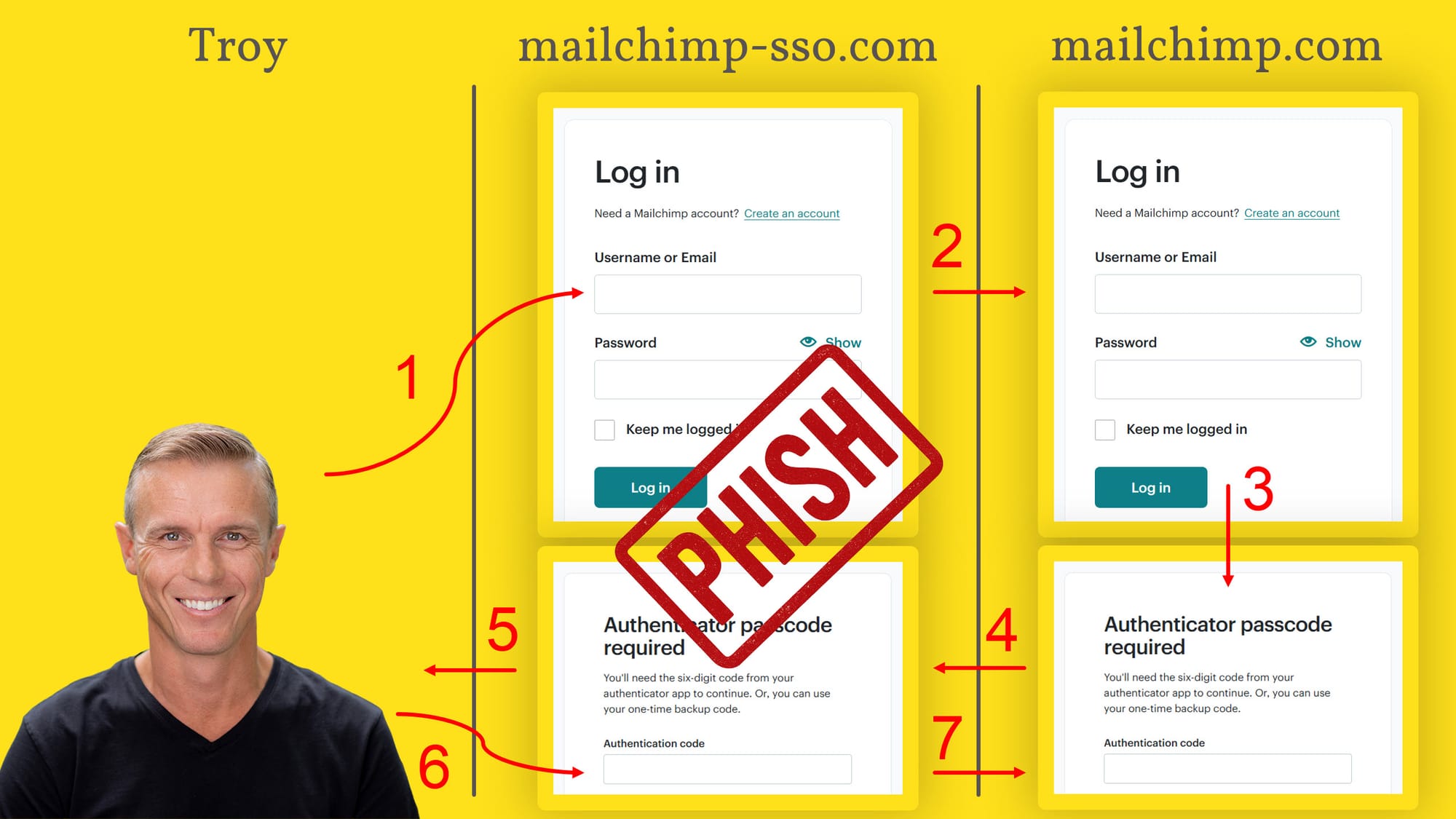
Let me start by very simply explaining the problem we're trying to solve with passkeys. Imagine you're logging on to a website like this:
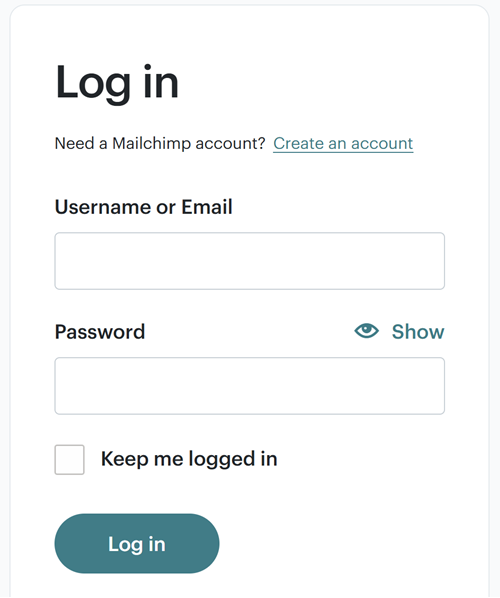
And, because you want to protect your account from being logged into by someone else who may obtain your username and password, you've turned on two-factor authentication (2FA). That means that even after entering the correct credentials in the screen above, you're now prompted to enter the six-digit code from your authenticator app:
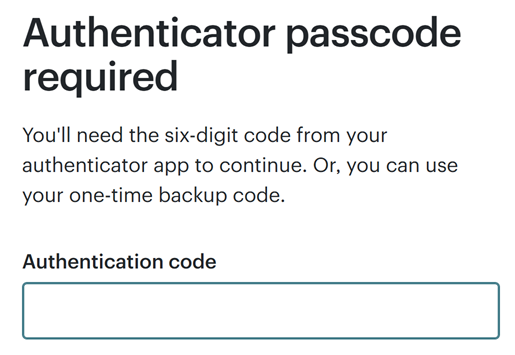
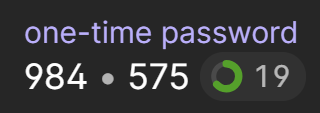
There are a few different authenticator apps out there, but what they all have in common is that they display a one-time password (henceforth referred to as an OTP) with a countdown timer next to it:
By only being valid for a short period of time, if someone else obtains the OTP then they have a very short window in which it's valid. Besides, who can possibly obtain it from your authenticator app anyway?! Well... that's where the problem lies, and I demonstrated this just recently, not intentionally, but rather entirely by accident when I fell victim to a phishing attack. Here's how it worked:
The problem with OTPs from authenticator apps (or sent via SMS) is that they're phishable in that it's possible for someone to trick you into handing one over. What we need instead is a "phishing-resistant" paradigm, and that's precisely what passkeys are. Let's look at how to set them up, how to use them on websites and in mobile apps, and talk about what some of their shortcomings are.
We'll start by setting one up for WhatsApp given I got a friendly prompt from them to do this recently:
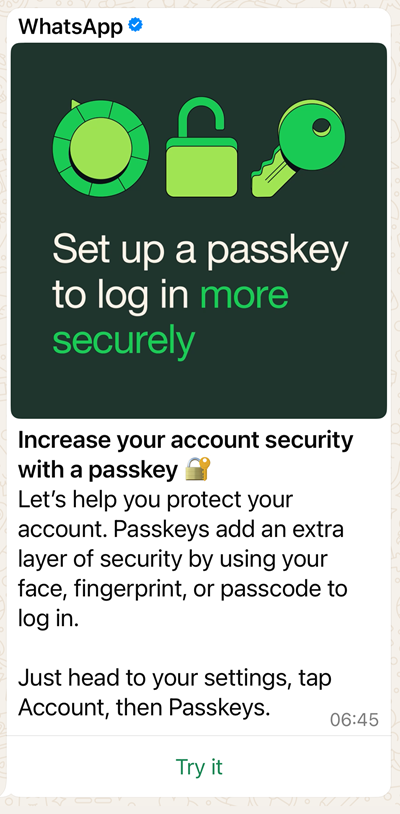
So, let's "Try it" and walk through the mechanics of what it means to setup a passkey. I'm using an iPhone, and this is the screen I'm first presented with:
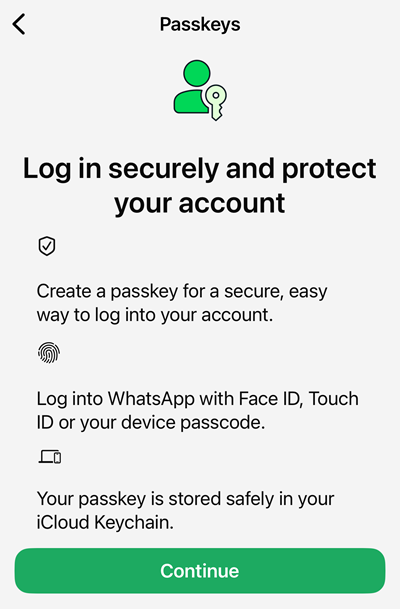
A passkey is simply a digital file you store on your device. It has various cryptographic protections in the way it is created and then used to login, but that goes beyond the scope of what I want to explain to the audience in this blog post. Let's touch briefly on the three items WhatsApp describes above:
That last point can be very device-specific and very user-specific. Because I have an iPhone, WhatsApp is suggesting I save the passkey into my iCloud Keychain. If you have an Android, you're obviously going to see a different message that aligns to how Google syncs passkeys. Choosing one of these native options is your path of least resistance - a couple of clicks and you're done. However...
I have lots of other services I want to use passkeys on, and I want to authenticate to them both from my iPhone and my Windows PC. For example, I use LinkedIn across all my devices, so I don't want my passkey tied solely to my iPhone. (It's a bit clunky, but some services enable this by using the mobile device your passkey is on to scan a QR code displayed on a web page). And what if one day I switch from iPhone to Android? I'd like my passkeys to be more transferable, so I'm going to store them in my dedicated password manager, 1Password.
A quick side note: as you'll read in this post, passkeys do not necessarily replace passwords. Sometimes they can be used as a "single factor" (the only thing you use to login with), but they may also be used as a "second factor" with the first being your password. This is up to the service implementing them, and one of the criticisms of passkeys is that your experience with them will differ between websites.
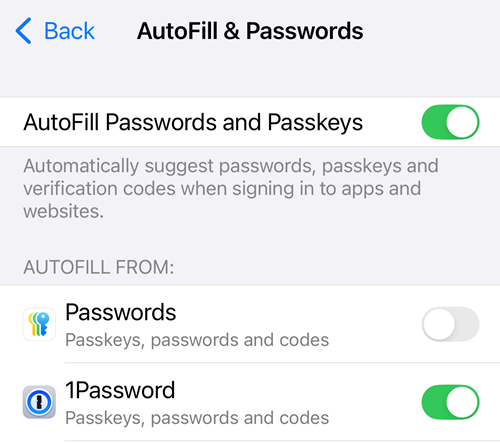
We still need passwords, we still want them to be strong and unique, therefore we still need password managers. I've been using 1Password for 14 years now (full disclosure: they sponsor Have I Been Pwned, and often sponsor this blog too) and as well as storing passwords (and credit cards and passport info and secure notes and sharing it all with my family), they can also store passkeys. I have 1Password installed on my iPhone and set as the default app to autofill passwords and passkeys:
Because of this, I'm given the option to store my WhatsApp passkey directly there:
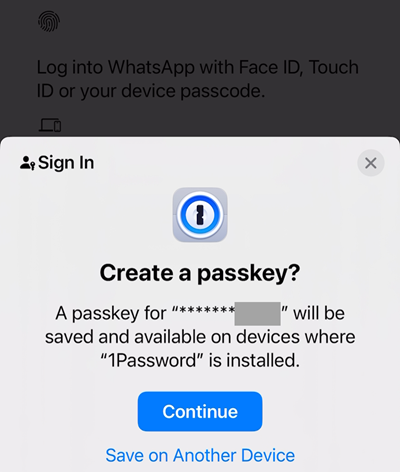
The obfuscated section is the last four digits of my phone number. Let's "Continue", and then 1Password pops up with a "Save" button:
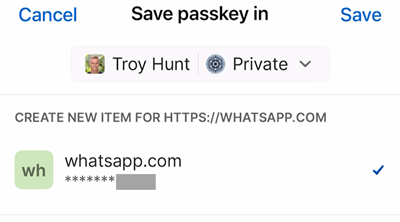
Once saved, WhatsApp displays the passkey that is now saved against my account:
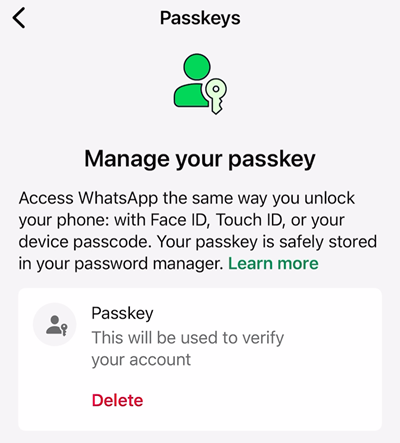
And because I saved it into 1Password that syncs across all my devices, I can jump over to the PC and see it there too.

And that's it, I now have a passkey for WhatsApp which can be used to log in. I picked this example as a starting point given the massive breadth of the platform and the fact I was literally just prompted to create a passkey (the very day my Mailchimp account was phished, ironically). Only thing is, I genuinely can't see how to log out of WhatsApp so I can then test using the passkey to login. Let's go and create another with a different service and see how that experience differs.
Let's pick another example, and we'll set this one up on my PC. I'm going to pick a service that contains some important personal information, which would be damaging if it were taken over. In this case, the service has also previously suffered a data breach themselves: LinkedIn.
I already had two-step verification enabled on LinkedIn, but as evidenced in my own phishing experience, this isn't always enough. (Note: the terms "two-step", "two-factor" and "multi-factor" do have subtle differences, but for the sake of simplicity, I'll treat them as interchangeable terms in this post.)
Onto passkeys, and you'll see similarities between LinkedIn's and WhatsApp's descriptions. An important difference, however, is LinkedIn's comment about not needing to remember complex passwords:
Let's jump into it and create that passkey, but just before we do, keep in mind that it's up to each and every different service to decide how they implement the workflow for creating passkeys. Just like how different services have different rules for password strength criteria, the same applies to the mechanics of passkey creation. LinkedIn begins by requiring my password again:
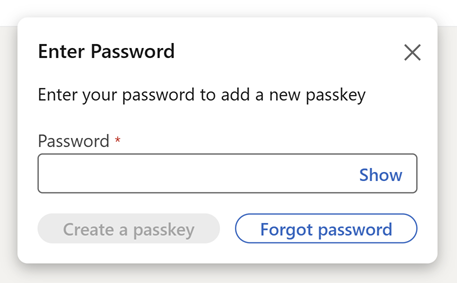
This is part of the verification process to ensure someone other than you (for example, someone who can sit down at your machine that's already logged into LinkedIn), can't add a new way of accessing your account. I'm then prompted for a 6-digit code:
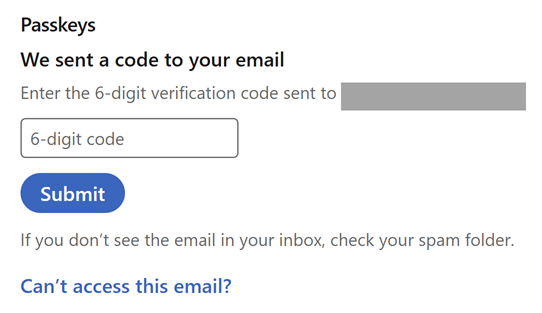
Which has already been sent to my email address, thus verifying I am indeed the legitimate account holder:
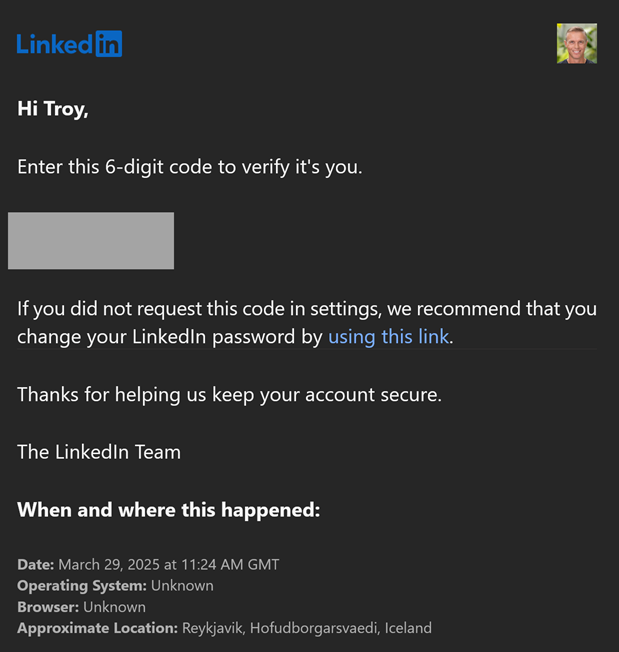
As soon as I enter that code in the website, LinkedIn pushes the passkey to me, which 1Password then offers to save:
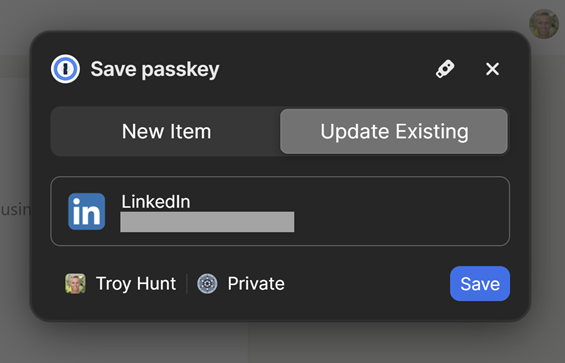
Again, your experience will differ based on which device and preferred method of storing passkeys you're using. But what will always be the same for LinkedIn is that you can then see the successfully created passkey on the website:

Now, let's see how it works by logging out of LinkedIn and then returning to the login page. Immediately, 1Password pops up and offers to sign me in with my passkey:
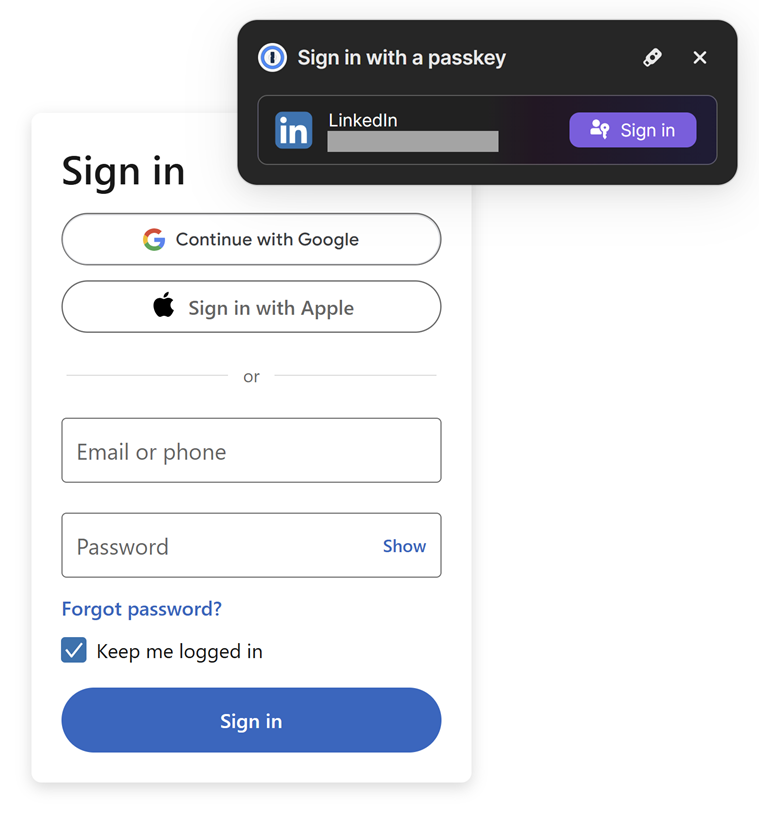
That's a one-click sign-in, and clicking the purple button immediately grants me access to my account. Not only will 1Password not let me enter the passkey into a phishing site, due to the technical implementation of the keys, it would be completely unusable even if it was submitted to a nefarious party. Let me emphasise something really significant about this process:
Passkeys are one of the few security constructs that make your life easier, rather than harder.
However, there's a problem: I still have a password on the account, and I can still log in with it. What this means is that LinkedIn has decided (and, again, this is one of those website-specific decisions), that a passkey merely represents a parallel means of logging in. It doesn't replace the password, nor can it be used as a second factor. Even after generating the passkey, only two options are available for that second factor:
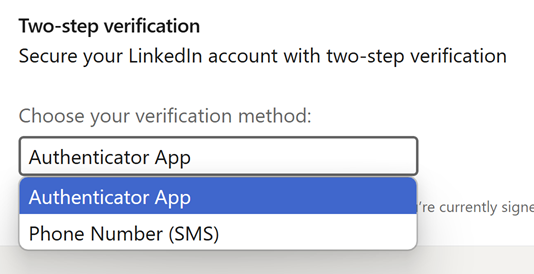
The risk here is that you can still be tricked into entering your password into a phishing site, and per my Mailchimp example, your second factor (the OTP generated by your authenticator app) can then also be phished. This is not to say you shouldn't use a passkey on LinkedIn, but whilst you still have a password and phishable 2FA, you're still at risk of the same sort of attack that got me.
Let's try one more example, and this time, it's one that implements passkeys as a genuine second factor: Ubiquiti.
Ubiquiti is my favourite manufacturer of networking equipment, and logging onto their system gives you an enormous amount of visibility into my home network. When originally setting up that account many years ago, I enabled 2FA with an OTP and, as you now understand, ran the risk of it being phished. But just the other day I noticed passkey support and a few minutes later, my Ubiquiti account in 1Password looked like this:
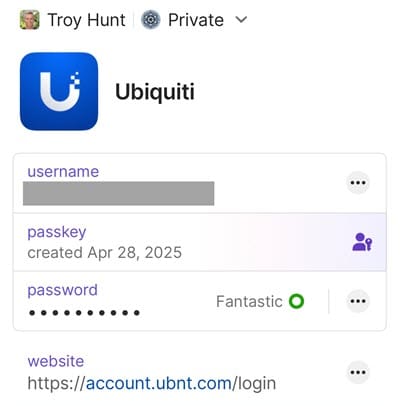
I won't bother running through the setup process again because it's largely similar to WhatsApp and LinkedIn, but I will share just what it looks like to now login to that account, and it's awesome:
I intentionally left this running at real-time speed to show how fast the login process is with a password manager and passkey (I've blanked out some fields with personal info in them). That's about seven seconds from when I first interacted with the screen to when I was fully logged in with a strong password and second factor. Let me break that process down step by step:
Now, remember "the LinkedIn problem" where you were still stuck with phishable 2FA? Not so with Ubiquiti, who allowed me to completely delete the authenticator app:
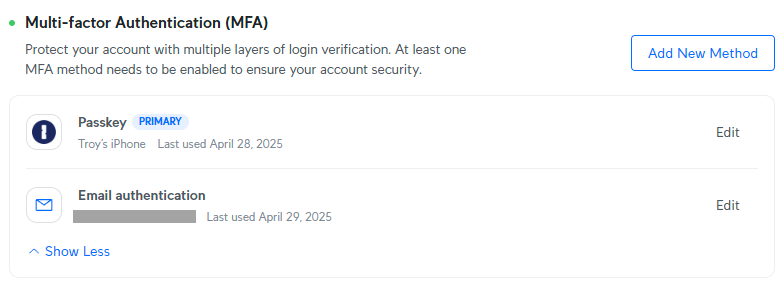
But there's one more thing we can do here to strengthen everything up further, and that's to get rid of email authentication and replace it with something even stronger than a passkey: a U2F key.
Whilst passkeys themselves are considered non-phishable, what happens if the place you store that digital key gets compromised? Your iCloud Keychain, for example, or your 1Password account. If you configure and manage these services properly then the likelihood of that happening is extremely remote, but the possibility remains. Let's add something entirely different now, and that's a physical security key:

This is a YubiKey and you can you can store your digital passkey on it. It needs to be purchased and as of today, that's about a US$60 investment for a single key. YubiKeys are called "Universal 2 Factor" or U2F keys and the one above (that's a 5C NFC) can either plug into a device with USB-C or be held next to a phone with NFC (that's "near field communication", a short-range wireless technology that requires devices to be a few centimetres apart). YubiKeys aren't the only makers of U2F keys, but their name has become synonymous with the technology.
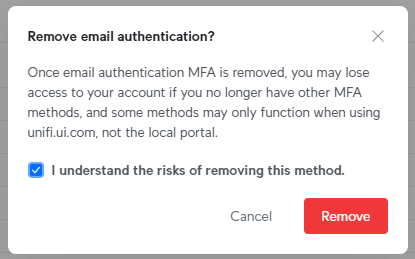
Back to Ubiquiti, and when I attempt to remove email authentication, the following prompt stops me dead in my tracks:
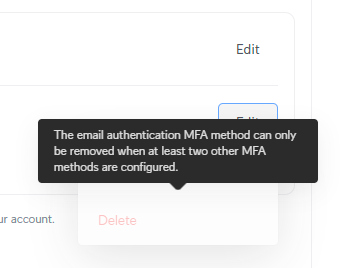
I don't want email authentication because that involves sending a code to my email address and, well, we all know what happens when we're relying on people to enter codes into login forms 🤔 So, let's now walk through the Ubiquiti process and add another passkey as a second factor:
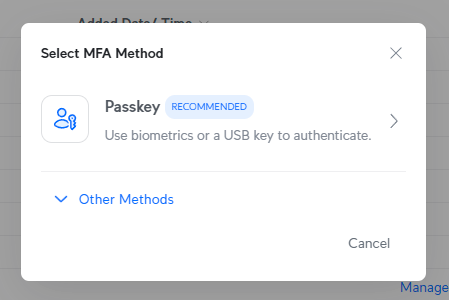
But this time, when Chrome pops up and offers to save it in 1Password, I'm going to choose the little USB icon at the top of the prompt instead:
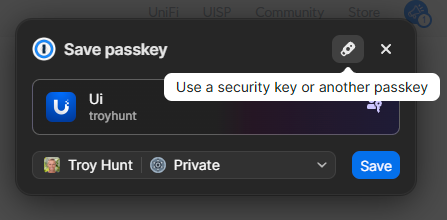
Windows then gives me a prompt to choose where I wish to save the passkey, which is where I choose the security key I've already inserted into my PC:
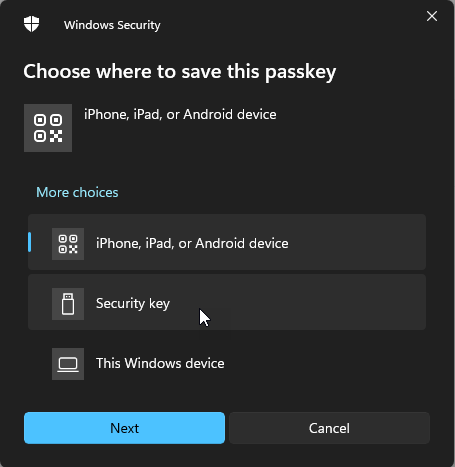
Each time you begin interacting with a U2F key, it requires a little tap:
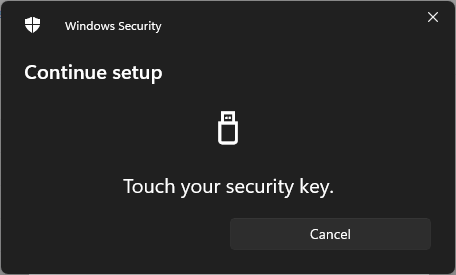
And a moment later, my digital passkey has been saved to my physical U2F key:
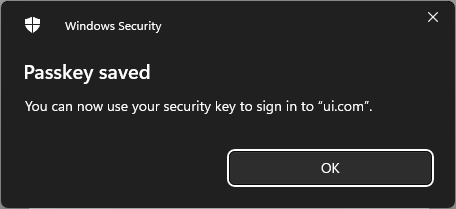
Just as you can save your passkey to Apple's iCloud Keychain or in 1Password and sync it across your devices, you can also save it to a physical key. And that's precisely what I've now done - saved one Ubiquiti passkey to 1Password and one to my YubiKey. Which means I can now go and remove email authentication, but it does carry a risk:
This is a good point to reflect on the paradox that securing your digital life presents: as we seek stronger forms of authentication, we create different risks. Losing all your forms of non-phishable 2FA, for example, creates the risk of losing access to your account. But we also have mitigating controls: your digital passkey is managed totally independently of your physical one so the chances of losing both are extremely low. Plus, best practice is usually to have two U2F keys and enrol them both (I always take one with me when I travel, and leave another one at home). New levels of security, new risks, new mitigations.
All that's great, but beyond my examples above, who actually supports passkeys?! A rapidly expanding number of services, many of which 1Password has documented in their excellent passkeys.directory website:
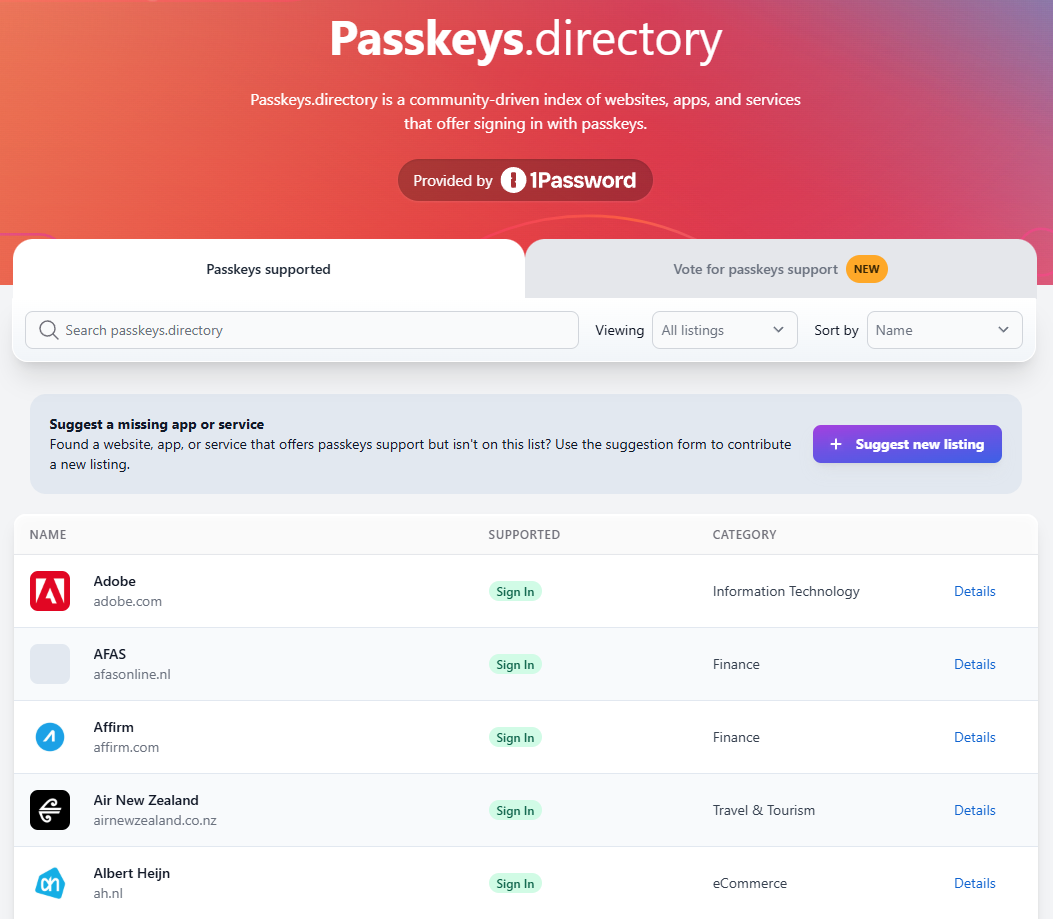
Have a look through the list there, and you'll see many very familiar brands. You won't see Ubiquiti as of the time of writing, but I've gone through the "Suggest new listing" process to have them added and will be chatting further with the 1Password folks to see how we can more rapidly populate that list.
Do also take a look at the "Vote for passkeys support" tab and if you see a brand that really should be there, make your voice heard. Hey, here's a good one to start voting for:
I've deliberately just focused on the mechanics of passkeys in this blog post, but let me take just a moment to highlight important separate but related concepts. Think of passkeys as one part of what we call "defence in depth", that is the application of multiple controls to help keep you safe online. For example, you should still treat emails containing links with a healthy suspicion and whenever in doubt, not click anything and independently navigate to the website in question via your browser. You should still have strong, unique passwords and use a password manager to store them. And you should probably also make sure you're fully awake and not jet lagged in bed before manually entering your credentials into a website your password manager didn't autofill for you 🙂
We're not at the very beginning of passkeys, and we're also not yet quite at the tipping point either... but it's within sight. Just last week, Microsoft announced that new accounts will be passwordless by default, with a preference to using passkeys. Whilst passkeys are by no means perfect, look at what they're replacing! Start using them now on your most essential services and push those that don't support them to genuinely take the security of their customers seriously.
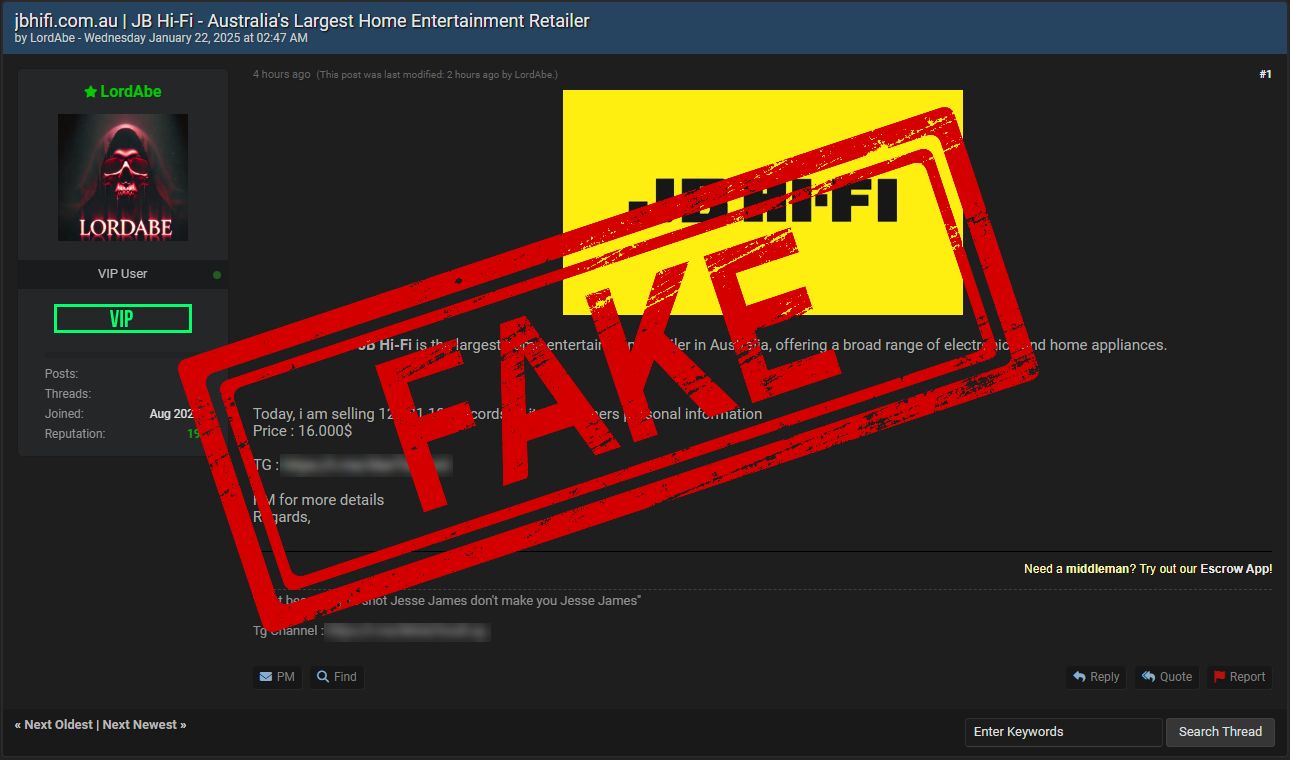
It's hard to find a good criminal these days. I mean a really trustworthy one you can be confident won't lead you up the garden path with false promises of data breaches. Like this guy yesterday:
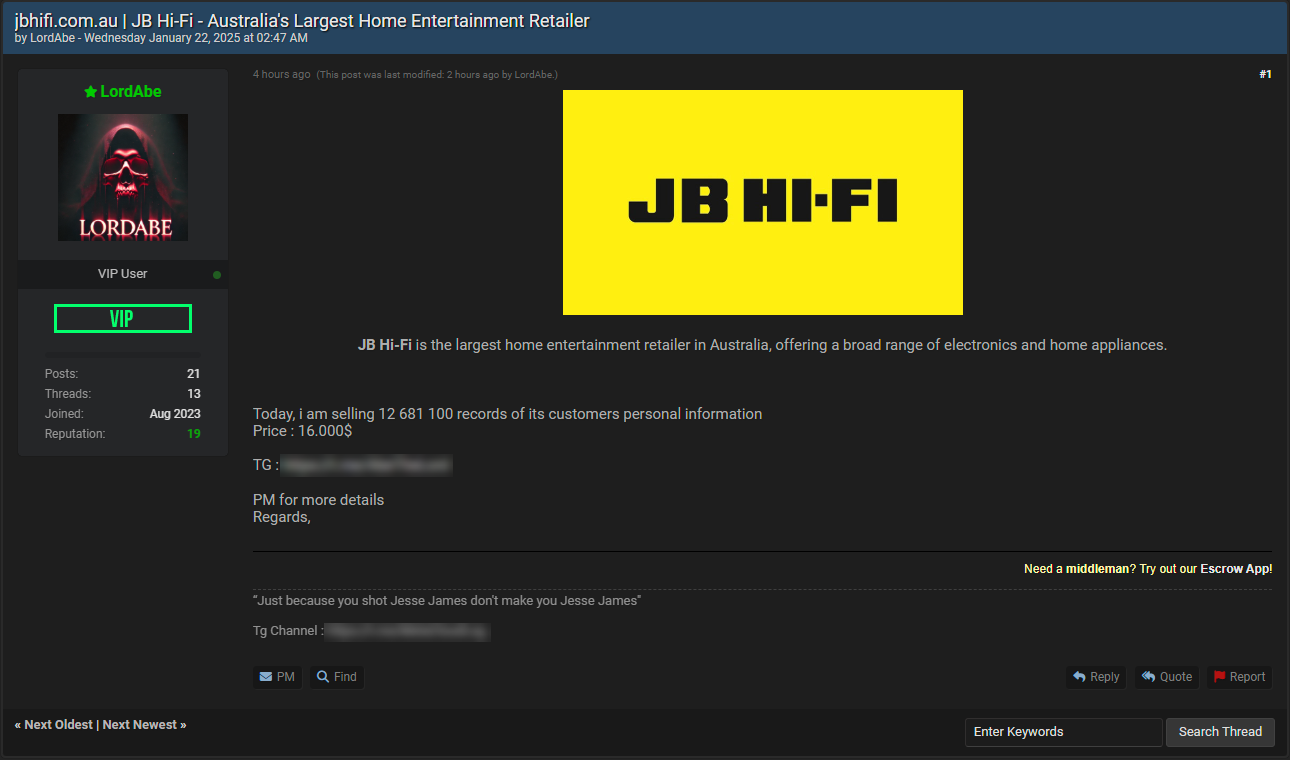
For my international friends, JB Hi-Fi is a massive electronics retailer down under and they have my data! I mean by design because I've bought a bunch of stuff from them, so I was curious not just about my own data but because a breach of 12 million plus people would be massive in a country of not much more than double that. So, I dropped the guy a message and asked if he'd be willing to help me verify the incident by sharing my own record. I didn't want to post any public commentary about this incident until I had a reasonable degree of confidence it was legit, not given how much impact it could have in my very own backyard.
Now, I wouldn't normally share a private conversation with another party, but when someone sets out to scam people, that rule goes out the window as far as I'm concerned. So here's where the conversation got interesting:
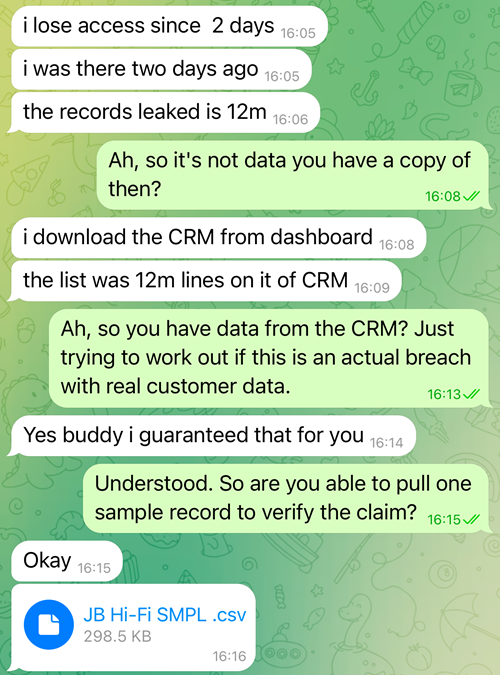
He guaranteed it for me! Sounds legit. But hey, everyone gets the benefit of the doubt until proven otherwise, so I started looking at the data. It turns out my own info wasn't in the full set, but he was happy to provide a few thousand sample records with 14 columns:
Pretty standard stuff, could be legit, let's check. I have a little Powershell script I run against the HIBP API when a new alleged breach comes in and I want to get a really good sense of how unique it is. It simply loops through all the email addresses in a file, checks which breaches they've been in and keeps track of the percentage that have been seen before. A unique breach will have anywhere from about 40% to 80% previously seen addresses, but this one had, well, more:
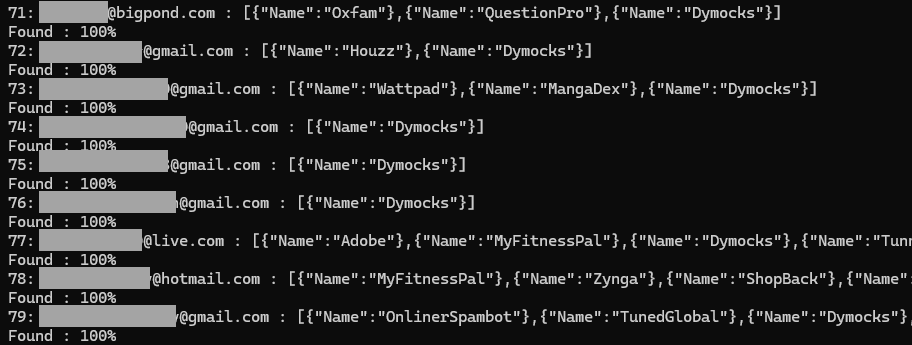
Spot the trend? Every single address has one breach in common. Hmmm... wonder what the guy has to say about that?
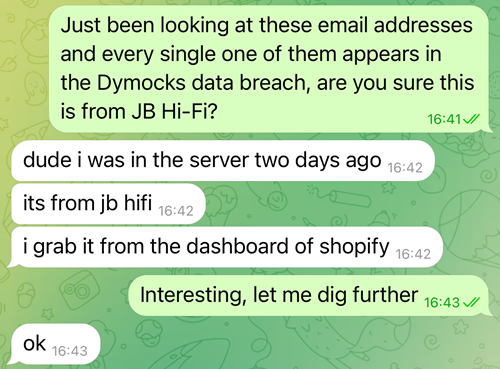
But he was in the server! And he grabbed it from the dashboard of Shopify! Must be legit, unless... what if I compared it to the actual full breach of Dymocks? That's a local Aussie bookseller (so it would have a lot of Aussie-looking email addresses in it, just like JB Hi-Fi would), and their breach dated back to mid-2023. I keep breaches like that on hand for just such occasions, let's compare the two:
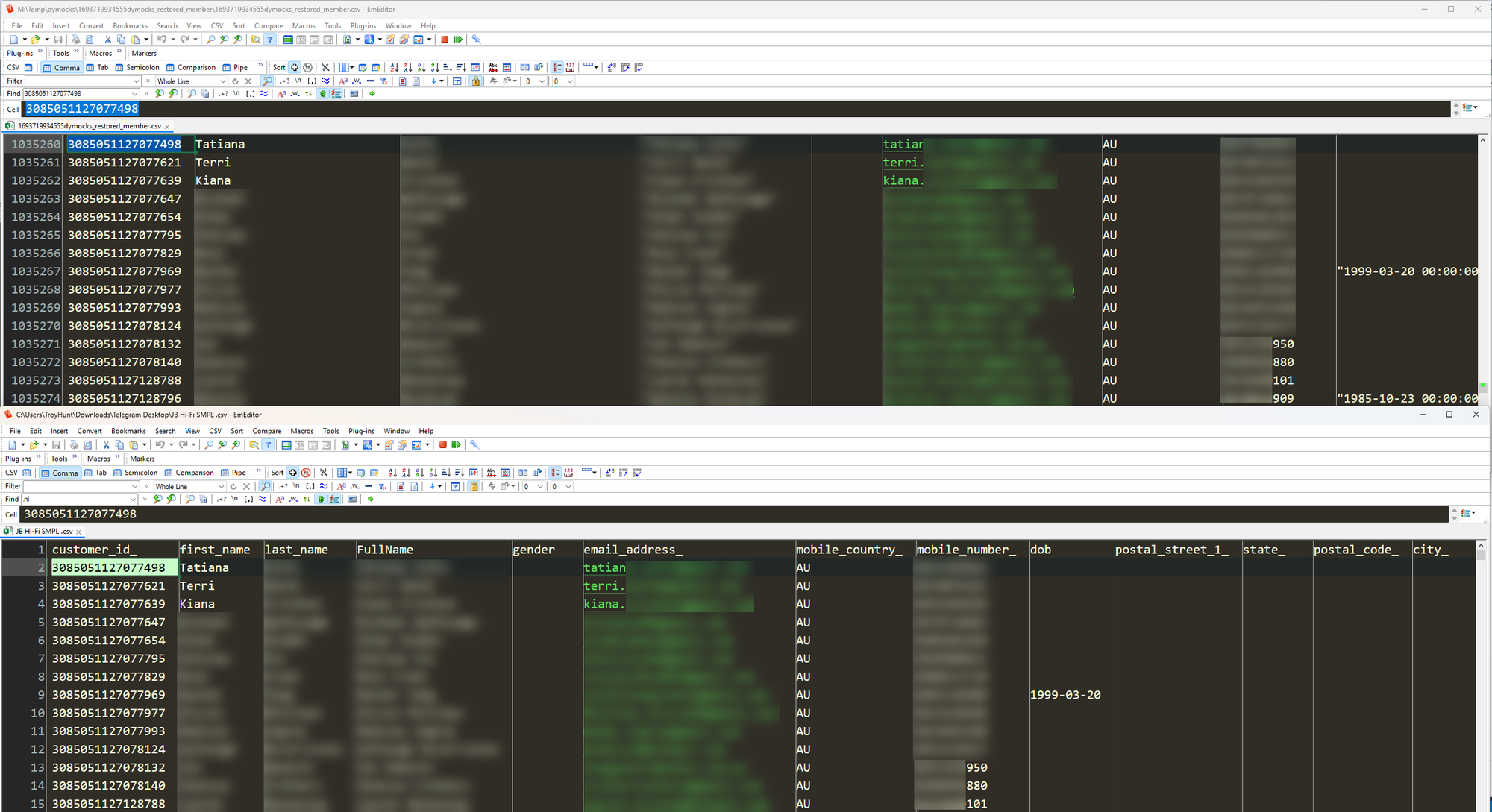
Wow! What are the chances?! He's going to be so interested when he hears about this!
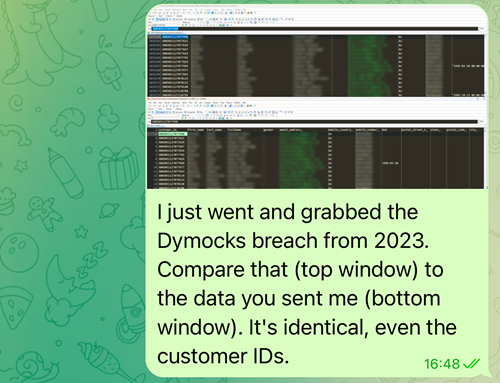
And that was it. The chat went silent and very shortly after, the listing was gone:
It looks like the bloke has also since been booted off the forum where he tried to run the scam so yeah, this one didn't work out great for him. That $16k would have been so tasty too!
I wrote this short post to highlight how important verification of data breach claims is. Obviously, I've seen loads of legitimate ones but I've also seen a lot of rubbish. Not usually this blatant where the party contacting me is making such demonstrably false claims about their own exploits, but very regularly from people who obtain something from another party and repeat the lie they've been told. This example also highlights how useful data from previous breaches is, even after the email addresses have been extracted and loaded into HIBP. Data is so often recycled and shipped around as something new, this was just a textbook perfect case of making use of a previous incident to disprove a new claim. Plus, it's kinda fun poking holes in a scamming criminal's claims 😊
I've spent more than a decade now writing about how to make Have I Been Pwned (HIBP) fast. Really fast. Fast to the extent that sometimes, it was even too fast:
The response from each search was coming back so quickly that the user wasn’t sure if it was legitimately checking subsequent addresses they entered or if there was a glitch.
Over the years, the service has evolved to use emerging new techniques to not just make things fast, but make them scale more under load, increase availability and sometimes, even drive down cost. For example, 8 years ago now I started rolling the most important services to Azure Functions, "serverless" code that was no longer bound by logical machines and would just scale out to whatever volume of requests was thrown at it. And just last year, I turned on Cloudflare cache reserve to ensure that all cachable objects remained cached, even under conditions where they previously would have been evicted.
And now, the pièce de résistance, the coolest performance thing we've done to date (and it is now "we", thank you Stefán): just caching the whole lot at Cloudflare. Everything. Every search you do... almost. Let me explain, firstly by way of some background:
When you hit any of the services on HIBP, the first place the traffic goes from your browser is to one of Cloudflare's 330 "edge nodes":
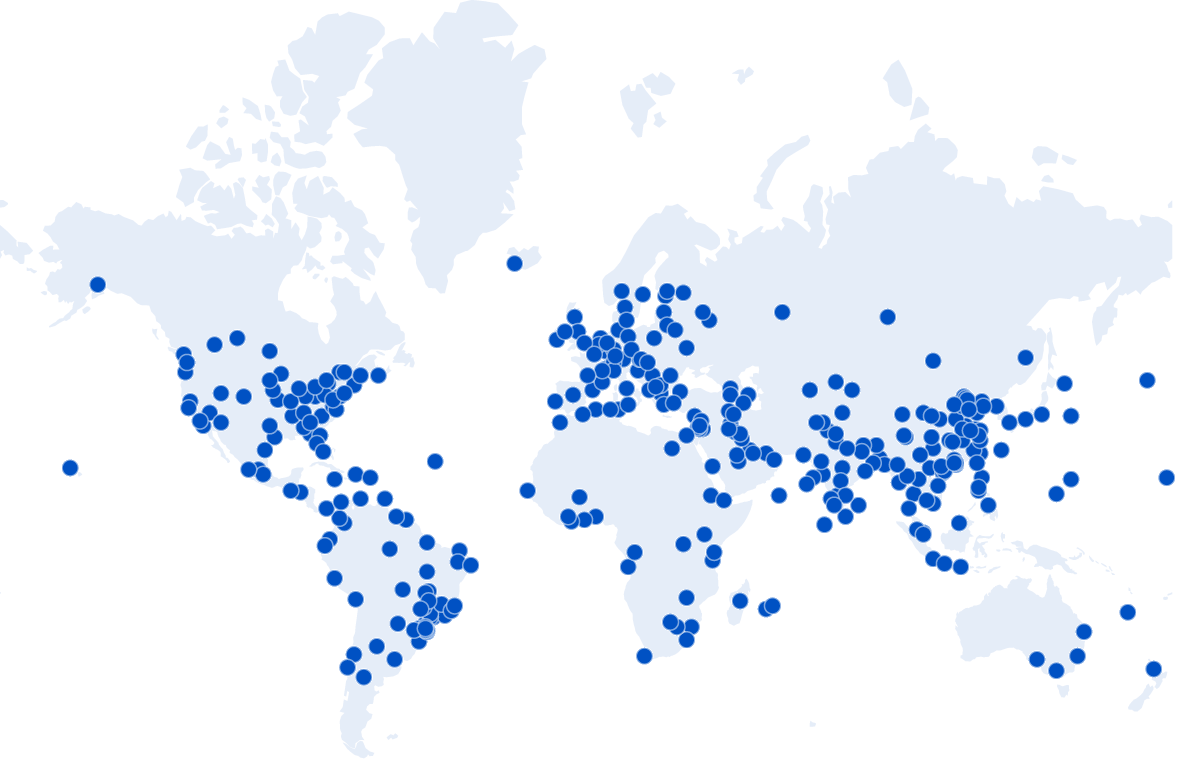
As I sit here writing this on the Gold Coast on Australia's most eastern seaboard, any request I make to HIBP hits that edge node on the far right of the Aussie continent which is just up the road in Brisbane. The capital city of our great state of Queensland is just a short jet ski away, about 80km as the crow flies. Before now, every single time I searched HIBP from home, my request bytes would travel up the wire to Brisbane and then take a giant 12,000km trip to Seattle where the Azure Function in the West US Azure data would query the database before sending the response 12,000km back west to Cloudflare's edge node, then the final 80km down to my Surfers Paradise home. But what if it didn't have to be that way? What if that data was already sitting on the Cloudflare edge node in Brisbane? And the one in Paris, and the one in well, I'm not even sure where all those blue dots are, but what if it was everywhere? Several awesome things would happen:
In short, pushing data and processing "closer to the edge" benefits both our customers and ourselves. But how do you do that for 5 billion unique email addresses? (Note: As of today, HIBP reports over 14 billion breached accounts, the number of unique email addresses is lower as on average, each breached address has appeared in multiple breaches.) To answer this question, let's recap on how the data is queried:
Let's delve into that last point further because it's the secret sauce to how this whole caching model works. In order to provide subscribers of this service with complete anonymity over the email addresses being searched for, the only data passed to the API is the first six characters of the SHA-1 hash of the full email address. If this sounds odd, read the blog post linked to in that last bullet point for full details. The important thing for now, though, is that it means there are a total of 16^6 different possible requests that can be made to the API, which is just over 16 million. Further, we can transform the first two use cases above into k-anonymity searches on the server side as it simply involved hashing the email address and taking those first six characters.
In summary, this means we can boil the entire searchable database of email addresses down to the following:
That's a large albeit finite list, and that's what we're now caching. So, here's what a search via email address looks like:
K-anonymity searches obviously go straight to step four, skipping the first few steps as we already know the hash prefix. All of this happens in a Cloudflare worker, so it's "code on the edge" creating hashes, checking cache then retrieving from the origin where necessary. That code also takes care of handling parameters that transform queries, for example, filtering by domain or truncating the response. It's a beautiful, simple model that's all self-contained within a worker and a very simple origin API. But there's a catch - what happens when the data changes?
There are two events that can change cached data, one is simple and one is major:
The second point is kind of frustrating as we've built up this beautiful collection of data all sitting close to the consumer where it's super fast to query, and then we nuke it all and go from scratch. The problem is it's either that or we selectively purge what could be many millions of individual hash prefixes, which you can't do:
For Zones on Enterprise plan, you may purge up to 500 URLs in one API call.
And:
Cache-Tag, host, and prefix purging each have a rate limit of 30,000 purge API calls in every 24 hour period.
We're giving all this further thought, but it's a non-trivial problem and a full cache flush is both easy and (near) instantaneous.
Enough words, let's get to some pictures! Here's a typical week of queries to the enterprise k-anonymity API:
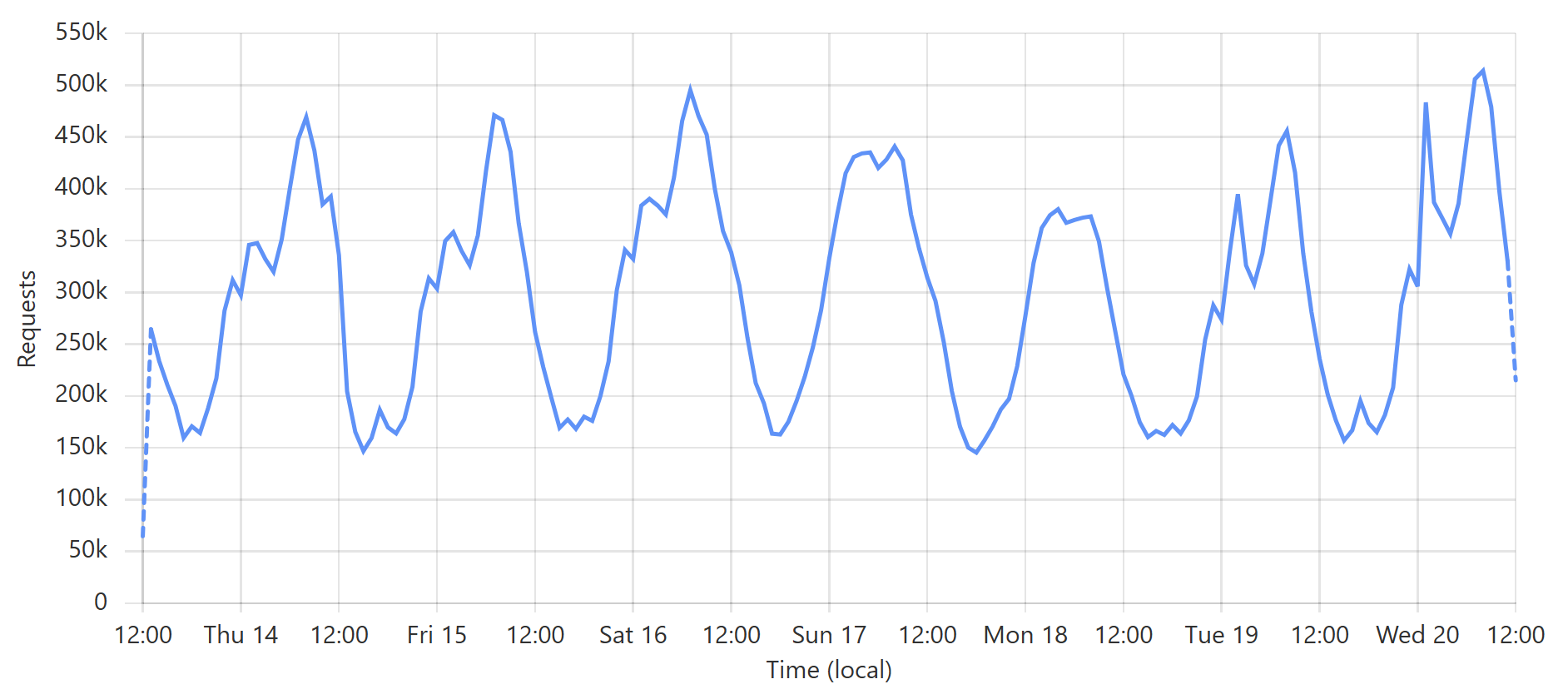
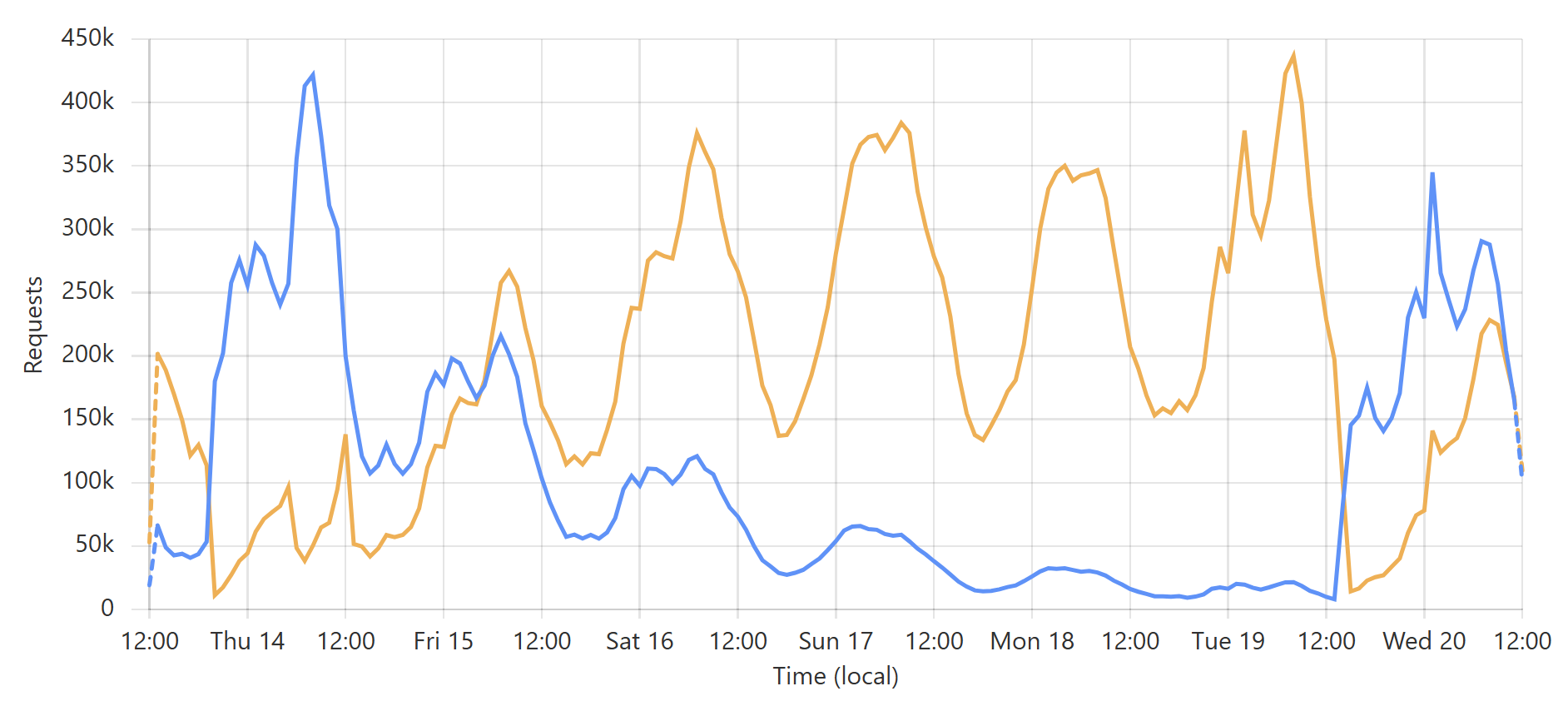
This is a very predictable pattern, largely due to one particular subscriber regularly querying their entire customer base each day. (Sidenote: most of our enterprise level subscribers use callbacks such that we push updates to them via webhook when a new breach impacts their customers.) That's the total volume of inbound requests, but the really interesting bit is the requests that hit the origin (blue) versus those served directly by Cloudflare (orange):
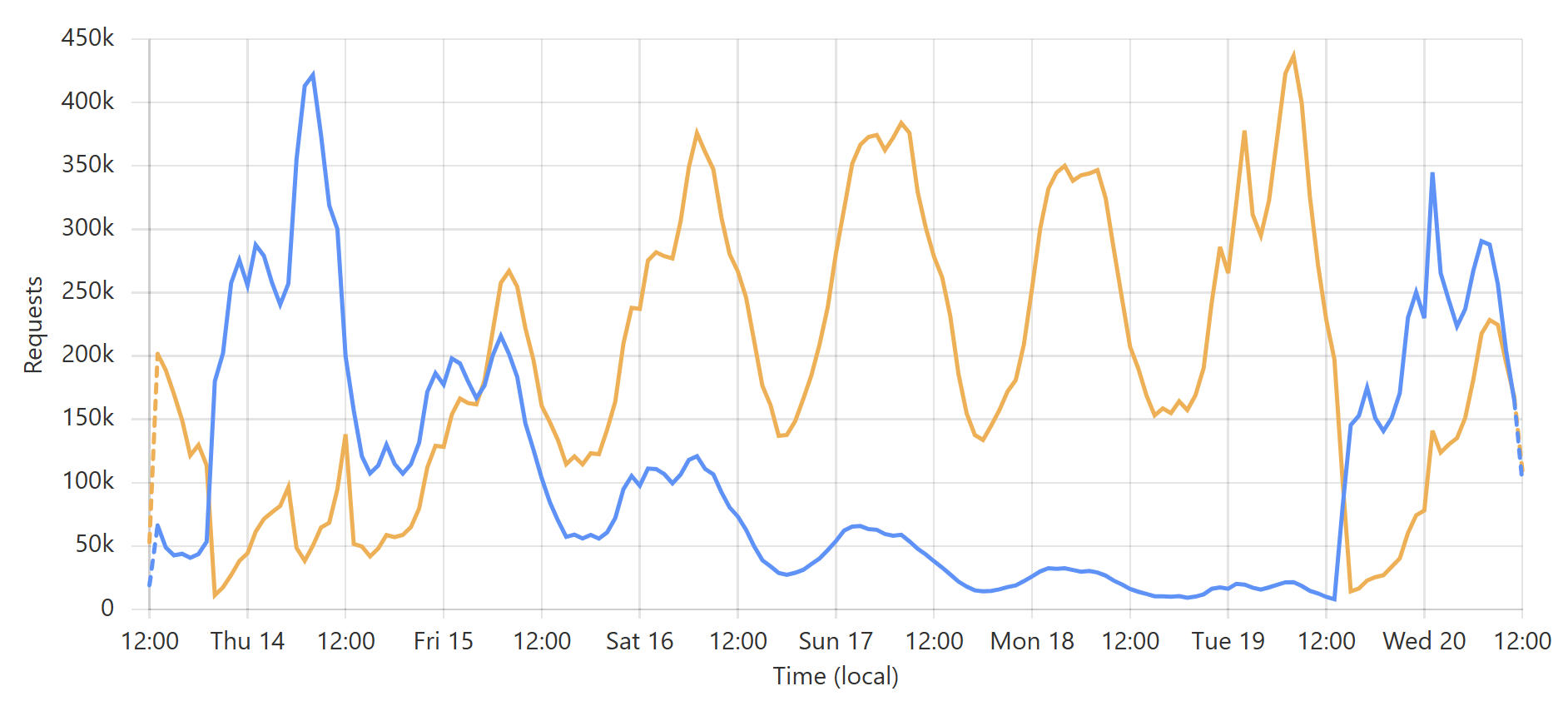
Let's take the lowest blue data point towards the end of the graph as an example:
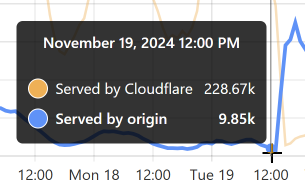
At that time, 96% of requests were served from Cloudflare's edge. Awesome! But look at it only a little bit later:
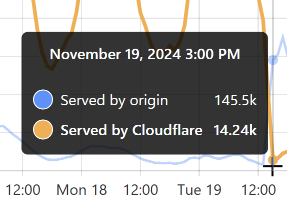
That's when I flushed cache for the Finsure breach, and 100% of traffic started being directed to the origin. (We're still seeing 14.24k hits via Cloudflare as, inevitably, some requests in that 1-hour block were to the same hash range and were served from cache.) It then took a whole 20 hours for the cache to repopulate to the extent that the hit:miss ratio returned to about 50:50:
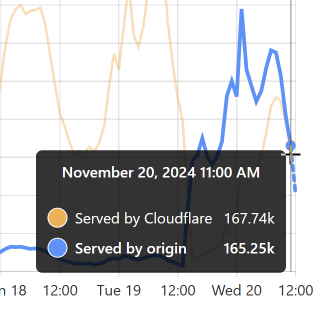
Look back towards the start of the graph and you can see the same pattern from when I loaded the DemandScience breach. This all does pretty funky things to our origin API:
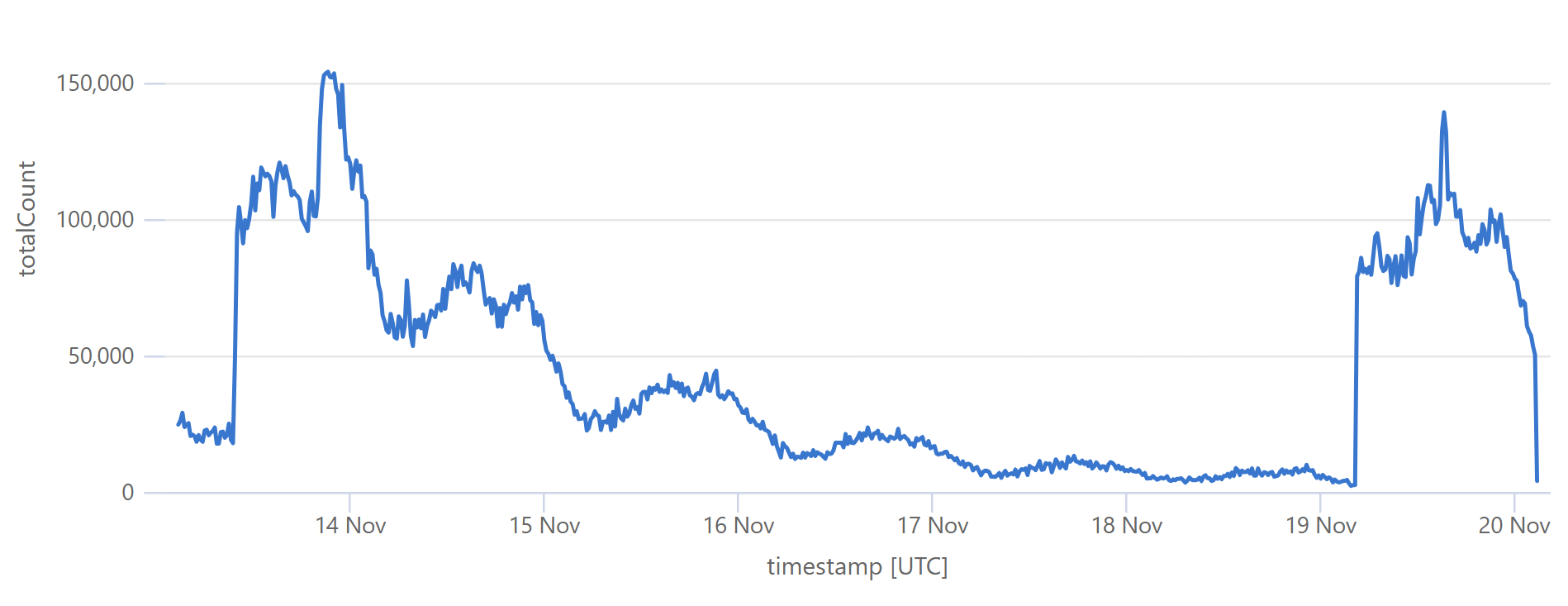
That last sudden increase is more than a 30x traffic increase in an instant! If we hadn't been careful about how we managed the origin infrastructure, we would have built a literal DDoS machine. Stefán will write later about how we manage the underlying database to ensure this doesn't happen, but even still, whilst we're dealing with the cyclical support patterns seen in that first graph above, I know that the best time to load a breach is later in the Aussie afternoon when the traffic is a third of what it is first thing in the morning. This helps smooth out the rate of requests to the origin such that by the time the traffic is ramping up, more of the content can be returned directly from Cloudflare. You can see that in the graphs above; that big peaky block towards the end of the last graph is pretty steady, even though the inbound traffic the first graph over the same period of time increases quite significantly. It's like we're trying to race the increasing inbound traffic by building ourselves up a bugger in cache.
Here's another angle to this whole thing: now more than ever, loading a data breach costs us money. For example, by the end of the graphs above, we were cruising along at a 50% cache hit ratio, which meant we were only paying for half as many of the Azure Function executions, egress bandwidth, and underlying SQL database as we would have been otherwise. Flushing cache and suddenly sending all the traffic to the origin doubles our cost. Waiting until we're back at 90% cache it ratio literally increases those costs 10x when we flush. If I were to be completely financially ruthless about it, I would need to either load fewer breaches or bulk them together such that a cache flush is only ejecting a small amount of data anyway, but clearly, that's not what I've been doing 😄
There's just one remaining fly in the ointment...
Of those three methods of querying email addresses, the first is a no-brainer: searches from the front page of the website hit a Cloudflare Worker where it validates the Turnstile token and returns a result. Easy. However, the second two models (the public and enterprise APIs) have the added burden of validating the API key against Azure API Management (APIM), and the only place that exists is in the West US origin service. What this means for those endpoints is that before we can return search results from a location that may be just a short jet ski ride away, we need to go all the way to the other side of the world to validate the key and ensure the request is within the rate limit. We do this in the lightest possible way with barely any data transiting the request to check the key, plus we do it in async with pulling the data back from the origin service if it isn't already in cache. In other words, we're as efficient as humanly possible, but we still cop a massive latency burden.
Doing API management at the origin is super frustrating, but there are really only two alternatives. The first is to distribute our APIM instance to other Azure data centres, and the problem with that is we need a Premium instance of the product. We presently run on a Basic instance, which means we're talking about a 19x increase in price just to unlock that ability. But that's just to go Premium; we then need at least one more instance somewhere else for this to make sense, which means we're talking about a 28x increase. And every region we add amplifies that even further. It's a financial non-starter.
The second option is for Cloudflare to build an API management product. This is the killer piece of this puzzle, as it would put all the checks and balances within the one edge node. It's a suggestion I've put forward on many occasions now, and who knows, maybe it's already in the works, but it's a suggestion I make out of a love of what the company does and a desire to go all-in on having them control the flow of our traffic. I did get a suggestion this week about rolling what is effectively a "poor man's API management" within workers, and it's a really cool suggestion, but it gets hard when people change plans or when we want to apply quotas to APIs rather than rate limits. So c'mon Cloudflare, let's make this happen!
Finally, just one more stat on how powerful serving content directly from the edge is: I shared this stat last month for Pwned Passwords which serves well over 99% of requests from Cloudflare's cache reserve:
There it is - we’ve now passed 10,000,000,000 requests to Pwned Password in 30 days 😮 This is made possible with @Cloudflare’s support, massively edge caching the data to make it super fast and highly available for everyone. pic.twitter.com/kw3C9gsHmB
— Troy Hunt (@troyhunt) October 5, 2024
That's about 3,900 requests per second, on average, non-stop for 30 days. It's obviously way more than that at peak; just a quick glance through the last month and it looks like about 17k requests per second in a one-minute period a few weeks ago:
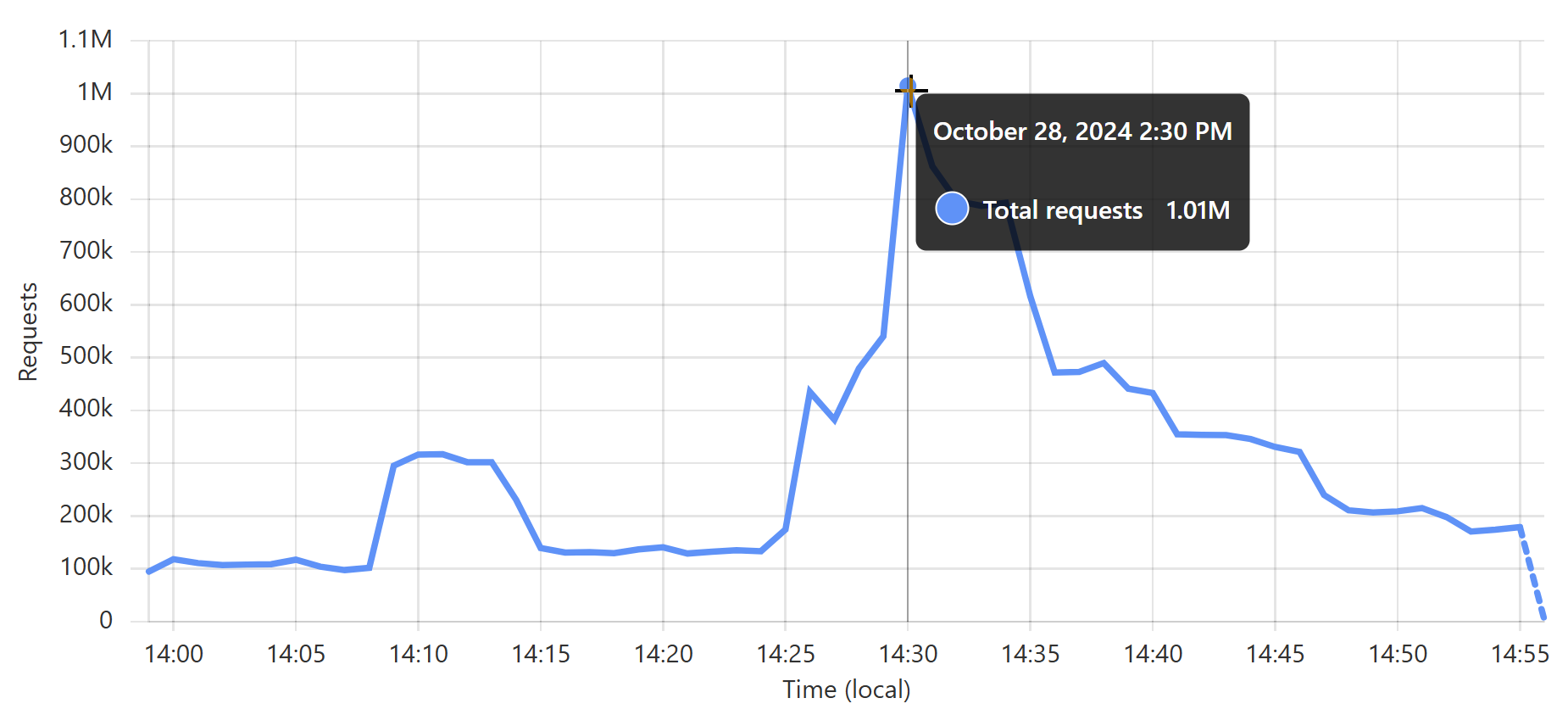
But it doesn't matter how high it is, because I never even think about it. I set up the worker, I turned on cache reserve, and that's it 😎
I hope you've enjoyed this post, Stefán and I will be doing a live stream on this topic at 06:00 AEST Friday morning for this week's regular video update, and it'll be available for replay immediately after. It's also embedded here for convenience:

The conundrum I refer to in the title of this post is the one faced by a breached organisation: disclose or suppress? And let me be even more specific: should they disclose to impacted individuals, or simply never let them know? I'm writing this after many recent such discussions with breached organisations where I've found myself wishing I had this blog post to point them to, so, here it is.
Let's start with tackling what is often a fundamental misunderstanding about disclosure obligations, and that is the legal necessity to disclose. Now, as soon as we start talking about legal things, we run into the problem of it being different all over the world, so I'll pick a few examples to illustrate the point. As it relates to the UK GDPR, there are two essential concepts to understand, and they're the first two bulleted items in their personal data breaches guide:
The UK GDPR introduces a duty on all organisations to report certain personal data breaches to the relevant supervisory authority. You must do this within 72 hours of becoming aware of the breach, where feasible.
If the breach is likely to result in a high risk of adversely affecting individuals’ rights and freedoms, you must also inform those individuals without undue delay.
On the first point, "certain" data breaches must be reported to "the relevant supervisory authority" within 72 hours of learning about it. When we talk about disclosure, often (not just under GDPR), that term refers to the responsibility to report it to the regulator, not the individuals. And even then, read down a bit, and you'll see the carveout of the incident needing to expose personal data that is likely to present a "risk to people’s rights and freedoms".
This brings me to the second point that has this massive carveout as it relates to disclosing to the individuals, namely that the breach has to present "a high risk of adversely affecting individuals’ rights and freedoms". We have a similar carveout in Australia where the obligation to report to individuals is predicated on the likelihood of causing "serious harm".
This leaves us with the fact that in many data breach cases, organisations may decide they don't need to notify individuals whose personal information they've inadvertently disclosed. Let me give you an example from smack bang in the middle of GDPR territory: Deezer, the French streaming media service that went into HIBP early January last year:
New breach: Deezer had 229M unique email addresses breached from a 2019 backup and shared online in late 2022. Data included names, IPs, DoBs, genders and customer location. 49% were already in @haveibeenpwned. Read more: https://t.co/1ngqDNYf6k
— Have I Been Pwned (@haveibeenpwned) January 2, 2023
229M records is a substantial incident, and there's no argument about the personally identifiable nature of attributes such as email address, name, IP address, and date of birth. However, at least initially (more on that soon), Deezer chose not to disclose to impacted individuals:
Chatting to @Scott_Helme, he never received a breach notification from them. They disclosed publicly via an announcement in November, did they never actually email impacted individuals? Did *anyone* who got an HIBP email get a notification from Deezer? https://t.co/dnRw8tkgLl https://t.co/jKvmhVCwlM
— Troy Hunt (@troyhunt) January 2, 2023
No, nothing … but then I’ve not used Deezer for years .. I did get this👇from FireFox Monitor (provided by your good selves) pic.twitter.com/JSCxB1XBil
— Andy H (@WH_Y) January 2, 2023
Yes, same situation. I got the breach notification from HaveIBeenPwned, I emailed customer service to get an export of my data, got this message in response: pic.twitter.com/w4maPwX0Qe
— Giulio Montagner (@Giu1io) January 2, 2023
This situation understandably upset many people, with many cries of "but GDPR!" quickly following. And they did know way before I loaded it into HIBP too, almost two months earlier, in fact (courtesy of archive.org):
This information came to light November 8 2022 as a result of our ongoing efforts to ensure the security and integrity of our users’ personal information
They knew, yet they chose not to contact impacted people. And they're also confident that position didn't violate any data protection regulations (current version of the same page):
Deezer has not violated any data protection regulations
And based on the carveouts discussed earlier, I can see how they drew that conclusion. Was the disclosed data likely to lead to "a high risk of adversely affecting individuals’ rights and freedoms"? You can imagine lawyers arguing that it wouldn't. Regardless, people were pissed, and if you read through those respective Twitter threads, you'll get a good sense of the public reaction to their handling of the incident. HIBP sent 445k notifications to our own individual subscribers and another 39k to those monitoring domains with email addresses in the breach, and if I were to hazard a guess, that may have been what led to this:
Is this *finally* the @Deezer disclosure notice to individuals, a month and a half later? It doesn’t look like a new incident to me, anyone else get this? https://t.co/RrWlczItLm
— Troy Hunt (@troyhunt) February 20, 2023
So, they know about the breach in Nov, and they told people in Feb. It took them a quarter of a year to tell their customers they'd been breached, and if my understanding of their position and the regulations they were adhering to is correct, they never needed to send the notice at all.
I appreciate that's a very long-winded introduction to this post, but it sets the scene and illustrates the conundrum perfectly: an organisation may not need to disclose to individuals, but if they don't, they risk a backlash that may eventually force their hand.
In my past dealing with organisations that were reticent to disclose to their customers, their positions were often that the data was relatively benign. Email addresses, names, and some other identifiers of minimal consequence. It's often clear that the organisation is leaning towards the "uh, maybe we just don't say anything" angle, and if it's not already obvious, that's not a position I'd encourage. Let's go through all the reasons:
I ask this question because the defence I've often heard from organisations choosing the non-disclosure path is that the data is theirs - the company's. I have a fundamental issue with this, and it's not one with any legal basis (but I can imagine it being argued by lawyers in favour of that position), rather the commonsense position that someone's email address, for example, is theirs. If my email address appears in a data breach, then that's my email address and I entrusted the organisation in question to look after it. Whether there's a legal basis for the argument or not, the assertion that personally identifiable attributes become the property of another party will buy you absolutely no favours with the individual who provided them to you when you don't let them know you've leaked it.
Picking those terms from earlier on, if my gender, sexuality, ethnicity, and, in my case, even my entire medical history were to be made public, I would suffer no serious harm. You'd learn nothing of any consequence that you don't already know about me, and personally, I would not feel that I suffered as a result. However...
For some people, simply the association of their email address to their name may have a tangible impact on their life, and using the term from above jeopardises their rights and freedoms. Some people choose to keep their IRL identities completely detached from their email address, only providing the two together to a handful of trusted parties. If you're handling a data breach for your organisation, do you know if any of your impacted customers are in that boat? No, of course not; how could you?
Further, let's imagine there is nothing more than email addresses and passwords exposed on a cat forum. Is that likely to cause harm to people? Well, it's just cats; how bad could it be? Now, ask that question - how bad could it be? - with the prevalence of password reuse in mind. This isn't just a cat forum; it is a repository of credentials that will unlock social media, email, and financial services. Of course, it's not the fault of the breached service that people reuse their passwords, but their breach could lead to serious harm via the compromise of accounts on totally unrelated services.
Let's make it even more benign: what if it's just email addresses? Nothing else, just addresses and, of course, the association to the breached service. Firstly, the victims of that breach may not want their association with the service to be publicly known. Granted, there's a spectrum and weaponising someone's presence in Ashley Madison is a very different story from pointing out that they're a LinkedIn user. But conversely, the association is enormously useful phishing material; it helps scammers build a more convincing narrative when they can construct their messages by repeating accurate facts about their victim: "Hey, it's Acme Corp here, we know you're a loyal user, and we'd like to make you a special offer". You get the idea.
I'll start this one in the complete opposite direction to what it sounds like it should be because this is what I've previously heard from breached organisations:
We don't want to disclose in order to protect our customers
Uh, you sure about that? And yes, you did read that paraphrasing correctly. In fact, here's a copy paste from a recent discussion about disclosure where there was an argument against any public discussion of the incident:
Our concern is that your public notification would direct bad actors to search for the file, which can potentially do harm to both the business and our mutual users.
The fundamental issue of this clearly being an attempt to suppress news of the incident aside, in this particular case, the data was already on a popular clear web hacking forum, and the incident has appeared in multiple tweets viewed by thousands of people. The argument makes no sense whatsoever; the bad guys - lots of them - already have the data. And the good guys (the customers) don't know about it.
I'll quote precisely from another company who took a similar approach around non-disclosure:
[company name] is taking steps to notify regulators and data subjects where it is legally required to do so, based on advice from external legal counsel.
By now, I don't think I need to emphasise the caveat that they inevitably relied on to suppress the incident, but just to be clear: "where it is legally required to do so". I can say with a very high degree of confidence that they never notified the 8-figure number of customers exposed in this incident because they didn't have to. (I hear about it pretty quickly when disclosure notices are sent out, and I regularly share these via my X feed).
Non-disclosure is intended to protect the brand and by extension, the shareholders, not the customers.
Usually, after being sent a data breach, the first thing I do is search for "[company name] data breach". Often, the only results I get are for a listing on a popular hacking forum (again, on the clear web) where their data was made available for download, complete with a description of the incident. Often, that description is wrong (turns out hackers like to embellish their accomplishments). Incorrect conclusions are drawn and publicised, and they're the ones people find when searching for the incident.
When a company doesn't have a public position on a breach, the vacuum it creates is filled by others. Obviously, those with nefarious intent, but also by journalists, and many of those don't have the facts right either. Public disclosure allows the breached organisation to set the narrative, assuming they're forthcoming and transparent and don't water it down such that there's no substance in the disclosure, of course.
All the way back in 2017, I wrote about The 5 Stages of Data Breach Grief as I watched The AA in the UK dig themselves into an ever-deepening hole. They were doubling down on bullshit, and there was simply no way the truth wasn't going to come out. It was such a predictable pattern that, just like with Kübler-Ross' stages of personal grief, it was very clear how this was going to play out.
If you choose not to disclose a breach - for whatever reason - how long will it be until your "truth" comes out? Tomorrow? Next month? Years from now?! You'll be looking over your shoulder until it happens, and if it does one day go public, how will you be judged? Which brings me to the next point:
I can't put any precise measure on it, but I feel we reached a turning point in 2017. I even remember where I was when it dawned on me, sitting in a car on the way to the airport to testify before US Congress on the impact of data breaches. News had recently broken that Uber had attempted to cover up its breach of the year before by passing it off as a bug bounty and, of course, not notifying impacted customers. What dawned on me at that moment of reflection was that by now, there had been so many data breaches that we were judging organisations not by whether they'd been breached but how they'd handled the breach. Uber was getting raked over the coals not for the breach itself but because they tried to conceal it. (Their CTO was also later convicted of federal charges for some of the shenanigans pulled under his watch.)
This is going to feel like I'm talking to my kids after they've done something wrong, but here goes anyway: If people entrusted you with your data and you "lost" it (had it disclosed to unauthorised parties), the only decent thing to do is own up and acknowledge it. It doesn't matter if it was your organisation directly or, as with the Deezer situation, a third party you entrusted with the data; you are the coalface to your customers, and you're the one who is accountable for their data.
I am yet to see any valid reasons not to disclose that are in the best interests of the impacted customers (the delay in the AT&T breach announcement at the request of the FBI due to national security interests is the closest I can come to justifying non-disclosure). It's undoubtedly the customers' expectation, and increasingly, it's the governments' expectations too; I'll leave you with a quote from our previous Cyber Security Minister Clare O'Neil in a recent interview:
But the real people who feel pain here are Australians when their information that they gave in good faith to that company is breached in a cyber incident, and the focus is not on those customers from the very first moment. The people whose data has been stolen are the real victims here. And if you focus on them and put their interests first every single day, you will get good outcomes. Your customers and your clients will be respectful of it, and the Australian government will applaud you for it.
I'm presently on a whirlwind North America tour, visiting government and law enforcement agencies to understand more about their challenges and where we can assist with HIBP. As I spend more time with these agencies around the world, I keep hearing that data breach victim notification is an essential piece of the cybersecurity story, and I'm making damn sure to highlight the deficiencies I've written about here. We're going to keep pushing for all data breach victims to be notified when their data is exposed, and my hope in writing this is that when it's read in future by other organisations I've disclosed to, they respect their customers and disclose promptly. Check out Data breach disclosure 101: How to succeed after you've failed for guidance and how to do this.
Edit (a couple of days later): I'm adding an addendum to this post given how relevant it is. I just saw the following from Ruben van Well of the Dutch Police, someone who has invested a lot of effort in victim notification and we had the pleasure of spending time with last year in Rotterdam:
To translate the key section:
Reporting and transparency around incidents is important. Of the companies that fall victim, between 8 and 10% report this, whether or not out of fear of reputational damage. I assume that your image will be more damaged if you do not report an incident and it does come out later.
It echos my sentiments from above precisely, and I hope that message has an impact on anyone considering whether or not to disclose.

I decided to write this post because there's no concise way to explain the nuances of what's being described as one of the largest data breaches ever. Usually, it's easy to articulate a data breach; a service people provide their information to had someone snag it through an act of unauthorised access and publish a discrete corpus of information that can be attributed back to that source. But in the case of National Public Data, we're talking about a data aggregator most people had never heard of where a "threat actor" has published various partial sets of data with no clear way to attribute it back to the source. And they're already the subject of a class action, to add yet another variable into the mix. I've been collating information related to this incident over the last couple of months, so let me talk about what's known about the incident, what data is circulating and what remains a bit of a mystery.
Let's start with the easy bit - who is National Public Data (NPD)? They're what we refer to as a "data aggregator", that is they provide services based on the large volumes of personal information they hold. From the front page of their website:
Criminal Records, Background Checks and more. Our services are currently used by investigators, background check websites, data resellers, mobile apps, applications and more.
There are many legally operating data aggregators out there... and there are many that end up with their data in Have I Been Pwned (HIBP). For example, Master Deeds, Exactis and Adapt, to name but a few. In April, we started seeing news of National Public Data and billions of breached records, with one of the first references coming from the Dark Web Intelligence account:
USDoD Allegedly Breached National Public Data Database, Selling 2.9 Billion Records https://t.co/emQIZ0lgsn pic.twitter.com/Tt8UNppPSu
— Dark Web Intelligence (@DailyDarkWeb) April 8, 2024
Back then, the breach was attributed to "USDoD", a name to remember as you'll see that throughout this post. The embedded image is the first reference of the 2.9B number we've subsequently seen flashed all over the press, and it's right there alongside the request of $3.5M for the data. Clearly, there is a financial motive involved here, so keep that in mind as we dig further into the story. That image also refers to 200GB of compressed data that expands out to 4TB when uncompressed, but that's not what initially caught my eye. Instead, something quite obvious in the embedded image doesn't add up: if this data is "the entire population of USA, CA and UK" (which is ~450M people in total), what's the 2.9B number we keep seeing? Because that doesn't reconcile with reports about "nearly 3 billion people" with social security numbers exposed. Further, SSNs are a rather American construct with Canada having SINs (Social Insurance Number) and the UK having, well, NI (National Insurance) numbers are probably the closestequivalent. This is the constant theme you'll read about in this post, stuff just being a bit... off. But hyperbole is often a theme with incidents like this, so let's take the headlines with a grain of salt and see what the data tells us.
I was first sent data allegedly sourced from NPD in early June. The corpus I received reconciled with what vx-underground reported on around the same time (note their reference to the 8th of April, which also lines up with the previous tweet):
April 8th, 2024, a Threat Actor operating under the moniker "USDoD" placed a large database up for sale on Breached titled: "National Public Data". They claimed it contained 2,900,000,000 records on United States citizens. They put the data up for sale for $3,500,000.
— vx-underground (@vxunderground) June 1, 2024
National…
In their message, they refer to having received data totalling 277.1GB uncompressed, which aligns with the sum total of the 2 files I received:
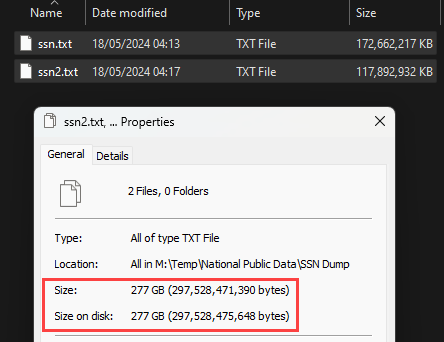
They also mentioned the data contains first and last names, addresses and SSNs, all of which appear in the first file above (among other fields):

These first rows also line up precisely with the post Dark Web Intelligence included in the earlier tweet. And in case you're looking at it and thinking "that's the same SSN repeated across multiple rows with different names", those records are all the same people, just with the names represented in different orders and with different addresses (all in the same city). In other words, those 6 rows only represent one person, which got me thinking about the ratio of rows to distinct numbers. Curious, I took 100M samples and found that only 31% of the rows had unique SSNs, so extrapolating that out, 2.9B would be more like 899M. This is something to always be conscious of when you read headline numbers: "2.9B" doesn't necessarily mean 2.9B people, it often means rows of data. Speaking of which, those 2 files contain 1,698,302,004 and 997,379,506 rows respectively for a combined total of 2.696B. Is this where the headline number comes from? Perhaps, it's close, and it's also precisely the same as Bleeping Computer reported a few days ago.
At this point in the story, there's no question that there is legitimate data in there. From the aforementioned Bleeping Computer story:
numerous people have confirmed to us that it included their and family members' legitimate information, including those who are deceased
And in vx-underground's tweet, they mention that:
It also allowed us to find their parents, and nearest siblings. We were able to identify someones parents, deceased relatives, Uncles, Aunts, and Cousins. Additionally, we can confirm this database also contains informed on individuals who are deceased. Some individuals located had been deceased for nearly 2 decades.
A quick tangential observation in the same tweet:
The database DOES NOT contain information from individuals who use data opt-out services. Every person who used some sort of data opt-out service was not present.
Which is what you'd expect from a legally operating data aggregator service. It's a minor point, but it does support the claim that the data came from NPD.
Important: None of the data discussed so far contains email addresses. That doesn't necessarily make it any less impactful for those involved, but it's an important point I'll come back to later as it relates to HIBP.
So, this data appeared in limited circulation as early as 3 months ago. It contains a huge amount of personal information (even if it isn't "2.9B people"), and then to make matters worse, it was posted publicly last week:
National Public Data, a service by Jerico Pictures Inc., suffered #databreach. Hacker “Fenice” leaked 2.9b records with personal details, including full names, addresses, & SSNs in plain text. https://t.co/fXY3SXEiKe
— Wolf Technology Group (@WolfTech) August 6, 2024
Who knows who "Fenice" is and what role they play, but clearly multiple parties had access to this data well in advance of last week. I've reviewed what they posted, and it aligns with what I was sent 2 months ago, which is bad. But on the flip side, at least it has allowed services designed to protect data breach victims to get notices out to them:
Twice this week I was alerted my SSN was found on the web thanks to a data breach at National Public Data. Cool. Thanks guys. pic.twitter.com/FAlfNmXUqm
— MrsNineTales (@MrsNineTales) August 8, 2024
Inevitably, breaches of this nature result in legal action, which, as I mentioned in the opening paragraph, began a couple of weeks ago. It looks like a tip-off from a data protection service was enough for someone to bring a case against NPD:
Named plaintiff Christopher Hofmann, a California resident, said he received a notification from his identity-theft protection service provider on July 24, notifying him that his data was exposed in a breach and leaked on the dark web.
Up until this point, pretty much everything lines up, but for one thing: Where is the 4TB of data? And this is where it gets messy as we're now into the territory of "partial" data. For example, this corpus from last month was posted to a popular hacking forum:
National Public Database Allegedly Partially Leaked
— Dark Web Intelligence (@DailyDarkWeb) July 23, 2024
It is stated that nearly 80 GB of sensitive data from the National Public Data is available.
The post contains different credits for the leakage and the alleged breach was credited to a threat actor “Sxul” and stressed that it… https://t.co/v8uq0o88NS pic.twitter.com/a6dn3MvYkf
That's 80GB, and whilst it's not clear whether that's the size of the compressed or extracted archive, either way, it's still a long way short of the full alleged 4TB. Do take note of the file name in the embedded image, though - "people_data-935660398-959524741.csv" - as this will come up again later on.
Earlier this month, a 27-part corpus of data alleged to have come from NPD was posted to Telegram, this image representing the first 10 parts at 4GB each:
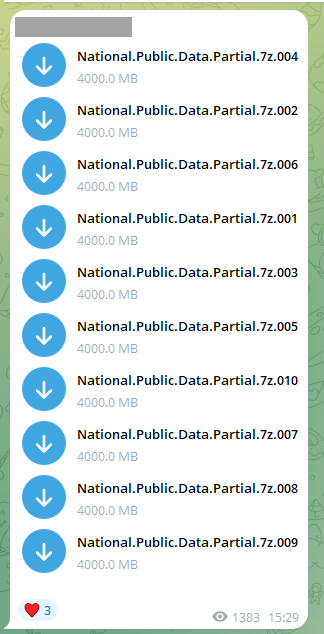
The compressed archive files totalled 104GB and contained what feels like a fairly random collection of data:
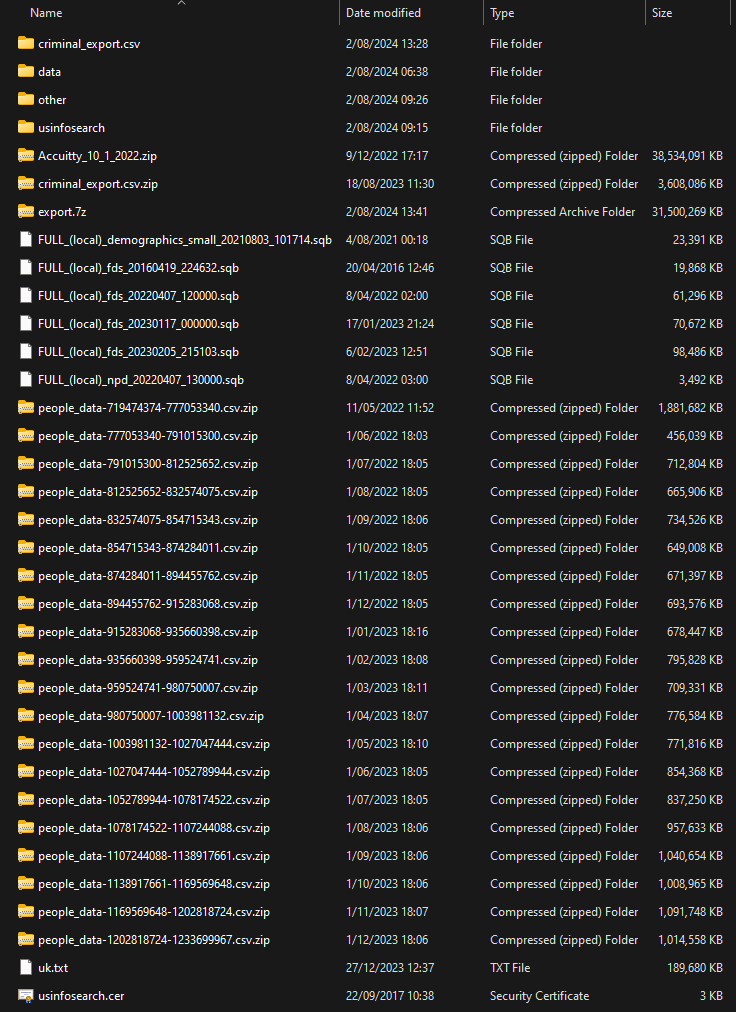
Many of these files are archives themselves, with many of those then containing yet more archives. I went through and recursively extracted everything which resulted in a total corpus of 642GB of uncompressed data across more than 1k files. If this is "partial", what was the story with the 80GB "partial" from last month? Who knows, but in the in those files above were 134M unique email addresses.
Just to take stock of where we're at, we've got the first set of SSN data which is legitimate and contains no email addresses yet is allegedly only a small part of the total NPD corpus. Then we've got this second set of data which is larger and has tens of millions of email addresses yet is pretty random in appearance. The burning question I was trying to answer is "is it legit?"
The problem with verifying breaches sourced from data aggregators is that nobody willingly - knowingly - provides their data to them, so I can't do my usual trick of just asking impacted HIBP subscribers if they'd used NPD before. Usually, I also can't just look at a data aggregator breach and find pointers that tie it back to the company in question due to references in the data mentioning their service. In part, that's because this data is just so damn generic. Take the earlier screenshot with the SSN data; how many different places have your first and last name, address, SSN, etc? Attributing a source when there's only generic data to go by is extremely difficult.
The kludge of different file types and naming conventions in the image above worried me. Is this actually all from NPD? Usually, you'd see some sort of continuity, for example, a heap of .json files with similar names or a swathe of .sql files with each one representing a dumped table. The presence of "people_data-935660398-959524741.csv" ties this corpus together with the one from the earlier tweet, but then there's stuff like "Accuitty_10_1_2022.zip"; could that refer to Acuity (single "c", single "t") which I wrote about in November? HIBP isn't returning hits for email addresses in that folder against the Acuity I loaded last year, so no, it's a different corpus. But that archive alone ended up having over 250GB of data with almost 100M unique email addresses, so it forms a substantial part of the overall corpus of data.
The 3,608,086KB "criminal_export.csv.zip" file caught my eye, in part because criminal record checks are a key component NPD's services, but also because it was only a few months ago we saw another breach containing 70M rows from a US criminal database. And see who that breach was attributed to? USDoD, the same party whose name is all over the NPD breach. I did actually receive that data but filed it away and didn't load it into HIBP as there were no email addresses in it. I wonder if the data from that story lines up with the file in the image above? Let's check the archives:

Different file name, but hey, it's a 3,608,086KB file! Given the NPD breach initially occurred in April and the criminal data hit the news in May, it's entirely possible the latter was obtained from the former, but I couldn't find any mention of this correlation anywhere. (Side note: this is a perfect example of why I retain breaches in offline storage after processing because they're so often helpful when assessing the origin and legitimacy of new breaches).
Continuing the search for oddities, I decided to see if I myself was in there. On many occasions now, I've loaded a breach, started the notification process running, walked away from the PC then received an email from myself about being in the breach 🤦♂️ I'm continually surprised by the places I find myself in, including this one:
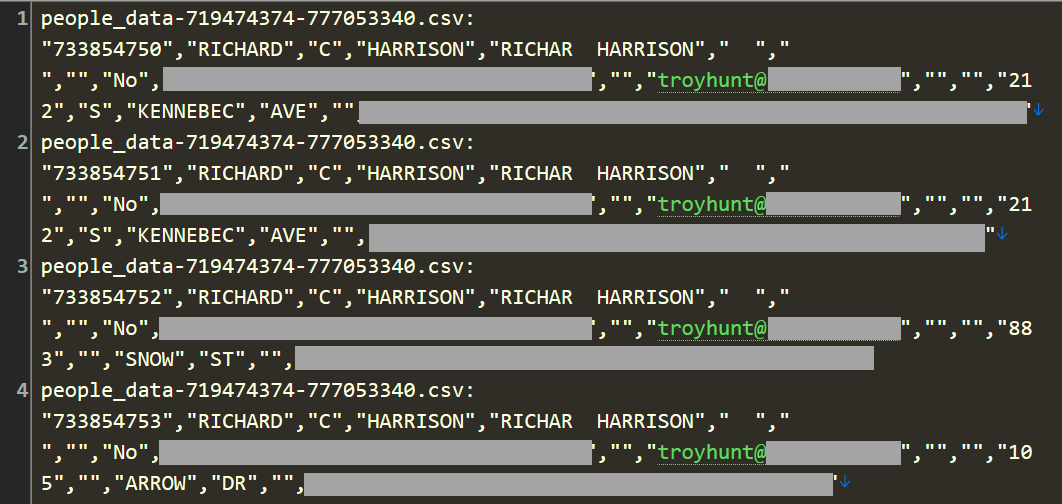
Dammit! It's an email address of mine, yet clearly, none of the other data is mine. Not my name, not my address, and the obfuscated numbers definitely aren't familiar to me (I don't believe they're SSNs or other sensitive identifiers, but because I can't be sure, I've obfuscated them). I suspect one of those numbers is a serialised date of birth, but of the total 28 rows with my email address on them, the two unique DoBs put "me" as being born in either 1936 or 1967. Both are a long way from the truth.
A cursory review of the other data in this corpus revealed a wide array of different personal attributes. One file contained information such as height, weight, eye colour, and ethnicity. The "uk.txt" file in the image above merely contained a business directory with public information. I could have dug deeper, but by now, there was no point. There's clearly some degree of invalid data in here, there's definitely data we've seen appear separately as a discrete breach, and there are many different versions of "partial" NPD data (although the 27-part archive discussed here is the largest I saw and the one I was most consistently directed to by other people). The more I searched, the more bits and pieces attributed back to NPD I found:
If I were to take a guess, there are two likely explanations for what we're seeing:
Both of these are purely speculative, though, and the only parties that know the truth are the anonymous threat actors passing the data around and the data aggregator that's now being sued in a class action, so yeah, we're not going to see any reliable clarification any time soon. Instead, we're left with 134M email addresses in public circulation and no clear origin or accountability. I sat on the fence about what to do with this data for days, not sure whether I should load it and, if I did, whether I should write about it. Eventually, I decided it deserved a place in HIBP as an unverified breach, and per the opening sentence, this blog post was the only way I could properly explain the nuances of what I discovered. This way, impacted people will know if their data is floating around in this corpus, and if they find this information unactionable, then they can do precisely what they would have done had I not loaded it - nothing.
Lastly, I want to re-emphasise a point I made earlier on: there were no email addresses in the social security number files. If you find yourself in this data breach via HIBP, there's no evidence your SSN was leaked, and if you're in the same boat as me, the data next to your record may not even be correct. And no, I don't have a mechanism to load additional attributes beyond email address into HIBP nor point people in the direction of the source data (some of you will have received a reminder about why I don't do that just a few days ago). And I'm definitely not equipped to be your personal lookup service, manually trawling through the data and pulling out individual records for you! So, treat this as informational only, an intriguing story that doesn't require any further action.

Last week, I wrote about The State of Data Breaches and got loads of feedback. It was predominantly sympathetic to the position I find myself in running HIBP, and that post was mostly one of frustration: lack of disclosure, standoffish organisations, downplaying breaches and the individual breach victims themselves making it worse by going to town on the corporate victims. But the other angle that's been milling around in my brain is the one represented by the image here:
Running HIBP has become a constant balancing act between a trilogy of three parties: hackers, corporate victims and law enforcement. Let me explain:
This is where most data breaches begin, with someone illegally accessing a protected system and snagging the data. That's a high-level generalisation, of course, but whether it's exploiting software vulnerabilities, downloading exposed database backups or phishing admin credentials and then grabbing the data, it's all in the same realm of taking something that isn't theirs. And sometimes, they contact me.
This is a hard position to find myself in, primarily because I need to weigh the potentially competing objectives of notifying impacted HIBP subscribers whilst simultaneously not pandering to the perverse incentives of likely criminals. Sometimes, it's easy: when someone reports exposed data or a security vulnerability, the advice is to contact the company involved and not turn it into a data breach. But when they already have the data, by definition it's now a breach and inevitably a bunch of my subscribers are in there. It's awkward, talking to the first party responsible for the breach.
There are all sorts of circumstances that may make it even more awkward, for example if the hacker is actively trying to shake the company down for money. Perhaps they're selling the data on the breach market. Maybe they also still have access to the corporate system. Having a discussion with someone in that position is delicate, and throughout it all, I'm conscious that they may very well end up in custody and every discussion we've had will be seen by law enforcement. Every single word I write is predicated on that assumption. And eventually, being caught is a very likely outcome; just as we say that as defenders we need to get it right every single time and the hacker only needs to get it right once, as hackers, they need to get their opsec right every single time and it only takes that one little mistake to bring them undone. A dropped VPN connection. An email address, handle or password used somewhere else that links to their identity. An incorrect assumption about the anonymity of cryptocurrency. One. Little. Mistake.
However, I also need to treat these discussions as confidential. The expectation when people reach out is that they can confide in me, and that's due to the trust I've built over more than a decade of running this service. Relaying those conversations without their permission could destroy that reputation in a heartbeat. So, I often find myself brokering conversations between the three parties mentioned here, providing contact details back and forth or relaying messages with the consent of each party.
This sort of communication gets messy: you've got the hacker (who's often suspicious of big corp) trying to draw attention to an issue, but they're trying to communicate with a party who's also naturally suspicious of anonymous characters who've accessed their data! And law enforcement is, of course, interested in the hacker because that's their job, but they're also respectful of the role I play and the confidence with which data is shared with me. Meanwhile, law enforcement is also often engaged by the corporate victim and now we've got all players conversing with each other and me in the middle.
I say this not to be grandiose about what I do, but to explain the delicate balance with which many of these data breaches need to be handled. Then, that's all wrapped in with the observations from the previous post about lack of urgency etc.
I choose to use this term because it's all too easy for people to point at a company that's suffered a data breach and level blame at them. Depending on the circumstances, some blame is likely warranted, but make no mistake: breached companies are usually the target of intentional, malicious, criminal activity. And when I say "companies", we're ultimately talking about individuals who are usually doing the best they can at their jobs and, during a period of incident response, are often having the worst time of their careers. I've heard the pain in their voices and seen the stress on their faces on so many prior occasions, and I want to make sure that the human element of this isn't lost amidst the chants of angry customers.
The way in which corporate victims engage with hackers is particularly delicate. They're understandably angry, but they're also walking the tightrope of trying to learn as much as they can about the incident (the vector by which data was obtained often isn't known in the early stages), whilst listening to often exorbitant demands and not losing their cool. It's very easy for the party who has always worked on the basis of anonymity to simply "go dark" and disappear altogether, and then what? We can see this balancing act in many of the communications later released by hackers, often after they've failed to secure the expected ransom payment; you have extremely polite corporations... who you know want nothing more than to have the guy thrown into prison!
The law enforcement angle, or perhaps, to put it more broadly, the interactions with government authorities in general, is an interesting one. Beyond the obvious engagements around the criminal activity of hackers, the corporate victims themselves have legal responsibilities. This is obviously highly dependent on jurisdiction and regulatory controls, but it may mean reporting the breach to the appropriate government entity, for example. It may even mean reporting to many government entities (i.e. state-based) depending on where they are in the world. Then there's the question of their own culpability and whether the actions they took (or didn't take) both pre and post-breach may result in punitive measures being taken. I had a headline in the previous post that included the term "covering their arses" and this doesn't just mean from customer or shareholder backlash, but increasingly, from massive corporate fines.
I suspect, based on many previous experiences, that corporations have a love-hate relationship with law enforcement. They obviously want their support when it comes to dealing with the criminals, but they're extraordinarily cautious about what they disclose lest it later contribute to the basis on which penalties are levelled against them. Imagine the balancing act involved when the corporate victims suspects the breach occurred due to some massive oversights on their behalf and they approach law enforcement for support: "So, how do you think they got in? Uh..."
Like I've already said so many times in this post: "delicate".
This is the most multidimensional player in the trilogy, interfacing backwards and forwards with each party in various ways. Most obviously, they're there to bring criminals to justice, and that clearly puts hackers well within their remit. I've often referred to "the FBI and friends" or similar terms that illustrate how much of a partnership international law enforcement efforts are, as is regularly evidenced by the takedown notices on cybercrime initiatives:

The hackers themselves are often all too eager to engage with law enforcement too. Sometimes to taunt, other times to outright target, often at a very individual level such as naming specific agents. It should be said also that "hacker" is a very broad term that, at its worst, is outright criminal activity intended to be destructive for their own financial gain. But at the other end of the scale is a much more nuanced space where folks who may be labelled with this title aren't necessarily malicious in their intent but to paraphrase: "I was poking around and I found something, can you help me report it to the authorities".
The engagement between law enforcement and corporate victims often begins with the latter reporting an incident. We see this all the time in disclosure statements "we've notified the authorities", and that's a very natural outcome following a criminal act. It's not just the hacking itself, this is often accompanied by a ransom demand which piles on yet another criminal activity that needs to be referred to the authorities. Conversely, law enforcement regularly sees early indications of compromise before the corporate victim does and is able to communicate that directly. Increasingly, we're seeing formal government entities issue much broader infosec advice, for example, as our Australian Signals Directorate regularly does.
I often end up finding myself in a variety of different roles with law enforcement agencies. For example, providing a pipeline for the FBI to feed breached passwords into, supporting the Estonian Central Criminal Police by making data impacting their citizens searchable, spending time with the Dutch police on victim notification, and even testifying in front of US Congress. And, of course, supporting three dozen national CERTs around the world with open access to exposure of their federal domains in HIBP. Many of these agencies also have a natural interest in the folks who contact me, especially from that first category listed above. That said, I've always found law enforcement to be respectful of the confidence with which hackers share information with me; they understand the importance of the trust I mentioned earlier on, and it's significance in playing the role I do.
A decade on, I still find this to be an odd space to occupy, sitting on the fringe and sometimes right in the middle of the interactions between these three parties. It's unpredictable, fascinating, exciting, stressful, and I hope you found this interesting reading 🙂

I've been harbouring some thoughts about the state of data breaches over recent months, and I feel they've finally manifested themselves into a cohesive enough story to write down. Parts of this story relate to very sensitive incidents and parts to criminal activity, not just on behalf of those executing data breaches but also very likely on behalf of some organisations handling them. As such, I'm not going to refer to any specific incidents or company names, rather I'm going to speak more generally to what I'm seeing in the industry.
Generally, when I disclose a breach to an impacted company, it's already out there in circulation and for all I know, the company is already aware of it. Or not. And that's the problem: a data breach circulating broadly on a popular clear web hacking forum doesn't mean the incident is known by the corporate victim. Now, if I can find press about the incident, then I have a pretty high degree of confidence that someone has at least tried to notify the company involved (journos generally reach out for comment when writing about a breach), but often that's non-existent. So, too, are any public statements from the company, and I very often haven't seen any breach notifications sent to impacted individuals either (I usually have a slew of these forwarded to me after they're sent out). So, I attempt to get in touch, and this is where the pain begins.
I've written before on many occasions about how hard it can be to contact a company and disclose a breach to them. Often, contact details aren't easily discoverable; if they are, they may be for sales, customer support, or some other capacity that's used to getting bombarded with spam. Is it any wonder, then, that so many breach disclosures that I (and others) attempt to make end up going to the spam folder? I've heard this so many times before after a breach ends up in the headlines - "we did have someone try to reach out to us, but we thought it was junk" - which then often results in news of the incident going public before the company has had an opportunity to respond. That's not good for anyone; the breached firm is caught off-guard, they may very well direct their ire at the reporter, and it may also be that the underlying flaw remains unpatched, and now you've got a bunch more people looking for it.
An approach like security.txt is meant to fix this, and I'm enormously supportive of this, but in my experience, there are usually two problems:
That one instance was so exceptional that, honestly, I hadn't even looked for the file before asking the public for a security contact at the firm. Shame on me for that, but is it any wonder?
Once I do manage to make contact, I'd say about half the time, the organisation is good to deal with. They often already know of HIBP and are already using it themselves for domain searches. We've joked before (the company and I) that they're grateful for the service but never wanted to hear from me!
The other half of the time, the response borders on open hostility. In one case that comes to mind, I got an email from their lawyer after finally tracking down a C-suite tech exec via LinkedIn and sending them a message. It wasn't threatening, but I had to go through a series of to-and-fro explaining what HIBP was, why I had their data and how the process usually unfolded. When in these positions, I find myself having to try and talk up the legitimacy of my service without sounding conceited, especially as it relates to publicly documented relationships with law enforcement agencies. It's laborious.
My approach during disclosure usually involves laying out the facts, pointing out where data has been published, and offering to provide the data to the impacted organisation if they can't obtain it themselves. I then ask about their timelines for notifying impacted customers and welcome their commentary to be included in the HIBP notifications sent to our subscribers. This last point is where things get more interesting, so let's talk about breach notifications.
This is perhaps one of my greatest bugbears right now and whilst the title will give you a pretty good sense of where I'm going, the nuances make this particularly interesting.
I suggest that most of us believe that if your personal information is compromised in a data breach, you'll be notified following this discovery by the organisation responsible for the service. Whether it's one day, one week, or even a month later isn't really the issue; frankly, any of these time frames would be a good step forward from where we frequently find ourselves. But constantly, I'm finding that companies are taking the position of consciously not notifying individuals at all. Let me give you a handful of examples:
During the disclosure process of a recent breach, it turned out the organisation was already aware of the incident and had taken "appropriate measures" (their term was something akin to that being vague enough to avoid saying what had been done, but, uh, "something" had been done). When pressed for a breach notice that would go to their customers, they advised they wouldn't be sending one as the incident had occurred more than 6 months ago. That stunned me - the outright admission that they wouldn't be communicating this incident - and in case you're thinking "this would never be allowed under GDPR", the company was HQ'd well within that scope being based in a major European city.
Another one that I need to be especially vague about (for reasons that will soon become obvious), involved a sizeable breach of customer data with the folks exposed inhabiting every corner of the globe. During my disclosure to them, I pushed them on a timeline for notifying victims and found their responses to be indirect but almost certainly indicating they'd never speak publicly about it. Statements to the effect of "we'll send notifications where we deem we're legally obligated to", which clearly left it up to them to make the determination. I later learned from a contact close to the incident that this particular organisation had an impending earnings call and didn't want the market to react negatively to news of a breach. "Uh, you know that's a whole different thing if they deliberately cover that up, right?"
An important point to make here, though, is that when it comes to companies themselves disclosing they've been breached, disclosure to individuals is often not what people think it is. In the various regulatory regimes we have across the globe, the legal requirement often stops at notifying the regulator and does not extend to notifying the individual victims. This surprises many people, and I constantly hear the rant of "But I'm in [insert your country here], and we have laws that demand I'm notified!" No, you almost certainly don't... but you should. We all should.
You can see further evidence by looking at recent Form 8-K SEC filings in the US. There are many examples of filings from companies that never notified the individuals themselves, yet here, you'll clearly see disclosure to the regulator. The breach is known, it's been reported in the public domain, but good luck ever getting an email about it yourself.
During one disclosure, I had the good fortune of a very close friend of mine working for the company involved in an infosec capacity. They were clearly stalling, being well over a week from my disclosure yet no public statements or notices to impacted individuals. I had a quiet chat with my contact, who explained it as follows:
Mate, it's a room full of lawyers working out how to spin this
Meanwhile, millions of records of customer data were in the hands of criminals, and every hour that went by was another hour victims went without any knowledge whatsoever that their personal info had been exposed. And as much as it pains me to say this, I get it: the company's priority is the company or, more specifically, the shareholders. That's who the board is accountable to, and maintaining the corporate reputation and profitability of the firm is their number one priority.
I see this all the time in post-breach communication too. One incident that comes to mind was the result of some egregiously stupid technical decisions. Once that breach hit the press, the CEO immediately went on the offence. Blame was laid firstly at those who obtained the data, then at me for my reporting of the incident (my own disclosure was absolutely "by the book").
I'm talking about class actions. I wrote about my views on this a few years ago and nothing has changed, other than it getting worse. I regularly hear from data breach victims about them wanting compensation for the impact a breach has had on them yet when pushed, most struggle to explain why. We've had multiple recent incidents in Australia where drivers' licences have been exposed and required reissuing, which is usually a process of going to a local transport office and waiting in a queue. "Are you looking for your time to be compensated for?", I asked one person. We have to rotate our licenses every 5 years anyway, so would you pro-rata that time based on the hourly value of your time and when you were due to be back in there anyway? And if there has been identity theft, was it from the breach you're now seeking compensation for? Or the other ones (both known and unknown) from which your data was taken?
Lawyers are a big part of the problem, and I still regularly hear from them seeking product placement on HIBP. What a time and a place to cash in if you could get your class action pitch right there in front of people at the moment they learn they were in a breach!
Frankly, I don't care too much about individuals getting a few bucks in compensation (and it's only ever a few), and I also don't even care about lawyers doing lawyer things. But I do care about the adverse consequences it has on the corporate victims, as it makes my job a hell of a lot harder when I'm talking to a company that's getting ready to get sued because of the information I've just disclosed to them.
These are all intertwined problems without single answers. But there are some clear paths forward:
Firstly, and this seems so obvious that it's frankly ridiculous I need to write it, but there should always be disclosure to individual victims. This may not need to be with the same degree of expeditiousness as disclosure to the regulator, but it has to happen. It is a harder problem for businesses; submitting a form to a gov body can be infinitely easier than emailing potentially hundreds of millions of breached customers. However, it is, without any doubt, the right thing to do and there should be legal constructs that mandate it.
Simultaneously providing protection from frivolous lawsuits where no material harm can be demonstrated and throwing the book at firms who deliberately conceal breaches also seems reasonable. No company is ever immune from a breach, and so frequently, it occurs not due to malicious behaviour by the organisation but a series of often unfortunate events. Ambitious lawyers shouldn't be in a position where they can make hell for a company at their worst possible hour unless there there is significant harm and negligence that can be clearly attributed back to the incident.
And then there's all the periphery stuff that pours fuel on the current dumpster fire. The aforementioned beg bounties that cause companies to be suspicious of even the most genuine disclosures, for example. On the other hand, the standoff-ish behaviour of many organisations receiving reports from folks who just want to see incidents disclosed. Flip side again is the number of people occupying that periphery of "security researcher / extortionist" who cause the aforementioned behaviours described in this paragraph. It's a mess, and writing it down like this makes it so abundantly apparent how many competing objectives there are.
I don't see anything changing any time soon, and anecdotally, it's worse now than it was 5 or 10 years ago. In part, I suspect that's due to how all those undesirable behaviours I described above have evolved over time, and in part I also believe the increasingly complexity of external dependencies is driving this. How many breaches have we seen in just the last year that can be attributed to "a third party"? I quote that term because it's often used by organisations who've been breached as though it somehow absolves them of some responsibility; "it wasn't us who was breached, it was those guys over there". Of course, it doesn't work that way, and more external dependencies leads to more points of failure, all of which you're still accountable for even if you've done everything else right.
Ah well, as I often end up lamenting, it's a fascinating time to be in the industry 🤷♂️
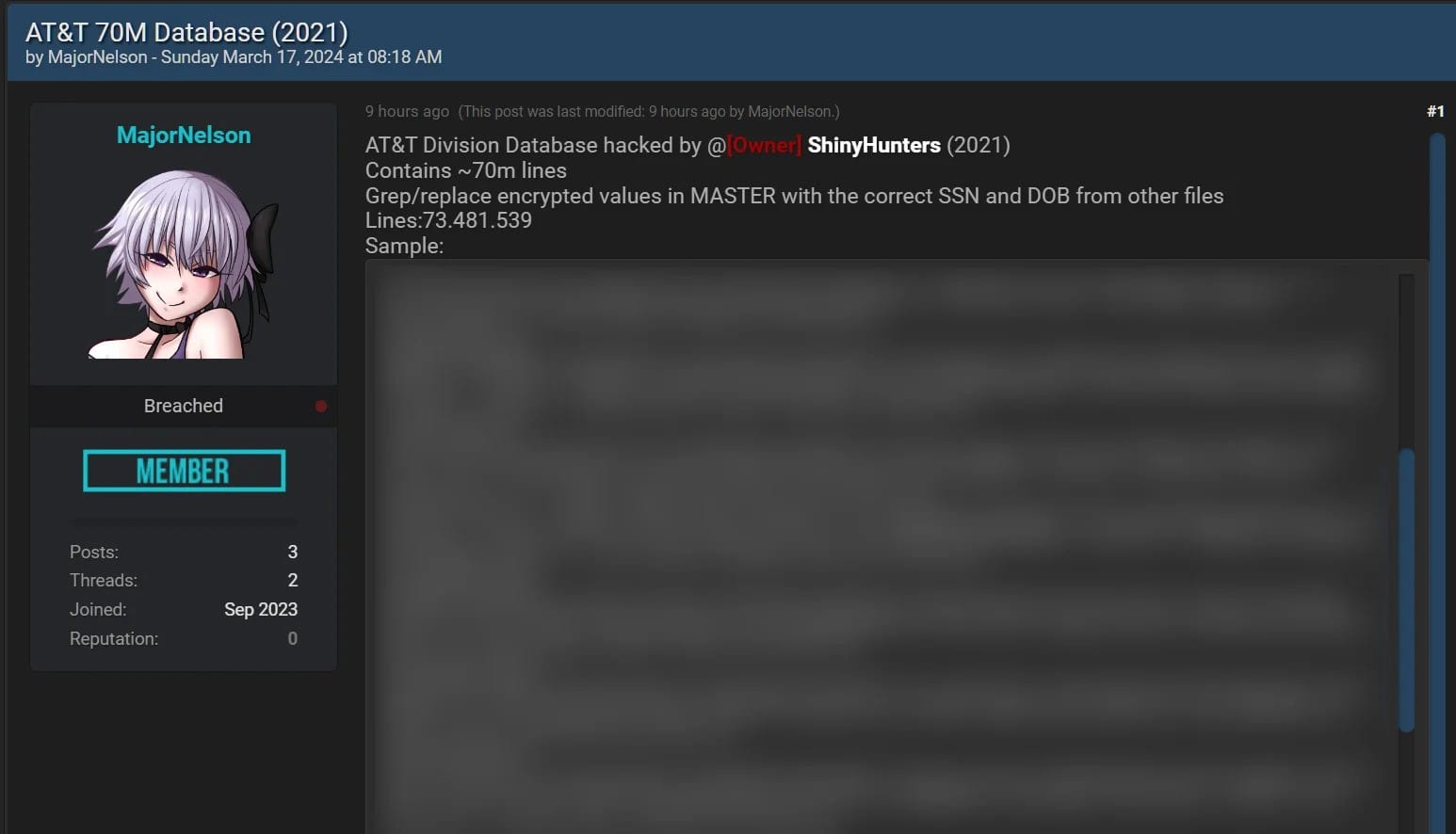
I hate having to use that word - "alleged" - because it's so inconclusive and I know it will leave people with many unanswered questions. (Edit: 12 days after publishing this blog post, it looks like the "alleged" caveat can be dropped, see the addition at the end of the post for more.) But sometimes, "alleged" is just where we need to begin and over the course of time, proper attribution is made and the dots are joined. We're here at "alleged" for two very simple reasons: one is that AT&T is saying "the data didn't come from us", and the other is that I have no way of proving otherwise. But I have proven, with sufficient confidence, that the data is real and the impact is significant. Let me explain:
Firstly, just as a primer if you're new to this story, read BleepingComputer's piece on the incident. What it boils down to is in August 2021, someone with a proven history of breaching large organisations posted what they claimed were 70 million AT&T records to a popular hacking forum and asked for a very large amount of money should anyone wish to purchase the data. From that story:
From the samples shared by the threat actor, the database contains customers' names, addresses, phone numbers, Social Security numbers, and date of birth.
Fast forward two and a half years and the successor to this forum saw a post this week alleging to contain the entire corpus of data. Except that rather than put it up for sale, someone has decided to just dump it all publicly and make it easily accessible to the masses. This isn't unusual: "fresh" data has much greater commercial value and is often tightly held for a long period before being released into the public domain. The Dropbox and LinkedIn breaches, for example, occurred in 2012 before being broadly distributed in 2016 and just like those incidents, the alleged AT&T data is now in very broad circulation. It is undoubtedly in the hands of thousands of internet randos.
AT&T's position on this is pretty simple:
AT&T continues to tell BleepingComputer today that they still see no evidence of a breach in their systems and still believe that this data did not originate from them.
The old adage of "absence of evidence is not evidence of absence" comes to mind (just because they can't find evidence of it doesn't mean it didn't happen), but as I said earlier on, I (and others) have so far been unable to prove otherwise. So, let's focus on what we can prove, starting with the accuracy of the data.
The linked article talks about the author verifying the data with various people he knows, as well as other well-known infosec identities verifying its accuracy. For my part, I've got 4.8M Have I Been Pwned (HIBP) subscribers I can lean on to assist with verification, and it turns out that 153k of them are in this data set. What I'll typically do in a scenario like this is reach out to the 30 newest subscribers (people who will hopefully recall the nature of HIBP from their recent memory), and ask them if they're willing to assist. I linked to the story from the beginning of this blog post and got a handful of willing respondents for whom I sent their data and asked two simple questions:
The first reply I received was simple, but emphatic:

This individual had their name, phone number, home address and most importantly, their social security number exposed. Per the linked story, social security numbers and dates of birth exist on most rows of the data in encrypted format, but two supplemental files expose these in plain text. Taken at face value, it looks like whoever snagged this data also obtained the private encryption key and simply decrypted the vast bulk (but not all of) the protected values.

The above example simply didn't have plain text entries for the encrypted data. Just by way of raw numbers, the file that aligns with the "70M" headline actually has 73,481,539 lines with 49,102,176 unique email addresses. The file with decrypted SSNs has 43,989,217 lines and the decrypted dates of birth file only has 43,524 rows. (Edit: the reason for this later became clear - there is only one entry per date of birth which is then referenced from multiple records.) The last file, for example, has rows that look just like this:
.encrypted_value='*0g91F1wJvGV03zUGm6mBWSg==' .decrypted_value='1996-07-18'That encrypted value is precisely what appears in the large file hence providing an easy way of matching all the data together. But those numbers also obviously mean that not every impacted individual had their SSN exposed, and most individuals didn't have their date of birth leaked. (Edit: per above, the same entries in the DoB file are referenced by multiple source records so whilst not every record had a DoB recorded, the difference isn't as stark as I originally reported.)

As I'm fond of saying, there's only one thing worse than your data appearing on the dark web: it's appearing on the clear web. And that's precisely where it is; the forum this was posted to isn't within the shady underbelly of a Tor hidden service, it's out there in plain sight on a public forum easily accessed by a normal web browser. And the data is real.
That last response is where most people impacted by this will now find themselves - "what do I do?" Usually I'd tell them to get in touch with the impacted organisation and request a copy of their data from the breach, but if AT&T's position is that it didn't come from them then they may not be much help. (Although if you are a current or previous customer, you can certainly request a copy of your personal information regardless of this incident.) I've personally also used identity theft protection services since as far back as the 90's now, simply to know when actions such as credit enquiries appear against my name. In the US, this is what services like Aura do and it's become common practice for breached organisations to provide identity protection subscriptions to impacted customers (full disclosure: Aura is a previous sponsor of this blog, although we have no ongoing or upcoming commercial relationship).
What I can't do is send you your breached data, or an indication of what fields you had exposed. Whilst I did this in that handful of aforementioned cases as part of the breach verification process, this is something that happens entirely manually and is infeasible en mass. HIBP only ever stores email addresses and never the additional fields of personal information that appear in data breaches. In case you're wondering why that is, we got a solid reminder only a couple of months ago when a service making this sort of data available to the masses had an incident that exposed tens of billions of rows of personal information. That's just an unacceptable risk for which the old adage of "you cannot lose what you do not have" provides the best possible fix.
As I said in the intro, this is not the conclusive end I wanted for this blog post... yet. As impacted HIBP subscribers receive their notifications and particularly as those monitoring domains learn of the aliases in the breach (many domain owners use unique aliases per service they sign up to), we may see a more conclusive outcome to this incident. That may not necessarily be confirmation that the data did indeed originate from AT&T, it could be that it came from a third party processor they use or from another entity altogether that's entirely unrelated. The truth is somewhere there in the data, I'll add any relevant updates to this blog post if and when it comes out.
As of now, all 49M impacted email addresses are searchable within HIBP.
Edit (31 March): AT&T have just released a short statement making 2 important points:
AT&T data-specific fields were contained in a data set
it is not yet known whether the data in those fields originated from AT&T or one of its vendors
They've also been mass-resetting account passcodes after TechCrunch apparently alerted AT&T to the presence of these in the data set. That article also includes the following statement from AT&T:
Based on our preliminary analysis, the data set appears to be from 2019 or earlier, impacting approximately 7.6 million current AT&T account holders and approximately 65.4 million former account holders
Between originally publishing this blog post and AT&T's announcements today, there have been dozens of comments left below that attribute the source of the breach to AT&T in ways that made it increasingly unlikely that the data could have been sourced from anywhere else. I know that many journos (and myself) reached out to folks in AT&T to draw their attention to this, I'm happy to now end this blog post by quoting myself from the opening para 😊
But sometimes, "alleged" is just where we need to begin and over the course of time, proper attribution is made and the dots are joined.
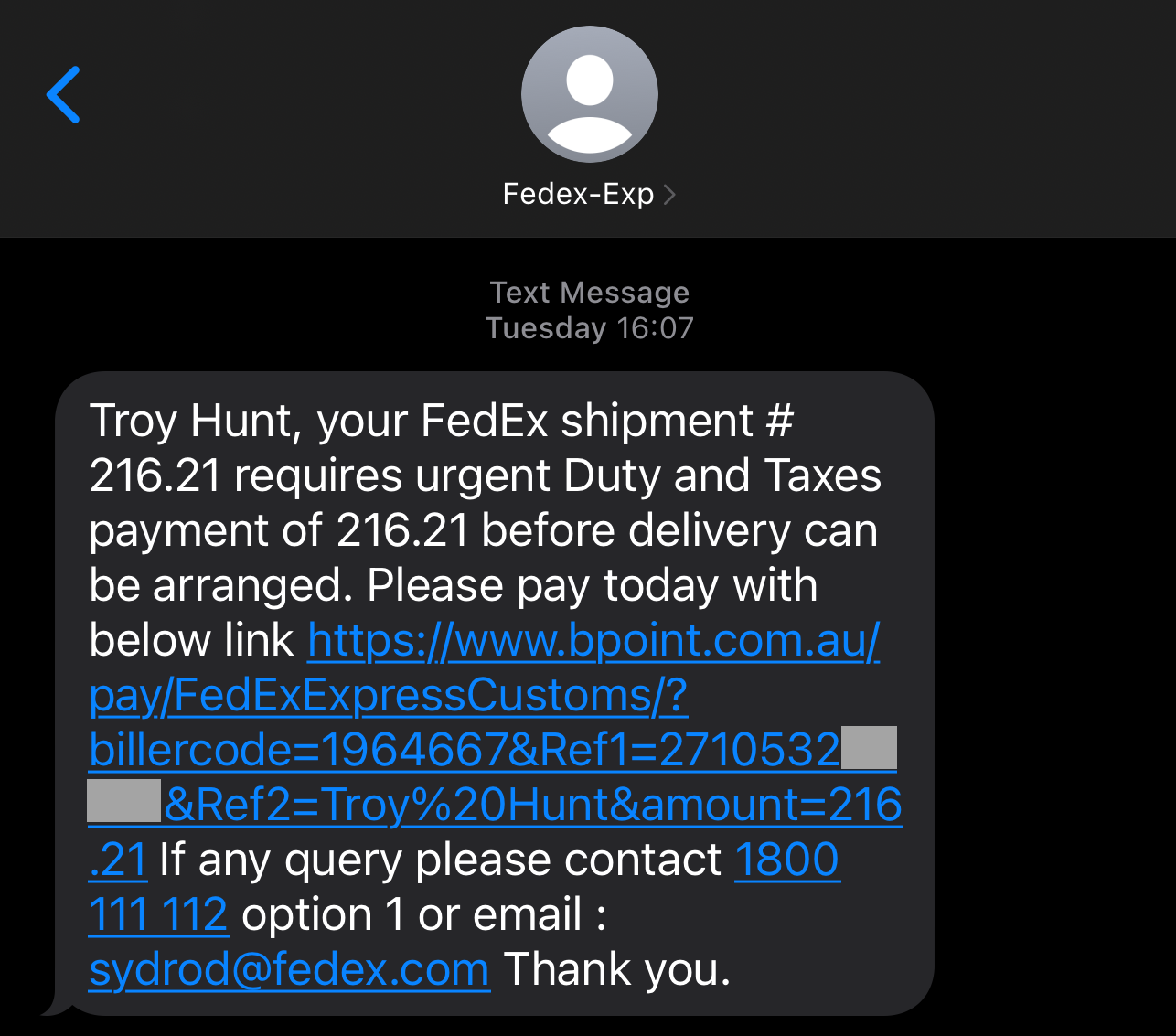
I've been getting a lot of those "your parcel couldn't be delivered" phishing attacks lately and if you're a human with a phone, you probably have been too. Just as a brief reminder, they look like this:

These get through all the technical controls that exist at my telco and they land smack bang in my SMS inbox. However, I don't fall for the scams because I look for the warning signs: a sense of urgency, fear of missing out, and strange URLs that look nothing like any parcel delivery service I know of. They have a pretty rough go of convincing me they're from Australia Post by putting "auspost" somewhere or other within each link, but I'm a smart human so I don't fall for this (that's a joke, read why humans are bad at URLs).
However... I am expecting a parcel. It's well into the 2020's and post COVID so I'm always expecting a parcel, because that's just how we buy stuff these days. And so, when I received the following SMS earlier this week I was expecting a parcel and I was expecting phishing attacks:
So... which is it? Parcel or phish? Let's see what the people say:
Referring to the parent tweet, is this message legit and should I pay the duty and taxes?
— Troy Hunt (@troyhunt) February 20, 2024
Whoa - that's an 87% "dodgy AF" vote from over 4,000 respondents so yeah, that's pretty emphatic. Why such an overwhelmingly suspicious crowd? Let's break that message down into 7 "dodgy AF" signs:
And so, I was with the 87% of other people. However... I was expecting a package. From FedEx. Coming from outside Australia so it may attract duty and taxes. And I really want to get this package because it's a new 3D printer from Prusa, and they're awesome!
There's a sage piece of advice that's always relevant in these cases and it's very simple: if in doubt, go the website in question and verify the request yourself. So, I went to the purchase confirmation from Prusa, found the shipping details and followed the link to the FedEx website. Now it was simply a matter of finding the section that talks about tax, except...

Dodgy. A. F.
I went all through that page and couldn't find a single reference to duty, nor for anything tax related. Try as I might, I couldn't establish the authenticity of the SMS by going directly to the (alleged) source. But what I could easily establish is that if you follow that link in the SMS, you can change the tracking number, the customer name and the amount to absolutely anything you want!
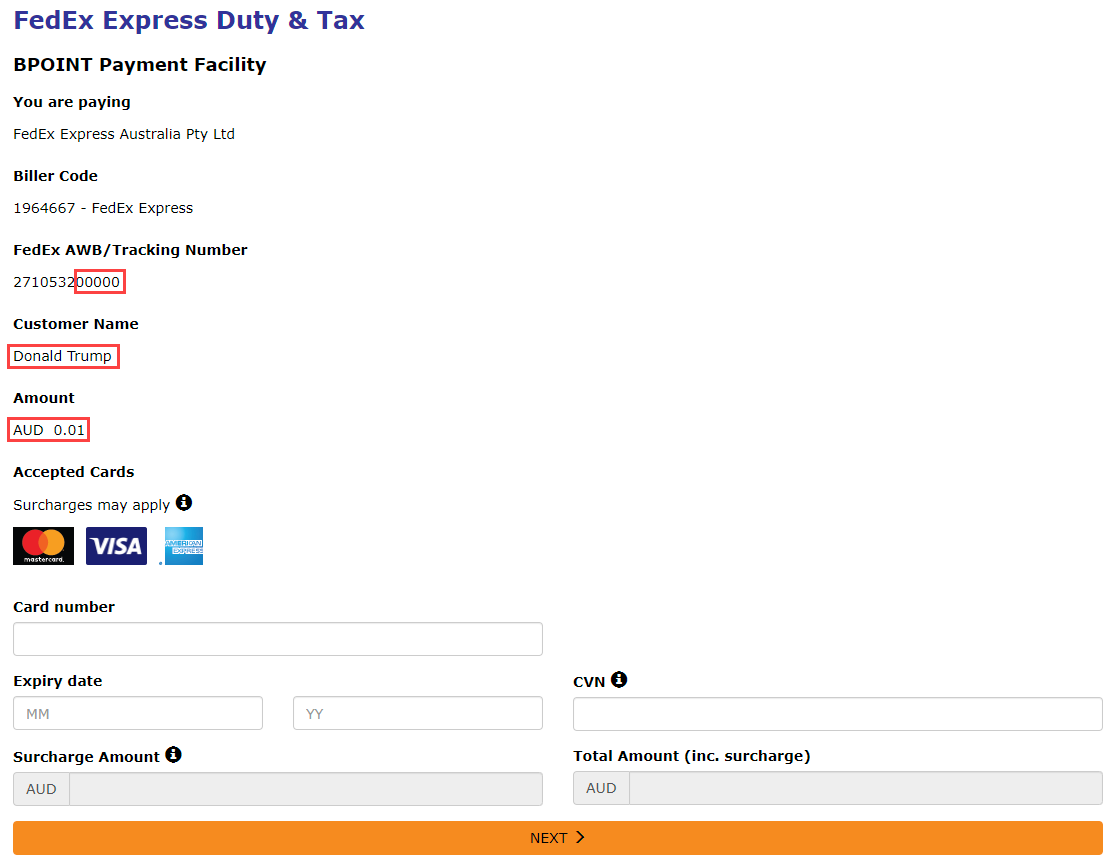
This is all done by simply changing the URL parameters; I'm not modifying the browser DOM or intercepting traffic or doing anything fancy, it's literally just query string parameter tampering reflected XSS style. This feels like every phishing site ever, not a payment service run by Australia's largest bank. Seriously, BPOINT is provided by the Commonwealth Bank and after the experience above, I'm at the point of reaching out to them and making a disclosure. Except that this is how the system was obviously designed to work and it's a completely parallel issue to phishy FedEx SMSs. Speaking of which, the very next morning I got another one from the same sender:
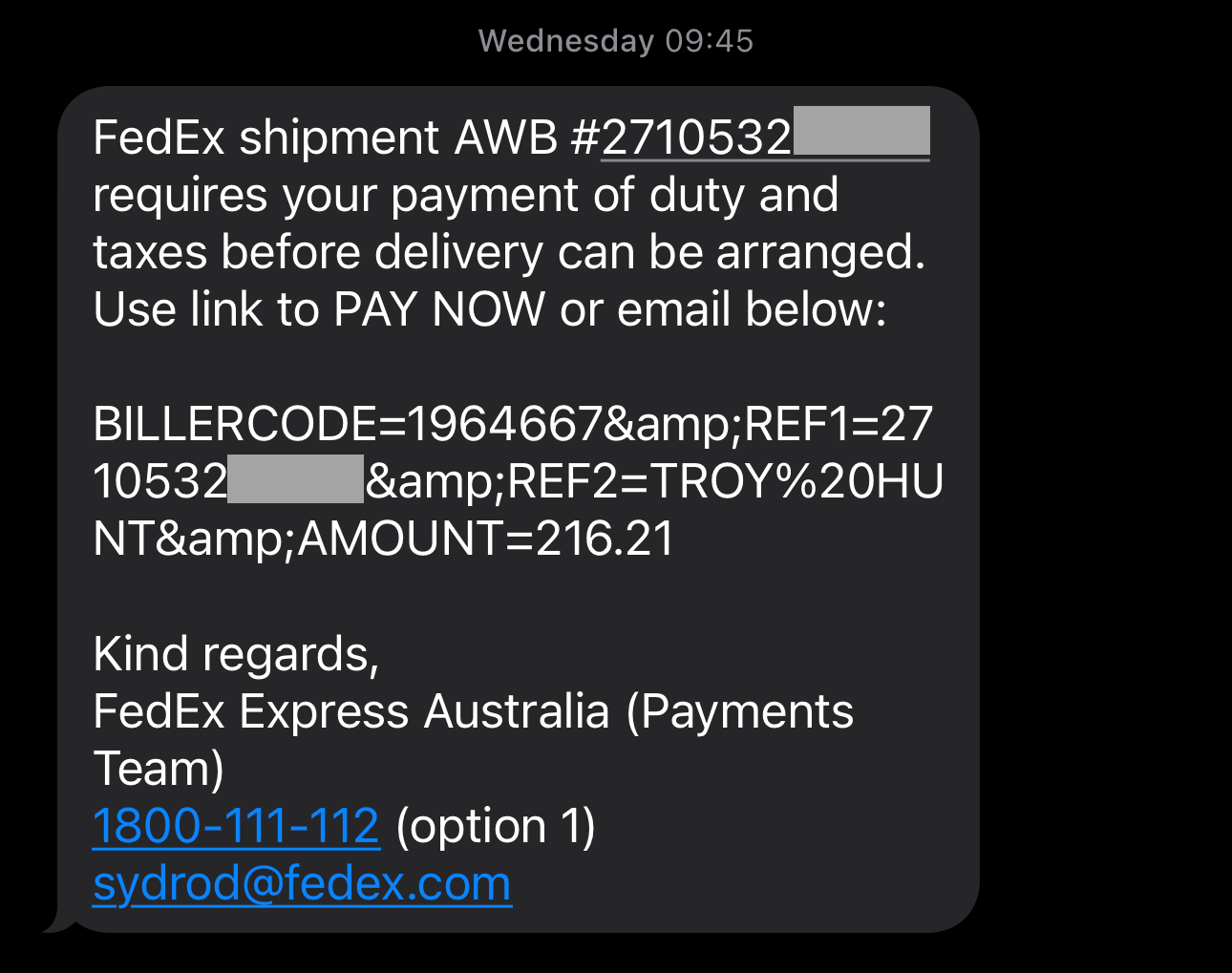
I don't know if this makes it better or worse 🤦♂️ Let's just jump into the highlights, both good and bad:
It's quite unbelievable what they've done with the link because it makes the SMS entirely unactionable. It's impossible to click anywhere and pay the money. And while I'm here, why are all the query string parameter names now capitalised? It's like there's a completely different (broken) process somewhere generating these links. Or scammers just aren't consistent...
Because "dodgy AF" is the prevailing theme, I needed to dig deeper, so I searched for the 1800 number. One of the first results was for a Reverse Australia page for that number which upon reading the first 3 comments, perfectly summed up the sentiment so far:
And the more you read both on that site and other top links in the search results, the more people are totally confused about the legitimacy of the messages. There's only one thing to do - call FedEx. Not by the number in the (still potentially phishy) SMS, but rather via the number on their website. So, click the "Support" menu item, down to "Customer Support" and we end up here:
I'll save you the pain of reading the response that ensued, suffice to say that it only referred to email communications and boiled down to suggesting you read the domain of the sender. But I did manage to pin the system down on a phone number which as you'll see, is completely different to the one in the SMS messages:
So, I call the number and follow the voice prompts, selecting options via the keypad to route me through to the duty and taxes section. But eventually, several steps deep into the process, the system stops responding to key presses! "1" doesn't work and neither does "2" so without a response, the same message just repeats. But it does offer an alternative and suggestions I call 132610. That's the number I called in the first place to get stuck in this infinite loop!
I try again, this time following a different series of prompts that eventually asks for a tracking number and then proceeds to tell me precisely what the website already does! But it also provides the option to speak to a customer service operator and I'm actually promptly put through. The operator explains that my shipment is valued at US$799 which converts to AU$1,215.97 and it therefore subject to some inbound fees. "Great, but how much and does it match what's in the phishy SMSs I've received?" He promises someone will call be back shortly...
And then, out of the blue 3 days after the initial phishy SMS arrived, an email landed in my inbox:
The dollar figure, the BPOINT address and the messaging all lined up with the SMSs, but that's just merely correlation and if someone had both my phone number and email address they could easily attempt to phish both with the same details. But then, I looked at the attachment to the email and found this:

IT'S THE MISSING LINK!!!
My complete Prusa invoice was attached along with the order number, price and shipping details. In other words, 87% of you were wrong 😲
On a more serious note, Aussies alone are losing north of AU$3B annually to scams, and that's obviously only a drop in the ocean compared to the global scale of this problem. Our Australian Communications and Media Authority body (ACMA) recently reported 336M blocked scam SMSs and technical controls like these are obviously great, but absent from their reporting was the number of scam messages they didn't block. There's an easy explanation for this omission: they simply don't know how many are sent. But if I were to take a guess, they've merely blocked the tip of the iceberg. This is why in addition to technical controls, we reply on human controls which means helping people identify the patterns of a scam: requests for money, a sense of urgency, grammar and casing that's a bit off, odd looking URLs. You know, stuff like this:
What makes this situation so ridiculous is that while we're all watching for scammers attempting to imitate legitimate organisations, FedEx is out there imitating scammers! Here we are in the era of burgeoning AI-driven scams that are becoming increasingly hard for humans to identify, and FedEx is like "here, hold my beer" as they one-up the scammers at their own game and do a perfect job of being completely indistinguishable from them.
Ah well, as I ultimately lament in these situations, it's a good time to be in the industry 😊