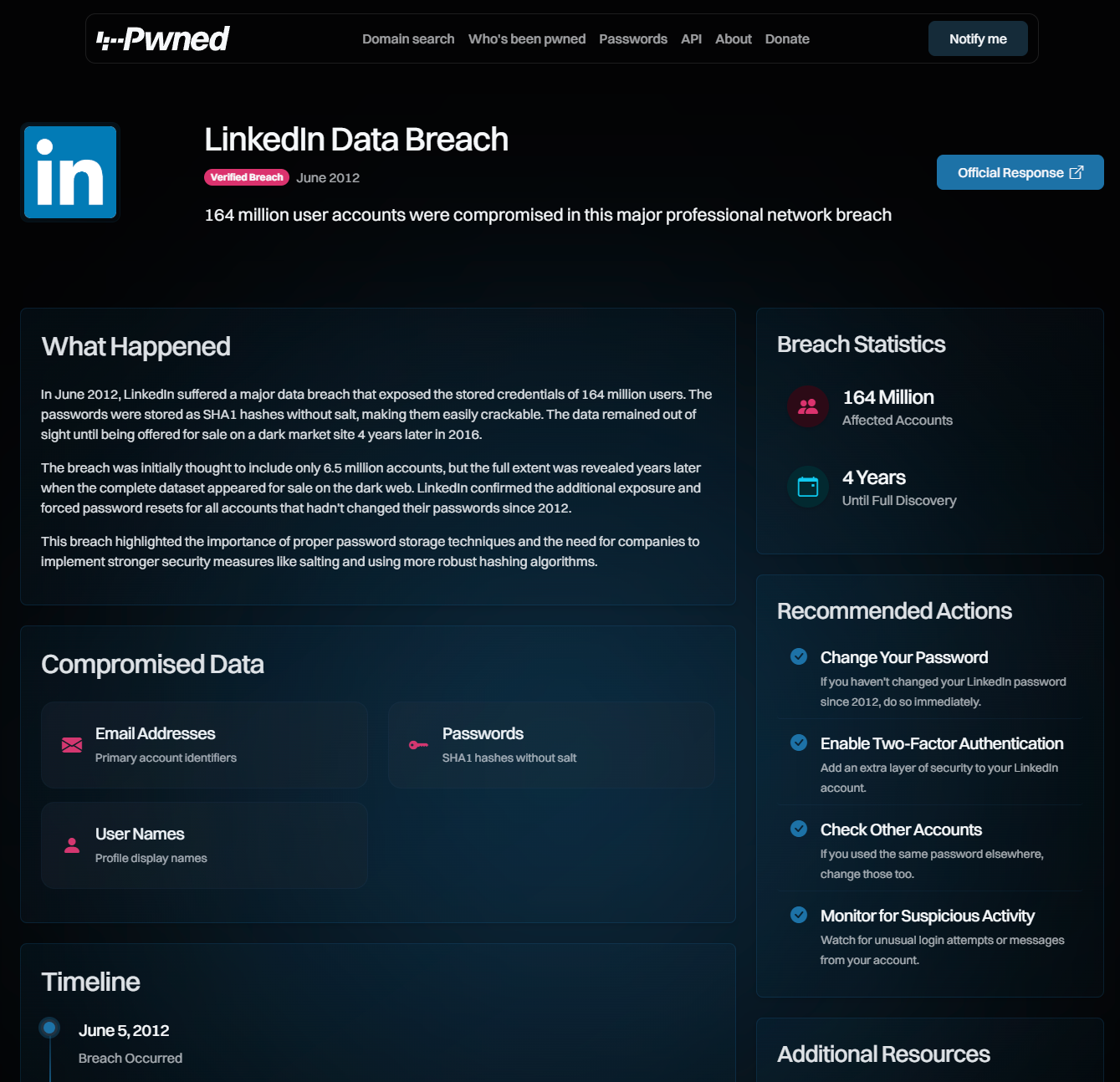
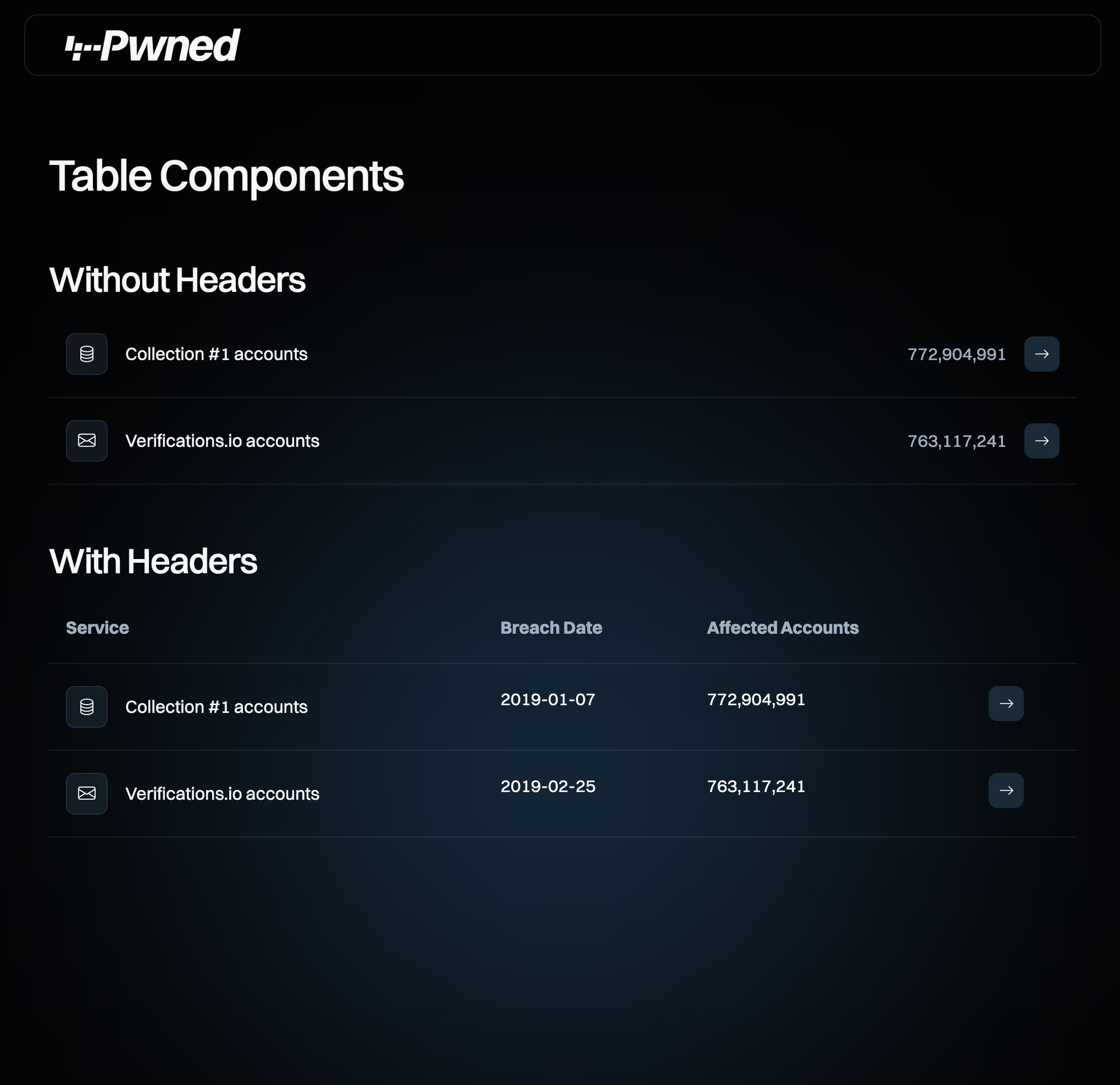
What I've really enjoyed with Ingiber's approach is that everything he's built is super clean, lightweight and visually beautiful (based on Mikael's work, of course). I've really appreciated his attention to detail that isn't always obvious too, for example making sure accessibility for the visually impaired is maximised:
Ingiber has helped get us to the point where very soon, Stefan and I will begin the integration work to roll the new brand into the main website. That's not just branding work either as the UX is getting a major overhaul. Some stuff is fairly minor: the list of pwned websites is now way too large and we need to have a dedicated page per breach. Other stuff is much more major: we want to have a specific "login" facility (quoting as it will likely remain passwordless by sending a token via email), where we'll then consolidate everything from notification enrolment to domain management to viewing stealer logs. It's a significant paradigm shift that requires a lot of very careful thought.
A quick caveat on the examples above and the others in the repository: we've given Ingiber free reign to experiment and throw ideas around. As a result, we've got some awsome stuff we hadn't thought about before. We've also got some stuff that will be infeasible in the short term, for example, a link through to the official response of the breached company and the full timeline of events. I hope ideas like this keep coming (both from Ingiber and the community), but just keep in mind that some things you see in this repo won't be on the website the day we roll all this out.
As with so much of this project since day one, we're doing this out in the open for everyone to see. Part of that is this blog post heralding what's to come, and part of it is also open sourcing the ux-rebuild repository. I actually created that repo more than a year ago and started crowd-sourcing ideas before closing it off last month whilst Ingiber got working. It's now open again, and I'd like to invite anyone interested to check out what we're building, leave their comments (either here on in the repo), send PRs and so on and so forth. I'm really stoked with the work the guys I've mentioned in this blog post have done, but there will be other great ideas that none of us have thought of yet. And if you come up with something awesome, we already have truckloads of stickers and 3D printed logos I'd love to send you:


So there we have it, that's the rebrand. Do please send us your feedback, not just about logos and look and feel, but also what you'd like to see UX and feature wise on the website. The discussions list on that repo is a great place the chime in or add new ideas, or even just the comments section below 👇
Edit: Wow, all the responses have been awesome! Gotta be honest, I was nervous redefining the brand after so long, but I couldn't have hoped for a better response 😊 I have two quick additions to this post:

I think I've finally caught my breath after dealing with those 23 billion rows of stealer logs last week. That was a bit intense, as is usually the way after any large incident goes into HIBP. But the confusing nature of stealer logs coupled with an overtly long blog post explaining them and the conflation of which services needed a subscription versus which were easily accessible by anyone made for a very intense last 6 days. And there were the issues around source data integrity on top of everything else, but I'll come back to that.
When we launched the ability to search through stealer logs last month, that wasn't the first corpus of data from an info stealer we'd loaded, it was just the first time we'd made the website domains they expose searchable. Now that we have an actual model around this, we're going to start going back through those prior incidents and backfilling the new searchable attributes. We've just done that with the 26M unique email address corpus from August last year and added a bunch previously unseen instances of an email address mapped against a website domain. We've also now flagged that incident as "IsStealerLog", so if you're using the API, you'll see that attribute now set to true.
For the most part, that data is all handled just the same as the existing stealer log data: we map email addresses to the domains they've appeared against in the logs then make all that searchable by full email address, email address domain or website domain (read last week's really, really long blog post if you need an explainer on that). But there's one crucial difference that we're applying both to the backfilling and the existing data, and that's related to a bit of cleaning up.
A theme that emerged last week was that there were email addresses that only appeared against one domain, and that was the domain the address itself was on. If john@gmail.com is in there and the only domain he appears against is gmail.com, what's up with that? At face value, John's details have been snared whilst logging on to Gmail, but it doesn't make sense that someone infected with an info stealer only has one website they've logging into captured by the malware. It should be many. This seems to be due to a combination of the source data containing credential stuffing rows (just email and password pairs) amidst info stealer data and somewhere in our processing pipeline, introducing integrity issues due to the odd inputs. Garbage in, garbage out, as they say.
So, we've decided to apply some Occam's razor to the situation and go with the simplest explanation: a single entry for an email address on the domain of that email address is unlikely to indicate an info stealer infection, so we're removing those rows. And not adding any more that meet that criteria. But there's no doubt the email address itself existed in the source; there is no level of integrity issues or parsing errors that causes john@gmail.com to appear out of thin air, so we're not removing the email addresses in the breach, just their mapping to the domain in the stealer log. I'd already explained such a condition in Jan, where there might be an email address in the breach but no corresponding stealer log entry:
The gap is explained by a combination of email addresses that appeared against invalidly formed domains and in some cases, addresses that only appeared with a password and not a domain. Criminals aren't exactly renowned for dumping perfectly formed data sets we can seamlessly work with, and I hope folks that fall into that few percent gap understand this limitation.
FWIW, entries that matched this pattern accounted for 13.6% of all rows in the stealer log table, so this hasn't made a great deal of difference in terms of outright volume.
This takes away a great deal of confusion regarding the infection status of the address owner. As part of this revision, we've updated all the stealer log counts seen on domain search dashboards, so if you're using that feature, you may see the number drop based on the purged data or increase based on the backfilled data. And we're not sending out any additional notifications for backfilled data either; there's a threshold at which comms becomes more noise than signal and I've a strong suspicion that's how it would be received if we started sending emails saying "hey, that stealer log breach from ages ago now has more data".
And that's it. We'll keep backfilling data, and the entire corpus within HIBP is now cleaner and more succinct. And we'll definitely clean up all the UX and website copy as part of our impending rebrand to ensure everything is a lot clearer in the future.
I'll leave you with a bit of levity related to subscription costs and value. As I recently lamented, resellers can be a nightmare to deal with, and we're seriously considering banning them altogether. But occasionally, they inadvertently share more than they should, and we get an insight into how the outside world views the service. Like a recent case where a reseller accidentally sent us the invoice they'd intended to send the customer who wanted to purchase from us, complete with a 131% price markup 😲 It was an annual Pwned 4 subscription that's meant to be $1,370, and simply to buy this on that customer's behalf and then hand them over to us, the reseller was charging $3,165. They can do this because we make the service dirt cheap. How do we know it's dirt cheap? Because another reseller inadvertently sent us this internal communication today:
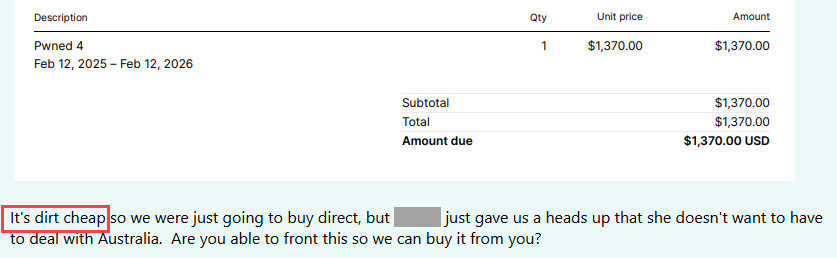
FWIW, we do have credit cards in Australia, and they work just the same as everywhere else. I still vehemently dislike resellers, but at least our customers are getting a good deal, especially when they buy direct 😊

I like to start long blog posts with a tl;dr, so here it is:
We've ingested a corpus of 1.5TB worth of stealer logs known as "ALIEN TXTBASE" into Have I Been Pwned. They contain 23 billion rows with 493 million unique website and email address pairs, affecting 284M unique email addresses. We've also added 244M passwords we've never seen before to Pwned Passwords and updated the counts against another 199M that were already in there. Finally, we now have a way for domain owners to query their entire domain for stealer logs and for website operators to identify customers who have had their email addresses snared when entering them into the site. (Note: stealer logs are still freely and easily searchable by individuals, scroll to the bottom for a walkthrough.)
This work has been a month-long saga that began hot off the heels of processing the last massive stash of stealer logs in the middle of Jan. That was the first time we'd ever added more context to stealer logs by way of making the websites email addresses had been logged against searchable. To save me repeating it all here, if you're unfamiliar with stealer logs as a concept and what we've previously done with HIBP, start there.
Up to speed? Good, let's talk about ALIEN TXTBASE.
Last month after loading the aforementioned corpus of data, someone in a government agency reached out and pointed me in the direction of more data by way of two files totalling just over 5GB. Their file names respectively contained the numbers "703" and "704", the word "Alien" and the following text at the beginning of each file:
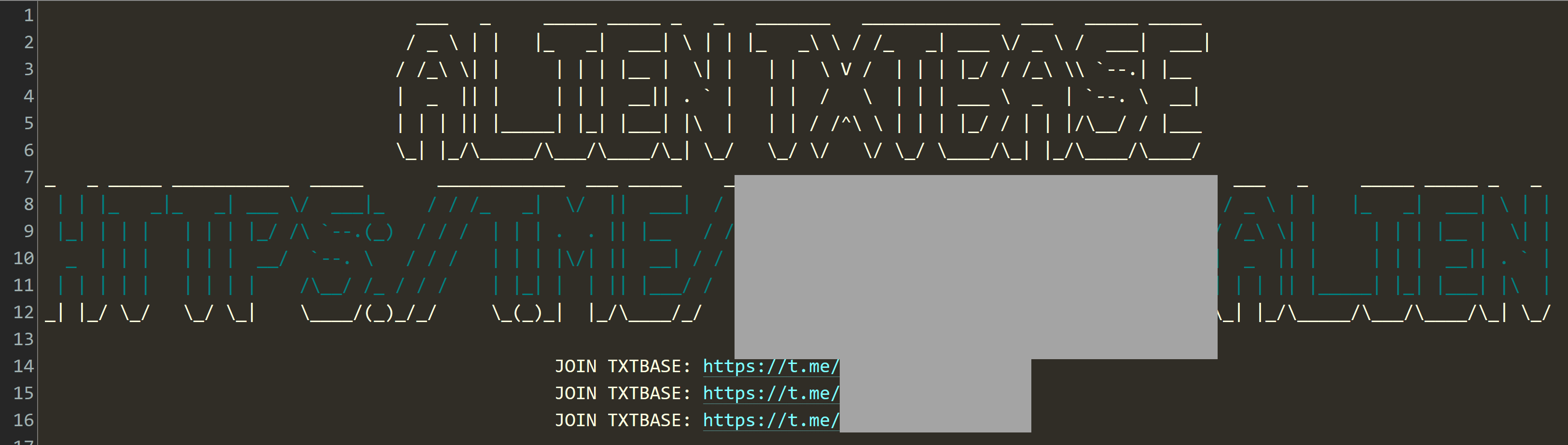
Pulling the threads, it turned out the Telegram channel referred to contained 744 files of which my contact had come across just the two. The data I'm writing about today is that full corpus, published to Telegram as individual files:
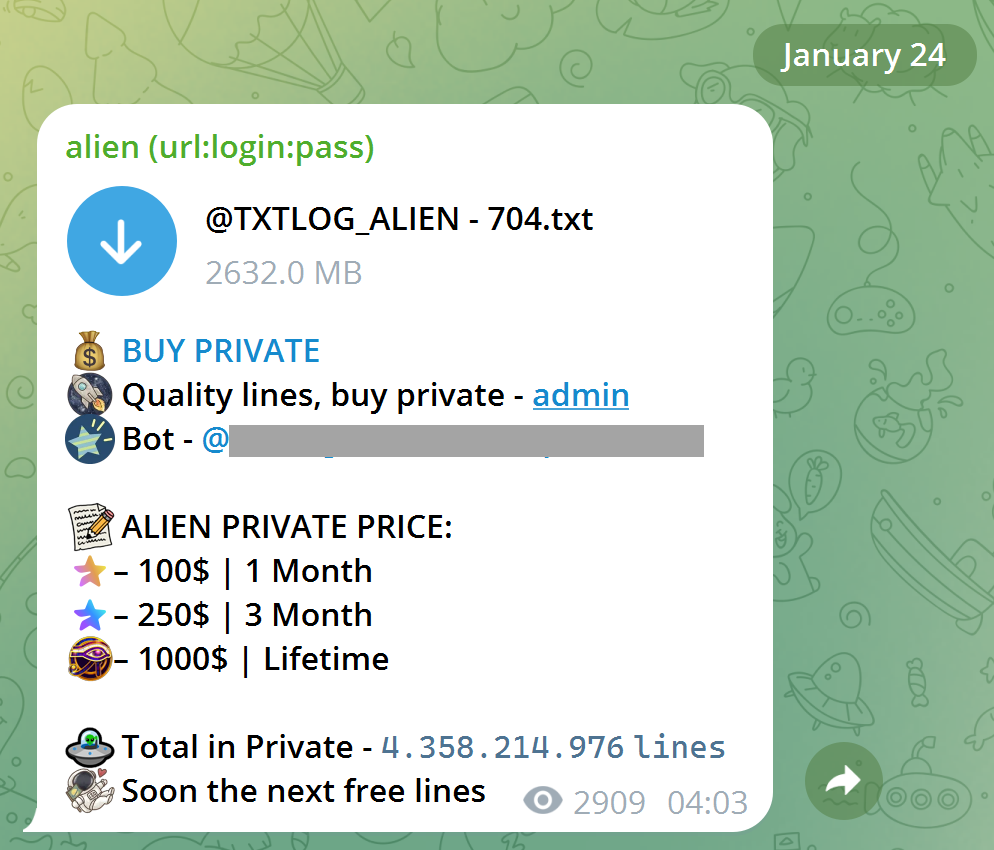
A quick side note on Telegram: There's been growing concern in recent years about the use of Telegram by organised crime, especially since the founder's arrest in France last year for not cracking down on illegal activity on the platform. Telegram makes it super easy to publish large volumes of data (such as we're talking about here) under the veil of anonymity and distribute it en mass. This is just one of many channels involved in cybercrime, but it's noteworthy due to the huge amount of freely accessible data.
The file in the image above contained over 36 million rows of data consisting of website URLs and the email addresses and passwords entered into them. But the file is just a sample - a teaser - with more data available via the subscription options offered in the message. And that's the monetisation route: provide existing data for free, then offer a subscription to feed newly obtained logs to consuming criminals with a desire to exploit the victims again. Again? The stealer logs are obtained in the first place by exploiting the victim's machine, for example:
How do people end up in stealer logs? By doing dumb stuff like this: “Around October I downloaded a pirated version of Adobe AE and after that a trojan got into my pc” pic.twitter.com/igEzOayCu6
— Troy Hunt (@troyhunt) August 5, 2024
So now this guy has malware running on his PC which is siphoning up all his credentials as they're entered into websites. It's those credentials that are then sold in the stealer logs and later used to access the victim's accounts, which is the second exploitation. Pirating software is just one way victims become infected; have a read of this recent case study from our Australian Signals Directorate:
When working from home, Alice remotely accesses the corporate network of her organisation using her personal laptop. Alice downloaded, onto her personal laptop, a version of Notepad++ from a website she believed to be legitimate. An info stealer was disguised as the installer for the Notepad++ software.
When Alice attempted to install the software, the info stealer activated and began harvesting user credentials from her laptop. This included her work username and password, which she had saved in her web browser’s saved logins feature. The info stealer then sent those user credentials to a remote command-and-control server controlled by a cybercriminal group.
Eventually, data like Alice's ends up in places like this Telegram channel and from there, it enables further crimes. From the same ASD article:
Stolen valid user credentials are highly valuable to cybercriminals, because they expedite the initial access to corporate networks and enterprise systems.
So, that's where the data has come from. As I said earlier, ALIEN TXTBASE is by no means the only Telegram channel out there, but it is definitely a major distribution channel.
When there's a breach of a discrete website, verification of the incident is usually pretty trivial. For example, if Netflix suffered a breach (and I have no indication they have, this is just an example), I can go to their website, head to the password reset field, enter a made-up email address and see a response like this:
On the other hand, an address that does exist on the service usually returns a message to the effect of "we've sent you a password reset email". This is called an "enumeration vector" in that it enables you to enumerate through a list of email addresses and find out which ones have an account on the site.
But stealer logs don't come from a single source like Netflix, instead they contain the credentials for a whole range of different sites visited by people infected with malware. However, I can still take lines from the stealer logs that were captured against Netflix and test the email addresses. (Note: I never test if the password is valid, that would be a privacy violation that constitutes unauthorised access and besides, as you'll read next, there's simply no need to.)
Initially, I actually ran into a bit of a roadblock when testing this:
I found this over and over again so, I went back and checked the source data and inspected this poor victim's record:

Their Netflix credentials were snared when they were entered into the website with a path of "/ph-en/login", implying they're likely Filipino. Let's try VPN'ing into Manilla:
And suddenly, a password reset gives me exactly what I need:
That's a little tangent from stealer logs, but Netflix obviously applies some geo-fencing logic to certain features. This actually worked out better than expected verification-wise because not only was I able to confirm the presence of the email address on their service, but that the stealer log entry placing them in the Philippines was also geographically correct. It was reproducible too: when I saw "something went wrong", but the path began with "mx", I VPN'd into Mexico City and Netflix happily confirmed the reset email was sent. Another path had "ve", so it was off to Caracas and the Venezuelan victim's account was confirmed. You get the idea. So, strong signal on confirmation of account existence via password reset, now let's also try something more personal.
I emailed a handful of HIBP subscribers and asked for their support verifying a breach. I got a fast, willing response from one guy and sent over more than 1,100 rows of data against his address 😲 It's fascinating what you can tell about a person from stealer log data: He's obviously German based on the presence of websites with a .de address, and he uses all the usual stuff most of us do (Amazon, eBay, LinkedIn, Airbnb). But it's the less common ones that make for more interesting reading: He drives a Mercedes because he's been logging into an address there for owners, and it also appears he likes whisky given his account at an online specialist. He's a Firefox user, as he's logged in there too, and he seems to be a techie as he's logged into Seagate and a site selling some very specialised electrical testing equipment. But is it legit?

Imagine the heart-in-mouth moment the poor guy must have had seeing his digital life laid out in front of him like that and knowing criminals have this data. It'd be a hell of a shock.
Having said all that, whilst I'm confident there's a large volume of legitimate data in this corpus, it's also possible there will be junk. Fabricated email addresses, websites that were never used, etc. I hope folks who experience this can appreciate how hard it is for us to discern "legitimate" stealer logs from those that were made up. We've done as much parsing and validation as possible, but we have no way of knowing if someone@yourdomain.com is an email address that actually exists or if it does, if they ever actually used Netflix or Spotify or whatever. They're just strings of data, and all we can do is report them as found.
When we published the stealer logs last month, I kept caveating everything with "experimental". Even the first word of the blog post title was "experimenting", simply because we didn't know how this would be received. Would people welcome the additional data we were making available? Or find it unactionable noise? It turns out it was entirely the former, and I didn't see a single negative comment or, as it often has been in the past with stealer logs or malware breaches, angry victims demanding I send their entire row(s) of data. And I guess that makes sense given what we made available so, starting today, we're making even more available!
First, a bit of nomenclature. Consider the following stealer log entry:
https://www.netflix.com/en-ph/login:john@gmail.com:P@ssw0rdThere are four parts to this entry that are relevant to the HIBP services I'm going to write about here:
| Email Address | ||||||
| Website Domain | Email Alias | Email Domain | ||||
| https:// | www.netflix.com | /en-ph/login | john | @ | example.com | P@ssw0rd |
Last month, we added functionality to the UI such that after verifying your email address you could see a collection of website domains. In the example above, this meant that John could use the free notification service to verify control of his email address after which he'd see www.netflix.com listed. (Note: we're presently totally redesigning this as part of our UX rebuild and it'll be much smoother in the very near future.) Likewise, we introduced an API to do exactly the same thing, but only after verifying control of the email domain. So, in the case above, the owner of example.com would be able to query john@example.com and get back www.netflix.com (along with any other website domains poor John had been using).
Today, we're introducing two new APIs, and they're big ones:
The first one is akin to our existing domain search feature so in the example above, the owner of the domain could query the stealer logs for example.com and get back each email address alias and the website domains they appear against. Here's what that output looks like:
{
"john": [
"netflix.com"
],
"jane": [
"netflix.com",
"spotify.com"
]
}
The previous model only allowed querying by email address, so you could end up with an organisation needing to iterate through thousands of individual API requests. This model means that can now be done in a single request, which will make life much easier for larger organisations assessing the exposure of their workforce.
The second new API is designed for website operators who want to identify customers who've had their credentials snared at login. So, in our demo row above, Netflix could query www.netflix.com (after verifying control of the domain, of course) and retrieve a list of their customers from the stealer logs:
[
"john@example.com",
"jane@yahoo.com"
]Both these new APIs are orientated towards larger organisations and can return vast volumes of data. When considering how to price this service, the simplest, most commensurate model we arrived at was to use a pricing tier we already had: Pwned 5:

Whilst we'd previously only ever listed tiers 1 through 4, we'd always had higher tiers sitting there in the background for organisations needing higher rate limits. Surfacing this subscription and adding the ability to query stealer logs via these two new APIs makes it easy for new and existing subscribers alike to unlock the feature. And if you are an existing subscriber, the price is simply adjusted pro rata at Stripe's end such that your existing balance is carried forward. Per the above image, this subscription is available either monthly or annually so if you just want to see what's in the current corpus of data and keep the cost down, take it for a month then cancel it. (Note: the Pwned 5 subscription is also now required for the API to search by email address we launched last month, but the web UI that uses the notification service to show stealer log results by email is absolutely still free and will remain that way.)
Another small addition since last month is that we've added an "IsStealerLog" flag on the breach model. This means that anyone programmatically dealing with data in HIBP can now easily elect to handle stealer logs differently than other breaches. For example, a new breach with this flag set to "true" might then trigger a query of the new API endpoints to search by domain so that an organisation can update their records with any new stealer log entries.
Anyone searching by email domain already knows the scope of addresses on their domain as it's reported on their dashboard. Plus, when email notifications are sent on breach load it tells you exactly how many new addresses from your domains are in the breach. Starting today, we've also added a column to explain how many email addresses appear against your website domain:
In other words, 3 people have had their email address grabbed by an info stealer when logging on to hibp-integration-tests.com, and the new API will return all of those addresses. It is only API-based for the moment, we'll consider if a UI makes sense as part of the rebranded site launch, it may not becuase of the potentially huge volumes of data.
Just one last thing: for the two new APIs that query by domain, we've set a rate limit which is entirely independent of the rate limit on, say, breached account searches. Whilst a Pwned 5 subscription would allow 1,000 requests to that API every minute, it's significantly more restricted when hitting those two new stealer log APIs. We haven't published a number as I expect we'll tweak it a bit based on usage, but it's more than enough for any normal use of the service whilst ensuring we don't get completely overwhelmed by high-overhead searches. The stealer log API that queries by email address inherits the 1,000 RPM rate limit of the Pwned 5 subscription.
One of the coolest most awesome best things we've ever done with HIBP is to create a massive repository of passwords that's all open source (both code and data) and can be queried anonymously without disclosing the searched password. Pwned Passwords is amazing, and it has gained huge traction:
There it is - we’ve now passed 10,000,000,000 requests to Pwned Password in 30 days 😮 This is made possible with @Cloudflare’s support, massively edge caching the data to make it super fast and highly available for everyone. pic.twitter.com/kw3C9gsHmB
— Troy Hunt (@troyhunt) October 5, 2024
10 billion times a month, our API helps a service somewhere assist one of their customers with making a good password choice. And that's just the API - we have no idea the full scope of the service as having the data open source means people can just download the entire corpus and run it themselves.
Per the opening para, we now have an additional 244 million previously unseen passwords in this corpus. And, as always, they make for some fun reading:
And, uh, some kangaroos doing other stuff I can't really repeat here. Those passwords are at the final stages of loading and should flush through cache to Cloudflare's hundreds of edge nodes in the next few hours. That's another quarter of a billion that join the list of previously breached ones, whilst 199 million we'd already seen before have had their prevalence counts upped.
It's amazing to see where my little pet project with the stupid name has gone, and nobody is more surprised than me when it pops up in cool places. Looking around for some stealer log references while writing this blog post, I came across this one:
This was already in place when you created a new account or updated your password. But now it's also verified on every login against the live HIBP database. Hats off to the tremendous service HIBP provides to the internet 🙏 https://t.co/Z61AgDaL2t
— DHH (@dhh) February 4, 2025
That's awesome! That's exactly the sort of use case that speaks to the motto of "do good things with breach data after bad things happen". By adding this latest trove of data, the folks using Basecamp will immediately benefit simply by virtue of the service being plugged into our API. And sidenote: David has done some amazing stuff in the past so I was especially excited to see this shout-out 😊
This one is a similar story, albeit using Pwned Passwords:
Their service is phenomenal! We also inform users in our product if they set/change their password to a known password that has been hacked. Admins have the option to not allow for users to use these passwords, if they wish. pic.twitter.com/bvLfYm9xzH
— Brad Marshall (@iamBMarshall) February 4, 2025
Inevitably, those requests form a slice of the 10 billion monthly we see that are now able to identify a quarter of a billion more compromised ones and hopefully, keep them out of harm's way.
For many organisations, the data we're making available via stealer logs is the missing piece of the puzzle that explains patterns that were previously unexplainable:
Gotta say I’m pretty happy with what we did with stealer logs last week, think we’re gonna need to do more of this 😎 pic.twitter.com/4rMaMmL8LU
— Troy Hunt (@troyhunt) January 21, 2025
I've had so many emails to that effect after loading various stealer logs over the years. The constant theme I love hearing is how it benefits the good guys and, well, not so much the bad guys:
I love it when @haveibeenpwned screws over the bad guys 😎 pic.twitter.com/I29aMhwClW
— Troy Hunt (@troyhunt) January 16, 2025
The introduction of these new APIs today will finally help many organisations identify the source of malicious activity and even more importantly, get ahead of it and block it before it does damange. Whilst there won't be any set cadence to the addition of more stealer logs (obviously, we can't really predict when this stuff will emerge), I have no doubt we'll continue to add a lot more data yet.
Processing this data has been non-trivial to say the least, so I thought I'd give you a bit of an overview of how I ultimately approached it. In essence, we're talking about transforming a very large amount of highly redundant text-based data and ultimately ending up with a distinct list of email addresses against website domains. Here's the high-level process:
It was actually much, much harder than this due to the trials and errors of attempting to distil what starts out as tens of billions of rows down into hundreds of millions of unique examples. I was initially doing a lot more of the processing in SQL Azure because hey, it's just cloud and you can turn up the performance as much as you want, right?! After running 80 cores of Azure SQL Hyperscale for days on end ($ouch$) and seeing no end in sight to the execution of queries intended to take distinct values across billions of rows, I fell back to local processing with .NET. You could, of course, use all sorts of other technologies of choice here, but it turned out that local processing with some hand-rolled code was way more efficient than delegating the task to a cloud-based RDBMS. The space used by the database tells a big part of the story:
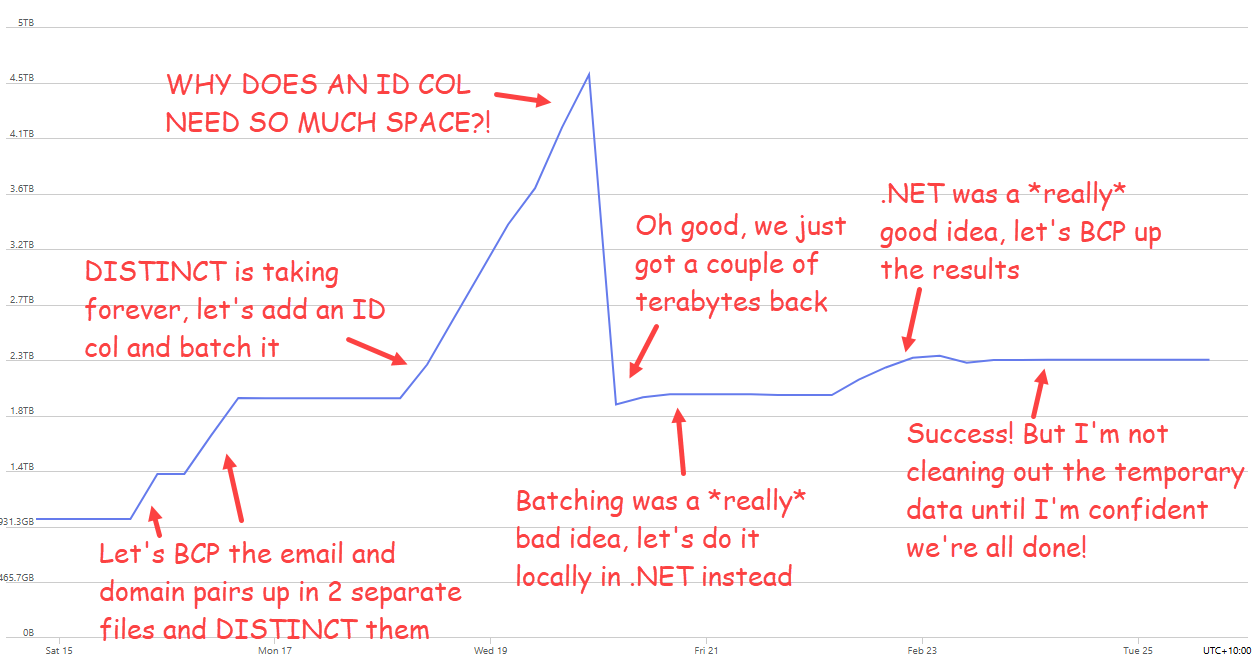
As I've said many times before, the cloud, my friends, is not always the answer. Do as much processing as possible locally on sunk-cost hardware unless there's a compelling reason not to.
I've detailed all this here in part because that's what I've always done with this project over the last 11 and a bit years, but also to illustrate how much time, effort, and money is burned processing data like this. It's very non-trivial, especially not when everything has to ultimately go into an increasingly large system with loads of external dependencies and be fast, reliable and cost-effective.
From 23 billion raw rows down to a much more manageable and discrete set of data, the latest stealer logs are now searchable via all the ways you've done for years, plus those two new domain-based stealer log APIs. We've called this breach "ALIEN TXTBASE Stealer Logs", let's see what positive outcomes we can all now produce with the data.
Edit 1: Let me re-emphasise an important point from the blog post I think got a bit buried: The web UI that uses the notification service to show stealer log results by email is absolutely still free and will remain that way. If you’ve got an email address in this breach and you want to see the stealer log domains against it, do this:
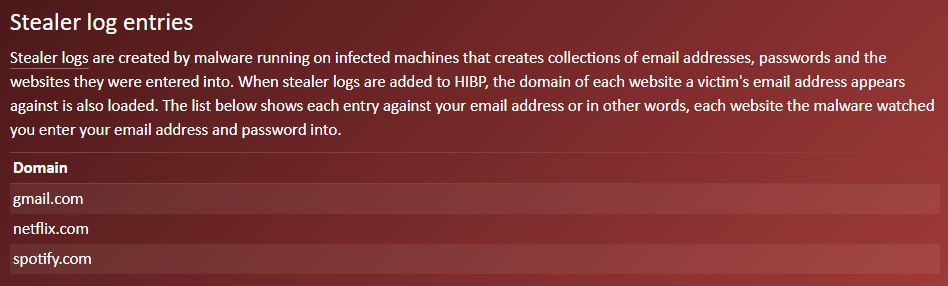
We need to make this clearer as it's obviously confusing. Thanks for everyone's feedback, we're working on it.
Edit 2: I've just published a (much shorter!) blog post that addresses a common theme in the comments regarding email addresses that only appear against a single website domain, being the same domain as the email address itself is on. Check that out if that's you.

TL;DR — Email addresses in stealer logs can now be queried in HIBP to discover which websites they've had credentials exposed against. Individuals can see this by verifying their address using the notification service and organisations monitoring domains can pull a list back via a new API.
Nasty stuff, stealer logs. I've written about them and loaded them into Have I Been Pwned (HIBP) before but just as a recap, we're talking about the logs created by malware running on infected machines. You know that game cheat you downloaded? Or that crack for the pirated software product? Or the video of your colleague doing something that sounded crazy but you thought you'd better download and run that executable program showing it just to be sure? That's just a few different ways you end up with malware on your machine that then watches what you're doing and logs it, just like this:
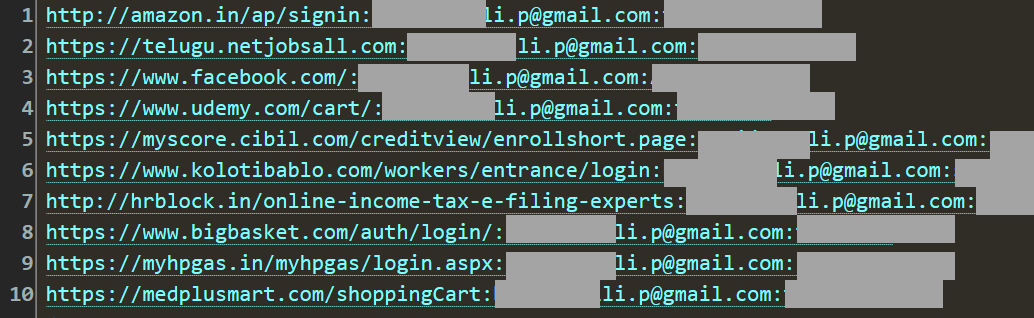
These logs all came from the same person and each time the poor bloke visited a website and logged in, the malware snared the URL, his email address and his password. It's akin to a criminal looking over his shoulder and writing down the credentials for every service he's using, except rather than it being one shoulder-surfing bad guy, it's somewhat larger than that. We're talking about billions of records of stealer logs floating around, often published via Telegram where they're easily accessible to the masses. Check out Bitsight's piece titled Exfiltration over Telegram Bots: Skidding Infostealer Logs if you'd like to get into the weeds of how and why this happens. Or, for a really quick snapshot, here's an example that popped up on Telegram as I was writing this post:
As it relates to HIBP, stealer logs have always presented a bit of a paradox: they contain huge troves of personal information that by any reasonable measure constitute a data breach that victims would like to know about, but then what can they actually do about it? What are the websites listed against their email address? And what password was used? Reading the comments from the blog post in the first para, you can sense the frustration; people want more info and merely saying "your email address appeared in stealer logs" has left many feeling more frustrated than informed. I've been giving that a lot of thought over recent months and today, we're going to take a big step towards addressing that concern:
The domains an email address appears next to in stealer logs can now be returned to authorised users.
This means the guy with the Gmail address from the screen grab above can now see that his address has appeared against Amazon, Facebook and H&R Block. Further, his password is also searchable in Pwned Passwords so every piece of info we have from the stealer log is now accessible to him. Let me explain the mechanics of this:
Firstly, the volumes of data we're talking about are immense. In the case of the most recent corpus of data I was sent, there are hundreds of text files with well over 100GB of data and billions of rows. Filtering it all down, we ended up with 220 million unique rows of email address and domain pairs covering 69 million of the total 71 million email addresses in the data. The gap is explained by a combination of email addresses that appeared against invalidly formed domains and in some cases, addresses that only appeared with a password and not a domain. Criminals aren't exactly renowned for dumping perfectly formed data sets we can seamlessly work with, and I hope folks that fall into that few percent gap understand this limitation.
So, we now have 220 million records of email addresses against domains, how do we surface that information? Keeping in mind that "experimental" caveat in the title, the first decision we made is that it should only be accessible to the following parties:
At face value it might look like that first point deviates from the current model of just entering an email address on the front page of the site and getting back a result (and there are very good reasons why the service works this way). There are some important differences though, the first of which is that whilst your classic email address search on HIBP returns verified breaches of specific services, stealer logs contain a list of services that have never have been breached. It means we're talking about much larger numbers that build up far richer profiles; instead of a few breached services someone used, we're talking about potentially hundreds of them. Secondly, many of the services that appear next to email addresses in the stealer logs are precisely the sort of thing we flag as sensitive and hide from public view. There's a heap of Pornhub. There are health-related services. Religious one. Political websites. There are a lot of services there that merely by association constitute sensitive information, and we just don't want to take the risk of showing that info to the masses.
The second point means that companies doing domain searches (for which they already need to prove control of the domain), can pull back the list of the websites people in their organisation have email addresses next to. When the company controls the domain, they also control the email addresses on that domain and by extension, have the technical ability to view messages sent to their mailbox. Whether they have policies prohibiting this is a different story but remember, your work email address is your work's email address! They can already see the services sending emails to their people, and in the case of stealer logs, this is likely to be enormously useful information as it relates to protecting the organisation. I ran a few big names through the data, and even I was shocked at the prevalence of corporate email addresses against services you wouldn't expect to be used in the workplace (then again, using the corp email address in places you definitely shouldn't be isn't exactly anything new). That in itself is an issue, then there's the question of whether these logs came from an infected corporate machine or from someone entering their work email address into their personal device.
I started thinking more about what you can learn about an organisation's exposure in these logs, so I grabbed a well-known brand in the Fortune 500. Here are some of the highlights:
That said, let me emphasise a critical point:
This data is prepared and sold by criminals who provide zero guarantees as to its accuracy. The only guarantee is that the presence of an email address next to a domain is precisely what's in the stealer log; the owner of the address may never have actually visited the indicated website.
Stealer logs are not like typical data breaches where it's a discrete incident leading to the dumping of customers of a specific service. I know that the presence of my personal email address in the LinkedIn and Dropbox data breaches, for example, is a near-ironclad indication that those services exposed my data. Stealer logs don't provide that guarantee, so please understand this when reviewing the data.
The way we've decided to implement these two use cases differs:
We'll make the individual searches cleaner in the near future as part of the rebrand I've recently been talking about. For now, here's what it looks like:
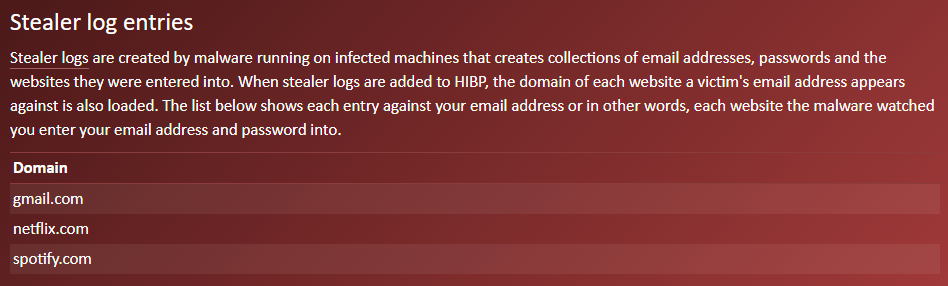
Because of the recirculation of many stealer logs, we're not tracking which domains appeared against which breaches in HIBP. Depending on how this experiment with stealer logs goes, we'll likely add more in the future (and fill in the domain data for existing stealer logs in HIBP), but additional domains will only appear in the screen above if they haven't already been seen.
We've done the searches by domain owners via API as we're talking about potentially huge volumes of data that really don't scale well to the browser experience. Imagine a company with tens or hundreds of thousands of breached addresses and then a whole heap of those addresses have a bunch of stealer log entries against them. Further, by putting this behind a per-email address API rather than automatically showing it on domain search means it's easy for an org to not see these results, which I suspect some will elect to do for privacy reasons. The API approach was easiest while we explore this service then we can build on that based on feedback. I mentioned this was experimental, right? For now, it looks like this:
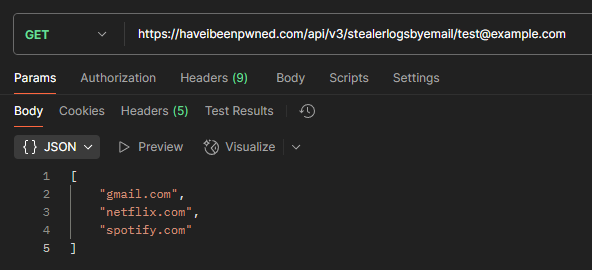
Lastly, there's another opportunity altogether that loading stealer logs in this fashion opens up, and the penny dropped when I loaded that last one mentioned earlier. I was contacted by a couple of different organisations that explained how around the time the data I'd loaded was circulating, they were seeing an uptick in account takeovers "and the attackers were getting the password right first go every time!" Using HIBP to try and understand where impacted customers might have been exposed, they posited that it was possible the same stealer logs I had were being used by criminals to extract every account that had logged onto their service. So, we started delving into the data and sure enough, all the other email addresses against their domain aligned with customers who were suffering from account takeover. We now have that data in HIBP, and it would be technically feasible to provide this to domain owners so that they can get an early heads up on which of their customers they probably have to rotate credentials for. I love the idea as it's a great preventative measure, perhaps that will be our next experiment.
Onto the passwords and as mentioned earlier, these have all been extracted and added to the existing Pwned Passwords service. This service remains totally free and open source (both code and data), has a really cool anonymity model allowing you to hit the API without disclosing the password being searched for, and has become absolutely MASSIVE!
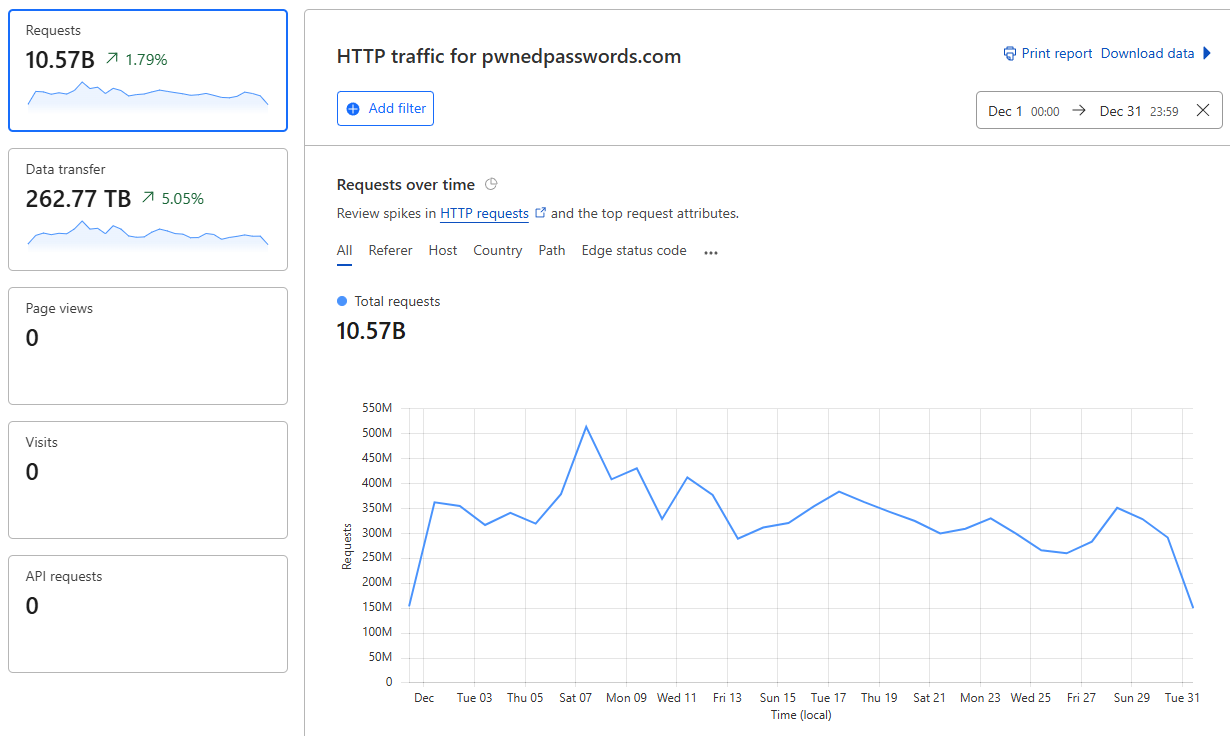
I thought that doing more than 10 billion requests a month was cool, but look at that data transfer - more than a quarter of a petabyte just last month! And it's in use at some pretty big name sites as well:
That's just where the API is implemented client-side, and we can identify the source of the requests via the referrer header. Most implementations are done server-side, and by design, we have absolutely no idea who those folks are. Shoutout to Cloudflare while we're here for continuing to provide the service behind this for free to help make a more secure web.
In terms of the passwords in this latest stealer log corpus, we found 167 million unique ones of which only 61 million were already in HIBP. That's a massive number, so we did some checks, and whilst there's always a bit of junk in these data sets (remember - criminals and formatting!) there's also a heap of new stuff. For example:
And about 106M other non-kangaroo themed passwords. Admittedly, we did start to get a bit preoccupied looking at some of the creative ways people were creating previously unseen passwords:
And here's something especially ironic: check out these stealer log entries:
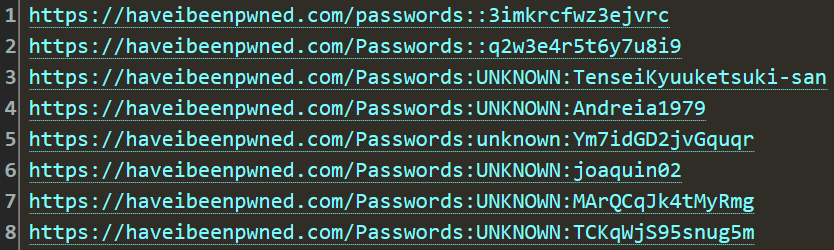
People have been checking these passwords on HIBP's service whilst infected with malware that logged the search! None of those passwords were in HIBP... but they all are now 🙂
Want to see something equally ironic? People using my Hack Yourself First website to learn about secure coding practices have also been infected with malware and ended up in stealer logs:

So, that's the experiment we're trying with stealer logs, and that's how to see the websites exposed against an email address. Just one final comment as it comes up every single time we load data like this:
We cannot manually provide data on a per-individual basis.
Hopefully, there's less need to now given the new feature outlined above, and I hope the massive burden of looking up individual records when there are 71 million people impacted is evident. Do leave your comments below and help us improve this feature to become as useful as we can possibly make it.

Nearly four years ago now, I set out to write a book with Charlotte and RobIt was the stories behind the stories, the things that drove me to write my most important blog posts, and then the things that happened afterwards. It's almost like a collection of meta posts, each one adding behind-the-scenes commentary that most people reading my material didn't know about at the time.
It was a strange time for all of us back then. I didn't leave the country for the first time in over a decade. I barely even left the state. I had time to toil on the passion project that became this book. As I wrote about years later, there were also other things occupying my mind at the time. Writing this book was cathartic, providing me the opportunity to express some of the emotions I was feeling at the time and to reflect on life.
Speaking of reflecting, this week was Have I Been Pwned's 11th birthday. Reaching this milestone, getting back to travel (I'm writing this poolside with a beer at a beautiful hotel in Dubai), life settling down (while sitting next to my amazing wife), and it now being 2 years since we launched the book, I decided we should just give it away for free. I mean really free, not "give me all your personal details, then here's a download link" I mean, here are the direct download links:
I hope you enjoy the book. It's the culmination of so many things I worked so hard to create over the preceding decade and a half, and I'm really happy to just be giving it away now. Enjoy the book 😊
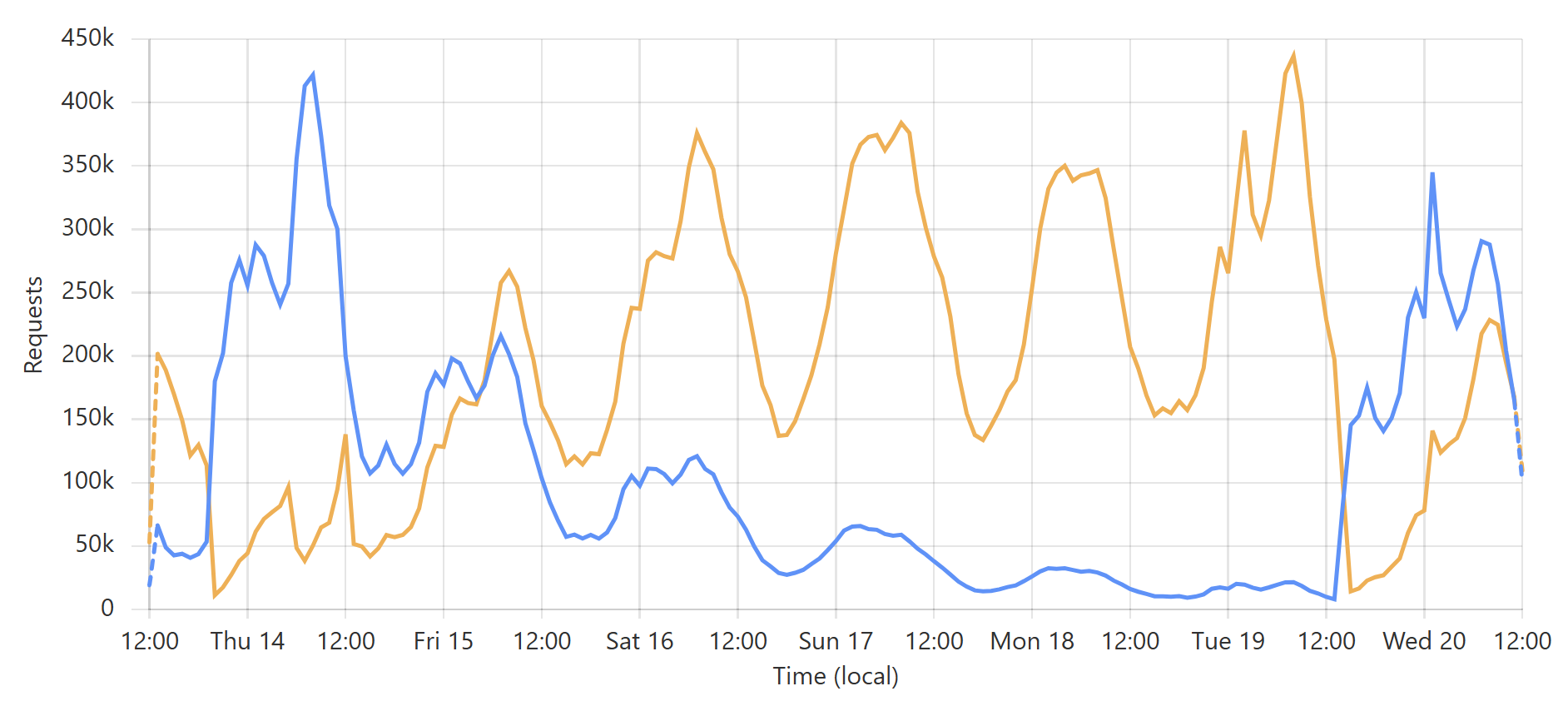
I've spent more than a decade now writing about how to make Have I Been Pwned (HIBP) fast. Really fast. Fast to the extent that sometimes, it was even too fast:
The response from each search was coming back so quickly that the user wasn’t sure if it was legitimately checking subsequent addresses they entered or if there was a glitch.
Over the years, the service has evolved to use emerging new techniques to not just make things fast, but make them scale more under load, increase availability and sometimes, even drive down cost. For example, 8 years ago now I started rolling the most important services to Azure Functions, "serverless" code that was no longer bound by logical machines and would just scale out to whatever volume of requests was thrown at it. And just last year, I turned on Cloudflare cache reserve to ensure that all cachable objects remained cached, even under conditions where they previously would have been evicted.
And now, the pièce de résistance, the coolest performance thing we've done to date (and it is now "we", thank you Stefán): just caching the whole lot at Cloudflare. Everything. Every search you do... almost. Let me explain, firstly by way of some background:
When you hit any of the services on HIBP, the first place the traffic goes from your browser is to one of Cloudflare's 330 "edge nodes":
As I sit here writing this on the Gold Coast on Australia's most eastern seaboard, any request I make to HIBP hits that edge node on the far right of the Aussie continent which is just up the road in Brisbane. The capital city of our great state of Queensland is just a short jet ski away, about 80km as the crow flies. Before now, every single time I searched HIBP from home, my request bytes would travel up the wire to Brisbane and then take a giant 12,000km trip to Seattle where the Azure Function in the West US Azure data would query the database before sending the response 12,000km back west to Cloudflare's edge node, then the final 80km down to my Surfers Paradise home. But what if it didn't have to be that way? What if that data was already sitting on the Cloudflare edge node in Brisbane? And the one in Paris, and the one in well, I'm not even sure where all those blue dots are, but what if it was everywhere? Several awesome things would happen:
In short, pushing data and processing "closer to the edge" benefits both our customers and ourselves. But how do you do that for 5 billion unique email addresses? (Note: As of today, HIBP reports over 14 billion breached accounts, the number of unique email addresses is lower as on average, each breached address has appeared in multiple breaches.) To answer this question, let's recap on how the data is queried:
Let's delve into that last point further because it's the secret sauce to how this whole caching model works. In order to provide subscribers of this service with complete anonymity over the email addresses being searched for, the only data passed to the API is the first six characters of the SHA-1 hash of the full email address. If this sounds odd, read the blog post linked to in that last bullet point for full details. The important thing for now, though, is that it means there are a total of 16^6 different possible requests that can be made to the API, which is just over 16 million. Further, we can transform the first two use cases above into k-anonymity searches on the server side as it simply involved hashing the email address and taking those first six characters.
In summary, this means we can boil the entire searchable database of email addresses down to the following:
That's a large albeit finite list, and that's what we're now caching. So, here's what a search via email address looks like:
K-anonymity searches obviously go straight to step four, skipping the first few steps as we already know the hash prefix. All of this happens in a Cloudflare worker, so it's "code on the edge" creating hashes, checking cache then retrieving from the origin where necessary. That code also takes care of handling parameters that transform queries, for example, filtering by domain or truncating the response. It's a beautiful, simple model that's all self-contained within a worker and a very simple origin API. But there's a catch - what happens when the data changes?
There are two events that can change cached data, one is simple and one is major:
The second point is kind of frustrating as we've built up this beautiful collection of data all sitting close to the consumer where it's super fast to query, and then we nuke it all and go from scratch. The problem is it's either that or we selectively purge what could be many millions of individual hash prefixes, which you can't do:
For Zones on Enterprise plan, you may purge up to 500 URLs in one API call.
And:
Cache-Tag, host, and prefix purging each have a rate limit of 30,000 purge API calls in every 24 hour period.
We're giving all this further thought, but it's a non-trivial problem and a full cache flush is both easy and (near) instantaneous.
Enough words, let's get to some pictures! Here's a typical week of queries to the enterprise k-anonymity API:
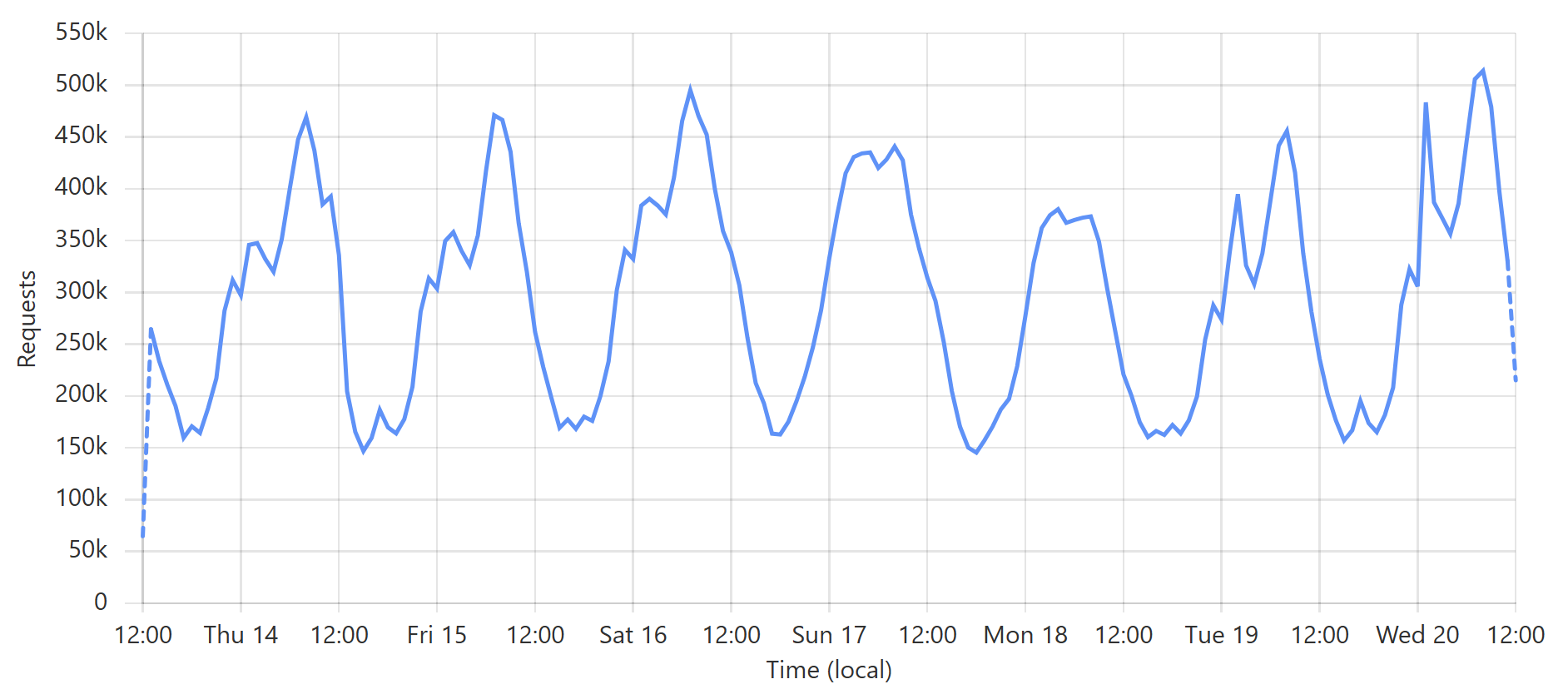
This is a very predictable pattern, largely due to one particular subscriber regularly querying their entire customer base each day. (Sidenote: most of our enterprise level subscribers use callbacks such that we push updates to them via webhook when a new breach impacts their customers.) That's the total volume of inbound requests, but the really interesting bit is the requests that hit the origin (blue) versus those served directly by Cloudflare (orange):
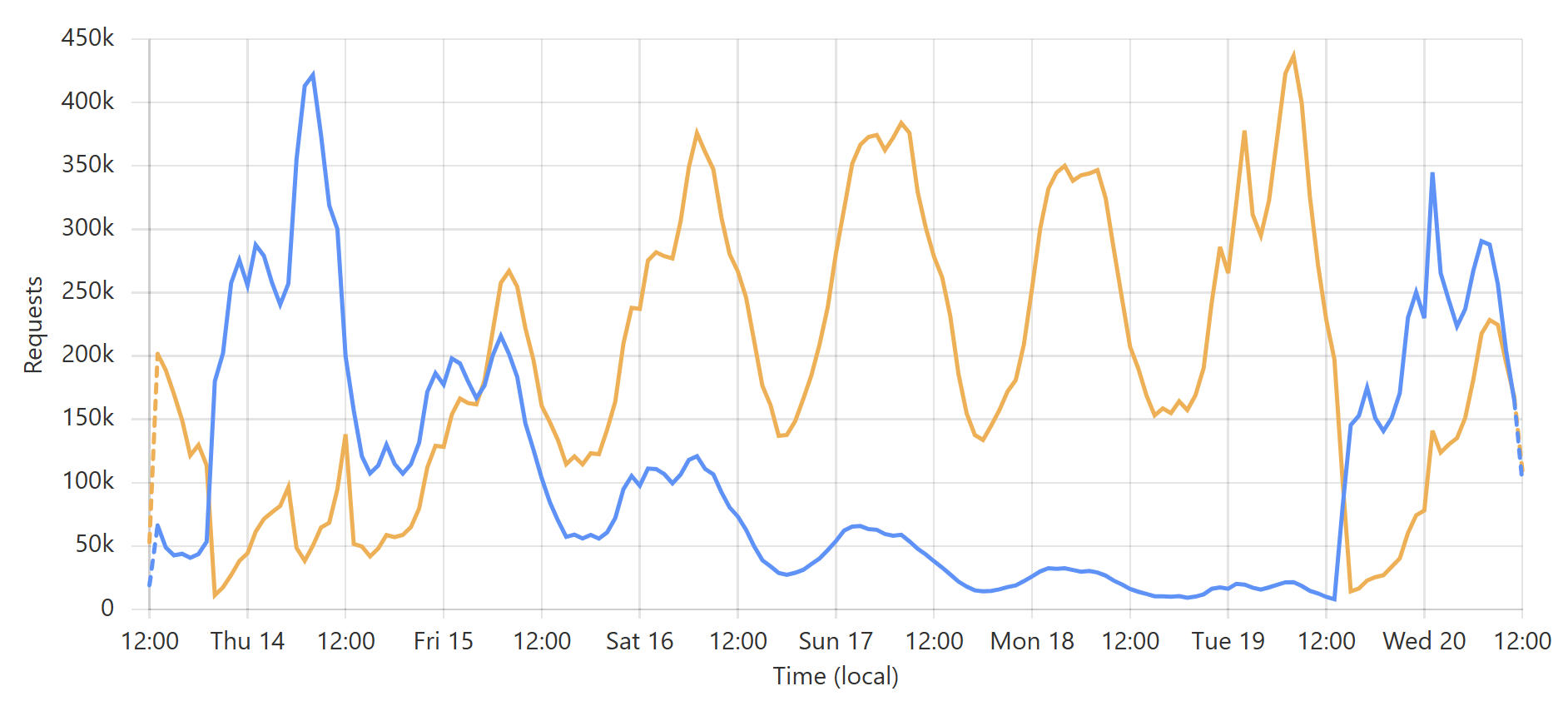
Let's take the lowest blue data point towards the end of the graph as an example:
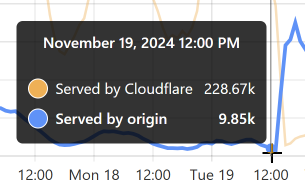
At that time, 96% of requests were served from Cloudflare's edge. Awesome! But look at it only a little bit later:
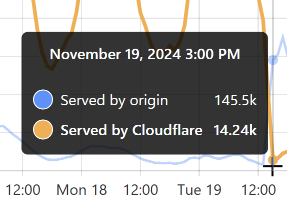
That's when I flushed cache for the Finsure breach, and 100% of traffic started being directed to the origin. (We're still seeing 14.24k hits via Cloudflare as, inevitably, some requests in that 1-hour block were to the same hash range and were served from cache.) It then took a whole 20 hours for the cache to repopulate to the extent that the hit:miss ratio returned to about 50:50:
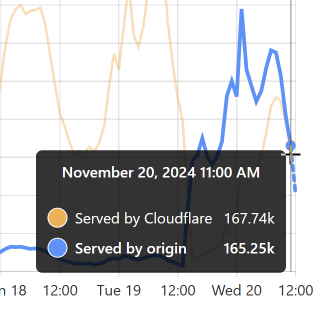
Look back towards the start of the graph and you can see the same pattern from when I loaded the DemandScience breach. This all does pretty funky things to our origin API:
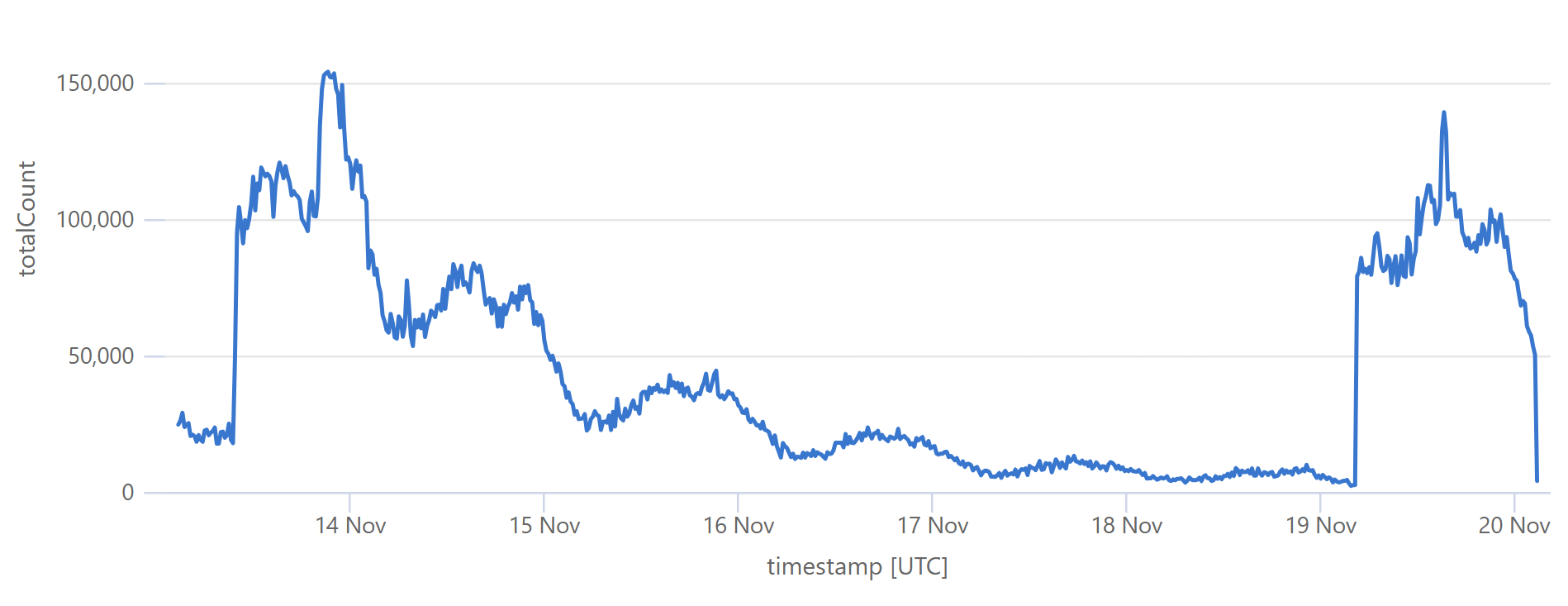
That last sudden increase is more than a 30x traffic increase in an instant! If we hadn't been careful about how we managed the origin infrastructure, we would have built a literal DDoS machine. Stefán will write later about how we manage the underlying database to ensure this doesn't happen, but even still, whilst we're dealing with the cyclical support patterns seen in that first graph above, I know that the best time to load a breach is later in the Aussie afternoon when the traffic is a third of what it is first thing in the morning. This helps smooth out the rate of requests to the origin such that by the time the traffic is ramping up, more of the content can be returned directly from Cloudflare. You can see that in the graphs above; that big peaky block towards the end of the last graph is pretty steady, even though the inbound traffic the first graph over the same period of time increases quite significantly. It's like we're trying to race the increasing inbound traffic by building ourselves up a bugger in cache.
Here's another angle to this whole thing: now more than ever, loading a data breach costs us money. For example, by the end of the graphs above, we were cruising along at a 50% cache hit ratio, which meant we were only paying for half as many of the Azure Function executions, egress bandwidth, and underlying SQL database as we would have been otherwise. Flushing cache and suddenly sending all the traffic to the origin doubles our cost. Waiting until we're back at 90% cache it ratio literally increases those costs 10x when we flush. If I were to be completely financially ruthless about it, I would need to either load fewer breaches or bulk them together such that a cache flush is only ejecting a small amount of data anyway, but clearly, that's not what I've been doing 😄
There's just one remaining fly in the ointment...
Of those three methods of querying email addresses, the first is a no-brainer: searches from the front page of the website hit a Cloudflare Worker where it validates the Turnstile token and returns a result. Easy. However, the second two models (the public and enterprise APIs) have the added burden of validating the API key against Azure API Management (APIM), and the only place that exists is in the West US origin service. What this means for those endpoints is that before we can return search results from a location that may be just a short jet ski ride away, we need to go all the way to the other side of the world to validate the key and ensure the request is within the rate limit. We do this in the lightest possible way with barely any data transiting the request to check the key, plus we do it in async with pulling the data back from the origin service if it isn't already in cache. In other words, we're as efficient as humanly possible, but we still cop a massive latency burden.
Doing API management at the origin is super frustrating, but there are really only two alternatives. The first is to distribute our APIM instance to other Azure data centres, and the problem with that is we need a Premium instance of the product. We presently run on a Basic instance, which means we're talking about a 19x increase in price just to unlock that ability. But that's just to go Premium; we then need at least one more instance somewhere else for this to make sense, which means we're talking about a 28x increase. And every region we add amplifies that even further. It's a financial non-starter.
The second option is for Cloudflare to build an API management product. This is the killer piece of this puzzle, as it would put all the checks and balances within the one edge node. It's a suggestion I've put forward on many occasions now, and who knows, maybe it's already in the works, but it's a suggestion I make out of a love of what the company does and a desire to go all-in on having them control the flow of our traffic. I did get a suggestion this week about rolling what is effectively a "poor man's API management" within workers, and it's a really cool suggestion, but it gets hard when people change plans or when we want to apply quotas to APIs rather than rate limits. So c'mon Cloudflare, let's make this happen!
Finally, just one more stat on how powerful serving content directly from the edge is: I shared this stat last month for Pwned Passwords which serves well over 99% of requests from Cloudflare's cache reserve:
There it is - we’ve now passed 10,000,000,000 requests to Pwned Password in 30 days 😮 This is made possible with @Cloudflare’s support, massively edge caching the data to make it super fast and highly available for everyone. pic.twitter.com/kw3C9gsHmB
— Troy Hunt (@troyhunt) October 5, 2024
That's about 3,900 requests per second, on average, non-stop for 30 days. It's obviously way more than that at peak; just a quick glance through the last month and it looks like about 17k requests per second in a one-minute period a few weeks ago:
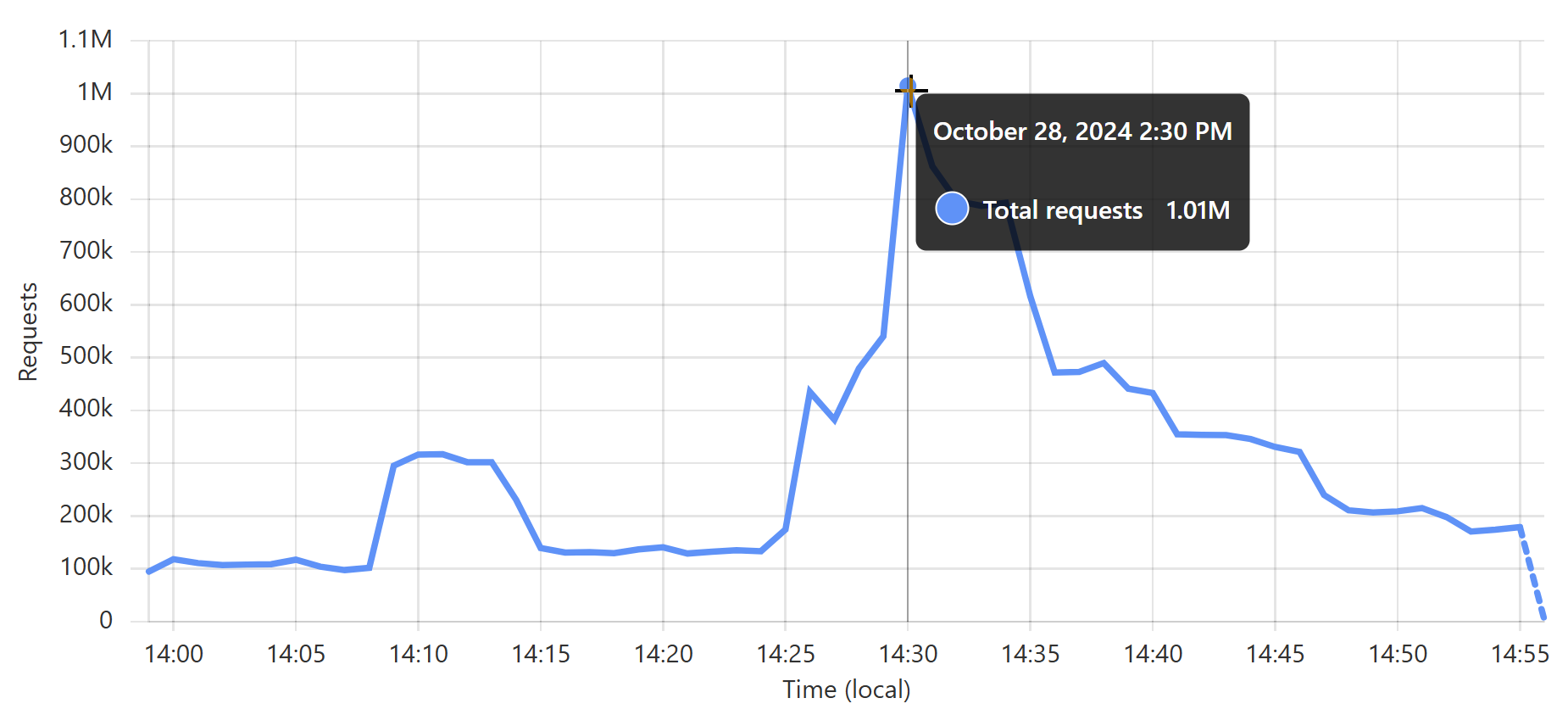
But it doesn't matter how high it is, because I never even think about it. I set up the worker, I turned on cache reserve, and that's it 😎
I hope you've enjoyed this post, Stefán and I will be doing a live stream on this topic at 06:00 AEST Friday morning for this week's regular video update, and it'll be available for replay immediately after. It's also embedded here for convenience:

Apparently, before a child reaches the age of 13, advertisers will have gathered more 72 million data points on them. I knew I'd seen a metric about this sometime recently, so I went looking for "7,000", which perfectly illustrates how unaware we are of the extent of data collection on all of us. I started Have I Been Pwned (HIBP) in the first place because I was surprised at where my data had turned up in breaches. 11 years and 14 billion breached records later, I'm still surprised!
Jason (not his real name) was also recently surprised at where his data had appeared. He found it in a breach of a service called "Pure Incubation", a company whose records had appeared on a popular hacking forum earlier this year:
#DataLeak Alert ⚠️⚠️⚠️
— HackManac (@H4ckManac) February 28, 2024
🚨Over 183 Million Pure Incubation Ventures Records for Sale 🚨
183,754,481 records belonging to Pure Incubation Ventures (https://t.co/m3sjzAMlXN) have been put up for sale on a hacking forum for $6,000 negotiable.
Additionally, the threat actor with… pic.twitter.com/tqsyb8plPG
When Jason found his email address and other info in this corpus, he had the same question so many others do when their data turns up in a place they've never heard of before - how? Why?! So, he asked them:
I seem to have found my email in your data breach. I am interested in finding how my information ended up in your database.
To their credit, he got a very comprehensive answer, which I've included below:

Well, that answers the "how" part of the equation; they've aggregated data from public sources. And the "why" part? It's the old "data is the new oil" analogy that recognises how valuable our info is, and as such, there's a market for it. There are lots of terms used to describe what DemandScience does, including "B2B demand generation", "buyer intelligence solutions provider", "empowering technology companies to accelerate ROI", "supercharging pipelines" and "account intelligence". Or, to put it in a more lay-person-friendly fashion, they sell data on people.
DemandScience is what we refer to as a "data aggregator" in that they combine identity data from multiple locations, bundle it up, and then sell it. Occasionally, data aggregators end up having sizeable data breaches; before today, HIBP already contained Adapt (9M records), Data & Leads (44M records), Exactis (132M records), Factual (2M records), and You've Been Scraped (66M records). According to DemandScience, "none of our current operational systems were exploited", yet simultaneously, "the leaked data originated from a system that has been decommissioned". So, it's a breach of an old system.
Does it matter? I mean, if it's just public data, should people care? Jason cared, at least enough to make the original enquiry and for DemandScience to look him up and realise he's not in their current database. Still, he existed in the breached one (I later sent Jason his record from the breach, and he confirmed the accuracy). As I often do in these cases, I reached out to a bunch of recent HIBP subscribers in the breach and asked them three simple questions:
The answers were all the same: the data is accurate, it's already in the public domain, and people aren't too concerned about it appearing in this breach. Well that was easy 🙂 However...
There are two nuances that aren't captured here, and the first one is that this is valuable data, that's why DemandScience sells it! It comes back to that "new oil" analogy and if you have enough of it, you can charge good money for it. Companies typically use data such as this to do precisely the sort of catchphrasey stuff the company talks about, primarily around maximising revenue from their customers by understanding them better.
The second nuance is that whilst this data may already be in the public domain, did the owners of it expect it to be used in this fashion? For example, if you publish your details in a business directory, is your expectation that this info may then be sold to other companies to help them upsell you on their products? Probably not. And if, like many of the records in the data, someone's row is accompanied by their LinkedIn profile, would they expect that data to matched and sold? I suggest the responses would likely be split here, and that in itself is an important observation: how we view the sensitivity of our data and the impact of it being exposed (whether personal or business) is extremely personal. Some people take the view of "I have nothing to hide", whilst others become irate if even just their email address is exposed.
Whilst considering how to add more insights to this blog post, I thought I'd do a quick check on just one more email address:
"54543060",,"0","TROY","HUNT","PO BOX 57",,"WEST RYDE",,,"AU","61298503333",,,,"troy.hunt@pfizer.com","pfizer.com","PFIZER INC",,"250-499","$50 - 99 Million","Healthcare, Pharmaceuticals and Biotech","VICE PRESIDENT OF INFORMATION TECHNOLOGY","VP Level","2834",,"Senior Management (SVP/GM/Director)","IT",,"1","GemsTarget INTL","GEMSTARGET_INTL_648K_10.17.18",,,,,,,,,"18/10/2018 05:12:39","5/10/2021 16:47:56","PFIZER.COM",,,,,"IT Management General","Information Technology"
I'll be entirely transparent and honest here - my exact words after finding this were "motherfucker!" True story, told uncensored here because I want to impress on the audience how I feel when my data turns up somewhere publicly. And I do feel like it's "my" data; it's certainly my name and even though it's my old Pfizer email address I've not used for almost a decade now, that also has my name in it. My job title is also there... and it's completely wrong! I never had a VP-level role, even though the other data around my tech role is at least in the vicinity of being correct. But other than the initial shock of finding myself in yet another data breach, personally, I'm in the same boat as the HIBP subscribers I contacted, and this doesn't bother me too much. But I also agree with the following responses I received to my third question:
I think it is useful to be notified of such breaches, even if it is just to confirm no sensitive data has been compromised. As I said, our IT department recently notified me that some of my data was leaked and a pre-emptive password reset was enforced as they didn't know what was leaked.
It would be good to see it as an informational notification in case there's an increase in attack attempts against my email address.
I would like to opt-out of here to reduce the SPAM and Phishing emails.
That last one seems perfectly reasonable, and fortunately, DemandScience does have a link on their website to Do Not Sell My Information:
Dammit! If, like me, you're part of the 99.5% of the world that doesn't live in California, then apparently this form isn't for you. However, they do list dataprivacy@demandscience.com on that page, which is the same address Jason was communicating with above. Chances are, if you want to remove your data then that's where to start.
There were almost 122M unique email addresses in this corpus and those have now been added to HIBP. Treat this as informational; I suspect that for most people, it won't bother them, whilst others will ask for their data not to be sold (regardless of where they live in the world). But in all likelihood, there will be more than a handful of domain subscribers who take issue with that volume of people data sitting there in one corpus easily downloadable via a clear web hacking forum. For example, mine was just one of many tens of thousands of Pfizer email addresses, and that sort of thing is going to raise the ire of some folks in corporate infosec capacities.
One last comment: there was a story published earlier this year titled Our Investigation of the Pure Incubation Ventures Leak and in there they refer to "encrypted passwords" being present in the data. Many of the files do contain a column with bcrypt hashes (which is definitely not encryption), but given the way in which this data was collated, I can see no evidence whatsoever that these are password hashes. As such, I haven't listed "Passwords" as one of the compromised data classes in HIBP and you find yourself in this breach, I wouldn't be at all worried about this.

The conundrum I refer to in the title of this post is the one faced by a breached organisation: disclose or suppress? And let me be even more specific: should they disclose to impacted individuals, or simply never let them know? I'm writing this after many recent such discussions with breached organisations where I've found myself wishing I had this blog post to point them to, so, here it is.
Let's start with tackling what is often a fundamental misunderstanding about disclosure obligations, and that is the legal necessity to disclose. Now, as soon as we start talking about legal things, we run into the problem of it being different all over the world, so I'll pick a few examples to illustrate the point. As it relates to the UK GDPR, there are two essential concepts to understand, and they're the first two bulleted items in their personal data breaches guide:
The UK GDPR introduces a duty on all organisations to report certain personal data breaches to the relevant supervisory authority. You must do this within 72 hours of becoming aware of the breach, where feasible.
If the breach is likely to result in a high risk of adversely affecting individuals’ rights and freedoms, you must also inform those individuals without undue delay.
On the first point, "certain" data breaches must be reported to "the relevant supervisory authority" within 72 hours of learning about it. When we talk about disclosure, often (not just under GDPR), that term refers to the responsibility to report it to the regulator, not the individuals. And even then, read down a bit, and you'll see the carveout of the incident needing to expose personal data that is likely to present a "risk to people’s rights and freedoms".
This brings me to the second point that has this massive carveout as it relates to disclosing to the individuals, namely that the breach has to present "a high risk of adversely affecting individuals’ rights and freedoms". We have a similar carveout in Australia where the obligation to report to individuals is predicated on the likelihood of causing "serious harm".
This leaves us with the fact that in many data breach cases, organisations may decide they don't need to notify individuals whose personal information they've inadvertently disclosed. Let me give you an example from smack bang in the middle of GDPR territory: Deezer, the French streaming media service that went into HIBP early January last year:
New breach: Deezer had 229M unique email addresses breached from a 2019 backup and shared online in late 2022. Data included names, IPs, DoBs, genders and customer location. 49% were already in @haveibeenpwned. Read more: https://t.co/1ngqDNYf6k
— Have I Been Pwned (@haveibeenpwned) January 2, 2023
229M records is a substantial incident, and there's no argument about the personally identifiable nature of attributes such as email address, name, IP address, and date of birth. However, at least initially (more on that soon), Deezer chose not to disclose to impacted individuals:
Chatting to @Scott_Helme, he never received a breach notification from them. They disclosed publicly via an announcement in November, did they never actually email impacted individuals? Did *anyone* who got an HIBP email get a notification from Deezer? https://t.co/dnRw8tkgLl https://t.co/jKvmhVCwlM
— Troy Hunt (@troyhunt) January 2, 2023
No, nothing … but then I’ve not used Deezer for years .. I did get this👇from FireFox Monitor (provided by your good selves) pic.twitter.com/JSCxB1XBil
— Andy H (@WH_Y) January 2, 2023
Yes, same situation. I got the breach notification from HaveIBeenPwned, I emailed customer service to get an export of my data, got this message in response: pic.twitter.com/w4maPwX0Qe
— Giulio Montagner (@Giu1io) January 2, 2023
This situation understandably upset many people, with many cries of "but GDPR!" quickly following. And they did know way before I loaded it into HIBP too, almost two months earlier, in fact (courtesy of archive.org):
This information came to light November 8 2022 as a result of our ongoing efforts to ensure the security and integrity of our users’ personal information
They knew, yet they chose not to contact impacted people. And they're also confident that position didn't violate any data protection regulations (current version of the same page):
Deezer has not violated any data protection regulations
And based on the carveouts discussed earlier, I can see how they drew that conclusion. Was the disclosed data likely to lead to "a high risk of adversely affecting individuals’ rights and freedoms"? You can imagine lawyers arguing that it wouldn't. Regardless, people were pissed, and if you read through those respective Twitter threads, you'll get a good sense of the public reaction to their handling of the incident. HIBP sent 445k notifications to our own individual subscribers and another 39k to those monitoring domains with email addresses in the breach, and if I were to hazard a guess, that may have been what led to this:
Is this *finally* the @Deezer disclosure notice to individuals, a month and a half later? It doesn’t look like a new incident to me, anyone else get this? https://t.co/RrWlczItLm
— Troy Hunt (@troyhunt) February 20, 2023
So, they know about the breach in Nov, and they told people in Feb. It took them a quarter of a year to tell their customers they'd been breached, and if my understanding of their position and the regulations they were adhering to is correct, they never needed to send the notice at all.
I appreciate that's a very long-winded introduction to this post, but it sets the scene and illustrates the conundrum perfectly: an organisation may not need to disclose to individuals, but if they don't, they risk a backlash that may eventually force their hand.
In my past dealing with organisations that were reticent to disclose to their customers, their positions were often that the data was relatively benign. Email addresses, names, and some other identifiers of minimal consequence. It's often clear that the organisation is leaning towards the "uh, maybe we just don't say anything" angle, and if it's not already obvious, that's not a position I'd encourage. Let's go through all the reasons:
I ask this question because the defence I've often heard from organisations choosing the non-disclosure path is that the data is theirs - the company's. I have a fundamental issue with this, and it's not one with any legal basis (but I can imagine it being argued by lawyers in favour of that position), rather the commonsense position that someone's email address, for example, is theirs. If my email address appears in a data breach, then that's my email address and I entrusted the organisation in question to look after it. Whether there's a legal basis for the argument or not, the assertion that personally identifiable attributes become the property of another party will buy you absolutely no favours with the individual who provided them to you when you don't let them know you've leaked it.
Picking those terms from earlier on, if my gender, sexuality, ethnicity, and, in my case, even my entire medical history were to be made public, I would suffer no serious harm. You'd learn nothing of any consequence that you don't already know about me, and personally, I would not feel that I suffered as a result. However...
For some people, simply the association of their email address to their name may have a tangible impact on their life, and using the term from above jeopardises their rights and freedoms. Some people choose to keep their IRL identities completely detached from their email address, only providing the two together to a handful of trusted parties. If you're handling a data breach for your organisation, do you know if any of your impacted customers are in that boat? No, of course not; how could you?
Further, let's imagine there is nothing more than email addresses and passwords exposed on a cat forum. Is that likely to cause harm to people? Well, it's just cats; how bad could it be? Now, ask that question - how bad could it be? - with the prevalence of password reuse in mind. This isn't just a cat forum; it is a repository of credentials that will unlock social media, email, and financial services. Of course, it's not the fault of the breached service that people reuse their passwords, but their breach could lead to serious harm via the compromise of accounts on totally unrelated services.
Let's make it even more benign: what if it's just email addresses? Nothing else, just addresses and, of course, the association to the breached service. Firstly, the victims of that breach may not want their association with the service to be publicly known. Granted, there's a spectrum and weaponising someone's presence in Ashley Madison is a very different story from pointing out that they're a LinkedIn user. But conversely, the association is enormously useful phishing material; it helps scammers build a more convincing narrative when they can construct their messages by repeating accurate facts about their victim: "Hey, it's Acme Corp here, we know you're a loyal user, and we'd like to make you a special offer". You get the idea.
I'll start this one in the complete opposite direction to what it sounds like it should be because this is what I've previously heard from breached organisations:
We don't want to disclose in order to protect our customers
Uh, you sure about that? And yes, you did read that paraphrasing correctly. In fact, here's a copy paste from a recent discussion about disclosure where there was an argument against any public discussion of the incident:
Our concern is that your public notification would direct bad actors to search for the file, which can potentially do harm to both the business and our mutual users.
The fundamental issue of this clearly being an attempt to suppress news of the incident aside, in this particular case, the data was already on a popular clear web hacking forum, and the incident has appeared in multiple tweets viewed by thousands of people. The argument makes no sense whatsoever; the bad guys - lots of them - already have the data. And the good guys (the customers) don't know about it.
I'll quote precisely from another company who took a similar approach around non-disclosure:
[company name] is taking steps to notify regulators and data subjects where it is legally required to do so, based on advice from external legal counsel.
By now, I don't think I need to emphasise the caveat that they inevitably relied on to suppress the incident, but just to be clear: "where it is legally required to do so". I can say with a very high degree of confidence that they never notified the 8-figure number of customers exposed in this incident because they didn't have to. (I hear about it pretty quickly when disclosure notices are sent out, and I regularly share these via my X feed).
Non-disclosure is intended to protect the brand and by extension, the shareholders, not the customers.
Usually, after being sent a data breach, the first thing I do is search for "[company name] data breach". Often, the only results I get are for a listing on a popular hacking forum (again, on the clear web) where their data was made available for download, complete with a description of the incident. Often, that description is wrong (turns out hackers like to embellish their accomplishments). Incorrect conclusions are drawn and publicised, and they're the ones people find when searching for the incident.
When a company doesn't have a public position on a breach, the vacuum it creates is filled by others. Obviously, those with nefarious intent, but also by journalists, and many of those don't have the facts right either. Public disclosure allows the breached organisation to set the narrative, assuming they're forthcoming and transparent and don't water it down such that there's no substance in the disclosure, of course.
All the way back in 2017, I wrote about The 5 Stages of Data Breach Grief as I watched The AA in the UK dig themselves into an ever-deepening hole. They were doubling down on bullshit, and there was simply no way the truth wasn't going to come out. It was such a predictable pattern that, just like with Kübler-Ross' stages of personal grief, it was very clear how this was going to play out.
If you choose not to disclose a breach - for whatever reason - how long will it be until your "truth" comes out? Tomorrow? Next month? Years from now?! You'll be looking over your shoulder until it happens, and if it does one day go public, how will you be judged? Which brings me to the next point:
I can't put any precise measure on it, but I feel we reached a turning point in 2017. I even remember where I was when it dawned on me, sitting in a car on the way to the airport to testify before US Congress on the impact of data breaches. News had recently broken that Uber had attempted to cover up its breach of the year before by passing it off as a bug bounty and, of course, not notifying impacted customers. What dawned on me at that moment of reflection was that by now, there had been so many data breaches that we were judging organisations not by whether they'd been breached but how they'd handled the breach. Uber was getting raked over the coals not for the breach itself but because they tried to conceal it. (Their CTO was also later convicted of federal charges for some of the shenanigans pulled under his watch.)
This is going to feel like I'm talking to my kids after they've done something wrong, but here goes anyway: If people entrusted you with your data and you "lost" it (had it disclosed to unauthorised parties), the only decent thing to do is own up and acknowledge it. It doesn't matter if it was your organisation directly or, as with the Deezer situation, a third party you entrusted with the data; you are the coalface to your customers, and you're the one who is accountable for their data.
I am yet to see any valid reasons not to disclose that are in the best interests of the impacted customers (the delay in the AT&T breach announcement at the request of the FBI due to national security interests is the closest I can come to justifying non-disclosure). It's undoubtedly the customers' expectation, and increasingly, it's the governments' expectations too; I'll leave you with a quote from our previous Cyber Security Minister Clare O'Neil in a recent interview:
But the real people who feel pain here are Australians when their information that they gave in good faith to that company is breached in a cyber incident, and the focus is not on those customers from the very first moment. The people whose data has been stolen are the real victims here. And if you focus on them and put their interests first every single day, you will get good outcomes. Your customers and your clients will be respectful of it, and the Australian government will applaud you for it.
I'm presently on a whirlwind North America tour, visiting government and law enforcement agencies to understand more about their challenges and where we can assist with HIBP. As I spend more time with these agencies around the world, I keep hearing that data breach victim notification is an essential piece of the cybersecurity story, and I'm making damn sure to highlight the deficiencies I've written about here. We're going to keep pushing for all data breach victims to be notified when their data is exposed, and my hope in writing this is that when it's read in future by other organisations I've disclosed to, they respect their customers and disclose promptly. Check out Data breach disclosure 101: How to succeed after you've failed for guidance and how to do this.
Edit (a couple of days later): I'm adding an addendum to this post given how relevant it is. I just saw the following from Ruben van Well of the Dutch Police, someone who has invested a lot of effort in victim notification and we had the pleasure of spending time with last year in Rotterdam:
To translate the key section:
Reporting and transparency around incidents is important. Of the companies that fall victim, between 8 and 10% report this, whether or not out of fear of reputational damage. I assume that your image will be more damaged if you do not report an incident and it does come out later.
It echos my sentiments from above precisely, and I hope that message has an impact on anyone considering whether or not to disclose.
A great many readers this month reported receiving alerts that their Social Security Number, name, address and other personal information were exposed in a breach at a little-known but aptly-named consumer data broker called NationalPublicData.com. This post examines what we know about a breach that has exposed hundreds of millions of consumer records. We’ll also take a closer look at the data broker that got hacked — a background check company founded by an actor and retired sheriff’s deputy from Florida.
On July 21, 2024, denizens of the cybercrime community Breachforums released more than 4 terabytes of data they claimed was stolen from nationalpublicdata.com, a Florida-based company that collects data on consumers and processes background checks.
The breach tracking service HaveIBeenPwned.com and the cybercrime-focused Twitter account vx-underground both concluded the leak is the same information first put up for sale in April 2024 by a prolific cybercriminal who goes by the name “USDoD.”
On April 7, USDoD posted a sales thread on Breachforums for four terabytes of data — 2.9 billion rows of records — they claimed was taken from nationalpublicdata.com. The snippets of stolen data that USDoD offered as teasers showed rows of names, addresses, phone numbers, and Social Security Numbers (SSNs). Their asking price? $3.5 million.
Many media outlets mistakenly reported that the National Public data breach affects 2.9 billion people (that figure actually refers to the number of rows in the leaked data sets). HaveIBeenPwned.com’s Troy Hunt analyzed the leaked data and found it is a somewhat disparate collection of consumer and business records, including the real names, addresses, phone numbers and SSNs of millions of Americans (both living and deceased), and 70 million rows from a database of U.S. criminal records.
Hunt said he found 137 million unique email addresses in the leaked data, but stressed that there were no email addresses in the files containing SSN records.
“If you find yourself in this data breach via HaveIBeenPwned.com, there’s no evidence your SSN was leaked, and if you’re in the same boat as me, the data next to your record may not even be correct.”
Nationalpublicdata.com publicly acknowledged a breach in a statement on Aug. 12, saying “there appears to have been a data security incident that may have involved some of your personal information. The incident appears to have involved a third-party bad actor that was trying to hack into data in late December 2023, with potential leaks of certain data in April 2024 and summer 2024.”
The company said the information “suspected of being breached” contained name, email address, phone number, social security number, and mailing address(es).
“We cooperated with law enforcement and governmental investigators and conducted a review of the potentially affected records and will try to notify you if there are further significant developments applicable to you,” the statement continues. “We have also implemented additional security measures in efforts to prevent the reoccurrence of such a breach and to protect our systems.”
Hunt’s analysis didn’t say how many unique SSNs were included in the leaked data. But according to researchers at Atlas Data Privacy Corp., there are 272 million unique SSNs in the entire records set.
Atlas found most records have a name, SSN, and home address, and that approximately 26 percent of those records included a phone number. Atlas said they verified 5,000 addresses and phone numbers, and found the records pertain to people born before Jan. 1, 2002 (with very few exceptions).
If there is a tiny silver lining to the breach it is this: Atlas discovered that many of the records related to people who are now almost certainly deceased. They found the average age of the consumer in these records is 70, and fully two million records are related to people whose date of birth would make them more than 120 years old today.
Where did National Public Data get its consumer data? The company’s website doesn’t say, but it is operated by an entity in Coral Springs, Fla. called Jerico Pictures Inc. The website for Jerico Pictures is not currently responding. However, cached versions of it at archive.org show it is a film studio with offices in Los Angeles and South Florida.
The Florida Secretary of State says Jerico Pictures is owned by Salvatore (Sal) Verini Jr., a retired deputy with the Broward County Sheriff’s office. The Secretary of State also says Mr. Verini is or was a founder of several other Florida companies, including National Criminal Data LLC, Twisted History LLC, Shadowglade LLC and Trinity Entertainment Inc., among others.
Mr. Verini did not respond to multiple requests for comment. Cached copies of Mr. Verini’s vanity domain salvatoreverini.com recount his experience in acting (e.g. a role in a 1980s detective drama with Burt Reynolds) and more recently producing dramas and documentaries for several streaming channels.
Sal Verini’s profile page at imdb.com.
Pivoting on the email address used to register that vanity domain, DomainTools.com finds several other domains whose history offers a clearer picture of the types of data sources relied upon by National Public Data.
One of those domains is recordscheck.net (formerly recordscheck.info), which advertises “instant background checks, SSN traces, employees screening and more.” Another now-defunct business tied to Mr. Verini’s email — publicrecordsunlimited.com — said it obtained consumer data from a variety of sources, including: birth, marriage and death records; voting records; professional licenses; state and federal criminal records.
The homepage for publicrecordsunlimited.com, per archive.org circa 2017.
It remains unclear how thieves originally obtained these records from National Public Data. KrebsOnSecurity sought comment from USDoD, who is perhaps best known for hacking into Infragard, an FBI program that facilitates information sharing about cyber and physical threats with vetted people in the private sector.
USDoD said they indeed sold the same data set that was leaked on Breachforums this past month, but that the person who leaked the data did not obtain it from them. USDoD said the data stolen from National Public Data had traded hands several times since it was initially stolen in December 2023.
“The database has been floating around for a while,” USDoD said. “I was not the first one to get it.”
USDoD said the person who originally stole the data from NPD was a hacker who goes by the handle SXUL. That user appears to have deleted their Telegram account several days ago, presumably in response to intense media coverage of the breach.
Data brokers like National Public Data typically get their information by scouring federal, state and local government records. Those government files include voting registries, property filings, marriage certificates, motor vehicle records, criminal records, court documents, death records, professional licenses, bankruptcy filings, and more.
Americans may believe they have the right to opt out of having these records collected and sold to anyone. But experts say these underlying sources of information — the above-mentioned “public” records — are carved out from every single state consumer privacy law. This includes California’s privacy regime, which is often held up as the national leader in state privacy regulations.
You see, here in America, virtually anyone can become a consumer data broker. And with few exceptions, there aren’t any special requirements for brokers to show that they actually care about protecting the data they collect, store, repackage and sell so freely.
In February 2023, PeopleConnect, the owners of the background search services TruthFinder and Instant Checkmate, acknowledged a breach affecting 20 million customers who paid the data brokers to run background checks. The data exposed included email addresses, hashed passwords, first and last names, and phone numbers.
In 2019, malicious hackers stole data on more than 1.5 billion people from People Data Labs, a San Francisco data broker whose people-search services linked hundreds of millions of email addresses, LinkedIn and Facebook profiles and more than 200 million valid cell phone numbers.
These data brokers are the digital equivalent of massive oil tankers wandering the coast without GPS or an anchor, because when they get hacked, the effect is very much akin to the ecological and economic fallout from a giant oil spill.
It’s an apt analogy because the dissemination of so much personal data all at once has ripple effects for months and years to come, as this information invariably feeds into a vast underground ocean of scammers who are already equipped and staffed to commit identity theft and account takeovers at scale.
It’s also apt because much like with real-life oil spills, the cleanup costs and effort from data spills — even just vast collections of technically “public” documents like the NPD corpus — can be enormous, and most of the costs associated with that fall to consumers, directly or indirectly.
Should you worry that your SSN and other personal data might be exposed in this breach? That isn’t necessary for people who’ve been following the advice here for years, which is to freeze one’s credit file at each of the major consumer reporting bureaus. Having a freeze on your files makes it much harder for identity thieves to create new accounts in your name, and it limits who can view your credit information.
The main reason I recommend the freeze is that all of the information ID thieves need to assume your identity is now broadly available from multiple sources, thanks to the multiplicity of data breaches we’ve seen involving SSN data and other key static data points about people.
But beyond that, there are numerous cybercriminal services that offer detailed background checks on consumers, including full SSNs. These services are powered by compromised accounts at data brokers that cater to private investigators and law enforcement officials, and some are now fully automated via Telegram instant message bots. Meaning, if you’re an American who hasn’t frozen their credit files and you haven’t yet experienced some form of new account fraud, the ID thieves probably just haven’t gotten around to you yet.
All Americans are also entitled to obtain a free copy of their credit report weekly from each of the three major credit bureaus. It used to be that consumers were allowed one free report from each of the bureaus annually, but in October 2023 the Federal Trade Commission announced the bureaus had permanently extended a program that lets you check your credit report once a week for free.
If you haven’t done this in a while, now would be an excellent time to order your files. To place a freeze, you need to create an account at each of the three major reporting bureaus, Equifax, Experian and TransUnion. Once you’ve established an account, you should be able to then view and freeze your credit file. Dispute any inaccuracies you may find. If you spot errors, such as random addresses and phone numbers you don’t recognize, do not ignore them: Identity theft and new account fraud are not problems that get easier to solve by letting them fester.
Mr. Verini probably didn’t respond to requests for comment because his company is now the subject of a class-action lawsuit (NB: the lawsuit also erroneously claims 3 billion people were affected). These lawsuits are practically inevitable now after a major breach, but they also have the unfortunate tendency to let regulators and lawmakers off the hook.
Almost every time there’s a major breach of SSN data, Americans are offered credit monitoring services. Most of the time, those services come from one of the three major consumer credit bureaus, the same companies that profit by compiling and selling incredibly detailed dossiers on consumers’ financial lives. The same companies that use dark patterns to trick people into paying for “credit lock” services that achieve a similar result as a freeze but still let the bureaus sell your data to their partners.
But class-actions alone will not drive us toward a national conversation about what needs to change. Americans currently have very few rights to opt out of the personal and financial surveillance, data collection and sale that is pervasive in today’s tech-based economy.
The breach at National Public Data may not be the worst data breach ever. But it does present yet another opportunity for this country’s leaders to acknowledge that the SSN has completely failed as a measure of authentication or authorization. It was never a good idea to use as an authenticator to begin with, and it is certainly no longer suitable for this purpose.
The truth is that these data brokers will continue to proliferate and thrive (and get hacked and relieved of their data) until Congress begins to realize it’s time for some consumer privacy and data protection laws that are relevant to life in the 21st century.
Further reporting: National Public Data Published Its Own Passwords
Update, Aug. 16, 8:00 a.m. ET: Corrected the story to note that consumers can now obtain a free credit report from each of the three consumer reporting bureaus weekly, instead of just annually.
Update, Aug. 23, 12:33 p.m. ET: Added link to latest story on NPD breach.

TL;DR — Tens of millions of credentials obtained from info stealer logs populated by malware were posted to Telegram channels last month and used to shake down companies for bug bounties under the misrepresentation the data originated from their service.
How many attempted scams do you get each day? I woke up to yet another "redeem your points" SMS this morning, I'll probably receive a phone call from "my bank" today (edit: I was close, it was "Amazon Prime" 🤷♂️) and don't even get me started on my inbox. We're bombarded to the point of desensitisation, which itself is dangerous because it creates the risk of inadvertently dismissing something that really does require your attention. Which brings me to the email Scott Helme from Report URI (disclosure: a service I've long partnered with and advised) received yesterday titled "Bug bounty Program - PII leak Credentials more than 170". It began as follows:
Through open-source intelligence gathering, I discovered a significant amount of "report-uri.com" user credentials and sensitive documents have been leaked and are publicly accessible.
The sender then attached a text file with 197 lines of email addresses and passwords belonging to users of Scott's pride and joy. The first lines looked like this (url:email:password):

Imagine the heart-in-mouth moment he had when first seeing that; had someone compromised his service? Was this the data of his customers who had entrusted it to him and it was now floating around the internet? Isn't he the guy who's meant to be teaching others about application security?! The email went on:
The impact of this vulnerability is severe, potentially resulting in:
Mass account takeovers by malicious actors.
Exposure of sensitive user data including names, emails, addresses, and documents.
Unauthorized transactions or malicious activities using compromised accounts.
Further compromise of organizational infrastructure through account abuse.
Financial and reputational damage due to security breaches.
Just to avoid any semblance of doubt as to the motive of the sender, the subject began by flagging the desire for a bug bounty (Report URI does not advertise a bounty program, but clearly a reward was being sought), followed by an email body stating it related to leaked Report URI credentials and then highlighted that "this vulnerability is severe". And then there's that last line about financial and reputation damage. It looked bad. However, cooler heads prevailed, and we started looking closer at the email addresses in the "breach" by checking them against Have I Been Pwned. Very quickly, a pattern emerged:
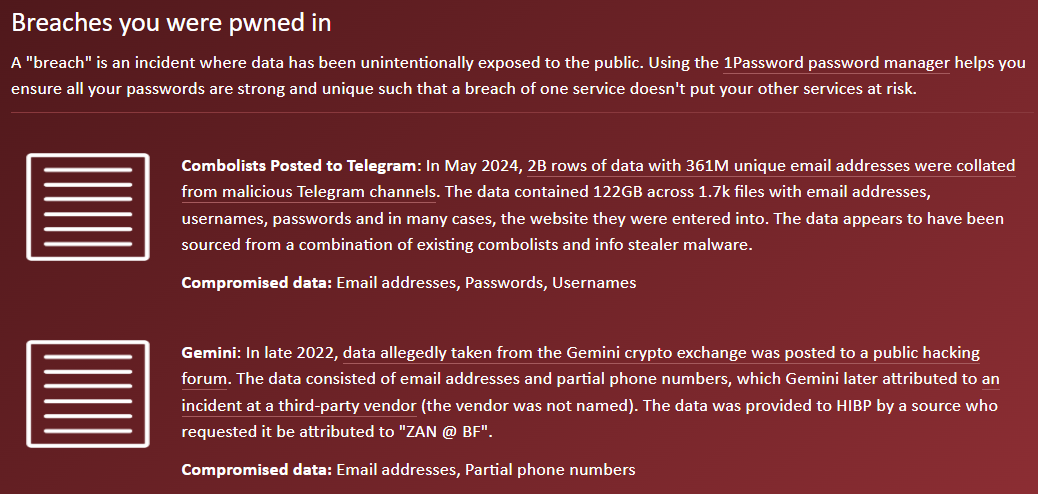
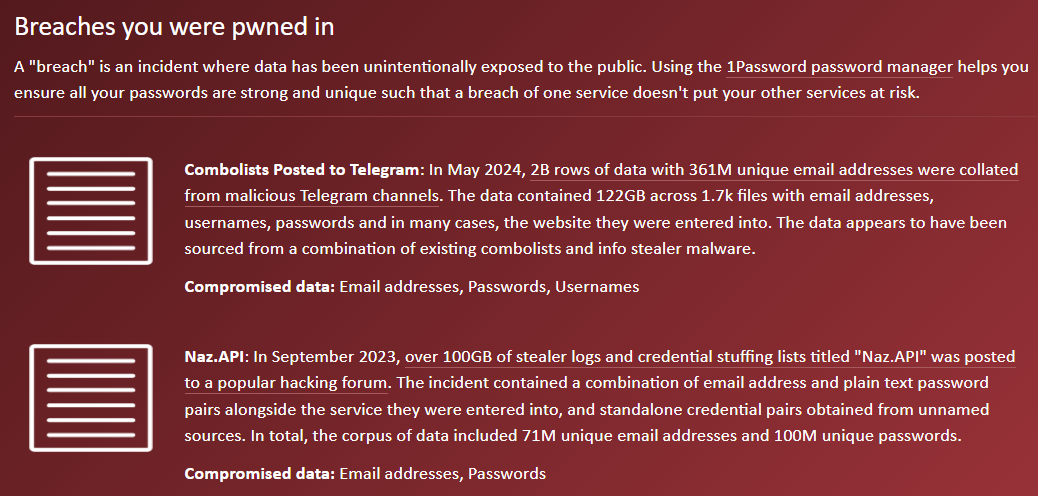
Most of the addresses we checked had appeared in the lists posted to Telegram I'd loaded into HIBP a couple of months ago. These were stealer logs, not a breach of Report URI! To validate that assertion, I pulled the original data source and parsed out every line containing "report-uri.com". Sure enough, the lines from the file sent to Scott were usually contained in the stealer log files. So, let's talk about how this works:
Take the URL you saw at the beginning of each line earlier on, the one being for the registration page. Here's what it looks like:
Now, imagine you're filling out this form and your machine is infected with malware that can observe the data entered into each field. It takes that data, "steals" it and logs it at the attacker's server, hence the term "info stealer logs". There is absolutely nothing Scott can do to prevent this; the user's machine is compromised, not Report URI.
To illustrate the point, I grabbed the first email address in the file Scott was sent and pulled the rows just for that address rather than solely the Report URI rows. This would show us all the other services this person's credentials were snared from, and there were dozens. Here are just the first ten:
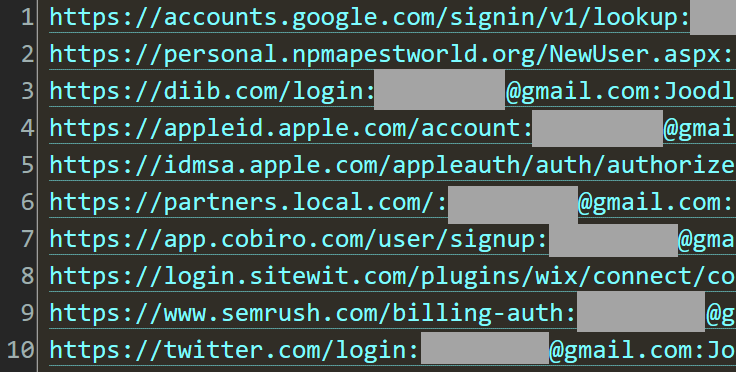
Google. Apple. Twitter. Most with the same password too, because a normal person obviously owns this email address. So, has each of these organisations also received a beg bounty? No, that's not a typo, this is classic behaviour where unsophisticated and self-proclaimed "security researchers" use automated tooling to identify largely benign security configurations that could be construed as vulnerabilities. For example, they'll send through a report that an SPF record is too permissive (they probably can't even spell "SPF", let alone understand the nuances of sender policies), then try to shake people like Scott down for money under the guise of a "bug bounty". This isn't Scott's problem, nor is it Google's or Apple's or Twitter's, it's something only the malware infected victim's can address.
In this post, I referred to "most" of the addresses already being in HIBP and the lines from the file he was sent "usually" occurring in the logs I had. But there were gaps. For example, whilst there were 197 rows in "his" file, I only found 161 in the data I'd previously loaded. But I had a hunch on how to fill that gap and make up the difference...
Two weeks ago, I was sent a further 22GB of stealer logs found in Telegram channels. Unlike the previous corpus of data, this set contained only stealer logs (no credential stuffing lists) and had a total of 26,105,473 unique email addresses. That's significant, as it implies that every single one of those addresses belongs to someone infected with malware that's stealing their creds. Of the total count, 89.7% had been seen in previous data breaches already in HIBP which is a high crossover, but it also meant that 2,679,550 addresses were all new. I'd been considering whether or not it made sense to load this data given corpuses such as this create frustration when people don't know which site their record was snared from nor which password was impacted. One particular frustration you'll read in comments on the previous post was that people weren't sure whether their email address was in a stealer log or a credential stuffing list; did they have a machine infected with malware or was it merely recycled credentials from an old data breach? But given the way in which this new corpus of data is being used (to attempt to scam Scott and, one would assume, many others), the 7-figure number of previously unseen addresses and the fact that this time, they can all emphatically be tied back to malware campaigns, this is now searchable in HIBP as "Stealer Logs Posted to Telegram".
Ultimately, this is just scam on top of scam: the victims in the logs have had their credentials scammed, and the person who emailed Scott attempted to use that to scam him out of a bounty. Making data like this searchable in HIBP helps people do exactly what I did as soon as Scott forwarded me over the email: validate the origin and as Scott will now do, send a terse reply encouraging the guy to show some decency and stop with the beg bounties.
Lastly, I'm increasingly conscious of how useful the information contained in stealer logs is to organisations like Report URI, and after loading that previous corpus posted from Telegram, I did help out a few companies who thought they might have been hit by it. The position they were coming from was "we keep seeing account takeovers by what looks like credential stuffing attacks, but the attackers are getting the credentials right on the first go". When I pulled the data for their domain as I later did for Report URI, the email addresses were precisely the ones being targeted for account takeover. I want to address this via HIBP, but it's non-trivial for a variety of reasons, especially those related to privacy. In order for this data to be useful to companies like Report URI, I'd need to give them other people's email addresses (the password wouldn't be necessary) based on the assumption they were customers of the service. I'm working out how to do this in way that makes sense for everyone (well, everyone except for the bad guys), stay tuned for more and please do chime in via the comments if you have ideas on how to turn this into a useful service.

Last week, a security researcher sent me 122GB of data scraped out of thousands of Telegram channels. It contained 1.7k files with 2B lines and 361M unique email addresses of which 151M had never been seen in HIBP before. Alongside those addresses were passwords and, in many cases, the website the data pertains to. I've loaded it into Have I Been Pwned (HIBP) today because there's a huge amount of previously unseen email addresses and based on all the checks I've done, it's legitimate data. That's the high-level overview, now here are the details:
Telegram is a popular messaging platform that makes it easy to stand up a "channel" and share information to those who wish to visit it. As Telegram describes the service, it's simple, private and secure and as such, has become very popular with those wishing to share content anonymously, including content related to data breaches. Many of the breaches I've previously loaded into HIBP have been distributed via Telegram as it's simple to publish this class of data to the platform. Here's what data posted to Telegram often looks like:

These are referred to as "combolists", that is they're combinations of email addresses or usernames and passwords. The combination of these is obviously what's used to authenticate to various services, and we often see attackers using these to mount "credential stuffing" attacks where they use the lists to attempt to access accounts en mass. The list above is simply breaking the combos into their respective email service providers. For example, that last Gmail example contains over a quarter of a million rows like this:
That's only one of many files across many different Telegram channels. The data that was sent to me last week was sourced from 518 different channels and amounted to 1,748 separate files similar to the one above. Some of the files have literally no data (0kb), others are many gigabytes with many tens of millions of rows. For example, the largest file starts like this:
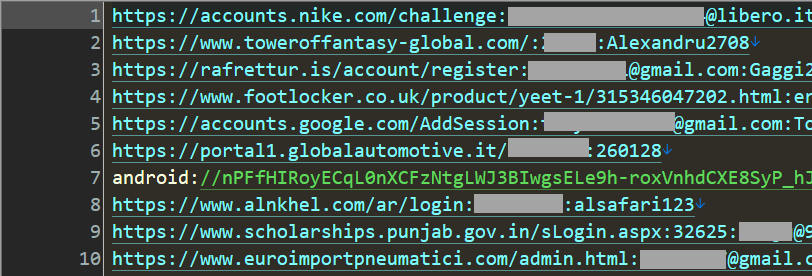
That looks very much like the result of info stealer malware that has obtained credentials as they were entered into websites on compromised machines. For example, the first record appears to have been snared when someone attempted to login to Nike. There's an easy way to get a sense of the accuracy of this data, just head over to the Nike homepage and click the login link which presents the following screen:
They serve the same page to both existing subscribers and new ones but then serve different pages depending on whether the email address already has an account (a classic enumeration vector). Mash the keyboard to create a fake email address and you'll be shown a registration form, but enter the address in the stealer log and, well, you get something different:
The email address has an account, hence the prompt for a password. I'm not going to test the password because that would constitute unauthorised access, but I also don't need to as the goal has already been achieved: I've demonstrated that the address has an account on Nike. (Also note that if the password didn't work it wouldn't necessarily mean it wasn't valid at some point in time at the past, it would simply mean it isn't valid now.)
Footlocker tries to be a bit more clever in avoiding enumeration on password reset, but they'll happily tell you via the registration page if the email address you've entered already exists:
Even the Italian tyre retailer happily confirmed the existence of the tested account:

Time and time again, each service I tested confirmed the presence of the email address in the stealer log. But are (or were) the passwords correct? Again, I'm not going to test those myself, but I have nearly 5M subscribers in HIBP and there's always a handful of them in any new breach that are happy to help out. So, I emailed some of the most recent ones, asked if they could help with verification and upon confirmation, sent them their data.
In reaching out to existing subscribers, I expected some repetition in terms of them already appearing in existing data breaches. For one person already in 13 different breaches in HIBP, this was their response:
Thanks Troy. These details were leaked in previous data breaches.
So accurate, but not new, and several of the breaches for this one were of a similar structure to the one we're talking about today in terms of them being combolists used for credential stuffing attacks. Same with another subscriber who was in 7 prior breaches:
Yes that’s familiar. Most likely would have used those credentials on the previous data breaches.
That one was more interesting as of the 7 prior breaches, only 6 had passwords exposed and none of them were combolists. Instead, it was incidents including MyFitnessPal, 8fit, FlexBooker, Jefit, MyHeritage and ShopBack; have passwords been cracked out of those (most were hashed) and used to create new lists? Very possibly. (Sidenote: this unfortunate person is obviously a bit of a fitness buff and has managed to end up in 3 different "fit" breaches.)
Another subscriber had an entry in the following format, similar to what we saw earlier on in the stealer log:
https://accounts.epicgames.com/login:[email]:[password]They responded to my queries with the following:
I think that epic games account was for my daughter a couple of years ago but I cancelled it last year from memory. That sds like a password she may have chosen so I'll check with her in an hour or two when I see her again.
And then, a little bit later
My daughter doesn't remember if that was her password as it was 4-5 years ago when she was only 8-9 years old. However it does sound like something she would have chosen so in all probability, I would say that is a legitimate link. We believe it was used when she played a game called Fortnite which she did infrequently at that time hence her memory is sketchy.
I realised that whilst each of these responses confirmed the legitimacy of the data, they really weren't giving me much insight into the factor that made it worth loading into HIBP: the unseen addresses. So, I went through the same process of contacting HIBP subscribers again but this time, only the ones that I'd never seen in a breach before. This would then rule out all the repurposed prior incidents and give me a much better idea of how impactful this data really was. And that's when things got really interesting.
Let's start with the most interesting one and what you're about to see is two hundred rows of stealer logs:
https://steuer.check24.de/customer-center/aff/check24/authentication:[email]:[password]
https://www.disneyplus.com/de-de/reset-password:[email]:[password]
https://auth.rtl.de/auth/realms/rtlplus/protocol/openid-connect/auth:[email]:[password]
https://www.tink.de/checkout/login:[email]:[password]
https://signin.ebay.de/ws/eBayISAPI.dll:[email]:[password]
https://vrr-db-ticketshop.de/authentication/login:[email]:[password]
https://www.planet-sports.de/checkout/register:[email]:[password]
https://www.bstn.com/eu_de/checkout/:[email]:[password]
https://www.lico-nature.de/index.php:[email]:[password]
https://ticketshop.mobil.nrw/authentication/register:[email]:[password]
https://softwareindustrie24.de/checkout/confirm/as/customer:[email]:[password]
https://www.zurbrueggen.de/checkout/register:[email]:[password]
https://www.hertz247.de/ikeage/de-de/SignUp/Profile:[email]:[password]
https://www.bluemovement.com/de-de/checkout2:[email]:[password]
android://pfDvxsQIIXYFer6DxBcqXjgyr9X3z0_f4GlJfpZMErP2oGHX74fUnXpWA29CNgnCyZ_phC8IyV0exIV6hg3iyQ==@com.sixt.reservation/:[email]:[password]
https://members.persil-service.de/login/:[email]:[password]
https://www.nicotel.de/index.php:[email]:[password]
https://www.hellofresh.de/login:[email]:[password]
https://login.live.com/login.srf:[email]:[password]
https://accounts.login.idm.telekom.com/factorx:[email]:[password]
https://grillhaus-bei-reimann.order.dish.co/register:[email]:[password]
https://signup.sipgateteam.de/:[email]:[password]
https://www.baur.de/kasse/registrieren:[email]:[password]
https://buchung.carlundcarla.de/28572879/schritt-3:[email]:[password]
https://www.qvc.de/checkout/your-information.html:[email]:[password]
https://de.omio.com/app/search-frontend/booking/96720342-e20e-4de7-8b21-ddefc0fa44bd/passenger-details:[email]:[password]
https://www.shop-apotheke.com/nx/login/:[email]:[password]
https://druckmittel.de/checkout/confirm:[email]:[password]
https://www.global-carpet.de/checkout/confirm:[email]:[password]
https://software-hero.de/checkout/confirm:[email]:[password]
https://myenergykey.com/login:[email]:[password]
https://www.sixt.de/:[email]:[password]
https://www.wlan-shop24.de/Bestellvorgang:[email]:[password]
https://www.cyberport.de/checkout/anmelden.html:[email]:[password]
https://waschmal.de/registerCustomer:[email]:[password]
https://www.wgv.de/app/moped201802/rechner/abschluss/moped:[email]:[password]
https://www.persil-service.de/signup:[email]:[password]
https://nicotel.de/:[email]:[password]
https://temial.vorwerk.de/register/checkout:[email]:[password]
https://accounts.bahn.de/auth/realms/db/login-actions/required-action:[email]:[password].
https://www.petsdeli.de/login:[email]:[password]
https://www.netflix.com/de/login:[email]:[password]
https://login.live.com/login.srf:[email]:[password]
https://accounts.login.idm.telekom.com/factorx:[email]:[password]
https://www.netflix.com/de/login:[email]:[password]
https://www.zoll-portal.de/registrierung/benutzerkonto/daten:[email]:[password]
https://v3.account.samsung.com/iam/passwords/register:[email]:[password]
https://www.amazon.pl/ap/signin:[email]:[password]
https://www.amazon.de/:[email]:[password]
https://meinkonto.telekom-dienste.de/wiederherstellung/passwort/web-pw-setzen.xhtml:[email]:[password]
https://www.netflix.com/de/login:[email]:[password]
https://steuer.check24.de/customer-center/aff/check24/authentication [email]:[password]
https://www.disneyplus.com/de-de/reset-password [email]:[password]
https://auth.rtl.de/auth/realms/rtlplus/protocol/openid-connect/auth [email]:[password]
https://www.tink.de/checkout/login [email]:[password]
https://signin.ebay.de/ws/eBayISAPI.dll [email]:[password]
https://vrr-db-ticketshop.de/authentication/login [email]:[password]
https://www.planet-sports.de/checkout/register [email]:[password]
https://www.bstn.com/eu_de/checkout/ [email]:[password]
https://www.lico-nature.de/index.php [email]:[password]
https://ticketshop.mobil.nrw/authentication/register [email]:[password]
https://softwareindustrie24.de/checkout/confirm/as/customer [email]:[password]
https://www.zurbrueggen.de/checkout/register [email]:[password]
https://www.hertz247.de/ikeage/de-de/SignUp/Profile [email]:[password]
https://www.bluemovement.com/de-de/checkout2 [email]:[password]
android://pfDvxsQIIXYFer6DxBcqXjgyr9X3z0_f4GlJfpZMErP2oGHX74fUnXpWA29CNgnCyZ_phC8IyV0exIV6hg3iyQ==@com.sixt.reservation/[email]:[password]
https://members.persil-service.de/login/ [email]:[password]
https://www.nicotel.de/index.php [email]:[password]
https://www.hellofresh.de/login [email]:[password]
https://login.live.com/login.srf [email]:[password]
https://accounts.login.idm.telekom.com/factorx [email]:[password]
https://grillhaus-bei-reimann.order.dish.co/register [email]:[password]
https://signup.sipgateteam.de/ [email]:[password]
https://www.baur.de/kasse/registrieren [email]:[password]
https://buchung.carlundcarla.de/28572879/schritt-3 [email]:[password]
https://www.qvc.de/checkout/your-information.html [email]:[password]
https://de.omio.com/app/search-frontend/booking/96720342-e20e-4de7-8b21-ddefc0fa44bd/passenger-details [email]:[password]
https://www.shop-apotheke.com/nx/login/ [email]:[password]
https://druckmittel.de/checkout/confirm [email]:[password]
https://www.global-carpet.de/checkout/confirm [email]:[password]
https://software-hero.de/checkout/confirm [email]:[password]
https://myenergykey.com/login [email]:[password]
https://www.sixt.de/ [email]:[password]
https://www.wlan-shop24.de/Bestellvorgang [email]:[password]
https://www.cyberport.de/checkout/anmelden.html [email]:[password]
https://waschmal.de/registerCustomer [email]:[password]
https://www.wgv.de/app/moped201802/rechner/abschluss/moped [email]:[password]
https://www.persil-service.de/signup [email]:[password]
https://nicotel.de/ [email]:[password]
https://temial.vorwerk.de/register/checkout [email]:[password]
https://accounts.bahn.de/auth/realms/db/login-actions/required-action [email]:[password].
https://www.petsdeli.de/login [email]:[password]
https://www.netflix.com/de/login [email]:[password]
https://login.live.com/login.srf [email]:[password]
https://accounts.login.idm.telekom.com/factorx [email]:[password]
https://www.netflix.com/de/login [email]:[password]
https://www.zoll-portal.de/registrierung/benutzerkonto/daten [email]:[password]
https://v3.account.samsung.com/iam/passwords/register [email]:[password]
https://www.amazon.pl/ap/signin [email]:[password]
https://www.amazon.de/ [email]:[password]
https://meinkonto.telekom-dienste.de/wiederherstellung/passwort/web-pw-setzen.xhtml [email]:[password]
https://www.netflix.com/de/login [email]:[password]
https://steuer.check24.de/customer-center/aff/check24/authentication:[email]:[password]
https://www.disneyplus.com/de-de/reset-password:[email]:[password]
https://auth.rtl.de/auth/realms/rtlplus/protocol/openid-connect/auth:[email]:[password]
https://www.tink.de/checkout/login:[email]:[password]
https://signin.ebay.de/ws/eBayISAPI.dll:[email]:[password]
https://vrr-db-ticketshop.de/authentication/login:[email]:[password]
https://www.planet-sports.de/checkout/register:[email]:[password]
https://www.bstn.com/eu_de/checkout/:[email]:[password]
https://www.lico-nature.de/index.php:[email]:[password]
https://ticketshop.mobil.nrw/authentication/register:[email]:[password]
https://softwareindustrie24.de/checkout/confirm/as/customer:[email]:[password]
https://www.zurbrueggen.de/checkout/register:[email]:[password]
https://www.hertz247.de/ikeage/de-de/SignUp/Profile:[email]:[password]
https://www.bluemovement.com/de-de/checkout2:[email]:[password]
android://pfDvxsQIIXYFer6DxBcqXjgyr9X3z0_f4GlJfpZMErP2oGHX74fUnXpWA29CNgnCyZ_phC8IyV0exIV6hg3iyQ==@com.sixt.reservation/:[email]:[password]
https://members.persil-service.de/login/:[email]:[password]
https://www.nicotel.de/index.php:[email]:[password]
https://www.hellofresh.de/login:[email]:[password]
https://login.live.com/login.srf:[email]:[password]
https://accounts.login.idm.telekom.com/factorx:[email]:[password]
https://grillhaus-bei-reimann.order.dish.co/register:[email]:[password]
https://signup.sipgateteam.de/:[email]:[password]
https://www.baur.de/kasse/registrieren:[email]:[password]
https://buchung.carlundcarla.de/28572879/schritt-3:[email]:[password]
https://www.qvc.de/checkout/your-information.html:[email]:[password]
https://de.omio.com/app/search-frontend/booking/96720342-e20e-4de7-8b21-ddefc0fa44bd/passenger-details:[email]:[password]
https://www.shop-apotheke.com/nx/login/:[email]:[password]
https://druckmittel.de/checkout/confirm:[email]:[password]
https://www.global-carpet.de/checkout/confirm:[email]:[password]
https://software-hero.de/checkout/confirm:[email]:[password]
https://myenergykey.com/login:[email]:[password]
https://www.sixt.de/:[email]:[password]
https://www.wlan-shop24.de/Bestellvorgang:[email]:[password]
https://www.cyberport.de/checkout/anmelden.html:[email]:[password]
https://waschmal.de/registerCustomer:[email]:[password]
https://www.wgv.de/app/moped201802/rechner/abschluss/moped:[email]:[password]
https://www.persil-service.de/signup:[email]:[password]
https://nicotel.de/:[email]:[password]
https://temial.vorwerk.de/register/checkout:[email]:[password]
https://accounts.bahn.de/auth/realms/db/login-actions/required-action:[email]:[password].
https://www.petsdeli.de/login:[email]:[password]
https://www.netflix.com/de/login:[email]:[password]
https://login.live.com/login.srf:[email]:[password]
https://accounts.login.idm.telekom.com/factorx:[email]:[password]
https://www.netflix.com/de/login:[email]:[password]
https://www.zoll-portal.de/registrierung/benutzerkonto/daten:[email]:[password]
https://v3.account.samsung.com/iam/passwords/register:[email]:[password]
https://www.amazon.pl/ap/signin:[email]:[password]
https://www.amazon.de/:[email]:[password]
https://meinkonto.telekom-dienste.de/wiederherstellung/passwort/web-pw-setzen.xhtml:[email]:[password]
steuer.check24.de/customer-center/aff/check24/authentication:[email]:[password]
www.disneyplus.com/de-de/reset-password:[email]:[password]
auth.rtl.de/auth/realms/rtlplus/protocol/openid-connect/auth:[email]:[password]
www.tink.de/checkout/login:[email]:[password]
signin.ebay.de/ws/eBayISAPI.dll:[email]:[password]
vrr-db-ticketshop.de/authentication/login:[email]:[password]
www.planet-sports.de/checkout/register:[email]:[password]
www.bstn.com/eu_de/checkout/:[email]:[password]
www.lico-nature.de/index.php:[email]:[password]
ticketshop.mobil.nrw/authentication/register:[email]:[password]
softwareindustrie24.de/checkout/confirm/as/customer:[email]:[password]
www.zurbrueggen.de/checkout/register:[email]:[password]
www.hertz247.de/ikeage/de-de/SignUp/Profile:[email]:[password]
www.bluemovement.com/de-de/checkout2:[email]:[password]
members.persil-service.de/login/:[email]:[password]
www.nicotel.de/index.php:[email]:[password]
www.hellofresh.de/login:[email]:[password]
login.live.com/login.srf:[email]:[password]
accounts.login.idm.telekom.com/factorx:[email]:[password]
grillhaus-bei-reimann.order.dish.co/register:[email]:[password]
signup.sipgateteam.de/:[email]:[password]
www.baur.de/kasse/registrieren:[email]:[password]
buchung.carlundcarla.de/28572879/schritt-3:[email]:[password]
www.qvc.de/checkout/your-information.html:[email]:[password]
de.omio.com/app/search-frontend/booking/96720342-e20e-4de7-8b21-ddefc0fa44bd/passenger-details:[email]:[password]
www.shop-apotheke.com/nx/login/:[email]:[password]
druckmittel.de/checkout/confirm:[email]:[password]
www.global-carpet.de/checkout/confirm:[email]:[password]
software-hero.de/checkout/confirm:[email]:[password]
myenergykey.com/login:[email]:[password]
www.sixt.de/:[email]:[password]
www.wlan-shop24.de/Bestellvorgang:[email]:[password]
www.cyberport.de/checkout/anmelden.html:[email]:[password]
waschmal.de/registerCustomer:[email]:[password]
www.wgv.de/app/moped201802/rechner/abschluss/moped:[email]:[password]
www.persil-service.de/signup:[email]:[password]
nicotel.de/:[email]:[password]
temial.vorwerk.de/register/checkout:[email]:[password]
accounts.bahn.de/auth/realms/db/login-actions/required-action:[email]:[password].
www.petsdeli.de/login:[email]:[password]
login.live.com/login.srf:[email]:[password]
accounts.login.idm.telekom.com/factorx:[email]:[password]
www.netflix.com/de/login:[email]:[password]
www.zoll-portal.de/registrierung/benutzerkonto/daten:[email]:[password]
v3.account.samsung.com/iam/passwords/register:[email]:[password]
www.amazon.pl/ap/signin:[email]:[password]
www.amazon.de/:[email]:[password]
meinkonto.telekom-dienste.de/wiederherstellung/passwort/web-pw-setzen.xhtml:[email]:[password]
Even without seeing the email address and password, the commonality is clear: German websites. Whilst the email address is common, the passwords are not... at least not always. In 168 instances they were near identical with only a handful of them deviating by a character or two. There's some duplication across the lines (9 different rows of Netflix, 4 of Disney Plus, etc), but clearly this remains a significant volume of data. But is it real? Let's find out:
The data seems accurate so far. I have already changed some of the passwords as I was notified by the provider that my account was hacked. It is strange that the Telekom password was already generated and should not be guessable. I store my passwords in Firefox, so is it possible that they were stolen from there?
It's legit. Stealer malware explains both the Telekom password and why passwords in Firefox were obtained; there's not necessarily anything wrong with either service, but if a machine is infected with software that can grab passwords straight out of the fields they've been entered into in the browser, it's game over.
We started having some to-and-fro as I gathered more info, especially as it related to the timeframe:
It started about a month ago, maximum 6 weeks. I use a Macbook and an iPhone, only a Windows PC at work, maybe it happened there? About a week ago there was an extreme spam attack on my Gmail account, and several expensive items were ordered with my accounts in the same period, which fortunately could be canceled.
We had the usual discussion about password managers and of course before that, tracking down which device is infected and siphoning off secrets. This was obviously distressing for her to see all her accounts laid out like this, not to mention learning that they were being exchanged in channels frequented by criminals. But from the perspective of verifying both the legitimacy and uniqueness of the data (not to mention the freshness), this was an enormously valuable exchange.
Next up was another subscriber who'd previously dodged all the data breaches in HIBP yet somehow managed to end up with 53 rows of data in the corpus:
[email]:Gru[redacted password]
[email]:fux[redacted password]
[email]:zWi[redacted password]
[email]:6ii[redacted password]
[email]:qTM[redacted password]
[email]:Pre[redacted password]
[email]:i8$[redacted password]
[email]:9cr[redacted password]
[email]:fuc[redacted password]
[email]:kuM[redacted password]
[email]:Fuc[redacted password]
[email]:Pre[redacted password]
[email]:Vxt[redacted password]
[email]:%3r[redacted password]
[email]:But[redacted password]
[email]:1qH[redacted password]
[email]:^VS[redacted password]
[email]:But[redacted password]
[email]:Nbs[redacted password]
[email]:*W2[redacted password]
[email]:$aM[redacted password]
[email]:DA^[redacted password]
[email]:vPE[redacted password]
[email]:Z8u[redacted password]
[email]:But[redacted password]
[email]:aXi[redacted password]
[email]:rPe[redacted password]
[email]:b4F[redacted password]
[email]:2u&[redacted password]
[email]:5%f[redacted password]
[email]:Lmt[redacted password]
[email]:p
[email]:Tem[redacted password]
[email]:fuc[redacted password]
[email]:*e@[redacted password]
[email]:(k+[redacted password]
[email]:Ste[redacted password]
[email]:^@f[redacted password]
[email]:XT$[redacted password]
[email]:25@[redacted password]
[email]:Jav[redacted password]
[email]:U8![redacted password]
[email]:LsZ[redacted password]
[email]:But[redacted password]
[email]:g$V[redacted password]
[email]:M9@[redacted password]
[email]:!6D[redacted password]
[email]:Fac[redacted password]
[email]:but[redacted password]
[email]:Why[redacted password]
[email]:h45[redacted password]
[email]:blo[redacted password]
[email]:azT[redacted password]
I've redacted everything after the first three characters of the password so you can get a sense of the breadth of different ones here. In this instance, there was no accompanying website, but the data checked out:
Oh damn a lot of those do seem pretty accurate. Some are quite old and outdated too. I tend to use that gmail account for inconsequential shit so I'm not too fussed, but I'll defintely get stuck in and change all those passwords ASAP. This actually explains a lot because I've noticed some pretty suspicious activity with a couple of different accounts lately.
Another with 35 records of website, email and password triplets responded as follows (I'll stop pasting in the source data, you know what that looks like by now):
Thank you very much for the information, although I already knew about this (I think it was due to a breach in LastPass) and I already changed the passwords, your information is much more complete and clear. It helped me find some pages where I haven't changed the password.
The final one of note really struck a chord with me, not because of the thrirteen rows of records similar to the ones above, but because of what he told me in his reply:
Thank you for your kindness. Most of these I have been able to change the passwords of and they do look familiar. The passwords on there have been changed. Is there a way we both can fix this problem as seeing I am only 14?
That's my son's age and predictably, all the websites listed were gaming sites. The kid had obviously installed something nasty and had signed up to HIBP notifications only a week earlier. He explained he'd recently received an email attempting to extort him for $1.3k worth of Bitcoin and shared the message. It was clearly a mass-mailed, indiscriminate shakedown and I advised him that it in no way targeted him directly. Concerned, he countered with a second extortion email he'd received, this time it was your classic "we caught you watching porn and masturbating" scam, and this one really had him worried:
I have been stressed and scared about these scams (even though I shouldn’t be). I have been very stressed and scared today because of another one of those emails.
Imagine being a young teenage boy and receiving that?! That's the sort of thing criminals frequenting Telegram channels such as the ones in question are using this data for, and it's reprehensible. I gave him some tips (I see the sorts of things my son's friends randomly install!) and hopefully, that'll set him on the right course.
They were the most noteworthy responses, the others that were often just a single email address and password pair just simply reinforced the same message:
Yes, this is an old password that I have used in the past, and matches the password of my accounts that had been logged into recently.
And:
Yes that password is familiar and accurate. I used to practice password re-use with this password across many services 5+ years ago.This makes it impossible to correlate it to a particular service or breach. It is known to me to be out there already, I've received crypto extortion emails containing it.
I know that many people who find themselves in this incident will be confused; which breach is it? I've never used Telegram before, why am I there? Those questions came through during my verification process and I know from loading previous similar breaches, they'll come up over and over again in the coming days and I hope that the overview above sufficiently answers these.
The questions that are harder to answer (and again, I know these will come up based on prior experience), are what the password is that was exposed, what the website it appeared next to was and, indeed, if it appeared next to a website at all or just alongside an email address. Right at the beginning of this project more than a decade ago, I made the decision not to load the data that would answer these questions due to the risk it posed to individuals and by extension, the risk to my ability to continue running HIBP. We were reminded of how important this decision was earlier in the year when a service aggregating data breaches left the whole thing exposed and put everyone in there at even more risk.
So, if you're in here, what do you do? It's a repeat of the same old advice we've been giving in this industry for decades now, namely keeping devices patched and updated, running security software appropriate for your device (I use Microsoft Defender on my PCs), using strong and unique passwords (get a password manager!) and enabling 2FA wherever possible. Each HIBP subscriber I contacted wasn't doing at least one of these things, which was evident in their password selection. Time and time again, passwords consisted of highly predictable patterns and often included their name, year of birth (I assume) and common character substitutions, usually within a dozen characters of length too. It's the absolute basics that are going wrong here.
To the point one of the HIBP subscribers made above, loading this data will help many people explain why they've been seeing unusual behaviour on their accounts. It's also the wakeup call to lift everyone's security game per the previous paragraph. But this also isn't the end of it, and more combolists have been posted in more Telegram channels since loading this incident. Whilst I'm still of the view from years ago that I'm not going to continuously load endless lists, I do hope people recognise that their security posture is an ongoing concern and not just something you think about after appearing in a breach.
The data is now searchable in Have I Been Pwned.

Today we loaded 16.5M email addresses and 13.5M unique passwords provided by law enforcement agencies into Have I Been Pwned (HIBP) following botnet takedowns in a campaign they've coined Operation Endgame. That link provides an excellent overview so start there then come back to this blog post which adds some insight into the data and explains how HIBP fits into the picture.
Since 2013 when I kicked off HIBP as a pet project, it has become an increasingly important part of the security posture of individuals, organisations, governments and law enforcement agencies. Gradually and organically, it has found a fit where it's able to provide a useful service to the good guys after the bad guys have done evil cyber things. The phrase I've been fond of this last decade is that HIBP is there to do good things with data after bad things happen. The reputation and reach the service has gained in this time has led to partnerships such as the one you're reading about here today. So, with that in mind, let's get into the mechanics of the data:
In terms of the email addresses, there were 16.5M in total with 4.5M of them not having been seen in previous data breaches already in HIBP. We found 25k of our own individual subscribers in the corpus of data, plus another 20k domain subscribers which is usually organisations monitoring the exposure of their customers (all of these subscribers have now been sent notification emails). As the data was provided to us by law enforcement for the public good, the breach is flagged as subscription free which means any organisation that can prove control of the domain can search it irrespective of the subscription model we launched for large domains in August last year.
The only data we've been provided with is email addresses and disassociated password hashes, that is they don't appear alongside a corresponding address. This is the bare minimum we need to make that data searchable and useful to those impacted. So, let's talk about those standalone passwords:
There are 13.5 million unique passwords of which 8.9M were already in Pwned Passwords. Those passwords have had their prevalence counts updated accordingly (we received counts for each password with many appearing in the takedown multiple times over), so if you're using Pwned Passwords already, you'll see new numbers next to some entries. That also means there are 4.6M passwords we've never seen before which you can freely download using our open source tool. Or even better, if you're querying Pwned Passwords on demand you don't need to do anything as the new entries are automatically added to the result set. All this is made possible by feeding the data into the law enforcement pipeline we built for the FBI and NCA a few years ago.
A quick geek-out moment on Pwned Passwords: at present, we're serving almost 8 billion requests per month to this service:
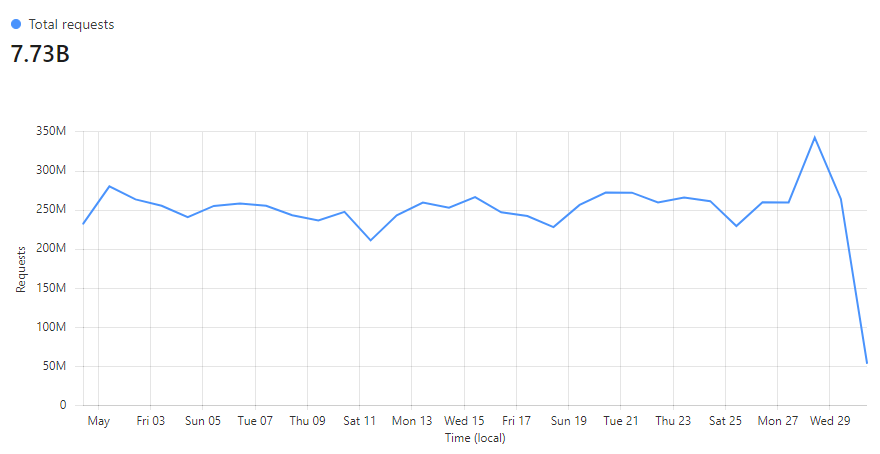
Taking just last week as an example, we're a rounding error off 100% of requests being served directly from Cloudflare's cache:
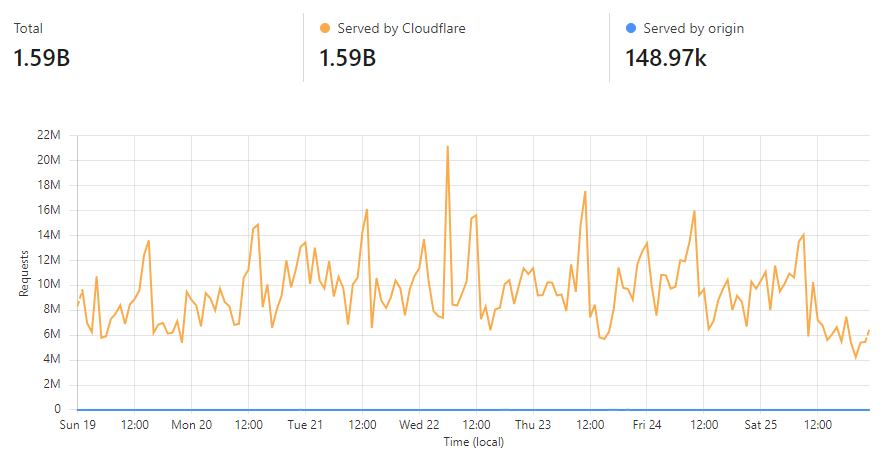
That's over 99.99% of all requests during that period that were served from one of Cloudflare's edge nodes that sit in 320 cities globally. What that means for consumers of the service is massively fast response times due to the low latency of serving content from a nearby location and huge confidence in availability as there's only about a one-in-ten-thousand chance of the request being served by our origin service. If you'd like to know more about how we achieved this, check out my post from a year ago on using Cloudflare Cache Reserve.
After pushing out the new passwords today, all but 5 hash prefixes were modified (read more about how we use hashes to enable anonymous password searches) so we did a complete Cloudflare cache flush. By the time you read this, almost the entire 16^5 possible hash ranges have been completely repopulated into cache due to the volume of requests the service receives:
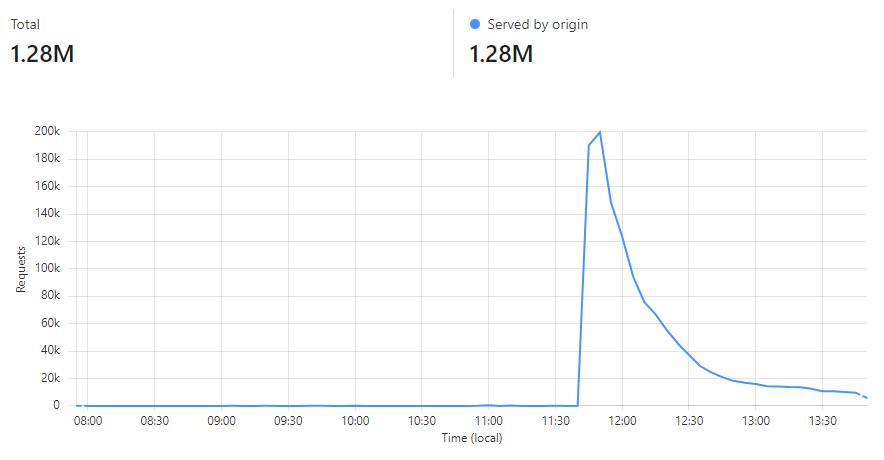
Lastly, when we talk about passwords in HIBP, the inputs we receive from law enforcement consist of 3 parts:
The rationale for this is explained in the links above but in a nutshell, the SHA-1 format ensures any badly parsed data that may inadvertently include PII is protected and it aligns with the underlying data structure that drives the k-anonymity searches. We have NTLM hashes as well because many orgs use them to check passwords in their own Active Directory instances.
So, what can you do if you find your data in this incident? It's a similar story to the Emotet malware provided by the FBI and NHTCU a few years ago in that the sage old advice applies: get a password manager and make them all strong and unique, turn on 2FA everywhere, keep machines patched, etc. If you find your password in the data (the HIBP password search feature anonymises it before searching, or password managers like 1Password can scan all of your passwords in one go), obviously change it everywhere you've used it.
This operation will be significant in terms of the impact on cybercrime, and I'm glad we've been able to put this little project to good use by supporting our friends in law enforcement who are doing their best to support all of us as online citizens.

We often do that in this industry, the whole "1.0" thing, but it seems apt here. I started Have I Been Pwned (HIBP) in 2013 as a pet project that scratched an itch, so I never really thought of myself as an "employee". Over time, it grew (and I tell you what, nobody is more surprised by that than me!) and over the last few years, my wife Charlotte got more and more involved. Technically, we're both employees and we work on HIBP things but we're like, well, beta versions.
Today, I'm very happy to announce our first full-time, production-ready employee: Stefán Jökull Sigurðarson. This is both a massive commitment on Charlotte's and my part and a leap of faith on Stefán's and deserves some background:
I suffer somewhat from what I'll call the "founder's paradox", that is I find myself having built something genuinely useful and wanting to see it grow and mature yet also not wanting to let go. I want to be involved in everything, but I also want to go on holidays sometimes and tune out. I like making decisions on every aspect of how the service runs, but I want it to outlive me. Bringing any outside party into any business can be hard to come to terms with, but especially in the case of HIBP where it's become so critical to so many people and deals with so much sensitive data. Which is why I have to trust people like Stefán because if I don't, I'm one shark / snake / croc incident away from disappointing a lot of people.
Trust is the cornerstone of why Stefán is joining us now. Not just trust in his technical skills, but trust in him as a person. I've known Stefán for many years now, initially when he came to one of my Hack Yourself First workshops in Oslo back in 2018, then as a blogger writing about how he was implementing Pwned Passwords at EVE Online, then as conference speaker himself, a Microsoft MVP, and in 2021, as the person who selflessly gave up his own time to support the open source Pwned Passwords. What we never made any formal announcements about is that we did hire Stefán on a part-time basis beginning earlier last year to help out with the coding when he had free cycles amidst his full-time work. That went great and he obviously enjoyed working at HIBP so earlier this month, Stefán handed in his resignation and will shortly be a full-time employee.
I'm really happy with the timing of this and how it's all worked out. We're in a position to make the financial commitment largely because of finally putting a price on searches for large domains last year. What this has allowed us to do is shift money from companies who see value in the service (more than half the Fortune 500 use the domain search feature), and reinvest it into making HIBP more sustainable. Getting Stefán onboard is the manifestation of that investment and you'll very shortly see his work begin to translate into highly visible new features. But what you won't see is the stuff that's even more important, especially as it relates to running a more sustainable service that no longer has me as a single point of failure.
So, welcome Stefán, and thank you for your commitment 😊
Oh - just one more thing: I was looking around for a great hero image for this blog post and I found this awesome video of Stefán swimming through a semi-frozen Norwegian fjord before riding an iceberg. For real, this it perhaps the most Nordic thing I've ever seen (Stefán being from Iceland and all), but unfortunately videos don't really lend themselves to hero images, so I went switch a stylised AI-generated rendition of the event.
The nonprofit organization that supports the Firefox web browser said today it is winding down its new partnership with Onerep, an identity protection service recently bundled with Firefox that offers to remove users from hundreds of people-search sites. The move comes just days after a report by KrebsOnSecurity forced Onerep’s CEO to admit that he has founded dozens of people-search networks over the years.
Mozilla Monitor. Image Mozilla Monitor Plus video on Youtube.
Mozilla only began bundling Onerep in Firefox last month, when it announced the reputation service would be offered on a subscription basis as part of Mozilla Monitor Plus. Launched in 2018 under the name Firefox Monitor, Mozilla Monitor also checks data from the website Have I Been Pwned? to let users know when their email addresses or password are leaked in data breaches.
On March 14, KrebsOnSecurity published a story showing that Onerep’s Belarusian CEO and founder Dimitiri Shelest launched dozens of people-search services since 2010, including a still-active data broker called Nuwber that sells background reports on people. Onerep and Shelest did not respond to requests for comment on that story.
But on March 21, Shelest released a lengthy statement wherein he admitted to maintaining an ownership stake in Nuwber, a consumer data broker he founded in 2015 — around the same time he launched Onerep.
Shelest maintained that Nuwber has “zero cross-over or information-sharing with Onerep,” and said any other old domains that may be found and associated with his name are no longer being operated by him.
“I get it,” Shelest wrote. “My affiliation with a people search business may look odd from the outside. In truth, if I hadn’t taken that initial path with a deep dive into how people search sites work, Onerep wouldn’t have the best tech and team in the space. Still, I now appreciate that we did not make this more clear in the past and I’m aiming to do better in the future.” The full statement is available here (PDF).
Onerep CEO and founder Dimitri Shelest.
In a statement released today, a spokesperson for Mozilla said it was moving away from Onerep as a service provider in its Monitor Plus product.
“Though customer data was never at risk, the outside financial interests and activities of Onerep’s CEO do not align with our values,” Mozilla wrote. “We’re working now to solidify a transition plan that will provide customers with a seamless experience and will continue to put their interests first.”
KrebsOnSecurity also reported that Shelest’s email address was used circa 2010 by an affiliate of Spamit, a Russian-language organization that paid people to aggressively promote websites hawking male enhancement drugs and generic pharmaceuticals. As noted in the March 14 story, this connection was confirmed by research from multiple graduate students at my alma mater George Mason University.
Shelest denied ever being associated with Spamit. “Between 2010 and 2014, we put up some web pages and optimize them — a widely used SEO practice — and then ran AdSense banners on them,” Shelest said, presumably referring to the dozens of people-search domains KrebsOnSecurity found were connected to his email addresses (dmitrcox@gmail.com and dmitrcox2@gmail.com). “As we progressed and learned more, we saw that a lot of the inquiries coming in were for people.”
Shelest also acknowledged that Onerep pays to run ads on “on a handful of data broker sites in very specific circumstances.”
“Our ad is served once someone has manually completed an opt-out form on their own,” Shelest wrote. “The goal is to let them know that if they were exposed on that site, there may be others, and bring awareness to there being a more automated opt-out option, such as Onerep.”
Reached via Twitter/X, HaveIBeenPwned founder Troy Hunt said he knew Mozilla was considering a partnership with Onerep, but that he was previously unaware of the Onerep CEO’s many conflicts of interest.
“I knew Mozilla had this in the works and we’d casually discussed it when talking about Firefox monitor,” Hunt told KrebsOnSecurity. “The point I made to them was the same as I’ve made to various companies wanting to put data broker removal ads on HIBP: removing your data from legally operating services has minimal impact, and you can’t remove it from the outright illegal ones who are doing the genuine damage.”
Playing both sides — creating and spreading the same digital disease that your medicine is designed to treat — may be highly unethical and wrong. But in the United States it’s not against the law. Nor is collecting and selling data on Americans. Privacy experts say the problem is that data brokers, people-search services like Nuwber and Onerep, and online reputation management firms exist because virtually all U.S. states exempt so-called “public” or “government” records from consumer privacy laws.
Those include voting registries, property filings, marriage certificates, motor vehicle records, criminal records, court documents, death records, professional licenses, and bankruptcy filings. Data brokers also can enrich consumer records with additional information, by adding social media data and known associates.
The March 14 story on Onerep was the second in a series of three investigative reports published here this month that examined the data broker and people-search industries, and highlighted the need for more congressional oversight — if not regulation — on consumer data protection and privacy.
On March 8, KrebsOnSecurity published A Close Up Look at the Consumer Data Broker Radaris, which showed that the co-founders of Radaris operate multiple Russian-language dating services and affiliate programs. It also appears many of their businesses have ties to a California marketing firm that works with a Russian state-run media conglomerate currently sanctioned by the U.S. government.
On March 20, KrebsOnSecurity published The Not-So-True People-Search Network from China, which revealed an elaborate web of phony people-search companies and executives designed to conceal the location of people-search affiliates in China who are earning money promoting U.S. based data brokers that sell personal information on Americans.
I hate having to use that word - "alleged" - because it's so inconclusive and I know it will leave people with many unanswered questions. (Edit: 12 days after publishing this blog post, it looks like the "alleged" caveat can be dropped, see the addition at the end of the post for more.) But sometimes, "alleged" is just where we need to begin and over the course of time, proper attribution is made and the dots are joined. We're here at "alleged" for two very simple reasons: one is that AT&T is saying "the data didn't come from us", and the other is that I have no way of proving otherwise. But I have proven, with sufficient confidence, that the data is real and the impact is significant. Let me explain:
Firstly, just as a primer if you're new to this story, read BleepingComputer's piece on the incident. What it boils down to is in August 2021, someone with a proven history of breaching large organisations posted what they claimed were 70 million AT&T records to a popular hacking forum and asked for a very large amount of money should anyone wish to purchase the data. From that story:
From the samples shared by the threat actor, the database contains customers' names, addresses, phone numbers, Social Security numbers, and date of birth.
Fast forward two and a half years and the successor to this forum saw a post this week alleging to contain the entire corpus of data. Except that rather than put it up for sale, someone has decided to just dump it all publicly and make it easily accessible to the masses. This isn't unusual: "fresh" data has much greater commercial value and is often tightly held for a long period before being released into the public domain. The Dropbox and LinkedIn breaches, for example, occurred in 2012 before being broadly distributed in 2016 and just like those incidents, the alleged AT&T data is now in very broad circulation. It is undoubtedly in the hands of thousands of internet randos.
AT&T's position on this is pretty simple:
AT&T continues to tell BleepingComputer today that they still see no evidence of a breach in their systems and still believe that this data did not originate from them.
The old adage of "absence of evidence is not evidence of absence" comes to mind (just because they can't find evidence of it doesn't mean it didn't happen), but as I said earlier on, I (and others) have so far been unable to prove otherwise. So, let's focus on what we can prove, starting with the accuracy of the data.
The linked article talks about the author verifying the data with various people he knows, as well as other well-known infosec identities verifying its accuracy. For my part, I've got 4.8M Have I Been Pwned (HIBP) subscribers I can lean on to assist with verification, and it turns out that 153k of them are in this data set. What I'll typically do in a scenario like this is reach out to the 30 newest subscribers (people who will hopefully recall the nature of HIBP from their recent memory), and ask them if they're willing to assist. I linked to the story from the beginning of this blog post and got a handful of willing respondents for whom I sent their data and asked two simple questions:
The first reply I received was simple, but emphatic:

This individual had their name, phone number, home address and most importantly, their social security number exposed. Per the linked story, social security numbers and dates of birth exist on most rows of the data in encrypted format, but two supplemental files expose these in plain text. Taken at face value, it looks like whoever snagged this data also obtained the private encryption key and simply decrypted the vast bulk (but not all of) the protected values.

The above example simply didn't have plain text entries for the encrypted data. Just by way of raw numbers, the file that aligns with the "70M" headline actually has 73,481,539 lines with 49,102,176 unique email addresses. The file with decrypted SSNs has 43,989,217 lines and the decrypted dates of birth file only has 43,524 rows. (Edit: the reason for this later became clear - there is only one entry per date of birth which is then referenced from multiple records.) The last file, for example, has rows that look just like this:
.encrypted_value='*0g91F1wJvGV03zUGm6mBWSg==' .decrypted_value='1996-07-18'That encrypted value is precisely what appears in the large file hence providing an easy way of matching all the data together. But those numbers also obviously mean that not every impacted individual had their SSN exposed, and most individuals didn't have their date of birth leaked. (Edit: per above, the same entries in the DoB file are referenced by multiple source records so whilst not every record had a DoB recorded, the difference isn't as stark as I originally reported.)

As I'm fond of saying, there's only one thing worse than your data appearing on the dark web: it's appearing on the clear web. And that's precisely where it is; the forum this was posted to isn't within the shady underbelly of a Tor hidden service, it's out there in plain sight on a public forum easily accessed by a normal web browser. And the data is real.
That last response is where most people impacted by this will now find themselves - "what do I do?" Usually I'd tell them to get in touch with the impacted organisation and request a copy of their data from the breach, but if AT&T's position is that it didn't come from them then they may not be much help. (Although if you are a current or previous customer, you can certainly request a copy of your personal information regardless of this incident.) I've personally also used identity theft protection services since as far back as the 90's now, simply to know when actions such as credit enquiries appear against my name. In the US, this is what services like Aura do and it's become common practice for breached organisations to provide identity protection subscriptions to impacted customers (full disclosure: Aura is a previous sponsor of this blog, although we have no ongoing or upcoming commercial relationship).
What I can't do is send you your breached data, or an indication of what fields you had exposed. Whilst I did this in that handful of aforementioned cases as part of the breach verification process, this is something that happens entirely manually and is infeasible en mass. HIBP only ever stores email addresses and never the additional fields of personal information that appear in data breaches. In case you're wondering why that is, we got a solid reminder only a couple of months ago when a service making this sort of data available to the masses had an incident that exposed tens of billions of rows of personal information. That's just an unacceptable risk for which the old adage of "you cannot lose what you do not have" provides the best possible fix.
As I said in the intro, this is not the conclusive end I wanted for this blog post... yet. As impacted HIBP subscribers receive their notifications and particularly as those monitoring domains learn of the aliases in the breach (many domain owners use unique aliases per service they sign up to), we may see a more conclusive outcome to this incident. That may not necessarily be confirmation that the data did indeed originate from AT&T, it could be that it came from a third party processor they use or from another entity altogether that's entirely unrelated. The truth is somewhere there in the data, I'll add any relevant updates to this blog post if and when it comes out.
As of now, all 49M impacted email addresses are searchable within HIBP.
Edit (31 March): AT&T have just released a short statement making 2 important points:
AT&T data-specific fields were contained in a data set
it is not yet known whether the data in those fields originated from AT&T or one of its vendors
They've also been mass-resetting account passcodes after TechCrunch apparently alerted AT&T to the presence of these in the data set. That article also includes the following statement from AT&T:
Based on our preliminary analysis, the data set appears to be from 2019 or earlier, impacting approximately 7.6 million current AT&T account holders and approximately 65.4 million former account holders
Between originally publishing this blog post and AT&T's announcements today, there have been dozens of comments left below that attribute the source of the breach to AT&T in ways that made it increasingly unlikely that the data could have been sourced from anywhere else. I know that many journos (and myself) reached out to folks in AT&T to draw their attention to this, I'm happy to now end this blog post by quoting myself from the opening para 😊
But sometimes, "alleged" is just where we need to begin and over the course of time, proper attribution is made and the dots are joined.

I've always thought of it a bit like baseball cards; a kid has a card of this one player that another kid is keen on, and that kid has a card the first one wants so they make a trade. They both have a bunch of cards they've collected over time and by virtue of existing in the same social circles, trades are frequent, and cards flow back and forth on a regular basis. That's the analogy I often use to describe the data breach "personal stash" ecosystem, but with one key difference: if you trade a baseball card then you no longer have the original card, but if you trade a data breach which is merely a digital file, it replicates.
There are personal stashes of data breaches all over the place and they're usually presented like this one:
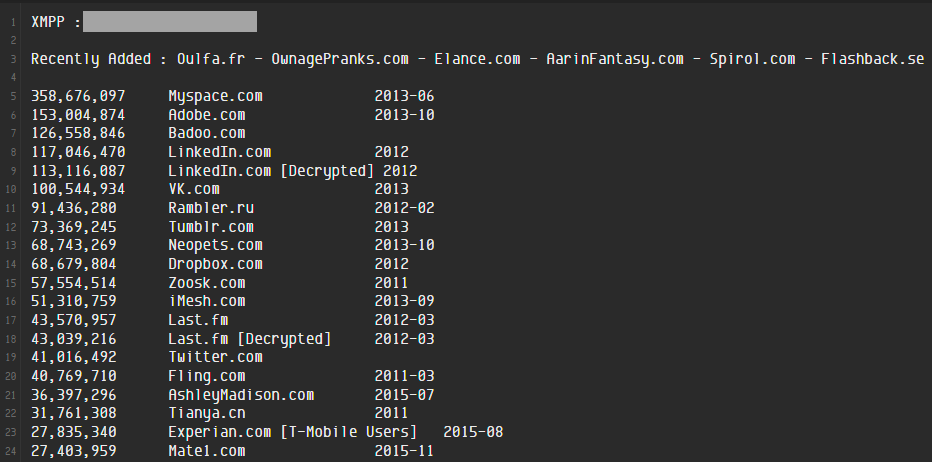
You'll recognise many of those names because they're noteworthy incidents that received a bunch of press. My Space. Adobe. LinkedIn. Ashley Madison.
The same incidents appear here:
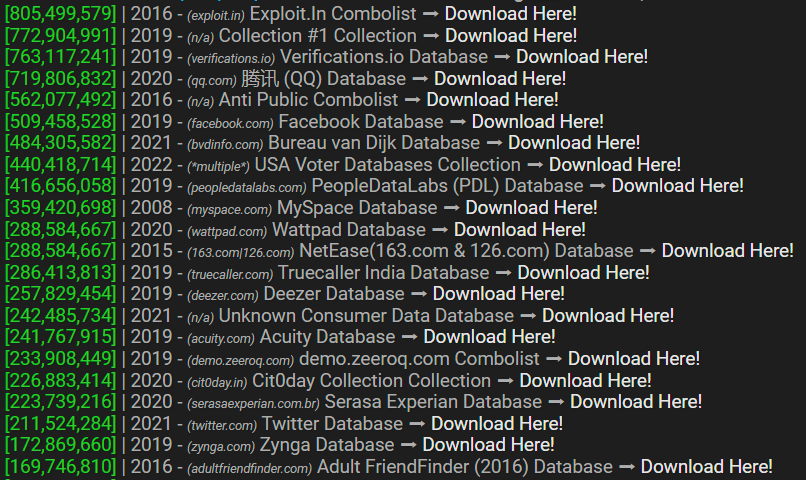
And so on and so forth. Stashes of breaches like this are all over the place and they fuel an exchange ecosystem that replicates billions of records of personal data over and over again. Your data. My data. The data of a significant portion of the global internet-using population, just freely flowing backwards and forwards not just in the shady corners of "the dark web" but traded out there in the clear on mainstream websites. Until inevitably:

Diogo Santos Coelho was 14 when he started RaidForums, and was 21 by the time he was arrested for running the service 2 years ago. A kid, exchanging data without the maturity to understand the consequences of his actions. RaidForums left a void that was quickly filled by BreachForums:

Conor Fitzpatrick was 20 years old when he was finally picked up for running the service last year. Still just a kid, at least in the colloquial fashion in which we refer to youngsters as when we get a bit older, but surely still legally a minor when he chose to begin collecting data breaches.
Websites like these are taken down for a simple reason:
The ecosystem of personal stashes exchanged with other parties fuels crime.
For example, data breaches seed services set up with the express intent of monetising a broad range of personal attributes to the detriment of people who are already victims of a breach. Call them shady versions of Have I Been Pwned if you will, and this talk I gave at AusCERT a couple of years ago is a great explainer (deep-linked to the start of that segment):
The first service I spoke about in that segment was We Leak Info and it was run by two 22 year old guys. The website first appeared 3 years earlier - only a year after the creators had left childhood - and it allowed anyone with the money to access anyone else's personal data including:
names, email addresses, usernames, phone numbers, and passwords
One of the duo was later sentenced to 2 years in prison for his role, and when you read the sorts of conversations they were having, you can't help but think they behaved exactly like you'd expect a couple of young guys who thought they were anonymous would:
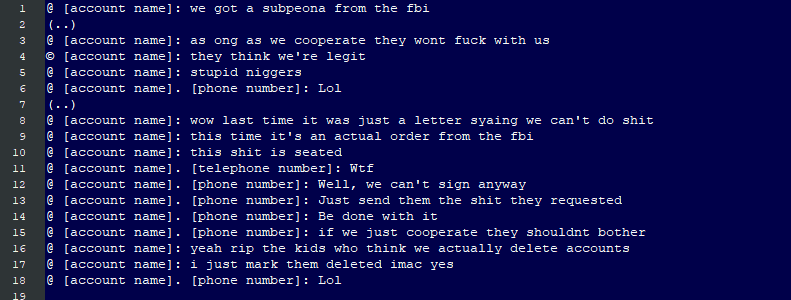
In the video, I mentioned Jordan Bloom in relation to LeakedSource, a veritable older gentleman of this class of crime being 24 when the site first appeared.
The company operating LeakedSource, Defiant Tech Inc, which was founded by Jordan Bloom, eventually entered a guilty plea to charges that included trafficking in identity information and when you read what that involved, you can see why this would attract the ire of law enforcement agencies:
However, unlike other breach notification services, such as Have I Been Pwned, LeakedSource also gave subscribers access to usernames, passwords (including in clear text), email addresses and IP addresses. LeakedSource services were often advertised on hacking forums and there was suspicion that its operators were actively looking to hack organizations whose data they could add to their database.
In 2016, a well-wisher purchased my own data from LeakedSource and sent over a dozen different records similar to this one:
Not mentioned in my talk but running in the same era was Leakbase, yet another service that collated huge volumes of sensitive data and sold it to absolutely anyone:

And just like all the other ones, the same data appeared over and over again:

It went dark at the end of 2017 amidst speculation the disappearance was tied to the takedown of the Hansa dark web market. If that was the case, why did we never hear of charges being laid as we did with We Leak Info and LeakedSource? Could it be that the operator of Leakbase was only ever so slightly younger than the other guys mentioned above and not having yet reached adulthood, managed to dodge charges? It would certainly be consistent with the demographic pattern of those with personal stashes of data breaches.
Speaking of patterns: We Leak Info, LeakedSource, Leakbase - it's like there's a theme of shady services attached to the word. As I say in the video, there's also a theme of attempting to remain anonymous (which clearly hasn't worked very well!), and a theme of attempting to eschew legal responsibility for how the data is used by merely putting words in the terms of service. For example, here's Jordan's go at deflecting his role in the ecosystem and yes, this was the entire terms of service:
I particularly like this clause:
You may only use this tool for your own personal security and data research. You may only search information about yourself, or those you are authorized in writing to do so.
That's not going to keep you out of trouble! Time and time again, I see this sort of wording on services used as if it's going to make a difference when the law comes asking hard questions; "Hey we literally told people to play nice with the data!"
We Leak Info used similar entertaining wording with some of the highlights including:
That last one in particular is an absolute zinger! But again, remember, we're talking about guys who stood this service up as teenagers and literally worked on the assumption of "as [l]ong as we cooperate they [the FBI] won't fuck with us" 🤦♂️ The ignorance of that attitude whilst advertising services on criminal forums is just mind-blowing, even for kids.
All of which brings me to the inspiration for this blog post:
Interesting find by @MayhemDayOne, wonder if it was from a shady breach search service (we’ve seen a bunch shut down over the years)? Either way, collecting and storing this data is now trivial so not a big surprise to see someone screw up their permissions and (re)leak it all. https://t.co/DM7udeUcRk
— Troy Hunt (@troyhunt) January 22, 2024
It's like I've seen it all before! No, really, because only a couple of days later someone running a service popped up and claimed responsibility for having exposed the data due to "a firewall misconfiguration". I'm not going to name or link the service, but I will describe a few key features:
I could write predictions about the future of this service but if you've read this far and paid attention to the precedents, you can reliably form your own conclusion. The outcome is easily predictable and indeed it was the predictability of the whole situation when I started getting bombarded with queries about the "Mother of all Breaches" that frustrated me; of course it was someone's personal stash, because we've seen it all before and we live in an era where it's dead easy to build services like this. Cloud is ubiquitous and storage is cheap, you can stand up great looking websites in next to no time courtesy of freely available templates, and the whole data breach trading ecosystem I referred to earlier can easily seed services like this.
Maybe the young guy running this service (assuming the previously observed patterns apply) will learn from history and quietly exit while the getting is good, I don't know, time will tell. At the very least, if he reads this and takes nothing else away, don't go driving around in a bright green Lamborghini!
Edit: In the original version of this blog post, it was incorrectly implied that Jordan Bloom may have been the person who pled guilty to charges when in fact it was the company that ran LeakedSource, Defiant Tech Inc, that the plea was entered under. To the extent that the blog contained words to the effect of, or otherwise implied or contained innuendo that Mr Bloom engaged in criminal or otherwise illegal conduct, or pled guilty to trafficking identify information, I apologise and unreservedly retract such statements and this blog has been edited to ensure that the facts involved in this matter are accurately portrayed.
